
Vertex AI מספקת שתי אפשרויות לחיזוי ערכים עתידיים באמצעות מודל החיזוי שאומן: מסקנות אונליין ומסקנות באצווה.
הסקת מסקנות אונליין היא בקשה סנכרונית. משתמשים בהסקת מסקנות אונליין כשמגישים בקשות בתגובה לקלט של אפליקציה או במצבים אחרים שבהם נדרשת הסקת מסקנות בזמן אמת.
בקשה להסקת מסקנות באצווה היא בקשה לא סנכרונית. משתמשים בהסקת מסקנות באצווה כשלא נדרשת תשובה מיידית ורוצים לעבד נתונים שנצברו באמצעות בקשה אחת.
בדף הזה מוסבר איך להשתמש בהסקת מסקנות באצווה כדי לחזות ערכים עתידיים. כדי ללמוד איך לחזות ערכים באמצעות הסקה אונליין, אפשר לעיין במאמר קבלת הסקות אונליין למודל תחזית.
אפשר לבקש מסקנות של קבוצות נתונים ישירות ממקור המידע של המודל.
אתם יכולים לבקש הסבר על ההסקה (שנקרא גם שיוך תכונות) כדי לראות איך המודל הגיע להסקה. ערכי החשיבות של התכונות המקומיות מציינים את מידת התרומה של כל תכונה לתוצאת ההסקה. סקירה כללית של המושגים מופיעה במאמר שיוך תכונות לחיזוי.
למידע על תמחור של מסקנות באצווה, אפשר לעיין במאמר בנושא תמחור של זרימות עבודה טבלאיות.
לפני שמתחילים
לפני ששולחים בקשת הסקה באצווה, צריך קודם לאמן מודל.
נתוני קלט
נתוני הקלט לבקשות של הסקת מסקנות באצווה הם הנתונים שבהם המודל משתמש כדי ליצור תחזיות. אפשר לספק נתוני קלט באחד משני פורמטים:
- אובייקטים של CSV ב-Cloud Storage
- טבלאות ב-BigQuery
מומלץ להשתמש באותו פורמט לנתוני הקלט כמו זה שבו השתמשתם לאימון המודל. לדוגמה, אם אימנתם את המודל באמצעות נתונים ב-BigQuery, מומלץ להשתמש בטבלה ב-BigQuery כקלט להסקת מסקנות באצווה. מכיוון שמערכת Vertex AI מתייחסת לכל השדות להזנת קלט בפורמט CSV כמחרוזות, ערבוב של פורמטים של נתוני אימון ונתוני קלט עלול לגרום לשגיאות.
מקור הנתונים צריך להכיל נתונים בפורמט טבלאי שכוללים את כל העמודות, בכל סדר, ששימשו לאימון המודל. אפשר לכלול עמודות שלא היו בנתוני האימון, או שהיו בנתוני האימון אבל לא נכללו בשימוש לצורך אימון. העמודות הנוספות האלה נכללות בפלט אבל לא משפיעות על תוצאות התחזית.
הדרישות לגבי נתוני הקלט
הקלט למודלים של תחזיות צריך לעמוד בדרישות הבאות:
- כל הערכים בעמודת השעה חייבים להיות נוכחים ותקינים.
- כל העמודות שמשמשות בבקשת ההסקה צריכות להיות בנתוני הקלט. אם העמודות ריקות או לא קיימות, מערכת Vertex AI מוסיפה ריפוד לנתונים באופן אוטומטי.
- תדירות הנתונים של נתוני הקלט ונתוני האימון צריכה להיות זהה. אם חסרות שורות בסדרת הזמן, צריך להוסיף אותן באופן ידני בהתאם לידע המתאים בתחום.
- סדרות זמן עם חותמות זמן כפולות מוסרות מההסקות. כדי לכלול אותם, צריך להסיר את חותמות הזמן הכפולות.
- מספקים נתונים היסטוריים לכל סדרת זמן שרוצים לחזות. כדי לקבל תחזיות מדויקות ככל האפשר, כמות הנתונים צריכה להיות שווה לחלון ההקשר, שמוגדר במהלך אימון המודל. לדוגמה, אם חלון ההקשר הוא 14 ימים, צריך לספק נתונים היסטוריים של 14 ימים לפחות. אם מספקים פחות נתונים, מערכת Vertex AI מוסיפה לנתונים ערכים ריקים.
- התחזית מתחילה בשורה הראשונה של סדרת זמן (מסודרת לפי זמן)
עם ערך Null בעמודת היעד. ערך ה-null חייב להיות רציף בסדרת הזמן. לדוגמה, אם העמודה של היעד מסודרת לפי זמן, אי אפשר להזין ערכים כמו
1,2,null,3,4,null,nullלסדרת זמן אחת. בקובצי CSV, Vertex AI מתייחס למחרוזת ריקה כאל null, וב-BigQuery יש תמיכה מובנית בערכי null.
טבלת BigQuery
אם בוחרים טבלה ב-BigQuery כקלט, צריך לוודא את הדברים הבאים:
- הגודל של טבלאות במקור נתונים של BigQuery לא יכול להיות גדול מ-100GB.
- אם הטבלה נמצאת בפרויקט אחר, צריך להעניק לחשבון השירות של Vertex AI את התפקיד
BigQuery Data Editorבפרויקט הזה.
קובץ CSV
אם בוחרים אובייקט CSV ב-Cloud Storage כקלט, צריך לוודא את הדברים הבאים:
- מקור הנתונים חייב להתחיל בשורת כותרת עם שמות העמודות.
- גודל כל אובייקט של מקור נתונים לא יכול להיות גדול מ-10GB. אפשר לכלול כמה קבצים, עד לגודל מקסימלי של 100GB.
- אם קטגוריית Cloud Storage נמצאת בפרויקט אחר, צריך להקצות את התפקיד
Storage Object Creatorלחשבון השירות של Vertex AI בפרויקט הזה. - חובה להקיף את כל המחרוזות במירכאות כפולות (").
פורמט פלט
פורמט הפלט של בקשת ההסקה באצווה לא צריך להיות זהה לפורמט הקלט. לדוגמה, אם משתמשים בטבלה ב-BigQuery כקלט, אפשר לייצא את תוצאות התחזית לאובייקט CSV ב-Cloud Storage.
שליחת בקשת הסקה באצווה למודל
כדי לשלוח בקשות להסקת מסקנות באצווה, אפשר להשתמש במסוף Google Cloud או ב-Vertex AI API. מקור נתוני הקלט יכול להיות אובייקטים מסוג CSV שמאוחסנים בקטגוריה של Cloud Storage או בטבלאות של BigQuery. בהתאם לכמות הנתונים שאתם שולחים כקלט, יכול להיות שיעבור זמן עד שמשימת הסקת מסקנות בכמות גדולה תסתיים.
מסוף Google Cloud
משתמשים במסוף Google Cloud כדי לבקש הסקה באצווה.
- במסוף Google Cloud , בקטע Vertex AI, עוברים לדף Batch inferences.
- לוחצים על Create (יצירה) כדי לפתוח את החלון New batch inference (הסקת מסקנות חדשה באצווה).
- בקטע Define your batch inference (הגדרת מסקנות אצווה), מבצעים את השלבים הבאים:
- מזינים שם להסקת המסקנות באצווה.
- בקטע שם המודל, בוחרים את שם המודל שרוצים להשתמש בו להסקת המסקנות באצווה הזו.
- בשדה Version (גרסה), בוחרים את גרסת המודל.
- בקטע Select source (בחירת מקור), בוחרים אם נתוני הקלט של המקור הם קובץ CSV ב-Cloud Storage או טבלה ב-BigQuery.
- עבור קובצי CSV, מציינים את המיקום ב-Cloud Storage שבו נמצא קובץ הקלט CSV.
- בטבלאות BigQuery, מציינים את מזהה הפרויקט שבו נמצאת הטבלה, את מזהה מערך הנתונים ב-BigQuery ואת מזהה הטבלה או התצוגה ב-BigQuery.
- בקטע Batch inference output (פלט של הסקת מסקנות באצווה), בוחרים באפשרות CSV או BigQuery.
- במקרה של CSV, מציינים את קטגוריה של Cloud Storage שבה Vertex AI מאחסן את הפלט.
- ב-BigQuery, אפשר לציין מזהה פרויקט או מערך נתונים קיים:
- כדי לציין את מזהה הפרויקט, מזינים את מזהה הפרויקט בשדה מזהה פרויקט ב-Google Cloud. Vertex AI יוצר בשבילכם מערך נתונים חדש של פלט.
- כדי לציין מערך נתונים קיים, מזינים את הנתיב שלו ב-BigQuery בשדה מזהה הפרויקט ב-Google Cloud, למשל
bq://projectid.datasetid.
- אופציונלי. אם יעד הפלט הוא BigQuery או JSONL ב-Cloud Storage, אפשר להפעיל שיוך תכונות בנוסף למסקנות. כדי לעשות את זה, בוחרים באפשרות הפעלת שיוך תכונות למודל הזה. Feature attributions לא נתמך עבור CSV ב-Cloud Storage. מידע נוסף
- אופציונלי: ניתוח של מעקב אחרי מודלים של מסקנות אצווה זמין בתצוגה מקדימה. במאמר דרישות מוקדמות מוסבר איך מוסיפים הגדרה של זיהוי הטיה למשימת הסקת מסקנות באצווה.
- לוחצים על המתג כדי להפעיל את האפשרות הפעלת מעקב אחר המודל עבור הסקת המסקנות הזו.
- בוחרים מקור נתוני אימון. מזינים את נתיב הנתונים או המיקום של מקור נתוני האימון שבחרתם.
- אופציונלי: בקטע ערכי סף להתראות, מציינים את ערכי הסף להפעלת ההתראות.
- בקטע Notification emails (התראות באימייל), מזינים כתובת אימייל אחת או יותר שמופרדות בפסיקים כדי לקבל התראות כשמודל חורג מערך הסף להתראה.
- אופציונלי: בערוצי התראות, מוסיפים ערוצים של Cloud Monitoring כדי לקבל התראות כשמודל חורג מסף ההתראה. אפשר לבחור ערוצים קיימים של Cloud Monitoring או ליצור ערוץ חדש בלחיצה על Manage notification channels. המסוף תומך בערוצי התראות של PagerDuty, Slack ו-Pub/Sub.
- לוחצים על יצירה.
API : BigQuery
REST
משתמשים ב-method batchPredictionJobs.create כדי לבקש הסקה של נתונים בכמות גדולה.
לפני שמשתמשים בנתוני הבקשה, צריך להחליף את הנתונים הבאים:
- LOCATION_ID: האזור שבו המודל מאוחסן ועבודת ההסקה באצווה מבוצעת. לדוגמה,
us-central1. - PROJECT_ID: מזהה הפרויקט
- BATCH_JOB_NAME: השם המוצג של המשימה באצווה
- MODEL_ID: המזהה של המודל שבו רוצים להשתמש כדי להסיק מסקנות
-
INPUT_URI: הפניה למקור הנתונים של BigQuery. בטופס:
bq://bqprojectId.bqDatasetId.bqTableId
-
OUTPUT_URI: הפניה ליעד ב-BigQuery (המקום שבו נכתבות ההסקות). מציינים את מזהה הפרויקט ואופציונלית מזהה של מערך נתונים קיים. צריך להשתמש בטופס הבא:
bq://bqprojectId.bqDatasetId
bq://bqprojectId
- GENERATE_EXPLANATION: ערך ברירת המחדל הוא false. מגדירים את הערך true כדי להפעיל את שיוך התכונות. מידע נוסף זמין במאמר בנושא שיוך תכונות לתחזיות.
ה-method של ה-HTTP וכתובת ה-URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs
גוף בקשת JSON:
{
"displayName": "BATCH_JOB_NAME",
"model": "projects/PROJECT_ID/locations/LOCATION_ID/models/MODEL_ID",
"inputConfig": {
"instancesFormat": "bigquery",
"bigquerySource": {
"inputUri": "INPUT_URI"
}
},
"outputConfig": {
"predictionsFormat": "bigquery",
"bigqueryDestination": {
"outputUri": "OUTPUT_URI"
}
},
"generate_explanation": GENERATE_EXPLANATION
}
כדי לשלוח את הבקשה עליכם לבחור אחת מהאפשרויות הבאות:
curl
שומרים את גוף הבקשה בקובץ בשם request.json ומריצים את הפקודה הבאה:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs"
PowerShell
שומרים את גוף הבקשה בקובץ בשם request.json ומריצים את הפקודה הבאה:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs" | Select-Object -Expand Content
אתם אמורים לקבל תגובת JSON שדומה לזו:
{
"name": "projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs/67890",
"displayName": "batch_job_1 202005291958",
"model": "projects/12345/locations/us-central1/models/5678",
"state": "JOB_STATE_PENDING",
"inputConfig": {
"instancesFormat": "bigquery",
"bigquerySource": {
"inputUri": "INPUT_URI"
}
},
"outputConfig": {
"predictionsFormat": "bigquery",
"bigqueryDestination": {
"outputUri": bq://12345
}
},
"dedicatedResources": {
"machineSpec": {
"machineType": "n1-standard-32",
"acceleratorCount": "0"
},
"startingReplicaCount": 2,
"maxReplicaCount": 6
},
"manualBatchTuningParameters": {
"batchSize": 4
},
"outputInfo": {
"bigqueryOutputDataset": "bq://12345.reg_model_2020_10_02_06_04
}
"state": "JOB_STATE_PENDING",
"createTime": "2020-09-30T02:58:44.341643Z",
"updateTime": "2020-09-30T02:58:44.341643Z",
}
Java
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Javaהוראות ההגדרה במאמר Vertex AI quickstart using client libraries. מידע נוסף מופיע במאמרי העזרה של Vertex AI Java API.
כדי לבצע אימות ב-Vertex AI, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
בדוגמה הבאה, מחליפים את INSTANCES_FORMAT ואת PREDICTIONS_FORMAT ב-bigquery. כדי ללמוד איך להחליף את שאר placeholders, אפשר לעיין בכרטיסייה REST & CMD LINE בקטע הזה.Python
במאמר התקנת Vertex AI SDK ל-Python מוסבר איך להתקין או לעדכן את Vertex AI SDK ל-Python. מידע נוסף מופיע ב מאמרי העזרה של Python API.
API : Cloud Storage
REST
משתמשים ב-method batchPredictionJobs.create כדי לבקש הסקה של נתונים בכמות גדולה.
לפני שמשתמשים בנתוני הבקשה, צריך להחליף את הנתונים הבאים:
- LOCATION_ID: האזור שבו המודל מאוחסן ועבודת ההסקה באצווה מבוצעת. לדוגמה,
us-central1. - PROJECT_ID:
- BATCH_JOB_NAME: השם המוצג של המשימה באצווה
- MODEL_ID: המזהה של המודל שבו רוצים להשתמש כדי להסיק מסקנות
-
URI: נתיבים (URI) לקטגוריות של Cloud Storage שמכילות את נתוני האימון.
יכול להיות שיש יותר מאחת. כל מזהה URI מופיע בפורמט:
gs://bucketName/pathToFileName
-
OUTPUT_URI_PREFIX: הנתיב ליעד ב-Cloud Storage שבו ייכתבו ההסקות. Vertex AI כותב מסקנות של אצווה לספריית משנה עם חותמת זמן של הנתיב הזה. מגדירים את הערך הזה כמחרוזת בפורמט הבא:
gs://bucketName/pathToOutputDirectory
- GENERATE_EXPLANATION: ערך ברירת המחדל הוא false. מגדירים את הערך true כדי להפעיל את שיוך התכונות. האפשרות הזו זמינה רק אם יעד הפלט הוא JSONL. ייחוס תכונות לא נתמך לקובצי CSV ב-Cloud Storage. מידע נוסף זמין במאמר בנושא שיוך תכונות לתחזיות.
ה-method של ה-HTTP וכתובת ה-URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs
גוף בקשת JSON:
{
"displayName": "BATCH_JOB_NAME",
"model": "projects/PROJECT_ID/locations/LOCATION_ID/models/MODEL_ID",
"inputConfig": {
"instancesFormat": "csv",
"gcsSource": {
"uris": [
URI1,...
]
},
},
"outputConfig": {
"predictionsFormat": "csv",
"gcsDestination": {
"outputUriPrefix": "OUTPUT_URI_PREFIX"
}
},
"generate_explanation": GENERATE_EXPLANATION
}
כדי לשלוח את הבקשה עליכם לבחור אחת מהאפשרויות הבאות:
curl
שומרים את גוף הבקשה בקובץ בשם request.json ומריצים את הפקודה הבאה:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs"
PowerShell
שומרים את גוף הבקשה בקובץ בשם request.json ומריצים את הפקודה הבאה:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs" | Select-Object -Expand Content
אתם אמורים לקבל תגובת JSON שדומה לזו:
{
"name": "projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs/67890",
"displayName": "batch_job_1 202005291958",
"model": "projects/12345/locations/us-central1/models/5678",
"state": "JOB_STATE_PENDING",
"inputConfig": {
"instancesFormat": "csv",
"gcsSource": {
"uris": [
"gs://bp_bucket/reg_mode_test"
]
}
},
"outputConfig": {
"predictionsFormat": "csv",
"gcsDestination": {
"outputUriPrefix": "OUTPUT_URI_PREFIX"
}
},
"dedicatedResources": {
"machineSpec": {
"machineType": "n1-standard-32",
"acceleratorCount": "0"
},
"startingReplicaCount": 2,
"maxReplicaCount": 6
}
"outputInfo": {
"gcsOutputDataset": "OUTPUT_URI_PREFIX/prediction-batch_job_1 202005291958-2020-09-30T02:58:44.341643Z"
}
"state": "JOB_STATE_PENDING",
"createTime": "2020-09-30T02:58:44.341643Z",
"updateTime": "2020-09-30T02:58:44.341643Z",
}
Python
במאמר התקנת Vertex AI SDK ל-Python מוסבר איך להתקין או לעדכן את Vertex AI SDK ל-Python. מידע נוסף מופיע ב מאמרי העזרה של Python API.
אחזור תוצאות של הסקה בקבוצות
מערכת Vertex AI שולחת את הפלט של מסקנות אצווה ליעד שציינתם, שיכול להיות BigQuery או Cloud Storage.
אין תמיכה בפלט של Cloud Storage לשיוך תכונות.
BigQuery
מערך נתונים של פלט
אם אתם משתמשים ב-BigQuery, הפלט של הסקת מסקנות באצווה מאוחסן במערך נתונים של פלט. אם סיפקתם מערך נתונים ל-Vertex AI, השם של מערך הנתונים (BQ_DATASET_NAME) הוא השם שסיפקתם קודם. אם לא סיפקתם מערך נתונים של פלט, מערכת Vertex AI יצרה בשבילכם מערך כזה. כדי למצוא את השם שלו (BQ_DATASET_NAME), צריך לבצע את השלבים הבאים:
- במסוף Google Cloud , נכנסים לדף Batch inferences של Vertex AI.
- בוחרים את ההסקה שיצרתם.
-
מערך הנתונים של הפלט מופיע במיקום הייצוא. שם מערך הנתונים מופיע בפורמט הבא:
prediction_MODEL_NAME_TIMESTAMP
טבלאות פלט
מערך הנתונים של הפלט מכיל אחת או יותר משלוש טבלאות הפלט הבאות:
-
טבלת היקש
הטבלה הזו מכילה שורה לכל שורה בנתוני הקלט שבהם נדרשה הסקה (כלומר, שבהם TARGET_COLUMN_NAME = null). לדוגמה, אם הקלט שלכם כלל 14 ערכים ריקים בעמודת היעד (למשל, מכירות ל-14 הימים הבאים), בקשת ההסקה תחזיר 14 שורות, עם מספר המכירות לכל יום. אם בקשת ההסקה חורגת מאופק החיזוי של המודל, Vertex AI מחזיר רק הסקות עד אופק החיזוי.
-
טבלת אימות שגיאות
בטבלה הזו יש שורה לכל שגיאה לא קריטית שנתקלה בה במהלך שלב צבירת הנתונים שמתרחש לפני היקש באצווה. כל שגיאה לא קריטית תואמת לשורה בנתוני הקלט ש-Vertex AI לא הצליח להחזיר לגביה תחזית.
-
טבלת השגיאות
הטבלה הזו מכילה שורה לכל שגיאה לא קריטית שנתקלה בה במהלך הסקת מסקנות בקבוצה. כל שגיאה לא קריטית מתאימה לשורה בנתוני הקלט שלא ניתן היה להחזיר לגביה תחזית ב-Vertex AI.
טבלת חיזויים
שם הטבלה (BQ_PREDICTIONS_TABLE_NAME) נוצר על ידי הוספת הקידומת `predictions_` לחותמת הזמן של תחילת העבודה של משימת ההסקה באצווה: predictions_TIMESTAMP
כדי לאחזר את טבלת ההסקות:
-
במסוף, נכנסים לדף BigQuery.
כניסה ל-BigQuery -
מריצים את השאילתה הבאה:
SELECT * FROM BQ_DATASET_NAME.BQ_PREDICTIONS_TABLE_NAME
מסקנות מאוחסנות ב-Vertex AI בעמודה predicted_TARGET_COLUMN_NAME.value.
אם אימנתם מודל עם Temporal Fusion Transformer (TFT), תוכלו למצוא את פלט הפרשנות של TFT בעמודה predicted_TARGET_COLUMN_NAME.tft_feature_importance.
העמודה הזו מחולקת עוד יותר לקטגוריות הבאות:
-
context_columns: תכונות חיזוי שהערכים של חלון ההקשר שלהן משמשים כקלט למקודד הזיכרון ארוך הטווח לטווח קצר (LSTM) של TFT. -
context_weights: המשקלים של חשיבות התכונות שמשויכים לכל אחד מהערכים שלcontext_columnsעבור המופע החזוי. -
horizon_columns: תכונות חיזוי שהערכים של הטווח לחיזוי שלהן משמשים כקלט למפענח של זיכרון ארוך לטווח קצר (LSTM) של TFT. -
horizon_weights: המשקלים של חשיבות התכונות שמשויכים לכל אחד מהערכים שלhorizon_columnsעבור המופע החזוי. -
attribute_columns: תכונות של תחזיות שהן בלתי תלויות בזמן. -
attribute_weights: המשקלים שמשויכים לכל אחד מהמאפייניםattribute_columns.
אם המודל
מותאם לחישוב הפסד קוונטילי וקבוצת הקוונטילים כוללת את החציון,
predicted_TARGET_COLUMN_NAME.value הוא ערך ההסקה בחציון. אחרת, predicted_TARGET_COLUMN_NAME.value הוא ערך ההסקה באחוזון הנמוך ביותר בקבוצה. לדוגמה, אם קבוצת הכמויות שלכם היא [0.1, 0.5, 0.9], אז value הוא ההסקה לגבי הכמות 0.5.
אם קבוצת הכמויות היא [0.1, 0.9], אז value היא ההסקה לגבי הכמות 0.1.
בנוסף, מערכת Vertex AI מאחסנת ערכים של קוונטילים והסקות בעמודות הבאות:
-
predicted_TARGET_COLUMN_NAME.quantile_values: ערכי הכמויות, שמוגדרים במהלך אימון המודל. לדוגמה, אלה יכולים להיות0.1,0.5ו-0.9. -
predicted_TARGET_COLUMN_NAME.quantile_predictions: ערכי ההסקה שמשויכים לערכי הכמותון.
אם המודל משתמש בהסקה הסתברותית,
predicted_TARGET_COLUMN_NAME.value מכיל את המינימייזר של
יעד האופטימיזציה. לדוגמה, אם יעד האופטימיזציה הוא minimize-rmse,
הערך של predicted_TARGET_COLUMN_NAME.value הוא הערך הממוצע. אם הוא minimize-mae, predicted_TARGET_COLUMN_NAME.value מכיל את ערך החציון.
אם המודל שלכם משתמש בהסקה הסתברותית עם קוונטילים, מערכת Vertex AI מאחסנת את ערכי הקוונטילים ואת ההסקות בעמודות הבאות:
-
predicted_TARGET_COLUMN_NAME.quantile_values: ערכי הכמויות, שמוגדרים במהלך אימון המודל. לדוגמה, אלה יכולים להיות0.1,0.5ו-0.9. -
predicted_TARGET_COLUMN_NAME.quantile_predictions: ערכי ההסקה שמשויכים לערכי הכמותון.
אם הפעלתם שיוך תכונות, תוכלו למצוא אותן גם בטבלת ההסקה. כדי לגשת לשיוכים של תכונה מסוימת BQ_FEATURE_NAME, מריצים את השאילתה הבאה:
SELECT explanation.attributions[OFFSET(0)].featureAttributions.BQ_FEATURE_NAME FROM BQ_DATASET_NAME.BQ_PREDICTIONS_TABLE_NAME
מידע נוסף זמין במאמר בנושא שיוך תכונות לחיזויים.
טבלת אימות שגיאות
שם הטבלה (BQ_ERRORS_VALIDATION_TABLE_NAME)
נוצר על ידי הוספת `errors_validation` לחותמת הזמן של תחילת משימת ההסקה של אצווה: errors_validation_TIMESTAMP
-
במסוף, נכנסים לדף BigQuery.
כניסה ל-BigQuery -
מריצים את השאילתה הבאה:
SELECT * FROM BQ_DATASET_NAME.BQ_ERRORS_VALIDATION_TABLE_NAME
- errors_TARGET_COLUMN_NAME
טבלת השגיאות
שם הטבלה (BQ_ERRORS_TABLE_NAME) נוצר על ידי הוספת המחרוזת errors_ לחותמת הזמן שבה התחיל תהליך ההסקה של אצווה: errors_TIMESTAMP
-
במסוף, נכנסים לדף BigQuery.
כניסה ל-BigQuery -
מריצים את השאילתה הבאה:
SELECT * FROM BQ_DATASET_NAME.BQ_ERRORS_TABLE_NAME
- errors_TARGET_COLUMN_NAME.code
- errors_TARGET_COLUMN_NAME.message
Cloud Storage
אם ציינתם את Cloud Storage כיעד הפלט, התוצאות של בקשת ההסקה באצווה יוחזרו כאובייקטים של CSV בתיקייה חדשה בדלי שציינתם. שם התיקייה הוא שם המודל, עם הקידומת prediction- ותוספת של חותמת הזמן של תחילת העבודה של ההסקת המסקנות באצווה. אפשר לראות את שם התיקייה ב-Cloud Storage בכרטיסייה Batch predictions (תחזיות אצווה) של המודל.
התיקייה ב-Cloud Storage מכילה שני סוגים של אובייקטים:-
אובייקטים של הסקה
שמות האובייקטים של ההסקה הם predictions_1.csv, predictions_2.csv וכן הלאה. הם מכילים שורת כותרת עם שמות העמודות ושורה לכל תחזית שמוחזרת. מספר ערכי ההסקה תלוי בקלט ההסקה ובטווח התחזית. לדוגמה, אם הקלט שלכם כלל 14 ערכים ריקים בעמודת היעד (למשל, מכירות ל-14 הימים הבאים), בקשת ההסקה תחזיר 14 שורות, עם מספר המכירות לכל יום. אם בקשת ההסקה חורגת מאופק החיזוי של המודל, Vertex AI מחזיר רק הסקות עד אופק החיזוי.
ערכי התחזית מוחזרים בעמודה בשם `predicted_TARGET_COLUMN_NAME`. בתחזיות של קוונטילים, עמודת הפלט מכילה את ההסקות של הקוונטילים ואת ערכי הקוונטילים בפורמט JSON.
-
אובייקטים של שגיאות
שמות אובייקטי השגיאות הם errors_1.csv, errors_2.csv וכן הלאה. הם מכילים שורת כותרת ושורה לכל שורה בנתוני הקלט ש-Vertex AI לא הצליח להחזיר עבורה תחזית (לדוגמה, אם מאפיין שלא ניתן להגדיר כ-null היה null).
הערה: אם התוצאות גדולות, הן יפוצלו לכמה אובייקטים.
שאילתות לדוגמה לשיוך תכונות ב-BigQuery
דוגמה 1: קביעת שיוכים להסקת מסקנה יחידה
כדאי לשקול את השאלה הבאה:
בכמה פרסום של מוצר מסוים הגדיל את המכירות הצפויות בחנות מסוימת ב-24 בנובמבר?
השאילתה המתאימה היא:
SELECT
* EXCEPT(explanation, predicted_sales),
ROUND(predicted_sales.value, 2) AS predicted_sales,
ROUND(
explanation.attributions[OFFSET(0)].featureAttributions.advertisement,
2
) AS attribution_advertisement
FROM
`project.dataset.predictions`
WHERE
product = 'product_0'
AND store = 'store_0'
AND date = '2019-11-24'
דוגמה 2: קביעת חשיבות התכונות הגלובלית
כדאי לשקול את השאלה הבאה:
מה הייתה התרומה של כל תכונה למכירות הכוללות הצפויות?
אפשר לחשב ידנית את חשיבות התכונות הגלובלית על ידי צבירה של שיוכי חשיבות התכונות המקומיים. השאילתה המתאימה היא:
WITH
/*
* Aggregate from (id, date) level attributions to global feature importance.
*/
attributions_aggregated AS (
SELECT
SUM(ABS(attributions.featureAttributions.date)) AS date,
SUM(ABS(attributions.featureAttributions.advertisement)) AS advertisement,
SUM(ABS(attributions.featureAttributions.holiday)) AS holiday,
SUM(ABS(attributions.featureAttributions.sales)) AS sales,
SUM(ABS(attributions.featureAttributions.store)) AS store,
SUM(ABS(attributions.featureAttributions.product)) AS product,
FROM
project.dataset.predictions,
UNNEST(explanation.attributions) AS attributions
),
/*
* Calculate the normalization constant for global feature importance.
*/
attributions_aggregated_with_total AS (
SELECT
*,
date + advertisement + holiday + sales + store + product AS total
FROM
attributions_aggregated
)
/*
* Calculate the normalized global feature importance.
*/
SELECT
ROUND(date / total, 2) AS date,
ROUND(advertisement / total, 2) AS advertisement,
ROUND(holiday / total, 2) AS holiday,
ROUND(sales / total, 2) AS sales,
ROUND(store / total, 2) AS store,
ROUND(product / total, 2) AS product,
FROM
attributions_aggregated_with_total
דוגמה לפלט של הסקת מסקנות באצווה ב-BigQuery
במערך נתונים לדוגמה של מכירות משקאות חריפים, יש ארבע חנויות בעיר 'איידה גרוב': 'איידה גרוב פוד פרייד', 'דיסקאונט ליקורס אוף איידה גרוב', 'קייסי'ז ג'נרל סטור מס' 3757' ו'ברו איידה גרוב'. store_name הוא series identifier ושלוש מתוך ארבע החנויות מבקשות הסקה לעמודת היעד sale_dollars. נוצרת שגיאת אימות כי לא נשלחה בקשה לתחזית עבור Discount Liquors of Ida Grove.
הקטע הבא הוא חלק מקבוצת נתוני הקלט שמשמשת להסקת מסקנות:
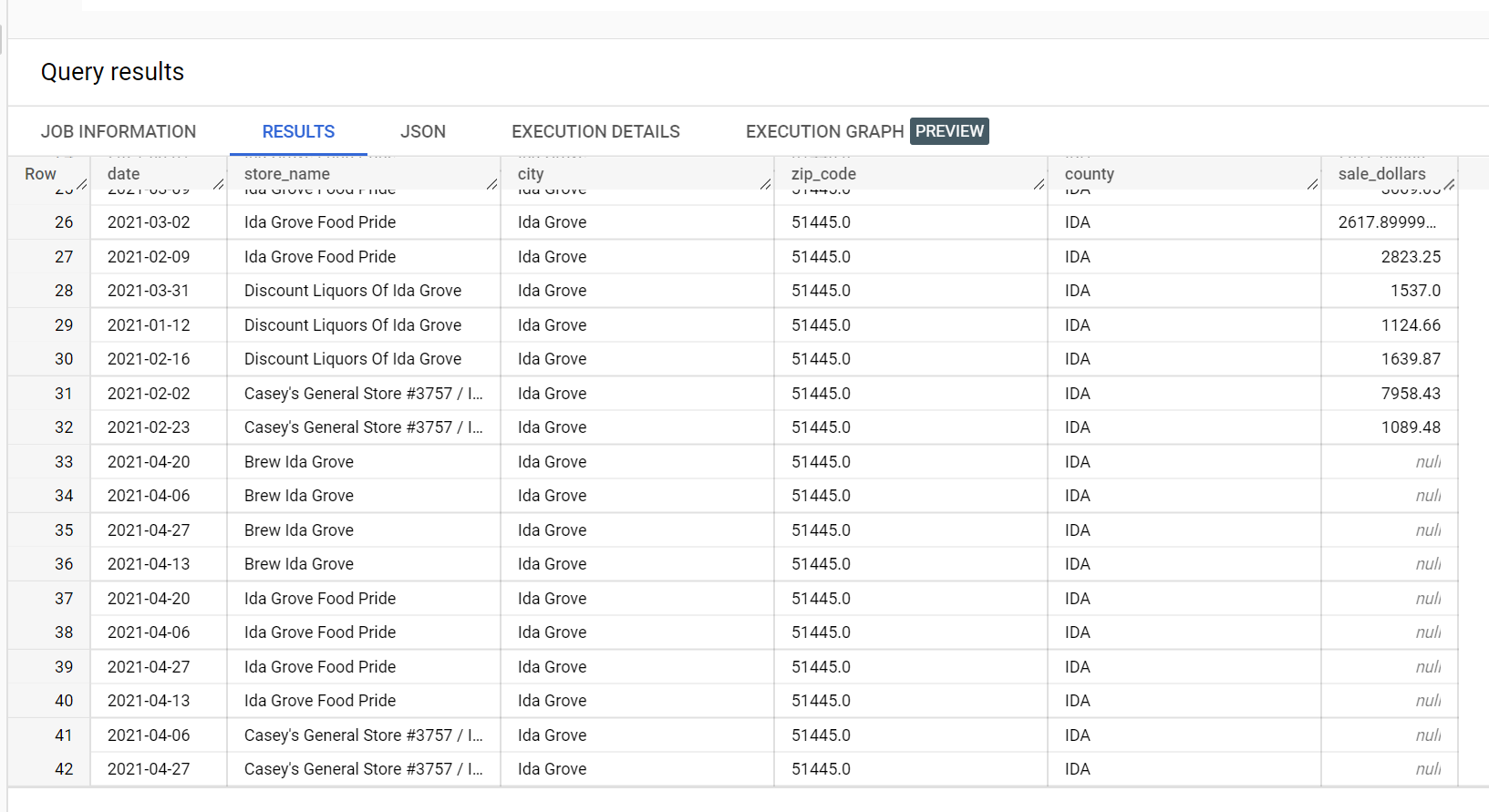
קטע מתוצאות ההסקה:
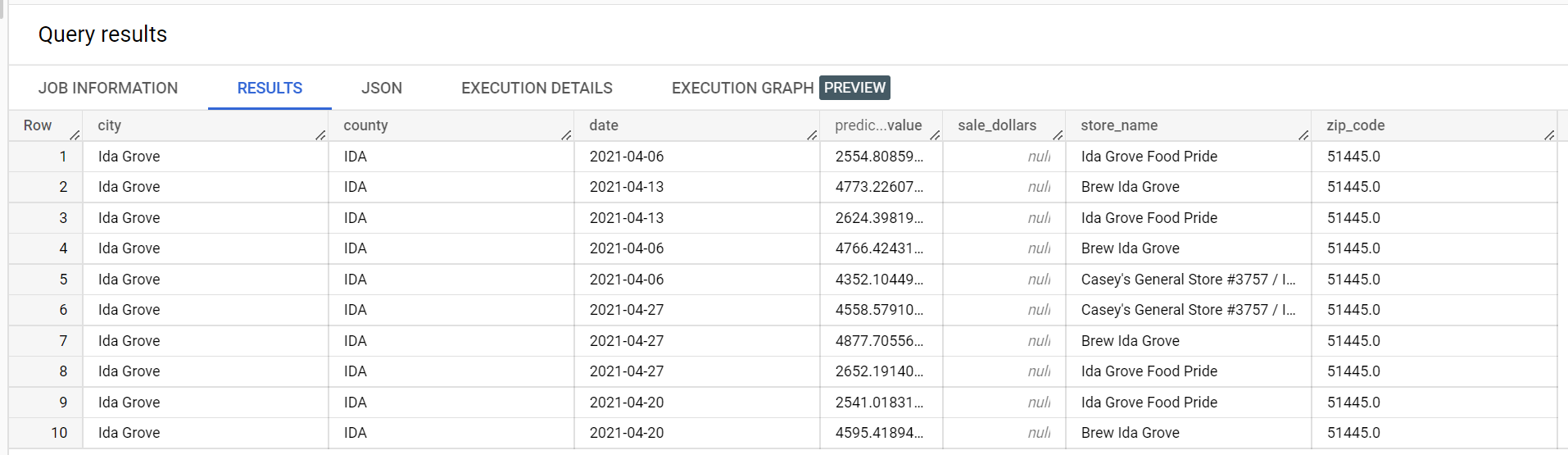
קטע מתוך שגיאות האימות:

פלט לדוגמה של הסקה באצווה עבור מודל שעבר אופטימיזציה של quantile-loss
הדוגמה הבאה היא פלט של הסקה באצווה עבור מודל שעבר אופטימיזציה של quantile-loss. בתרחיש הזה, מודל התחזית חזה את המכירות ל-14 הימים הבאים לכל חנות.
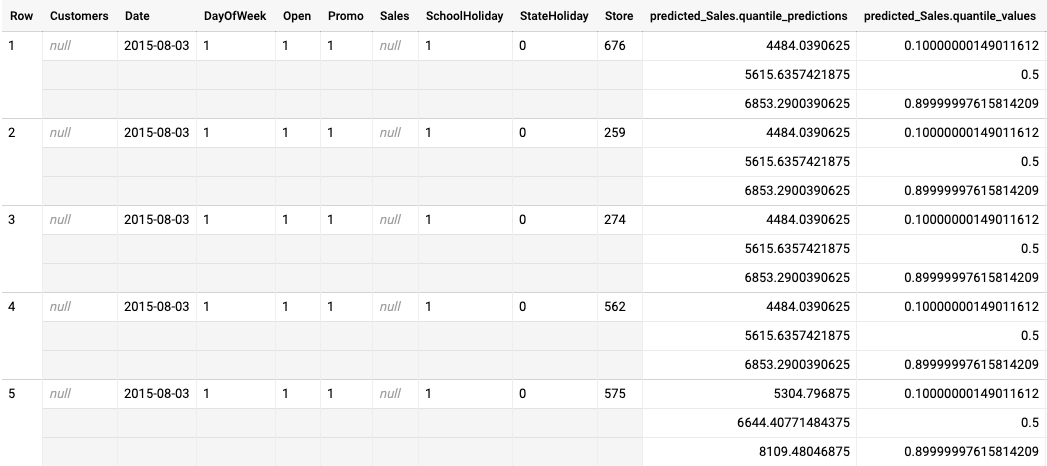
ערכי הכמותיים מוצגים בעמודה predicted_Sales.quantile_values. בדוגמה הזו, המודל חזה ערכים באחוזונים 0.1, 0.5 ו-0.9.
ערכי ההסקה מופיעים בעמודה predicted_Sales.quantile_predictions.
זהו מערך של ערכי מכירות, שממופים לערכי הכמות החציונית בעמודה predicted_Sales.quantile_values. בשורה הראשונה אנחנו רואים שההסתברות לכך שערך המכירות יהיה נמוך מ-4484.04 היא 10%. ההסתברות שערך המכירות יהיה נמוך מ-5615.64 היא 50%. ההסתברות לכך שערך המכירות יהיה נמוך מ-6853.29 היא 90%. ההסקה לשורה הראשונה, שמיוצגת כערך יחיד, היא
5615.64.