
במאמר הזה מוסבר איך להגדיר את OpenTelemetry Collector כדי לבצע scraping של מדדי Prometheus רגילים ולדווח על המדדים האלה לשירות המנוהל של Google Cloud ל-Prometheus. OpenTelemetry Collector הוא סוכן שאפשר לפרוס בעצמכם ולהגדיר אותו לייצוא אל השירות המנוהל ל-Prometheus. ההגדרה דומה להרצת שירות מנוהל ל-Prometheus עם פריסה עצמית של איסוף.
יכול להיות שתבחרו ב-OpenTelemetry Collector במקום באיסוף שמוטמע באופן עצמאי מהסיבות הבאות:
- OpenTelemetry Collector מאפשר לכם להפנות את נתוני הטלמטריה למספר קצוות עורפיים על ידי הגדרת מספר יחידות לייצוא בצינור.
- הכלי Collector תומך גם באותות ממדדים, מיומנים ומעקבות, כך שבאמצעותו אפשר לטפל בכל שלושת סוגי האותות בסוכן אחד.
- פורמט הנתונים של OpenTelemetry שלא תלוי בספק (פרוטוקול OpenTelemetry, או OTLP) תומך במערכת אקולוגית חזקה של ספריות ורכיבי Collector שניתנים לחיבור. כך תוכלו ליהנות ממגוון אפשרויות להתאמה אישית של קבלת הנתונים, העיבוד שלהם והייצוא שלהם.
החיסרון בשימוש ב-OpenTelemetry Collector הוא שצריך להשתמש בגישה של פריסה ותחזוקה בניהול עצמי. הגישה שתבחרו תלויה בצרכים הספציפיים שלכם, אבל במסמך הזה אנחנו מציעים הנחיות מומלצות להגדרת OpenTelemetry Collector באמצעות שירות מנוהל ל-Prometheus כקצה עורפי.
לפני שמתחילים
בקטע הזה מפורטות ההגדרות שנדרשות למשימות שמתוארות במסמך הזה.
הגדרת פרויקטים וכלים
כדי להשתמש בשירות המנוהל של Google Cloud ל-Prometheus, אתם צריכים את המשאבים הבאים:
Google Cloud פרויקט שבו מופעל Cloud Monitoring API.
אם אין לכם Google Cloud פרויקט, אתם יכולים ליצור אחד.
במסוף Google Cloud , עוברים אל New Project:
בשדה שם הפרויקט, מזינים שם לפרויקט ולוחצים על יצירה.
עוברים אל חיוב:
אם הפרויקט שיצרתם לא מסומן בחלק העליון של הדף, בוחרים אותו.
תתבקשו לבחור פרופיל תשלומים קיים או ליצור פרופיל תשלומים חדש.
ה-API של Monitoring מופעל כברירת מחדל בפרויקטים חדשים.
אם כבר יש לכם פרויקט ב- Google Cloud , צריך לוודא ש-Monitoring API מופעל:
עוברים אל APIs & services:
בוחרים את הפרויקט הרצוי.
לוחצים על Enable APIs and Services.
מחפשים את 'מעקב'.
בתוצאות החיפוש, לוחצים על Cloud Monitoring API.
אם לא מוצגת האפשרות 'API enabled' (ה-API מופעל), לוחצים על הלחצן Enable (הפעלה).
אשכול Kubernetes. אם אין לכם אשכול Kubernetes, פועלים לפי ההוראות שבמדריך למתחילים של GKE.
אתם צריכים גם את כלי שורת הפקודה הבאים:
gcloudkubectl
הכלים gcloud ו-kubectl הם חלק מ-Google Cloud CLI. מידע על התקנת הרכיבים האלה מופיע במאמר ניהול רכיבי Google Cloud CLI. כדי לראות את הרכיבים של ה-CLI של gcloud שהתקנתם, מריצים את הפקודה הבאה:
gcloud components list
הגדרת הסביבה
כדי להימנע מהזנת מזהה הפרויקט או שם האשכול שוב ושוב, צריך לבצע את ההגדרה הבאה:
מגדירים את כלי שורת הפקודה באופן הבא:
מגדירים את ה-CLI של gcloud כך שיפנה למזהה של פרויקטGoogle Cloud :
gcloud config set project PROJECT_ID
אם אתם מריצים את הפקודה ב-GKE, צריך להשתמש ב-CLI של gcloud כדי להגדיר את האשכול:
gcloud container clusters get-credentials CLUSTER_NAME --location LOCATION --project PROJECT_ID
אחרת, משתמשים ב-CLI של
kubectlכדי להגדיר את האשכול:kubectl config set-cluster CLUSTER_NAME
מידע נוסף על הכלים האלה:
הגדרת מרחב שמות
יוצרים את מרחב השמות NAMESPACE_NAME Kubernetes בשביל המשאבים שיוצרים כחלק מאפליקציית הדוגמה. מומלץ להשתמש בשם מרחב השמות gmp-test כשמשתמשים במסמכי התיעוד האלה כדי להגדיר דוגמה של הגדרת Prometheus.
יוצרים את מרחב השמות באמצעות הפקודה הבאה:
kubectl create ns NAMESPACE_NAME
אימות פרטי הכניסה לחשבון שירות
אם באשכול Kubernetes שלכם מופעל איחוד זהויות של עומסי עבודה ל-GKE, אתם יכולים לדלג על הקטע הזה.
כשמריצים את שירות מנוהל ל-Prometheus ב-GKE, המערכת מאחזרת באופן אוטומטי פרטי כניסה מהסביבה על סמך חשבון השירות שמוגדר כברירת מחדל של Compute Engine. לחשבון השירות שמוגדר כברירת מחדל יש את ההרשאות הנדרשות. אם אינכם משתמשים באיחוד זהויות של עומסי עבודה ל-GKE, ואם בעבר הסרתם את הענקת התפקיד monitoring.metricWriter ו-monitoring.viewer מחשבון השירות שמוגדר כברירת מחדל של הצומת, תצטרכו להוסיף מחדש את התפקידים החסרים האלה לפני שתמשיכו.
הגדרת חשבון שירות לשימוש באיחוד זהויות של עומסי עבודה ב-GKE
אם איחוד זהויות של עומסי עבודה ל-GKE לא מופעל באשכול Kubernetes, אפשר לדלג על הקטע הזה.
השירות המנוהל ל-Prometheus אוסף נתוני מדדים באמצעות Cloud Monitoring API. אם באשכול שלכם נעשה שימוש באיחוד זהויות של עומסי עבודה ל-GKE, אתם צריכים לתת לחשבון השירות של Kubernetes הרשאה ל-Monitoring API. בקטע הזה מתוארים הנושאים הבאים:
- יצירה של Google Cloud חשבון שירות ייעודי,
gmp-test-sa. - קישור חשבון השירות Google Cloud אל חשבון השירות שמוגדר כברירת מחדל ב-Kubernetes במרחב שמות לבדיקה,
NAMESPACE_NAME. - מעניקים את ההרשאה הנדרשת לחשבון השירות Google Cloud .
יצירה של חשבון השירות וקישור שלו
השלב הזה מופיע בכמה מקומות במסמכי התיעוד של השירות המנוהל ל-Prometheus. אם כבר ביצעתם את השלב הזה במסגרת משימה קודמת, אין צורך לחזור עליו. אפשר לדלג אל אישור חשבון השירות.
קודם יוצרים חשבון שירות, אם עדיין לא עשיתם זאת:
gcloud config set project PROJECT_ID \ && gcloud iam service-accounts create gmp-test-sa
אחר כך משתמשים ברצף הפקודות הבא כדי לקשר את חשבון השירות gmp-test-saלחשבון השירות שמוגדר כברירת מחדל ב-Kubernetes במרחב השמות NAMESPACE_NAME:
gcloud config set project PROJECT_ID \ && gcloud iam service-accounts add-iam-policy-binding \ --role roles/iam.workloadIdentityUser \ --condition=None \ --member "serviceAccount:PROJECT_ID.svc.id.goog[NAMESPACE_NAME/default]" \ gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ && kubectl annotate serviceaccount \ --namespace NAMESPACE_NAME \ default \ iam.gke.io/gcp-service-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
אם אתם משתמשים במרחב שמות או בחשבון שירות אחרים של GKE, צריך לשנות את הפקודות בהתאם.
אישור חשבון השירות
קבוצות של הרשאות קשורות נאספות בתפקידים, ואת התפקידים מקצים לחשבון משתמש, ובדוגמה הזו לחשבון השירות Google Cloud. מידע נוסף על תפקידים ב-Monitoring זמין במאמר בקרת גישה.
הפקודה הבאה מעניקה לחשבון השירות Google Cloud , gmp-test-sa את התפקידים ב-Monitoring API שדרושים לו כדי לכתוב נתוני מדדים.
אם כבר הענקתם לחשבון השירות תפקיד ספציפי כחלק ממשימה קודמת, אין צורך לעשות זאת שוב. Google Cloud
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter \ --condition=None \ && \ gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/iam.serviceAccountTokenCreator \ --condition=None
ניפוי באגים בהגדרת איחוד הזהויות של עומסי עבודה ל-GKE
אם נתקלתם בבעיות בהפעלת איחוד זהויות של עומסי עבודה ל-GKE, תוכלו לעיין במסמכים בנושא אימות ההגדרה של איחוד זהויות של עומסי עבודה ל-GKE ובמדריך לפתרון בעיות באיחוד זהויות של עומסי עבודה ל-GKE.
שגיאות נפוצות בהגדרת איחוד שירותי אימות הזהות של עומסי עבודה ב-GKE נובעות משגיאות הקלדה או מהעתקה והדבקה חלקיות. לכן, מומלץ מאוד להשתמש במשתנים הניתנים לעריכה ובסמלי ההעתקה וההדבקה שניתן ללחוץ עליהם, שמוטמעים בדוגמאות הקוד בהוראות האלה.
איחוד זהויות של עומסי עבודה ל-GKE בסביבות ייצור
בדוגמה שמתוארת במסמך הזה, חשבון השירות Google Cloud משויך לחשבון השירות שמוגדר כברירת מחדל ב-Kubernetes, ומקבל את כל ההרשאות הנדרשות לשימוש ב-Monitoring API. Google Cloud
בסביבת ייצור, יכול להיות שתרצו להשתמש בגישה מפורטת יותר, עם חשבון שירות לכל רכיב, ולכל אחד מהם הרשאות מינימליות. מידע נוסף על הגדרת חשבונות שירות לניהול Workload Identity זמין במאמר שימוש באיחוד זהויות של עומסי עבודה ל-GKE.
הגדרת OpenTelemetry Collector
בקטע הזה מוסבר איך להגדיר את OpenTelemetry Collector ולהשתמש בו כדי לגרד מדדים מאפליקציה לדוגמה ולשלוח את הנתונים לשירות מנוהל של Google Cloud ל-Prometheus. מידע מפורט על ההגדרות מופיע בקטעים הבאים:
ה-OpenTelemetry Collector דומה לקובץ הבינארי של הסוכן של השירות המנוהל ל-Prometheus. קהילת OpenTelemetry מפרסמת באופן קבוע גרסאות, כולל קוד מקור, קבצים בינאריים ותמונות של קונטיינרים.
אפשר לפרוס את הארטיפקטים האלה במכונות וירטואליות או באשכולות Kubernetes באמצעות הגדרות ברירת המחדל המומלצות, או להשתמש בכלי ליצירת אוספים כדי ליצור אוסף משלכם שכולל רק את הרכיבים שאתם צריכים. כדי ליצור כלי לאיסוף נתונים לשימוש עם שירות מנוהל ל-Prometheus, אתם צריכים את הרכיבים הבאים:
- הכלי לייצוא של השירות המנוהל ל-Prometheus, שכותב את המדדים שלכם לשירות המנוהל ל-Prometheus.
- מקבל שיגרד את המדדים שלכם. במסמך הזה אנחנו מניחים שאתם משתמשים ב-OpenTelemetry Prometheus receiver, אבל שירות מנוהל ל-Prometheus exporter תואם לכל OpenTelemetry metrics receiver.
- מעבדים לאיגום ולסימון של המדדים כדי לכלול מזהי משאבים חשובים בהתאם לסביבה שלכם.
כדי להפעיל את הרכיבים האלה, צריך להשתמש בקובץ תצורה שמועבר אל Collector באמצעות הדגל --config.
בקטעים הבאים נסביר איך להגדיר כל אחד מהרכיבים האלה בפירוט. במאמר הזה מוסבר איך להפעיל את הכלי לאיסוף נתונים ב-GKE ובמקומות אחרים.
הגדרה ופריסה של כלי האיסוף
לא משנה אם אתם מריצים את האוסף ב- Google Cloud או בסביבה אחרת, אתם עדיין יכולים להגדיר את OpenTelemetry Collector לייצוא אל שירות מנוהל ל-Prometheus. ההבדל הגדול ביותר יהיה באופן שבו מגדירים את כלי האיסוף. בסביבות שאינןGoogle Cloud , יכול להיות שיהיה צורך בפורמט נוסף של נתוני המדדים כדי שתהיה להם תאימות לשירות מנוהל ל-Prometheus. לעומת זאת, ב- Google Cloud, הכלי לאיסוף נתונים יכול לזהות באופן אוטומטי חלק גדול מהפורמט הזה.
הפעלת OpenTelemetry Collector ב-GKE
כדי להגדיר את OpenTelemetry Collector ב-GKE, אפשר להעתיק את ההגדרה הבאה לקובץ בשם config.yaml:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'SCRAPE_JOB_NAME'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
action: keep
regex: prom-example
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
# Note that the googlemanagedprometheus exporter block is intentionally blank
exporters:
googlemanagedprometheus:
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [batch, memory_limiter, resourcedetection, transform]
exporters: [googlemanagedprometheus]
ההגדרה הקודמת משתמשת במקלט Prometheus ובכלי הייצוא של השירות המנוהל ל-Prometheus כדי לגרד את נקודות הקצה של המדדים ב-Pods של Kubernetes ולייצא את המדדים האלה לשירות המנוהל ל-Prometheus. מעבדי הצינור מעצבים את הנתונים ומקבצים אותם באצווה.
פרטים נוספים על הפעולה של כל חלק בהגדרה הזו, וגם הגדרות לפלטפורמות שונות, מופיעים בקטעים המפורטים הבאים בנושא גירוד מדדים והוספת מעבדים.
כשמשתמשים בהגדרה קיימת של Prometheus עם רכיב ה-prometheus receiver של OpenTelemetry Collector, צריך להחליף כל תו של סימן דולר בודד, 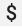 , בתווים כפולים,
, בתווים כפולים, 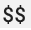 , כדי למנוע הפעלה של החלפת משתני סביבה. מידע נוסף זמין במאמר בנושא גירוד מדדים של Prometheus.
, כדי למנוע הפעלה של החלפת משתני סביבה. מידע נוסף זמין במאמר בנושא גירוד מדדים של Prometheus.
אפשר לשנות את ההגדרה הזו בהתאם לסביבה, לספק ולמדדים שרוצים לגרד, אבל ההגדרה לדוגמה היא נקודת התחלה מומלצת להרצה ב-GKE.
הפעלת OpenTelemetry Collector מחוץ ל- Google Cloud
הפעלת OpenTelemetry Collector מחוץ ל- Google Cloud, למשל בשרת מקומי או בספקי ענן אחרים, דומה להפעלת Collector ב-GKE. עם זאת, סביר להניח שהמדדים שאתם מגרדים לא יכללו באופן אוטומטי נתונים שמעוצבים בצורה הטובה ביותר עבור שירות מנוהל ל-Prometheus. לכן, חשוב להקפיד להגדיר את האוסף כך שיעצב את המדדים באופן שתהיה להם תאימות לשירות המנוהל ל-Prometheus.
אפשר להעתיק את ההגדרה הבאה לקובץ בשם config.yaml כדי להגדיר את OpenTelemetry Collector לפריסה באשכול Kubernetes שאינו GKE:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'SCRAPE_JOB_NAME'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
action: keep
regex: prom-example
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
processors:
resource:
attributes:
- key: "cluster"
value: "CLUSTER_NAME"
action: upsert
- key: "namespace"
value: "NAMESPACE_NAME"
action: upsert
- key: "location"
value: "REGION"
action: upsert
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
exporters:
googlemanagedprometheus:
project: "PROJECT_ID"
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [batch, memory_limiter, resource, transform]
exporters: [googlemanagedprometheus]
ההגדרה הזו מבצעת את הפעולות הבאות:
- הגדרת תצורת גירוד של גילוי שירותים ב-Kubernetes עבור Prometheus. מידע נוסף זמין במאמר בנושא גירוד מדדי Prometheus.
- הגדרה ידנית של מאפייני המשאבים
cluster,namespaceו-location. מידע נוסף על מאפייני משאבים, כולל זיהוי משאבים ב-Amazon EKS וב-Azure AKS, זמין במאמר זיהוי מאפייני משאבים. - הקוד מגדיר את האפשרות
projectבכלי לייצואgooglemanagedprometheus. מידע נוסף על הכלי לייצוא אפשר למצוא במאמר הגדרת הכלי לייצואgooglemanagedprometheus.
כשמשתמשים בהגדרה קיימת של Prometheus עם רכיב ה-prometheus receiver של OpenTelemetry Collector, צריך להחליף כל תו של סימן דולר בודד, , בתווים כפולים, , כדי למנוע הפעלה של החלפת משתני סביבה. מידע נוסף זמין במאמר בנושא גירוד מדדים של Prometheus.
מידע על שיטות מומלצות להגדרת ה-Collector בעננים אחרים זמין במאמרים בנושא Amazon EKS או Azure AKS.
פריסת האפליקציה לדוגמה
אפליקציית הדוגמה פולטת את מדד הדלפק example_requests_total ואת מדד ההיסטוגרמה example_random_numbers (בין היתר) ביציאה metrics שלה.
המניפסט בדוגמה הזו מגדיר שלוש רפליקות.
כדי לפרוס את האפליקציה לדוגמה, מריצים את הפקודה הבאה:
kubectl -n NAMESPACE_NAME apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.17.2/examples/example-app.yaml
יצירת קובץ הגדרה של האוסף כ-ConfigMap
אחרי שיוצרים את קובץ ההגדרות וממקמים אותו בקובץ בשם config.yaml, משתמשים בקובץ הזה כדי ליצור Kubernetes ConfigMap על סמך קובץ config.yaml.
כשפורסים את האוסף, הוא מטמיע את ConfigMap וטוען את הקובץ.
כדי ליצור ConfigMap בשם otel-config עם ההגדרה שלכם, משתמשים בפקודה הבאה:
kubectl -n NAMESPACE_NAME create configmap otel-config --from-file config.yaml
פריסת הכלי לאיסוף נתונים
יוצרים קובץ בשם collector-deployment.yaml עם התוכן הבא:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: NAMESPACE_NAME:prometheus-test
rules:
- apiGroups: [""]
resources:
- pods
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: NAMESPACE_NAME:prometheus-test
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: NAMESPACE_NAME:prometheus-test
subjects:
- kind: ServiceAccount
namespace: NAMESPACE_NAME
name: default
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: otel-collector
spec:
replicas: 1
selector:
matchLabels:
app: otel-collector
template:
metadata:
labels:
app: otel-collector
spec:
containers:
- name: otel-collector
image: otel/opentelemetry-collector-contrib:0.140.0
args:
- --config
- /etc/otel/config.yaml
- --feature-gates=exporter.googlemanagedprometheus.intToDouble
volumeMounts:
- mountPath: /etc/otel/
name: otel-config
volumes:
- name: otel-config
configMap:
name: otel-config
מריצים את הפקודה הבאה כדי ליצור את פריסת ה-Collector באשכול Kubernetes:
kubectl -n NAMESPACE_NAME create -f collector-deployment.yaml
אחרי שה-pod מופעל, הוא מבצע scraping של האפליקציה לדוגמה ומדווח על מדדים לשירות המנוהל ל-Prometheus.
מידע על דרכים לשליחת שאילתות על הנתונים זמין במאמרים שליחת שאילתות באמצעות Cloud Monitoring או שליחת שאילתות באמצעות Grafana.
הזנת פרטי הכניסה באופן מפורש
כשמריצים את OpenTelemetry Collector ב-GKE, המערכת מאחזרת באופן אוטומטי את פרטי הכניסה מהסביבה על סמך חשבון השירות של הצומת.
באשכולות Kubernetes שאינם GKE, צריך לספק את פרטי הכניסה ל-OpenTelemetry Collector באופן מפורש באמצעות דגלים או משתנה הסביבה GOOGLE_APPLICATION_CREDENTIALS.
מגדירים את ההקשר לפרויקט היעד:
gcloud config set project PROJECT_ID
יוצרים חשבון שירות:
gcloud iam service-accounts create gmp-test-sa
בשלב הזה נוצר חשבון השירות שאולי כבר יצרתם בהוראות בנושא איחוד זהויות של עומסי עבודה ל-GKE.
מעניקים לחשבון השירות את ההרשאות הנדרשות:
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
יוצרים ומורידים מפתח לחשבון השירות:
gcloud iam service-accounts keys create gmp-test-sa-key.json \ --iam-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
מוסיפים את קובץ המפתח כסוד לאשכול שאינו GKE:
kubectl -n NAMESPACE_NAME create secret generic gmp-test-sa \ --from-file=key.json=gmp-test-sa-key.json
פותחים את משאב הפריסה של OpenTelemetry לעריכה:
kubectl -n NAMESPACE_NAME edit deployment otel-collector
מוסיפים את הטקסט שמופיע בהדגשה למשאב:
apiVersion: apps/v1 kind: Deployment metadata: namespace: NAMESPACE_NAME name: otel-collector spec: template spec: containers: - name: otel-collector env: - name: "GOOGLE_APPLICATION_CREDENTIALS" value: "/gmp/key.json" ... volumeMounts: - name: gmp-sa mountPath: /gmp readOnly: true ... volumes: - name: gmp-sa secret: secretName: gmp-test-sa ...שומרים את הקובץ וסוגרים את הכלי לעריכה. אחרי שהשינוי יוחל, יחידות ה-Pod ייווצרו מחדש ויתחילו לבצע אימות לשרת העורפי של המדדים באמצעות חשבון השירות שצוין.
גירוד מדדים של Prometheus
בקטע הזה ובקטע הבא מפורט מידע נוסף על התאמה אישית של OpenTelemetry Collector. המידע הזה יכול להיות שימושי במצבים מסוימים, אבל הוא לא נחוץ כדי להריץ את הדוגמה שמתוארת במאמר הגדרת OpenTelemetry Collector.
אם האפליקציות שלכם כבר חושפות נקודות קצה של Prometheus, OpenTelemetry Collector יכול לגרד את נקודות הקצה האלה באמצעות אותו פורמט של הגדרות גירוד שבו הייתם משתמשים בכל הגדרת Prometheus רגילה. כדי לעשות את זה, צריך להפעיל את ה-receiver של Prometheus בהגדרות של ה-collector.
הגדרת מקלט Prometheus לקבוצות Pod של Kubernetes יכולה להיראות כך:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
service:
pipelines:
metrics:
receivers: [prometheus]
זוהי הגדרת גירוד (scrape) שמבוססת על גילוי שירותים, ואפשר לשנות אותה לפי הצורך כדי לגרד את האפליקציות.
כשמשתמשים בהגדרה קיימת של Prometheus עם רכיב ה-prometheus receiver של OpenTelemetry Collector, צריך להחליף כל תו של סימן דולר בודד, , בתווים כפולים, , כדי למנוע הפעלה של החלפת משתני סביבה. חשוב במיוחד לעשות את זה לגבי הערך replacement בקטע relabel_configs. לדוגמה, אם יש לכם את הקטע relabel_config הבא:
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: (.+):(?:\d+);(\d+) replacement: $1:$2 target_label: __address__
אחר כך שכתב אותו כך:
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: (.+):(?:\d+);(\d+) replacement: $$1:$$2 target_label: __address__
מידע נוסף זמין במסמכי התיעוד של OpenTelemetry.
בשלב הבא, מומלץ מאוד להשתמש במעבדים כדי לעצב את המדדים. במקרים רבים, צריך להשתמש במעבדים כדי לעצב את המדדים בצורה נכונה.
הוספת מעבדים
OpenTelemetry מעבדים משנים נתוני טלמטריה לפני שהם מיוצאים. אתם יכולים להשתמש במעבדים הבאים כדי לוודא שהמדדים שלכם נכתבים בפורמט שתואם לשירות המנוהל ל-Prometheus.
זיהוי מאפייני משאבים
הכלי לייצוא נתונים של שירות מנוהל ל-Prometheus ל-OpenTelemetry משתמש בprometheus_target משאב שנמצא במעקב כדי לזהות באופן ייחודי נקודות נתונים של סדרות זמנים. הכלי לייצוא מנתח את השדות הנדרשים של monitored-resource ממאפייני המשאבים בנקודות הנתונים של המדד.
השדות והמאפיינים שמהם נסרקים הערכים הם:
- project_id: מזוהה אוטומטית על ידי Application Default
Credentials,
gcp.project.idאוprojectבהגדרות של כלי הייצוא (ראו הגדרת כלי הייצוא) - מיקום:
location,cloud.availability_zone,cloud.region - אשכול:
cluster,k8s.cluster.name - namespace:
namespace,k8s.namespace.name - עבודה:
service.name+service.namespace - instance:
service.instance.id
אם לא מגדירים לתוויות האלה ערכים ייחודיים, עלולות להופיע שגיאות מסוג 'duplicate timeseries' (סדרות זמן כפולות) כשמייצאים לשירות מנוהל ל-Prometheus. במקרים רבים, המערכת יכולה לזהות את הערכים של התוויות האלה באופן אוטומטי, אבל לפעמים תצטרכו למפות אותם בעצמכם. בהמשך הקטע הזה מתוארים התרחישים האלה.
רכיב ה-receiver של Prometheus מגדיר באופן אוטומטי את המאפיין service.name על סמך job_name בהגדרת הסקראפינג, ואת המאפיין service.instance.id על סמך instance של יעד הסקראפינג. המקבל מגדיר גם את k8s.namespace.name כשמשתמשים ב-role: pod בהגדרת הסקריפט.
אם אפשר, מאכלסים את שאר המאפיינים באופן אוטומטי באמצעות מעבד זיהוי המשאבים. עם זאת, בהתאם לסביבה שלכם, יכול להיות שלא תהיה אפשרות לזהות חלק מהמאפיינים באופן אוטומטי. במקרה כזה, אפשר להשתמש במעבדים אחרים כדי להוסיף את הערכים האלה באופן ידני או לנתח אותם מתוויות של מדדים. בקטעים הבאים מפורטות הגדרות לזיהוי משאבים בפלטפורמות שונות.
GKE
כשמריצים את OpenTelemetry ב-GKE, צריך להפעיל את מעבד זיהוי המשאבים כדי למלא את תוויות המשאבים. חשוב לוודא שהמדדים לא מכילים כבר אף אחת מתוויות המשאבים השמורות. אם אי אפשר להימנע מכך, אפשר לקרוא את המאמר מניעת התנגשויות בין מאפייני משאבים על ידי שינוי שמות של מאפיינים.
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
אפשר להעתיק את הקטע הזה ישירות לקובץ התצורה, ולהחליף את הקטע processors אם הוא כבר קיים.
Amazon EKS
הכלי לזיהוי משאבים של EKS לא ממלא באופן אוטומטי את המאפיינים cluster או namespace. אפשר לספק את הערכים האלה באופן ידני באמצעות מעבד המשאבים, כמו בדוגמה הבאה:
processors:
resourcedetection:
detectors: [eks]
timeout: 10s
resource:
attributes:
- key: "cluster"
value: "my-eks-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
אפשר גם להמיר את הערכים האלה מתוויות של מדדים באמצעות groupbyattrs
המעבד (ראו העברת תוויות של מדדים לתוויות של משאבים בהמשך).
Azure AKS
גלאי המשאבים של AKS לא ממלא אוטומטית את המאפיינים cluster או namespace. אפשר לספק את הערכים האלה באופן ידני באמצעות מעבד המשאבים, כמו בדוגמה הבאה:
processors:
resourcedetection:
detectors: [aks]
timeout: 10s
resource:
attributes:
- key: "cluster"
value: "my-eks-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
אפשר גם להמיר את הערכים האלה מתוויות של מדדים באמצעות groupbyattrsהמעבד. מידע נוסף זמין במאמר העברת תוויות של מדדים לתוויות של משאבים.
סביבות מקומיות וסביבות שאינן בענן
בסביבות מקומיות או בסביבות שאינן בענן, כנראה שלא תוכלו לזהות באופן אוטומטי אף אחד ממאפייני המשאבים הנדרשים. במקרה כזה, אפשר להוסיף את התוויות האלה למדדים ולהעביר אותן למאפייני משאבים (ראו העברת תוויות של מדדים לתוויות של משאבים), או להגדיר ידנית את כל מאפייני המשאבים כמו בדוגמה הבאה:
processors:
resource:
attributes:
- key: "cluster"
value: "my-on-prem-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
- key: "location"
value: "us-east-1"
action: upsert
במאמר יצירת הגדרות של אוסף נתונים כ-ConfigMap מוסבר איך להשתמש בהגדרות. בקטע הזה מניחים שהגדרתם את התצורה בקובץ בשם config.yaml.
עדיין אפשר להגדיר אוטומטית את מאפיין המשאב project_id כשמריצים את ה-Collector עם Application Default Credentials.
אם ל-Collector אין גישה ל-Application Default Credentials, אפשר לעיין במאמר בנושא הגדרה של project_id.
לחלופין, אפשר להגדיר ידנית את מאפייני המשאב שאתם צריכים במשתנה סביבה, OTEL_RESOURCE_ATTRIBUTES, עם רשימה מופרדת בפסיקים של צמדי מפתח/ערך, למשל:
export OTEL_RESOURCE_ATTRIBUTES="cluster=my-cluster,namespace=my-app,location=us-east-1"
לאחר מכן משתמשים במעבד env לאיתור משאבים כדי להגדיר את מאפייני המשאב:
processors:
resourcedetection:
detectors: [env]
כדי להימנע מהתנגשויות בין מאפייני משאבים, צריך לשנות את השם של המאפיינים
אם המדדים שלכם כבר מכילים תוויות שמתנגשות עם מאפייני המשאבים הנדרשים (כמו location, cluster או namespace), צריך לשנות את השם שלהן כדי למנוע את ההתנגשות. המוסכמה ב-Prometheus היא להוסיף את הקידומת exported_ לשם התווית. כדי להוסיף את הקידומת הזו, משתמשים במעבד transform.
ההגדרה הבאה processors משנה את השם של כל התנגשות פוטנציאלית ופותרת כל מפתח מתנגש מהמדד:
processors:
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
העברת תוויות של מדדים לתוויות של משאבים
במקרים מסוימים, יכול להיות שהמדדים ידווחו בכוונה על תוויות כמו
namespace כי הכלי לייצוא עוקב אחרי כמה מרחבי שמות. לדוגמה, כשמריצים את kube-state-metrics exporter.
בתרחיש הזה, אפשר להעביר את התוויות האלה למאפייני משאבים באמצעות מעבד groupbyattrs:
processors:
groupbyattrs:
keys:
- namespace
- cluster
- location
בדוגמה הקודמת, אם יש מדד עם התוויות namespace, cluster או location, התוויות האלה יומרו למאפייני המשאב התואמים.
הגבלת בקשות API ושימוש בזיכרון
שני מעבדים נוספים, batch processor ו-memory limiter processor, מאפשרים לכם להגביל את צריכת המשאבים של האוסף.
עיבוד באצווה
בקשות באצווה מאפשרות לכם להגדיר כמה נקודות נתונים לשלוח בבקשה אחת. שימו לב למגבלה של Cloud Monitoring של 200 סדרות זמן לכל בקשה. מפעילים את מעבד האצווה באמצעות ההגדרות הבאות:
processors:
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
הגבלת הזיכרון
מומלץ להפעיל את המעבד של מגביל הזיכרון כדי למנוע קריסה של האוסף בזמנים של תפוקה גבוהה. כדי להפעיל את העיבוד, משתמשים בהגדרות הבאות:
processors:
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
הגדרת הכלי לייצוא googlemanagedprometheus
כברירת מחדל, לא נדרשת הגדרה נוספת כדי להשתמש ב-exporter googlemanagedprometheus ב-GKE. במקרים רבים, צריך רק להפעיל את התכונה עם בלוק ריק בקטע exporters:
exporters: googlemanagedprometheus:
עם זאת, הכלי לייצוא נתונים מספק כמה הגדרות אופציונליות. בקטעים הבאים מתוארות הגדרות תצורה אחרות.
הגדרה project_id
כדי לשייך את סדרת הזמן ל Google Cloud פרויקט, צריך להגדיר את project_id במשאב במעקב prometheus_target.
כשמריצים את OpenTelemetry ב- Google Cloud, ערך ברירת המחדל של שירות מנוהל ל-Prometheus exporter מוגדר על סמך Application Default Credentials שהוא מוצא. אם אין פרטי כניסה זמינים, או אם רוצים לבטל את הגדרת ברירת המחדל של הפרויקט, יש שתי אפשרויות:
- מגדירים את
projectבתצורת הכלי לייצוא - מוסיפים מאפיין משאב
gcp.project.idלמדדים.
מומלץ מאוד להשתמש בערך ברירת המחדל (לא מוגדר) של project_id, ולא להגדיר אותו באופן מפורש, כשזה אפשרי.
מגדירים את project בתצורת הכלי לייצוא
קטע ההגדרות הבא שולח מדדים לשירות מנוהל ל-Prometheus בפרויקט Google Cloud MY_PROJECT:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
exporters:
googlemanagedprometheus:
project: MY_PROJECT
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection]
exporters: [googlemanagedprometheus]
השינוי היחיד מהדוגמאות הקודמות הוא השורה החדשה project: MY_PROJECT.
ההגדרה הזו שימושית אם אתם יודעים שכל מדד שמגיע דרך האוסף הזה צריך להישלח אל MY_PROJECT.
הגדרת מאפיין משאב של gcp.project.id
אפשר להגדיר שיוך לפרויקט על בסיס כל מדד בנפרד על ידי הוספה של מאפיין משאב gcp.project.id למדדים. מגדירים את ערך המאפיין לשם הפרויקט שאליו רוצים לשייך את המדד.
לדוגמה, אם למדד שלכם כבר יש תווית project, אפשר להעביר את התווית הזו למאפיין של משאב ולשנות את השם שלה ל-gcp.project.id באמצעות מעבדים בהגדרות של ה-Collector, כמו בדוגמה הבאה:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
groupbyattrs:
keys:
- project
resource:
attributes:
- key: "gcp.project.id"
from_attribute: "project"
action: upsert
exporters:
googlemanagedprometheus:
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection, groupbyattrs, resource]
exporters: [googlemanagedprometheus]
הגדרת אפשרויות לקוח
הכלי googlemanagedprometheus exporter משתמש בלקוחות gRPC בשביל השירות המנוהל ל-Prometheus. לכן, יש הגדרות אופציונליות להגדרת לקוח gRPC:
-
compression: מאפשר דחיסת gzip לבקשות gRPC, שימושי לצמצום עמלות על העברת נתונים כששולחים נתונים מעננים אחרים אל שירות מנוהל ל-Prometheus (ערכים תקינים:gzip). -
user_agent: מחליף את מחרוזת סוכן המשתמש שנשלחת בבקשות אל Cloud Monitoring. רלוונטי רק למדדים. ברירת המחדל היא מספר ה-build והגרסה של OpenTelemetry Collector, למשלopentelemetry-collector-contrib 0.140.0. -
endpoint: מגדיר את נקודת הקצה שאליה יישלחו נתוני המדדים. -
use_insecure: אם הערך הוא true, נעשה שימוש ב-gRPC כפרוטוקול התקשורת. ההשפעה של המאפיין הזה מתרחשת רק אם הערך שלendpointהוא לא ''. -
grpc_pool_size: הגדרת הגודל של מאגר החיבורים בלקוח gRPC. -
prefix: הגדרת הקידומת של המדדים שנשלחים לשירות המנוהל ל-Prometheus. ברירת המחדל היאprometheus.googleapis.com. אל תשנו את הקידומת הזו, אחרת לא תוכלו להריץ שאילתות על המדדים באמצעות PromQL בממשק המשתמש של Cloud Monitoring.
ברוב המקרים, אין צורך לשנות את ערכי ברירת המחדל האלה. אבל אפשר לשנות אותן כדי להתאים אותן לנסיבות מיוחדות.
כל ההגדרות האלה מוגדרות בבלוק metric בקטע googlemanagedprometheus של הכלי לייצוא, כמו בדוגמה הבאה:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
exporters:
googlemanagedprometheus:
metric:
compression: gzip
user_agent: opentelemetry-collector-contrib 0.140.0
endpoint: ""
use_insecure: false
grpc_pool_size: 1
prefix: prometheus.googleapis.com
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection]
exporters: [googlemanagedprometheus]
המאמרים הבאים
- שימוש ב-PromQL ב-Cloud Monitoring כדי לשלוח שאילתות על מדדי Prometheus.
- שימוש ב-Grafana כדי לשלוח שאילתות על מדדי Prometheus.
- מגדירים את OpenTelemetry Collector כסוכן sidecar ב-Cloud Run.
-
בדף Metrics Management ב-Cloud Monitoring יש מידע שיכול לעזור לכם לשלוט בסכום שאתם מוציאים על מדדים שניתנים לחיוב, בלי לפגוע ביכולת הצפייה. בדף Metrics Management מופיע המידע הבא:
- נפחי ההטמעה לחיוב על בסיס בייט ועל בסיס דגימה, בדומיינים של מדדים ובמדדים נפרדים.
- נתונים על תוויות ועוצמה של מדדים.
- מספר הקריאות לכל מדד.
- שימוש במדדים במדיניות התראות ובמרכזי בקרה בהתאמה אישית.
- שיעור השגיאות בכתיבת מדדים.
אפשר גם להשתמש בדף ניהול מדדים כדי להחריג מדדים לא נחוצים, וכך לבטל את העלות של ההטמעה שלהם. מידע נוסף על הדף ניהול מדדים זמין במאמר איך רואים ומנהלים את השימוש במדדים.