
כדי לוודא שתרחישי השימוש של צרכני הנתונים מתקיימים, חשוב לתכנן ולבנות בקפידה את מוצרי הנתונים ברשת נתונים. העיצוב של מוצר נתונים מתחיל בהגדרה של האופן שבו צרכני הנתונים ישתמשו במוצר הזה, ואיך המוצר הזה ייחשף לצרכנים. מוצרי נתונים ב-data mesh מבוססים על מאגר נתונים (לדוגמה, מחסן נתונים או אגם נתונים של דומיין). כשיוצרים מוצרי נתונים ב-data mesh, יש כמה גורמים חשובים שכדאי לקחת בחשבון לאורך התהליך. השיקולים האלה מתוארים במסמך הזה.
המאמר הזה הוא חלק מסדרה שמתארת איך להטמיע רשת נתונים ב- Google Cloud. המאמר הזה מיועד למי שקרא את המאמרים ארכיטקטורה ופונקציות ב-Data Mesh ו-איך בונים Data Mesh מודרני ומבוזר באמצעות Google Cloud ומכיר את המושגים שמתוארים בהם.
הסדרה כוללת את החלקים הבאים:
- ארכיטקטורה ופונקציות ברשת נתונים
- תכנון פלטפורמת נתונים בשירות עצמי לרשת נתונים
- יצירת מוצרי נתונים ב-Data Mesh (המסמך הזה)
- איתור ושימוש במוצרי נתונים ברשת נתונים
כשיוצרים מוצרי נתונים ממחסן נתונים של דומיין, מומלץ ליצרני הנתונים לתכנן בקפידה ממשקי ניתוח (צריכה) למוצרים האלה. ממשקי הצריכה האלה כוללים קבוצה של הבטחות לגבי איכות הנתונים ופרמטרים תפעוליים, לצד מודל תמיכה במוצר ותיעוד מוצר. העלות של שינוי ממשקי צריכה היא בדרך כלל גבוהה, כי גם יצרן הנתונים וגם צרכני הנתונים צריכים לשנות את תהליכי הצריכה והאפליקציות שלהם. בהתחשב בכך שצרכני הנתונים נמצאים לרוב ביחידות ארגוניות שונות מאלה של יוצרי הנתונים, תיאום השינויים יכול להיות מסובך.
בקטעים הבאים מוסבר מה צריך לקחת בחשבון כשיוצרים מחסן נתונים של דומיין, מגדירים ממשקי צריכה וחושפים את הממשקים האלה לצרכני נתונים.
יצירת מחסן נתונים של הדומיין
אין הבדל מהותי בין בניית מחסן נתונים עצמאי לבין בניית מחסן נתונים של דומיין שממנו צוות הפקת הנתונים יוצר מוצרי נתונים. ההבדל האמיתי היחיד בין השניים הוא שבמקרה השני, מוצג חלק מהנתונים דרך ממשקי הצריכה.
במחסני נתונים רבים, הנתונים הגולמיים שנקלטים ממקורות נתונים תפעוליים עוברים תהליך של העשרה ואימות איכות הנתונים (אוצרות). באגמי נתונים שמנוהלים על ידי Dataplex Universal Catalog, נתונים שנאספו בדרך כלל מאוחסנים באזורים ייעודיים. כשמסיימים את האוצרות, קבוצת משנה של הנתונים אמורה להיות מוכנה לשימוש מחוץ לדומיין באמצעות כמה סוגים של ממשקי משתמש. כדי להגדיר את ממשקי הצריכה האלה, ארגון צריך לספק קבוצה של כלים לצוותי הדומיין שחדשים בגישה של רשת נתונים. הכלים האלה מאפשרים למפיקי נתונים ליצור מוצרי נתונים חדשים על בסיס שירות עצמי. שיטות מומלצות מפורטות במאמר תכנון פלטפורמת נתונים בשירות עצמי.
בנוסף, מוצרי נתונים צריכים לעמוד בדרישות של משילות מידע (data governance) שמוגדרות באופן מרכזי. הדרישות האלה משפיעות על איכות הנתונים, על זמינות הנתונים ועל ניהול מחזור החיים. הדרישות האלה עוזרות לבנות את האמון של צרכני הנתונים במוצרי הנתונים, ומעודדות שימוש במוצרי הנתונים. לכן, כדאי להשקיע מאמץ כדי לעמוד בדרישות האלה וליהנות מהיתרונות שלהן.
הגדרת ממשקי צריכה
מומלץ ליצרני נתונים להשתמש בכמה סוגים של ממשקי משתמש, במקום להגדיר רק אחד או שניים. לכל סוג של ממשק בניתוח נתונים יש יתרונות וחסרונות, ואין סוג אחד של ממשק שמצטיין בכל דבר. כשיוצרי נתונים מעריכים את ההתאמה של כל סוג ממשק, הם צריכים להביא בחשבון את הגורמים הבאים:
- היכולת לבצע את עיבוד הנתונים הנדרש.
- יכולת הרחבה כדי לתמוך בתרחישי שימוש נוכחיים ועתידיים של צרכני נתונים.
- הביצועים שנדרשים על ידי צרכני הנתונים.
- עלות הפיתוח והתחזוקה.
- העלות של הפעלת הממשק.
- תמיכה בשפות ובכלים שבהם הארגון שלכם משתמש.
- תמיכה בהפרדה בין אחסון לבין מחשוב.
לדוגמה, אם הדרישה העסקית היא להריץ שאילתות ניתוח על מערך נתונים בגודל פטה-בייט, הממשק היחיד שמתאים לכך הוא תצוגה של BigQuery. אבל אם הדרישות הן לספק נתונים כמעט בזמן אמת, ממשק שמבוסס על Pub/Sub מתאים יותר.
בממשקים רבים כאלה לא צריך להעתיק או לשכפל נתונים קיימים. ברובם אפשר גם להפריד בין אחסון לבין מחשוב, תכונה חשובה שלGoogle Cloud כלי ניתוח. הצרכנים של הנתונים שנחשפים דרך הממשקים האלה מעבדים את הנתונים באמצעות משאבי המחשוב שזמינים להם. מפיקי הנתונים לא צריכים להקצות משאבים נוספים לתשתית.
יש מגוון רחב של ממשקי צריכה. אלה הממשקים הכי נפוצים שמשמשים ב-Data Mesh, והם מפורטים בקטעים הבאים:
- תצוגות מורשות ופונקציות
- ממשקי API לקריאה ישירה
- נתונים כמקורות נתונים
- Data access API
- בלוקים של Looker
- מודלים של למידת מכונה (ML)
רשימת הממשקים במסמך הזה היא חלקית. יש גם אפשרויות אחרות שתוכלו לשקול לגבי ממשקי הצריכה שלכם (למשל, BigQuery sharing (לשעבר Analytics Hub)). אבל הממשקים האחרים האלה לא נכללים במסמך הזה.
תצוגות ופונקציות מורשות
כדאי לחשוף מוצרי נתונים ככל האפשר באמצעות תצוגות מורשות ופונקציות מורשות, כולל פונקציות שמחזירות ערכים של טבלה. מערכי נתונים מורשים מספקים דרך נוחה להרשאה אוטומטית של כמה תצוגות מפורטות. שימוש בתצוגות מורשות מונע גישה ישירה לטבלאות הבסיס, ומאפשר לכם לבצע אופטימיזציה של הטבלאות הבסיסיות והשאילתות שמופעלות עליהן, בלי להשפיע על השימוש של הצרכנים בתצוגות האלה. המשתמשים בממשק הזה משתמשים ב-SQL כדי להריץ שאילתות על הנתונים. בדיאגרמה הבאה מוצג שימוש במערכי נתונים מורשים כממשק הצריכה.
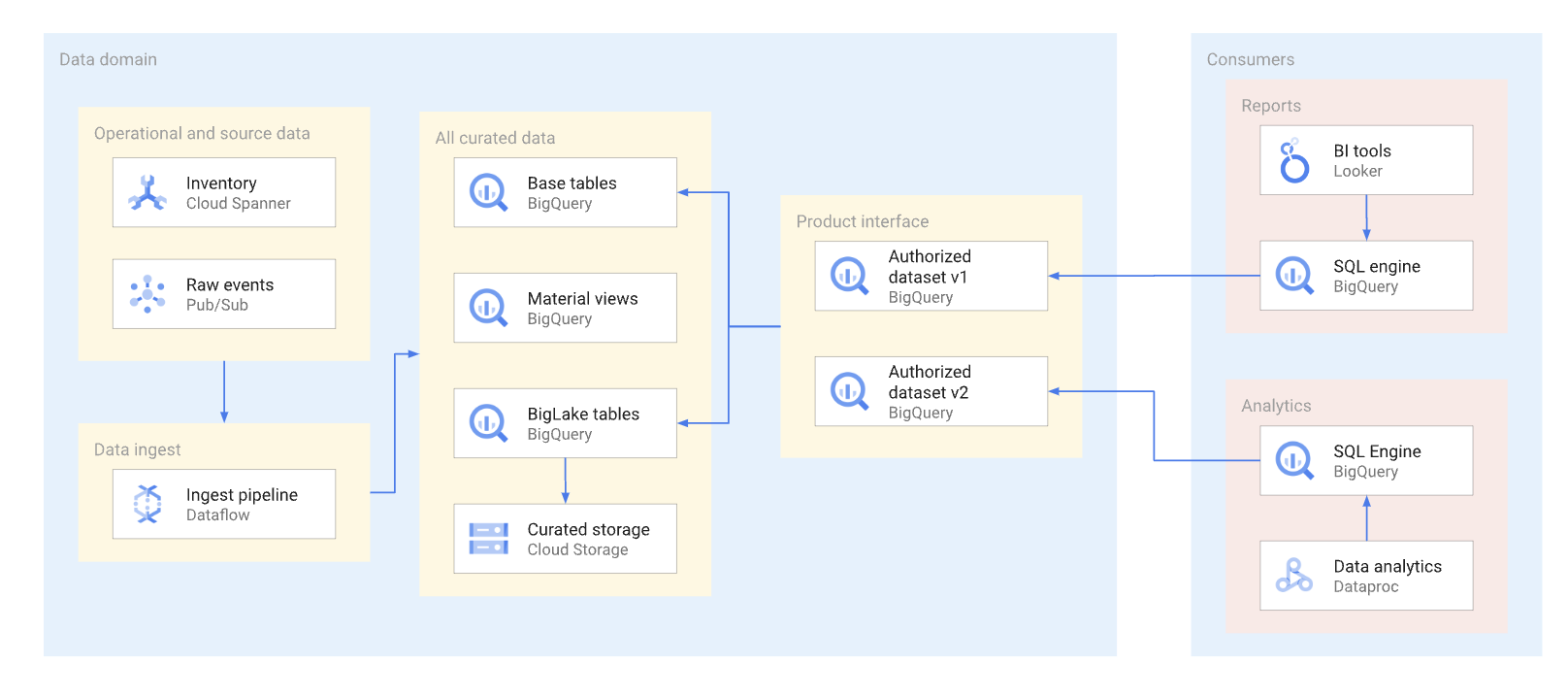
בעזרת מערכי נתונים ותצוגות מורשים, קל יותר ליצור גרסאות שונות של ממשקים. כפי שמוצג בתרשים הבא, יש שתי גישות עיקריות לניהול גרסאות שיוצרי נתונים יכולים לנקוט:
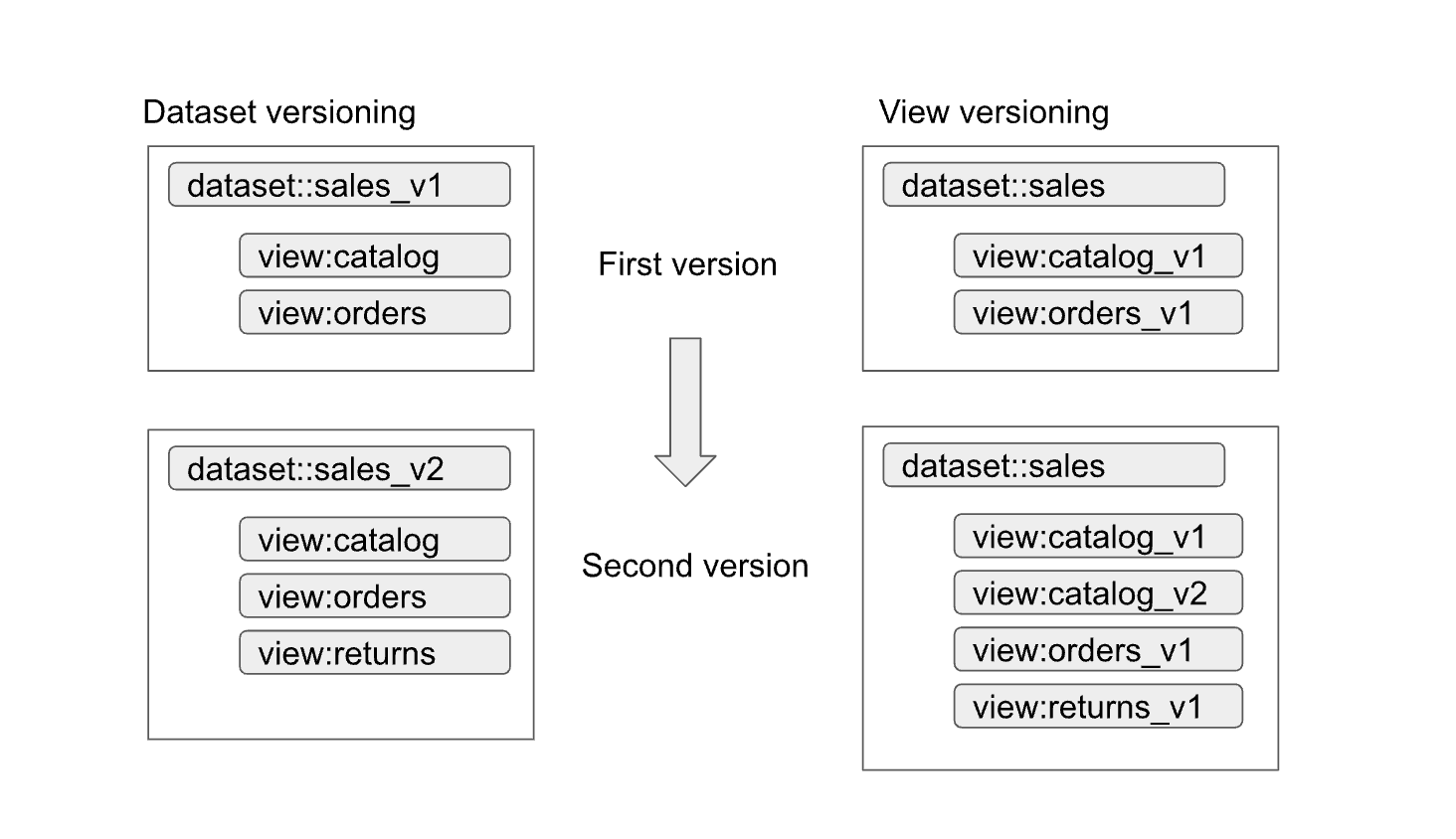
אפשר לסכם את הגישות באופן הבא:
- יצירת גרסאות של מערך הנתונים: בגישה הזו, יוצרים גרסאות של השם של מערך הנתונים.
אתם לא יוצרים גרסאות של התצוגות והפונקציות בתוך מערך הנתונים. השמות של התצוגות והפונקציות נשארים זהים בכל הגרסאות. לדוגמה, הגרסה הראשונה של מערך נתוני מכירות מוגדרת במערך נתונים בשם
sales_v1עם שתי תצוגות,catalogו-orders. בגרסה השנייה, מערך הנתונים של המכירות נקראsales_v2, ולתצוגות הקודמות במערך הנתונים יש את השמות הקודמים שלהן, אבל הן כוללות סכימות חדשות. יכול להיות שגם לגרסה השנייה של מערך הנתונים יתווספו תצוגות חדשות, או שיוסרו ממנה תצוגות קודמות. - ניהול גרסאות של תצוגות מפורטות: בגישה הזו, הגרסאות של התצוגות המפורטות בתוך מערך הנתונים מנוהלות, ולא הגרסאות של מערך הנתונים עצמו. לדוגמה, מערך הנתונים של המכירות שומר על השם
salesבלי קשר לגרסה. עם זאת, השמות של התצוגות בתוך מערך הנתונים משתנים כדי לשקף כל גרסה חדשה של התצוגה (למשל,catalog_v1,catalog_v2,orders_v1,orders_v2ו-orders_v3).
הגישה הטובה ביותר לניהול גרסאות בארגון שלכם תלויה במדיניות הארגון ובמספר התצוגות שיוצאות משימוש בעקבות העדכון של הנתונים הבסיסיים. השימוש בניהול גרסאות של מערך נתונים מומלץ במקרים שבהם נדרש עדכון משמעותי של המוצר וצריך לשנות את רוב התצוגות. ניהול גרסאות של תצוגות מוביל לפחות תצוגות עם שמות זהים במערכי נתונים שונים, אבל עלול להוביל לאי בהירות. לדוגמה, איך אפשר לדעת אם הצטרפות בין מערכי נתונים פועלת בצורה תקינה. גישה היברידית יכולה להיות פשרה טובה. בגישה היברידית, שינויים תואמים בסכימה מותרים במערך נתונים יחיד, ושינויים לא תואמים דורשים מערך נתונים חדש.
שיקולים לגבי טבלאות BigLake
אפשר ליצור תצוגות מורשות לא רק בטבלאות BigQuery, אלא גם בטבלאות BigLake. טבלאות BigLake מאפשרות למשתמשים לשלוח שאילתות לנתונים שמאוחסנים ב-Cloud Storage באמצעות ממשק BigQuery SQL. טבלאות BigLake תומכות בבקרת גישה פרטנית בלי שצרכני הנתונים יצטרכו הרשאות קריאה לקטגוריית Cloud Storage הבסיסית.
מפיקי נתונים צריכים לקחת בחשבון את הדברים הבאים לגבי טבלאות BigLake:
- העיצוב של פורמטי הקבצים ופריסת הנתונים משפיעים על הביצועים של השאילתות. פורמטים מבוססי-עמודות, למשל Parquet או ORC, בדרך כלל מתאימים יותר לשאילתות ניתוח מאשר פורמטים של JSON או CSV.
- פריסת מחיצות ב-Hive מאפשרת לכם להסיר מחיצות ולזרז שאילתות שמשתמשות בעמודות של חלוקה למחיצות.
- בשלב התכנון צריך לקחת בחשבון גם את מספר הקבצים ואת ביצועי השאילתה המועדפים לגבי גודל הקובץ.
אם שאילתות שמשתמשות בטבלאות BigLake לא עומדות בדרישות של הסכם רמת השירות (SLA) לממשק, ואי אפשר לבצע אופטימיזציה שלהן, מומלץ לבצע את הפעולות הבאות:
- כדי שהנתונים יהיו זמינים לצרכן הנתונים, צריך להמיר אותם לאחסון ב-BigQuery.
- מגדירים מחדש את התצוגות המורשות לשימוש בטבלאות BigQuery.
בדרך כלל, הגישה הזו לא גורמת לשיבושים בנתונים של הצרכנים ולא דורשת שינויים בשאילתות שלהם. אפשר לייעל את השאילתות באחסון BigQuery באמצעות טכניקות שלא אפשריות בטבלאות BigLake. לדוגמה, באמצעות אחסון ב-BigQuery, צרכנים יכולים להריץ שאילתות על תצוגות חומריות עם חלוקה למחיצות ואשכולות שונים מאלה של טבלאות הבסיס, והם יכולים להשתמש ב-BigQuery BI Engine.
ממשקי API לקריאה ישירה
בדרך כלל אנחנו לא ממליצים ליצרני נתונים לתת לצרכני נתונים גישת קריאה ישירה לטבלאות הבסיס, אבל לפעמים כדאי לאפשר גישה כזו מסיבות כמו ביצועים ועלות. במקרים כאלה, חשוב במיוחד לוודא שסכימת הטבלה יציבה.
יש שתי דרכים לגשת ישירות לנתונים במחסן נתונים טיפוסי. מפיקי נתונים יכולים להשתמש ב-BigQuery Storage Read API או ב-Cloud Storage JSON או XML APIs. התרשים הבא מציג שתי דוגמאות לצרכנים שמשתמשים בממשקי ה-API האלה. אחד מהם הוא תרחיש שימוש בלמידת מכונה (ML), והשני הוא משימת עיבוד נתונים.
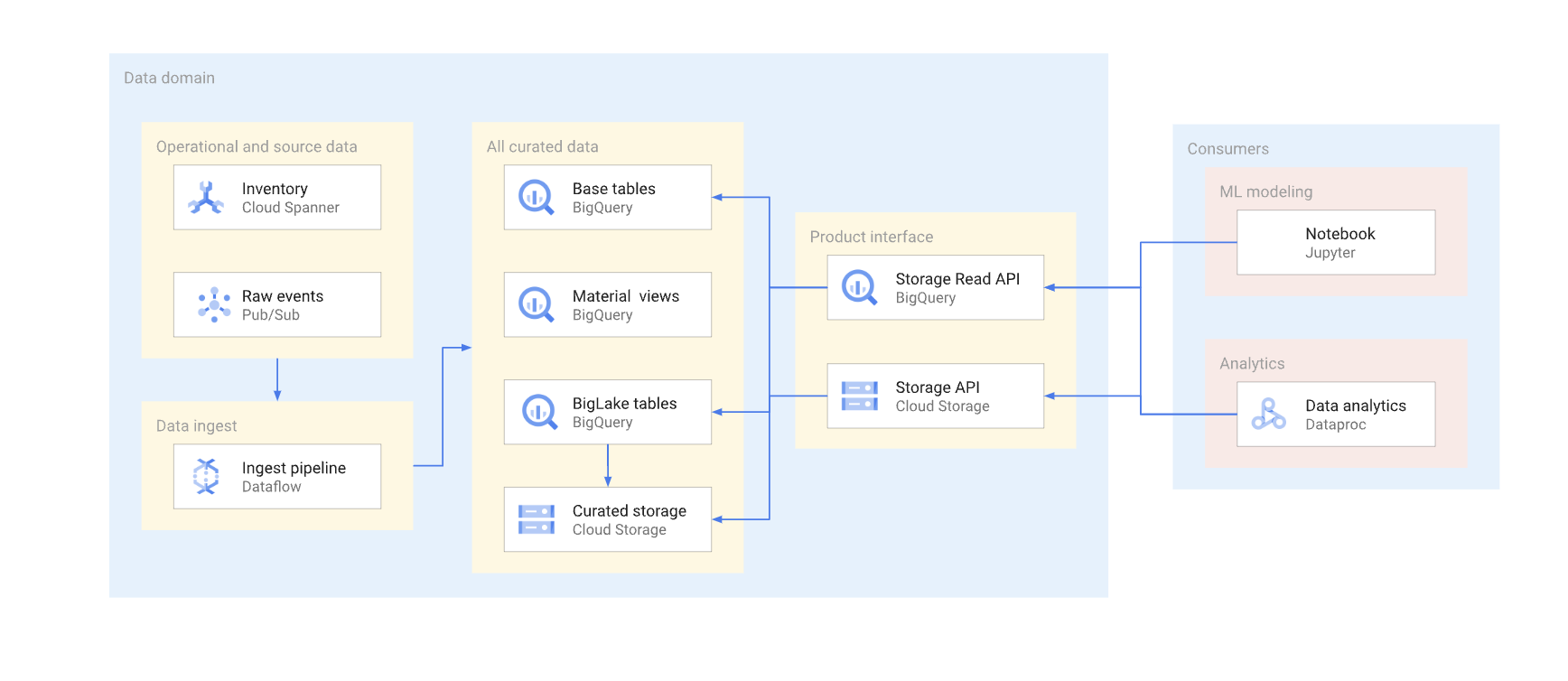
הוספת גרסאות לממשק קריאה ישירה היא תהליך מורכב. בדרך כלל, יוצרי הנתונים צריכים ליצור טבלה נוספת עם סכימה שונה. בנוסף, הם צריכים לתחזק שתי גרסאות של הטבלה עד שכל הצרכנים של הנתונים בגרסה שהוצאה משימוש יעברו לגרסה החדשה. אם הלקוחות יכולים לסבול את השיבוש שייגרם כתוצאה מבנייה מחדש של הטבלה וממעבר לסכימה החדשה, אפשר להימנע משכפול הנתונים. במקרים שבהם שינויים בסכימה יכולים להיות תואמים לאחור, אפשר להימנע מהעברה של טבלת הבסיס. לדוגמה, לא צריך להעביר את טבלת הבסיס אם נוספו רק עמודות חדשות והנתונים בעמודות האלה מולאו מחדש לכל השורות.
בטבלה הבאה מוצג סיכום של ההבדלים בין Storage Read API לבין Cloud Storage API. באופן כללי, מומלץ ליצרני נתונים להשתמש ב-BigQuery API עבור אפליקציות אנליטיות, בכל מקרה שבו הדבר אפשרי.
Storage Read API: אפשר להשתמש ב-Storage Read API כדי לקרוא נתונים בטבלאות של BigQuery ובטבלאות של BigLake. ה-API הזה תומך בסינון ובבקרת גישה ברמת פירוט גבוהה, והוא יכול להיות אפשרות טובה לניתוח נתונים יציב או לצרכני ML.
Cloud Storage API: יצרני נתונים עשויים להזדקק לשיתוף ישיר של קטגוריה מסוימת ב-Cloud Storage עם צרכני נתונים. לדוגמה, יצרני נתונים יכולים לשתף את הקטגוריה אם צרכני הנתונים לא יכולים להשתמש בממשק SQL מסיבה כלשהי, או אם הקטגוריה מכילה פורמטים של נתונים שלא נתמכים על ידי Storage Read API.
באופן כללי, אנחנו לא ממליצים ליצרני נתונים לאפשר גישה ישירה דרך ממשקי ה-API של Storage, כי גישה ישירה לא מאפשרת סינון ושליטה מדויקת בהרשאות הגישה. עם זאת, גישה ישירה יכולה להיות בחירה טובה למערכי נתונים יציבים וקטנים (בגודל של גיגה-בייט).
מתן גישה ל-Pub/Sub לקטגוריה מאפשר לצרכני הנתונים להעתיק בקלות את הנתונים לפרויקטים שלהם ולעבד אותם שם. באופן כללי, לא מומלץ להעתיק נתונים אם אפשר להימנע מכך. ריבוי עותקים של נתונים מגדיל את עלויות האחסון, ומוסיף לעלויות התחזוקה והמעקב אחר השתלשלות הנתונים.
נתונים כמקורות נתונים
דומיין יכול לחשוף נתונים בסטרימינג על ידי פרסום הנתונים האלה בנושא Pub/Sub. מנויים שרוצים לצרוך את הנתונים יוצרים מינויים כדי לצרוך את ההודעות שפורסמו בנושא הזה. כל מנוי מקבל נתונים ומשתמש בהם באופן עצמאי. בתרשים הבא מוצגת דוגמה לזרמי נתונים כאלה.
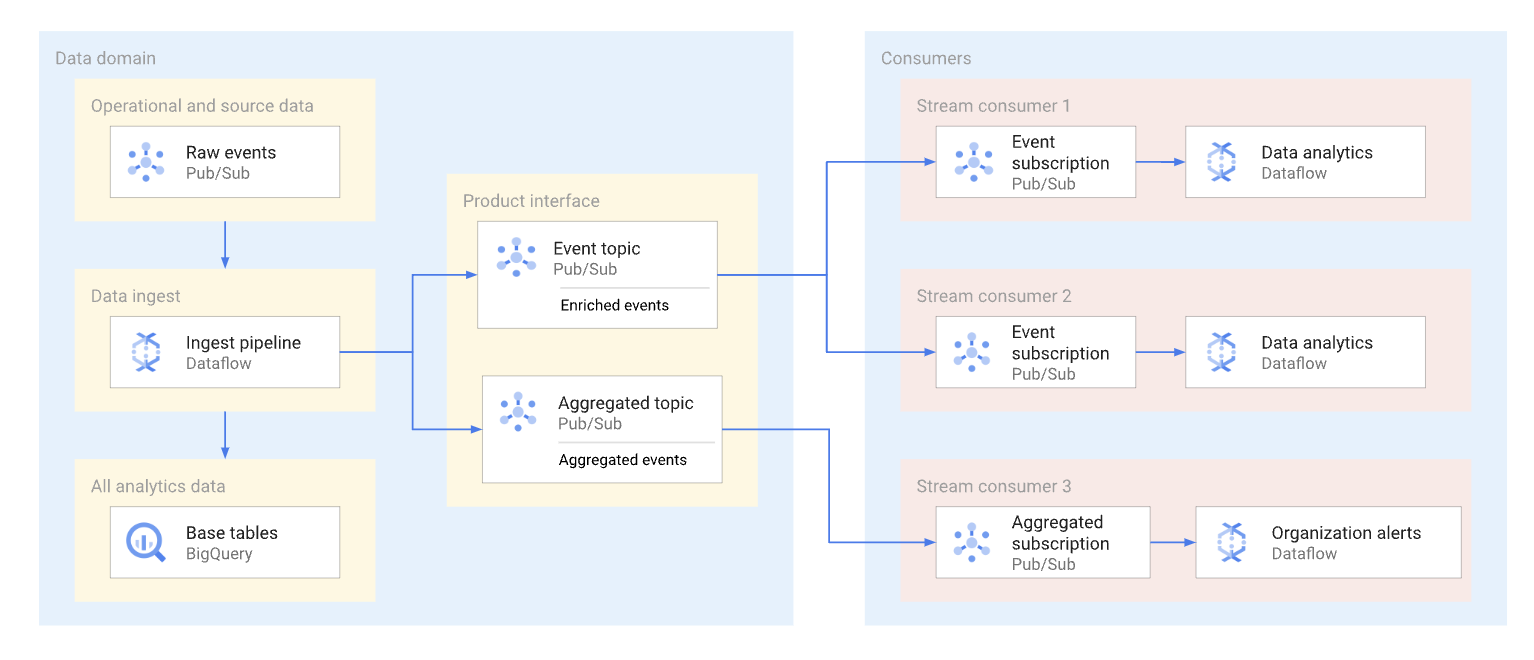
בתרשים, צינור ההעברה קורא אירועים גולמיים, מעשיר אותם (מבצע אוצרות) ושומר את הנתונים המאורגנים במאגר הנתונים האנליטי (טבלת הבסיס של BigQuery). במקביל, צינור הנתונים מפרסם את האירועים המועשרים בנושא ייעודי. כמה מנויים צורכים את הנושא הזה, וכל אחד מהם עשוי לסנן את האירועים האלה כדי לקבל רק את האירועים שרלוונטיים לו. בנוסף, צינור הנתונים צובר ומפרסם נתונים סטטיסטיים של אירועים בנושא משלו משלו כדי שצרכן נתונים אחר יוכל לעבד אותם.
אלה כמה תרחישים לדוגמה לשימוש במינויים ל-Pub/Sub:
- אירועים מועשרים, כמו אספקת מידע מלא על פרופיל הלקוח יחד עם נתונים על הזמנה ספציפית של לקוח.
- התראות על צבירה כמעט בזמן אמת, כמו נתונים סטטיסטיים של הזמנות כוללות ב-15 הדקות האחרונות.
- התראות ברמת העסק, כמו יצירת התראה אם נפח ההזמנות ירד ב-20% בהשוואה לתקופה דומה ביום הקודם.
- התראות על שינוי בנתונים (בדומה למושג של סימון נתונים שהשתנו (CDC)), למשל, שינוי סטטוס של הזמנה מסוימת.
פורמט הנתונים שבו משתמשים יוצרי הנתונים בהודעות Pub/Sub משפיע על העלויות ועל אופן העיבוד של ההודעות האלה. לסטרימינג של נפחים גדולים בארכיטקטורת רשת נתונים, כדאי להשתמש בפורמטים Avro או Protobuf. אם מקורות הנתונים משתמשים בפורמטים האלה, הם יכולים להקצות סכימות לנושאי Pub/Sub. הסכימות עוזרות לוודא שהצרכנים מקבלים הודעות בפורמט תקין.
מבנה נתוני הסטרימינג יכול להשתנות כל הזמן, ולכן כדי ליצור גרסאות של הממשק הזה צריך לתאם בין הגורמים שמפיקים את הנתונים לבין הגורמים שצורכים אותם. יש כמה גישות נפוצות שיוצרי נתונים יכולים לנקוט, והן:
- נושא חדש נוצר בכל פעם שמבנה ההודעה משתנה. לרוב, הנושא הזה כולל סכימת Pub/Sub מפורשת. צרכני נתונים שזקוקים לממשק החדש יכולים להתחיל לצרוך את הנתונים החדשים. גרסת ההודעה משתמעת משם הנושא, למשל,
click_events_v1. פורמטים של הודעות הם בעלי הקלדה חזקה. אין הבדל בפורמט ההודעה בין הודעות באותו נושא. החיסרון בגישה הזו הוא שאולי יהיו צרכני נתונים שלא יוכלו לעבור למינוי החדש. במקרה כזה, יוצר הנתונים צריך להמשיך לפרסם אירועים בכל הנושאים הפעילים למשך זמן מסוים, וצרכני הנתונים שנרשמו לנושא צריכים להתמודד עם פער בזרימת ההודעות או לבטל את הכפילות של ההודעות. - הנתונים תמיד מתפרסמים באותו נושא. עם זאת, המבנה של ההודעה יכול להשתנות. מאפיין ההודעה ב-Pub/Sub (נפרד מהמטען הייעודי (payload)) מגדיר את גרסת ההודעה. לדוגמה,
v=1.0. הגישה הזו מבטלת את הצורך להתמודד עם פערים או כפילויות, אבל כל צרכני הנתונים צריכים להיות מוכנים לקבל הודעות מסוג חדש. גם יוצרי נתונים לא יכולים להשתמש בסכימות של נושאי Pub/Sub בגישה הזו. - גישה היברידית. לסכימת ההודעה יכול להיות קטע נתונים שרירותי שאפשר להשתמש בו לשדות חדשים. הגישה הזו יכולה לספק איזון סביר בין נתונים עם הקלדה חזקה לבין שינויים תכופים ומורכבים בגרסה.
Data access API
מפיקי נתונים יכולים ליצור API בהתאמה אישית כדי לגשת ישירות לטבלאות הבסיס במחסן נתונים. בדרך כלל, הספקים האלה חושפים את ה-API המותאם אישית הזה כ-API ל-REST או כ-API ל-gRPC, ופורסים אותו ב-Cloud Run או באשכול Kubernetes. שער API כמו Apigee יכול לספק תכונות נוספות אחרות, כמו הגבלת תעבורה או שכבת מטמון. הפונקציות האלה שימושיות כשחושפים את ה-API לגישה לנתונים לצרכנים מחוץ לארגון Google Cloud . מועמדים פוטנציאליים לשימוש ב-API לגישה לנתונים הם שאילתות שרגישות לזמן האחזור ושמתבצעות בהן פעולות בו-זמניות רבות. שתי הקטגוריות האלה מחזירות תוצאה קטנה יחסית ב-API יחיד, ואפשר לשמור אותן במטמון בצורה יעילה.
דוגמאות ל-API מותאם אישית לגישה לנתונים:
- תצוגה משולבת של מדדי ה-SLA של הטבלה או המוצר.
- 10 הרשומות הראשונות (יכול להיות שהן שמורות במטמון) מטבלה מסוימת.
- מערך נתונים של נתונים סטטיסטיים של טבלה (מספר השורות הכולל או פיזור הנתונים בעמודות מפתח).
כל ההנחיות והכללים שהארגון קבע לגבי יצירת ממשקי API של אפליקציות חלים גם על ממשקי API בהתאמה אישית שנוצרו על ידי יוצרי נתונים. ההנחיות והמדיניות של הארגון צריכות לכלול נושאים כמו אירוח, מעקב, בקרת גישה וניהול גרסאות.
החיסרון של API מותאם אישית הוא שיוצרי הנתונים אחראים לכל התשתית הנוספת שנדרשת לאירוח הממשק הזה, כמו גם לקידוד ולתחזוקה של ה-API המותאם אישית. מומלץ ליצרני נתונים לבדוק אפשרויות אחרות לפני שמחליטים ליצור ממשקי API מותאמים אישית לגישה לנתונים. לדוגמה, מפיקי נתונים יכולים להשתמש ב-BigQuery BI Engine כדי להקטין את זמן האחזור של התגובה ולהגדיל את מספר הפעולות שמתבצעות בו-זמנית.
Looker Blocks
במוצרים כמו Looker, שנעשה בהם שימוש נרחב בכלים של בינה עסקית (BI), כדאי לשמור קבוצה של ווידג'טים ספציפיים לכלים של BI. צוות הפקת הנתונים מכיר את מודל הנתונים הבסיסי שבו נעשה שימוש בדומיין, ולכן הוא הצוות המתאים ביותר ליצור ולתחזק קבוצה מוכנה מראש של תרשימים.
במקרה של Looker, הוויזואליזציה הזו יכולה להיות קבוצה של Looker Blocks (מודלים מוכנים מראש של נתונים ב-LookML). אפשר לשלב בקלות את Looker Blocks במרכזי בקרה שמתארחים אצל צרכנים.
מודלים של למידת מכונה
לצוותים שעובדים בתחומי נתונים יש הבנה וידע מעמיקים לגבי הנתונים שלהם, ולכן הם לרוב הצוותים הכי מתאימים לבנייה ולתחזוקה של מודלים של למידת מכונה שאומנו על נתוני התחום. אפשר לחשוף את המודלים האלה של למידת מכונה דרך כמה ממשקים שונים, כולל:
- אפשר לפרוס מודלים של BigQuery ML במערך נתונים ייעודי ולשתף אותם עם צרכני נתונים לחיזויים של BigQuery.
- אפשר לייצא מודלים של BigQuery ML ל-Vertex AI כדי להשתמש בהם לחיזויים אונליין.
שיקולים לגבי מיקום הנתונים בממשקי צריכה
שיקול חשוב כשיוצרי נתונים מגדירים ממשקי צריכה למוצרי נתונים הוא מיקום הנתונים. באופן כללי, כדי לצמצם את העלויות, הנתונים צריכים לעבור עיבוד באותו אזור שבו הם מאוחסנים. הגישה הזו עוזרת למנוע חיובים על תעבורת נתונים יוצאת (egress) בין אזורים. בנוסף, הגישה הזו מאפשרת צריכת נתונים עם זמן האחזור הקצר ביותר. לכן, נתונים שמאוחסנים במיקומים מרובי-אזוריים ב-BigQuery הם בדרך כלל המועמדים הכי טובים להצגה כמוצר נתונים.
עם זאת, מטעמי ביצועים, נתונים שמאוחסנים ב-Cloud Storage ונחשפים דרך טבלאות BigLake או ממשקי API לקריאה ישירה צריכים להיות מאוחסנים בקטגוריות אזוריות.
אם נתונים שנחשפים במוצר אחד נמצאים באזור אחד וצריך לשלב אותם עם נתונים בדומיין אחר באזור אחר, צרכני הנתונים צריכים לקחת בחשבון את המגבלות הבאות:
אין תמיכה בשאילתות חוצות אזורים שמשתמשות ב-BigQuery SQL. אם שיטת הצריכה העיקרית של הנתונים היא BigQuery SQL, כל הטבלאות בשאילתה צריכות להיות באותו מיקום.
התחייבויות לתמחור קבוע ב-BigQuery הן אזוריות. אם בפרויקט נעשה שימוש רק בהתחייבות לתשלום קבוע באזור אחד, אבל מתבצעות בו שאילתות על מוצר נתונים באזור אחר, יחול תמחור לפי דרישה.
צרכני נתונים יכולים להשתמש בממשקי API לקריאה ישירה כדי לקרוא נתונים מאזור אחר. עם זאת, חלים חיובים על תעבורת נתונים יוצאת (egress) בין אזורים, ולצרכני הנתונים סביר להניח שיהיה זמן אחזור בהעברות נתונים גדולות.
אפשר לשכפל נתונים שמתבצעת אליהם גישה לעיתים קרובות באזורים שונים, כדי להקטין את העלות ואת זמן האחזור של השאילתות שמופעלות על ידי צרכני המוצר. לדוגמה, אפשר להעתיק מערכי נתונים ב-BigQuery לאזורים אחרים. עם זאת, כדאי להעתיק נתונים רק כשצריך. מומלץ ליצרני נתונים להעתיק רק קבוצת משנה של נתוני המוצרים הזמינים לכמה אזורים. הגישה הזו עוזרת למזער את זמן האחזור ואת העלות של השכפול. הגישה הזו יכולה להוביל לצורך לספק כמה גרסאות של ממשק הצריכה עם אזור מיקום הנתונים שמוגדר באופן מפורש. לדוגמה, אפשר לחשוף תצוגות מורשות של BigQuery באמצעות שמות כמו sales_eu_v1 ו-sales_us_v1.
בממשקי נתונים של זרם שמשתמשים בנושאים של Pub/Sub לא צריך להוסיף לוגיקה של שכפול כדי לצרוך הודעות באזורים שונים מאלה שבהם ההודעה מאוחסנת. עם זאת, במקרה הזה יחולו חיובים נוספים על תעבורת נתונים יוצאת (egress) בין אזורים.
חשיפת ממשקי צריכה לצרכני נתונים
בקטע הזה מוסבר איך להפוך את ממשקי הצריכה לגלויים לצרכנים פוטנציאליים. Data Catalog הוא שירות שמנוהל במלואו שארגונים יכולים להשתמש בו כדי לספק שירותים של חיפוש נתונים וניהול מטא-נתונים. יוצרי נתונים צריכים לאפשר חיפוש בממשקי הצריכה של מוצרי הנתונים שלהם, ולהוסיף להם את המטא-נתונים המתאימים כדי שצרכני המוצרים יוכלו לגשת אליהם בשירות עצמי. אנחנו
בקטעים הבאים מוסבר איך כל סוג של ממשק מוגדר כרשומה בקטלוג הנתונים.
ממשקי SQL שמבוססים על BigQuery
מטא-נתונים טכניים, כמו שם טבלה שמוגדר במלואו או סכימת טבלה, מתועדים באופן אוטומטי לתצוגות מורשות, לתצוגות BigLake ולטבלאות BigQuery שזמינות דרך Storage Read API. מומלץ שיוצרי נתונים יספקו גם מידע נוסף במסמכי המוצר של הנתונים כדי לעזור לצרכני הנתונים. לדוגמה, כדי לעזור למשתמשים למצוא את תיעוד המוצר של רשומה, יוצרי נתונים יכולים להוסיף כתובת URL לאחד מהתגים שהוחלו על הרשומה. המפיקים יכולים גם לספק את הפרטים הבאים:
- קבוצות של עמודות מצטברות שצריך להשתמש בהן במסנני שאילתות.
- ערכי ספירה לשדות עם סוג ספירה לוגי, אם הסוג לא מסופק כחלק מתיאור השדה.
- אפשר לבצע הצטרפות נתונים עם טבלאות אחרות.
מקורות נתונים
נושאי Pub/Sub נרשמים אוטומטית ב-Data Catalog. עם זאת, יוצרי הנתונים צריכים לתאר את הסכימה במסמכי המוצר.
Cloud Storage API
ב-Data Catalog יש תמיכה בהגדרת רשומות של קבצים ב-Cloud Storage והסכימה שלהן. אם קבוצת קבצים של אגם נתונים מנוהלת על ידי Dataplex Universal Catalog, קבוצת הקבצים נרשמת באופן אוטומטי ב-Data Catalog. קבוצות קבצים שלא משויכות ל-Dataplex Universal Catalog מתווספות באמצעות גישה אחרת.
ממשקים אחרים
אפשר להוסיף ממשקים אחרים שלא נתמכים באופן מובנה ב-Data Catalog על ידי יצירת רשומות בהתאמה אישית.
המאמרים הבאים
- דוגמה להטמעה של ארכיטקטורת רשת נתונים
- BigQuery
- מידע נוסף על Dataplex
- לדוגמאות נוספות של ארכיטקטורות, תרשימים ושיטות מומלצות, עיינו במאמר Cloud Architecture Center.