
「leaf」運算子沒有子項。leaf 運算子的類型如下:
資料庫結構定義
本頁的查詢和執行計畫是根據下列資料庫結構定義:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
您可以使用下列資料操縱語言 (DML) 陳述式,將資料新增至這些資料表:
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
Array unnest
「array unnest」運算子會將輸入陣列整併到元素資料列中。每個結果資料列最多包含兩個資料欄:陣列中的值,以及陣列中以零為基礎的位置 (選用)。
下列查詢會示範這個運算子:
SELECT a, b FROM UNNEST([1,2,3]) a WITH OFFSET b;
/*---+---+
| a | b |
+---+---+
| 1 | 0 |
| 2 | 1 |
| 3 | 2 |
+---+---*/
查詢會將資料欄 a 中的陣列 [1,2,3] 整併,並且將陣列的位置顯示在資料欄 b 中。
執行計畫如下所示:
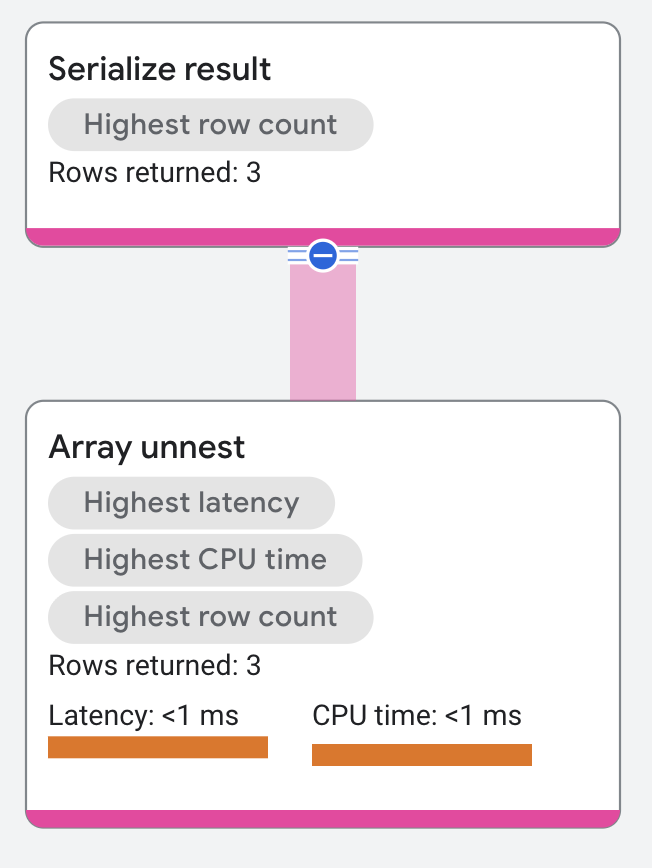
屬性和執行作業統計資料
運算子的屬性會說明運算子執行時使用的特徵。執行統計資料是在查詢執行期間收集的值,可協助您評估運算子的效能。
屬性
| 名稱 | 說明 |
|---|---|
| 執行方法 | 在列執行中,運算子一次處理一列。 在批次執行中,運算子會一次處理一批資料列。 |
執行作業統計資料
| 名稱 | 說明 |
|---|---|
| 延遲時間 | 運算子中所有執行作業的經過時間。 |
| 累計延遲時間 | 目前運算子及其後代的總時間。 |
| CPU 作業時間 | 執行運算子所耗費的 CPU 作業時間總和。 |
| 累計 CPU 作業時間 | 執行運算子及其後代所花費的 CPU 作業時間總計。 |
| 執行時間 | 執行查詢及處理結果所花費的總時間。 |
| 傳回的資料列數 | 這個運算子輸出的資料列數 |
| 執行作業數量 | 運算子的執行次數。部分執行作業可以平行執行。 |
Generate relation
「generate relation」運算子會傳回零或多個資料列。
屬性和執行作業統計資料
運算子的屬性會說明運算子執行時使用的特徵。執行統計資料是在查詢執行期間收集的值,可協助您評估運算子的效能。
屬性
| 名稱 | 說明 |
|---|---|
| 執行方法 | 在列執行中,運算子一次處理一列。 在批次執行中,運算子會一次處理一批資料列。 |
執行作業統計資料
| 名稱 | 說明 |
|---|---|
| 延遲時間 | 運算子中所有執行作業的經過時間。 |
| 累計延遲時間 | 目前運算子及其後代的總時間。 |
| CPU 作業時間 | 執行運算子所耗費的 CPU 作業時間總和。 |
| 累計 CPU 作業時間 | 執行運算子及其後代所花費的 CPU 作業時間總計。 |
| 執行時間 | 執行查詢及處理結果所花費的總時間。 |
| 傳回的資料列數 | 這個運算子輸出的資料列數 |
| 執行作業數量 | 運算子的執行次數。部分執行作業可以平行執行。 |
Unit relation
「unit relation」會傳回一個資料列。這是「generate relation」運算子的特殊案例。
下列查詢會示範這個運算子:
SELECT 1 + 2 AS Result;
/*--------+
| Result |
+--------+
| 3 |
+--------*/
執行計畫如下所示:
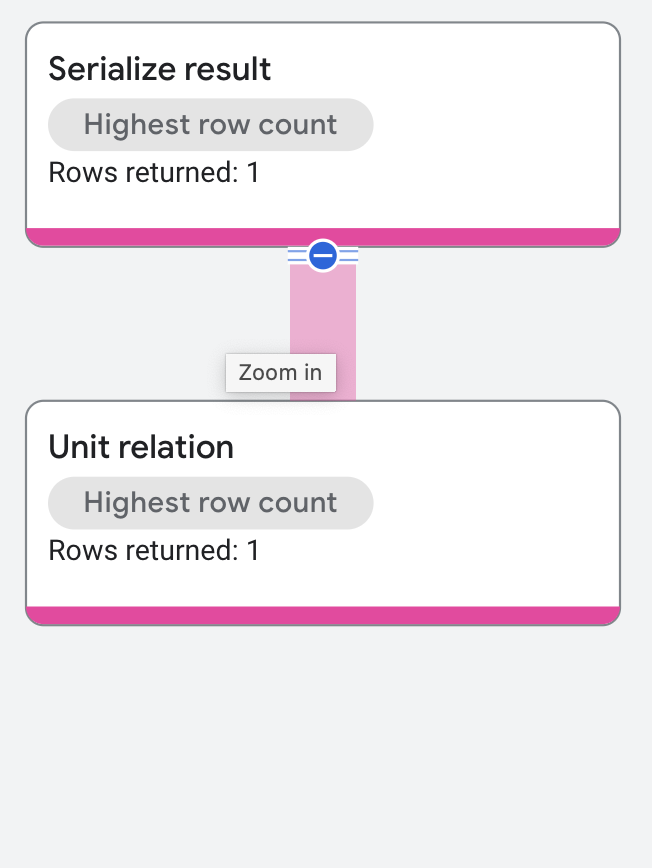
屬性和執行作業統計資料
運算子的屬性會說明運算子執行時使用的特徵。執行統計資料是在查詢執行期間收集的值,可協助您評估運算子的效能。
屬性
| 名稱 | 說明 |
|---|---|
| 執行方法 | 在列執行中,運算子一次處理一列。 在批次執行中,運算子會一次處理一批資料列。 |
執行作業統計資料
| 名稱 | 說明 |
|---|---|
| 延遲時間 | 運算子中所有執行作業的經過時間。 |
| 累計延遲時間 | 目前運算子及其後代的總時間。 |
| CPU 作業時間 | 執行運算子所耗費的 CPU 作業時間總和。 |
| 累計 CPU 作業時間 | 執行運算子及其後代所花費的 CPU 作業時間總計。 |
| 執行時間 | 執行查詢及處理結果所花費的總時間。 |
| 傳回的資料列數 | 這個運算子輸出的資料列數 |
| 執行作業數量 | 運算子的執行次數。部分執行作業可以平行執行。 |
Empty relation
「empty relation」不會傳回資料列。這是「generate relation」運算子的特殊案例。
下列查詢會示範這個運算子:
SELECT *
FROM albums
LIMIT 0
/*
No result
*/
執行計畫如下所示:
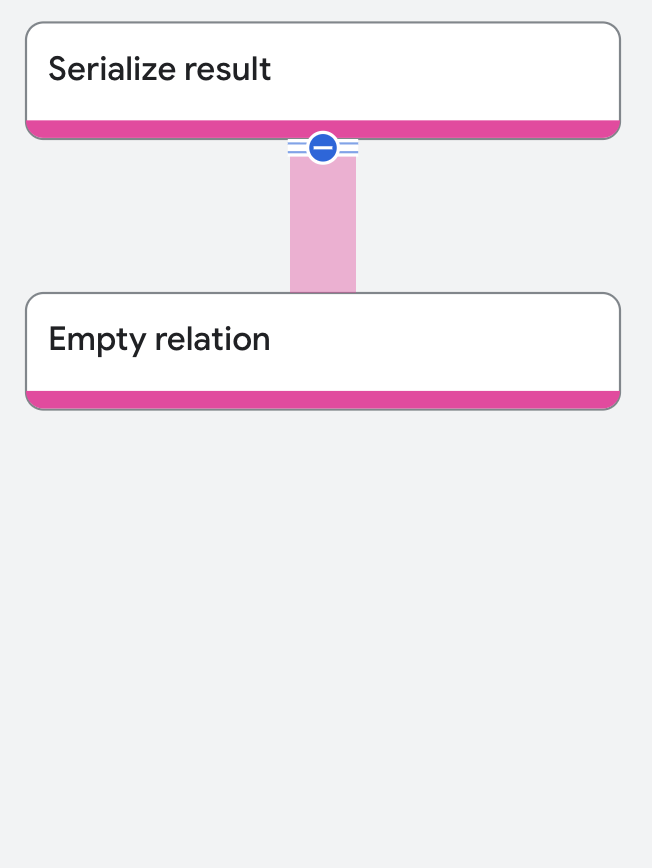
屬性和執行作業統計資料
運算子的屬性會說明運算子執行時使用的特徵。執行統計資料是在查詢執行期間收集的值,可協助您評估運算子的效能。
屬性
| 名稱 | 說明 |
|---|---|
| 執行方法 | 在列執行中,運算子一次處理一列。 在批次執行中,運算子會一次處理一批資料列。 |
執行作業統計資料
| 名稱 | 說明 |
|---|---|
| 延遲時間 | 運算子中所有執行作業的經過時間。 |
| 累計延遲時間 | 目前運算子及其後代的總時間。 |
| CPU 作業時間 | 執行運算子所耗費的 CPU 作業時間總和。 |
| 累計 CPU 作業時間 | 執行運算子及其後代所花費的 CPU 作業時間總計。 |
| 執行時間 | 執行查詢及處理結果所花費的總時間。 |
| 傳回的資料列數 | 這個運算子輸出的資料列數 |
| 執行作業數量 | 運算子的執行次數。部分執行作業可以平行執行。 |
掃描
「scan」運算子會掃描資料列來源並傳回資料列。scan 運算子的類型如下:
- 資料表掃描:掃描資料表。
- 索引掃描:掃描索引。
- 批次掃描:掃描會在其他關聯運算子建立的中繼資料表 (例如由分散式 cross apply 所建立的資料表) 上進行。
Spanner 會盡可能在索引鍵上套用述詞,做為掃描的一部分。Spanner 套用述詞後,掃描作業的執行效率會更高,因為掃描不需要讀取整個資料表或索引。述詞在執行計畫中的形式為:
- 可搜尋的條件:若 Spanner 可決定要存取資料表中的哪個資料列,便適用可搜尋的條件。一般而言,這會在 filter 位於主鍵的前置字串時發生。舉例來說,如果主鍵包含
Col1和Col2,那麼包含明確的Col1值的WHERE子句或Col1和Col2便是可搜尋的。在該情況下,Spanner 只會讀取索引鍵範圍內的值。
如果查詢必須查閱資料表中的所有資料列,就會發生完整掃描,並在執行計畫中顯示為 full scan: true。
下列查詢會示範這個運算子:
SELECT s.lastname
FROM singers@{FORCE_INDEX=SingersByFirstLastName} as s
WHERE s.firstname = 'Catalina';
/*----------+
| LastName |
+----------+
| Smith |
+----------*/
執行計畫區隔如下所示:
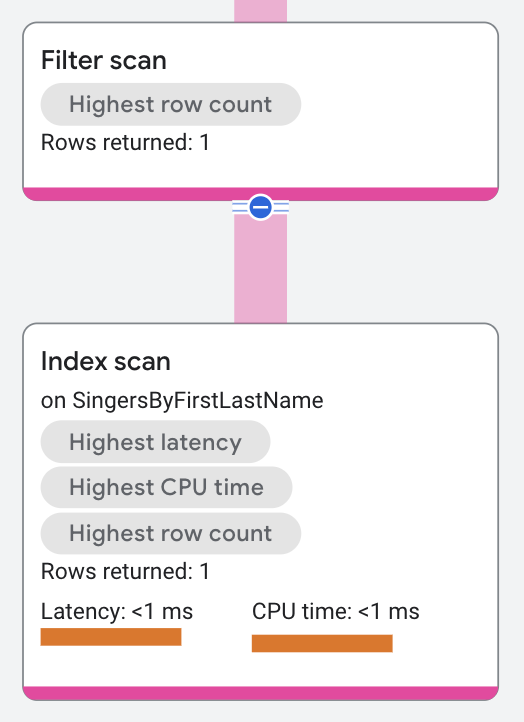
在執行計畫中,頂層的 distributed union 運算子會傳送子計畫到遠端伺服器。每個子計畫都有一個序列化結果運算子和一個索引掃描運算子。述詞 Key Predicate: FirstName = 'Catalina' 會將掃描限制在索引 SingersByFirstLastname 中,FirstName 等於 Catalina 的資料列。索引掃描會將輸出傳回 serialize result 運算子。
Spanner 會將掃描作業與「篩選掃描」緊密結合,並視為單一運算子。如果沒有「搜尋條件」,運算子會顯示為「完整掃描」。
屬性和執行作業統計資料
運算子的屬性會說明運算子執行時使用的特徵。執行統計資料是在查詢執行期間收集的值,可協助您評估運算子的效能。
「掃描」運算子具有其他不同的屬性和執行統計資料。屬性
| 名稱 | 說明 |
|---|---|
| 掃描方法 | 可以是「Row」、「Batch」或「Automatic」。在列執行中,運算子一次處理一列。在批次執行中,運算子會一次處理一批資料列。在自動執行模式中,運算子會使用「Row」方法開始掃描,但視需要可以改用「Batch」。 |
| 搜尋條件 | 主鍵上的述詞,用於有效率地查閱資料表。這項屬性表示系統不必掃描整個資料表,即可產生所需的資料列集。這項屬性僅適用於 Table Scans 和 Index Scans。 |
| 變數指派 | 從資料表讀取的資料欄清單。 |
| 執行方法 | 在列執行中,運算子一次處理一列。 在批次執行中,運算子會一次處理一批資料列。 |
執行作業統計資料
| 名稱 | 說明 |
|---|---|
| 掃描的資料列 | 掃描期間讀取的列數。 |
| 搜尋次數 | 這個掃描運算子執行的查閱或搜尋次數。 |
| 延遲時間 | 運算子中所有執行作業的經過時間。 |
| 累計延遲時間 | 目前運算子及其後代的總時間。 |
| CPU 作業時間 | 執行運算子所耗費的 CPU 作業時間總和。 |
| 累計 CPU 作業時間 | 執行運算子及其後代所花費的 CPU 作業時間總計。 |
| 執行時間 | 執行查詢及處理結果所花費的總時間。 |
| 傳回的資料列數 | 這個運算子輸出的資料列數 |
| 執行作業數量 | 運算子的執行次數。部分執行作業可以平行執行。 |
Filter scan
「filter scan」運算子一律會顯示在「table scan」或「index scan」的上方。 它會與掃描作業搭配使用,減少從資料庫讀取的資料列數,而這樣的掃描通常會比使用 filter 更快。在某些條件下,Spanner 會套用篩選掃描:
- 其餘條件:其他 Spanner 可評估掃描,以限制讀取資料量的條件。
下列查詢會示範這個運算子:
SELECT lastname
FROM singers
WHERE singerid = 1
/*----------+
| LastName |
+----------+
| Richards |
+----------*/
執行計畫如下所示:

屬性和執行作業統計資料
運算子的屬性會說明運算子執行時使用的特徵。執行統計資料是在查詢執行期間收集的值,可協助您評估運算子的效能。
「篩選掃描」運算子具有其他相異屬性。屬性
| 名稱 | 說明 |
|---|---|
| 剩餘條件 | 在讀取資料列後套用的述詞。 |
| 執行方法 | 在列執行中,運算子一次處理一列。 在批次執行中,運算子會一次處理一批資料列。 |
執行作業統計資料
| 名稱 | 說明 |
|---|---|
| 延遲時間 | 運算子中所有執行作業的經過時間。 |
| 累計延遲時間 | 目前運算子及其後代的總時間。 |
| CPU 作業時間 | 執行運算子所耗費的 CPU 作業時間總和。 |
| 累計 CPU 作業時間 | 執行運算子及其後代所花費的 CPU 作業時間總計。 |
| 執行時間 | 執行查詢及處理結果所花費的總時間。 |
| 傳回的資料列數 | 這個運算子輸出的資料列數 |
| 執行作業數量 | 運算子的執行次數。部分執行作業可以平行執行。 |