
Tabular Workflows הוא אוסף של צינורות עיבוד נתונים משולבים, מנוהלים במלואם וניתנים להתאמה, ללמידת מכונה מקצה לקצה עם נתונים טבלאיים. הוא מבוסס על הטכנולוגיה של Google לפיתוח מודלים, ומספק לכם אפשרויות התאמה אישית כדי להתאים לצרכים שלכם.
יתרונות
- מנוהל באופן מלא: לא צריך לדאוג לעדכונים, לתלות ולבעיות תאימות.
- קל להרחבה: לא צריך לתכנן מחדש את התשתית ככל שהעומסים או מערכי הנתונים גדלים.
- אופטימיזציה לביצועים: החומרה המתאימה מוגדרת אוטומטית בהתאם לדרישות של תהליך העבודה.
- אינטגרציה עמוקה: תאימות למוצרים בחבילת Vertex AI MLOps, כמו Vertex AI Pipelines ו-Vertex AI Experiments, מאפשרת להריץ הרבה ניסויים בפרק זמן קצר.
סקירה טכנית
כל תהליך עבודה הוא מופע מנוהל של Vertex AI Pipelines.
Vertex AI Pipelines הוא שירות ללא שרתים שמריץ צינורות עיבוד נתונים של Kubeflow. אתם יכולים להשתמש בצינורות כדי להפוך לאוטומטיות את המשימות שלכם בלמידת מכונה ובהכנת נתונים, ולעקוב אחריהן. כל שלב בצינור העברת נתונים מבצע חלק מזרימת העבודה של צינור העברת הנתונים. לדוגמה, צינור יכול לכלול שלבים לפיצול נתונים, המרה של סוגי נתונים ואימון מודל. מכיוון ששלבים הם מופעים של רכיבי צינור עיבוד נתונים, יש להם קלט, פלט וקובץ אימג' של קונטיינר. אפשר להגדיר את קלט השלב מתוך הקלט של צינור העיבוד, או שהוא יכול להיות תלוי בפלט של שלבים אחרים בצינור העיבוד הזה. התלויות האלה מגדירות את תהליך העבודה של הצינור כגרף אציקלי מכוון.
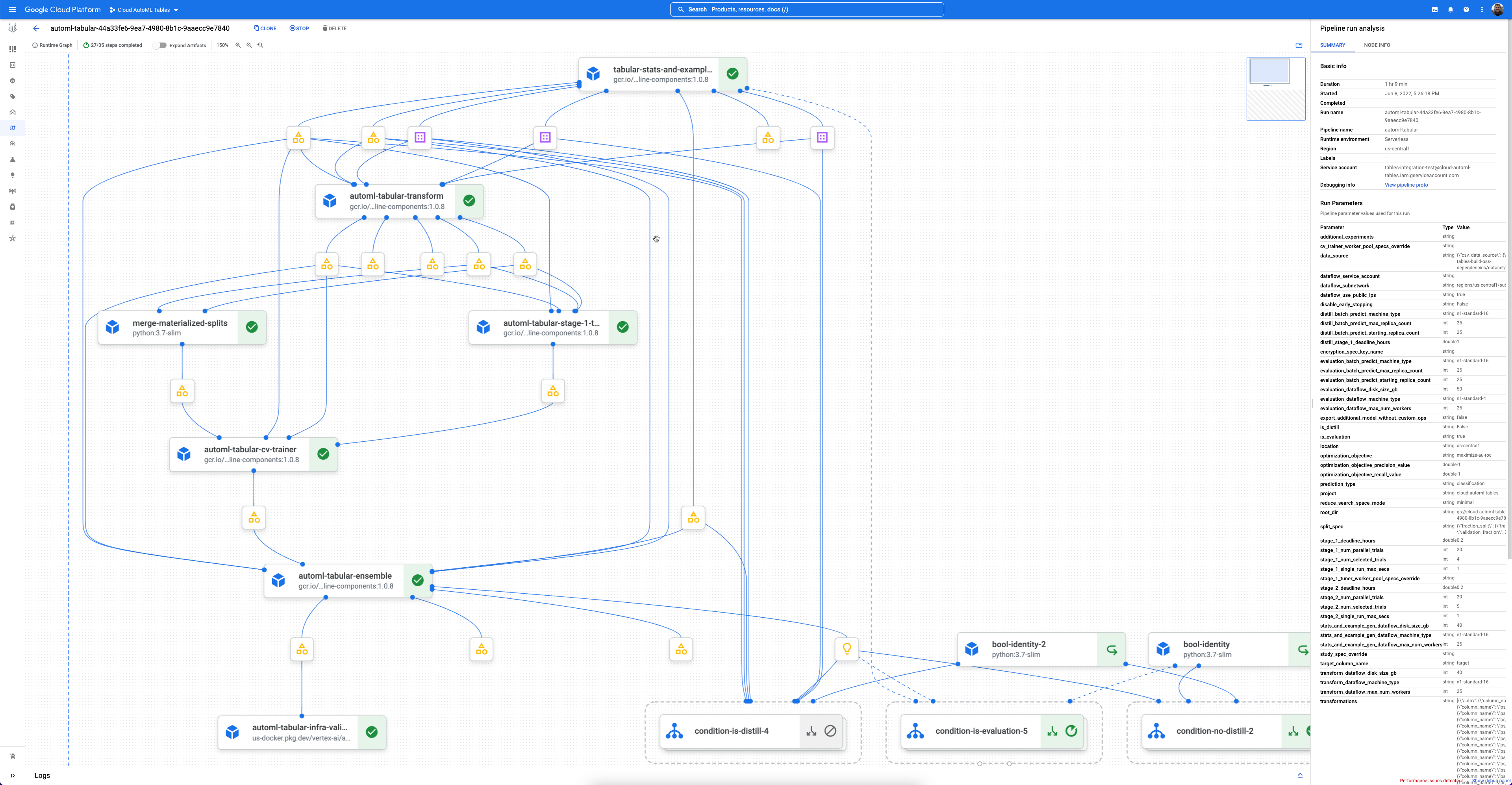
קדימה, מתחילים
ברוב המקרים, מגדירים ומריצים את צינור עיבוד הנתונים באמצעות Google Cloud Pipeline Components SDK. הקוד לדוגמה הבא ממחיש את התהליך הזה. שימו לב שההטמעה בפועל של הקוד עשויה להיות שונה.
// Define the pipeline and the parameters
template_path, parameter_values = tabular_utils.get_default_pipeline_and_parameters(
…
optimization_objective=optimization_objective,
data_source=data_source,
target_column_name=target_column_name
…)
// Run the pipeline
job = pipeline_jobs.PipelineJob(..., template_path=template_path, parameter_values=parameter_values)
job.run(...)
כדי לקבל דוגמאות של מחברות ו-Colab, אפשר לפנות לנציג המכירות או למלא טופס בקשה.
ניהול גרסאות ותחזוקה
ל-Tabular Workflows יש מערכת יעילה לניהול גרסאות, שמאפשרת לבצע עדכונים ושיפורים באופן רציף בלי לשנות את האפליקציות.
כל תהליך עבודה מופץ ומעודכן כחלק מGoogle Cloud Pipeline Components SDK. עדכונים ושינויים בתהליך עבודה כלשהו מתפרסמים כגרסאות חדשות של אותו תהליך עבודה. גרסאות קודמות של כל תהליך עבודה תמיד זמינות דרך הגרסאות הקודמות של ה-SDK. אם גרסת ה-SDK מוצמדת, גם גרסת תהליך העבודה מוצמדת.
תהליכי עבודה זמינים
Vertex AI מספק את תהליכי העבודה הטבלאיים הבאים:
| שם | סוג | זמינות |
|---|---|---|
| Feature Transform Engine | Feature Engineering | גרסת טרום-השקה ציבורית |
| End-to-End AutoML | סיווג ורגרסיה | זמינות לכלל המשתמשים (GA) |
| TabNet | סיווג ורגרסיה | גרסת טרום-השקה ציבורית |
| תחזיות | תחזיות | גרסת טרום-השקה ציבורית |
לקבלת מידע נוסף ומחברות לדוגמה, אפשר לפנות לנציג המכירות או למלא טופס בקשה.
מנוע טרנספורמציה של תכונות
התכונה Transform Engine מבצעת בחירת תכונות וטרנספורמציות של תכונות. אם האפשרות 'בחירת תכונות' מופעלת, Feature Transform Engine יוצר קבוצה מדורגת של תכונות חשובות. אם הפעלתם את התכונה 'טרנספורמציות של תכונות', המנוע Feature Transform Engine מעבד את התכונות כדי לוודא שהקלט לאימון המודל ולהצגת המודל יהיה עקבי. אפשר להשתמש ב-Feature Transform Engine בנפרד או יחד עם כל אחד מתהליכי העבודה של אימון נתונים בפורמט טבלאי. הוא תומך ב-frameworks של TensorFlow וגם ב-frameworks אחרים.
מידע נוסף זמין במאמר בנושא הנדסת פיצ'רים (feature engineering).
תהליכי עבודה טבלאיים לסיווג ולרגרסיה
תהליך עבודה טבלאי של AutoML מקצה לקצה
Tabular Workflow for End-to-End AutoML הוא צינור AutoML מלא למשימות סיווג ורגרסיה. הוא דומה ל-AutoML API, אבל מאפשר לכם לבחור מה לשלוט ומה להפוך לאוטומטי. במקום אמצעי בקרה לכל הצינור, יש אמצעי בקרה לכל שלב בצינור. אמצעי הבקרה של הצינור כוללים:
- פיצול נתונים
- Feature engineering
- חיפוש אדריכלות
- אימון המודל
- שילוב מודלים
- זיקוק מודלים
יתרונות
- תמיכה במערכי נתונים גדולים בגודל של כמה טרה-בייט ועד 1,000 עמודות.
- האפשרות הזו מאפשרת לכם לשפר את היציבות ולקצר את זמן האימון על ידי הגבלת מרחב החיפוש של סוגי הארכיטקטורה או דילוג על חיפוש הארכיטקטורה.
- האפשרות הזו מאפשרת לכם לשפר את מהירות האימון על ידי בחירה ידנית של החומרה שמשמשת לאימון ולחיפוש ארכיטקטורה.
- מאפשרת להקטין את גודל המודל ולשפר את זמן האחזור באמצעות זיקוק או שינוי גודל האנסמבל.
- אפשר לבדוק כל רכיב של AutoML בממשק גרפי רב-עוצמה של צינורות, שמאפשר לראות את טבלאות הנתונים שעברו טרנספורמציה, את ארכיטקטורות המודלים שנבדקו ועוד הרבה פרטים.
- כל רכיב AutoML מקבל גמישות ושקיפות מורחבות, כמו היכולת להתאים אישית פרמטרים, חומרה, להציג את סטטוס התהליך, יומנים ועוד.
קלט-פלט
- מקבלת כקלט טבלה ב-BigQuery או קובץ CSV מ-Cloud Storage.
- יוצר מודל Vertex AI כפלט.
- הפלט הזמני כולל נתונים סטטיסטיים של מערך הנתונים ופיצולים של מערך הנתונים.
מידע נוסף זמין במאמר תהליך עבודה טבלאי ל-AutoML מקצה לקצה.
תהליך עבודה טבלאי ל-TabNet
תהליך העבודה הטבלאי של TabNet הוא צינור עיבוד נתונים שאפשר להשתמש בו כדי לאמן מודלים של סיווג או רגרסיה. TabNet משתמש בתשומת לב רציפה כדי לבחור את התכונות שמהן יוסקו מסקנות בכל שלב של קבלת החלטה. השיטה הזו מקדמת פרשנות ולמידה יעילה יותר, כי יכולת הלמידה משמשת לתכונות הבולטות ביותר.
יתרונות
- המערכת בוחרת באופן אוטומטי את מרחב החיפוש המתאים של היפר-פרמטרים על סמך גודל מערך הנתונים, סוג ההיקש ותקציב האימון.
- משולב עם Vertex AI. המודל המאומן הוא מודל Vertex AI. אתם יכולים להריץ מסקנות באצווה או לפרוס את המודל למסקנות אונליין באופן מיידי.
- מספק יכולת מובנית לפרשנות של המודל. אתם יכולים לקבל תובנות לגבי התכונות שבהן נעשה שימוש ב-TabNet כדי לקבל את ההחלטה.
- תמיכה באימון GPU.
קלט-פלט
מקבלת כקלט טבלה ב-BigQuery או קובץ CSV מ-Cloud Storage, ומספקת כפלט מודל Vertex AI.
מידע נוסף זמין במאמר בנושא תהליך עבודה טבלאי עבור TabNet.
תהליכי עבודה טבלאיים ליצירת תחזיות
תהליך עבודה טבלאי ליצירת תחזיות
תהליך העבודה הטבלאי ליצירת תחזיות הוא צינור מלא למשימות של יצירת תחזיות. הוא דומה ל-AutoML API, אבל מאפשר לכם לבחור מה לשלוט ומה להפוך לאוטומטי. במקום אמצעי בקרה לכל הצינור, יש אמצעי בקרה לכל שלב בצינור. אמצעי הבקרה של הצינור כוללים:
- פיצול נתונים
- Feature engineering
- חיפוש אדריכלות
- אימון המודל
- שילוב מודלים
יתרונות
- תמיכה במערכי נתונים גדולים בגודל של עד 1TB ועם עד 200 עמודות.
- האפשרות הזו מאפשרת לשפר את היציבות ולקצר את זמן האימון על ידי הגבלת מרחב החיפוש של סוגי הארכיטקטורה או דילוג על חיפוש הארכיטקטורה.
- אפשר לשפר את מהירות האימון על ידי בחירה ידנית של החומרה שמשמשת לאימון ולחיפוש ארכיטקטורה.
- אפשר להקטין את גודל המודל ולשפר את זמן האחזור על ידי שינוי גודל האנסמבל.
- אפשר לבדוק כל רכיב בממשק גרפי רב-עוצמה של צינורות, שמאפשר לראות את טבלאות הנתונים שעברו טרנספורמציה, את ארכיטקטורות המודלים שנבדקו ועוד הרבה פרטים.
- כל רכיב מקבל גמישות ושקיפות מורחבות, כמו היכולת להתאים אישית פרמטרים, חומרה, סטטוס תהליך הצפייה, יומנים ועוד.
קלט-פלט
- מקבלת כקלט טבלה ב-BigQuery או קובץ CSV מ-Cloud Storage.
- יוצר מודל Vertex AI כפלט.
- הפלט הזמני כולל נתונים סטטיסטיים של מערך הנתונים ופיצולים של מערך הנתונים.
מידע נוסף זמין במאמר Tabular Workflow for Forecasting.
המאמרים הבאים
- מידע נוסף על תהליך עבודה של טבלאות ל-AutoML מקצה לקצה
- מידע נוסף על תהליך עבודה טבלאי ל-TabNet
- מידע על תהליך עבודה טבלאי ליצירת תחזיות
- מידע על הנדסת פיצ'רים (feature engineering)
- מידע על התמחור של Tabular Workflows