
Depois de criar e avaliar o seu modelo de IA gen., pode usar o modelo para criar um agente, como um chatbot. O serviço de avaliação de IA gen permite-lhe medir a capacidade do seu agente para concluir tarefas e alcançar objetivos para o seu exemplo de utilização.
Vista geral
Tem as seguintes opções para avaliar o seu agente:
Avaliação da resposta final: avalie o resultado final de um agente (se o agente atingiu ou não o respetivo objetivo).
Avaliação da trajetória: avalie o caminho (sequência de chamadas de ferramentas) que o agente seguiu para chegar à resposta final.
Com o serviço de avaliação de IA gen., pode acionar uma execução do agente e obter métricas para a avaliação da trajetória e a avaliação da resposta final numa consulta do SDK do Vertex AI.
Agentes suportados
O serviço de avaliação de IA gen suporta as seguintes categorias de agentes:
| Agentes suportados | Descrição |
|---|---|
| Agente criado com o modelo do Agent Engine | O Agent Engine (LangChain no Vertex AI) é uma Google Cloud plataforma onde pode implementar e gerir agentes. |
| Agentes LangChain criados com o modelo personalizável do Agent Engine | O LangChain é uma plataforma de código aberto. |
| Função de agente personalizada | A função de agente personalizada é uma função flexível que recebe um comando para o agente e devolve uma resposta e uma trajetória num dicionário. |
Definir métricas para a avaliação de agentes
Defina as métricas para a resposta final ou a avaliação da trajetória:
Avaliação da resposta final
A avaliação da resposta final segue o mesmo processo que a avaliação da resposta do modelo. Para mais informações, consulte o artigo Defina as métricas de avaliação.
Avaliação da trajetória
As seguintes métricas ajudam a avaliar a capacidade do modelo de seguir a trajetória esperada:
Correspondência exata
Se a trajetória prevista for idêntica à trajetória de referência, com as mesmas chamadas de ferramentas na mesma ordem, a métrica trajectory_exact_match devolve uma pontuação de 1, caso contrário, 0.
Parâmetros de entrada de métricas
| Parâmetro de entrada | Descrição |
|---|---|
predicted_trajectory |
A lista de chamadas de ferramentas usadas pelo agente para alcançar a resposta final. |
reference_trajectory |
A utilização esperada da ferramenta para o agente satisfazer a consulta. |
Pontuações de saída
| Valor | Descrição |
|---|---|
| 0 | A trajetória prevista não corresponde à referência. |
| 1 | A trajetória prevista corresponde à referência. |
Correspondência na ordem
Se a trajetória prevista contiver todas as chamadas de ferramentas da trajetória de referência pela mesma ordem e também puder ter chamadas de ferramentas adicionais, a métrica trajectory_in_order_match devolve uma pontuação de 1, caso contrário, 0.
Parâmetros de entrada de métricas
| Parâmetro de entrada | Descrição |
|---|---|
predicted_trajectory |
A trajetória prevista usada pelo agente para alcançar a resposta final. |
reference_trajectory |
A trajetória prevista esperada para o agente satisfazer a consulta. |
Pontuações de saída
| Valor | Descrição |
|---|---|
| 0 | As chamadas de ferramentas na trajetória prevista não correspondem à ordem na trajetória de referência. |
| 1 | A trajetória prevista corresponde à referência. |
Correspondência em qualquer ordem
Se a trajetória prevista contiver todas as chamadas de ferramentas da trajetória de referência, mas a ordem não for importante e puder conter chamadas de ferramentas adicionais, a métrica trajectory_any_order_match devolve uma pontuação de 1. Caso contrário, devolve 0.
Parâmetros de entrada de métricas
| Parâmetro de entrada | Descrição |
|---|---|
predicted_trajectory |
A lista de chamadas de ferramentas usadas pelo agente para alcançar a resposta final. |
reference_trajectory |
A utilização esperada da ferramenta para o agente satisfazer a consulta. |
Pontuações de saída
| Valor | Descrição |
|---|---|
| 0 | A trajetória prevista não contém todas as chamadas de ferramentas na trajetória de referência. |
| 1 | A trajetória prevista corresponde à referência. |
Precisão
A métrica trajectory_precision mede quantos dos chamamentos de ferramentas na trajetória prevista são realmente relevantes ou corretos de acordo com a trajetória de referência.
A precisão é calculada da seguinte forma: conte quantas ações na trajetória prevista também aparecem na trajetória de referência. Divida essa contagem pelo número total de ações na trajetória prevista.
Parâmetros de entrada de métricas
| Parâmetro de entrada | Descrição |
|---|---|
predicted_trajectory |
A lista de chamadas de ferramentas usadas pelo agente para alcançar a resposta final. |
reference_trajectory |
A utilização esperada da ferramenta para o agente satisfazer a consulta. |
Pontuações de saída
| Valor | Descrição |
|---|---|
| Um valor de ponto flutuante no intervalo [0,1] | Quanto mais elevada for a pontuação, mais precisa é a trajetória prevista. |
Recordar
A métrica trajectory_recall mede quantas das chamadas de ferramentas essenciais da trajetória de referência são realmente captadas na trajetória prevista.
A precisão é calculada da seguinte forma: conte quantas ações na trajetória de referência também aparecem na trajetória prevista. Divida essa contagem pelo número total de ações na trajetória de referência.
Parâmetros de entrada de métricas
| Parâmetro de entrada | Descrição |
|---|---|
predicted_trajectory |
A lista de chamadas de ferramentas usadas pelo agente para alcançar a resposta final. |
reference_trajectory |
A utilização esperada da ferramenta para o agente satisfazer a consulta. |
Pontuações de saída
| Valor | Descrição |
|---|---|
| Um valor flutuante no intervalo de [0,1] | Quanto mais elevada for a pontuação, melhor é a recordação da trajetória prevista. |
Utilização de uma única ferramenta
A métrica trajectory_single_tool_use verifica se uma ferramenta específica que é especificada na especificação da métrica é usada na trajetória prevista. Não verifica a ordem das chamadas de ferramentas nem quantas vezes a ferramenta é usada, apenas se está presente ou não.
Parâmetros de entrada de métricas
| Parâmetro de entrada | Descrição |
|---|---|
predicted_trajectory |
A lista de chamadas de ferramentas usadas pelo agente para alcançar a resposta final. |
Pontuações de saída
| Valor | Descrição |
|---|---|
| 0 | A ferramenta está ausente |
| 1 | A ferramenta está presente. |
Além disso, as duas métricas de desempenho do agente seguintes são adicionadas aos resultados da avaliação por predefinição. Não precisa de os especificar em EvalTask.
latency
Tempo que o agente demora a devolver uma resposta.
| Valor | Descrição |
|---|---|
| Um flutuador | Calculado em segundos. |
failure
Um valor booleano para descrever se a invocação do agente resultou num erro ou foi bem-sucedida.
Pontuações de saída
| Valor | Descrição |
|---|---|
| 1 | Erro |
| 0 | Resposta válida devolvida |
Prepare o seu conjunto de dados para a avaliação do agente
Prepare o seu conjunto de dados para a resposta final ou a avaliação da trajetória.
O esquema de dados para a avaliação da resposta final é semelhante ao da avaliação da resposta do modelo.
Para a avaliação de trajetórias baseada em cálculos, o conjunto de dados tem de fornecer as seguintes informações:
| Tipo de entrada | Conteúdo do campo de entrada |
|---|---|
predicted_trajectory |
A lista de chamadas de ferramentas usadas pelos agentes para alcançar a resposta final. |
reference_trajectory (não necessário para trajectory_single_tool_use metric) |
A utilização esperada da ferramenta para o agente satisfazer a consulta. |
Exemplos de conjuntos de dados de avaliação
Os exemplos seguintes mostram conjuntos de dados para a avaliação de trajetórias. Tenha em atenção que reference_trajectory é obrigatório para todas as métricas, exceto trajectory_single_tool_use.
reference_trajectory = [
# example 1
[
{
"tool_name": "set_device_info",
"tool_input": {
"device_id": "device_2",
"updates": {
"status": "OFF"
}
}
}
],
# example 2
[
{
"tool_name": "get_user_preferences",
"tool_input": {
"user_id": "user_y"
}
},
{
"tool_name": "set_temperature",
"tool_input": {
"location": "Living Room",
"temperature": 23
}
},
]
]
predicted_trajectory = [
# example 1
[
{
"tool_name": "set_device_info",
"tool_input": {
"device_id": "device_3",
"updates": {
"status": "OFF"
}
}
}
],
# example 2
[
{
"tool_name": "get_user_preferences",
"tool_input": {
"user_id": "user_z"
}
},
{
"tool_name": "set_temperature",
"tool_input": {
"location": "Living Room",
"temperature": 23
}
},
]
]
eval_dataset = pd.DataFrame({
"predicted_trajectory": predicted_trajectory,
"reference_trajectory": reference_trajectory,
})
Importe o seu conjunto de dados de avaliação
Pode importar o conjunto de dados nos seguintes formatos:
Ficheiro JSONL ou CSV armazenado no Cloud Storage
tabela do BigQuery
Pandas DataFrame
O serviço de avaliação de IA gen fornece conjuntos de dados públicos de exemplo para demonstrar como pode avaliar os seus agentes. O código seguinte mostra como importar os conjuntos de dados públicos de um contentor do Cloud Storage:
# dataset name to be imported
dataset = "on-device" # Alternatives: "customer-support", "content-creation"
# copy the tools and dataset file
!gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/{dataset}/tools.py .
!gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/{dataset}/eval_dataset.json .
# load the dataset examples
import json
eval_dataset = json.loads(open('eval_dataset.json').read())
# run the tools file
%run -i tools.py
em que dataset é um dos seguintes conjuntos de dados públicos:
"on-device"para um Assistente doméstico no dispositivo, que controla os dispositivos domésticos. O agente ajuda com consultas como "Agenda o ar condicionado no quarto para que esteja ligado entre as 23:00 e as 08:00 e desligado no resto do tempo"."customer-support"para falar com um agente do apoio técnico. O agente ajuda com consultas como "Podes cancelar pedidos pendentes e encaminhar pedidos de apoio técnico abertos?""content-creation"para um agente de criação de conteúdo de marketing. O agente ajuda com consultas como "Reprograma a campanha X para ser uma campanha única no site de redes sociais Y com um orçamento 50% inferior, apenas a 25 de dezembro de 2024".
Execute a avaliação do agente
Execute uma avaliação para a trajetória ou a avaliação da resposta final:
Para a avaliação de agentes, pode misturar métricas de avaliação de respostas e métricas de avaliação de trajetórias, como no seguinte código:
single_tool_use_metric = TrajectorySingleToolUse(tool_name='tool_name')
eval_task = EvalTask(
dataset=EVAL_DATASET,
metrics=[
"rouge_l_sum",
"bleu",
custom_trajectory_eval_metric, # custom computation-based metric
"trajectory_exact_match",
"trajectory_precision",
single_tool_use_metric,
response_follows_trajectory_metric # llm-based metric
],
)
eval_result = eval_task.evaluate(
runnable=RUNNABLE,
)
Personalização de métricas
Pode personalizar uma métrica baseada em modelos de linguagem (conteúdo extenso) para avaliação de trajetória através de uma interface baseada em modelos ou de raiz. Para mais detalhes, consulte a secção sobre métricas baseadas em modelos. Segue-se um exemplo com base em modelos:
response_follows_trajectory_prompt_template = PointwiseMetricPromptTemplate(
criteria={
"Follows trajectory": (
"Evaluate whether the agent's response logically follows from the "
"sequence of actions it took. Consider these sub-points:\n"
" - Does the response reflect the information gathered during the trajectory?\n"
" - Is the response consistent with the goals and constraints of the task?\n"
" - Are there any unexpected or illogical jumps in reasoning?\n"
"Provide specific examples from the trajectory and response to support your evaluation."
)
},
rating_rubric={
"1": "Follows trajectory",
"0": "Does not follow trajectory",
},
input_variables=["prompt", "predicted_trajectory"],
)
response_follows_trajectory_metric = PointwiseMetric(
metric="response_follows_trajectory",
metric_prompt_template=response_follows_trajectory_prompt_template,
)
Também pode definir uma métrica personalizada baseada em cálculos para a avaliação da trajetória ou a avaliação da resposta da seguinte forma:
def essential_tools_present(instance, required_tools = ["tool1", "tool2"]):
trajectory = instance["predicted_trajectory"]
tools_present = [tool_used['tool_name'] for tool_used in trajectory]
if len(required_tools) == 0:
return {"essential_tools_present": 1}
score = 0
for tool in required_tools:
if tool in tools_present:
score += 1
return {
"essential_tools_present": score/len(required_tools),
}
custom_trajectory_eval_metric = CustomMetric(name="essential_tools_present", metric_function=essential_tools_present)
Veja e interprete os resultados
Para a avaliação de trajetória ou a avaliação de resposta final, os resultados da avaliação são apresentados da seguinte forma:
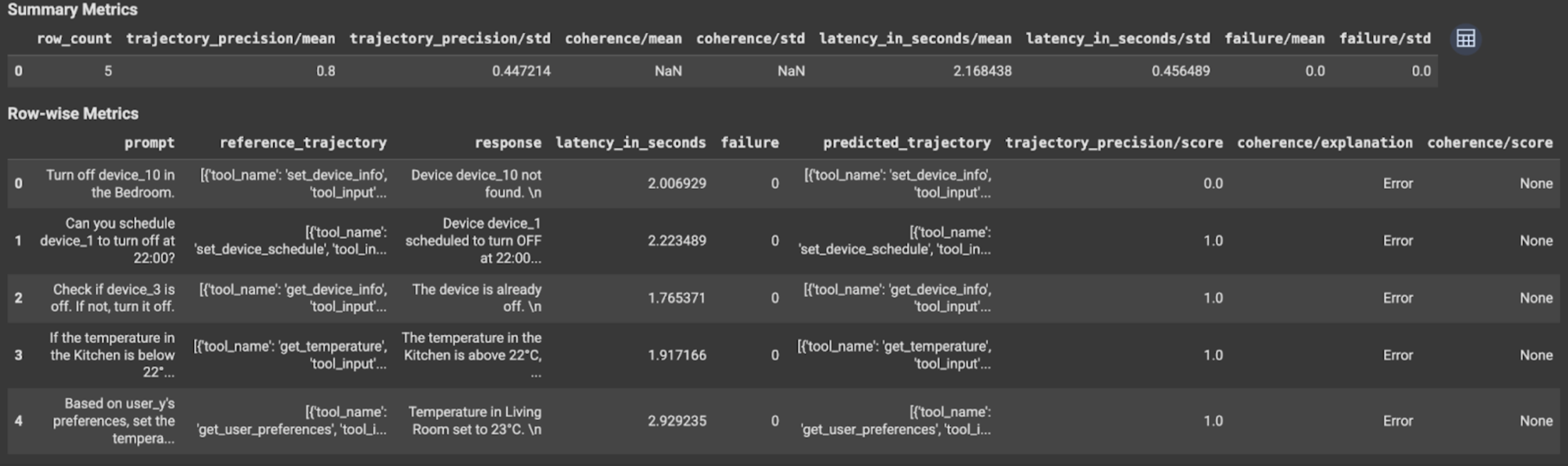
Os resultados da avaliação contêm as seguintes informações:
Métricas de resposta final
Resultados ao nível da instância
| Coluna | Descrição |
|---|---|
| resposta | Resposta final gerada pelo agente. |
| latency_in_seconds | Tempo necessário para gerar a resposta. |
| falha | Indica se foi gerada ou não uma resposta válida. |
| pontuação | Uma pontuação calculada para a resposta especificada na especificação da métrica. |
| explicação | A explicação da pontuação especificada na especificação da métrica. |
Agregue resultados
| Coluna | Descrição |
|---|---|
| média | Classificação média para todas as instâncias. |
| desvio padrão | Desvio padrão de todas as pontuações. |
Métricas de trajetória
Resultados ao nível da instância
| Coluna | Descrição |
|---|---|
| predicted_trajectory | Sequência de chamadas de ferramentas seguidas pelo agente para alcançar a resposta final. |
| reference_trajectory | Sequência de chamadas de ferramentas esperadas. |
| pontuação | Uma pontuação calculada para a trajetória prevista e a trajetória de referência especificadas na especificação da métrica. |
| latency_in_seconds | Tempo necessário para gerar a resposta. |
| falha | Indica se foi gerada ou não uma resposta válida. |
Agregue resultados
| Coluna | Descrição |
|---|---|
| média | Classificação média para todas as instâncias. |
| desvio padrão | Desvio padrão de todas as pontuações. |
Protocolo Agent2Agent (A2A)
Se estiver a criar um sistema multiagente, recomendamos vivamente que reveja o protocolo A2A. O protocolo A2A é uma norma aberta que permite uma comunicação e uma colaboração perfeitas entre agentes de IA, independentemente das respetivas estruturas subjacentes. Foi doado pela Google Cloud à Linux Foundation em junho de 2025. Para usar os SDKs A2A ou experimentar os exemplos, consulte o repositório do GitHub.
O que se segue?
Experimente os seguintes blocos de notas de avaliação de agentes: