

Nesta página, você verá como realizar uma avaliação baseada em modelo par a par usando AutoSxS, que é uma ferramenta com o serviço de pipeline de avaliação. Qa explicar como usar AutoSxS com a API Agent Platform, o SDK Agent Platform para Python ou o console Google Cloud .
AutoSxS
O recurso de avaliação lado-a-lado automática (AutoSxS) é uma ferramenta de avaliação baseada em modelo que é executada usando o serviço de pipeline de avaliação. O AutoSxS pode ser usado para avaliar o desempenho de modelos de IA generativa no Model Registry da Gemini Enterprise Agent Platform ou de previsões pré-geradas, o que permite suporte a modelos de fundação da Gemini Enterprise Agent Platform, modelos de IA generativa ajustados e modelos de linguagem de terceiros. O AutoSxS usa um avaliador automático para decidir qual modelo dá a melhor resposta a um comando. Ele está disponível sob demanda e avalia modelos de linguagem com desempenho comparável ao de avaliadores humanos.
O avaliador automático
De modo geral, o diagrama mostra como o AutoSxS compara as previsões dos modelos A e B com um terceiro modelo, o avaliador automático.
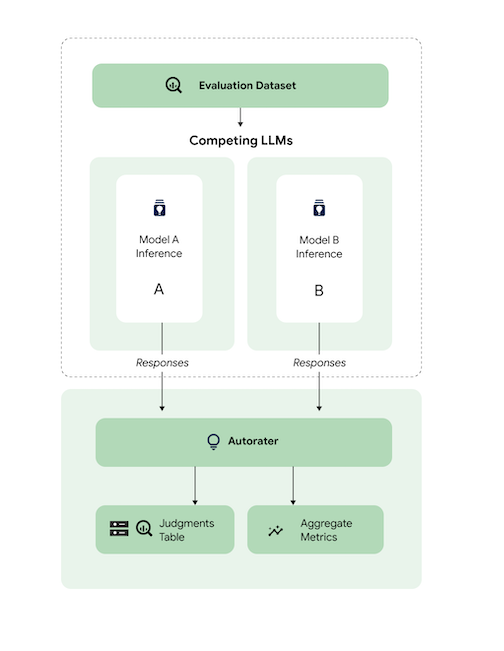
Os modelos A e B recebem prompts de entrada, e cada modelo gera respostas que são enviadas ao avaliador automático. Semelhante a um rotulador humano, um avaliador automático é um modelo de linguagem que avalia a qualidade das respostas do modelo com base em um comando de inferência original. Com o AutoSxS, o avaliador automático compara a qualidade de duas respostas do modelo de acordo com a instrução de inferência usando um conjunto de critérios. Os critérios são usados para determinar qual modelo teve o melhor desempenho comparando os resultados do Modelo A com os do Modelo B. O autor gera preferências de resposta como métricas agregadas e gera explicações de preferência e pontuações de confiança para cada exemplo. Para saber mais, consulte a tabela de avaliações.
Modelos compatíveis
O AutoSxS oferece suporte à avaliação de qualquer modelo quando as previsões pré-geradas são fornecidas. O AutoSxS também oferece suporte à geração automática de respostas para qualquer modelo no Model Registry da Gemini Enterprise Agent Platform, que oferece suporte à predição em lote na Gemini Enterprise Agent Platform.
Se o modelo de texto não for compatível com o Model Registry do Gemini Enterprise Agent Platform, o AutoSxS também vai aceitar previsões pré-geradas armazenadas como JSONL no Cloud Storage ou em uma tabela do BigQuery. Para saber os preços, consulte Geração de texto.
Tarefas e critérios compatíveis
O AutoSxS oferece suporte à avaliação de modelos para tarefas de resumo e perguntas e respostas. Os critérios de avaliação são predefinidos para cada tarefa, o que torna a avaliação de linguagem mais objetiva e melhora a qualidade da resposta.
Os critérios são listados por tarefa.
Resumo
A tarefa summarization tem um limite de 4.096 tokens de entrada.
A lista de critérios de avaliação de summarization é a seguinte:
| Critérios | |
|---|---|
| 1. Segue as instruções | Até que ponto a resposta do modelo demonstra que o comando entende a instrução? |
| 2. Empírico | A resposta inclui apenas informações do contexto e da instrução de inferência? |
| 3. Abrangente | Até que ponto o modelo captura detalhes importantes no resumo? |
| 4. Breve | O resumo é detalhado? Ele inclui linguagem floreada? É muito conciso? |
Resposta da pergunta
A tarefa question_answering tem um limite de tokens de entrada de 4.096.
A lista de critérios de avaliação de question_answering é a seguinte:
| Critérios | |
|---|---|
| 1. Responde totalmente à pergunta | A resposta responde à pergunta de maneira completa. |
| 2. Empírico | A resposta inclui apenas informações do contexto da instrução e da instrução de inferência? |
| 3. Relevância | O conteúdo da resposta está relacionado à pergunta? |
| 4. Abrangente | Até que ponto o modelo captura detalhes importantes na pergunta? |
Preparar conjunto de dados de avaliação para AutoSxS
Nesta seção, detalhamos os dados que você precisa fornecer no conjunto de dados de avaliação e as práticas recomendadas para a criação do conjunto de dados. Os exemplos devem refletir entradas reais que seus modelos podem encontrar na produção, além de contrastar o comportamento dos modelos ativos.
Formato do conjunto de dados
O AutoSxS aceita um único conjunto de dados de avaliação com um esquema flexível. O conjunto de dados pode ser uma tabela do BigQuery ou armazenado como linhas JSON no Cloud Storage.
Cada linha do conjunto de dados de avaliação representa um único exemplo, e as colunas são uma das seguintes:
- Colunas de ID: usadas para identificar cada exemplo exclusivo.
- Colunas de dados: usadas para preencher modelos de comandos. Consulte Parâmetros de prompt.
- Previsões pré-geradas: previsões feitas pelo mesmo modelo usando o mesmo comando. O uso de previsões pré-geradas economiza tempo e recursos.
- Preferências humanas de informações empíricas: usadas para comparar a AutoSxS com seus dados de preferência de informações empíricas quando previsões pré-geradas são fornecidas para os dois modelos.
Confira um exemplo de conjunto de dados de avaliação em que context e question são colunas de dados, e model_b_response contém previsões pré-geradas.
context |
question |
model_b_response |
|---|---|---|
| Alguns podem pensar que o aço é o material mais duro, ou titânio, mas o diamante é o material mais duro. | Qual é o material mais duro? | Diamante é o material mais duro. É mais duro que aço ou titânio. |
Para mais informações sobre como chamar AutoSxS, consulte Realizar avaliação do modelo. Para detalhes sobre o tamanho do token, consulte Tarefas e critérios compatíveis. Para fazer o upload dos dados para o Cloud Storage, consulte Fazer upload do conjunto de dados de avaliação para o Cloud Storage.
Parâmetros do comando
Muitos modelos de linguagem usam parâmetros de comando como entradas no lugar de uma única string de comando. Por exemplo, o chat-bison usa vários parâmetros de comando (mensagens, exemplos, contexto), que compõem as partes do comando. No entanto, o text-bison tem apenas um parâmetro chamado prompt, que contém todo o comando.
Descrevemos como é possível especificar com flexibilidade os parâmetros do comando do modelo no momento da inferência e avaliação. O AutoSxS oferece a flexibilidade de chamar modelos de linguagem com entradas esperadas variadas via parâmetros de comando com modelos.
Inferência
Se algum dos modelos não tiver previsões pré-geradas, a AutoSxS vai usar a previsão em lote da Gemini Enterprise Agent Platform para gerar respostas. É preciso especificar os parâmetros de prompt de cada modelo.
No AutoSxS, é possível fornecer uma única coluna no conjunto de dados de avaliação como um parâmetro de prompt.
{'some_parameter': {'column': 'my_column'}}
Outra opção é definir modelos usando colunas do conjunto de dados de avaliação como variáveis para especificar os parâmetros do comando:
{'some_parameter': {'template': 'Summarize the following: {{ my_column }}.'}}
Ao fornecer parâmetros de comando de modelo para inferência, os usuários podem usar a
palavra-chave default_instruction protegida como um argumento de modelo, que é
substituído pela instrução de inferência padrão para a tarefa especificada:
model_prompt_parameters = {
'prompt': {'template': '{{ default_instruction }}: {{ context }}'},
}
Se estiver gerando previsões, forneça os parâmetros do prompt do modelo e uma coluna de saída. Veja os exemplos a seguir:
Gemini
Para modelos do Gemini, as chaves para os parâmetros de comando do modelo são
contents (obrigatória) e system_instruction (opcional), que se alinham com o esquema de corpo da solicitação do Gemini.
model_a_prompt_parameters={
'contents': {
'column': 'context'
},
'system_instruction': {'template': '{{ default_instruction }}'},
},
text-bison
Por exemplo, text-bison usa "prompt" para entrada e "content" para saída. Siga estas etapas:
- Identificar as entradas e saídas necessárias para os modelos que estão sendo avaliados.
- Defina as entradas como parâmetros do prompt do modelo.
- Transmitir a saída para a coluna de resposta.
model_a_prompt_parameters={
'prompt': {
'template': {
'Answer the following question from the point of view of a college professor: {{ context }}\n{{ question }}'
},
},
},
response_column_a='content', # Column in Model A response.
response_column_b='model_b_response', # Column in eval dataset.
Avaliação
Assim como é necessário fornecer parâmetros de comando para inferência, também é necessário fornecer parâmetros de comando para avaliação. O avaliador automático exige os seguintes parâmetros de comando:
| Parâmetro de comando do avaliador automático | Configurável pelo usuário? | Descrição | Exemplo |
|---|---|---|---|
| Instrução do avaliador automático | Não | Uma instrução calibrada que descreve os critérios que o avaliador automático deve usar para julgar as respostas fornecidas. | Escolha a resposta que responde à pergunta e segue melhor as instruções. |
| Instrução de inferência | Sim | Uma descrição da tarefa que cada modelo candidato deve realizar. | Responda à pergunta de maneira precisa: qual é o material mais duro? |
| Contexto de inferência | Sim | Contexto extra para a tarefa que está sendo realizada. | Embora o titânio e o diamante sejam mais duros do que o cobre, o diamante tem uma classificação de dureza de 98 e o titânio tem uma classificação de 36. Uma classificação mais alta significa maior dureza. |
| Respostas | Não1 | Um par de respostas para avaliar, uma de cada modelo candidato. | Diamante |
1Só é possível configurar o parâmetro "comando" com respostas pré-geradas.
Exemplo de código usando os parâmetros:
autorater_prompt_parameters={
'inference_instruction': {
'template': 'Answer the following question from the point of view of a college professor: {{ question }}.'
},
'inference_context': {
'column': 'context'
}
}
Os modelos A e B podem ter instruções e contextos de inferência formatados de maneira diferente, independentemente de as mesmas informações serem fornecidas ou não. Isso significa que o avaliador automático recebe uma instrução e um contexto de inferência separados, mas únicos.
Exemplo de conjunto de dados de avaliação
Nesta seção, você verá um exemplo de um conjunto de dados de avaliação de tarefas de perguntas e respostas, incluindo previsões pré-geradas para o modelo B. Neste exemplo, o AutoSxS
executa inferência apenas para o modelo A. Fornecemos uma coluna id para diferenciar
exemplos com a mesma pergunta e contexto.
{
"id": 1,
"question": "What is the hardest material?",
"context": "Some might think that steel is the hardest material, or even titanium. However, diamond is actually the hardest material.",
"model_b_response": "Diamond is the hardest material. It is harder than steel or titanium."
}
{
"id": 2,
"question": "What is the highest mountain in the world?",
"context": "K2 and Everest are the two tallest mountains, with K2 being just over 28k feet and Everest being 29k feet tall.",
"model_b_response": "Mount Everest is the tallest mountain, with a height of 29k feet."
}
{
"id": 3,
"question": "Who directed The Godfather?",
"context": "Mario Puzo and Francis Ford Coppola co-wrote the screenplay for The Godfather, and the latter directed it as well.",
"model_b_response": "Francis Ford Coppola directed The Godfather."
}
{
"id": 4,
"question": "Who directed The Godfather?",
"context": "Mario Puzo and Francis Ford Coppola co-wrote the screenplay for The Godfather, and the latter directed it as well.",
"model_b_response": "John Smith."
}
Práticas recomendadas
Siga estas práticas recomendadas ao definir seu conjunto de dados de avaliação:
- Forneça exemplos que representem os tipos de entradas que seus modelos processam na produção.
- Seu conjunto de dados precisa incluir no mínimo um exemplo de avaliação. Recomendamos cerca de 100 exemplos para garantir métricas agregadas de alta qualidade. A taxa de melhorias de qualidade da métrica agregada tende a diminuir quando mais de 400 exemplos são fornecidos.
- Para saber como escrever comandos, consulte Criar comandos de texto.
- Se você estiver usando previsões pré-geradas em qualquer um dos modelos, inclua-as em uma coluna do conjunto de dados de avaliação. Fornecer previsões pré-geradas é útil porque permite comparar a saída de modelos que não estão no Vertex Model Registry e reutilizar respostas.
Fazer avaliação de modelo.
É possível avaliar modelos usando a API REST, o SDK da Agent Platform para Python ou o consoleGoogle Cloud .
Use a seguinte sintaxe para especificar o caminho do modelo:
- Modelo do editor:
publishers/PUBLISHER/models/MODELExemplo:publishers/google/models/text-bison Modelo ajustado:
projects/PROJECT_NUMBER/locations/LOCATION/models/MODEL@VERSIONExemplo:projects/123456789012/locations/us-central1/models/1234567890123456789
REST
Para criar um job de avaliação de modelo, envie uma solicitação POST usando o método pipelineJobs.
Antes de usar os dados da solicitação, faça as substituições a seguir:
- PIPELINEJOB_DISPLAYNAME : nome de exibição da
pipelineJob. - PROJECT_ID : Google Cloud projeto que executa os componentes do pipeline.
- LOCATION: a região para executar os componentes do pipeline.
us-central1é compatível. - OUTPUT_DIR: URI do Cloud Storage para armazenar a saída da avaliação.
- EVALUATION_DATASET: tabela do BigQuery ou uma lista separada por vírgulas de caminhos do Cloud Storage para um conjunto de dados JSONL que contém exemplos de avaliação.
- TASK: tarefa de avaliação, que pode ser uma das
[summarization, question_answering]. - ID_COLUMNS: colunas que distinguem exemplos de avaliação únicos.
- AUTORATER_PROMPT_PARAMETERS : parâmetros de comando do avaliador automático mapeados para colunas ou modelos. Os parâmetros esperados são:
inference_instruction(detalhes sobre como executar uma tarefa) einference_context(conteúdo de referência para realizar a tarefa). Por exemplo,{'inference_context': {'column': 'my_prompt'}}usa a coluna "my_prompt" do conjunto de dados de avaliação para o contexto do avaliador automático. - RESPONSE_COLUMN_A : o nome de uma coluna no conjunto de dados de avaliação que contém previsões predefinidas ou o nome da coluna na saída do Modelo A que contém previsões. Se nenhum valor for fornecido, o nome correto da coluna de saída do modelo vai tentar ser inferido.
- RESPONSE_COLUMN_B : o nome de uma coluna no conjunto de dados de avaliação que contém previsões predefinidas ou o nome da coluna na saída do Modelo B que contém previsões. Se nenhum valor for fornecido, o nome correto da coluna de saída do modelo vai tentar ser inferido.
- MODEL_A (opcional): um nome de recurso de modelo totalmente qualificado (
projects/{project}/locations/{location}/models/{model}@{version}) ou nome de recurso de modelo do editor (publishers/{publisher}/models/{model}). Se as respostas do Modelo A forem especificadas, esse parâmetro não deverá ser fornecido. - MODEL_B (opcional): um nome de recurso de modelo totalmente qualificado (
projects/{project}/locations/{location}/models/{model}@{version}) ou nome de recurso de modelo do editor (publishers/{publisher}/models/{model}). Se as respostas do Modelo B forem especificadas, esse parâmetro não deverá ser fornecido. - MODEL_A_PROMPT_PARAMETERS (opcional): parâmetros do modelo de prompt do Modelo A mapeados para colunas ou modelos. Se as respostas do Modelo A forem predefinidas, esse parâmetro não deverá ser fornecido. Exemplo:
{'prompt': {'column': 'my_prompt'}}usa a colunamy_promptdo conjunto de dados de avaliação para o parâmetro de comando chamadoprompt. - MODEL_B_PROMPT_PARAMETERS (opcional): parâmetros do modelo de prompt do Modelo B mapeados para colunas ou modelos. Se as respostas do Modelo B forem predefinidas, esse parâmetro não deverá ser fornecido. Exemplo:
{'prompt': {'column': 'my_prompt'}}usa a colunamy_promptdo conjunto de dados de avaliação para o parâmetro de comando chamadoprompt. - JUDGMENTS_FORMAT
(opcional): o formato para gravar julgamentos. Pode ser
jsonl(padrão),jsonoubigquery. - BIGQUERY_DESTINATION_PREFIX: tabela do BigQuery em que as avaliações serão gravadas se o formato especificado for
bigquery.
Corpo JSON da solicitação
{
"displayName": "PIPELINEJOB_DISPLAYNAME",
"runtimeConfig": {
"gcsOutputDirectory": "gs://OUTPUT_DIR",
"parameterValues": {
"evaluation_dataset": "EVALUATION_DATASET",
"id_columns": ["ID_COLUMNS"],
"task": "TASK",
"autorater_prompt_parameters": AUTORATER_PROMPT_PARAMETERS,
"response_column_a": "RESPONSE_COLUMN_A",
"response_column_b": "RESPONSE_COLUMN_B",
"model_a": "MODEL_A",
"model_a_prompt_parameters": MODEL_A_PROMPT_PARAMETERS,
"model_b": "MODEL_B",
"model_b_prompt_parameters": MODEL_B_PROMPT_PARAMETERS,
"judgments_format": "JUDGMENTS_FORMAT",
"bigquery_destination_prefix":BIGQUERY_DESTINATION_PREFIX,
},
},
"templateUri": "https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default"
}
Use curl para enviar sua solicitação.
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/pipelineJobs"
Resposta
"state": "PIPELINE_STATE_PENDING",
"labels": {
"vertex-ai-pipelines-run-billing-id": "1234567890123456789"
},
"runtimeConfig": {
"gcsOutputDirectory": "gs://my-evaluation-bucket/output",
"parameterValues": {
"evaluation_dataset": "gs://my-evaluation-bucket/output/data.json",
"id_columns": [
"context"
],
"task": "question_answering",
"autorater_prompt_parameters": {
"inference_instruction": {
"template": "Answer the following question: {{ question }} }."
},
"inference_context": {
"column": "context"
}
},
"response_column_a": "",
"response_column_b": "response_b",
"model_a": "publishers/google/models/text-bison@002",
"model_a_prompt_parameters": {
"prompt": {
"template": "Answer the following question from the point of view of a college professor: {{ question }}\n{{ context }} }"
}
},
"model_b": "",
"model_b_prompt_parameters": {}
}
},
"serviceAccount": "123456789012-compute@developer.gserviceaccount.com",
"templateUri": "https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default",
"templateMetadata": {
"version": "sha256:7366b784205551ed28f2c076e841c0dbeec4111b6df16743fc5605daa2da8f8a"
}
}
SDK da Agent Platform para Python
Para saber como instalar ou atualizar o SDK da Agent Platform para Python, consulte Instalar o SDK da Vertex AI para Python. Para mais informações sobre a API Python, consulte a API do SDK da Agent Platform para Python.
Para mais informações sobre parâmetros de pipeline, consulte a Documentação de referência dos componentes de pipeline do Google Cloud.
Antes de usar os dados da solicitação, faça as substituições a seguir:
- PIPELINEJOB_DISPLAYNAME : nome de exibição da
pipelineJob. - PROJECT_ID : Google Cloud projeto que executa os componentes do pipeline.
- LOCATION: a região para executar os componentes do pipeline.
us-central1é compatível. - OUTPUT_DIR: URI do Cloud Storage para armazenar a saída da avaliação.
- EVALUATION_DATASET: tabela do BigQuery ou uma lista separada por vírgulas de caminhos do Cloud Storage para um conjunto de dados JSONL que contém exemplos de avaliação.
- TASK: tarefa de avaliação, que pode ser uma das
[summarization, question_answering]. - ID_COLUMNS: colunas que distinguem exemplos de avaliação únicos.
- AUTORATER_PROMPT_PARAMETERS : parâmetros de comando do avaliador automático mapeados para colunas ou modelos. Os parâmetros esperados são:
inference_instruction(detalhes sobre como executar uma tarefa) einference_context(conteúdo de referência para realizar a tarefa). Por exemplo,{'inference_context': {'column': 'my_prompt'}}usa a coluna "my_prompt" do conjunto de dados de avaliação para o contexto do avaliador automático. - RESPONSE_COLUMN_A : o nome de uma coluna no conjunto de dados de avaliação que contém previsões predefinidas ou o nome da coluna na saída do Modelo A que contém previsões. Se nenhum valor for fornecido, o nome correto da coluna de saída do modelo vai tentar ser inferido.
- RESPONSE_COLUMN_B : o nome de uma coluna no conjunto de dados de avaliação que contém previsões predefinidas ou o nome da coluna na saída do Modelo B que contém previsões. Se nenhum valor for fornecido, o nome correto da coluna de saída do modelo vai tentar ser inferido.
- MODEL_A (opcional): um nome de recurso de modelo totalmente qualificado (
projects/{project}/locations/{location}/models/{model}@{version}) ou nome de recurso de modelo do editor (publishers/{publisher}/models/{model}). Se as respostas do Modelo A forem especificadas, esse parâmetro não deverá ser fornecido. - MODEL_B (opcional): um nome de recurso de modelo totalmente qualificado (
projects/{project}/locations/{location}/models/{model}@{version}) ou nome de recurso de modelo do editor (publishers/{publisher}/models/{model}). Se as respostas do Modelo B forem especificadas, esse parâmetro não deverá ser fornecido. - MODEL_A_PROMPT_PARAMETERS (opcional): parâmetros do modelo de prompt do Modelo A mapeados para colunas ou modelos. Se as respostas do Modelo A forem predefinidas, esse parâmetro não deverá ser fornecido. Exemplo:
{'prompt': {'column': 'my_prompt'}}usa a colunamy_promptdo conjunto de dados de avaliação para o parâmetro de comando chamadoprompt. - MODEL_B_PROMPT_PARAMETERS (opcional): parâmetros do modelo de prompt do Modelo B mapeados para colunas ou modelos. Se as respostas do Modelo B forem predefinidas, esse parâmetro não deverá ser fornecido. Exemplo:
{'prompt': {'column': 'my_prompt'}}usa a colunamy_promptdo conjunto de dados de avaliação para o parâmetro de comando chamadoprompt. - JUDGMENTS_FORMAT
(opcional): o formato para gravar julgamentos. Pode ser
jsonl(padrão),jsonoubigquery. - BIGQUERY_DESTINATION_PREFIX: tabela do BigQuery em que as avaliações serão gravadas se o formato especificado for
bigquery.
import os
from google.cloud import aiplatform
parameters = {
'evaluation_dataset': 'EVALUATION_DATASET',
'id_columns': ['ID_COLUMNS'],
'task': 'TASK',
'autorater_prompt_parameters': AUTORATER_PROMPT_PARAMETERS,
'response_column_a': 'RESPONSE_COLUMN_A',
'response_column_b': 'RESPONSE_COLUMN_B',
'model_a': 'MODEL_A',
'model_a_prompt_parameters': MODEL_A_PROMPT_PARAMETERS,
'model_b': 'MODEL_B',
'model_b_prompt_parameters': MODEL_B_PROMPT_PARAMETERS,
'judgments_format': 'JUDGMENTS_FORMAT',
'bigquery_destination_prefix':
BIGQUERY_DESTINATION_PREFIX,
}
aiplatform.init(project='PROJECT_ID', location='LOCATION', staging_bucket='gs://OUTPUT_DIR')
aiplatform.PipelineJob(
display_name='PIPELINEJOB_DISPLAYNAME',
pipeline_root=os.path.join('gs://OUTPUT_DIR', 'PIPELINEJOB_DISPLAYNAME'),
template_path=(
'https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default'),
parameter_values=parameters,
).run()
Console
Para criar um job de avaliação de modelo por par usando o console Google Cloud , execute as seguintes etapas:
Comece com um modelo de fundação do Google ou use um que já existe no Model Registry da plataforma de agentes do Gemini Enterprise:
Para avaliar um modelo de base do Google:
Acesse o Model Garden da Gemini Enterprise Agent Platform e selecione um modelo que ofereça suporte à avaliação em pares, como
text-bison.Clique em Avaliar.
No menu exibido, clique em Selecionar para escolher uma versão de modelo.
O painel Salvar modelo pode pedir que você salve uma cópia do modelo no Model Registry da Gemini Enterprise Agent Platform, caso ainda não tenha uma cópia. Digite o nome do rótulo e clique em Salvar.
A página Criar avaliação é exibida. Para o método de avaliação selecione Avaliar este modelo em comparação com outro modelo.
Clique em Continuar.
Para avaliar um modelo atual no Model Registry da Gemini Enterprise Agent Platform:
Acesse a página Model Registry da Gemini Enterprise Agent Platform:
Acessar o Model Registry da plataforma de agentes do Gemini Enterprise
Clique no nome do modelo que você quer avaliar. Certifique-se de que tem suporte para avaliação de paridade. Exemplo,
text-bison.Na guia Avaliar, clique em SxS.
Clique em Criar avaliação de SxS.
Em cada etapa na página de criação da avaliação, insira o valor informações e clique em Continuar:
Na etapa Conjunto de dados de avaliação, selecione um objetivo de avaliação e um para comparar com o modelo selecionado. Selecione uma avaliação conjunto de dados e insira as colunas de ID (colunas de resposta).
Na etapa Configurações do modelo, especifique se você quer usar o respostas do modelo que já estão no conjunto de dados ou, se quiser usá-las Previsão em lote da plataforma do agente do Gemini Enterprise para gerar as respostas. Especificar as colunas de resposta dos dois modelos. Para a opção Prediction em lote da Gemini Enterprise Agent Platform, é possível especificar os parâmetros de comando do modelo de inferência.
Para a etapa Configurações do Autorater, insira seu aviso do autor. parâmetros e um local de saída para o com base em dados.
Clique emIniciar avaliação.
Visualizar os resultados da avaliação
Para encontrar os resultados da avaliação no Agent Platform Pipelines, inspecione os seguintes artefatos produzidos pelo pipeline do AutoSxS:
- A tabela julgamentos é produzida pelo árbitro do AutoSxS.
- As métricas agregadas são produzidas pelo componente de métricas AutoSxS.
- As métricas de alinhamento de preferências humanas são produzidas pelo componente de métricas AutoSxS.
Julgamentos
O AutoSxS gera avaliações (métricas de exemplo) que ajudam os usuários a entender o desempenho do modelo no nível do exemplo. Os julgamentos incluem as seguintes informações:
- Comandos de inferência
- Respostas do modelo
- Decisões do avaliador automático
- Explicações sobre as classificações
- Pontuações de confiança
Os julgamentos podem ser gravados no Cloud Storage no formato JSONL ou em uma tabela do BigQuery com estas colunas:
| Coluna | Descrição |
|---|---|
| Colunas de ID | Colunas que distinguem exemplos de avaliação exclusivos. |
inference_instruction |
Instrução usada para gerar respostas de modelo. |
inference_context |
Contexto usado para gerar respostas do modelo. |
response_a |
Resposta do modelo A, com base na instrução e no contexto de inferência. |
response_b |
Resposta do modelo B, com base na instrução e no contexto de inferência. |
choice |
O modelo com a melhor resposta. Os valores possíveis são Model A, Model B ou Error. Error significa que um erro impediu o autor de determinar se a resposta do modelo A ou do modelo B era a melhor opção. |
confidence |
Uma pontuação entre 0 e 1, que indica o nível de confiança do autor na escolha. |
explanation |
O motivo da escolha do avaliador automático. |
Métricas agregadas
A AutoSxS calcula métricas agregadas (taxa de ganhos) usando a tabela de julgamentos. Se nenhum dado de preferência humana for fornecido, as seguintes métricas agregadas serão geradas:
| Métrica | Descrição |
|---|---|
| Taxa de ganhos do modelo A do avaliador automático | Porcentagem de tempo que o avaliador automático decidiu que o modelo A tinha a melhor resposta. |
| Taxa de ganhos do modelo B do avaliador automático | Porcentagem de tempo que o avaliador automático decidiu que o modelo B tinha a melhor resposta. |
Para entender melhor a taxa de ganhos, analise os resultados baseados em linhas e as explicações do avaliador automático para determinar se eles estão alinhados às suas expectativas.
Métricas de alinhamento de preferências humanas
Se forem fornecidos dados de preferência humana, o AutoSxS vai gerar as seguintes métricas:
| Métrica | Descrição | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Taxa de ganhos do modelo A do avaliador automático | Porcentagem de tempo que o avaliador automático decidiu que o modelo A tinha a melhor resposta. | ||||||||||||||
| Taxa de ganhos do modelo B do avaliador automático | Porcentagem de tempo que o avaliador automático decidiu que o modelo B tinha a melhor resposta. | ||||||||||||||
| Taxa de ganhos A do modelo de preferência humana | Porcentagem de tempo que os humanos decidiram que o modelo A tinha a melhor resposta. | ||||||||||||||
| Taxa de ganhos do modelo B de preferência humana | Porcentagem de tempo que os humanos decidiram que o modelo B tinha a melhor resposta. | ||||||||||||||
| VP | Número de exemplos em que tanto o avaliador automático quanto as preferências humanas foram que o Modelo A teve a melhor resposta. | ||||||||||||||
| FP | Número de exemplos em que o avaliador automático escolheu o modelo A como a melhor resposta, mas a preferência humana foi que o modelo B tivesse a melhor resposta. | ||||||||||||||
| TN | Número de exemplos em que tanto o avaliador automático quanto as preferências humanas foram que o Modelo B teve a melhor resposta. | ||||||||||||||
| FN | Número de exemplos em que o avaliador automático escolheu o modelo B como a melhor resposta, mas a preferência humana foi que o modelo A tivesse a melhor resposta. | ||||||||||||||
| Precisão | Porcentagem de tempo em que o autorater concordou com avaliadores humanos. | ||||||||||||||
| Precisão | É a porcentagem de tempo em que tanto o autorater quanto os humanos acharam que o modelo A tinha uma resposta melhor, entre todos os casos em que ele achou que o modelo A tinha uma resposta melhor. | ||||||||||||||
| Recall | Porcentagem de tempo em que o autorater e os humanos pensaram que o Modelo A tinha uma resposta melhor, entre todos os casos em que os humanos pensaram que o Modelo A tinha uma resposta melhor. | ||||||||||||||
| F1 | A média harmônica de precisão e recall. | ||||||||||||||
| Kappa de Cohen | Uma medida de concordância entre o autorater e os avaliadores humanos que leva em consideração a probabilidade de um acordo aleatório. Cohen sugere a seguinte interpretação:
|
Casos de uso da AutoSxS
Você pode explorar como usar a AutoSxS com três cenários de caso de uso.
Comparação de modelos
Avaliar um modelo próprio ajustado (1p) em relação a um modelo 1p de referência.
É possível especificar que a inferência seja executada nos dois modelos simultaneamente.
Esse exemplo de código avalia um modelo ajustado do Vertex Model Registry em comparação com um modelo de referência do mesmo registro.
# Evaluation dataset schema:
# my_question: str
# my_context: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters': {
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'model_a': 'publishers/google/models/text-bison@002',
'model_a_prompt_parameters': {QUESTION: {'template': '{{my_question}}\nCONTEXT: {{my_context}}'}},
'response_column_a': 'content',
'model_b': 'projects/abc/locations/abc/models/tuned_bison',
'model_b_prompt_parameters': {'prompt': {'template': '{{my_context}}\n{{my_question}}'}},
'response_column_b': 'content',
}
Comparar previsões
Avaliar um modelo ajustado de terceiros (3p) em relação a um modelo de terceiros de referência.
É possível pular a inferência fornecendo diretamente as respostas do modelo.
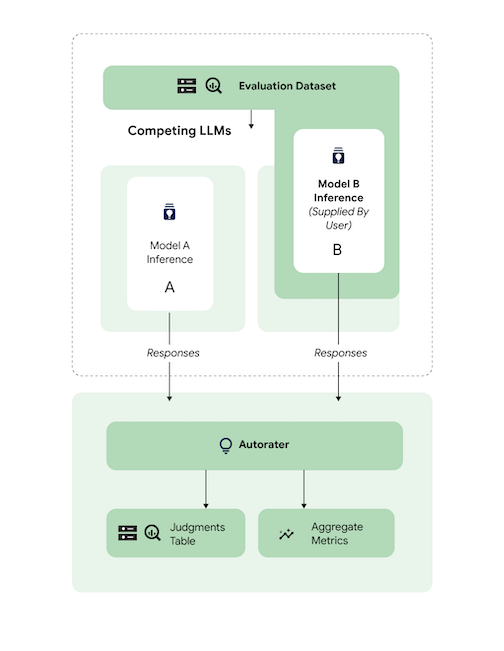
Esse exemplo de código avalia um modelo 3p ajustado em relação a um modelo 3p de referência.
# Evaluation dataset schema:
# my_question: str
# my_context: str
# response_b: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters':
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'response_column_a': 'content',
'response_column_b': 'response_b',
}
Verificar o alinhamento
Todas as tarefas com suporte foram comparadas usando dados de avaliadores humanos para garantir que as respostas do avaliador automático estejam alinhadas às preferências humanas. Se você quiser comparar o AutoSxS com seus casos de uso, forneça dados de preferência humana diretamente para o AutoSxS, que vai gerar estatísticas de alinhamento agregado.
Para verificar o alinhamento com um conjunto de dados de preferência humana, especifique as duas saídas (resultados da previsão) para o avaliador automático. Também é possível fornecer os resultados de inferência.
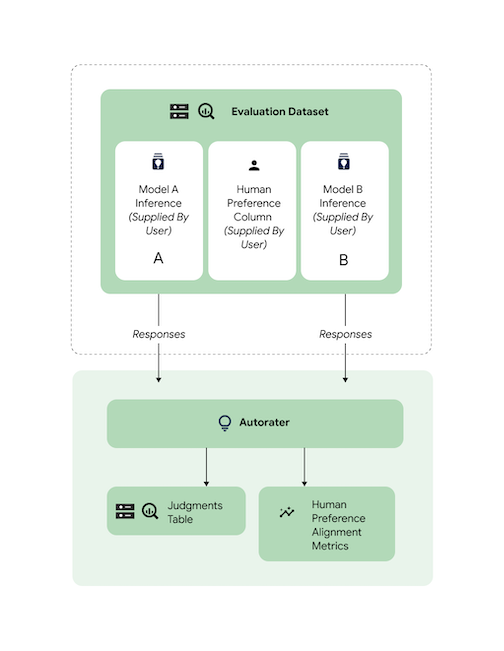
Esse exemplo de código verifica se os resultados e as explicações do avaliador automático estão alinhados com suas expectativas.
# Evaluation dataset schema:
# my_question: str
# my_context: str
# response_a: str
# response_b: str
# actual: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters': {
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'response_column_a': 'response_a',
'response_column_b': 'response_b',
'human_preference_column': 'actual',
}
A seguir
- Saiba mais sobre avaliação de IA generativa.
- Saiba mais sobre a avaliação on-line com o Serviço de avaliação de IA generativa.
- Saiba como ajustar modelos de base de linguagem.