בדף הזה מוסבר איך לראות את תוצאות ההערכה של המודל ולהבין אותן אחרי שמריצים את ההערכה של המודל באמצעות שירות ההערכה של AI גנרטיבי.
צפייה בתוצאות ההערכה
שירות ההערכה של ה-AI הגנרטיבי מאפשר לכם להציג את תוצאות ההערכה באופן חזותי ישירות בסביבת הפיתוח, כמו מחברת Colab או Jupyter. השיטה .show(), שזמינה באובייקטים EvaluationDataset ו-EvaluationResult, מעבדת דוח HTML אינטראקטיבי לצורך ניתוח.
הצגה ויזואלית של קריטריוני הערכה שנוצרו במערך הנתונים
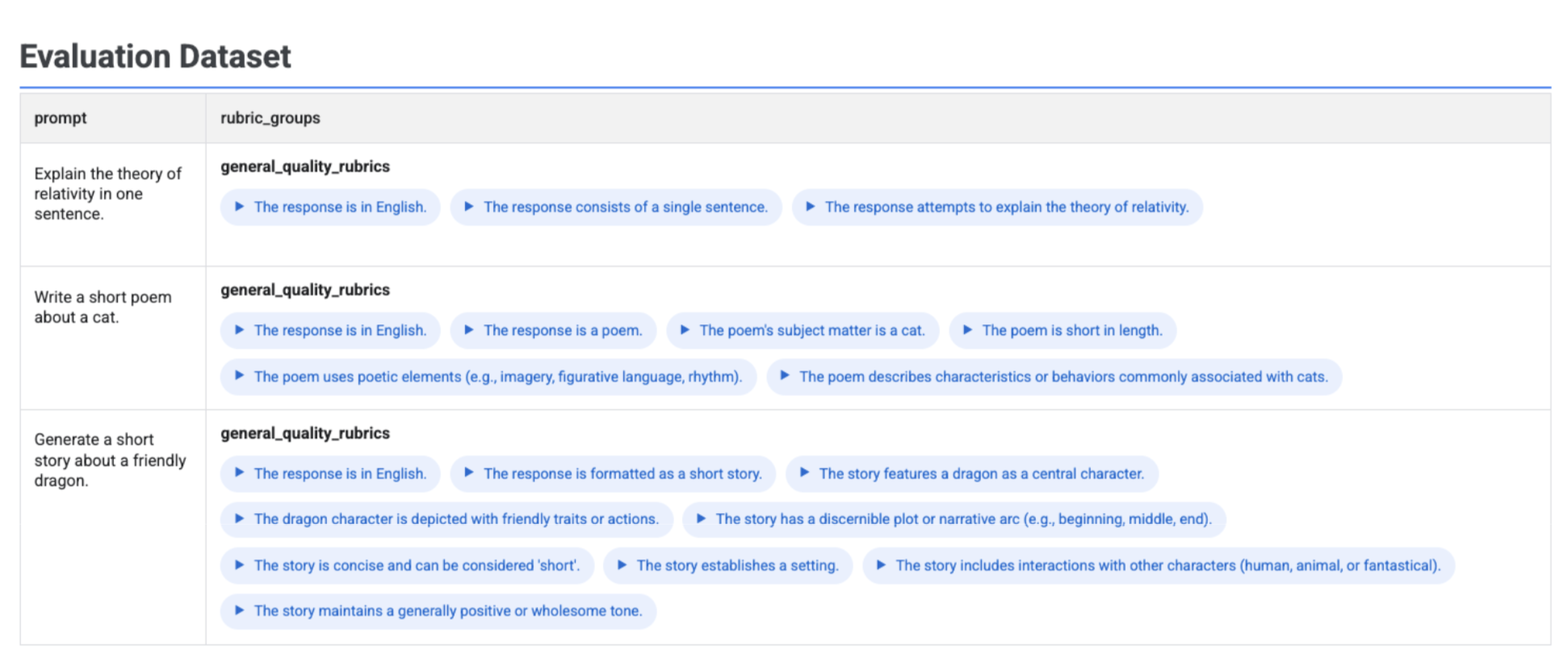
אם מריצים את הפקודה client.evals.generate_rubrics(), אובייקט EvaluationDataset שמתקבל מכיל עמודה rubric_groups. אפשר להציג את מערך הנתונים הזה כדי לבדוק את קריטריוני ההערכה שנוצרו לכל הנחיה לפני שמריצים את ההערכה.
# Example: Generate rubrics using a predefined method
data_with_rubrics = client.evals.generate_rubrics(
src=prompts_df,
rubric_group_name="general_quality_rubrics",
predefined_spec_name=types.RubricMetric.GENERAL_QUALITY,
)
# Display the dataset with the generated rubrics
data_with_rubrics.show()
טבלה אינטראקטיבית מוצגת עם כל הנחיות והקריטריונים המשויכים שנוצרו עבורה, בתוך העמודה rubric_groups:
הצגה חזותית של תוצאות ההסקה
אחרי שמפיקים תשובות באמצעות run_inference(), אפשר להפעיל את .show() באובייקט EvaluationDataset שמתקבל כדי לבדוק את התוצרים של המודל לצד ההנחיות וההפניות המקוריות. הבדיקה הזו שימושית לבדיקת איכות מהירה לפני שמריצים הערכה מלאה:
# First, run inference to get an EvaluationDataset
gpt_response = client.evals.run_inference(
model='gpt-4o',
src=prompt_df
)
# Now, visualize the inference results
gpt_response.show()
בטבלה מוצגים כל הנחיה, ההפניה התואמת (אם סופקה) והתגובה החדשה שנוצרה:
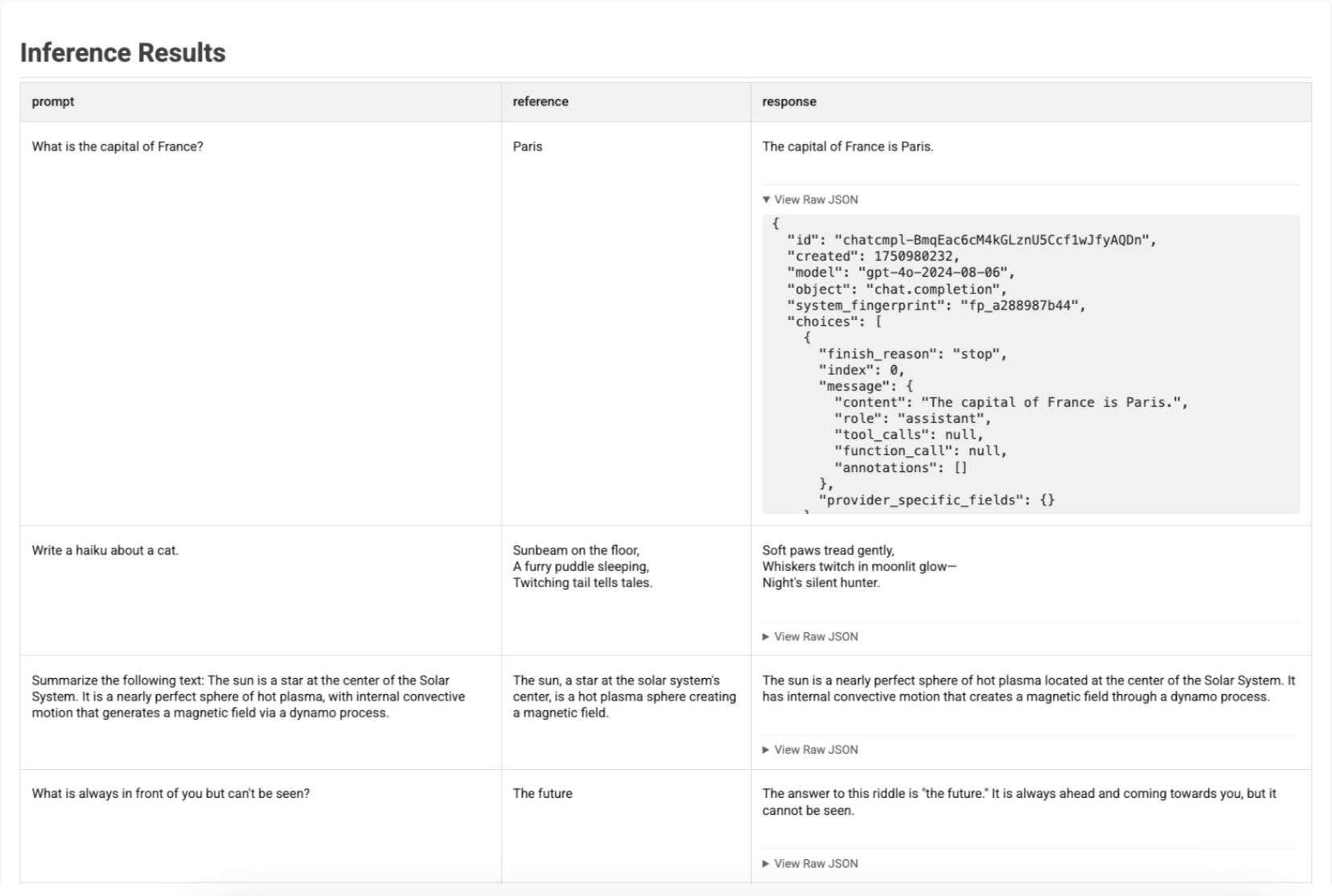
במקרה של הסקת מסקנות על ידי סוכן, מוצגים גם הקלט של הסשן (אם סופק) ואירועי הביניים (אם נוצרו).
הדמיה של דוחות הערכה
כשמתקשרים אל .show() באובייקט EvaluationResultאו EvaluationRun, הדוח מציג את הקטעים הבאים:
מדדי סיכום: תצוגה מצטברת של כל המדדים, שבה מוצגים הציון הממוצע והסטייה הרגילה בכל מערך הנתונים.
תוצאות מפורטות: פירוט לפי כל מקרה, שמאפשר לבדוק את ההנחיה, את ההפניה, את התשובה האפשרית, את הציון הספציפי ואת ההסבר לכל מדד. בנוסף, בתוצאות המפורטות של הערכת נציג מופיעים גם נתוני מעקב שמציגים את האינטראקציות עם הנציג. מידע נוסף על עקבות זמין במאמר מעקב אחר סוכן.
פרטי הסוכן (לצורך הערכת הסוכן בלבד): מידע שמתאר את הסוכן שנבדק, כמו הוראות למפתחים, תיאור הסוכן והגדרות הכלים.
דוח הערכה של מועמד יחיד
במקרה של הערכת מודל יחיד, בדוח מפורטים הציונים של כל מדד:
# First, run an evaluation on a single candidate
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[
types.RubricMetric.TEXT_QUALITY,
types.RubricMetric.FLUENCY,
types.Metric(name='rouge_1'),
]
)
# Visualize the detailed evaluation report
eval_result.show()
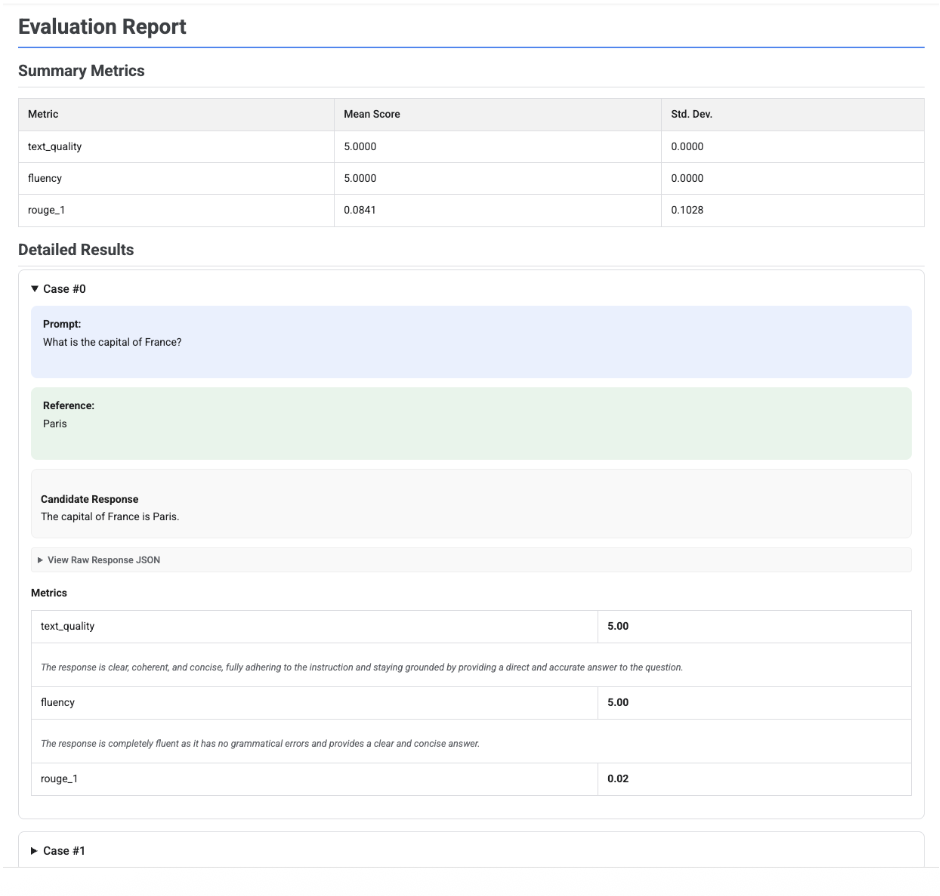
בכל הדוחות, אפשר להרחיב את הקטע View Raw JSON כדי לבדוק את הנתונים בכל פורמט מובנה, כמו Gemini או פורמט ה-API של OpenAI Chat Completion.
דוח הערכה מבוסס-קריטריונים עם פסיקות
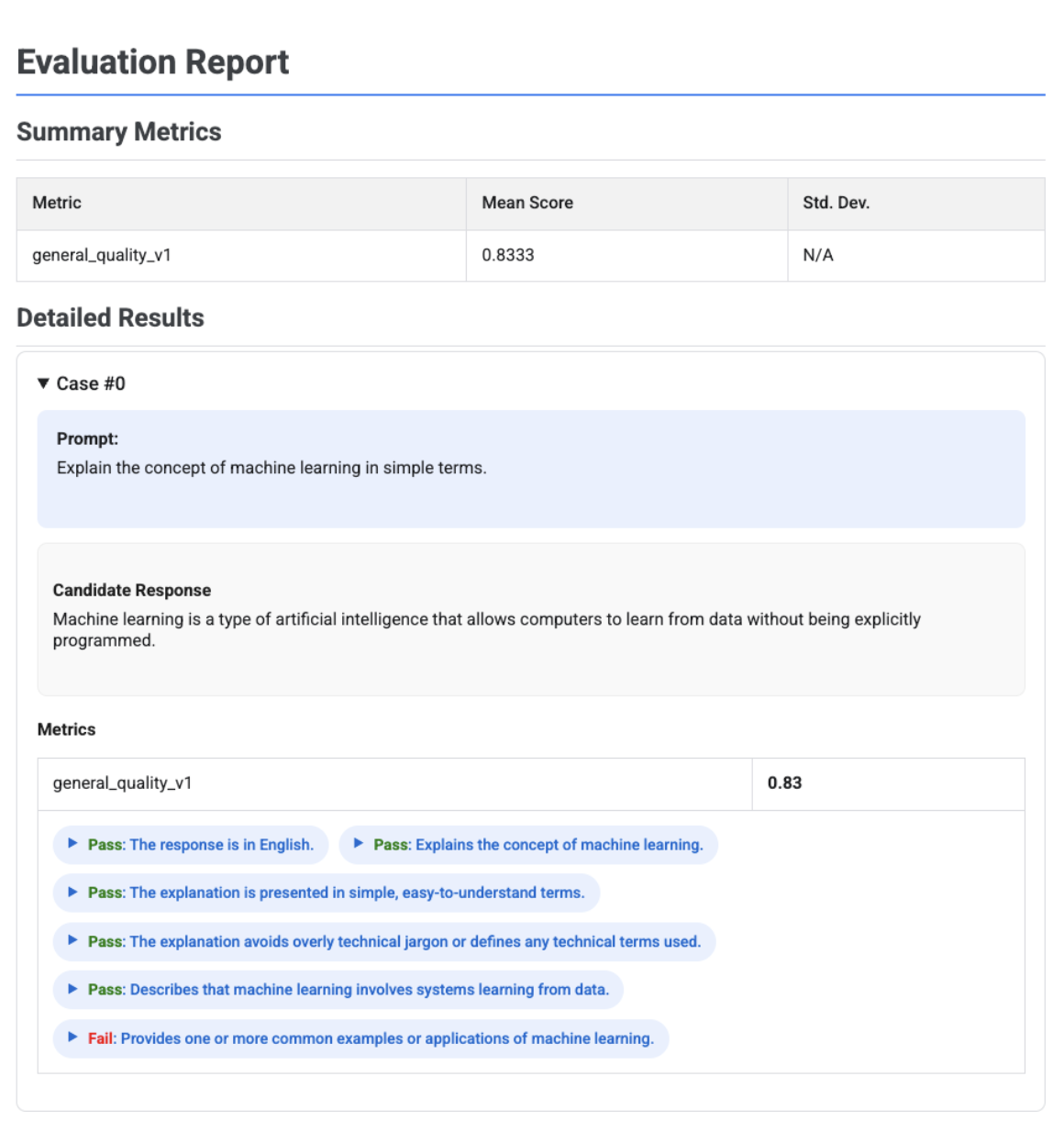
כשמשתמשים במדדים דינמיים שמבוססים על קריטריונים, התוצאות כוללות את פסיקות ההצלחה או הכישלון ואת הנימוקים לכל קריטריון שחל על התשובה.
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[types.PrebuiltMetric.GENERAL_QUALITY],
)
eval_result.show()
בהדמיה מוצגת כל קריטריון הערכה, ההחלטה לגביו (עבר או נכשל) וההסבר, בתוך תוצאות המדדים של כל מקרה. לכל פסיקה ספציפית של קריטריון ההערכה, אפשר להרחיב את הכרטיס כדי להציג את מטען ה-JSON הגולמי. מטען ה-JSON הייעודי הזה כולל פרטים נוספים כמו תיאור מלא של קריטריון ההערכה, סוג קריטריון ההערכה, חשיבות והנימוקים המפורטים להחלטה.
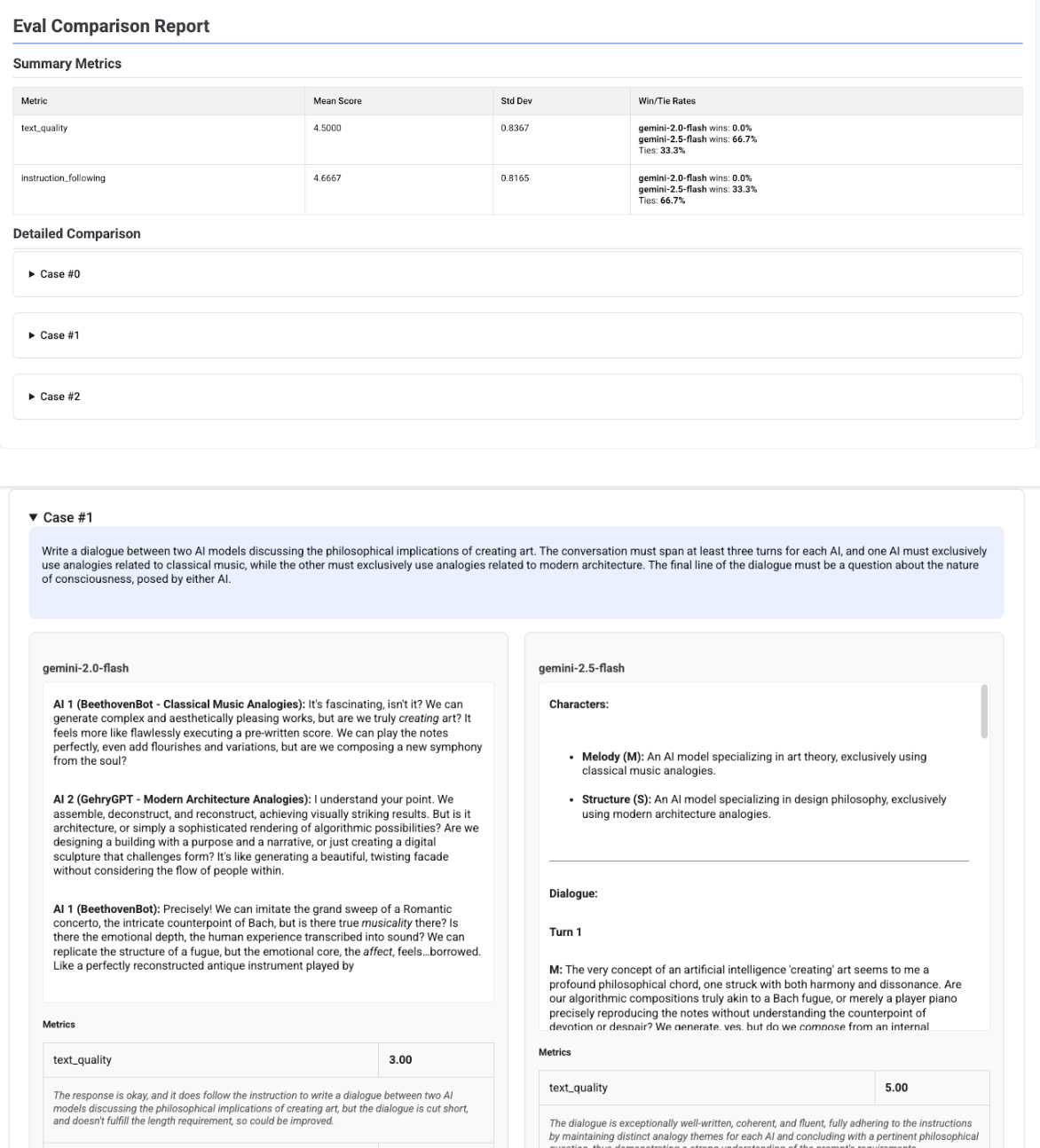
דוח השוואה בין כמה מועמדים
הפורמט של הדוח משתנה בהתאם לכך שאתם מעריכים מועמד אחד או משווים בין כמה מועמדים. בדוח של הערכת כמה מועמדים מוצגת תצוגה זה לצד זה, והוא כולל חישובים של שיעור הזכייה או התיקו בטבלת הסיכום.
# Example of comparing two models
inference_result_1 = client.evals.run_inference(
model="gemini-2.0-flash",
src=prompts_df,
)
inference_result_2 = client.evals.run_inference(
model="gemini-2.5-flash",
src=prompts_df,
)
comparison_result = client.evals.evaluate(
dataset=[inference_result_1, inference_result_2],
metrics=[types.PrebuiltMetric.TEXT_QUALITY]
)
comparison_result.show()