
בדף הזה מוסבר איך לאמן מודל חיזוי ממערך נתונים טבלאי באמצעות Tabular Workflow for Forecasting.
מידע על חשבונות השירות שמשמשים בתהליך העבודה הזה מופיע במאמר חשבונות שירות ל-Tabular Workflows.
אם אתם מקבלים שגיאת מכסה בזמן הפעלת Tabular Workflow for Forecasting, יכול להיות שתצטרכו לבקש מכסה גבוהה יותר. איך מנהלים את המכסות של Tabular Workflows
אי אפשר לייצא מודלים באמצעות תהליך העבודה של תחזיות בטבלה.
Workflow APIs
תהליך העבודה הזה משתמש בממשקי ה-API הבאים:
- Vertex AI
- Dataflow
- Compute Engine
- Cloud Storage
קבלת ה-URI של תוצאת כוונון ההיפרפרמטרים הקודמת
אם השלמתם בעבר הפעלה של תהליך עבודה טבלאי ליצירת תחזיות, תוכלו להשתמש בתוצאה של כוונון ההיפר-פרמטרים מההפעלה הקודמת כדי לחסוך זמן ומשאבים בתהליך ההכשרה. אפשר למצוא את התוצאה הקודמת של כוונון ההיפרפרמטרים באמצעות המסוף Google Cloud או באמצעות טעינה תוכנתית עם ה-API.
מסוף Google Cloud
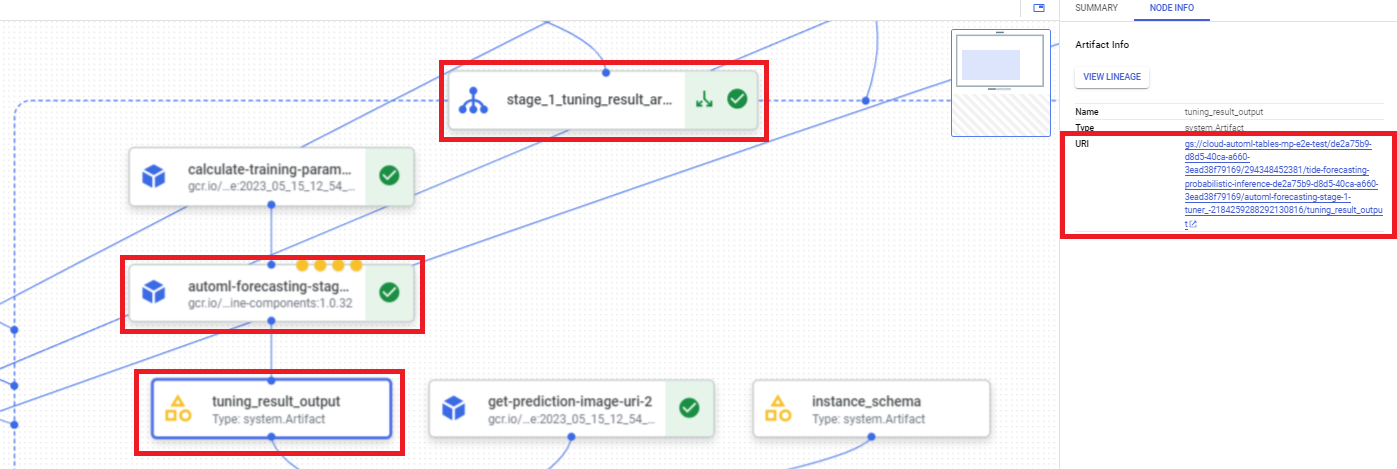
כדי למצוא את ה-URI של תוצאת אופטימיזציית ההיפר-פרמטרים באמצעות מסוף Google Cloud , פועלים לפי השלבים הבאים:
במסוף Google Cloud , בקטע Vertex AI, עוברים לדף Pipelines.
לוחצים על הכרטיסייה הפעלות.
בוחרים את ההרצה של צינור הנתונים שרוצים להשתמש בה.
בוחרים באפשרות הרחבת ארטיפקטים.
לוחצים על הרכיב exit-handler-1.
לוחצים על רכיב stage_1_tuning_result_artifact_uri_empty.
מחפשים את הרכיב automl-forecasting-stage-1-tuner.
לוחצים על הארטיפקט המשויך tuning_result_output.
בוחרים בכרטיסייה Node Info (פרטי הצומת).
מעתיקים את ה-URI לשימוש בשלב Train a model (אימון מודל).
API: Python
בדוגמת הקוד הבאה אפשר לראות איך טוענים את התוצאה של כוונון ההיפר-פרמטרים באמצעות ה-API. המשתנה job מתייחס להרצה הקודמת של צינור עיבוד הנתונים לאימון המודל.
def get_task_detail(
task_details: List[Dict[str, Any]], task_name: str
) -> List[Dict[str, Any]]:
for task_detail in task_details:
if task_detail.task_name == task_name:
return task_detail
pipeline_task_details = job.gca_resource.job_detail.task_details
stage_1_tuner_task = get_task_detail(
pipeline_task_details, "automl-forecasting-stage-1-tuner"
)
stage_1_tuning_result_artifact_uri = (
stage_1_tuner_task.outputs["tuning_result_output"].artifacts[0].uri
)
אימון מודל
בדוגמת הקוד הבאה מוצג איך מריצים צינור עיבוד נתונים לאימון מודל:
job = aiplatform.PipelineJob(
...
template_path=template_path,
parameter_values=parameter_values,
...
)
job.run(service_account=SERVICE_ACCOUNT)
הפרמטר האופציונלי service_account ב-job.run() מאפשר להגדיר את חשבון השירות של Vertex AI Pipelines לחשבון לפי בחירתכם.
Vertex AI תומך בשיטות הבאות לאימון המודל:
Time series Dense Encoder (TiDE). כדי להשתמש בשיטה הזו לאימון המודל, צריך להגדיר את צינור העיבוד ואת ערכי הפרמטרים באמצעות הפונקציה הבאה:
template_path, parameter_values = automl_forecasting_utils.get_time_series_dense_encoder_forecasting_pipeline_and_parameters(...)Temporal Fusion Transformer (TFT). כדי להשתמש בשיטה הזו לאימון המודל, צריך להגדיר את צינור העיבוד ואת ערכי הפרמטרים באמצעות הפונקציה הבאה:
template_path, parameter_values = automl_forecasting_utils.get_temporal_fusion_transformer_forecasting_pipeline_and_parameters(...)AutoML (L2L). כדי להשתמש בשיטה הזו לאימון המודל, צריך להגדיר את צינור העיבוד ואת ערכי הפרמטרים באמצעות הפונקציה הבאה:
template_path, parameter_values = automl_forecasting_utils.get_learn_to_learn_forecasting_pipeline_and_parameters(...)Seq2Seq+. כדי להשתמש בשיטה הזו לאימון המודל, צריך להגדיר את צינור העיבוד ואת ערכי הפרמטרים באמצעות הפונקציה הבאה:
template_path, parameter_values = automl_forecasting_utils.get_sequence_to_sequence_forecasting_pipeline_and_parameters(...)
מידע נוסף זמין במאמר בנושא שיטות לאימון מודלים.
נתוני האימון יכולים להיות קובץ CSV ב-Cloud Storage או טבלה ב-BigQuery.
זוהי קבוצת משנה של פרמטרים לאימון מודלים:
| שם הפרמטר | סוג | הגדרה |
|---|---|---|
optimization_objective |
String | כברירת מחדל, Vertex AI ממזער את שורש הטעות הריבועית הממוצעת (RMSE). אם רוצים להגדיר יעד אופטימיזציה אחר למודל התחזית, בוחרים אחת מהאפשרויות שמופיעות בקטע יעדי אופטימיזציה למודלים של תחזיות. אם בוחרים למזער את הפסד הכמותון, צריך גם לציין ערך ל-quantiles. |
enable_probabilistic_inference |
בוליאני | אם הערך הוא true, מודלים של Vertex AI את התפלגות ההסתברות של התחזית. הסקת מסקנות הסתברותית יכולה לשפר את איכות המודל על ידי טיפול בנתונים רועשים וכימות של אי הוודאות. אם מציינים את quantiles, Vertex AI מחזיר גם את הכמויות של ההתפלגות. הסקת מסקנות הסתברותית תואמת רק לשיטות ההדרכה Time series Dense Encoder (TiDE) ו-AutoML (L2L). הסקת מסקנות הסתברותית לא תואמת ליעד האופטימיזציה minimize-quantile-loss. |
quantiles |
List[float] | הקוונטילים שבהם יש להשתמש עבור minimize-quantile-loss יעד האופטימיזציה וההסקה ההסתברותית. צריך לספק רשימה של עד חמישה מספרים ייחודיים בין 0 ל-1, לא כולל. |
time_column |
String | עמודת הזמן. מידע נוסף על דרישות מבנה הנתונים |
time_series_identifier_columns |
List[str] | עמודות המזהה של סדרת הזמנים. מידע נוסף על דרישות מבנה הנתונים |
weight_column |
String | (אופציונלי) עמודת המשקל. מידע נוסף על הוספת משקלים לנתוני האימון |
time_series_attribute_columns |
List[str] | (אופציונלי) השם או השמות של העמודות שמכילות מאפיינים של סדרת זמן. מידע נוסף מפורט במאמר סוג התכונה והזמינות שלה בתחזית. |
available_at_forecast_columns |
List[str] | (אופציונלי) השם או השמות של עמודות המשתנים המשולבים שהערך שלהם ידוע בזמן התחזית. מידע נוסף מפורט במאמר סוג התכונה והזמינות שלה בתחזית. |
unavailable_at_forecast_columns |
List[str] | (אופציונלי) השם או השמות של עמודות המשתנים המסבירים שהערך שלהם לא ידוע בזמן התחזית. מידע נוסף מפורט במאמר סוג התכונה והזמינות שלה בתחזית. |
forecast_horizon |
מספר שלם | (אופציונלי) טווח התחזית קובע עד כמה רחוק בעתיד המודל יחזה את ערך היעד לכל שורה של נתוני הסקה. מידע נוסף זמין במאמר אופק התחזית, חלון ההקשר וחלון התחזית. |
context_window |
מספר שלם | (אופציונלי) חלון ההקשר מגדיר כמה זמן אחורה המודל בודק במהלך האימון (ובתחזיות). במילים אחרות, לגבי כל נקודת נתונים לאימון, חלון ההקשר קובע עד כמה המודל יחזור אחורה כדי לחפש דפוסים לחיזוי. מידע נוסף זמין במאמר אופק התחזית, חלון ההקשר וחלון התחזית. |
window_max_count |
מספר שלם | (אופציונלי) מערכת Vertex AI יוצרת חלונות של תחזיות מנתוני הקלט באמצעות אסטרטגיה של חלון נע. שיטת ברירת המחדל היא ספירה. ערך ברירת המחדל של המספר המקסימלי של חלונות הוא 100,000,000. מגדירים את הפרמטר הזה כדי לספק ערך מותאם אישית למספר המקסימלי של החלונות. מידע נוסף על שיטות בידינג עם חלון זמן מתגלגל |
window_stride_length |
מספר שלם | (אופציונלי) מערכת Vertex AI יוצרת חלונות של תחזיות מנתוני הקלט באמצעות אסטרטגיה של חלון נע. כדי לבחור את שיטת הצעד, מגדירים את הפרמטר הזה לערך של אורך פסיעה. מידע נוסף על שיטות בידינג עם חלון זמן מתגלגל |
window_predefined_column |
String | (אופציונלי) מערכת Vertex AI יוצרת חלונות של תחזיות מנתוני הקלט באמצעות אסטרטגיה של חלון נע. כדי לבחור את שיטת הבידינג Column, מגדירים את הפרמטר הזה לשם העמודה עם הערכים True או False. מידע נוסף על שיטות בידינג עם חלון זמן מתגלגל |
holiday_regions |
List[str] | (אופציונלי) אתם יכולים לבחור אזור גיאוגרפי אחד או יותר כדי להפעיל מודלים של השפעות חגים. במהלך האימון, מערכת Vertex AI יוצרת במודל תכונות קטגוריות של חגים על סמך התאריך מ-time_column והאזורים הגיאוגרפיים שצוינו. כברירת מחדל, בניית מודלים של השפעות של חגים מושבתת. מידע נוסף על אזורים עם חגים |
predefined_split_key |
String | (אופציונלי) כברירת מחדל, מערכת Vertex AI משתמשת באלגוריתם של פיצול כרונולוגי כדי להפריד את נתוני התחזית לשלושה פיצולים של נתונים. אם רוצים לשלוט בשורות של נתוני האימון שמשמשות לכל פיצול, צריך לספק את שם העמודה שמכילה את ערכי פיצול הנתונים (TRAIN, VALIDATION, TEST). מידע נוסף זמין במאמר בנושא פיצול נתונים לצורך חיזוי. |
training_fraction |
Float | (אופציונלי) כברירת מחדל, מערכת Vertex AI משתמשת באלגוריתם של פיצול כרונולוגי כדי להפריד את נתוני התחזית לשלושה פיצולים של נתונים. 80% מהנתונים מוקצים לקבוצת נתונים לאימון, 10% מוקצים לפיצול האימות ו-10% מוקצים לפיצול הבדיקה. מגדירים את הפרמטר הזה אם רוצים להתאים אישית את החלק היחסי של הנתונים שמוקצה לקבוצת נתונים לאימון. מידע נוסף זמין במאמר פיצול נתונים לצורך תחזיות. |
validation_fraction |
Float | (אופציונלי) כברירת מחדל, מערכת Vertex AI משתמשת באלגוריתם של פיצול כרונולוגי כדי להפריד את נתוני התחזית לשלושה פיצולים של נתונים. 80% מהנתונים מוקצים לקבוצת נתונים לאימון, 10% מוקצים לפיצול האימות ו-10% מוקצים לפיצול הבדיקה. מגדירים את הפרמטר הזה אם רוצים להתאים אישית את החלק היחסי של הנתונים שמוקצה לקבוצת נתונים לתיקוף. מידע נוסף זמין במאמר פיצול נתונים לצורך תחזיות. |
test_fraction |
Float | (אופציונלי) כברירת מחדל, מערכת Vertex AI משתמשת באלגוריתם של פיצול כרונולוגי כדי להפריד את נתוני התחזית לשלושה פיצולים של נתונים. 80% מהנתונים מוקצים לקבוצת נתונים לאימון, 10% מוקצים לפיצול האימות ו-10% מוקצים לפיצול הבדיקה. מגדירים את הפרמטר הזה אם רוצים להתאים אישית את החלק היחסי של הנתונים שמוקצה לקבוצת נתונים לבדיקה. מידע נוסף זמין במאמר פיצול נתונים לצורך תחזיות. |
data_source_csv_filenames |
String | URI של קובץ CSV שמאוחסן ב-Cloud Storage. |
data_source_bigquery_table_path |
String | כתובת URI של טבלה ב-BigQuery. |
dataflow_service_account |
String | (אופציונלי) חשבון שירות מותאם אישית להרצת משימות Dataflow. אפשר להגדיר את עבודת Dataflow כך שתשתמש בכתובות IP פרטיות וברשת משנה ספציפית של VPC. הפרמטר הזה משמש כשינוי של חשבון השירות שמוגדר כברירת מחדל של עובד Dataflow. |
run_evaluation |
בוליאני | אם הערך הוא True, Vertex AI מעריך את המודל המשולב בחלוקת הבדיקה. |
evaluated_examples_bigquery_path |
String | הנתיב של מערך הנתונים ב-BigQuery שבו נעשה שימוש במהלך הערכת המודל. מערך הנתונים משמש כיעד לדוגמאות החזויות. אם הפרמטר run_evaluation מוגדר לערך True, צריך להגדיר את ערך הפרמטר בפורמט הבא: bq://[PROJECT].[DATASET]. |
טרנספורמציות
אפשר לספק מיפוי מילוני של פתרונות אוטומטיים או פתרונות שמתקבלים מהקלדה לעמודות של תכונות. הסוגים הנתמכים הם: אוטומטי, מספרי, קטגורי, טקסט וחותמת זמן.
| שם הפרמטר | סוג | הגדרה |
|---|---|---|
transformations |
Dict[str, List[str]] | מיפוי מילוני של פתרונות אוטומטיים או פתרונות לפי סוג |
הקוד הבא מספק פונקציית עזר לאכלוס הפרמטר transformations. בנוסף, אפשר לראות איך משתמשים בפונקציה הזו כדי להחיל טרנספורמציות אוטומטיות על קבוצת עמודות שמוגדרת על ידי משתנה features.
def generate_transformation(
auto_column_names: Optional[List[str]]=None,
numeric_column_names: Optional[List[str]]=None,
categorical_column_names: Optional[List[str]]=None,
text_column_names: Optional[List[str]]=None,
timestamp_column_names: Optional[List[str]]=None,
) -> List[Dict[str, Any]]:
if auto_column_names is None:
auto_column_names = []
if numeric_column_names is None:
numeric_column_names = []
if categorical_column_names is None:
categorical_column_names = []
if text_column_names is None:
text_column_names = []
if timestamp_column_names is None:
timestamp_column_names = []
return {
"auto": auto_column_names,
"numeric": numeric_column_names,
"categorical": categorical_column_names,
"text": text_column_names,
"timestamp": timestamp_column_names,
}
transformations = generate_transformation(auto_column_names=features)
אפשרויות להתאמה אישית של תהליכי עבודה
אפשר להתאים אישית את תהליך העבודה הטבלאי לחיזוי על ידי הגדרת ערכי ארגומנטים שמועברים במהלך הגדרת צינור הנתונים. אפשר להתאים אישית את תהליך העבודה בדרכים הבאות:
- הגדרת ציוד ואביזרים
- דילוג על חיפוש הארכיטקטורה
הגדרת החומרה
פרמטר האימון הבא של המודל מאפשר להגדיר את סוגי המכונות ואת מספר המכונות לאימון. האפשרות הזו מתאימה אם יש לכם מערך נתונים גדול ואתם רוצים לבצע אופטימיזציה של חומרת המכונה בהתאם.
| שם הפרמטר | סוג | הגדרה |
|---|---|---|
stage_1_tuner_worker_pool_specs_override |
Dict[String, Any] | (אופציונלי) הגדרה בהתאמה אישית של סוגי המכונות ומספר המכונות לאימון. הפרמטר הזה מגדיר את רכיב automl-forecasting-stage-1-tuner בצינור עיבוד הנתונים. |
הקוד הבא מדגים איך להגדיר את n1-standard-8 סוג המכונה עבור צומת ה-chief של TensorFlow ואת n1-standard-4 סוג המכונה עבור צומת ה-evaluator של TensorFlow:
worker_pool_specs_override = [
{"machine_spec": {"machine_type": "n1-standard-8"}}, # override for TF chief node
{}, # override for TF worker node, since it's not used, leave it empty
{}, # override for TF ps node, since it's not used, leave it empty
{
"machine_spec": {
"machine_type": "n1-standard-4" # override for TF evaluator node
}
}
]
דילוג על חיפוש ארכיטקטורה
הפרמטר הבא של אימון המודל מאפשר להריץ את צינור העיבוד בלי חיפוש הארכיטקטורה, ולספק במקום זאת קבוצה של היפרפרמטרים מהרצת צינור עיבוד קודמת.
| שם הפרמטר | סוג | הגדרה |
|---|---|---|
stage_1_tuning_result_artifact_uri |
String | (אופציונלי) כתובת ה-URI של תוצאת כוונון ההיפרפרמטרים מהרצת צינור קודמת. |
המאמרים הבאים
- מידע על הסקת מסקנות באצווה לגבי מודלים של תחזיות.
- מידע נוסף על התמחור של אימון מודלים