
Operadores distribuídos são executados em vários servidores, ao contrário dos operadores folha, unários, binários ou n-ários.
Os operadores a seguir são distribuídos:
- Distributed union
- Distributed apply
- União de mesclagem distribuída
- Junção do hash de transmissão push
Database schema
As consultas e os planos de execução dessa página se baseiam no esquema de banco de dados abaixo:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
É possível usar as seguintes instruções da linguagem de manipulação de dados (DML) para adicionar dados a estas tabelas:
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
O operador "distributed union" é o operador primitivo do qual se derivam o "distributed cross apply" e o "distributed outer apply".
Os operadores distribuídos aparecem em planos de execução com uma variante de distributed union acima de uma ou mais variantes de local distributed union. Uma variante de "distributed union" executa a distribuição remota de subplanos.
Uma variante de "local distributed union" está acima de cada uma das verificações executadas para a consulta. As variantes de "local distributed union" asseguram a execução estável da consulta quando ocorrem reinicializações para alterar dinamicamente os limites de divisão. Embora esse operador fique oculto no plano visual, ele está sempre presente.
Sempre que possível, uma variante de "distributed union" usa um predicado de divisão para remoção de divisão. O corte de divisão significa que os servidores remotos executam subplanos apenas em divisões que atendem ao predicado, melhorando a latência e o desempenho da consulta.
Distributed union
O operador distributed union permite separar conceitualmente uma ou mais tabelas em várias divisões, avaliar remotamente uma subconsulta de modo independente em cada divisão e, em seguida, unir todos os resultados.
A consulta a seguir demonstra esse operador:
SELECT s.songname,
s.songgenre
FROM songs AS s
WHERE s.singerid = 2
AND s.songgenre = 'ROCK';
/*-----------------+-----------+
| SongName | SongGenre |
+-----------------+-----------+
| Starting Again | ROCK |
| The Second Time | ROCK |
| Fight Story | ROCK |
+-----------------+-----------*/
O plano de execução aparece da seguinte forma:
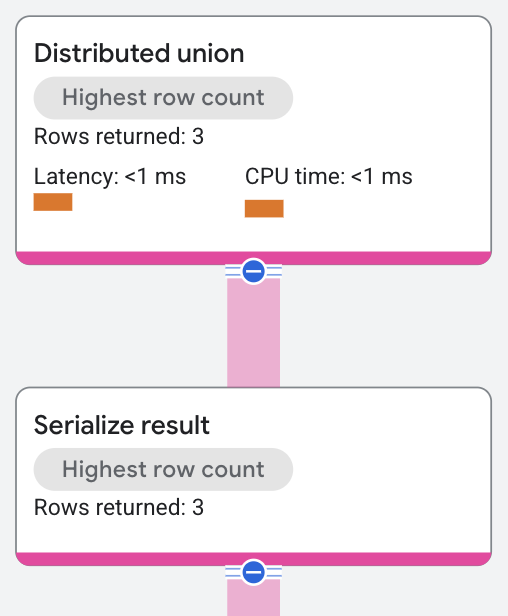
O operador "distributed union" envia subplanos a servidores remotos, que executam uma varredura de tabela em divisões que atendem ao predicado da consulta WHERE s.SingerId = 2 AND s.SongGenre = 'ROCK'.
Um operador serialize result calcula os valores SongName e SongGenre das linhas retornadas pelas varreduras de tabela. Em seguida, o operador "distributed union" retorna os resultados combinados dos servidores remotos como resultados da consulta SQL.
Propriedades e estatísticas de execução
Uma propriedade de um operador descreve uma característica usada quando o operador é executado. Uma estatística de execução é um valor coletado durante a execução da consulta para ajudar você a avaliar a performance do operador.
O operador Distributed union tem outras estatísticas de execução distintas.Propriedades
| Nome | Descrição |
|---|---|
| Método de execução | Na execução de linha, o operador processa uma linha por vez. Na execução em lote, o operador processa um lote de linhas de uma só vez. |
Estatísticas de execução
| Nome | Descrição |
|---|---|
| Execuções paralelas locais | O número de subconsultas executadas em paralelo. |
| Chamadas remotas | O número de subconsultas remotas executadas. |
| Latência | Tempo decorrido de todas as execuções feitas no operador. |
| Latência cumulativa | O tempo total do operador atual e dos descendentes dele. |
| Tempo de CPU | Soma do tempo de CPU gasto na execução do operador. |
| Tempo de CPU cumulativo | O tempo total de CPU gasto na execução do operador e dos descendentes dele. |
| Tempo de execução | O tempo total gasto para executar a consulta e processar os resultados. |
| Linhas retornadas | O número de linhas geradas por esse operador. |
| Número de execuções | O número de vezes que o operador foi executado. Algumas execuções podem ser realizadas em paralelo. |
Em geral, as execuções são paralelas, ao contrário das execuções de aplicação cruzada. Por isso, os números de latência em operadores distribuídos são cumulativos, ao contrário da maioria dos operadores, que informam quanta latência o operador adicionou. O número de execuções em uma união distribuída se baseia nos limites de divisão da tabela, que, por sua vez, dependem do tamanho e da carga dos dados e podem incluir a dica de instrução use_additional_parallelism. Essa abordagem se aplica a todos os operadores distribuídos.
Distributed apply
Um operador distributed apply (DA) estende o operador apply join por meio da execução em vários servidores. O lado de entrada agrupa linhas em lotes, ao contrário de um operador de aplicação cruzada regular, que atua em apenas uma linha de entrada por vez. O lado "map" do DA é um conjunto de operadores de junção de aplicação simples que são executados em servidores remotos. Uma junção distributed apply é compatível com os mesmos métodos de junção apply.
Propriedades e estatísticas de execução
Uma propriedade de um operador descreve uma característica usada quando o operador é executado. Uma estatística de execução é um valor coletado durante a execução da consulta para ajudar você a avaliar a performance do operador.
O operador Distributed apply tem outras estatísticas de execução distintas.Propriedades
| Nome | Descrição |
|---|---|
| Método de execução | Na execução de linha, o operador processa uma linha por vez. Na execução em lote, o operador processa um lote de linhas de uma só vez. |
Estatísticas de execução
| Nome | Descrição |
|---|---|
| Execuções paralelas locais | O número de subconsultas executadas em paralelo. |
| Chamadas remotas | O número de subconsultas remotas executadas. |
| Número de lotes | Um lote é um conjunto dinâmico de linhas processadas ao mesmo tempo. Mostra o número de lotes que um cross apply distribuído enviou da entrada para o lado do mapa. |
| Latência | Tempo decorrido de todas as execuções feitas no operador. |
| Latência cumulativa | O tempo total do operador atual e dos descendentes dele. |
| Tempo de CPU | Soma do tempo de CPU gasto na execução do operador. |
| Tempo de CPU cumulativo | O tempo total de CPU gasto na execução do operador e dos descendentes dele. |
| Tempo de execução | O tempo total gasto para executar a consulta e processar os resultados. |
| Linhas retornadas | O número de linhas geradas por esse operador. |
| Número de execuções | O número de vezes que o operador foi executado. Algumas execuções podem ser realizadas em paralelo. |
Distributed cross apply
A consulta a seguir demonstra esse operador:
SELECT albumtitle
FROM songs
JOIN albums
ON albums.albumid = songs.albumid;
/*-----------------------+
| AlbumTitle |
+-----------------------+
| Green |
| Nothing To Do With Me |
| Play |
| Total Junk |
| Green |
+-----------------------*/
O plano de execução aparece da seguinte forma:
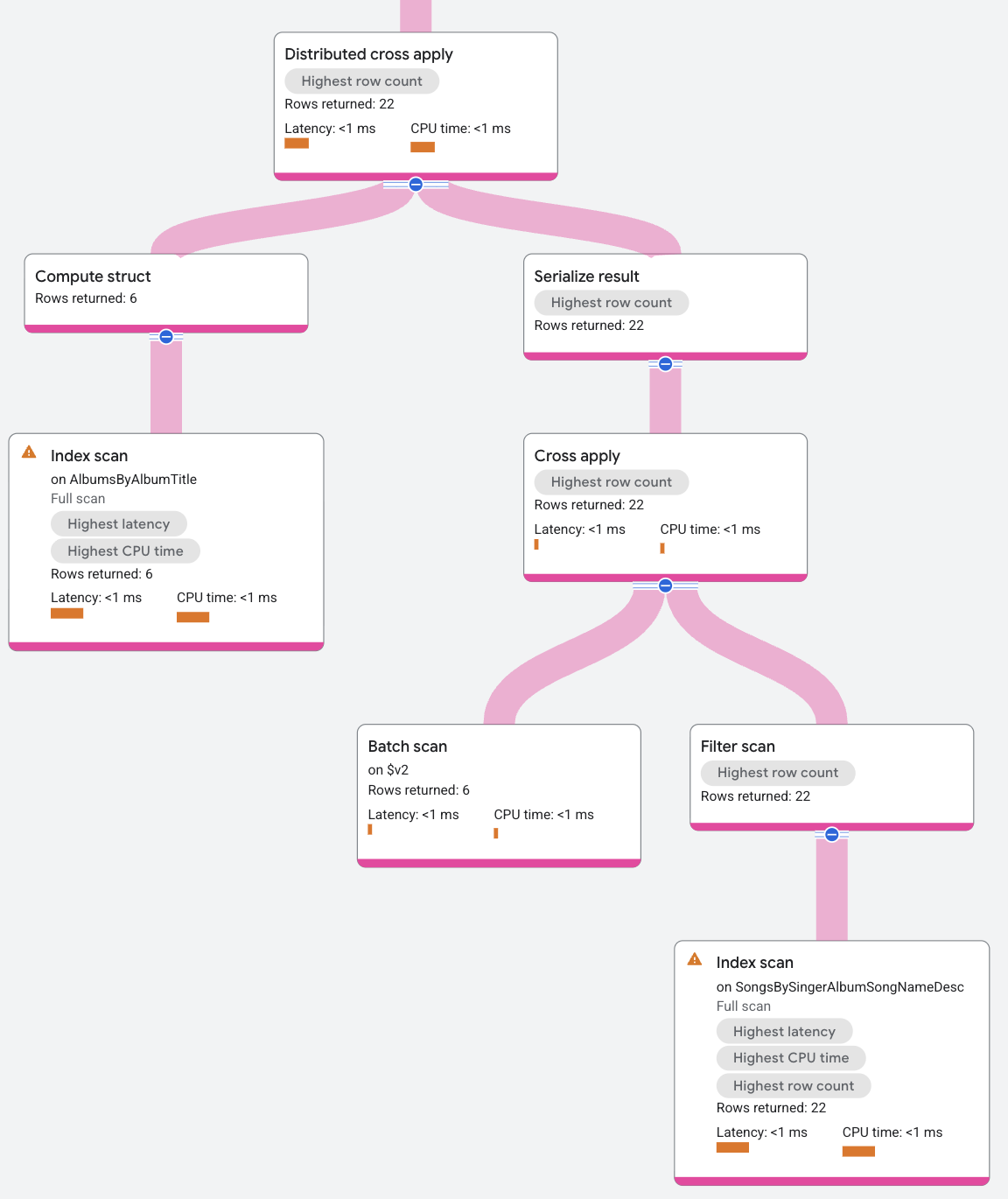
A entrada de DCA contém uma verificação de índice SongsBySingerAlbumSongNameDesc que agrupa linhas de AlbumId. O lado "map" do DCA é um cross apply padrão, em que a entrada é um lote de linhas, e o lado "map" é uma verificação de índice no índice AlbumsByAlbumTitle, sujeito ao predicado de AlbumId na linha de entrada que corresponde à chave AlbumId no índice AlbumsByAlbumTitle. O mapeamento retorna o SongName para os valores SingerId nas linhas de entrada em lote.
Para resumir o processo de DCA para este exemplo, a entrada do DCA é as linhas em lote da tabela Albums, e a saída do DCA é o aplicativo dessas linhas no mapa da varredura de índice.
Distributed outer apply
Um distributed outer apply é uma DA com semântica de left outer join. Consulte outer apply para mais detalhes sobre a semântica.
A consulta a seguir demonstra esse operador:
SELECT lastname,
concertdate
FROM singers LEFT OUTER join@{JOIN_TYPE=APPLY_JOIN} concerts
ON singers.singerid=concerts.singerid;
/*----------+-------------+
| LastName | ConcertDate |
+----------+-------------+
| Trentor | 2014-02-18 |
| Smith | 2011-09-03 |
| Smith | 2010-06-06 |
| Lomond | 2005-04-30 |
| Martin | 2015-11-04 |
| Richards | |
+----------+-------------*/
O plano de execução aparece da seguinte forma:
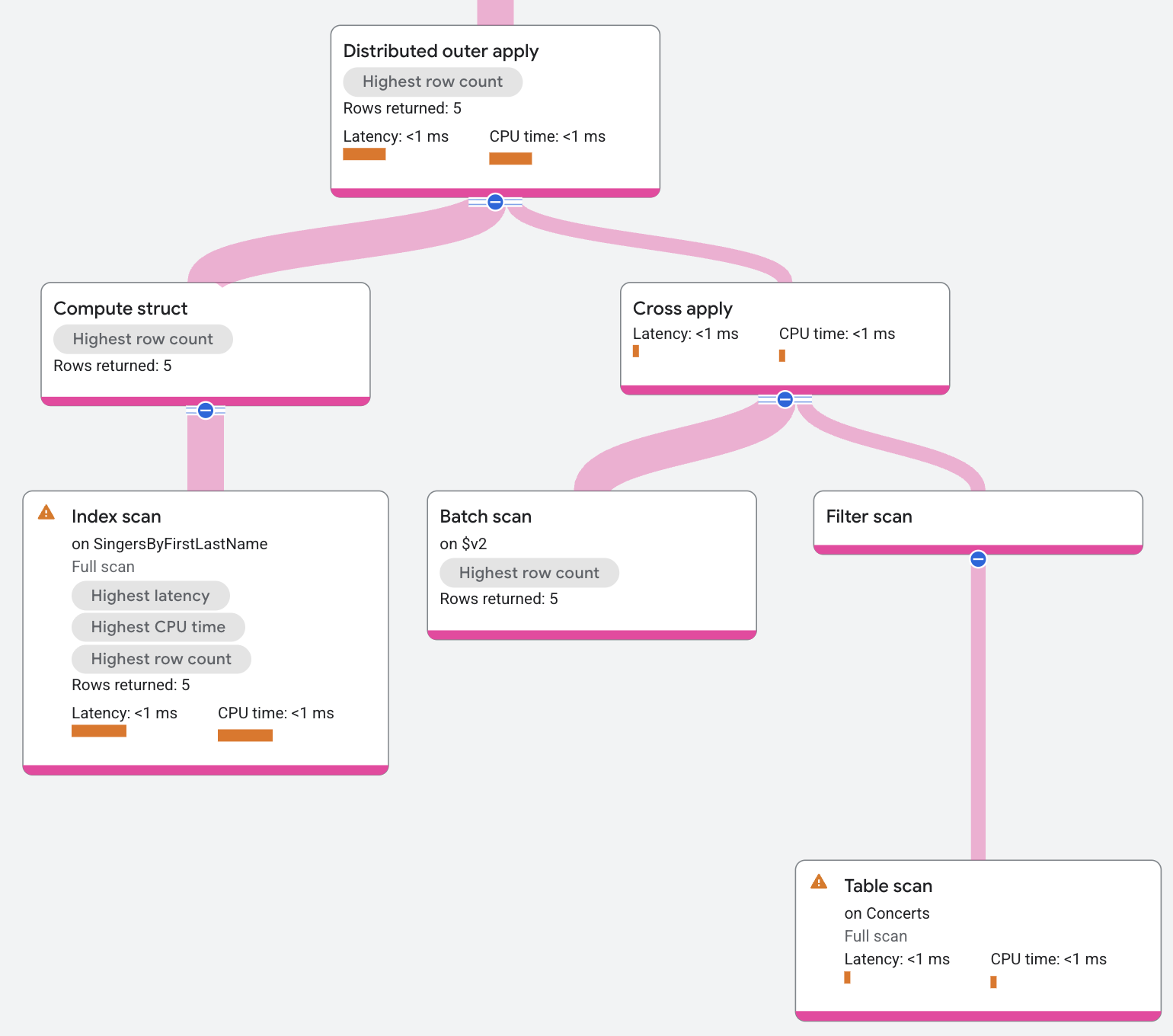
Distributed semi apply
Um semi-join distribuído é uma DA com semântica de semi-join. Consulte semi apply para mais detalhes sobre a semântica.
Distributed anti-semi apply
Um Distributed anti-semi apply é um DA com semântica de anti-semi join. Consulte anti-semi apply para detalhes sobre a semântica.
União de mesclagem distribuída
O operador distributed merge union distribui uma consulta em vários servidores remotos. Em seguida, ele combina os resultados da consulta para produzir um resultado classificado, conhecido como classificação de mesclagem distribuída.
Uma união de mesclagem distribuída executa as seguintes etapas:
O servidor raiz envia uma subconsulta a cada servidor remoto que hospeda uma divisão dos dados consultados. A subconsulta inclui instruções para que os resultados sejam classificados em uma ordem específica.
Cada servidor remoto executa a subconsulta na divisão e envia os resultados de volta na ordem solicitada.
O servidor raiz mescla a subconsulta classificada para produzir um resultado totalmente classificado.
A união de mesclagem distribuída é ativada por padrão para o Spanner versão 3 e mais recentes.
Propriedades e estatísticas de execução
Uma propriedade de um operador descreve uma característica usada quando o operador é executado. Uma estatística de execução é um valor coletado durante a execução da consulta para ajudar você a avaliar a performance do operador.
O operador Distributed apply tem outras estatísticas de execução distintas.Propriedades
| Nome | Descrição |
|---|---|
| Método de execução | Na execução de linha, o operador processa uma linha por vez. Na execução em lote, o operador processa um lote de linhas de uma só vez. |
Estatísticas de execução
| Nome | Descrição |
|---|---|
| Execuções paralelas locais | O número de subconsultas executadas em paralelo. |
| Chamadas remotas | O número de subconsultas remotas executadas. |
| Número de lotes | Um lote é um conjunto dinâmico de linhas processadas ao mesmo tempo. Mostra o número de lotes que um cross apply distribuído enviou da entrada para o lado do mapa. |
| Latência | Tempo decorrido de todas as execuções feitas no operador. |
| Latência cumulativa | O tempo total do operador atual e dos descendentes dele. |
| Tempo de CPU | Soma do tempo de CPU gasto na execução do operador. |
| Tempo de CPU cumulativo | O tempo total de CPU gasto na execução do operador e dos descendentes dele. |
| Tempo de execução | O tempo total gasto para executar a consulta e processar os resultados. |
| Linhas retornadas | O número de linhas geradas por esse operador. |
| Número de execuções | O número de vezes que o operador foi executado. Algumas execuções podem ser realizadas em paralelo. |
Junção do hash de transmissão push
Um operador envio de hash de transmissão push é uma implementação distribuída de junções de SQL baseadas em hash. O operador de hash de transmissão push lê linhas do lado da entrada para construir um lote de dados. O operador transmite esse lote para todos os servidores que contêm dados de mapeamento. Nos servidores de destino em que o lote de dados é recebido, o operador cria uma junção de hash usando o lote como os dados do lado da versão e verifica os dados locais como o lado da sondagem da junção de hash.
A junção do hash de transmissão push tem as seguintes vantagens:
- Se a tabela de build for pequena, ela poderá ser enviada para todas as divisões do lado do mapa.
- A tabela lateral do mapa pode ser verificada com ou sem filtros residuais. Isso acontece quando as chaves de junção não são as mesmas que as chaves primárias da tabela de mapeamento.
Push broadcast hash join não é selecionado automaticamente pelo otimizador. Para usar
esse operador, defina o método de junção como PUSH_BROADCAST_HASH_JOIN na
dica de consulta, conforme mostrado no exemplo a seguir:
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=push_broadcast_hash_join} songs AS s
ON a.singerid = s.singerid
AND a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
| Nothing To Do With Me | Not About The Guitar |
+-----------------------+--------------------------*/
O plano de execução aparece da seguinte forma:
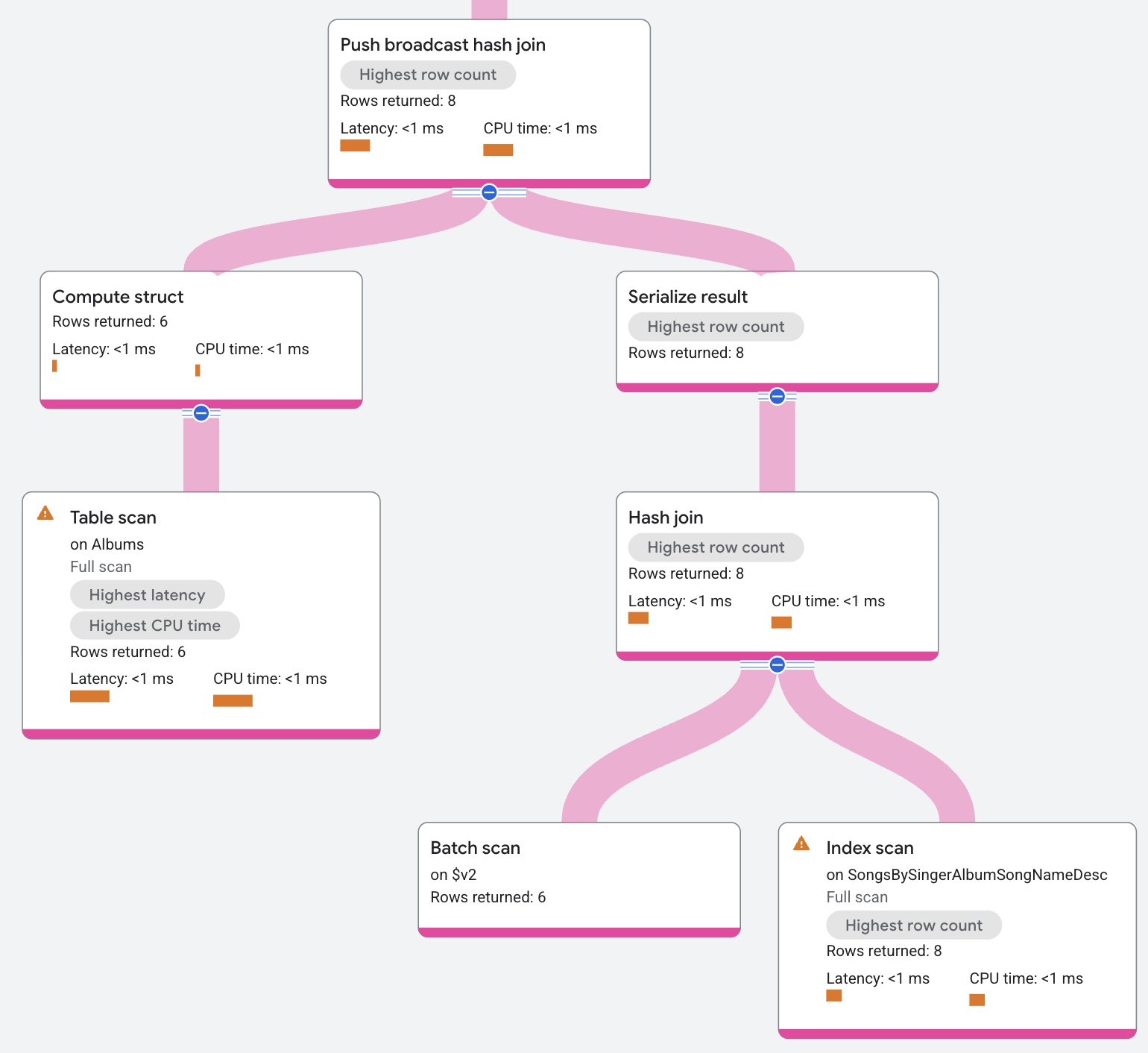
A entrada da junção de hash de transmissão push é o índice AlbumsByAlbumTitle.
O operador serializa essa entrada em um lote de dados. O operador envia esse lote para todas as divisões locais do índice SongsBySingerAlbumSongNameDesc, em que o operador desserializa o lote e o cria em uma tabela de hash. Em seguida, a tabela de hash usa os dados do índice local como uma sondagem que retorna correspondências resultantes.
As correspondências resultantes também podem ser filtradas por uma condição residual antes de serem retornadas. Um exemplo de onde as condições residuais aparecem é em junções de não igualdade.
Propriedades e estatísticas de execução
Uma propriedade de um operador descreve uma característica usada quando o operador é executado. Uma estatística de execução é um valor coletado durante a execução da consulta para ajudar você a avaliar a performance do operador.
O operador Distributed apply tem outras estatísticas de execução distintas.Propriedades
| Nome | Descrição |
|---|---|
| Método de execução | Na execução de linha, o operador processa uma linha por vez. Na execução em lote, o operador processa um lote de linhas de uma só vez. |
Estatísticas de execução
| Nome | Descrição |
|---|---|
| Execuções paralelas locais | O número de subconsultas executadas em paralelo. |
| Chamadas remotas | O número de subconsultas remotas executadas. |
| Número de lotes | Um lote é um conjunto dinâmico de linhas processadas ao mesmo tempo. Mostra o número de lotes que um cross apply distribuído enviou da entrada para o lado do mapa. |
| Latência | Tempo decorrido de todas as execuções feitas no operador. |
| Latência cumulativa | O tempo total do operador atual e dos descendentes dele. |
| Tempo de CPU | Soma do tempo de CPU gasto na execução do operador. |
| Tempo de CPU cumulativo | O tempo total de CPU gasto na execução do operador e dos descendentes dele. |
| Tempo de execução | O tempo total gasto para executar a consulta e processar os resultados. |
| Linhas retornadas | O número de linhas geradas por esse operador. |
| Número de execuções | O número de vezes que o operador foi executado. Algumas execuções podem ser realizadas em paralelo. |