
本文說明如何設定 LangGraph ReAct 代理程式,或使用 Agent Development Kit (ADK) 架構建構的生成式 AI 代理程式,將多模態提示和回應傳送至 Google Cloud 專案。同時也會說明如何查看、分析及評估儲存的多模態媒體:
您可以在「追蹤記錄探索器」頁面中查看個別提示或回覆,也可以查看整段對話。您可以選擇以算繪或原始格式查看媒體。詳情請參閱「查看多模態提示和回覆」。
使用 BigQuery 服務分析多模態資料。舉例來說,您可以使用
AI.GENERATE等函式來總結對話。詳情請參閱「使用 BigQuery 分析提示和回應資料」。使用 Vertex AI SDK 評估對話。舉例來說,您可以使用 Google Colaboratory 執行情緒分析。詳情請參閱「使用 Colaboratory 評估提示-回應資料」。
可收集的媒體類型
您可以收集下列類型的媒體:
- 音訊。
- 文件。
- 圖片。
- 純文字和 Markdown 格式的文字。
- 。
提示和回覆可以包含內嵌內容和連結。連結可指向公開資源或 Cloud Storage bucket。
提示和回覆的儲存位置
當代理程式應用程式建立或接收提示或回應時,應用程式使用的 SDK 會叫用 OpenTelemetry 檢測。這項檢測會根據 OpenTelemetry GenAI 語意慣例 1.37.0 版,格式化提示和回應,以及其中可能包含的多模態資料。也支援較新版本。
接著,OpenTelemetry 檢測功能會執行下列操作:
這項功能會為提示和回應資料建立物件 ID,然後將資料寫入 Cloud Storage 值區。 Cloud Storage bucket 中的項目會以 JSON Lines 格式儲存。
這項服務會將記錄和追蹤資料傳送至您的 Google Cloud 專案,由 Logging 和 Trace 服務擷取及儲存資料。OpenTelemetry 語意慣例會決定附加至記錄檔項目或追蹤記錄範圍的許多屬性和欄位。
OpenTelemetry 檢測工具建立 Cloud Storage bucket 物件時,也會寫入包含這些物件參照的記錄項目。以下範例顯示部分記錄項目,其中包含物件參照:
{ ... "labels": { "gen_ai.system": "vertex_ai", "event.name": "gen_ai.client.inference.operation.details", "gen_ai.output.messages_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_output.jsonl", "gen_ai.system_instructions_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_system_instructions.jsonl", "gen_ai.input.messages_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_input.jsonl" }, "logName": "projects/my-project/logs/gen_ai.client.inference.operation.details", "trace": "projects/my-project/traces/963761020fc7713e4590cad89ad03229", "spanId": "1234512345123451", ... }在記錄項目範例中,請注意下列事項:
"event.name": "gen_ai.client.inference.operation.details"標籤表示記錄項目包含 Cloud Storage 物件的參照。- 鍵包含
gen_ai的標籤會參照 Cloud Storage 值區中的物件。 - 所有包含物件參照的記錄項目都會寫入同一個記錄,該記錄名為
projects/my-project/logs/gen_ai.client.inference.operation.details。
如要瞭解如何顯示包含物件參照的記錄項目,請參閱本文的「尋找參照提示和回應的所有記錄項目」一節。
收集多模態提示和回覆
應用程式使用的 SDK 會自動叫用 OpenTelemetry,儲存提示和回覆,並將記錄和追蹤記錄資料傳送至 Google Cloud 專案。您不需要修改應用程式。不過,您需要設定Google Cloud 專案和使用的 SDK。
如要從應用程式收集及查看多模態提示和回覆,請按照下列步驟操作:
設定專案:
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI, Cloud Storage, Telemetry, Cloud Logging, and Cloud Trace APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. 確認您有 Cloud Storage bucket。視需要建立 Cloud Storage bucket。
建議您採取下列做法:
建立 Cloud Storage 值區時,請與儲存應用程式記錄資料的記錄值區位於相同位置。這項設定可提高 BigQuery 查詢效率。
請確認 Cloud Storage bucket 的儲存空間類別支援外部資料表。這項功能可讓您使用 BigQuery 查詢提示和回應。如果您不打算為新的 Cloud Storage bucket 使用預設設定,請先參閱「建立 Cloud Storage 外部資料表」,再建立 bucket。
將 Cloud Storage 值區的保留期限設為與儲存記錄檔項目的記錄檔值區保留期限相同。記錄資料的預設保留期限為 30 天。如要瞭解如何設定 Cloud Storage bucket 的保留期限,請參閱bucket 鎖定。
授予應用程式使用的服務帳戶 Cloud Storage bucket 的
storage.objects.create權限。這項權限可讓應用程式將物件寫入 Cloud Storage 值區。這些物件會儲存代理程式應用程式建立或接收的提示和回覆。詳情請參閱「在 bucket 上設定及管理 IAM 政策」。
-
設定 SDK:
安裝及升級下列依附元件:
ADK
google-adk>=1.16.0opentelemetry-instrumentation-google-genai>=0.4b0fsspec[gcs]
LangGraph
opentelemetry-instrumentation-vertexai==2.2b0(或更新版本)opentelemetry-instrumentation-google-genai>=0.4b0fsspec[gcs]
如果您使用 ADK,請更新應用程式的叫用項目,開啟
otel_to_cloud旗標:如果您使用 ADK 的 CLI,請執行下列指令:
adk web --otel_to_cloud [other options]否則,請在建立 FastAPI 應用程式時傳遞旗標:
get_fast_api_app(..., otel_to_cloud=True)
請設定下列環境變數:
指示 OpenTelemetry 將 Cloud Storage 物件格式設為 JSON Lines。
OTEL_INSTRUMENTATION_GENAI_UPLOAD_FORMAT='jsonl'指示 OpenTelemetry 上傳提示和回應資料,而非將這些內容嵌入追蹤範圍。記錄項目會包含上傳物件的參照。
OTEL_INSTRUMENTATION_GENAI_COMPLETION_HOOK='upload'指示 OpenTelemetry 使用生成式 AI 的最新語意慣例。
OTEL_SEMCONV_STABILITY_OPT_IN='gen_ai_latest_experimental'指定物件的路徑:
OTEL_INSTRUMENTATION_GENAI_UPLOAD_BASE_PATH='gs://STORAGE_BUCKET/PATH'在上述運算式中,STORAGE_BUCKET 是指 Cloud Storage bucket 的名稱。PATH 是指物件的儲存路徑。
如果是 LangGraph ReAct 代理程式,請指示 OpenTelemetry 自動擷取記錄檔資料:
OTEL_PYTHON_LOGGING_AUTO_INSTRUMENTATION_ENABLED='true'
查看多模態提示和回覆
為判斷要顯示的提示和回覆,Cloud Trace 會發出查詢,讀取記錄檔資料和儲存在 Cloud Storage 值區中的資料。您在查詢資源中的 Identity and Access Management (IAM) 角色,會決定是否傳回資料。有時您可能會看到錯誤訊息。舉例來說,如果您沒有從 Cloud Storage 值區讀取資料的權限,嘗試存取該資料就會導致權限遭拒的錯誤。
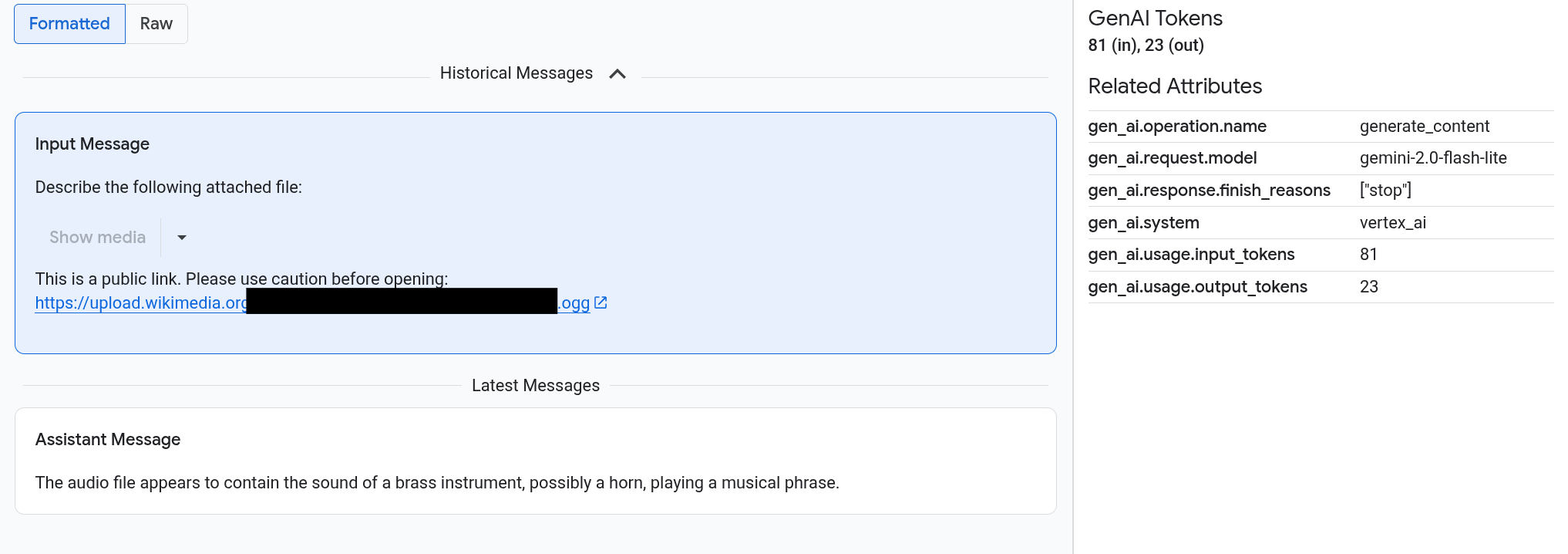
提示和回覆會以類似即時通訊的格式顯示,您可以選擇自動算繪圖片等媒體,或以來源格式顯示。同樣地,您可以查看完整的對話記錄,或只查看附加至時間範圍的提示和回覆。
舉例來說,以下範例說明提示和回覆的顯示方式,以及如何摘要 OpenTelemetry:屬性:
事前準備
如要取得查看多模態提示和回覆所需的權限,請要求管理員在專案中授予您下列 IAM 角色:
- Cloud Trace 使用者 (
roles/cloudtrace.user) -
記錄檢視器 (
roles/logging.viewer) -
Storage 物件檢視者 (
roles/storage.objectViewer)
如要進一步瞭解如何授予角色,請參閱「管理專案、資料夾和組織的存取權」。
找出包含多模態提示和回覆的範圍
如要找出包含多模態提示和回應的範圍,請執行下列操作:
-
前往 Google Cloud 控制台的「Trace Explorer」頁面:
您也可以透過搜尋列找到這個頁面。
在「範圍篩選器」窗格中,前往「範圍名稱」部分,然後選取
generate_content。或者新增篩選器
gen_ai.operation.name: generate_content。從時間範圍清單中選取時間範圍。
系統會開啟 span 的「Details」(詳細資料) 頁面。這個頁面會顯示追蹤記錄中的範圍。如果 span 名稱有標示「輸入/輸出」的按鈕
 ,表示有生成式 AI 事件。下一節「探索多模態提示和回覆」說明瞭資料的呈現方式和視覺化選項。
,表示有生成式 AI 事件。下一節「探索多模態提示和回覆」說明瞭資料的呈現方式和視覺化選項。
探索多模態提示和回覆
「輸入/輸出」分頁包含兩個部分。
一個部分會顯示提示和回應,另一個部分則會顯示「OpenTelemetry:屬性」。只有在傳送至 Trace 的時距遵循 OpenTelemetry GenAI 語意慣例 (1.37.0 以上版本) 時,這個分頁才會顯示,這會導致名稱開頭為 gen_ai 的訊息。
「輸入/輸出」分頁會以類似對話的格式顯示訊息。您可以使用分頁標籤上的選項,控制顯示的訊息和格式:
- 如要查看完整對話,請展開「歷史訊息」窗格。
- 如要只查看所選時間範圍內的提示和回覆,請使用「最新訊息」窗格。
如要查看圖片、影片或其他媒體,請選取「已格式化」。
系統不一定會顯示媒體。為保護您的安全,如果提示或回覆包含公開圖片、文件或影片的連結,您必須確認是否要顯示該媒體。同樣地,如果提示或回覆包含儲存在 Cloud Storage bucket 中的媒體,且媒體非常大,則必須確認是否要顯示媒體。
部分媒體 (例如圖片和影片) 會顯示附加選單。您可以使用這個選單執行動作,例如將圖片下載到本機磁碟機。選單選項會因媒體類型而異。
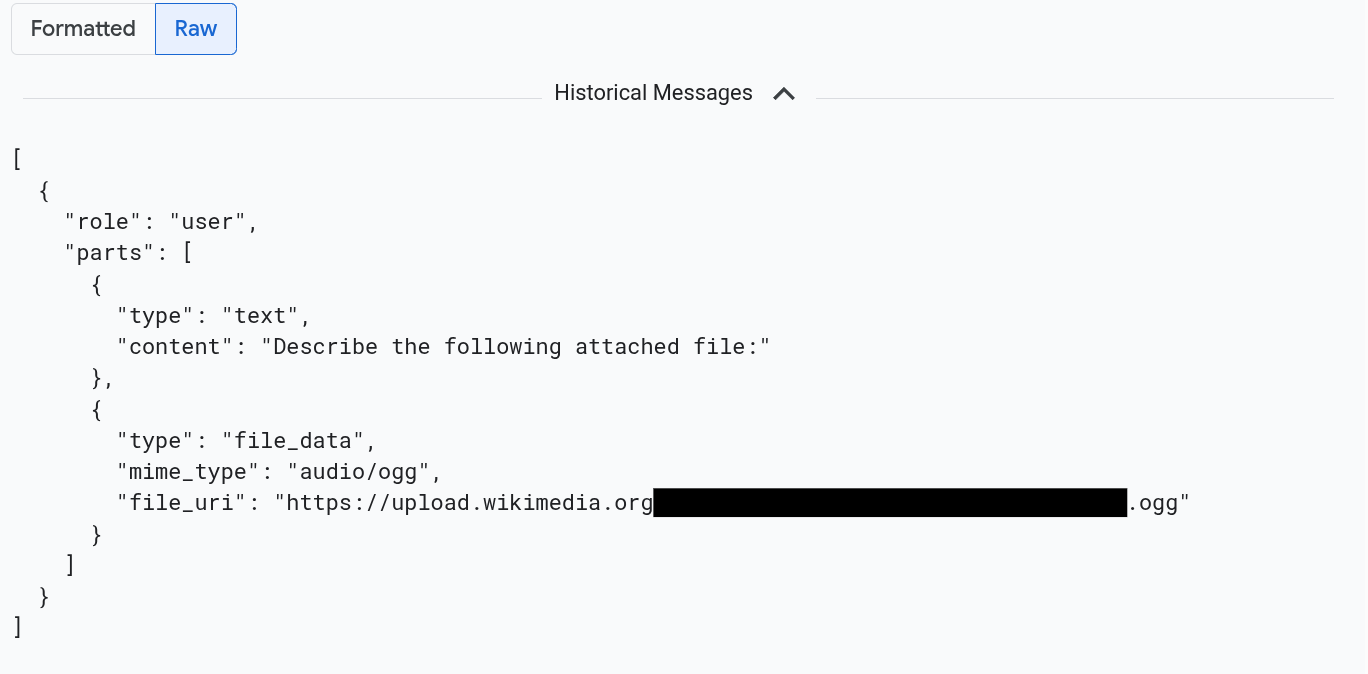
如要以 JSON 格式查看訊息,請選取「原始」。選取這個選項後,系統不會算繪圖片等媒體。
舉例來說,下圖說明對話在原始格式中的顯示方式:
找出所有參照提示和回覆的記錄項目
如要列出包含多模態提示和回應物件參照的記錄項目,請按照下列步驟操作:
-
前往 Google Cloud 控制台的「Logs Explorer」頁面:
如果您是使用搜尋列尋找這個頁面,請選取子標題為「Logging」的結果。
在專案選擇工具中選取 Google Cloud 專案。
在工具列中展開「所有記錄名稱」,在篩選器中輸入
gen_ai,然後選取名為「gen_ai.client.inference.operation.details」的記錄。上述步驟會在 Logs Explorer 中新增下列查詢:
logName="projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details"如有需要,您可以複製陳述式並貼到 Logs Explorer 的「Query」(查詢) 窗格,但請先將 PROJECT_ID 替換為專案 ID,再複製陳述式。
您也可以依標籤值篩選記錄資料。舉例來說,如果您新增下列篩選器,系統只會顯示包含指定標籤的記錄項目:
labels."event.name"="gen_ai.client.inference.operation.details"如要查看記錄項目參照的提示和回覆,請在記錄項目中按一下
 「查看追蹤記錄詳細資料」。
「查看追蹤記錄詳細資料」。如要瞭解如何使用「Inputs/Outputs」(輸入/輸出) 分頁中的選項,請參閱本文的「探索多模態提示和回覆」一節。
使用 BigQuery 分析提示和回應資料
您可以使用 BigQuery,分析 Cloud Storage 值區儲存的提示和回覆。執行這項分析前,請先完成下列步驟:
- 啟用必要 API,並確認您已獲派必要 IAM 角色。
- 在記錄 bucket 中建立連結的資料集。
- 授予 BigQuery 從 Cloud Storage 值區讀取資料的權限。
- 建立外部資料表。
建立外部資料表後,請將記錄檔儲存空間中的資料與外部資料表彙整,並對彙整後的資料執行分析。本節說明如何彙整資料表及擷取特定欄位。並說明如何使用 BigQuery ML 函式分析聯結的資料表。
事前準備
如要執行升級記錄值區和建立外部資料表等動作,您必須具備本節列出的 IAM 角色。不過,設定完成後,執行查詢所需的權限較少。
-
Enable the BigQuery and BigQuery Connection APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
如要取得設定系統所需的權限,以便在 BigQuery 中查看多模態提示和回覆,請要求管理員在專案中授予您下列 IAM 角色:
-
記錄設定寫入者 (
roles/logging.configWriter) - 儲存空間管理員 (
roles/storage.admin) -
BigQuery Connection 管理員 (
roles/bigquery.connectionAdmin) -
BigQuery 資料檢視者 (
roles/bigquery.dataViewer) -
BigQuery Studio 使用者 (
roles/bigquery.studioUser)
如要進一步瞭解如何授予角色,請參閱「管理專案、資料夾和組織的存取權」。
-
記錄設定寫入者 (
在記錄值區中建立連結的資料集
如要判斷儲存記錄資料的記錄檔 bucket 是否已升級為使用記錄檔分析,請執行下列指令:
gcloud logging buckets describe LOG_BUCKET_ID --location=LOCATION執行指令前,請先取代下列項目:
- LOG_BUCKET_ID:記錄儲存區的 ID。
- LOCATION:記錄 bucket 的位置。
記錄檔 bucket 升級為使用記錄檔分析後,
describe指令的結果會包含下列陳述式:analyticsEnabled: true如果記錄檔 bucket 未升級,請執行下列指令:
gcloud logging buckets update LOG_BUCKET_ID --location=LOCATION --enable-analytics --async升級作業可能需要幾分鐘才能完成。當
describe指令將lifecycleState回報為ACTIVE時,升級作業即完成。如要在記錄值區中建立連結的資料集,請執行下列指令:
gcloud logging links create LINKED_DATASET_NAME --bucket=LOG_BUCKET_ID --location=LOCATION執行指令前,請先取代下列項目:
- LOG_BUCKET_ID:記錄儲存區的 ID。
- LOCATION:記錄 bucket 的位置。
- LINKED_DATASET_NAME:要建立的連結資料集名稱。
BigQuery 可透過連結的資料集,讀取儲存在記錄檔 bucket 中的記錄檔資料。詳情請參閱「查詢連結的 BigQuery 資料集」。
如要確認連結是否存在,請執行下列指令:
gcloud logging links list --bucket=LOG_BUCKET_ID --location=LOCATION如果成功,前一個指令的回應會包含下列行:
LINK_ID: LINKED_DATASET_NAME
授予 BigQuery 從 Cloud Storage 值區讀取資料的權限
如要建立 BigQuery 連線,請執行下列指令:
bq mk --connection --location=CONNECTION_LOCATION --project_id=PROJECT_ID \ --connection_type=CLOUD_RESOURCE CONNECTION_ID執行指令前,請先取代下列項目:
- PROJECT_ID:專案的 ID。
- CONNECTION_ID:要建立的連線 ID。
- CONNECTION_LOCATION:連線的位置。
指令成功完成後,會顯示類似以下的訊息:
Connection 151560119848.CONNECTION_LOCATION.CONNECTION_ID successfully created確認連線。
bq show --connection PROJECT_ID.CONNECTION_LOCATION.CONNECTION_ID這項指令的回應會列出連線 ID,以及服務帳戶:
{"serviceAccountId": "bqcx-151560119848-s1pd@gcp-sa-bigquery-condel.iam.gserviceaccount.com"}授予 BigQuery 連線的服務帳戶 IAM 角色,讓服務帳戶讀取儲存在 Cloud Storage bucket 中的資料:
gcloud storage buckets add-iam-policy-binding gs://STORAGE_BUCKET \ --member=serviceAccount:SERVICE_ACCT_EMAIL \ --role=roles/storage.objectViewer執行指令前,請先取代下列項目:
- STORAGE_BUCKET:Cloud Storage bucket 的名稱。
- SERVICE_ACCT_EMAIL:服務帳戶的電子郵件地址。
建立外部 BigLake 資料表
如要使用 BigQuery 查詢 BigQuery 未儲存的資料,請建立外部資料表。由於 Cloud Storage 儲存空間會儲存提示和回覆,因此請建立 BigLake 外部資料表。
-
前往 Google Cloud 控制台的「BigQuery」BigQuery頁面:
您也可以透過搜尋列找到這個頁面。
在查詢編輯器中輸入下列陳述式:
CREATE OR REPLACE EXTERNAL TABLE `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME` ( -- Schema matching the JSON structure in a Cloud Storage bucket. parts ARRAY< STRUCT< type STRING, content STRING, -- multimodal attachments mime_type STRING, uri STRING, data BYTES, -- tool calls id STRING, name STRING, arguments JSON, response JSON > >, role STRING, `index` INT64, ) WITH CONNECTION `PROJECT_ID.CONNECTION_LOCATION.CONNECTION_ID` OPTIONS ( format = 'NEWLINE_DELIMITED_JSON', uris = ['gs://STORAGE_BUCKET/PATH/*'], ignore_unknown_values = TRUE );執行指令前,請先取代下列項目:
- PROJECT_ID:專案的 ID。
- EXT_TABLE_DATASET_NAME:要建立的資料集名稱。
- EXT_TABLE_NAME:要建立的外部 BigLake 資料表名稱。
- CONNECTION_LOCATION:CONNECTION_ID 的位置。
- CONNECTION_ID:連線 ID。
- STORAGE_BUCKET:Cloud Storage bucket 的名稱。
- PATH:提示和回覆的路徑。
OTEL_INSTRUMENTATION_GENAI_UPLOAD_BASE_PATH環境變數會指定路徑。
按一下「執行」。
如要進一步瞭解外部資料表,請參閱下列內容:
將外部資料表與記錄資料彙整
本節說明如何在 BigQuery 中分析多模態提示。這項解決方案會將外部 BigLake 資料表與記錄資料聯結,讓您從 Cloud Storage 值區擷取物件。這個範例會根據輸入訊息的 URI (gen_ai.input.messages) 進行聯結。您也可以加入輸出訊息的 URI gen_ai.output.messages,或系統指令 gen_ai.system_instructions。
如要彙整外部 BigLake 資料表與記錄檔資料,請執行下列操作:
-
前往 Google Cloud 控制台的「BigQuery」BigQuery頁面:
您也可以透過搜尋列找到這個頁面。
在查詢編輯器中輸入下列查詢,將記錄資料和外部資料表彙整到 Cloud Storage 值區項目的路徑:
-- Query the linked dataset for completion logs. FROM-- Join completion log entries with the external table. |> JOIN `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME` ON messages_ref_uri = _FILE_NAME |> RENAME `index` AS message_idx -- Flatten. |> CROSS JOIN UNNEST(parts) AS part WITH OFFSET AS part_idx -- Print fields. |> SELECT insert_id, labels, timestamp, trace, span_id, role, part.content, part.uri, part.mime_type, TO_HEX(MD5(part.data)) AS data_md5_hex, part.id AS tool_id, part.name AS tool_name, part.arguments AS tool_args, part.response AS tool_response, message_idx, part_idx, |> ORDER BY timestamp, message_idx, part_idx; |> LIMIT 10;PROJECT_ID.LINKED_DATASET_NAME._AllLogs|> WHERE log_name = 'projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details' AND timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY) |> SELECT insert_id, timestamp, labels, trace, span_id, STRING(labels['gen_ai.input.messages_ref']) AS messages_ref_uri執行查詢前,請替換下列項目:
- PROJECT_ID:專案的 ID。
- LINKED_DATASET_NAME:連結資料集的名稱。
- EXT_TABLE_DATASET_NAME:外部 BigLake 資料表的資料集名稱。
- EXT_TABLE_NAME:外部 BigLake 資料表的名稱。
選用:先前的查詢會依記錄名稱和時間戳記篩選。如要依特定追蹤 ID 篩選,請在
WHERE子句中加入下列陳述式:AND trace = 'projects/PROJECT_ID/traces/TRACE_ID'在先前的運算式中,請將 TRACE_ID 替換為包含追蹤 ID 的 16 位元組十六進位字串。
使用 BigQuery ML 函式
您可以對儲存在 Cloud Storage 儲存空間的提示和回覆,使用 BigQuery ML 函式,例如 AI.GENERATE。
舉例來說,下列查詢會將完成記錄項目與外部資料表聯結、扁平化並篩選聯結結果。接著,提示會執行 AI.GENERATE,分析項目是否包含圖片,並產生每個項目的摘要:
-- Query the linked dataset for completion logs.
FROM PROJECT_ID.LINKED_DATASET_NAME._AllLogs
|> WHERE
log_name = 'projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details'
AND timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY)
|> SELECT
insert_id,
timestamp,
labels,
trace,
span_id,
STRING(labels['gen_ai.input.messages_ref']) AS messages_ref_uri
-- Join completion log entries with the external table.
|> JOIN `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME`
ON messages_ref_uri = _FILE_NAME
|> RENAME `index` AS message_idx
-- Flatten.
|> CROSS JOIN UNNEST(parts) AS part WITH OFFSET AS part_idx
|> WHERE part.uri IS NOT NULL AND part.uri LIKE 'gs://%'
|> LIMIT 10
-- Use natural language to search for images, and then summarize the entry.
|> EXTEND
AI.GENERATE(
(
'Describe the attachment in one sentence and whether the image contains a diagram.',
OBJ.FETCH_METADATA(OBJ.MAKE_REF(part.uri, 'CONNECTION_LOCATION.CONNECTION_ID'))),
connection_id => 'CONNECTION_LOCATION.CONNECTION_ID',
endpoint => 'gemini-2.5-flash-lite',
output_schema => 'description STRING, is_match BOOLEAN') AS gemini_summary
|> SELECT insert_id, trace, span_id, timestamp, part_idx, part.uri, part.mime_type, gemini_summary
|> WHERE gemini_summary.is_match = TRUE
|> ORDER BY timestamp DESC
執行查詢前,請替換下列項目:
- PROJECT_ID:專案的 ID。
- LINKED_DATASET_NAME:連結資料集的名稱。
- EXT_TABLE_DATASET_NAME:外部 BigLake 資料表的資料集名稱。
- EXT_TABLE_NAME:外部 BigLake 資料表的名稱。
- CONNECTION_LOCATION:CONNECTION_ID 的位置。
- CONNECTION_ID:連線 ID。
使用 Colaboratory 評估提示-回應資料
您可以使用 Python 適用的 Vertex AI SDK 評估提示和回覆。
如要使用 Google Colaboratory 筆記本執行評估,請按照下列步驟操作:
如要查看範例筆記本,請按一下
evaluating_observability_datasets.ipynb。GitHub 會開啟並顯示筆記本的使用說明。
選取「在 Colab 中開啟」。
Colaboratory 會開啟並顯示
evaluating_observability_datasets.ipynb檔案。按一下工具列中的「複製到雲端硬碟」。
Colaboratory 會建立筆記本副本,並儲存至您的雲端硬碟,然後開啟副本。
在副本中,前往「設定 Google Cloud 專案資訊」一節,然後輸入 Google Cloud 專案 ID 和 Vertex AI 支援的地區。 舉例來說,您可以將位置設為
"us-central1"。前往「Load in Google Observability Gen AI datasets」(載入 Google Observability Gen AI 資料集) 一節,然後輸入下列來源的值:
- INPUT_SOURCE
- OUTPUT_SOURCE
- SYSTEM_SOURCE
您可以使用附加至記錄項目的
gen_ai標籤,找出這些欄位的值。舉例來說,INPUT_SOURCE 的值類似於下列內容:'gs://STORAGE_BUCKET/PATH/REFERENCE_inputs.jsonl'在上述運算式中,各個欄位的意義如下:
- STORAGE_BUCKET:Cloud Storage bucket 的名稱。
- PATH:提示和回覆的路徑。
- REFERENCE:Cloud Storage bucket 中資料的 ID。
如要瞭解如何找出這些來源的值,請參閱「找出參照提示和回應的所有記錄項目」。
按一下工具列中的「全部執行」。