
כשמשתמשים במערך נתונים כדי לאמן מודל AutoML, Vertex AI מחלק את הנתונים לשלושה חלקים: חלק לאימון, חלק לאימות וחלק לבדיקה. המטרה העיקרית כשיוצרים פיצולים של נתונים היא לוודא שקבוצת הבדיקה מייצגת בצורה מדויקת את נתוני הייצור. כך אפשר לוודא שמדדי ההערכה מספקים אות מדויק לגבי הביצועים של המודל בנתונים מהעולם האמיתי.
בדף הזה מוסבר איך Vertex AI משתמשת בקבוצות האימון, האימות והבדיקה של הנתונים כדי לאמן מודל AutoML. בנוסף, מוסבר איך אפשר לשלוט באופן שבו הנתונים מחולקים בין שלושת המערכים האלה. אלגוריתמים לפיצול נתונים לסיווג ולרגרסיה שונים מאלגוריתמים לפיצול נתונים לחיזוי.
פיצול נתונים לסיווג ולרגרסיה
איך משתמשים בפילוח נתונים
הפיצולים של הנתונים משמשים בתהליך האימון באופן הבא:
מודלים לניסיון
קבוצת נתונים לאימון משמשת לאימון מודלים עם שילובים שונים של עיבוד מקדים, ארכיטקטורה ואפשרויות היפר-פרמטרים. Vertex AI מעריך את המודלים האלה בקבוצת הנתונים לתיקוף כדי לקבוע את האיכות שלהם, ועל סמך זה הוא בוחן שילובים נוספים של אפשרויות. קבוצת נתונים לתיקוף משמשת גם לבחירת נקודת הבדיקה הטובה ביותר מתוך הערכה תקופתית במהלך ההכשרה. Vertex AI משתמש בפרמטרים ובארכיטקטורות הטובים ביותר שנקבעו בשלב הכוונון המקביל כדי לאמן שני מודלים משולבים, כפי שמתואר בהמשך.
הערכת מודל
מערכת Vertex AI מאמנת מודל הערכה באמצעות קבוצות האימון והאימות כנתוני אימון. Vertex AI יוצר את מדדי הערכת המודל הסופיים של המודל הזה באמצעות קבוצת נתונים לבדיקה. זו הפעם הראשונה בתהליך שבה נעשה שימוש בקבוצת הנתונים לבדיקה. הגישה הזו מבטיחה שמדדי ההערכה הסופיים ישקפו באופן אובייקטיבי את רמת הביצועים של המודל הסופי שאומן בסביבת הייצור.
מודל ההצגה
Vertex AI מאמן מודל עם מערכי האימון, האימות והבדיקה כדי למקסם את כמות נתוני האימון. אפשר להשתמש במודל הזה כדי לבקש תחזיות אונליין או תחזיות באצווה.
פיצול הנתונים שמוגדר כברירת מחדל
כברירת מחדל, מערכת Vertex AI משתמשת באלגוריתם של פיצול רנדומלי כדי להפריד את הנתונים לשלושת חלקי הנתונים. מערכת Vertex AI בוחרת באופן אקראי 80% משורות הנתונים שלכם לקבוצת נתונים לאימון, 10% לקבוצת נתונים לתיקוף ו-10% לקבוצת נתונים לבדיקה. אנחנו ממליצים על חלוקת ברירת המחדל למערכי נתונים:
- לא משתנה לאורך זמן.
- מאוזן יחסית.
- הנתונים מופצים כמו הנתונים שמשמשים לחיזויים בסביבת ייצור.
כדי להשתמש בחלוקת הנתונים שמוגדרת כברירת מחדל, מאשרים את ברירת המחדל במסוף Google Cloud , או משאירים את השדה split ריק ב-API.
אפשרויות לשליטה בפיצול הנתונים
כדי לקבוע אילו שורות ייבחרו לכל פיצול, אפשר להשתמש באחת מהשיטות הבאות:
- פיצול אקראי: מגדירים את אחוזי הפיצול ומקצים את שורות הנתונים באופן אקראי.
- פיצול ידני: בוחרים שורות ספציפיות לשימוש באימון, באימות ובבדיקה בעמודת פיצול הנתונים.
- פיצול כרונולוגי: פיצול הנתונים לפי זמן בעמודה 'זמן'.
צריך לבחור רק אחת מהאפשרויות האלה, בזמן אימון המודל. חלק מהאפשרויות האלה מחייבות שינויים בנתוני האימון (לדוגמה, עמודת פיצול הנתונים או עמודת הזמן). הכללת נתונים לאפשרויות של פיצול נתונים לא מחייבת אתכם להשתמש באפשרויות האלה. אתם עדיין יכולים לבחור אפשרות אחרת כשאתם מאמנים את המודל.
פיצול ברירת המחדל הוא לא הבחירה הכי טובה אם:
אתם לא מאמנים מודל חיזוי, אבל הנתונים שלכם רגישים לזמן.
במקרה כזה, כדאי להשתמש בפיצול כרונולוגי או בפיצול ידני שבו הנתונים העדכניים ביותר משמשים כקבוצת נתונים לבדיקה.
נתוני הבדיקה שלכם כוללים נתונים מאוכלוסיות שלא יהיו מיוצגות בסביבת הייצור.
לדוגמה, נניח שאתם מאמנים מודל עם נתוני רכישה מכמה חנויות. עם זאת, אתם יודעים שהמודל ישמש בעיקר לחיזויים לגבי חנויות שלא נכללות בנתוני האימון. כדי לוודא שהמודל יכול להכליל חנויות שלא נראו, צריך להפריד בין מערכי הנתונים לפי חנויות. במילים אחרות, קבוצת נתונים לבדיקה צריכה לכלול רק חנויות ששונות מקבוצת נתונים לתיקוף, וקבוצת נתונים לתיקוף צריכה לכלול רק חנויות ששונות מקבוצת נתונים לאימון.
יש חוסר איזון בין הכיתות.
אם יש לכם הרבה יותר דוגמאות של מחלקה אחת מאשר של מחלקה אחרת בנתוני האימון, יכול להיות שתצטרכו לכלול באופן ידני יותר דוגמאות של מחלקת המיעוט בנתוני הבדיקה. Vertex AI לא מבצע דגימה שכבתית, ולכן יכול להיות שקבוצת נתונים לבדיקה תכלול מעט מדי דוגמאות של המחלקה המיעוטית, או אפילו אפס דוגמאות.
חלוקה אקראית
הפיצול האקראי נקרא גם "פיצול מתמטי" או "פיצול חלקי".
כברירת מחדל, אחוז הנתונים לאימון שמשמשים לאימון, לאימות ולמערכי הבדיקה הוא 80, 10 ו-10 בהתאמה. אם אתם משתמשים Google Cloud במסוף, אתם יכולים לשנות את אחוזי ההמרות לכל ערך שסכום הערכים שלו הוא 100. אם משתמשים ב-Vertex AI API, צריך להשתמש בשברים שסכומם הוא 1.0.
כדי לשנות את האחוזים (השברים), משתמשים באובייקט FractionSplit כדי להגדיר את השברים.
Vertex AI בוחר שורות לפיצול נתונים באופן אקראי, אבל דטרמיניסטי. אם אתם לא מרוצים מהחלוקה של הנתונים שנוצרו, אתם יכולים לבצע חלוקה ידנית או לשנות את נתוני האימון. אימון מודל חדש עם אותם נתוני אימון יניב את אותו פיצול נתונים.
פיצול ידני
הפיצול הידני נקרא גם "פיצול מוגדר מראש".
עמודה לפיצול נתונים מאפשרת לכם לבחור שורות ספציפיות לשימוש באימון, באימות ובבדיקה. כשיוצרים את נתוני האימון, מוסיפים עמודה שיכולה להכיל אחד מהערכים הבאים (חשוב להקפיד על רישיות):
TRAINVALIDATETESTUNASSIGNED
הערכים בעמודה הזו צריכים להיות אחד משני השילובים הבאים:
- כל הפריטים הכלולים בתוכניות
TRAIN, VALIDATEו-TEST - רק
TESTו-UNASSIGNED
בכל שורה צריך להיות ערך בעמודה הזו, והערך לא יכול להיות מחרוזת ריקה.
לדוגמה, אם מציינים את כל הקבוצות:
"TRAIN","John","Doe","555-55-5555" "TEST","Jane","Doe","444-44-4444" "TRAIN","Roger","Rogers","123-45-6789" "VALIDATE","Sarah","Smith","333-33-3333"
אם מציינים רק את קבוצת נתונים לבדיקה:
"UNASSIGNED","John","Doe","555-55-5555" "TEST","Jane","Doe","444-44-4444" "UNASSIGNED","Roger","Rogers","123-45-6789" "UNASSIGNED","Sarah","Smith","333-33-3333"
לעמודה שבה מתבצע פיצול הנתונים יכול להיות כל שם עמודה חוקי. סוג ההמרה שלה יכול להיות קטגורי, טקסט או אוטומטי.
אם הערך של העמודה לפיצול הנתונים הוא UNASSIGNED, מערכת Vertex AI מקצה את השורה הזו באופן אוטומטי לקבוצת האימון או לקבוצת נתונים לתיקוף.
הגדרת עמודה כעמודה לפיצול נתונים במהלך אימון המודל.
חלוקה כרונולוגית
הפיצול הכרונולוגי נקרא גם 'פיצול לפי חותמת זמן'.
אם הנתונים שלכם תלויים בזמן, אתם יכולים להגדיר עמודה אחת כעמודת זמן. מערכת Vertex AI משתמשת בעמודה Time כדי לפצל את הנתונים. השורות הראשונות משמשות לאימון, השורות הבאות משמשות לאימות והשורות האחרונות משמשות לבדיקה.
ב-Vertex AI כל שורה נחשבת לדוגמה עצמאית לאימון עם התפלגות זהה. הגדרת העמודה Time לא משנה את זה. העמודה 'שעה' משמשת רק לפיצול מערך הנתונים.
אם מציינים עמודת זמן, צריך לכלול ערך בעמודת הזמן בכל שורה במערך הנתונים. מוודאים שיש בעמודה Time מספיק ערכים שונים, כך שקבוצות האימות והבדיקה לא יהיו ריקות. בדרך כלל, לפחות 20 ערכים שונים יספיקו.
הנתונים בעמודה Time צריכים להיות באחד מהפורמטים שנתמכים על ידי הטרנספורמציה של חותמת הזמן. עם זאת, בעמודה Time יכולה להיות כל טרנספורמציה נתמכת, כי הטרנספורמציה משפיעה רק על אופן השימוש בעמודה הזו באימון. טרנספורמציות לא משפיעות על פיצול הנתונים.
אפשר גם לציין את אחוזי נתוני האימון שיוקצו לכל קבוצה.
הגדרת עמודה כעמודת זמן במהלך אימון המודל.
פיצול נתונים לצורך תחזיות
כברירת מחדל, מערכת Vertex AI משתמשת באלגוריתם של פיצול כרונולוגי כדי להפריד את נתוני התחזית לשלושת פיצולי הנתונים. מומלץ להשתמש בפיצול שמוגדר כברירת מחדל. עם זאת, אם רוצים לשלוט בשורות של נתוני האימון שמשמשות לכל פיצול, צריך להשתמש בפיצול ידני.
איך משתמשים בפילוח נתונים
הפיצולים של הנתונים משמשים בתהליך האימון באופן הבא:
מודלים לניסיון
קבוצת נתונים לאימון משמשת לאימון מודלים עם שילובים שונים של עיבוד מקדים, ארכיטקטורה ואפשרויות היפר-פרמטרים. Vertex AI מעריך את המודלים האלה בקבוצת הנתונים לתיקוף כדי לקבוע את האיכות שלהם, ועל סמך זה הוא בוחן שילובים נוספים של אפשרויות. קבוצת נתונים לתיקוף משמשת גם לבחירת נקודת הבדיקה הטובה ביותר מתוך הערכה תקופתית במהלך האימון. Vertex AI משתמש בפרמטרים ובארכיטקטורות הטובים ביותר שנקבעו בשלב הכוונון המקביל כדי לאמן שני מודלים משולבים, כפי שמתואר בהמשך.
הערכת מודל
Vertex AI מאמן מודל הערכה באמצעות מערכי האימון והאימות כנתוני אימון. Vertex AI יוצר את מדדי הערכת המודל הסופיים של המודל הזה באמצעות קבוצת נתונים לבדיקה. זו הפעם הראשונה בתהליך שבה נעשה שימוש בקבוצת הנתונים לבדיקה. הגישה הזו מבטיחה שמדדי ההערכה הסופיים ישקפו באופן אובייקטיבי את רמת הביצועים של המודל הסופי שאומן בסביבת הייצור.
מודל ההצגה
Vertex AI מאמן מודל באמצעות קבוצת האימון וקבוצת הנתונים לתיקוף. המודל מאומת (כדי לבחור את נקודת הבדיקה הטובה ביותר) באמצעות קבוצת נתונים לבדיקה. קבוצת הבדיקה אף פעם לא משמשת לאימון במובן הזה שההפסד מחושב ממנה. אתם משתמשים במודל הזה כדי לקבל מסקנות.
חלוקה כברירת מחדל
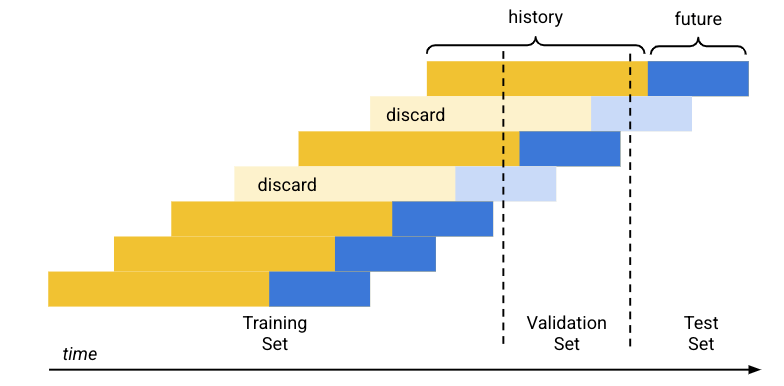
חלוקת הנתונים שמוגדרת כברירת מחדל (לפי סדר כרונולוגי) פועלת באופן הבא:
- מערכת Vertex AI ממיינת את נתוני האימון לפי תאריך.
- באמצעות אחוזי ההגדרה שנקבעו מראש (80/10/10), Vertex AI מפריד את פרק הזמן שמכוסה על ידי נתוני האימון לשלושה בלוקים, אחד לכל קבוצת נתונים לאימון.
- Vertex AI מוסיף שורות ריקות בתחילת כל סדרת זמן כדי לאפשר למודל ללמוד משורות שאין להן מספיק היסטוריה (חלון הקשר). מספר השורות שנוספו הוא גודל חלון ההקשר שהוגדר בזמן האימון.
מערכת Vertex AI משתמשת בכל שורה שבה הנתונים העתידיים (טווח התחזית) נכללים במלואם באחד ממערכי הנתונים של אותו סט, בהתאם לגודל טווח התחזית שהוגדר בזמן האימון. (Vertex AI משליך שורות שטווח התחזית שלהן משתרע על פני שני מערכים כדי למנוע דליפת נתונים).
פיצול ידני
עמודה לפיצול נתונים מאפשרת לכם לבחור שורות ספציפיות לשימוש באימון, באימות ובבדיקה. כשיוצרים את נתוני האימון, מוסיפים עמודה שיכולה להכיל אחד מהערכים הבאים (חשוב להקפיד על רישיות):
TRAINVALIDATETEST
בכל שורה צריך להיות ערך בעמודה הזו, והערך לא יכול להיות מחרוזת ריקה.
לדוגמה:
"TRAIN","sku_id_1","2020-09-21","10" "TEST","sku_id_1","2020-09-22","23" "TRAIN","sku_id_2","2020-09-22","3" "VALIDATE","sku_id_2","2020-09-23","45"
לעמודה שבה מתבצע פיצול הנתונים יכול להיות כל שם עמודה חוקי. סוג ההמרה שלה יכול להיות קטגורי, טקסט או אוטומטי.
הגדרת עמודה כעמודה לפיצול נתונים במהלך אימון המודל.
חשוב להקפיד להימנע מדליפת נתונים בין סדרות הזמן.