
Um operador binário tem dois filhos relacionais. Os seguintes operadores são binários:
Database schema
As consultas e os planos de execução dessa página se baseiam no esquema de banco de dados abaixo:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
É possível usar as seguintes instruções da linguagem de manipulação de dados (DML) para adicionar dados a estas tabelas:
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
Aplicar junção
Uma junção de aplicação é o principal operador de junção usado pelo Spanner. Os operadores apply join executam o processamento orientado por linha, em vez do processamento baseado em conjunto, como hash join. O operador "apply" tem duas entradas, input (filho à esquerda) e map (filho à direita). O operador "apply" aplica cada linha do lado "input" ao lado "map" usando um método de aplicação: cross, outer, semi ou anti-semi. Além disso, uma variante de uma junção de aplicação também aparece no lado do mapa de uma aplicação distribuída.
O operador "Apply join" é mais eficiente quando:
- A cardinalidade da entrada é baixa.
- A chave de junção é um prefixo da chave primária do lado do mapa.
- A consulta une duas tabelas intercaladas.
Propriedades e estatísticas de execução
Uma propriedade de um operador descreve uma característica usada quando o operador é executado. Uma estatística de execução é um valor coletado durante a execução da consulta para ajudar você a avaliar a performance do operador.
Propriedades
| Nome | Descrição |
|---|---|
| Método de execução | Na execução de linha, o operador processa uma linha por vez. Na execução em lote, o operador processa um lote de linhas de uma só vez. |
Estatísticas de execução
| Nome | Descrição |
|---|---|
| Latência | Tempo decorrido de todas as execuções feitas no operador. |
| Latência cumulativa | O tempo total do operador atual e dos descendentes dele. |
| Tempo de CPU | Soma do tempo de CPU gasto na execução do operador. |
| Tempo de CPU cumulativo | O tempo total de CPU gasto na execução do operador e dos descendentes dele. |
| Tempo de execução | O tempo total gasto para executar a consulta e processar os resultados. |
| Linhas retornadas | O número de linhas geradas por esse operador. |
| Número de execuções | O número de vezes que o operador foi executado. Algumas execuções podem ser realizadas em paralelo. |
Cross apply
Um Cross apply executa uma junção interna em que apenas as linhas correspondentes são retornadas.
A consulta a seguir demonstra esse operador:
A consulta pede o nome de cada cantor, juntamente com o nome de apenas uma das canções do cantor.
SELECT si.firstname,
(SELECT so.songname
FROM songs AS so
WHERE so.singerid = si.singerid
LIMIT 1)
FROM singers AS si;
/*-----------+--------------------------+
| FirstName | Unspecified |
+-----------+--------------------------+
| Alice | Not About The Guitar |
| Catalina | Let's Get Back Together |
| David | NULL |
| Lea | NULL |
| Marc | NULL |
+-----------+--------------------------*/
A consulta preenche a primeira coluna da tabela Singers e a segunda da tabela Songs. Caso haja SingerId na tabela Singers, mas não exista SingerId correspondente na tabela Songs, a segunda coluna conterá NULL.
O plano de execução começa assim:
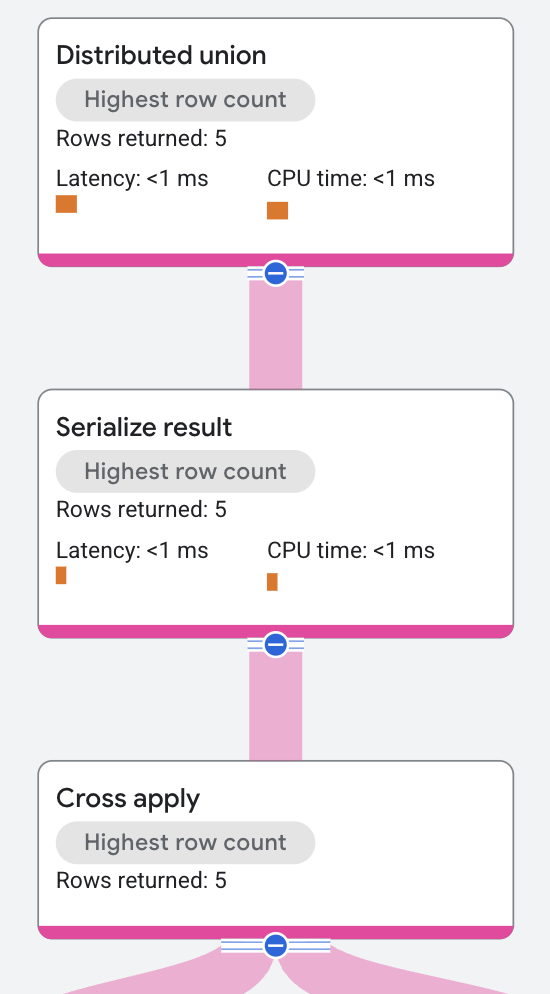
O nó de nível superior é um operador distributed union. O operador "distributed union" distribui subplanos a servidores remotos. O subplano contém um operador serialize result, que computa o nome do cantor e o nome de uma das músicas dele e serializa cada linha da saída.
O operador "serialize result" recebe a entrada de um operador "cross apply".
O lado "input" do operador "cross apply" é uma operação scan na tabela Singers.
O plano de execução continua da seguinte forma:
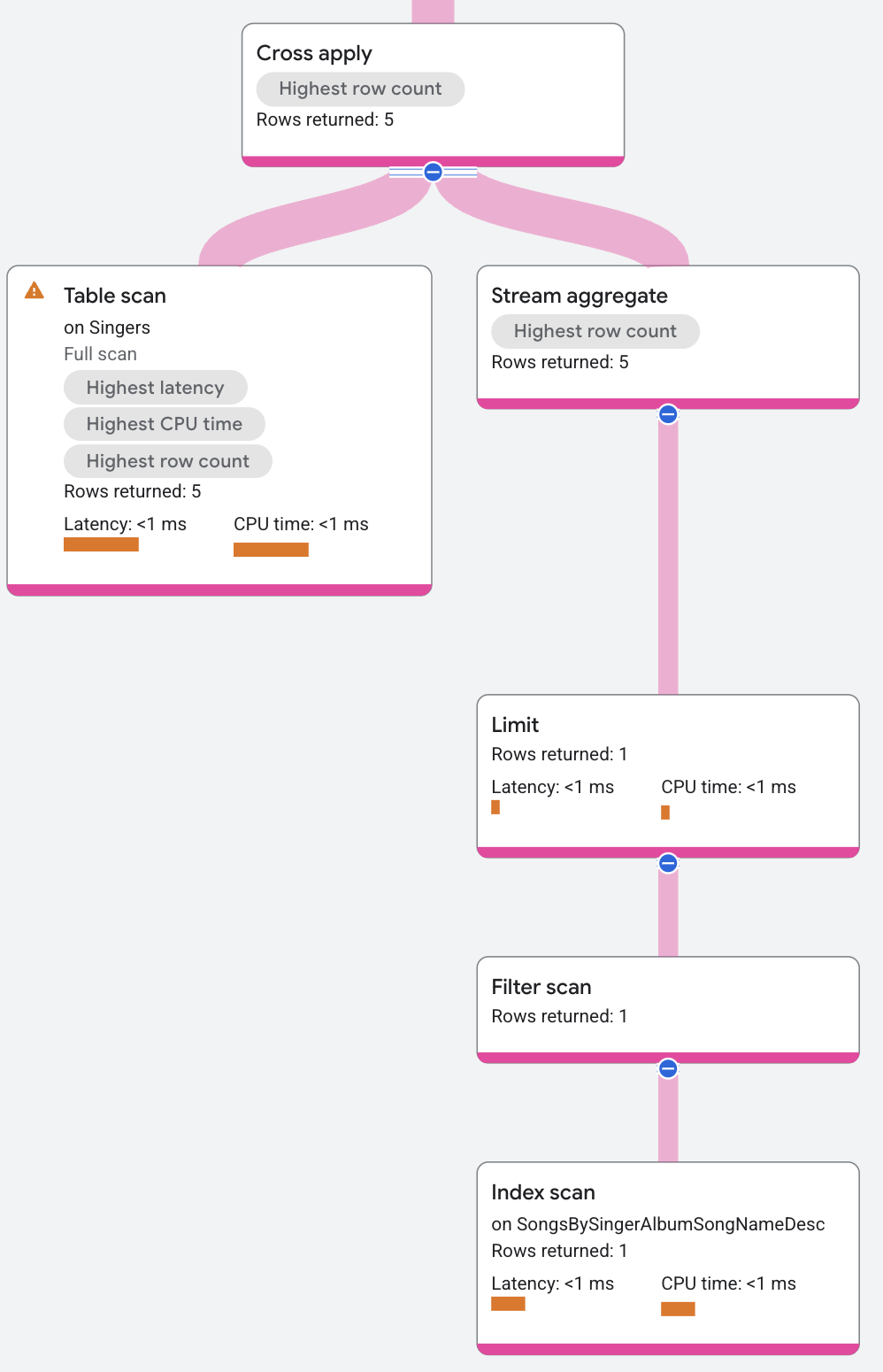
O lado "map" da operação "cross apply" contém os seguintes itens (de cima para baixo):
- Um operador aggregate que retorna
Songs.SongName. - Um operador limit que limita o número de músicas retornadas a uma por cantor.
- Um operador index scan no índice
SongsBySingerAlbumSongNameDesc.
O operador "cross apply" associa cada linha do lado "input" a uma linha do lado "map" que tenha o mesmo SingerId. A saída do operador "cross apply" é o valor FirstName da linha de "input" e o valor SongName da linha de "map".
(O valor SongName será NULL se não houver linha de mapa que corresponda a SingerId.) O operador de união distribuída na parte superior do plano de execução combina todas as linhas de saída dos servidores remotos e as retorna como os resultados da consulta.
Outer apply
Um outer apply fornece semântica de left outer join. Ele garante que cada execução no lado do mapa retorne pelo menos uma linha adicionando preenchimento com NULL, se necessário.
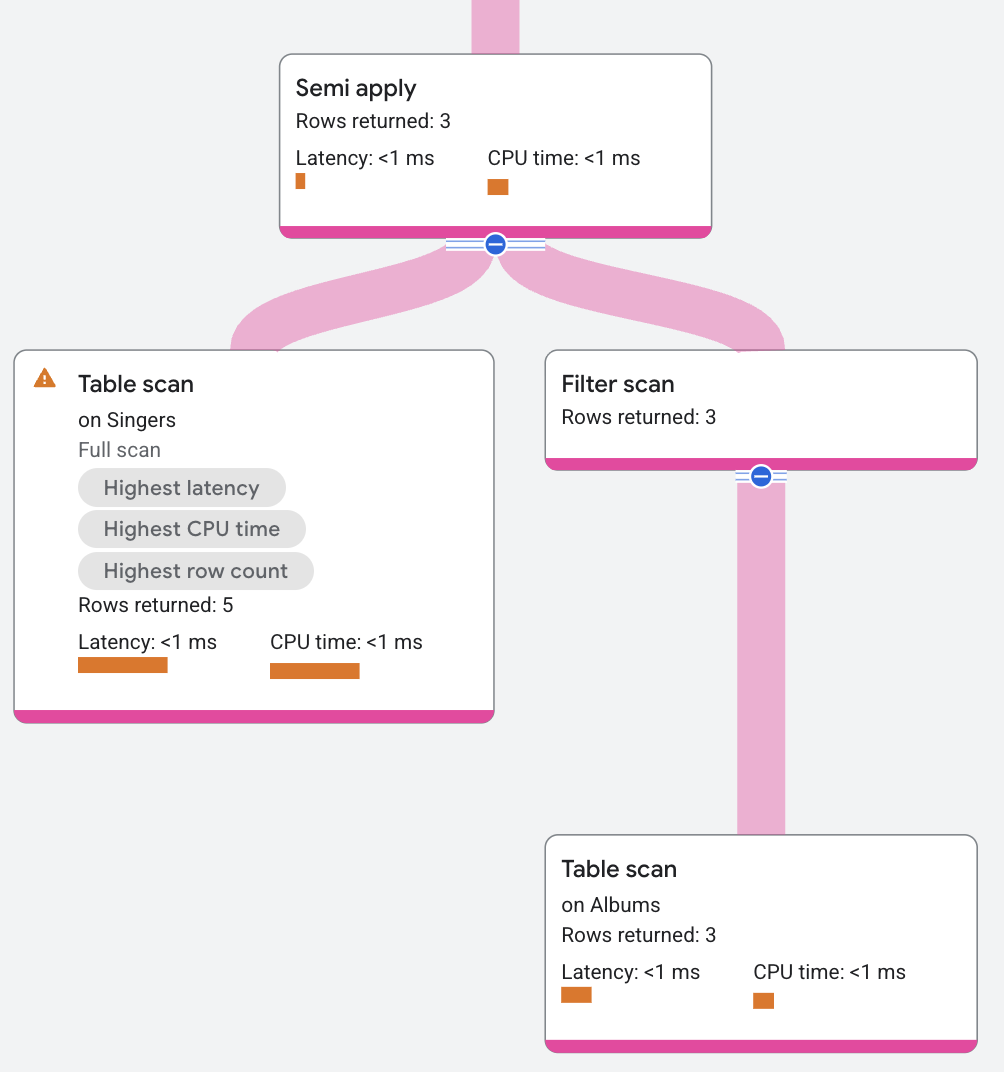
Semi apply
O operador semi apply retorna colunas de entrada somente quando uma correspondência ocorre no lado do mapa.
A consulta a seguir usa uma semi-join para encontrar quais cantores têm um álbum:
SELECT
FirstName,
LastName
FROM
Singers
WHERE
SingerId IN (
SELECT
SingerId
FROM
Albums);
/*-----------+----------+
| FirstName | LastName |
+-----------+----------+
| Marc | Richards |
| Catalina | Smith |
| Alice | Trentor |
| Lea | Martin |
+-----------+----------*/
O segmento do plano aparece da seguinte maneira:
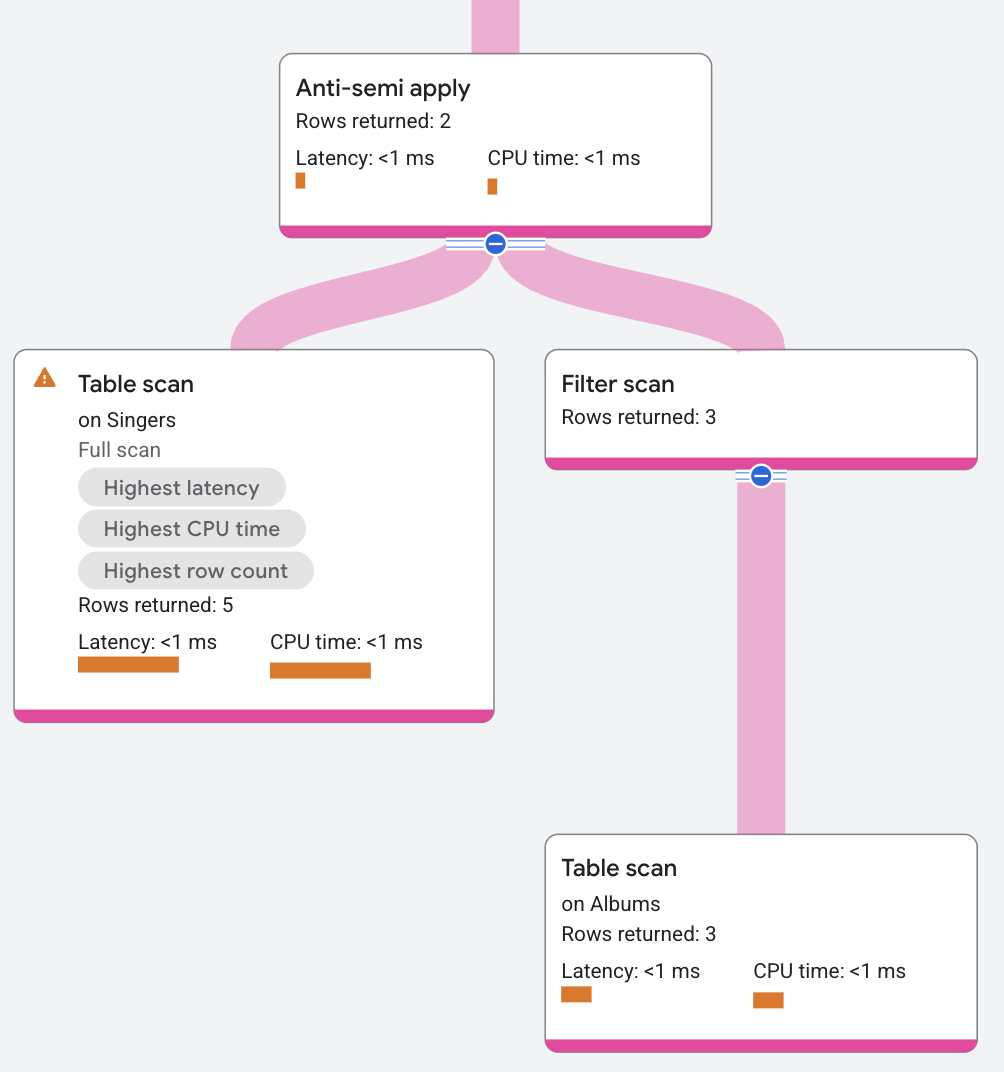
Anti-semi apply
Um operador anti-semi apply é semelhante a um operador semi apply, exceto que ele retorna as colunas da tabela de entrada somente quando não há uma correspondência no lado "map".
A consulta a seguir usa uma junção anti-semi para encontrar cantores que não têm um álbum:
SELECT
FirstName,
LastName
FROM
Singers
WHERE
SingerId NOT IN (
SELECT
SingerId
FROM
Albums);
/*-----------+----------+
| FirstName | LastName |
+-----------+----------+
| David | Lomond |
+-----------+----------*/
O segmento do plano aparece da seguinte maneira:
Junção de hash
Um operador hash join é uma implementação baseada em hash de junções SQL. Operações "hash join" executam processamento baseado em conjunto. O operador "hash join" lê as linhas da entrada marcadas como build (filho à esquerda) e as insere em uma tabela de hash com base em uma condição de junção. Em seguida, o operador "hash join" lê as linhas da entrada marcadas como probe (filho à direita). Para cada linha que lê da entrada "probe", o operador "hash join" procura linhas correspondentes na tabela de hash. O operador "hash join" retorna as linhas correspondentes como resultado.
A junção hash tem as seguintes vantagens:
- Não é necessário classificar as entradas.
- Ele calcula um filtro de Bloom ao criar a tabela hash. O operador usa o filtro para excluir linhas do lado da sondagem que não têm correspondências. Esse é um filtro residual, não um filtro de busca.
A consulta a seguir demonstra esse operador:
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=hash_join} songs AS s
ON a.singerid = s.singerid
AND a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Nothing To Do With Me | Not About The Guitar |
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
+-----------------------+--------------------------*/
O segmento do plano de execução aparece da seguinte maneira:
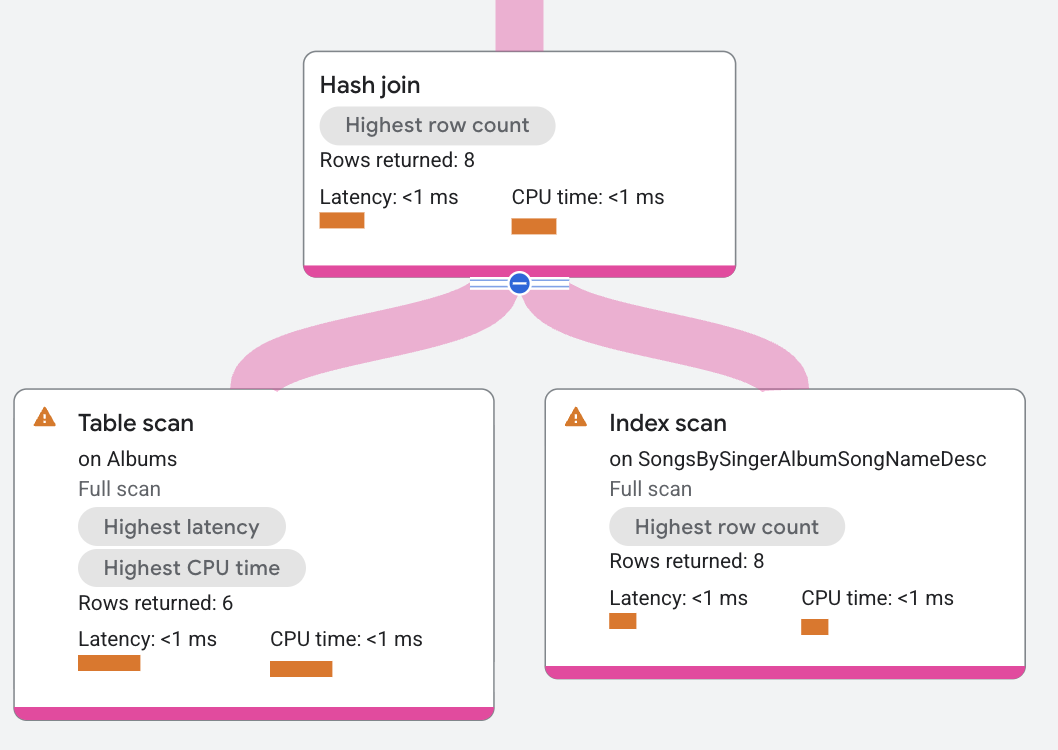
No plano de execução, build é um distributed union que distribui scans na tabela Albums. Probe é um operador "distributed union" que distribui "scans" no índice SongsBySingerAlbumSongNameDesc.
O operador "hash join" lê todas as linhas do lado "build". Cada linha "build" é colocada em uma tabela de hash com base nas colunas da condição a.SingerId =
s.SingerId AND a.AlbumId = s.AlbumId. Em seguida, o operador "hash join" lê todas as linhas do lado "probe". Para cada linha "probe", o operador "hash join" procura correspondências na tabela de hash. As correspondências resultantes são retornadas pelo operador "hash join".
As correspondências resultantes na tabela de hash também podem ser filtradas por uma condição residual antes de serem retornadas. Um exemplo de onde as condições residuais aparecem é em junções de não igualdade. Os planos de execução de "hash join" podem ser complexos devido ao gerenciamento de memória e às variantes de junção. O principal algoritmo de "hash join" é adaptado para lidar com as variantes "inner", "semi", "anti" e "outer join".
Propriedades e estatísticas de execução
Uma propriedade de um operador descreve uma característica usada quando o operador é executado. Uma estatística de execução é um valor coletado durante a execução da consulta para ajudar você a avaliar a performance do operador.
Propriedades
| Nome | Descrição |
|---|---|
| Método de execução | Na execução de linha, o operador processa uma linha por vez. Na execução em lote, o operador processa um lote de linhas de uma só vez. |
Estatísticas de execução
| Nome | Descrição |
|---|---|
| Latência | Tempo decorrido de todas as execuções feitas no operador. |
| Latência cumulativa | O tempo total do operador atual e dos descendentes dele. |
| Tempo de CPU | Soma do tempo de CPU gasto na execução do operador. |
| Tempo de CPU cumulativo | O tempo total de CPU gasto na execução do operador e dos descendentes dele. |
| Tempo de execução | O tempo total gasto para executar a consulta e processar os resultados. |
| Linhas retornadas | O número de linhas geradas por esse operador. |
| Número de execuções | O número de vezes que o operador foi executado. Algumas execuções podem ser realizadas em paralelo. |
Mesclar junção
Um operador merge join é uma implementação baseada em mesclagem de mesclagem SQL. Os dois lados da junção produzem linhas ordenadas pelas colunas usadas na condição de junção. A mesclagem de mesclar consome os streams de entrada simultaneamente e gera linhas quando a condição da junção é atendida. Se as entradas não estiverem classificadas, o otimizador adicionará operadores Sort explícitos ao plano.
O merge join tem as seguintes vantagens:
- Se os dados já estiverem classificados, não será necessário usar memória.
- Mesmo que os dados não estejam classificados, para uma junção distribuída, é possível realizar a classificação em cada divisão individual, em vez de criar uma grande tabela hash na raiz.
Merge join não é selecionado automaticamente pelo otimizador. Para usar esse
operador, defina o método de junção como MERGE_JOIN na dica de consulta, conforme mostrado
no exemplo a seguir:
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=merge_join} songs AS s
ON a.singerid = s.singerid
AND a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
| Nothing To Do With Me | Not About The Guitar |
+-----------------------+--------------------------*/
O plano de execução aparece da seguinte forma:
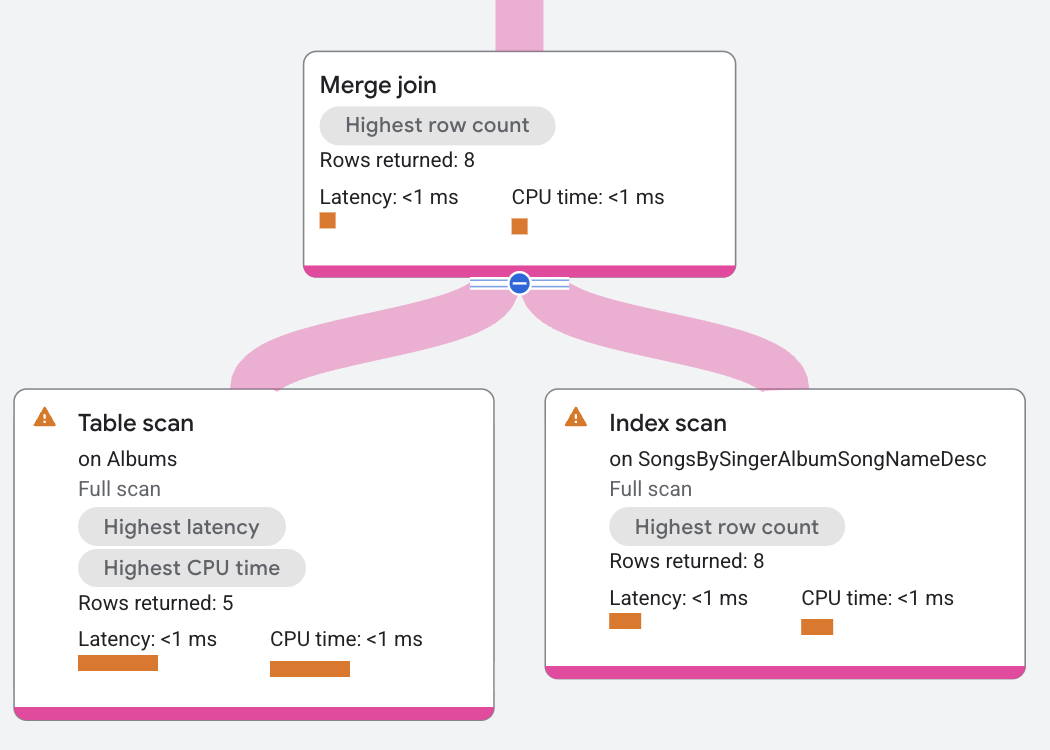
Neste plano de execução, a mesclagem é distribuída para que seja executada onde os dados estão localizados. Isso também permite que a mesclagem seja executada neste exemplo sem outros operadores de classificação, já que as duas verificações de tabela já estão classificadas por SingerId, AlbumId, que é a condição de junção. Neste plano, a verificação do lado esquerdo da tabela Albums avança sempre que SingerId, AlbumId é menor que os valores SingerId_1, AlbumId_1 da verificação do lado direito. Da mesma forma, a varredura à direita avança sempre que os valores dela são menores que os da varredura à esquerda. Esse avanço da junção continua procurando equivalências para retornar linhas correspondentes.
Considere outro exemplo de mesclagem usando a seguinte consulta:
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=merge_join} songs AS s
ON a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Total Junk | The Second Time |
| Total Junk | Starting Again |
| Total Junk | Nothing Is The Same |
| Total Junk | Let's Get Back Together |
| Total Junk | I Knew You Were Magic |
| Total Junk | Blue |
| Total Junk | 42 |
| Total Junk | Not About The Guitar |
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Green | Not About The Guitar |
| Nothing To Do With Me | The Second Time |
| Nothing To Do With Me | Starting Again |
| Nothing To Do With Me | Nothing Is The Same |
| Nothing To Do With Me | Let's Get Back Together |
| Nothing To Do With Me | I Knew You Were Magic |
| Nothing To Do With Me | Blue |
| Nothing To Do With Me | 42 |
| Nothing To Do With Me | Not About The Guitar |
| Play | The Second Time |
| Play | Starting Again |
| Play | Nothing Is The Same |
| Play | Let's Get Back Together |
| Play | I Knew You Were Magic |
| Play | Blue |
| Play | 42 |
| Play | Not About The Guitar |
| Terrified | Fight Story |
+-----------------------+--------------------------*/
O plano de execução aparece da seguinte forma:
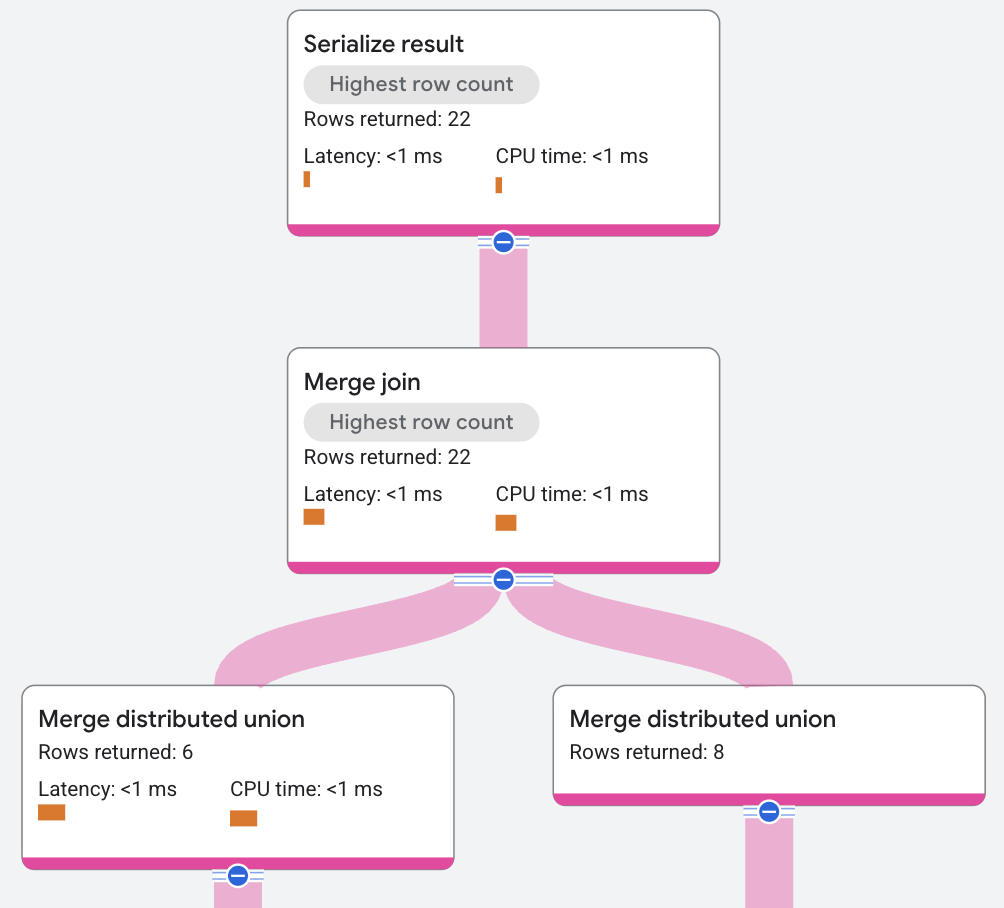
No plano de execução anterior, o otimizador de consulta introduziu outros operadores de classificação para executar a junção de mesclagem. A condição JOIN neste exemplo de consulta
está somente em AlbumId, que não é como os dados são armazenados. Portanto, uma classificação precisa ser
adicionada. O mecanismo de consulta é compatível com um algoritmo de Distribuição distribuída, permitindo que a classificação ocorra localmente em vez de globalmente, o que distribui e carrega em paralelo o custo da CPU.
As correspondências resultantes também podem ser filtradas por uma condição residual. Por exemplo, as condições residuais aparecem em junções de não igualdade. Os planos de execução da mesclagem podem ser complexos devido a outros requisitos de classificação. O principal algoritmo de "merge join" lida com as variantes "inner", "semi", "anti" e "outer join".
Propriedades e estatísticas de execução
Uma propriedade de um operador descreve uma característica usada quando o operador é executado. Uma estatística de execução é um valor coletado durante a execução da consulta para ajudar você a avaliar a performance do operador.
Propriedades
| Nome | Descrição |
|---|---|
| Método de execução | Na execução de linha, o operador processa uma linha por vez. Na execução em lote, o operador processa um lote de linhas de uma só vez. |
Estatísticas de execução
| Nome | Descrição |
|---|---|
| Latência | Tempo decorrido de todas as execuções feitas no operador. |
| Latência cumulativa | O tempo total do operador atual e dos descendentes dele. |
| Tempo de CPU | Soma do tempo de CPU gasto na execução do operador. |
| Tempo de CPU cumulativo | O tempo total de CPU gasto na execução do operador e dos descendentes dele. |
| Tempo de execução | O tempo total gasto para executar a consulta e processar os resultados. |
| Linhas retornadas | O número de linhas geradas por esse operador. |
| Número de execuções | O número de vezes que o operador foi executado. Algumas execuções podem ser realizadas em paralelo. |
União recursiva
Um operador de união recursiva realiza a união de duas entradas, uma que representa um caso base e outra que representa um caso recursive. Ele é usado em
consultas de gráficos com travessias de caminhos quantificados. A entrada de base é processada primeiro e exatamente uma vez. A entrada recursiva é processada até que a recursão seja encerrada. A recursão termina quando o limite superior, se especificado, é atingido ou quando a recursão não produz novos resultados. No exemplo a seguir, a tabela Collaborations é adicionada ao esquema, e um gráfico de propriedades chamado MusicGraph é criado.
CREATE TABLE Collaborations (
SingerId INT64 NOT NULL,
FeaturingSingerId INT64 NOT NULL,
AlbumTitle STRING(MAX) NOT NULL,
) PRIMARY KEY(SingerId, FeaturingSingerId, AlbumTitle);
CREATE OR REPLACE PROPERTY GRAPH MusicGraph
NODE TABLES(
Singers
KEY(SingerId)
LABEL Singers PROPERTIES(
BirthDate,
FirstName,
LastName,
SingerId,
SingerInfo)
)
EDGE TABLES(
Collaborations AS CollabWith
KEY(SingerId, FeaturingSingerId, AlbumTitle)
SOURCE KEY(SingerId) REFERENCES Singers(SingerId)
DESTINATION KEY(FeaturingSingerId) REFERENCES Singers(SingerId)
LABEL CollabWith PROPERTIES(
AlbumTitle,
FeaturingSingerId,
SingerId),
);
A consulta de gráfico a seguir encontra cantores que colaboraram com um determinado cantor ou com os colaboradores dele.
GRAPH MusicGraph
MATCH (singer:Singers {singerId:42})-[c:CollabWith]->{1,2}(featured:Singers)
RETURN singer.SingerId AS singer, featured.SingerId AS featured
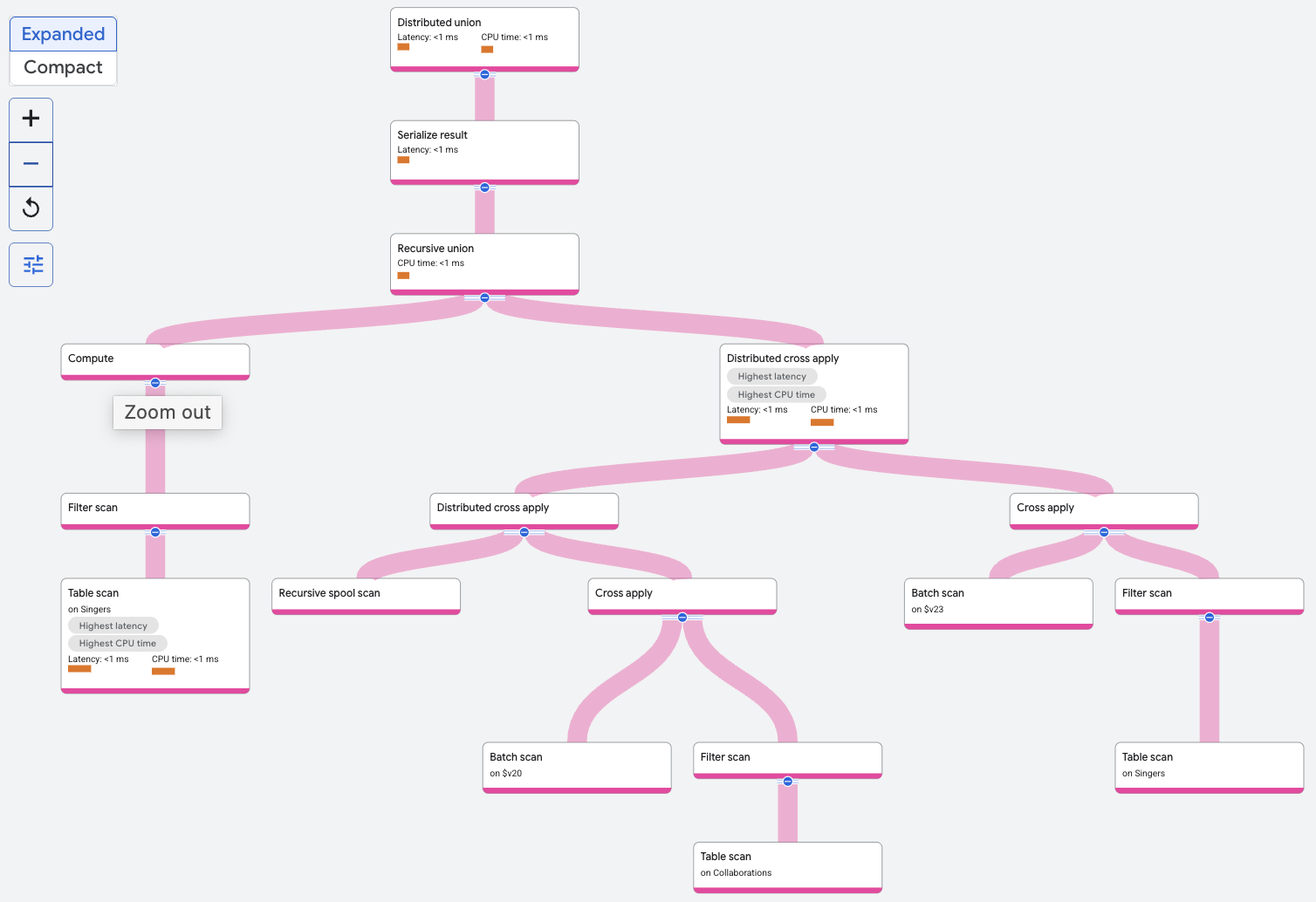
O operador união recursiva filtra a tabela Singers para encontrar o cantor com o SingerId especificado. Essa é a entrada básica da união recursiva. A entrada recursiva da união recursiva consiste em uma aplicação cruzada distribuída ou outro operador de junção para outras consultas que unem repetidamente a tabela Collaborations com os resultados da iteração anterior da junção. As linhas da entrada de base formam a iteração zero.
Em cada iteração, a saída é armazenada pela varredura recursiva de spool. As linhas da verificação de spool recursiva são unidas à tabela Collaborations em spoolscan.featuredSingerId = Collaborations.SingerId. A recursão termina quando duas iterações são concluídas, já que esse é o limite superior especificado na consulta.
Propriedades e estatísticas de execução
Uma propriedade de um operador descreve uma característica usada quando o operador é executado. Uma estatística de execução é um valor coletado durante a execução da consulta para ajudar você a avaliar a performance do operador.
Propriedades
| Nome | Descrição |
|---|---|
| Método de execução | Na execução de linha, o operador processa uma linha por vez. Na execução em lote, o operador processa um lote de linhas de uma só vez. |
Estatísticas de execução
| Nome | Descrição |
|---|---|
| Latência | Tempo decorrido de todas as execuções feitas no operador. |
| Latência cumulativa | O tempo total do operador atual e dos descendentes dele. |
| Tempo de CPU | Soma do tempo de CPU gasto na execução do operador. |
| Tempo de CPU cumulativo | O tempo total de CPU gasto na execução do operador e dos descendentes dele. |
| Tempo de execução | O tempo total gasto para executar a consulta e processar os resultados. |
| Linhas retornadas | O número de linhas geradas por esse operador. |
| Número de execuções | O número de vezes que o operador foi executado. Algumas execuções podem ser realizadas em paralelo. |