
Gli operatori distribuiti vengono eseguiti su più server, a differenza degli operatori foglia, unari, binari o n-ari.
I seguenti operatori sono operatori distribuiti:
Schema del database
Le query e i piani di esecuzione in questa pagina si basano sul seguente schema del database:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
Puoi utilizzare le seguenti istruzioni DML (Data Manipulation Language) per aggiungere dati a queste tabelle:
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
L'operatore Distributed Union è l'operatore primitivo da cui derivano Distributed Cross Apply e Distributed Outer Apply.
Gli operatori distribuiti vengono visualizzati nei piani di esecuzione con una variante di unione distribuita sopra una o più varianti di unione distribuita locale. Una variante di un'operazione Union distribuita esegue la distribuzione remota dei sottopiani.
Una variante di unione distribuita locale si trova in cima a ciascuna delle scansioni eseguite per la query. Le varianti dell'operazione Union distribuita locale garantiscono l'esecuzione stabile delle query quando si verificano riavvii perconfini della suddivisionee che cambiano dinamicamente. Sebbene questo operatore sia nascosto nel piano visivo, è sempre presente.
Quando possibile, una variante di unione distribuita utilizza un predicato di suddivisione per il taglio della suddivisione. Il pruning delle suddivisioni indica che i server remoti eseguono i sottopiani solo sulle suddivisioni che soddisfano il predicato, migliorando la latenza e le prestazioni delle query.
Distributed union
Un operatore distributed union divide concettualmente una o più tabelle in più split, valuta in remoto una sottoquery in modo indipendente su ogni split e poi unisce tutti i risultati.
La seguente query mostra questo operatore:
SELECT s.songname,
s.songgenre
FROM songs AS s
WHERE s.singerid = 2
AND s.songgenre = 'ROCK';
/*-----------------+-----------+
| SongName | SongGenre |
+-----------------+-----------+
| Starting Again | ROCK |
| The Second Time | ROCK |
| Fight Story | ROCK |
+-----------------+-----------*/
Il piano di esecuzione viene visualizzato nel seguente modo:
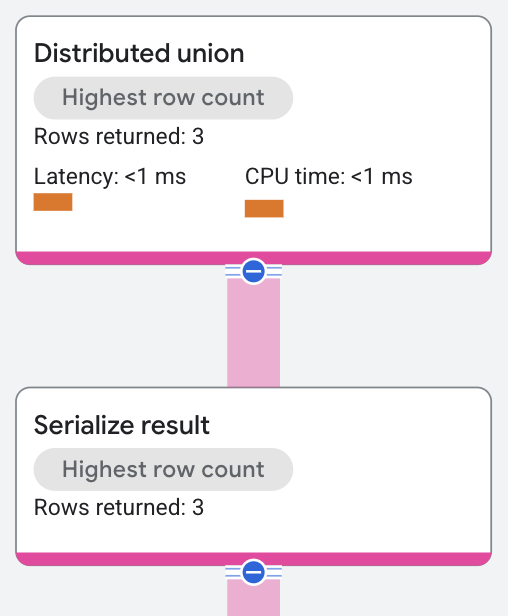
L'operatore di unione distribuita invia i sottopiani ai server remoti, che eseguono una
scansione della tabella tra le suddivisioni che soddisfano
il predicato WHERE s.SingerId = 2 AND s.SongGenre = 'ROCK' della query.
Un operatore serialize result
calcola i valori SongName e SongGenre
dalle righe restituite dalle scansioni delle tabelle. L'operatore di unione distribuita
restituisce quindi i risultati combinati dei server remoti come risultati della query SQL.
Proprietà e statistiche di esecuzione
Una proprietà di un operatore descrive una caratteristica utilizzata quando l'operatore viene eseguito. Una statistica di esecuzione è un valore raccolto durante l'esecuzione della query per aiutarti a valutare le prestazioni dell'operatore.
L'operatore Distributed union ha statistiche di esecuzione distinte aggiuntive.Proprietà
| Nome | Descrizione |
|---|---|
| Metodo di esecuzione | Nell'esecuzione per riga, l'operatore elabora una riga alla volta. Nell'esecuzione batch, l'operatore elabora un batch di righe contemporaneamente. |
Statistiche di esecuzione
| Nome | Descrizione |
|---|---|
| Esecuzioni parallele locali | Il numero di sottoquery eseguite in parallelo. |
| Chiamate remote | Il numero di sottoquery remote eseguite. |
| Latenza | Tempo trascorso di tutte le esecuzioni eseguite nell'operatore. |
| Latenza cumulativa | Il tempo totale dell'operatore corrente e dei relativi discendenti. |
| Tempo CPU | Somma del tempo di CPU dedicato all'esecuzione dell'operatore. |
| Tempo di CPU cumulativo | Il tempo di CPU totale dedicato all'esecuzione dell'operatore e dei relativi discendenti. |
| Tempo di esecuzione | Il tempo totale impiegato per eseguire la query ed elaborare i risultati. |
| Righe restituite | Il numero di righe generate da questo operatore |
| Numero di esecuzioni | Il numero di volte in cui l'operatore è stato eseguito. Alcune esecuzioni possono essere eseguite in parallelo. |
In genere, le esecuzioni sono parallele, a differenza delle esecuzioni cross apply. Per questo motivo, i numeri di latenza degli operatori distribuiti sono cumulativi, a differenza della maggior parte degli operatori, che indicano la latenza aggiunta dall'operatore. Il numero di esecuzioni in un'unione distribuita si basa suiconfini della suddivisionee della tabella, che a loro volta dipendono dalle dimensioni e dal caricamento dei dati e possono includere il suggerimento dell'istruzione use_additional_parallelism. Questo approccio alle statistiche si applica a tutti gli operatori distribuiti.
Applicazione distribuita
Un operatore distributed apply (DA) estende l'operatore apply join eseguendolo su più server. Il lato di input raggruppa le righe in batch (a differenza di un normale operatore Cross Apply, che agisce su una sola riga di input alla volta). Il lato della mappa DA è un insieme di operatori di join di applicazione semplice che vengono eseguiti su server remoti. Un join distributed apply supporta gli stessi metodi di applicazione del join apply.
Proprietà e statistiche di esecuzione
Una proprietà di un operatore descrive una caratteristica utilizzata quando l'operatore viene eseguito. Una statistica di esecuzione è un valore raccolto durante l'esecuzione della query per aiutarti a valutare le prestazioni dell'operatore.
L'operatore Applicazione distribuita ha statistiche di esecuzione distinte aggiuntive.Proprietà
| Nome | Descrizione |
|---|---|
| Metodo di esecuzione | Nell'esecuzione per riga, l'operatore elabora una riga alla volta. Nell'esecuzione batch, l'operatore elabora un batch di righe contemporaneamente. |
Statistiche di esecuzione
| Nome | Descrizione |
|---|---|
| Esecuzioni parallele locali | Il numero di sottoquery eseguite in parallelo. |
| Chiamate remote | Il numero di sottoquery remote eseguite. |
| Numero di batch | Un batch è una raccolta dinamica di righe elaborate contemporaneamente. Mostra il numero di batch di un cross-apply distribuito inviati dall'input al lato della mappa. |
| Latenza | Tempo trascorso di tutte le esecuzioni eseguite nell'operatore. |
| Latenza cumulativa | Il tempo totale dell'operatore corrente e dei relativi discendenti. |
| Tempo CPU | Somma del tempo di CPU dedicato all'esecuzione dell'operatore. |
| Tempo di CPU cumulativo | Il tempo di CPU totale dedicato all'esecuzione dell'operatore e dei relativi discendenti. |
| Tempo di esecuzione | Il tempo totale impiegato per eseguire la query ed elaborare i risultati. |
| Righe restituite | Il numero di righe generate da questo operatore |
| Numero di esecuzioni | Il numero di volte in cui l'operatore è stato eseguito. Alcune esecuzioni possono essere eseguite in parallelo. |
Distributed Cross Apply
La seguente query mostra questo operatore:
SELECT albumtitle
FROM songs
JOIN albums
ON albums.albumid = songs.albumid;
/*-----------------------+
| AlbumTitle |
+-----------------------+
| Green |
| Nothing To Do With Me |
| Play |
| Total Junk |
| Green |
+-----------------------*/
Il piano di esecuzione viene visualizzato nel seguente modo:
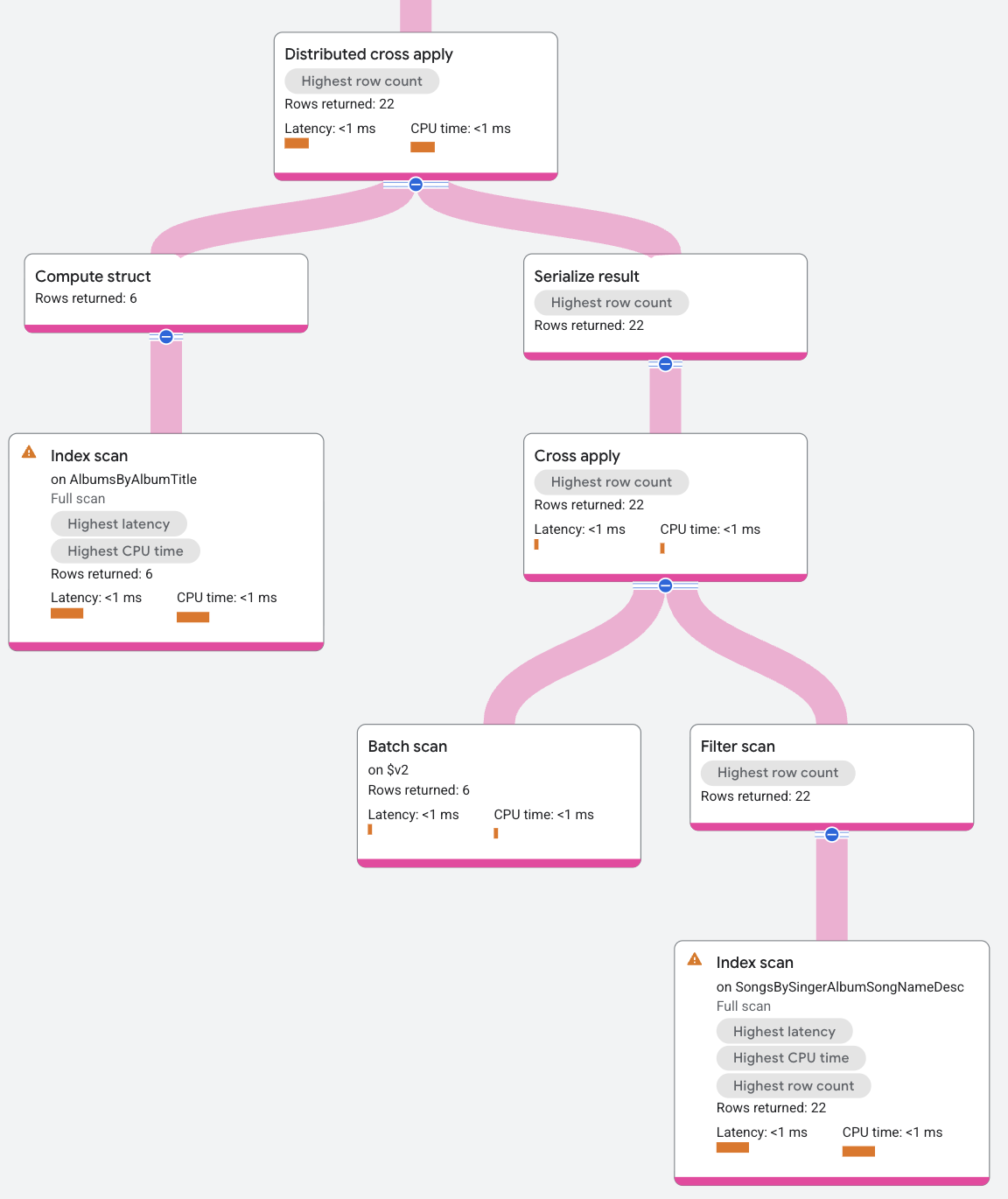
L'input DCA contiene una scansione dell'indice
SongsBySingerAlbumSongNameDesc che raggruppa le righe di AlbumId. La parte
della mappa per DCA è un'applicazione incrociata standard, in cui l'input è un batch di righe e
la parte della mappa è una scansione dell'indice AlbumsByAlbumTitle, soggetta al
predicato di AlbumId nella riga di input corrispondente alla chiave AlbumId nell'indice
AlbumsByAlbumTitle. La mappatura restituisce SongName per i valori SingerId nelle righe di input batch.
Per riassumere la procedura DCA per questo esempio, l'input del DCA sono le righe in batch
della tabella Albums e l'output del DCA è l'applicazione di queste
righe alla mappa della scansione dell'indice.
Applica esterno distribuito
Un operatore Distributed Outer Apply è un DA con semantica left outer join. Per informazioni dettagliate sulla semantica, consulta outer apply.
La seguente query mostra questo operatore:
SELECT lastname,
concertdate
FROM singers LEFT OUTER join@{JOIN_TYPE=APPLY_JOIN} concerts
ON singers.singerid=concerts.singerid;
/*----------+-------------+
| LastName | ConcertDate |
+----------+-------------+
| Trentor | 2014-02-18 |
| Smith | 2011-09-03 |
| Smith | 2010-06-06 |
| Lomond | 2005-04-30 |
| Martin | 2015-11-04 |
| Richards | |
+----------+-------------*/
Il piano di esecuzione viene visualizzato nel seguente modo:
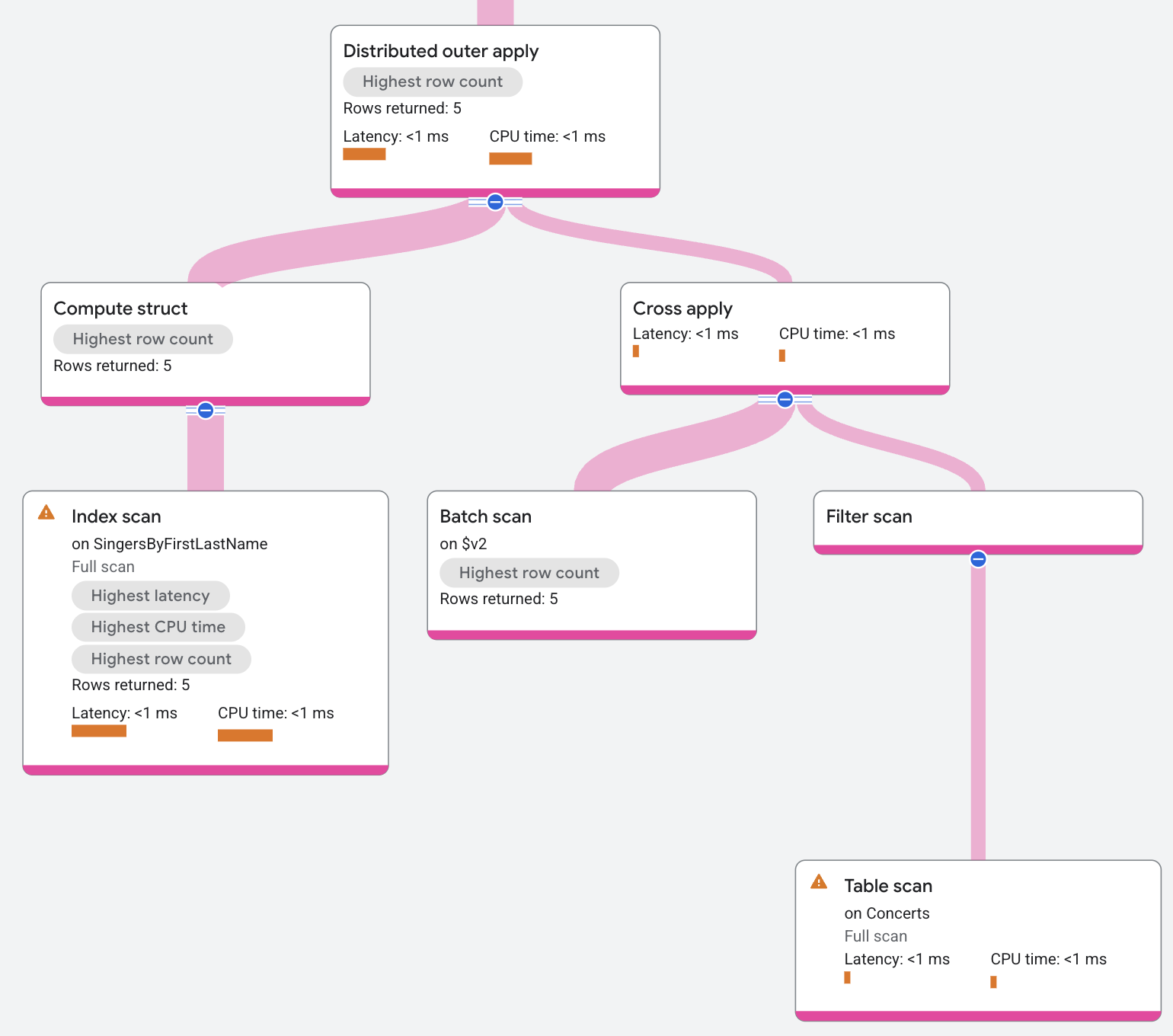
Distributed semi apply
Un Distributed semi apply è un DA con semantica di semi-join. Per informazioni sulla semantica, consulta semi apply.
Distributed anti-semi apply
Un Distributed Anti-Semi Apply è un operatore Distributed Apply con semantica anti-semi join. Per informazioni sulla semantica, consulta anti-semi apply.
Unione di unione distribuita
L'operatore distributed merge union distribuisce una query su più server remoti. Poi combina i risultati della query per produrre un risultato ordinato, noto come ordinamento di unione distribuito.
Un'unione di merge distribuita esegue i seguenti passaggi:
Il server radice invia una sottoquery a ogni server remoto che ospita una suddivisione dei dati sottoposti a query. La sottoquery include istruzioni che i risultati vengono ordinati in un ordine specifico.
Ogni server remoto esegue la sottoquery sulla propria suddivisione, quindi invia i risultati nell'ordine richiesto.
Il server radice unisce la sottoquery ordinata per produrre un risultato completamente ordinato.
L'unione di merge distribuita è abilitata per impostazione predefinita per Spanner versione 3 e successive.
Proprietà e statistiche di esecuzione
Una proprietà di un operatore descrive una caratteristica utilizzata quando l'operatore viene eseguito. Una statistica di esecuzione è un valore raccolto durante l'esecuzione della query per aiutarti a valutare le prestazioni dell'operatore.
L'operatore Applicazione distribuita ha statistiche di esecuzione distinte aggiuntive.Proprietà
| Nome | Descrizione |
|---|---|
| Metodo di esecuzione | Nell'esecuzione per riga, l'operatore elabora una riga alla volta. Nell'esecuzione batch, l'operatore elabora un batch di righe contemporaneamente. |
Statistiche di esecuzione
| Nome | Descrizione |
|---|---|
| Esecuzioni parallele locali | Il numero di sottoquery eseguite in parallelo. |
| Chiamate remote | Il numero di sottoquery remote eseguite. |
| Numero di batch | Un batch è una raccolta dinamica di righe elaborate contemporaneamente. Mostra il numero di batch di un cross-apply distribuito inviati dall'input al lato della mappa. |
| Latenza | Tempo trascorso di tutte le esecuzioni eseguite nell'operatore. |
| Latenza cumulativa | Il tempo totale dell'operatore corrente e dei relativi discendenti. |
| Tempo CPU | Somma del tempo di CPU dedicato all'esecuzione dell'operatore. |
| Tempo di CPU cumulativo | Il tempo di CPU totale dedicato all'esecuzione dell'operatore e dei relativi discendenti. |
| Tempo di esecuzione | Il tempo totale impiegato per eseguire la query ed elaborare i risultati. |
| Righe restituite | Il numero di righe generate da questo operatore |
| Numero di esecuzioni | Il numero di volte in cui l'operatore è stato eseguito. Alcune esecuzioni possono essere eseguite in parallelo. |
Push broadcast hash join
Un operatore push broadcast hash join è un'implementazione distribuita basata su hash join dei join SQL. L'operatore di join hash push broadcast legge le righe dal lato di input per costruire un batch di dati. L'operatore trasmette il batch a tutti i server contenenti dati lato mappa. Sui server di destinazione in cui viene ricevuto il batch di dati, l'operatore crea un hash join utilizzando il batch come dati del lato di build ed esegue la scansione dei dati locali come lato di probe dell'hash join.
Push broadcast hash join presenta i seguenti vantaggi:
- Se la tabella di build è piccola, può essere inviata a tutte le suddivisioni laterali della mappa.
- La tabella laterale della mappa può essere scansionata, con o senza filtri residui. Ciò si verifica quando le chiavi di join non sono uguali alle chiavi primarie della tabella della mappa.
Push broadcast hash join non viene selezionato automaticamente dall'ottimizzatore. Per utilizzare
questo operatore, imposta il metodo di unione su PUSH_BROADCAST_HASH_JOIN nel
suggerimento per la query, come mostrato nell'esempio seguente:
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=push_broadcast_hash_join} songs AS s
ON a.singerid = s.singerid
AND a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
| Nothing To Do With Me | Not About The Guitar |
+-----------------------+--------------------------*/
Il piano di esecuzione viene visualizzato nel seguente modo:
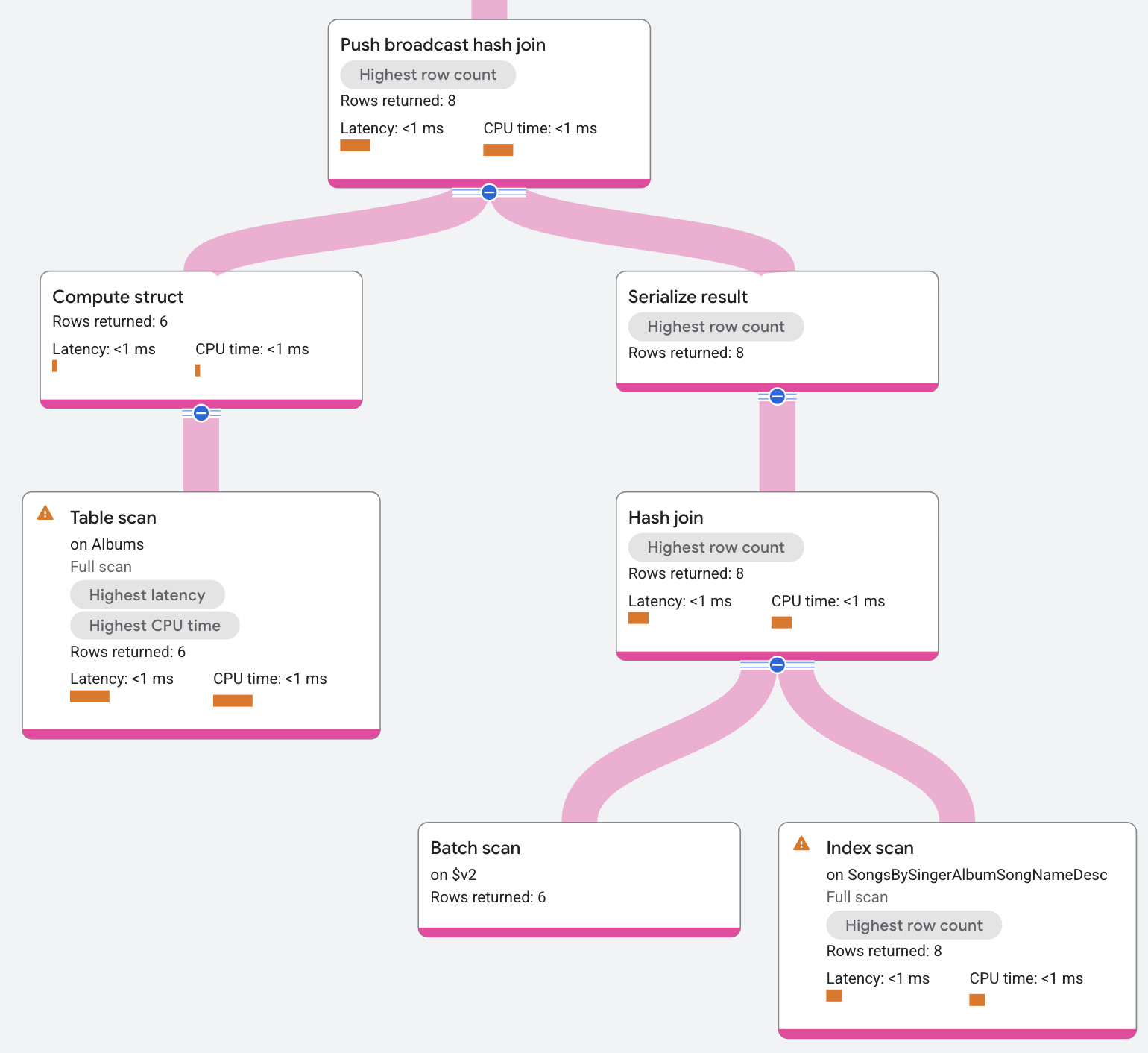
L'input dell'unione hash della trasmissione push è l'indice AlbumsByAlbumTitle.
L'operatore serializza l'input in un batch di dati. L'operatore invia il batch a tutte le suddivisioni locali dell'indice SongsBySingerAlbumSongNameDesc, dove lo deserializza e lo inserisce in una tabella hash. La tabella hash utilizza quindi
i dati dell'indice locale come probe che restituisce le corrispondenze risultanti.
Le corrispondenze risultanti potrebbero anche essere filtrate in base a una condizione residua prima di essere restituite. Un esempio di dove compaiono le condizioni residue è nei join di non uguaglianza.
Proprietà e statistiche di esecuzione
Una proprietà di un operatore descrive una caratteristica utilizzata quando l'operatore viene eseguito. Una statistica di esecuzione è un valore raccolto durante l'esecuzione della query per aiutarti a valutare le prestazioni dell'operatore.
L'operatore Applicazione distribuita ha statistiche di esecuzione distinte aggiuntive.Proprietà
| Nome | Descrizione |
|---|---|
| Metodo di esecuzione | Nell'esecuzione per riga, l'operatore elabora una riga alla volta. Nell'esecuzione batch, l'operatore elabora un batch di righe contemporaneamente. |
Statistiche di esecuzione
| Nome | Descrizione |
|---|---|
| Esecuzioni parallele locali | Il numero di sottoquery eseguite in parallelo. |
| Chiamate remote | Il numero di sottoquery remote eseguite. |
| Numero di batch | Un batch è una raccolta dinamica di righe elaborate contemporaneamente. Mostra il numero di batch di un cross-apply distribuito inviati dall'input al lato della mappa. |
| Latenza | Tempo trascorso di tutte le esecuzioni eseguite nell'operatore. |
| Latenza cumulativa | Il tempo totale dell'operatore corrente e dei relativi discendenti. |
| Tempo CPU | Somma del tempo di CPU dedicato all'esecuzione dell'operatore. |
| Tempo di CPU cumulativo | Il tempo di CPU totale dedicato all'esecuzione dell'operatore e dei relativi discendenti. |
| Tempo di esecuzione | Il tempo totale impiegato per eseguire la query ed elaborare i risultati. |
| Righe restituite | Il numero di righe generate da questo operatore |
| Numero di esecuzioni | Il numero di volte in cui l'operatore è stato eseguito. Alcune esecuzioni possono essere eseguite in parallelo. |