
「scalar subquery」屬於 SQL 子陳述式,是純量運算式的一部分。Spanner 會盡可能嘗試移除純量子查詢。不過,在某些情境下,計畫會明確包含純量子查詢。
資料庫結構定義
本頁的查詢和執行計畫是根據下列資料庫結構定義:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
您可以使用下列資料操縱語言 (DML) 陳述式,將資料新增至這些資料表:
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
下列查詢示範純量運算式運算子:
SELECT firstname,
IF(firstname = 'Alice', (SELECT Count(*)
FROM songs
WHERE duration > 300), 0)
FROM singers;
/*-----------+----+
| FirstName | |
+-----------+----+
| Alice | 1 |
| Catalina | 0 |
| David | 0 |
| Lea | 0 |
| Marc | 0 |
+-----------+----*/
執行計畫如下所示:
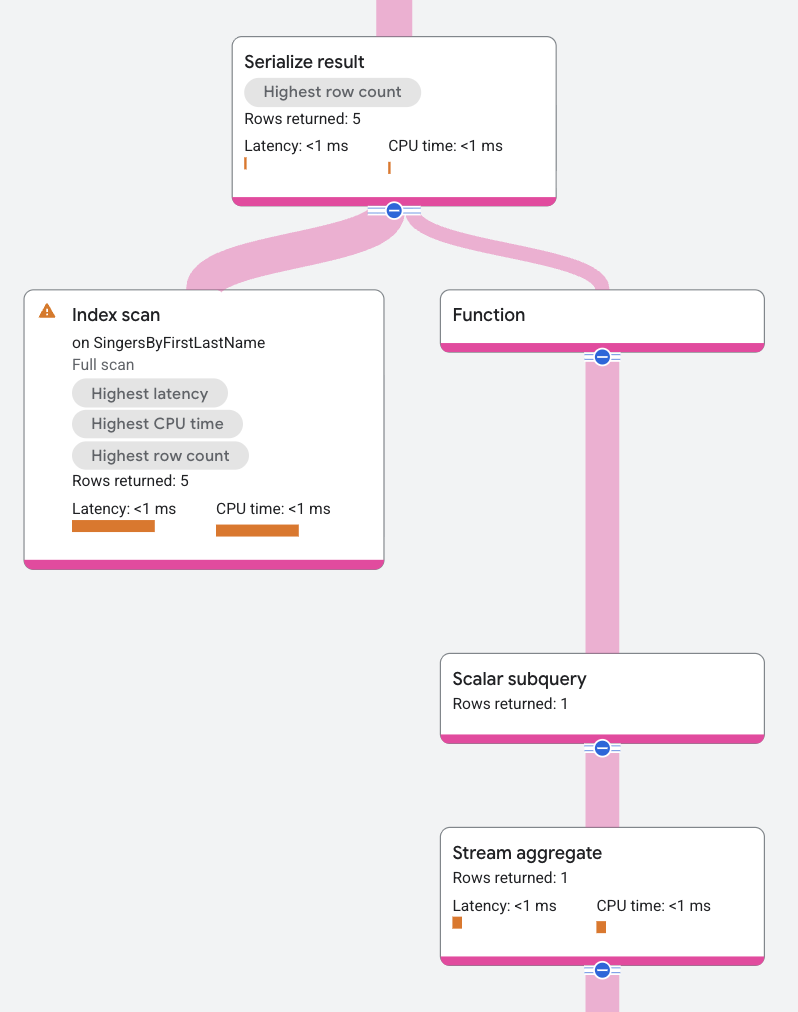
執行計畫會將純量子查詢顯示為 Scalar Subquery,位於 aggregate 運算子上方。
Spanner 有時會將純量子查詢轉換成另一個運算子,如 join 或 cross apply,以改善效能。
下列查詢會示範這個運算子:
SELECT *
FROM songs
WHERE duration = (SELECT Max(duration)
FROM songs);
/*----------+---------+---------+---------------------+----------+-----------+
| SingerId | AlbumId | TrackId | SongName | Duration | SongGenre |
+----------+---------+---------+---------------------+----------+-----------+
| 2 | 1 | 6 | Nothing Is The Same | 303 | BLUES |
+----------+---------+---------+---------------------+----------+-----------*/
執行計畫如下所示:
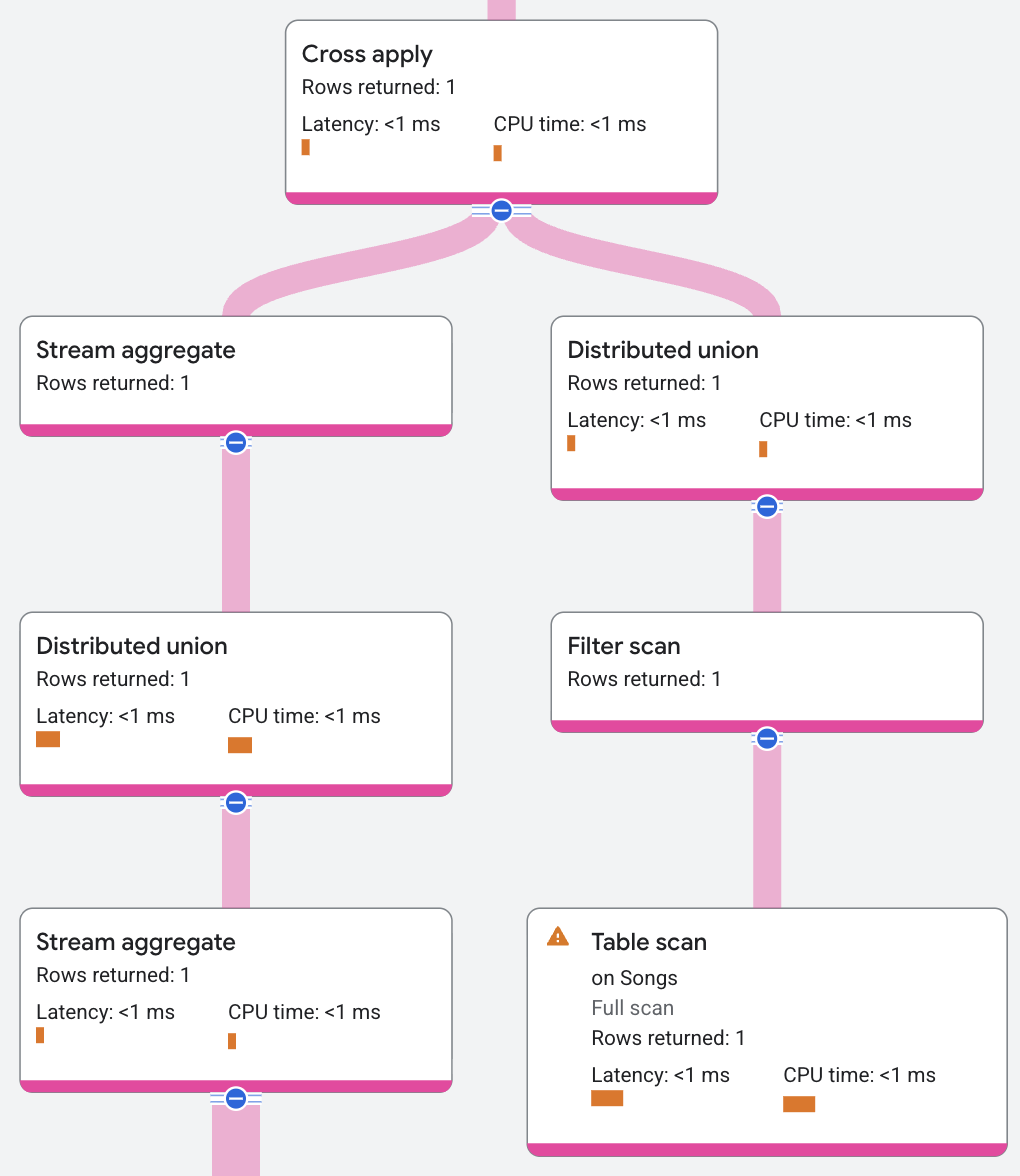
執行計畫不包含純量子查詢,因為 Spanner 已將純量子查詢轉換為交叉套用。
屬性和執行作業統計資料
運算子的屬性會說明運算子執行時使用的特徵。執行統計資料是在查詢執行期間收集的值,可協助您評估運算子的效能。
屬性
| 名稱 | 說明 |
|---|---|
| 執行方法 | 在列執行中,運算子一次處理一列。 在批次執行中,運算子會一次處理一批資料列。 |
執行作業統計資料
| 名稱 | 說明 |
|---|---|
| 延遲時間 | 運算子中所有執行作業的經過時間。 |
| 累計延遲時間 | 目前運算子及其後代的總時間。 |
| CPU 作業時間 | 執行運算子所耗費的 CPU 作業時間總和。 |
| 累計 CPU 作業時間 | 執行運算子及其後代所花費的 CPU 作業時間總計。 |
| 執行時間 | 執行查詢及處理結果所花費的總時間。 |
| 傳回的資料列數 | 這個運算子輸出的資料列數 |
| 執行作業數量 | 運算子的執行次數。部分執行作業可以平行執行。 |