
本文說明如何建立及最佳化脈絡資料集,協助資料代理程式應用程式在 QueryData 查詢中獲得高準確率。情境工程代理程式可自動建立及最佳化情境集,協助您建構、評估及改善情境集。
如要瞭解脈絡集和 QueryData,請參閱「脈絡集總覽」和「QueryData 總覽」。如要建構企業級資料應用程式,文字轉 SQL 模型通常需要達到近乎 100% 的準確率。不正確的查詢結果會影響整體應用程式可用性和使用者體驗。如要取得可解釋、與業務相關且準確率高的答案,需要進行情境工程,也就是建立並反覆疊代情境,以達到最佳準確率。
提供以業務應用程式為目標的 QueryData,即可為系統提供精確的業務規則,用來解決細微的使用者意圖。
脈絡工程代理
脈絡工程代理會自動執行這項最佳化工作流程。您可以與代理程式對話,處理臨時工作,進而最佳化情境。下表列出可指示代理程式的自然語言提示範例,以及代理程式的回應說明。請參考下列範例,建構及最佳化脈絡:
- 失敗分析的提示範例:「更新背景資訊,以便正確識別『迪士尼世界航班』等查詢的機場。」代理程式會分析失敗原因、推斷差距,並建議新增適當的內容項目,例如值搜尋查詢。
- 情境建議的範例提示:「Read my app code and suggest some context to add.」(閱讀我的應用程式程式碼,並建議要加入的情境。)代理程式會剖析程式碼、推斷應用程式的網域,並建議相關的內容項目。
- 大量處理的提示範例:「以下是 10 個問題和 SQL 查詢範例。將其轉換為範本。」代理會大量處理輸入內容,並更新內容集。
黃金資料集的重要性
如要最佳化情境,請先建立與應用程式自然語言輸入內容相符的資料集。代理程式可協助您建立黃金資料集,其中包含使用者問題和預期的資料庫查詢。最佳資料集可讓您:
- 建立查詢效能基準。
- 根據真值資料庫查詢驗證更新。
- 在各個疊代中,評估準確度提升幅度。
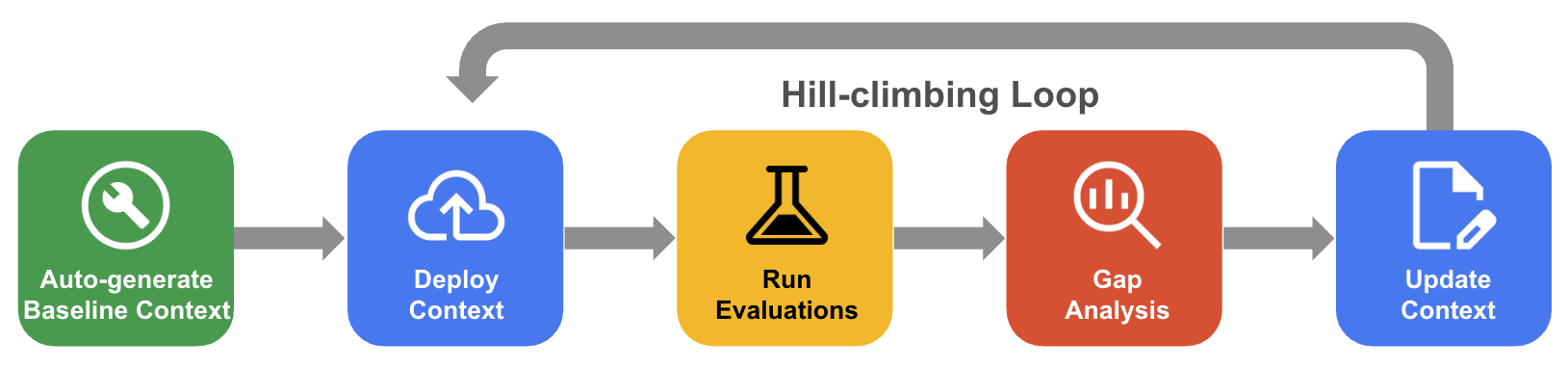
系統性的爬山程序
在系統性爬山演算法中,代理程式會透過評估黃金資料集、差距分析和更新,反覆改良內容集,將準確度提升至接近 100%。
- 自動產生基準環境:根據資料庫結構定義和應用程式構件,建立衍生起始環境集。
- 爬山演算法最佳化工作流程:讓代理程式評估 QueryData 的準確率、對失敗進行差距分析,並自動建議改善措施,以提高準確率。
下圖顯示系統性的爬山演算法工作流程:
事前準備
使用情境工程代理程式前,請先完成下列先決條件。
啟用必要服務
為專案啟用下列服務:準備 Cloud SQL 執行個體
- 請確認您有權存取現有的 Cloud SQL 執行個體,或建立新的執行個體。 詳情請參閱為 Cloud SQL 建立執行個體。
- 請務必在執行個體中建立資料庫,並在其中建立資料表。詳情請參閱在 Cloud SQL 執行個體上建立資料庫。
必要角色和權限
- 在執行個體層級新增 IAM 使用者或服務帳戶。詳情請參閱「為使用者、服務帳戶或群組新增 IAM 政策繫結」。
- 在專案層級將
cloudsql.studioUser、cloudsql.instanceUser和geminidataanalytics.queryDataUser角色授予 IAM 使用者或服務帳戶。詳情請參閱「為專案新增 IAM 政策繫結」。 - 您必須請具備權限的使用者將資料庫權限授予 IAM 使用者或服務帳戶。
GRANT SELECT PRIVILEGES ON * TO "IAM_USERNAME";
詳情請參閱「將資料庫權限授予個別 IAM 使用者或服務帳戶」。
授予 Cloud SQL 執行個體 executesql 權限
如要將 executesql 權限授予 Cloud SQL 執行個體,並啟用 Cloud SQL Data API,請執行下列指令:
gcloud config set project PROJECT_ID gcloud components update gcloud beta sql instances patch INSTANCE_ID --data-api-access=ALLOW_DATA_API
PROJECT_ID:專案的 ID。 Google CloudINSTANCE_ID:Cloud SQL 執行個體的 ID。
準備資料庫以進行值搜尋
如要使用語意和三元值搜尋,您必須設定 MySQL 適用的 Cloud SQL 執行個體,支援向量嵌入和 n 元索引。
如要讓 MySQL 適用的 Cloud SQL 執行個體執行語意值搜尋,請啟用下列旗標。
啟用
cloudsql_vector旗標。gcloud sql instances patch INSTANCE_NAME --database-flags=cloudsql_vector=on啟用
enable-google-ml-integration旗標,讓 MySQL 適用的 Cloud SQL 執行個體與 Vertex AI 整合。gcloud sql instances patch INSTANCE_NAME --enable-google-ml-integration建立向量資料欄來儲存城市嵌入
ALTER TABLE `airports` ADD COLUMN `city_embedding` VECTOR(768);生成及儲存城市名稱的向量嵌入
UPDATE `airports` SET `city_embedding` = mysql.ml_embedding('text-embedding-005', `city`) WHERE `city` IS NOT NULL;
如要讓 MySQL 適用的 Cloud SQL 執行個體執行三元值搜尋,請按照下列步驟操作:
啟用
ngram_token_size旗標。gcloud sql instances patch INSTANCE_NAME --database-flags=ngram_token_size=3為機場名稱建立三元組比對的 FULLTEXT 索引:
CREATE FULLTEXT INDEX `idx_ngram_airports_name` ON `airports`(`name`) WITH PARSER ngram;
準備環境
您可以從任何本機開發環境或 IDE 建構脈絡集檔案。如要準備環境,請完成下列步驟:
- 安裝脈絡工程代理程式
- 設定資料庫連線
安裝脈絡工程代理程式
脈絡工程代理會執行 Model Context Protocol (MCP) 伺服器,需要 uv 管理基礎 Python 封裝。
請按照「安裝
uv」一文中的說明安裝uv。確認已安裝
uv,且可從指令列存取:uv --version
如要準備環境,請在選取的代理駕馭系統 (例如 Antigravity CLI、Claude Code 或 Gemini CLI) 中安裝脈絡工程代理。
根據所選的代理程式架構,按照對應的安裝步驟操作:
Antigravity CLI
如要在 Antigravity CLI 中安裝背景資訊工程代理程式,請按照下列步驟操作:
- 安裝 Antigravity CLI。請參閱「開始使用 Antigravity CLI」。
- 安裝內容工程代理外掛程式,其中包含內容生成工作流程。將 VERSION 替換為所需的發布版本:
agy plugin install https://github.com/GoogleCloudPlatform/db-context-enrichment/tree/VERSION
- 啟動 Antigravity CLI:
agy
- 選用。更新外掛程式:
agy plugin uninstall google-cloud-db-context-engineering agy plugin install https://github.com/GoogleCloudPlatform/db-context-enrichment/tree/NEW_VERSION
Claude Code
如要在 Claude Code 中安裝背景資訊工程代理程式,請按照下列步驟操作:
- 新增外掛程式市集:
/plugin marketplace add https://github.com/GoogleCloudPlatform/db-context-enrichment.git
- 安裝外掛程式:
/plugin install db-context-engineering@db-context-enrichment-marketplace
- 重新載入外掛程式,啟用變更:
/reload-plugins
- 選用。更新外掛程式:
/plugin update db-context-engineering@db-context-enrichment-marketplace
Gemini CLI (已淘汰)
如要在 Gemini CLI 中安裝脈絡工程代理程式,請按照下列步驟操作:
- 安裝 Gemini CLI。請參閱「開始使用 Gemini CLI」。
- 安裝擴充功能:
gemini extensions install https://github.com/GoogleCloudPlatform/db-context-enrichment
- 選用。更新擴充功能:
gemini extensions update mcp-db-context-enrichment
設定資料庫連線
代理程式需要資料庫連線才能擷取結構定義,並驗證產生的 SQL 內容語法。如要讓代理程式與資料庫互動,請設定驗證憑證,並定義資料庫連線設定。
設定應用程式預設憑證
設定應用程式預設憑證 (ADC),提供使用者憑證,以便從內容工程代理程式存取 Google Cloud 資源:
- Toolbox MCP 伺服器:使用憑證連線至資料庫、擷取結構定義,並執行 SQL 進行驗證。
- Evalbench:使用憑證叫用 QueryData 進行評估。
在終端機中執行下列指令來進行驗證:
gcloud auth application-default login設定資料庫連線檔案
代理需要資料庫連線才能生成脈絡,而 MCP Toolbox 支援這項功能,並在設定檔中定義。
設定檔會指定資料庫來源,以及擷取結構定義或執行 SQL 時所需的工具。情境工程代理程式預先安裝了代理程式技能,可協助您產生設定。
啟動代理程式環境。
請服務專員協助設定資料庫連線,例如提示「幫我設定資料庫連線」。按照代理程式的指示,在目前的工作目錄中建立設定檔,並命名為
autoctx/tools.yaml。如要套用新的
tools.yaml設定,請重新載入連線:- 在 Antigravity CLI 中執行
/mcp,然後選取toolbox重新啟動。 - 在 Gemini CLI 中執行
/mcp reload。 - 在 Cloud Code 中執行
/mcp,選取toolbox,然後選取Reconnect。
- 在 Antigravity CLI 中執行
如要進一步瞭解如何手動設定資料庫設定檔,請參閱「MCP Toolbox 設定」。
生成及最佳化背景資訊
內容工程代理提供一系列代理技能和 MCP 工具,可提升程式設計代理的內容工程能力。您可以一併使用這些工具產生基準、評估成效,並反覆套用改善措施。不過,您可以在工作流程的任何階段開始:
- 如果已設定環境,可以直接進行評估。
- 如有要修正的失敗查詢,可以直接進行差距分析。
每項功能都會說明代理程式的動作、用途和叫用指令。
範例提示說明如何以自然語言查詢代理程式。如果代理程式需要更多詳細資料才能完成要求,系統會提示你提供說明。
建立及擴充評估資料集
如要提升成效,請先評估成效。如果沒有黃金資料集 (包含使用者問題和預期 SQL),脈絡工程就缺乏系統性驗證。有了黃金資料集,您就能根據基準真相驗證每項變更,並評估改善成效。
手動建立代表性的黃金資料集非常耗時,而且小型資料集可能會遺漏使用者措辭的變化。服務專員會採取下列行動解決問題:
- 根據資料庫結構定義生成候選問題/SQL 配對。
- 使用篩選器變化、同義詞和改寫內容,擴充小型種子資料集。
您可以選擇讓代理對資料庫執行產生的 SQL。這項驗證可確保查詢順利執行,再將查詢新增至資料集。
資料集是 JSON 檔案,內含問題和 SQL 查詢配對:
[
{
"id": "example_001",
"nlq": "What is the total revenue for the top 5 products?",
"golden_sql": "SELECT product_id, sum(net_revenue) FROM sales GROUP BY product_id ORDER BY sum(net_revenue) DESC LIMIT 5;"
}
]
核准的配對會填入工作區的 autoctx/golden.json 檔案,即可進行評估。您可以提供現有檔案,或直接編寫一些評估範例,供代理程式擴充。
您可以使用下列範例提示指示代理程式:
- 「根據我的結構定義生成評估資料集。」
- 「這是種子問題和 SQL,請將其擴展為更廣泛的資料集,並驗證查詢是否執行。」
產生基準脈絡資料集
為避免從頭建立內容,您可以讓 AI 代理從資料庫結構定義和應用程式構件 (例如業務規則、範例查詢或 README 檔案) 衍生初始內容集。雖然這個基準環境並非最終版本,但可做為經過驗證的起點,並以資料庫模型為基礎。
您可以使用下列範例提示指示代理程式:
- 「Generate a context set from my schema.」
- 「使用這些結構定義和
requirements.md中的業務規則,產生初始背景資訊。」
代理程式會提示您為實驗命名,以整理產生的構件,如果資料庫結構定義很大,代理程式可能會要求您縮小範圍。如要使用 Cloud SQL Studio 上傳內容,請在代理程式產生 JSON 檔案後,按照操作說明進行。
評估情境成效
建立情境集和黃金資料集後,您可以透過每個黃金問題查詢資料代理程式的 QueryData API,讓代理程式評估情境成效。代理程式會使用 Evalbench 處理比較作業,將生成的 SQL 查詢及其執行結果與預期答案進行比較。
執行評估作業可提供下列資訊:
- 量化指標,例如通過和失敗結果,以及匯總分數,可追蹤各情境疊代的進度。
- 實驗資料夾的
eval_reports/目錄中,會提供內嵌對話摘要和詳細的 CSV 報表。
如要開始評估,請提供黃金資料集路徑和內容集 ID。如要瞭解如何找出內容集 ID,請參閱「找出代理程式內容 ID」。
您可以使用下列範例提示指示代理程式:
- 「請根據
golden.json評估我的背景資訊。」 - 「使用上次實驗的設定重新執行評估。」
如要重新執行先前產生的評估設定,不必再次設定,請詢問代理程式或直接叫用 CLI:
uvx google-evalbench --run_config=autoctx/experiments/my-experiment/eval_configs/run_config.json
如要進一步瞭解評估設定結構定義,以及如何自訂評估執行作業,請參閱 Evalbench 說明文件。
進行差距分析並提出改善建議
如要解決查詢失敗問題,請找出根本原因,例如資料欄不正確、缺少資料表聯結,或模糊字詞未解決。如要手動找出這些問題,必須深入分析評估報告。
代理會自動執行這項分析和修正循環:
- 差距分析:代理程式會讀取評估結果和您設定的內容,將類似的失敗分組,並建議加入目標內容,例如範本、構面或值搜尋。
- 建議修正方式:代理程式會建議具體的編輯內容,並視需要對資料庫測試 SQL,確認解決方案是否可行。
- 保留基準:代理程式會將改善項目寫入新的 JSON 檔案,並保留原始檔案。
您可以使用下列範例提示指示代理程式:
- 「Run gap analysis on my last evaluation and propose fixes.」(對上次評估執行差距分析,並提出修正建議。)
- 「針對
golden.json最佳化這組內容。」
如要準備下一次疊代,請使用 Data Agents Studio 將改良的內容上傳至目標內容集,並按照操作說明操作。
視需要取得特定作者的情境項目
如果您已知道所需內容,例如特定問題的範本、重複篩選器的構面,或特定資料欄的值搜尋,手動編寫內容 JSON 可能會在參數名稱、型別中繼資料或片段語法中,產生序列化錯誤。代理程式會處理 JSON 格式,讓您專注於業務意圖。
您也可以使用這項功能進行臨時更新,例如需要支援新的查詢模式或處理缺少的結構定義詳細資料時。如要取得 JSON,請向代理程式說明必要情境,不必執行評估或設定實驗。
當您收到一次性工作時,也適合使用這項功能:利害關係人提供一組新的問題/SQL 配對,希望獲得支援,或您在程式碼審查期間發現缺少某個層面。您不需要設定實驗或執行評估來修正問題,只要說明所需內容,代理程式就會產生 JSON。
您可以使用下列範例提示指示代理程式:
- 「Create a template for: 'Which airports are in California?' with SQL:
SELECT name FROM airports WHERE country = 'United States' AND state = 'CA'." - 「為標示為『紅眼』的篩選器
departure_time BETWEEN '00:00:00' AND '06:00:00'建立分面。」 - 「Create a value search for
airports.iata.」
選取脈絡類型的原因
無論是範本、構面或值搜尋,選取正確的內容類型都有助於防止內容膨脹和資料庫查詢迴歸。舉例來說,使用範本而非 facet 可能會導致規則重複,而引入值搜尋 (範本已足夠) 則可能會增加查詢延遲。如要找出正確的結構定義格式,請先提示代理程式根據查詢結構或資料庫資料欄建議類型,再建立內容項目。代理程式會說明推論過程,協助您瞭解選項的背景資訊。
您可以使用下列範例提示指示代理程式:
- 「我一直要在許多查詢中撰寫篩選條件。
departure_time BETWEEN '00:00:00' AND '06:00:00'如何才能拍出這種效果? - 「使用者以自由格式文字描述航班狀態,我想將這些文字與
flights.status. 我該設定哪種值搜尋?" - 「範本和構面有何不同?我應該在什麼時候使用哪一個?」
對一組內容套用大量作業
代理支援大量更新,可持續管理大型內容集。如果需要同時更新多個內容項目 (例如資料庫資料欄重新命名、程式碼值變更格式,或範本參照已淘汰的表格),代理程式可以對每個受影響的項目套用變更,而不會修改不相關的項目。
您可以使用下列範例提示指示代理程式:
- 「請閱讀
golden.txt,並將所有配對轉換為範本。」 - 「在
context_set.json中,將參照「United」的任何項目,以「airline = 'United Airlines'」取代「airline = 'UA'」。請勿變更不相關的項目。"
後續步驟
- 進一步瞭解情境集。
- 瞭解如何在 Cloud SQL Studio 中建立或刪除內容集。
- 瞭解如何測試內容集。