
Transkripsi suara memungkinkan Anda mengonversi data audio streaming menjadi teks yang ditranskripsikan secara real time. Agent Assist memberikan saran berdasarkan teks, sehingga data audio harus dikonversi sebelum dapat digunakan. Anda juga dapat menggunakan audio streaming yang ditranskripsikan dengan Customer Experience Insights untuk mengumpulkan data real-time tentang percakapan agen (misalnya, Pemodelan Topik).
Ada dua cara untuk mentranskripsikan audio streaming untuk digunakan dengan Agent Assist: Menggunakan fitur SIPREC, atau dengan melakukan panggilan gRPC dengan data audio sebagai payload. Halaman ini menjelaskan proses mentranskripsikan data audio streaming menggunakan panggilan gRPC.
Transkripsi suara berfungsi menggunakan pengenalan ucapan streaming Speech-to-Text streaming speech recognition. Speech-to-Text menawarkan beberapa model pengenalan, standar dan ditingkatkan. Agent Assist tidak membatasi model yang dapat Anda gunakan dengan transkripsi suara, tetapi transkripsi suara didukung di tingkat GA hanya jika digunakan dengan model telepon atau Chirp 3. Untuk kualitas transkripsi yang optimal, model Chirp 3 direkomendasikan, bergantung pada ketersediaan regional.
Prasyarat
- Buat project di Google Cloud.
- Aktifkan Dialogflow API.
- Hubungi perwakilan Google Anda untuk memastikan akun Anda memiliki akses ke Speech-to-Text model yang ditingkatkan.
Membuat profil percakapan
Untuk membuat profil percakapan, gunakan
konsol Agent Assist atau panggil metode create pada
ConversationProfile
resource secara langsung.
Untuk transkripsi suara, sebaiknya konfigurasi
ConversationProfile.stt_config sebagai InputAudioConfig default saat mengirim
data audio dalam percakapan.
![]()
Mendapatkan transkripsi saat runtime percakapan
Untuk mendapatkan transkripsi saat runtime percakapan, Anda harus membuat peserta untuk percakapan, dan mengirim data audio untuk setiap peserta.
Membuat peserta
Ada tiga jenis
peserta.
Lihat dokumentasi
referensi
untuk mengetahui detail selengkapnya tentang perannya. Panggil metode create pada participant dan tentukan role. Hanya peserta END_USER atau HUMAN_AGENT yang dapat memanggil StreamingAnalyzeContent, yang diperlukan untuk mendapatkan transkripsi.
Mengirim data audio dan mendapatkan transkrip
Anda dapat menggunakan
StreamingAnalyzeContent
untuk mengirim audio peserta ke Google dan mendapatkan transkripsi, dengan
parameter berikut:
Permintaan pertama dalam streaming harus berupa
InputAudioConfig. (Kolom yang dikonfigurasi di sini akan mengganti setelan yang sesuai diConversationProfile.stt_config.) Jangan kirim input audio apa pun hingga permintaan kedua.audioEncodingharus ditetapkan keAUDIO_ENCODING_LINEAR_16atauAUDIO_ENCODING_MULAW.model: Ini adalah model Speech-to-Text yang ingin Anda gunakan untuk mentranskripsikan audio. Tetapkan kolom ini kechirp_3. Varian tidak memengaruhi kualitas transkripsi sehingga, Anda dapat membiarkan Varian model ucapan tidak ditentukan atau memilih Gunakan yang terbaik.singleUtteranceharus ditetapkan kefalseuntuk kualitas transkripsi terbaik. Anda tidak boleh mengharapkanEND_OF_SINGLE_UTTERANCEjikasingleUtteranceadalahfalse, tetapi Anda dapat bergantung padaisFinal==truedi dalamStreamingAnalyzeContentResponse.recognition_resultuntuk menutup streaming sebagian.- Parameter tambahan opsional: Parameter berikut bersifat
opsional. Untuk mendapatkan akses ke parameter ini, hubungi perwakilan Google Anda.
languageCode:language_codeaudio. Nilai defaultnya adalahen-US.alternativeLanguageCodes: Fitur ini hanya tersedia di tingkat GA untuk model Chirp 3. Bahasa tambahan yang mungkin terdeteksi dalam audio. Agent Assist menggunakan kolomlanguage_codeuntuk otomatis mendeteksi bahasa di awal audio dan menetapkannya sebagai default di semua giliran percakapan berikutnya. KolomalternativeLanguageCodesmemungkinkan Anda menentukan lebih banyak opsi untuk dipilih Agent Assist.phraseSets: Nama resource adaptasiphraseSetmodel Speech-to-Text.- Untuk mengonfigurasi adaptasi untuk model Chirp 3, tambahkan frasa inline yang dipisahkan oleh baris baru, tanpa koma.
- Untuk menggunakan adaptasi model dengan model lain seperti
telephonyuntuk transkripsi suara, Anda harus membuatphraseSetterlebih dahulu menggunakan Speech-to-Text API dan menentukan nama resource di sini.
Setelah mengirim permintaan kedua dengan payload audio, Anda akan mulai menerima beberapa
StreamingAnalyzeContentResponsesdari streaming.- Anda dapat menutup streaming sebagian (atau berhenti mengirim dalam beberapa bahasa seperti Python) saat melihat
is_finalditetapkan ketruediStreamingAnalyzeContentResponse.recognition_result. - Setelah Anda menutup streaming sebagian, server akan mengirim kembali respons yang berisi transkrip akhir, beserta saran Dialogflow atau saran Agent Assist yang potensial.
- Anda dapat menutup streaming sebagian (atau berhenti mengirim dalam beberapa bahasa seperti Python) saat melihat
Anda dapat menemukan transkripsi akhir di lokasi berikut:
StreamingAnalyzeContentResponse.message.content.- Jika mengaktifkan notifikasi Pub/Sub, Anda juga dapat melihat transkripsi di Pub/Sub.
Mulai streaming baru setelah streaming sebelumnya ditutup.
- Pengiriman ulang audio: Data audio yang dihasilkan setelah
speech_end_offsetterakhir dari respons denganis_final=trueke waktu mulai streaming baru harus dikirim ulang keStreamingAnalyzeContentuntuk kualitas transkripsi terbaik.
- Pengiriman ulang audio: Data audio yang dihasilkan setelah
Berikut diagram yang menggambarkan cara kerja streaming.
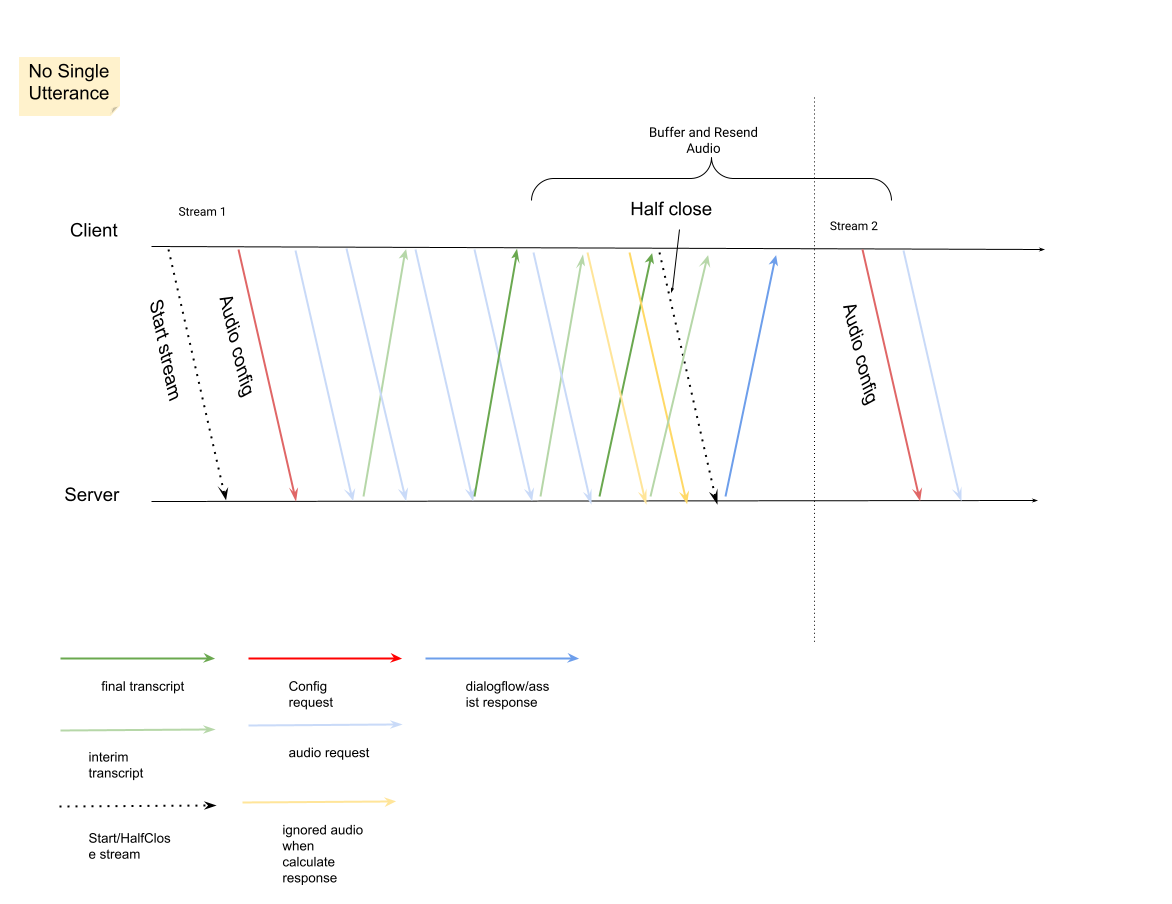
Contoh kode permintaan pengenalan streaming
Contoh kode berikut menggambarkan cara mengirim permintaan transkripsi streaming.
Python
Untuk melakukan autentikasi ke Agent Assist, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Ikuti langkah-langkah berikut untuk melihat file Python untuk conversation_management dan participant_management.
Buka repositori GitHub untuk dokumen Python.
Klik Go to file dan masukkan nama file:
conversation_managementatauparticipant_management.Klik Enter.
Praktik terbaik
Waktu pengiriman pesan adalah saat ucapan dimulai. Gunakan waktu pengiriman pesan untuk menentukan urutan pesan suara ditampilkan atau dianalisis oleh pusat kontak Anda.