

In diesem Dokument wird eine allgemeine Architektur für eine Anwendung beschrieben, in der ein Data-Science-Workflow ausgeführt wird, um komplexe Datenanalyse- und Machine-Learning-Aufgaben zu automatisieren.
In dieser Architektur werden Datasets verwendet, die in BigQuery oder AlloyDB for PostgreSQL gehostet werden. Die Architektur ist ein Multi-Agenten-System, mit dem Nutzer Aktionen in Befehlen in natürlicher Sprache ausführen können. So ist es nicht mehr erforderlich, komplexen SQL- oder Python-Code zu schreiben.
Dieses Dokument richtet sich an Architekten, Entwickler und Administratoren, die agentenbasierte KI-Anwendungen erstellen und verwalten. Mit dieser Architektur können Geschäfts- und Datenteams Messwerte in einer Vielzahl von Branchen analysieren, z. B. im Einzelhandel, im Finanzwesen und in der Fertigung. In diesem Dokument wird davon ausgegangen, dass Sie ein grundlegendes Verständnis von agentischen KI-Systemen haben. Informationen dazu, wie sich Agents von nicht agentischen Systemen unterscheiden, finden Sie unter Was ist der Unterschied zwischen KI-Agents, KI-Assistenten und Bots?
Im Abschnitt Bereitstellung dieses Dokuments finden Sie Links zu Codebeispielen, mit denen Sie die Bereitstellung einer agentenbasierten KI-Anwendung testen können, die einen Data-Science-Workflow ausführt.
Architektur
Das folgende Diagramm zeigt die Architektur eines Agents für Data-Science-Workflows.
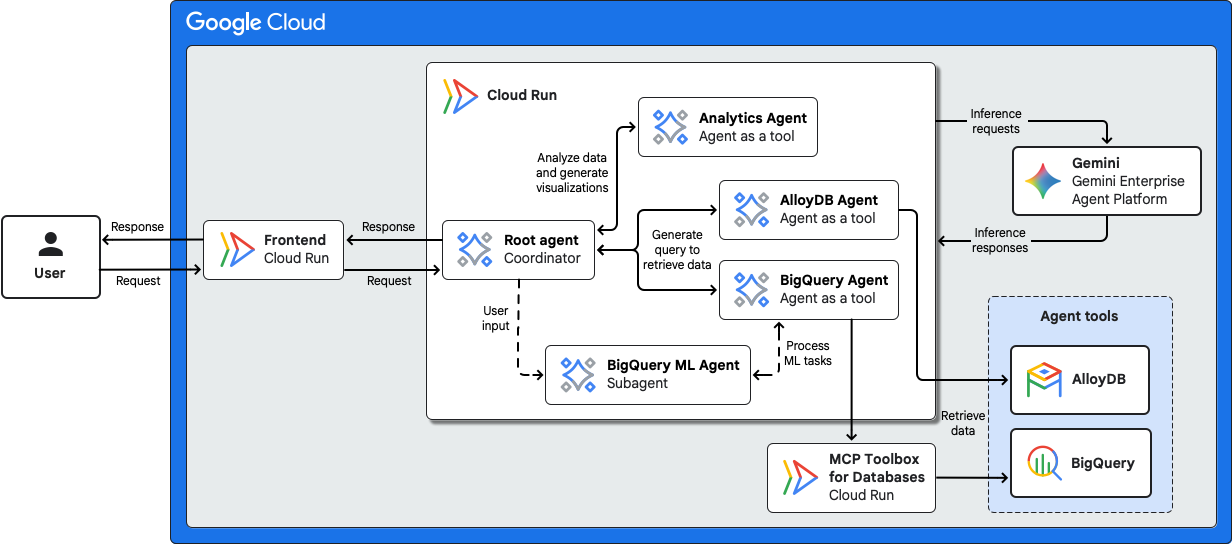
Diese Architektur umfasst die folgenden Komponenten:
| Komponente | Beschreibung |
|---|---|
| Frontend | Nutzer interagieren mit dem Multi-Agent-System über ein Frontend, z. B. eine Chat-Oberfläche, die als serverloser Cloud Run-Dienst ausgeführt wird. |
| Agents | In dieser Architektur werden die folgenden Agents verwendet:
|
| Laufzeit für KI-Agenten | Die KI-Agents in dieser Architektur werden als serverlose Cloud Run-Dienste bereitgestellt. |
| ADK | Das ADK bietet Tools und ein Framework zum Entwickeln, Testen und Bereitstellen von KI-Agenten. Das ADK abstrahiert die Komplexität der Agentenerstellung und ermöglicht es KI-Entwicklern, sich auf die Logik und die Funktionen des Agenten zu konzentrieren. |
| KI-Modell und Modelllaufzeiten | Für die Bereitstellung von Inferenzanfragen verwenden die Agents in dieser Beispielarchitektur das neueste Gemini-Modell auf der Gemini Enterprise Agent Platform. |
Verwendete Produkte
In dieser Beispielarchitektur werden die folgenden Google Cloud und Open-Source-Produkte und ‑Tools verwendet:
- Cloud Run ist eine serverlose Computing-Plattform, mit der Sie Container direkt auf der skalierbaren Infrastruktur von Google ausführen können.
- Agent Development Kit (ADK): Eine Sammlung von Tools und Bibliotheken zum Entwickeln, Testen und Bereitstellen von KI-Agenten.
- Gemini Enterprise Agent Platform: Eine umfassende Plattform, mit der Sie KI‑Agenten auf Unternehmensniveau erstellen, skalieren, verwalten und optimieren können.
- Gemini: Eine Reihe multimodaler KI-Modelle, die von Google entwickelt wurden.
- BigQuery: Ein Data Warehouse für Unternehmen, mit dem Sie Ihre Daten mit integrierten Features wie maschinellem Lernen, raumbezogenen Analysen und Business Intelligence verwalten und analysieren können.
- AlloyDB for PostgreSQL: Ein vollständig verwalteter, PostgreSQL-kompatibler Datenbankdienst, der für Ihre anspruchsvollsten Arbeitslasten entwickelt wurde, einschließlich hybrider transaktionsorientierter und analytischer Verarbeitung.
- MCP Toolbox for Databases: Ein Open-Source-Server für das Model Context Protocol (MCP), mit dem KI-Agenten sicher eine Verbindung zu Datenbanken herstellen können, indem Datenbankkomplexitäten wie Connection Pooling, Authentifizierung und Beobachtbarkeit verwaltet werden.
Bereitstellung
Verwenden Sie Data Science with Multiple Agents, um eine Beispielimplementierung dieser Architektur bereitzustellen. Das Repository enthält zwei Beispieldatasets, um die Flexibilität des Systems zu demonstrieren: ein Flugdataset für die operative Analyse und ein E-Commerce-Verkaufsdataset für die Unternehmensanalyse.
Nächste Schritte
- (Video) Podcast „Agent Factory“ zu KI-Agenten für Data Engineering und Data Science
- (Notebook) Data Science Agent in Colab Enterprise verwenden
- Informationen zum Hosten von KI-Agents in Cloud Run
- Eine Übersicht über Architekturprinzipien und Empfehlungen, die speziell für KI- und ML-Arbeitslasten in Google Cloudgelten, finden Sie im Well-Architected Framework unter KI- und ML-Perspektive.
- Weitere Referenzarchitekturen, Diagramme und Best Practices finden Sie im Cloud-Architekturcenter.
Beitragende
Autorin: Samantha He | Technische Autorin
Weitere Beitragende:
- Amina Mansour | Head of Cloud Platform Evaluations Team
- Kumar Dhanagopal | Cross-Product Solution Developer
- Megan O'Keefe | Developer Advocate
- Rachael Deacon-Smith | Developer Advocate
- Shir Meir Lador | Developer Relations Engineering Manager