
Nachdem Sie Ihr generatives KI-Modell erstellt und bewertet haben, können Sie es verwenden, um einen Agenten wie einen Chatbot zu erstellen. Mit dem Gen AI Evaluation Service können Sie die Fähigkeit Ihres Agents messen, Aufgaben und Ziele für Ihren Anwendungsfall zu erfüllen.
Übersicht
Sie haben die folgenden Möglichkeiten, Ihren Agent zu testen:
Bewertung der endgültigen Antwort: Bewerten Sie die endgültige Ausgabe eines Agenten (unabhängig davon, ob der Agent sein Ziel erreicht hat).
Bewertung des Ablaufs: Bewerten Sie den Pfad (die Abfolge der Tool-Aufrufe), den der Agent verwendet hat, um die endgültige Antwort zu erhalten.
Mit dem Gen AI Evaluation Service können Sie die Ausführung eines Agenten auslösen und Messwerte sowohl für die Ablaufbewertung als auch für die Bewertung der endgültigen Antwort in einer Vertex AI SDK-Abfrage abrufen.
Unterstützte Kundenservicemitarbeiter
Der Gen AI Evaluation Service unterstützt die folgenden Kategorien von Agents:
| Unterstützte Kundenservicemitarbeiter | Beschreibung |
|---|---|
| Mit der Vorlage der Agent Engine erstellter Agent | Agent Engine (LangChain in Vertex AI) ist eine Google Cloud Plattform, auf der Sie Agents bereitstellen und verwalten können. |
| LangChain-Agents, die mit der anpassbaren Vorlage von Agent Engine erstellt wurden | LangChain ist eine Open-Source-Plattform. |
| Benutzerdefinierte Agent-Funktion | Eine benutzerdefinierte Agent-Funktion ist eine flexible Funktion, die einen Prompt für den Agenten entgegennimmt und eine Antwort und einen Trajektor in einem Dictionary zurückgibt. |
Messwerte für die Agent-Bewertung definieren
Messwerte für die endgültige Antwort oder die Vorgehensweise definieren:
Bewertung der endgültigen Antwort
Die Bewertung der endgültigen Antwort erfolgt nach demselben Verfahren wie die Bewertung der Modellantwort. Weitere Informationen finden Sie unter Evaluierungsmesswerte definieren.
Bewertung der Vorgehensweise
Die folgenden Messwerte helfen Ihnen, die Fähigkeit des Modells zu bewerten, dem erwarteten Verlauf zu folgen:
Genaue Übereinstimmung
Wenn die vorhergesagte Trajektorie mit der Referenz-Trajektorie identisch ist, mit genau denselben Tool-Aufrufen in genau derselben Reihenfolge, gibt der Messwert trajectory_exact_match den Wert 1 zurück, andernfalls 0.
Messwerteingabeparameter
| Eingabeparameter | Beschreibung |
|---|---|
predicted_trajectory |
Die Liste der Tool-Aufrufe, die vom Agenten verwendet wurden, um die endgültige Antwort zu erhalten. |
reference_trajectory |
Die erwartete Verwendung von Tools durch den Agenten, um die Anfrage zu beantworten. |
Ausgabewerte
| Wert | Beschreibung |
|---|---|
| 0 | Die vorhergesagte Trajektorie stimmt nicht mit der Referenz überein. |
| 1 | Die vorhergesagte Trajektorie stimmt mit der Referenz überein. |
Übereinstimmung in der richtigen Reihenfolge
Wenn die vorhergesagte Trajektorie alle Tool-Aufrufe aus der Referenz-Trajektorie in derselben Reihenfolge enthält und möglicherweise zusätzliche Tool-Aufrufe hat, gibt der Messwert trajectory_in_order_match den Wert 1 zurück, andernfalls 0.
Messwerteingabeparameter
| Eingabeparameter | Beschreibung |
|---|---|
predicted_trajectory |
Die vom Agent verwendete vorhergesagte Vorgehensweise, um die endgültige Antwort zu erhalten. |
reference_trajectory |
Die erwartete vorhergesagte Trajektorie für den Agent, um die Anfrage zu erfüllen. |
Ausgabewerte
| Wert | Beschreibung |
|---|---|
| 0 | Die Toolaufrufe im vorhergesagten Pfad stimmen nicht mit der Reihenfolge im Referenzpfad überein. |
| 1 | Die vorhergesagte Trajektorie stimmt mit der Referenz überein. |
Any-order match
Wenn die vorhergesagte Sequenz alle Tool-Aufrufe aus der Referenzsequenz enthält, die Reihenfolge jedoch keine Rolle spielt und zusätzliche Tool-Aufrufe enthalten sein können, gibt der Messwert trajectory_any_order_match den Wert 1 zurück, andernfalls 0.
Messwerteingabeparameter
| Eingabeparameter | Beschreibung |
|---|---|
predicted_trajectory |
Die Liste der Tool-Aufrufe, die vom Agenten verwendet wurden, um die endgültige Antwort zu erhalten. |
reference_trajectory |
Die erwartete Verwendung von Tools durch den Agenten, um die Anfrage zu beantworten. |
Ausgabewerte
| Wert | Beschreibung |
|---|---|
| 0 | Die vorhergesagte Trajektorie enthält nicht alle Tool-Aufrufe in der Referenz-Trajektorie. |
| 1 | Die vorhergesagte Trajektorie stimmt mit der Referenz überein. |
Precision
Der Messwert trajectory_precision gibt an, wie viele der Tool-Aufrufe im vorhergesagten Pfad gemäß dem Referenzpfad tatsächlich relevant oder korrekt sind.
Die Genauigkeit wird so berechnet: Zählen Sie, wie viele Aktionen im vorhergesagten Pfad auch im Referenzpfad vorkommen. Teilen Sie diese Anzahl durch die Gesamtzahl der Aktionen im vorhergesagten Verlauf.
Messwerteingabeparameter
| Eingabeparameter | Beschreibung |
|---|---|
predicted_trajectory |
Die Liste der Tool-Aufrufe, die vom Agenten verwendet wurden, um die endgültige Antwort zu erhalten. |
reference_trajectory |
Die erwartete Verwendung von Tools durch den Agenten, um die Anfrage zu beantworten. |
Ausgabewerte
| Wert | Beschreibung |
|---|---|
| Eine Gleitkommazahl im Bereich [0,1] | Je höher der Wert, desto genauer die vorhergesagte Flugbahn. |
Recall
Der Messwert trajectory_recall gibt an, wie viele der wichtigen Tool-Aufrufe aus dem Referenzpfad tatsächlich im vorhergesagten Pfad enthalten sind.
Der Recall wird so berechnet: Zählen Sie, wie viele Aktionen im Referenzpfad auch im vorhergesagten Pfad vorkommen. Teilen Sie diese Anzahl durch die Gesamtzahl der Aktionen im Referenzpfad.
Messwerteingabeparameter
| Eingabeparameter | Beschreibung |
|---|---|
predicted_trajectory |
Die Liste der Tool-Aufrufe, die vom Agenten verwendet wurden, um die endgültige Antwort zu erhalten. |
reference_trajectory |
Die erwartete Verwendung von Tools durch den Agenten, um die Anfrage zu beantworten. |
Ausgabewerte
| Wert | Beschreibung |
|---|---|
| Eine Gleitkommazahl im Bereich [0,1] | Je höher der Wert, desto besser ist der Recall des vorhergesagten Pfads. |
Nutzung eines einzelnen Tools
Mit der Messwertgruppe trajectory_single_tool_use wird geprüft, ob ein bestimmtes Tool, das in der Messwertspezifikation angegeben ist, im vorhergesagten Verlauf verwendet wird. Es wird nicht geprüft, in welcher Reihenfolge Tool-Aufrufe erfolgen oder wie oft das Tool verwendet wird, sondern nur, ob es vorhanden ist.
Messwerteingabeparameter
| Eingabeparameter | Beschreibung |
|---|---|
predicted_trajectory |
Die Liste der Tool-Aufrufe, die vom Agenten verwendet wurden, um die endgültige Antwort zu erhalten. |
Ausgabewerte
| Wert | Beschreibung |
|---|---|
| 0 | Das Tool ist nicht vorhanden |
| 1 | Das Tool ist vorhanden. |
Außerdem werden den Bewertungsergebnissen standardmäßig die folgenden beiden Messwerte für die Agentenleistung hinzugefügt. Sie müssen sie nicht in EvalTask angeben.
latency
Die Zeit, die der Agent benötigt, um eine Antwort zurückzugeben.
| Wert | Beschreibung |
|---|---|
| Ein Float | Wird in Sekunden berechnet. |
failure
Ein boolescher Wert, der angibt, ob der Agentaufruf zu einem Fehler geführt hat oder erfolgreich war.
Ausgabewerte
| Wert | Beschreibung |
|---|---|
| 1 | Fehler |
| 0 | Gültige Antwort zurückgegeben |
Dataset für die Bewertung des KI-Agenten vorbereiten
Bereiten Sie Ihr Dataset für die Bewertung der endgültigen Antwort oder des Pfads vor.
Das Datenschema für die Bewertung der endgültigen Antwort ähnelt dem für die Bewertung der Modellantwort.
Für die berechnungsbasierte Trajektorienbewertung müssen in Ihrem Dataset die folgenden Informationen enthalten sein:
| Eingabetyp | Inhalt des Eingabefelds |
|---|---|
predicted_trajectory |
Die Liste der Tool-Aufrufe, die von den Agents verwendet wurden, um die endgültige Antwort zu erhalten. |
reference_trajectory (nicht erforderlich für trajectory_single_tool_use metric) |
Die erwartete Verwendung von Tools durch den Agenten, um die Anfrage zu beantworten. |
Beispiele für Bewertungs-Datasets
Die folgenden Beispiele zeigen Datasets für die Trajektorienbewertung. Hinweis: reference_trajectory ist für alle Messwerte außer trajectory_single_tool_use erforderlich.
reference_trajectory = [
# example 1
[
{
"tool_name": "set_device_info",
"tool_input": {
"device_id": "device_2",
"updates": {
"status": "OFF"
}
}
}
],
# example 2
[
{
"tool_name": "get_user_preferences",
"tool_input": {
"user_id": "user_y"
}
},
{
"tool_name": "set_temperature",
"tool_input": {
"location": "Living Room",
"temperature": 23
}
},
]
]
predicted_trajectory = [
# example 1
[
{
"tool_name": "set_device_info",
"tool_input": {
"device_id": "device_3",
"updates": {
"status": "OFF"
}
}
}
],
# example 2
[
{
"tool_name": "get_user_preferences",
"tool_input": {
"user_id": "user_z"
}
},
{
"tool_name": "set_temperature",
"tool_input": {
"location": "Living Room",
"temperature": 23
}
},
]
]
eval_dataset = pd.DataFrame({
"predicted_trajectory": predicted_trajectory,
"reference_trajectory": reference_trajectory,
})
Bewertungs-Dataset importieren
Sie können Ihr Dataset in den folgenden Formaten importieren:
In Cloud Storage gespeicherte JSONL- oder CSV-Datei
BigQuery-Tabelle
Pandas-DataFrame
Der Bewertungsdienst für generative KI bietet öffentliche Beispieldatasets, um zu veranschaulichen, wie Sie Ihre Agents bewerten können. Im folgenden Code wird gezeigt, wie Sie die öffentlichen Datasets aus einem Cloud Storage-Bucket importieren:
# dataset name to be imported
dataset = "on-device" # Alternatives: "customer-support", "content-creation"
# copy the tools and dataset file
!gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/{dataset}/tools.py .
!gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/{dataset}/eval_dataset.json .
# load the dataset examples
import json
eval_dataset = json.loads(open('eval_dataset.json').read())
# run the tools file
%run -i tools.py
Dabei kann dataset für eines der folgenden öffentlichen Datasets stehen:
"on-device"für einen On-Device Home Assistant, der Smart-Home-Geräte steuert. Der Agent hilft bei Anfragen wie „Stelle die Klimaanlage im Schlafzimmer so ein, dass sie zwischen 23:00 Uhr und 8:00 Uhr eingeschaltet und die restliche Zeit ausgeschaltet ist.“"customer-support", um mit einem Kundenservicemitarbeiter zu sprechen. Der Kundenservicemitarbeiter kann bei Anfragen wie „Kannst du alle ausstehenden Bestellungen stornieren und alle offenen Support-Tickets eskalieren?“ helfen."content-creation"für einen Marketing Content Creation Agent. Der Agent kann bei Anfragen wie „Verschiebe Kampagne X auf den 25. Dezember 2024 und führe sie als einmalige Kampagne auf der Social-Media-Website Y mit einem um 50% reduzierten Budget durch.“ helfen.
KI‑Agenten bewerten
So führen Sie eine Bewertung für die Trajektorie oder die endgültige Antwort durch:
Für die Agentenbewertung können Sie Messwerte für die Antwortbewertung und Messwerte für die Ablaufbewertung kombinieren, wie im folgenden Code:
single_tool_use_metric = TrajectorySingleToolUse(tool_name='tool_name')
eval_task = EvalTask(
dataset=EVAL_DATASET,
metrics=[
"rouge_l_sum",
"bleu",
custom_trajectory_eval_metric, # custom computation-based metric
"trajectory_exact_match",
"trajectory_precision",
single_tool_use_metric,
response_follows_trajectory_metric # llm-based metric
],
)
eval_result = eval_task.evaluate(
runnable=RUNNABLE,
)
Messwerte anpassen
Sie können einen auf einem Large Language Model basierenden Messwert für die Trajektorbewertung über eine Vorlagenschnittstelle oder von Grund auf anpassen. Weitere Informationen finden Sie im Abschnitt zu modellbasierten Messwerten. Hier ein Beispiel:
response_follows_trajectory_prompt_template = PointwiseMetricPromptTemplate(
criteria={
"Follows trajectory": (
"Evaluate whether the agent's response logically follows from the "
"sequence of actions it took. Consider these sub-points:\n"
" - Does the response reflect the information gathered during the trajectory?\n"
" - Is the response consistent with the goals and constraints of the task?\n"
" - Are there any unexpected or illogical jumps in reasoning?\n"
"Provide specific examples from the trajectory and response to support your evaluation."
)
},
rating_rubric={
"1": "Follows trajectory",
"0": "Does not follow trajectory",
},
input_variables=["prompt", "predicted_trajectory"],
)
response_follows_trajectory_metric = PointwiseMetric(
metric="response_follows_trajectory",
metric_prompt_template=response_follows_trajectory_prompt_template,
)
Sie können auch einen benutzerdefinierten berechnungsbasierten Messwert für die Trajektorien- oder Reaktionsbewertung definieren:
def essential_tools_present(instance, required_tools = ["tool1", "tool2"]):
trajectory = instance["predicted_trajectory"]
tools_present = [tool_used['tool_name'] for tool_used in trajectory]
if len(required_tools) == 0:
return {"essential_tools_present": 1}
score = 0
for tool in required_tools:
if tool in tools_present:
score += 1
return {
"essential_tools_present": score/len(required_tools),
}
custom_trajectory_eval_metric = CustomMetric(name="essential_tools_present", metric_function=essential_tools_present)
Ergebnisse ansehen und interpretieren
Bei der Bewertung von Trajektorien oder endgültigen Antworten werden die Bewertungsergebnisse so angezeigt:
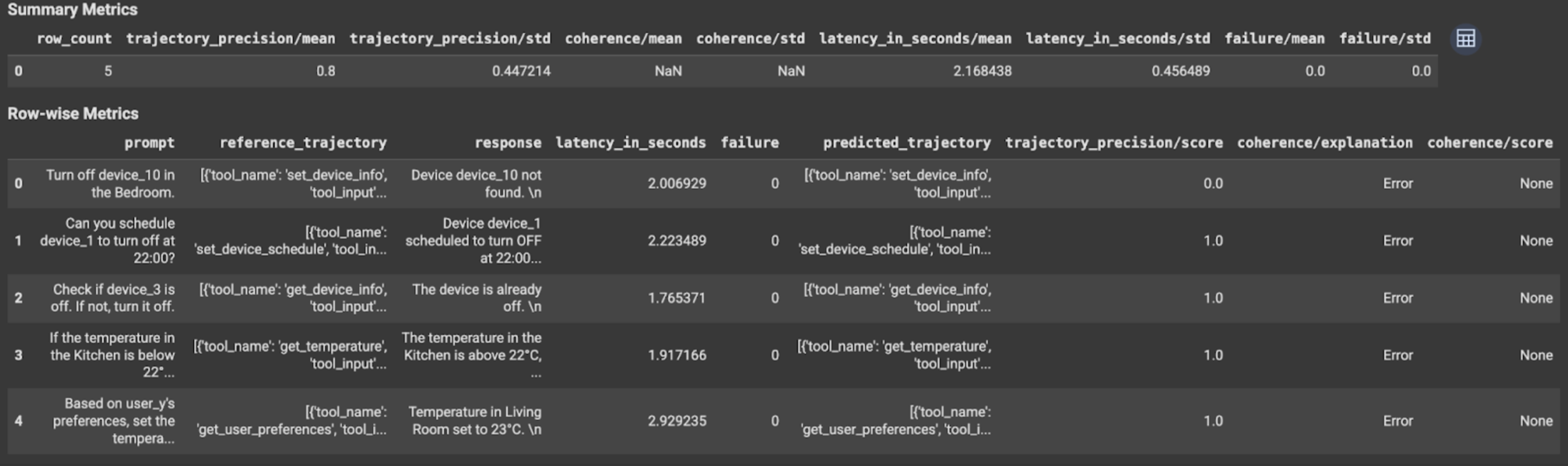
Die Auswertungsergebnisse enthalten die folgenden Informationen:
Messwerte für die endgültige Antwort
Ergebnisse auf Instanzebene
| Spalte | Beschreibung |
|---|---|
| Antwort | Die endgültige Antwort des Agenten. |
| latency_in_seconds | Zeit, die zum Generieren der Antwort benötigt wurde. |
| Fehler | Gibt an, ob eine gültige Antwort generiert wurde. |
| Punktzahl | Eine für die in der Messwertspezifikation angegebene Antwort berechnete Punktzahl. |
| Erklärung | Die Erklärung für den in der Messwertspezifikation angegebenen Wert. |
Zusammengefasste Ergebnisse
| Spalte | Beschreibung |
|---|---|
| Mittel | Durchschnittliche Punktzahl für alle Instanzen. |
| Standardabweichung | Standardabweichung aller Punktzahlen. |
Messwerte für die Vorgehensweise
Ergebnisse auf Instanzebene
| Spalte | Beschreibung |
|---|---|
| predicted_trajectory | Reihenfolge der Tool-Aufrufe, die vom Agenten ausgeführt werden, um die endgültige Antwort zu erhalten. |
| reference_trajectory | Reihenfolge der erwarteten Toolaufrufe. |
| Punktzahl | Ein Wert, der für die in der Messwertspezifikation angegebene Vorhersage- und Referenzvorgehensweise berechnet wird. |
| latency_in_seconds | Zeit, die zum Generieren der Antwort benötigt wurde. |
| Fehler | Gibt an, ob eine gültige Antwort generiert wurde. |
Zusammengefasste Ergebnisse
| Spalte | Beschreibung |
|---|---|
| Mittel | Durchschnittliche Punktzahl für alle Instanzen. |
| Standardabweichung | Standardabweichung aller Punktzahlen. |
Agent2Agent-Protokoll (A2A)
Wenn Sie ein Multi-Agent-System entwickeln, empfehlen wir Ihnen dringend, sich das A2A-Protokoll anzusehen. Das A2A-Protokoll ist ein offener Standard, der eine nahtlose Kommunikation und Zusammenarbeit zwischen KI-Agenten ermöglicht, unabhängig von den zugrunde liegenden Frameworks. Es wurde im Juni 2025 von Google Cloud an die Linux Foundation gespendet. Wenn Sie die A2A-SDKs verwenden oder die Beispiele ausprobieren möchten, sehen Sie sich das GitHub-Repository an.
Nächste Schritte
Probieren Sie die folgenden Notebooks zur Agent-Bewertung aus: