
As assinaturas de pensamento são representações encriptadas do processo de pensamento interno do modelo. As assinaturas de pensamento preservam o estado de raciocínio do Gemini durante conversas de vários turnos e vários passos, o que pode ser útil quando usa a chamada de funções. As respostas podem incluir um campo thought_signature em qualquer parte do conteúdo (por exemplo, text, functionCall).
Os modelos Gemini 3 aplicam uma validação mais rigorosa às assinaturas de raciocínio
do que as versões anteriores do Gemini, porque melhoram o desempenho do modelo
para a chamada de funções. Para garantir que o modelo mantém o contexto completo em várias fases de uma conversa, tem de devolver as assinaturas de raciocínio das respostas anteriores nos pedidos subsequentes, mesmo quando usa MINIMALníveis de raciocínio. Se não for devolvida uma assinatura de pensamento necessária quando usar os modelos Gemini 3, o modelo devolve um erro 400.
Embora o Gemini 3 Pro Image não aplique esta validação, para garantir que o modelo mantém o contexto completo em vários turnos de uma conversa, tem de continuar a devolver as assinaturas de reflexão das respostas anteriores nos seus pedidos subsequentes. O Gemini 3 Pro Image não devolve um erro 400 se não for devolvida uma assinatura de pensamento. Para ver exemplos de código relacionados com a edição de imagens com várias interações
usando o Gemini 3 Pro Image, consulte o
Exemplo de edição de imagens com várias interações usando assinaturas de pensamento.
Se estiver a usar o SDK de IA gen da Google oficial (Python, Node.js, Go ou Java) e a usar as funcionalidades padrão do histórico do chat ou a anexar a resposta completa do modelo ao histórico, as assinaturas de reflexão são processadas automaticamente.
Por que motivo são importantes?
Quando um modelo de pensamento chama uma ferramenta externa, pausa o respetivo processo de raciocínio interno. A assinatura de pensamento funciona como um "estado de gravação", o que permite ao modelo retomar a sua cadeia de pensamento de forma integrada assim que fornecer o resultado da função. Sem assinaturas de pensamento, o modelo "esquece" os passos de raciocínio específicos durante a fase de execução da ferramenta. A devolução da assinatura garante:
- Continuidade do contexto: o modelo preserva e pode verificar os passos de raciocínio que justificaram a chamada da ferramenta.
- Raciocínio complexo: permite tarefas com vários passos em que o resultado de uma ferramenta informa o raciocínio para a seguinte.
Voltas e passos
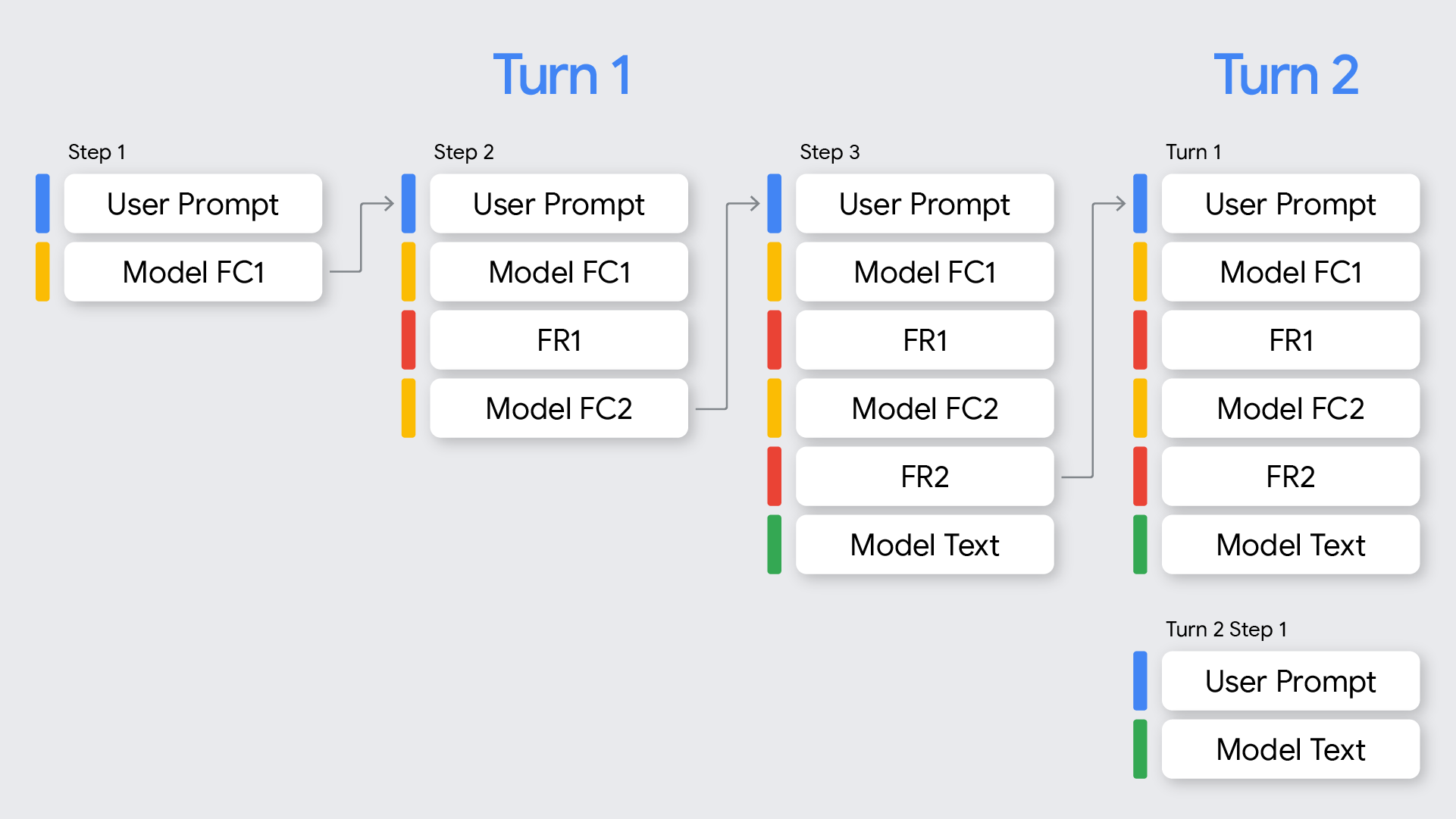
No contexto da chamada de funções, é importante compreender a diferença entre interações e passos:
- Uma interação representa uma troca de conversa completa, que começa com o comando de um utilizador e termina quando o modelo fornece uma resposta final que não é uma chamada de função a esse comando.
- Um passo ocorre num único turno quando o modelo invoca uma função e requer uma resposta da função para continuar o respetivo processo de raciocínio. Conforme mostrado no diagrama, um único turno pode envolver vários passos se o modelo precisar de chamar várias funções sequencialmente para satisfazer o pedido do utilizador.
Como usar as assinaturas de pensamentos
A forma mais simples de processar assinaturas de pensamento é incluir todos os
Parts de todas as mensagens anteriores no histórico da conversa quando enviar um
novo pedido, exatamente como foram devolvidos pelo modelo.
Se não estiver a usar um dos SDKs de IA gen da Google ou precisar de modificar ou cortar o histórico de conversas, tem de garantir que as assinaturas de reflexão são preservadas e enviadas de volta para o modelo.
Quando usar o SDK de IA gen da Google (recomendado)
Quando usar as funcionalidades do histórico do chat dos SDKs ou anexar o objeto content do modelo da resposta anterior ao contents do pedido seguinte, as assinaturas são processadas automaticamente.
O exemplo de Python seguinte mostra o processamento automático:
from google import genai
from google.genai.types import Content, FunctionDeclaration, GenerateContentConfig, Part, ThinkingConfig, Tool
client = genai.Client()
# 1. Define your tool
get_weather_declaration = FunctionDeclaration(
name="get_weather",
description="Gets the current weather temperature for a given location.",
parameters={
"type": "object",
"properties": {"location": {"type": "string"}},
"required": ["location"],
},
)
get_weather_tool = Tool(function_declarations=[get_weather_declaration])
# 2. Send a message that triggers the tool
prompt = "What's the weather like in London?"
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=prompt,
config=GenerateContentConfig(
tools=[get_weather_tool],
thinking_config=ThinkingConfig(include_thoughts=True)
),
)
# 3. Handle the function call
function_call = response.function_calls[0]
location = function_call.args["location"]
print(f"Model wants to call: {function_call.name}")
# Execute your tool (for example, call an API)
# (This is a mock response for the example)
print(f"Calling external tool for: {location}")
function_response_data = {
"location": location,
"temperature": "30C",
}
# 4. Send the tool's result back
# Append this turn's messages to history for a final response.
# The `content` object automatically attaches the required thought_signature behind the scenes.
history = [
Content(role="user", parts=[Part(text=prompt)]),
response.candidates[0].content, # Signature preserved here
Content(
role="tool",
parts=[
Part.from_function_response(
name=function_call.name,
response=function_response_data,
)
],
)
]
response_2 = client.models.generate_content(
model="gemini-2.5-flash",
contents=history,
config=GenerateContentConfig(
tools=[get_weather_tool],
thinking_config=ThinkingConfig(include_thoughts=True)
),
)
# 5. Get the final, natural-language answer
print(f"\nFinal model response: {response_2.text}")
Quando usar o REST ou o processamento manual
Se estiver a interagir diretamente com a API, tem de implementar o processamento de assinaturas com base nas seguintes regras para o Gemini 3 Pro:
- Chamada de funções:
- Se a resposta do modelo contiver uma ou mais partes
functionCall, é necessário umthought_signaturepara o processamento correto. - Nos casos de chamadas de funções paralelas numa única resposta, apenas a parte primeira
functionCallvai conter othought_signature. - Nos casos de chamadas de funções sequenciais em vários passos de uma interação,
cada parte vai conter um
thought_signature.functionCall - Regra: ao criar o pedido seguinte, tem de incluir o elemento
partque contém o elementofunctionCalle o respetivo elementothought_signatureexatamente como foi devolvido pelo modelo. Para a chamada de funções sequencial (com vários passos), a validação é realizada em todos os passos da volta atual e a omissão de umthought_signatureobrigatório para a primeira partefunctionCallem qualquer passo da volta atual resulta num erro400. Uma interação começa com a mensagem do utilizador mais recente que não seja umfunctionResponse. - Se o modelo devolver chamadas de funções paralelas (por exemplo,
FC1+signature,FC2), a sua resposta tem de conter todas as chamadas de funções seguidas de todas as respostas de funções (FC1+signature,FC2,FR1,FR2). As respostas intercaladas (FC1+signature,FR1,FC2,FR2) resultam num erro400. - Existem casos raros em que tem de fornecer
functionCallpartes que não foram geradas pela API e, por isso, não têm uma assinatura de raciocínio associada (por exemplo, quando transfere o histórico de um modelo que não inclui assinaturas de raciocínio). Pode definirthought_signaturecomoskip_thought_signature_validator, mas deve recorrer a esta opção apenas em último recurso, uma vez que afeta negativamente o desempenho do modelo.
- Se a resposta do modelo contiver uma ou mais partes
- Chamada de elementos que não são funções:
- Se a resposta do modelo não contiver um
functionCall, pode incluir umthought_signatureno últimopartda resposta (por exemplo, a última partetext). - Regra: incluir esta assinatura no pedido seguinte é
recomendado para o melhor desempenho, mas omiti-la não causa um
erro. Ao fazer streaming, esta assinatura pode ser devolvida numa parte com conteúdo de texto vazio. Por isso, certifique-se de que analisa todas as partes até que o modelo devolva
finish_reason.
- Se a resposta do modelo não contiver um
Siga estas regras para garantir que o contexto do modelo é preservado:
- Envie sempre o
thought_signaturede volta para o modelo dentro do seuPartoriginal. - Não associe um
Partque contenha uma assinatura a um que não contenha. Isto quebra o contexto posicional do pensamento. - Não combine dois
Parts que contenham assinaturas, porque as strings de assinatura não podem ser unidas.
Exemplo de chamadas de funções sequenciais
O exemplo seguinte mostra um exemplo de chamadas de funções com vários passos em que o utilizador pede "Verificar o estado do voo AA100 e reservar um táxi se houver atrasos", o que requer várias tarefas.
REST
O exemplo seguinte demonstra como processar assinaturas de raciocínio em vários passos num fluxo de trabalho de chamadas de funções sequenciais através da API REST.
Turno 1, passo 1 (pedido do utilizador)
{ "contents": [ { "role": "user", "parts": [ { "text": "Check flight status for AA100 and book a taxi 2 hours before if delayed." } ] } ], "tools": [ { "functionDeclarations": [ { "name": "check_flight", "description": "Gets the current status of a flight", "parameters": { "type": "object", "properties": { "flight": { "type": "string", "description": "The flight number to check" } }, "required": [ "flight" ] } }, { "name": "book_taxi", "description": "Book a taxi", "parameters": { "type": "object", "properties": { "time": { "type": "string", "description": "time to book the taxi" } }, "required": [ "time" ] } } ] } ] }
Turno 1, passo 1 (resposta do modelo)
{ "content": { "role": "model", "parts": [ { "functionCall": { "name": "check_flight", "args": { "flight": "AA100" } }, "thoughtSignature": "<SIGNATURE_A>" } ] } }
Turno 1, passo 2 (resposta do utilizador – envio de resultados da ferramenta)
Uma vez que este turno do utilizador contém apenas um functionResponse (sem texto novo), continuamos no turno 1. Tem de preservar o elemento <SIGNATURE_A>.
{ "role": "user", "parts": [ { "text": "Check flight status for AA100 and book a taxi 2 hours before if delayed." } ] }, { "role": "model", "parts": [ { "functionCall": { "name": "check_flight", "args": { "flight": "AA100" } }, "thoughtSignature": "<SIGNATURE_A>" } ] }, { "role": "user", "parts": [ { "functionResponse": { "name": "check_flight", "response": { "status": "delayed", "departure_time": "12 PM" } } } ] }
Turn 1, Step 2 (resposta do modelo)
O modelo decide agora reservar um táxi com base no resultado da ferramenta anterior.
{ "content": { "role": "model", "parts": [ { "functionCall": { "name": "book_taxi", "args": { "time": "10 AM" } }, "thoughtSignature": "<SIGNATURE_B>" } ] } }
Turno 1, passo 3 (resposta do utilizador: envio do resultado da ferramenta)
Para enviar a confirmação da reserva de táxi, tem de incluir assinaturas para todas
as chamadas de funções neste ciclo (<SIGNATURE_A> e <SIGNATURE_B>).
{ "role": "user", "parts": [ { "text": "Check flight status for AA100 and book a taxi 2 hours before if delayed." } ] }, { "role": "model", "parts": [ { "functionCall": { "name": "check_flight", "args": { "flight": "AA100" } }, "thoughtSignature": "<SIGNATURE_A>" } ] }, { "role": "user", "parts": [ { "functionResponse": { "name": "check_flight", "response": { "status": "delayed", "departure_time": "12 PM" } } } ] }, { "role": "model", "parts": [ { "functionCall": { "name": "book_taxi", "args": { "time": "10 AM" } }, "thoughtSignature": "<SIGNATURE_B>" } ] }, { "role": "user", "parts": [ { "functionResponse": { "name": "book_taxi", "response": { "booking_status": "success" } } } ] } }
Conclusões do chat
O exemplo seguinte demonstra como processar assinaturas de raciocínio em vários passos num fluxo de trabalho de chamadas de funções sequenciais através da API Chat Completions.
Turno 1, passo 1 (pedido do utilizador)
{ "model": "google/gemini-3-pro-preview", "messages": [ { "role": "user", "content": "Check flight status for AA100 and book a taxi 2 hours before if delayed." } ], "tools": [ { "type": "function", "function": { "name": "check_flight", "description": "Gets the current status of a flight", "parameters": { "type": "object", "properties": { "flight": { "type": "string", "description": "The flight number to check." } }, "required": [ "flight" ] } } }, { "type": "function", "function": { "name": "book_taxi", "description": "Book a taxi", "parameters": { "type": "object", "properties": { "time": { "type": "string", "description": "time to book the taxi" } }, "required": [ "time" ] } } } ] }
Turno 1, passo 1 (resposta do modelo)
{ "role": "model", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_A>" } }, "function": { "arguments": "{\"flight\":\"AA100\"}", "name": "check_flight" }, "id": "function-call-1", "type": "function" } ] }
Turno 1, passo 2 (resposta do utilizador – envio de resultados da ferramenta)
Uma vez que este turno do utilizador contém apenas um functionResponse (sem texto novo), continuamos no turno 1. Tem de preservar o elemento <SIGNATURE_A>.
"messages": [ { "role": "user", "content": "Check flight status for AA100 and book a taxi 2 hours before if delayed." }, { "role": "model", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_A>" } }, "function": { "arguments": "{\"flight\":\"AA100\"}", "name": "check_flight" }, "id": "function-call-1", "type": "function" } ] }, { "role": "tool", "name": "check_flight", "tool_call_id": "function-call-1", "content": "{\"status\":\"delayed\",\"departure_time\":\"12 PM\"}" } ]
Turn 1, Step 2 (resposta do modelo)
O modelo decide agora reservar um táxi com base no resultado da ferramenta anterior.
{ "role": "model", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_B>" } }, "function": { "arguments": "{\"time\":\"10 AM\"}", "name": "book_taxi" }, "id": "function-call-2", "type": "function" } ] }
Turno 1, passo 3 (resposta do utilizador: envio do resultado da ferramenta)
Para enviar a confirmação da reserva de táxi, tem de incluir assinaturas para todas
as chamadas de funções neste ciclo (<SIGNATURE_A> e <SIGNATURE_B>).
"messages": [ { "role": "user", "content": "Check flight status for AA100 and book a taxi 2 hours before if delayed." }, { "role": "model", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_A>" } }, "function": { "arguments": "{\"flight\":\"AA100\"}", "name": "check_flight" }, "id": "function-call-1d6a1a61-6f4f-4029-80ce-61586bd86da5", "type": "function" } ] }, { "role": "tool", "name": "check_flight", "tool_call_id": "function-call-1d6a1a61-6f4f-4029-80ce-61586bd86da5", "content": "{\"status\":\"delayed\",\"departure_time\":\"12 PM\"}" }, { "role": "model", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_B>" } }, "function": { "arguments": "{\"time\":\"10 AM\"}", "name": "book_taxi" }, "id": "function-call-65b325ba-9b40-4003-9535-8c7137b35634", "type": "function" } ] }, { "role": "tool", "name": "book_taxi", "tool_call_id": "function-call-65b325ba-9b40-4003-9535-8c7137b35634", "content": "{\"booking_status\":\"success\"}" } ]
Exemplo de chamadas de funções paralelas
O exemplo seguinte mostra um exemplo de chamadas de funções paralelas em que o utilizador pede: "Verificar o tempo em Paris e Londres".
REST
O exemplo seguinte demonstra como processar assinaturas de reflexão num fluxo de trabalho de chamadas de funções paralelas através da API REST.
Turno 1, passo 1 (pedido do utilizador)
{ "contents": [ { "role": "user", "parts": [ { "text": "Check the weather in Paris and London." } ] } ], "tools": [ { "functionDeclarations": [ { "name": "get_current_temperature", "description": "Gets the current temperature for a given location.", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The city name, e.g. San Francisco" } }, "required": [ "location" ] } } ] } ] }
Turno 1, passo 1 (resposta do modelo)
{ "content": { "parts": [ { "functionCall": { "name": "get_current_temperature", "args": { "location": "Paris" } }, "thoughtSignature": "<SIGNATURE_A>" }, { "functionCall": { "name": "get_current_temperature", "args": { "location": "London" } } } ] } }
Turno 1, passo 2 (resposta do utilizador – envio de resultados da ferramenta)
Tem de preservar <SIGNATURE_A> na primeira parte exatamente como a recebeu.
[ { "role": "user", "parts": [ { "text": "Check the weather in Paris and London." } ] }, { "role": "model", "parts": [ { "functionCall": { "name": "get_current_temperature", "args": { "city": "Paris" } }, "thought_signature": "<SIGNATURE_A>" }, { "functionCall": { "name": "get_current_temperature", "args": { "city": "London" } } } ] }, { "role": "user", "parts": [ { "functionResponse": { "name": "get_current_temperature", "response": { "temp": "15C" } } }, { "functionResponse": { "name": "get_current_temperature", "response": { "temp": "12C" } } } ] } ]
Conclusões do chat
O exemplo seguinte demonstra como processar assinaturas de reflexão num fluxo de trabalho de chamadas de funções paralelas usando a API Chat Completions.
Turno 1, passo 1 (pedido do utilizador)
{ "contents": [ { "role": "user", "parts": [ { "text": "Check the weather in Paris and London." } ] } ], "tools": [ { "functionDeclarations": [ { "name": "get_current_temperature", "description": "Gets the current temperature for a given location.", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The city name, e.g. San Francisco" } }, "required": [ "location" ] } } ] } ] }
Turno 1, passo 1 (resposta do modelo)
{ "role": "assistant", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_A>" } }, "function": { "arguments": "{\"location\":\"Paris\"}", "name": "get_current_temperature" }, "id": "function-call-f3b9ecb3-d55f-4076-98c8-b13e9d1c0e01", "type": "function" }, { "function": { "arguments": "{\"location\":\"London\"}", "name": "get_current_temperature" }, "id": "function-call-335673ad-913e-42d1-bbf5-387c8ab80f44", "type": "function" } ] }
Turno 1, passo 2 (resposta do utilizador – envio de resultados da ferramenta)
Tem de preservar <SIGNATURE_A> na primeira parte exatamente como a recebeu.
"messages": [ { "role": "user", "content": "Check the weather in Paris and London." }, { "role": "assistant", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_A>" } }, "function": { "arguments": "{\"location\":\"Paris\"}", "name": "get_current_temperature" }, "id": "function-call-f3b9ecb3-d55f-4076-98c8-b13e9d1c0e01", "type": "function" }, { "function": { "arguments": "{\"location\":\"London\"}", "name": "get_current_temperature" }, "id": "function-call-335673ad-913e-42d1-bbf5-387c8ab80f44", "type": "function" } ] }, { "role":"tool", "name": "get_current_temperature", "tool_call_id": "function-call-f3b9ecb3-d55f-4076-98c8-b13e9d1c0e01", "content": "{\"temp\":\"15C\"}" }, { "role":"tool", "name": "get_current_temperature", "tool_call_id": "function-call-335673ad-913e-42d1-bbf5-387c8ab80f44", "content": "{\"temp\":\"12C\"}" } ]
Assinaturas em functionCalls não Part
O Gemini também pode devolver um thought_signature no Part final de uma resposta, mesmo que não esteja presente nenhuma chamada de função.
- Comportamento: o conteúdo final
Part(text,inlineData, etc.) devolvido pelo modelo pode conter umthought_signature. - Requisito: a devolução desta assinatura é recomendada para garantir que o modelo mantém um raciocínio de alta qualidade, especialmente para instruções complexas ou fluxos de trabalho de agentes simulados.
- Validação: a API não aplica rigorosamente a validação para assinaturas em partes não
functionCall. Não recebe um erro de bloqueio se os omitir, embora o desempenho possa diminuir.
Exemplo de resposta do modelo com assinatura na parte de texto:
Os exemplos seguintes mostram uma resposta do modelo em que um thought_signature está incluído num functionCall Part e como processá-lo num pedido subsequente.
Turno 1, passo 1 (resposta do modelo)
{ "role": "model", "parts": [ { "text": "I need to calculate the risk. Let me think step-by-step...", "thought_signature": "<SIGNATURE_C>" // OPTIONAL (Recommended) } ] }
Turn 2, Step 1 (user)
[ { "role": "user", "parts": [{ "text": "What is the risk?" }] }, { "role": "model", "parts": [ { "text": "I need to calculate the risk. Let me think step-by-step...", // If you omit <SIGNATURE_C> here, no error will occur. } ] }, { "role": "user", "parts": [{ "text": "Summarize it." }] } ]
Exemplo de edição de imagens com várias interações através de assinaturas de pensamento
Os exemplos seguintes ilustram como obter e transmitir assinaturas de reflexão durante a criação e edição de imagens com várias interações com o Gemini 3 Pro Image.
Turn 1: Get the response and save data that includes thought signatures
chat = client.chats.create( model="gemini-3-pro-image-preview", config=types.GenerateContentConfig( response_modalities=['TEXT', 'IMAGE'] ) ) message = "Create an image of a clear perfume bottle sitting on a vanity." response = chat.send_message(message) data = b'' for part in response.candidates[0].content.parts: if part.text: display(Markdown(part.text)) if part.inline_data: data = part.inline_data.data display(Image(data=data, width=500))
Turn 2: passe os dados que incluem assinaturas de pensamento
response = chat.send_message( message=[ types.Part.from_bytes( data=data, mime_type="image/png", ), "Make the perfume bottle purple and add a vase of hydrangeas next to the bottle.", ], ) for part in response.candidates[0].content.parts: if part.text: display(Markdown(part.text)) if part.inline_data: display(Image(data=part.inline_data.data, width=500))
O que se segue?
- Saiba mais sobre o Thinking.
- Saiba mais acerca da chamada de funções.
- Saiba como criar comandos multimodais.