
Un operatore binario ha due elementi secondari relazionali. I seguenti operatori sono binari:
Schema del database
Le query e i piani di esecuzione in questa pagina si basano sul seguente schema del database:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
Puoi utilizzare le seguenti istruzioni DML (Data Manipulation Language) per aggiungere dati a queste tabelle:
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
Applica unione
Un'unione apply è l'operatore di unione principale utilizzato da Spanner. Gli operatori Apply join eseguono l'elaborazione orientata alle righe, a differenza degli operatori che eseguono l'elaborazione basata su set, come hash join. L'operatore Apply ha due input, input (figlio a sinistra) e map (figlio a destra). L'operatore apply applica ogni riga sul lato input al lato mappa utilizzando un metodo apply: cross, outer, semi o anti-semi. Inoltre, una variante di un apply join viene visualizzata anche sul lato della mappa di un Distributed apply.
L'operatore di unione Applica è più efficiente quando:
- La cardinalità dell'input è bassa.
- La chiave di join è un prefisso della chiave primaria lato mappa.
- La query unisce due tabelle con interfoliazione.
Proprietà e statistiche di esecuzione
Una proprietà di un operatore descrive una caratteristica utilizzata quando l'operatore viene eseguito. Una statistica di esecuzione è un valore raccolto durante l'esecuzione della query per aiutarti a valutare le prestazioni dell'operatore.
Proprietà
| Nome | Descrizione |
|---|---|
| Metodo di esecuzione | Nell'esecuzione per riga, l'operatore elabora una riga alla volta. Nell'esecuzione batch, l'operatore elabora un batch di righe contemporaneamente. |
Statistiche di esecuzione
| Nome | Descrizione |
|---|---|
| Latenza | Tempo trascorso di tutte le esecuzioni eseguite nell'operatore. |
| Latenza cumulativa | Il tempo totale dell'operatore corrente e dei relativi discendenti. |
| Tempo CPU | Somma del tempo di CPU dedicato all'esecuzione dell'operatore. |
| Tempo di CPU cumulativo | Il tempo di CPU totale dedicato all'esecuzione dell'operatore e dei relativi discendenti. |
| Tempo di esecuzione | Il tempo totale impiegato per eseguire la query ed elaborare i risultati. |
| Righe restituite | Il numero di righe generate da questo operatore |
| Numero di esecuzioni | Il numero di volte in cui l'operatore è stato eseguito. Alcune esecuzioni possono essere eseguite in parallelo. |
Cross apply
Un cross apply esegue un inner join in cui vengono restituite solo le righe corrispondenti.
La seguente query mostra questo operatore:
La query richiede il nome di ogni cantante, insieme al nome di una sola delle sue canzoni.
SELECT si.firstname,
(SELECT so.songname
FROM songs AS so
WHERE so.singerid = si.singerid
LIMIT 1)
FROM singers AS si;
/*-----------+--------------------------+
| FirstName | Unspecified |
+-----------+--------------------------+
| Alice | Not About The Guitar |
| Catalina | Let's Get Back Together |
| David | NULL |
| Lea | NULL |
| Marc | NULL |
+-----------+--------------------------*/
La query compila la prima colonna dalla tabella Singers e la seconda colonna dalla tabella Songs. Nei casi in cui esisteva un SingerId nella
tabella Singers ma non c'era un SingerId corrispondente nella tabella Songs, la
seconda colonna contiene NULL.
Il piano di esecuzione inizia come segue:
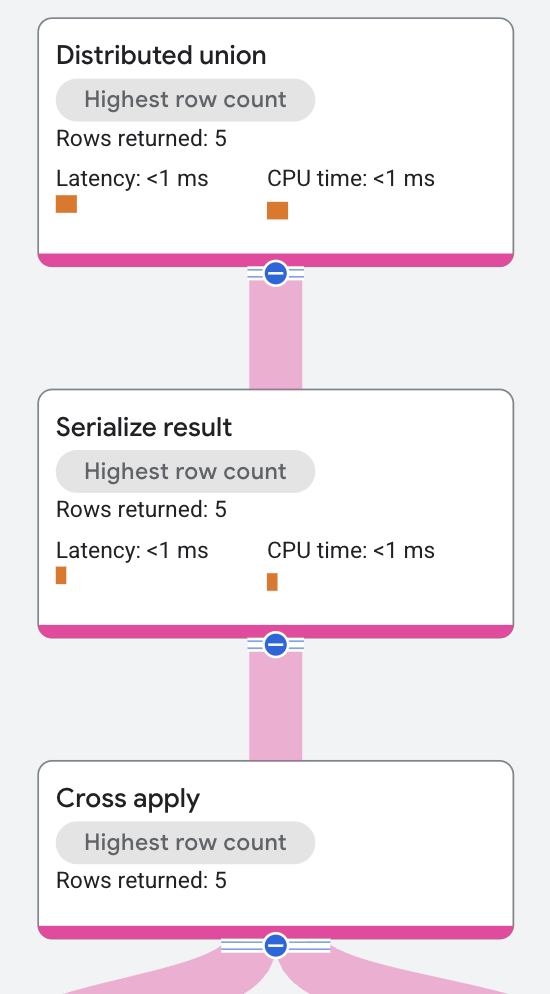
Il nodo di primo livello è un operatore di unione distribuita. L'operatore di unione distribuita distribuisce i piani secondari ai server remoti. Il piano secondario contiene un operatore serialize result che calcola il nome del cantante e il titolo di una delle sue canzoni e serializza ogni riga dell'output.
L'operatore di serializzazione dei risultati riceve l'input da un operatore di applicazione incrociata.
Il lato di input dell'operatore Cross Apply è una
scansione della tabella
Singers.
Il piano di esecuzione continua come segue:
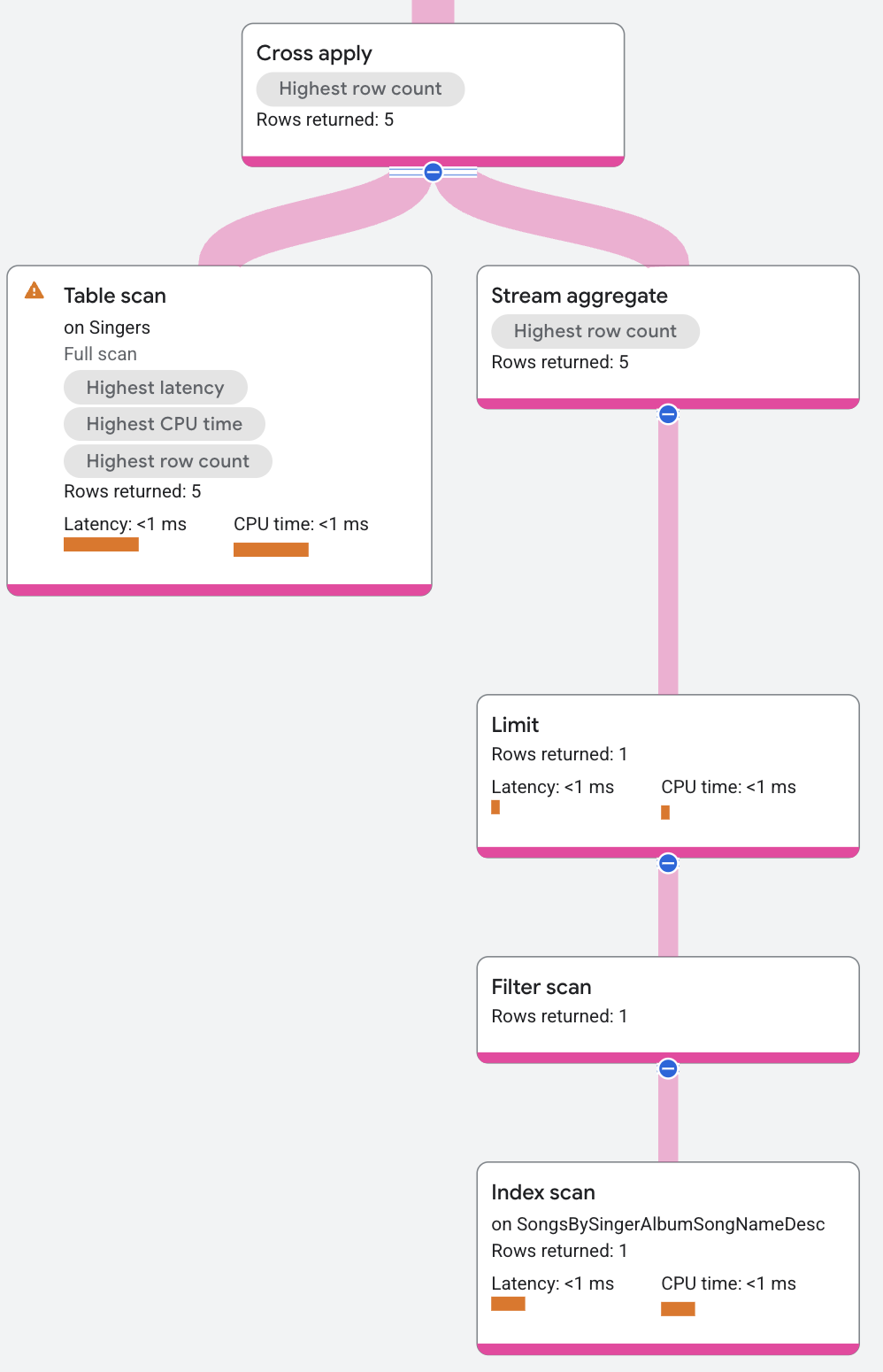
Il lato della mappa per l'operazione di applicazione incrociata contiene quanto segue (dall'alto verso il basso):
- Un operatore aggregato che
restituisce
Songs.SongName. - Un operatore limit che limita il numero di brani restituiti a uno per cantante.
- Una scansione dell'indice
SongsBySingerAlbumSongNameDesc.
L'operatore Cross Apply mappa ogni riga del lato input a una riga del lato mappa
che ha lo stesso SingerId. L'output dell'operatore Cross Apply è il valore FirstName della riga di input e il valore SongName della riga della mappa.
(Il valore di SongName è NULL se non esiste una riga della mappa che corrisponda a SingerId.) L'operatore di unione distribuita nella parte superiore del piano di esecuzione combina tutte le righe di output dei server remoti e le restituisce come risultati della query.
Applica esterno
Un outer apply fornisce la semantica del left outer join. Garantisce che ogni esecuzione sul lato mappa restituisca almeno una riga aggiungendo un riempimento NULL se necessario.
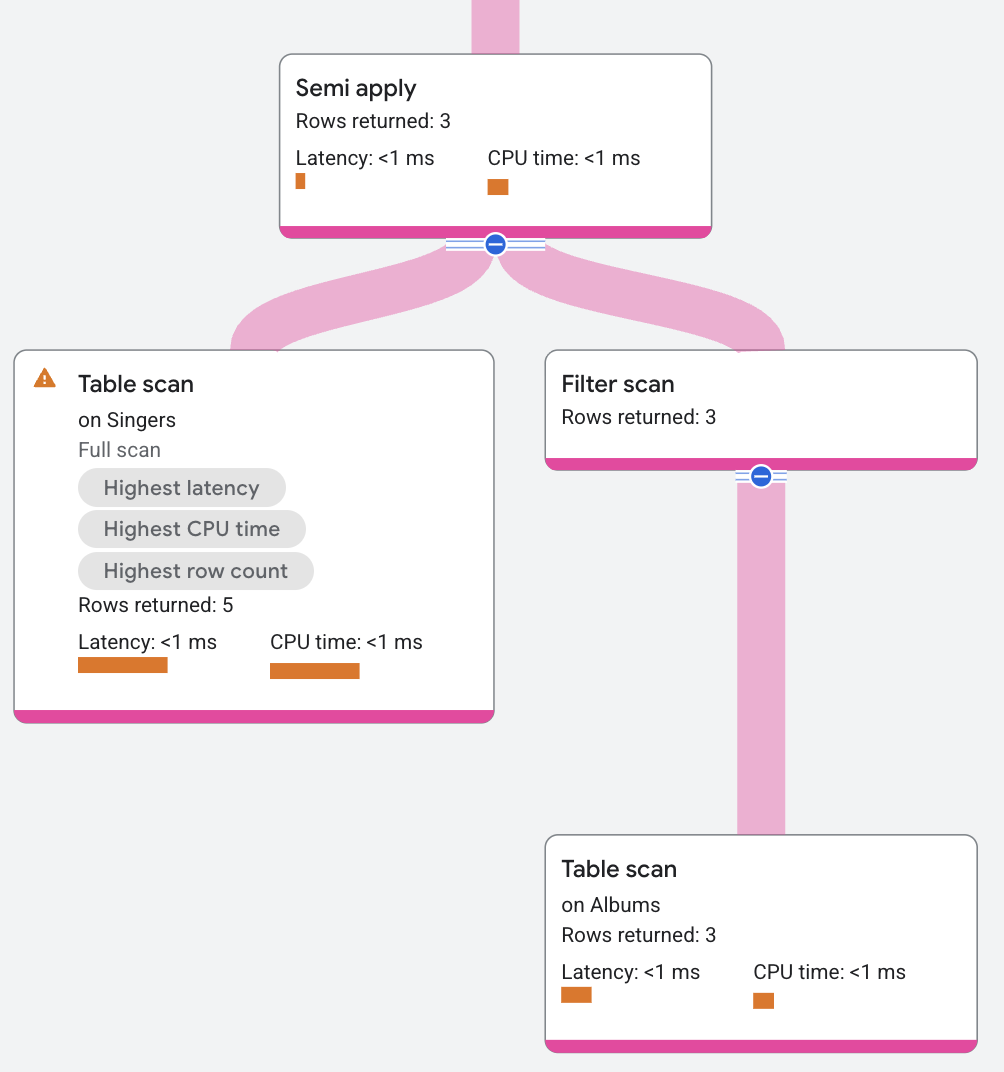
Semi apply
L'operatore semi apply restituisce le colonne di input solo quando si verifica una corrispondenza sul lato della mappa.
La seguente query utilizza un semi join per trovare i cantanti che hanno un album:
SELECT
FirstName,
LastName
FROM
Singers
WHERE
SingerId IN (
SELECT
SingerId
FROM
Albums);
/*-----------+----------+
| FirstName | LastName |
+-----------+----------+
| Marc | Richards |
| Catalina | Smith |
| Alice | Trentor |
| Lea | Martin |
+-----------+----------*/
Il segmento del piano viene visualizzato come segue:
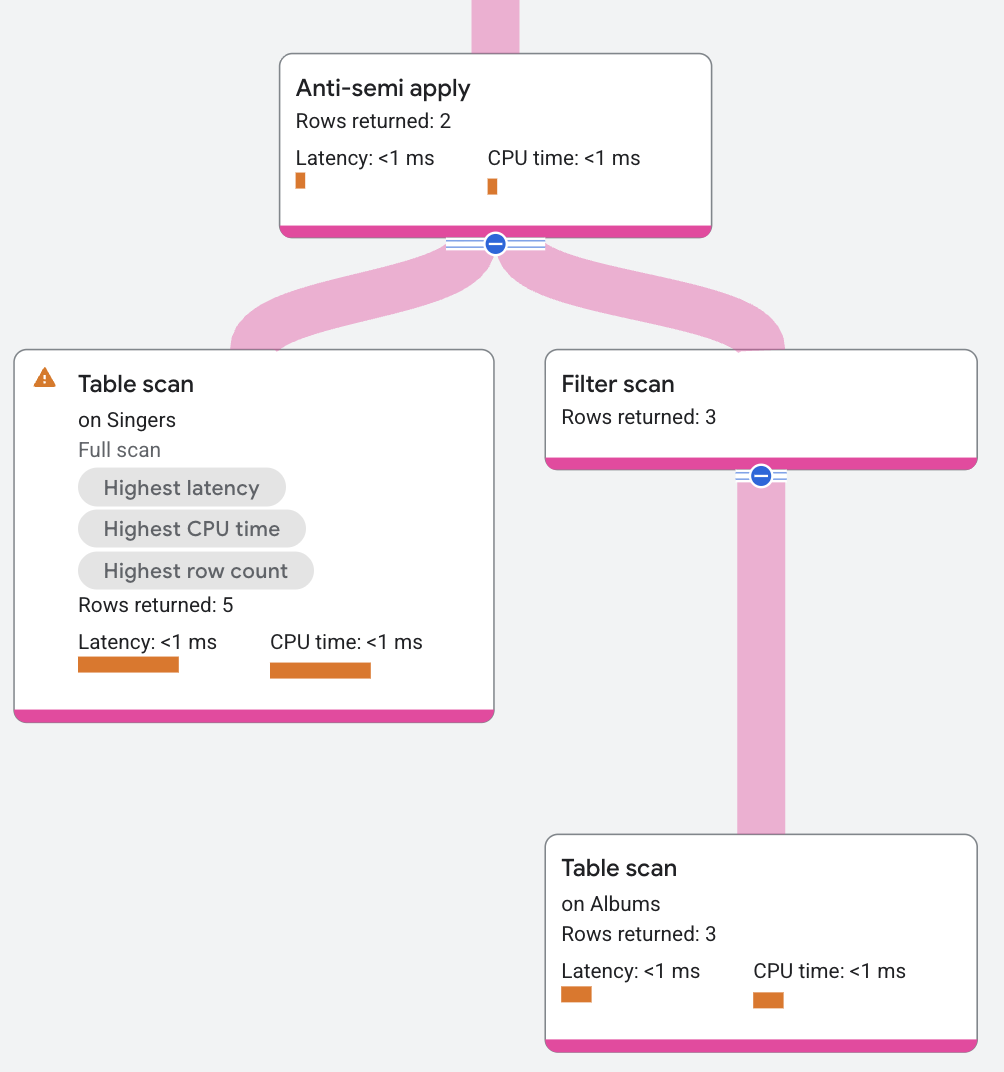
Anti-semi apply
Un operatore Anti-semi apply è simile a un operatore semi apply, tranne per il fatto che restituisce le colonne della tabella di input solo quando non si verifica una corrispondenza sul lato mappa.
La seguente query utilizza un anti-semi join per trovare i cantanti che non hanno un album:
SELECT
FirstName,
LastName
FROM
Singers
WHERE
SingerId NOT IN (
SELECT
SingerId
FROM
Albums);
/*-----------+----------+
| FirstName | LastName |
+-----------+----------+
| David | Lomond |
+-----------+----------*/
Il segmento del piano viene visualizzato come segue:
Hash join
Un operatore hash join è un'implementazione basata su hash dei join SQL. I join hash eseguono l'elaborazione basata su set. L'operatore di hash join legge le righe dall'input contrassegnato come build (elemento secondario a sinistra) e le inserisce in una tabella hash in base a una condizione di join. L'operatore Hash Join legge quindi le righe dell'input contrassegnato come probe (elemento figlio destro). Per ogni riga letta dall'input del probe, l'operatore hash join cerca le righe corrispondenti nella tabella hash. L'operatore di hash join restituisce le righe corrispondenti come risultato.
L'hash join presenta i seguenti vantaggi:
- Non richiede che gli input siano ordinati
- Calcola un filtro Bloom durante la creazione della tabella hash. L'operatore utilizza il filtro per escludere le righe dal lato probe che non hanno corrispondenze. Tieni presente che si tratta di un filtro residuo, non di un filtro di ricerca.
La seguente query mostra questo operatore:
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=hash_join} songs AS s
ON a.singerid = s.singerid
AND a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Nothing To Do With Me | Not About The Guitar |
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
+-----------------------+--------------------------*/
Il segmento del piano di esecuzione viene visualizzato nel seguente modo:
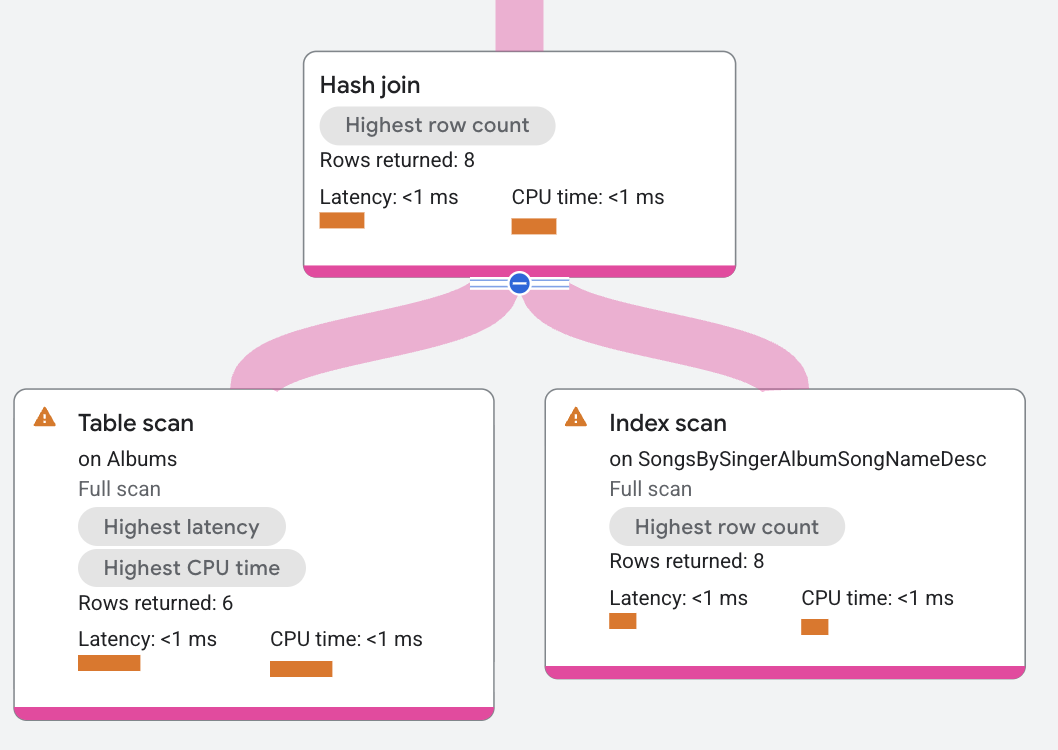
Nel piano di esecuzione, build è un'unione distribuita che
distribuisce le scansioni nella tabella Albums. Probe è un operatore di unione distribuita che distribuisce le scansioni sull'indice SongsBySingerAlbumSongNameDesc.
L'operatore Hash Join legge tutte le righe dal lato di build. Ogni riga di build viene
inserita in una tabella hash in base alle colonne della condizione a.SingerId =
s.SingerId AND a.AlbumId = s.AlbumId. Successivamente, l'operatore hash join legge tutte le righe del lato probe. Per ogni riga di probing, l'operatore di hash join cerca
corrispondenze nella tabella hash. Le corrispondenze risultanti vengono restituite dall'operatore
hash join.
Le corrispondenze risultanti nella tabella hash potrebbero anche essere filtrate in base a una condizione residua prima di essere restituite. Un esempio di dove compaiono le condizioni residue è nei join di non uguaglianza. I piani di esecuzione di Hash Join possono essere complessi a causa della gestione della memoria e delle varianti di join. L'algoritmo principale di hash join è adattato per gestire le varianti di inner join, semi join, anti join e outer join.
Proprietà e statistiche di esecuzione
Una proprietà di un operatore descrive una caratteristica utilizzata quando l'operatore viene eseguito. Una statistica di esecuzione è un valore raccolto durante l'esecuzione della query per aiutarti a valutare le prestazioni dell'operatore.
Proprietà
| Nome | Descrizione |
|---|---|
| Metodo di esecuzione | Nell'esecuzione per riga, l'operatore elabora una riga alla volta. Nell'esecuzione batch, l'operatore elabora un batch di righe contemporaneamente. |
Statistiche di esecuzione
| Nome | Descrizione |
|---|---|
| Latenza | Tempo trascorso di tutte le esecuzioni eseguite nell'operatore. |
| Latenza cumulativa | Il tempo totale dell'operatore corrente e dei relativi discendenti. |
| Tempo CPU | Somma del tempo di CPU dedicato all'esecuzione dell'operatore. |
| Tempo di CPU cumulativo | Il tempo di CPU totale dedicato all'esecuzione dell'operatore e dei relativi discendenti. |
| Tempo di esecuzione | Il tempo totale impiegato per eseguire la query ed elaborare i risultati. |
| Righe restituite | Il numero di righe generate da questo operatore |
| Numero di esecuzioni | Il numero di volte in cui l'operatore è stato eseguito. Alcune esecuzioni possono essere eseguite in parallelo. |
Unione
Un operatore merge join è un'implementazione basata sull'unione del join SQL. Entrambe le parti
del join producono righe ordinate in base alle colonne utilizzate nella condizione di join. Il
merge join utilizza entrambi i flussi di input contemporaneamente e restituisce le righe quando
la condizione di join è soddisfatta. Se gli input non sono ordinati, lo strumento di ottimizzazione aggiunge
operatori Sort espliciti al piano.
Unione di tipo Merge presenta i seguenti vantaggi:
- Se i dati sono già ordinati, non è necessaria alcuna memoria.
- Anche se i dati non sono ordinati, per un join distribuito può eseguire l'ordinamento su ogni singola suddivisione, anziché creare una grande tabella hash sulla radice.
Unione di tipo Merge non viene selezionata automaticamente dall'ottimizzatore. Per utilizzare questo operatore, imposta il metodo di unione su MERGE_JOIN nel suggerimento per la query, come mostrato nell'esempio seguente:
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=merge_join} songs AS s
ON a.singerid = s.singerid
AND a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
| Nothing To Do With Me | Not About The Guitar |
+-----------------------+--------------------------*/
Il piano di esecuzione viene visualizzato nel seguente modo:
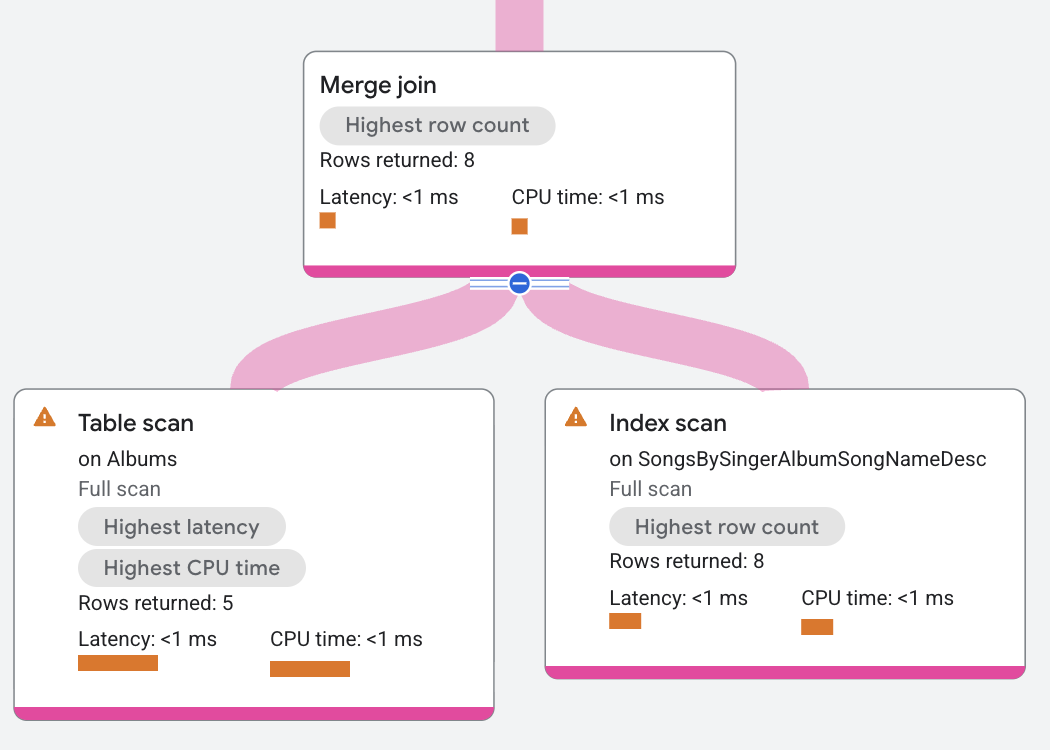
In questo piano di esecuzione, l'unione di tipo merge viene distribuita in modo che l'unione venga eseguita
dove risiedono i dati. In questo modo, il merge join in questo esempio può operare
senza operatori di ordinamento aggiuntivi, perché entrambe le scansioni delle tabelle sono già ordinate
per SingerId, AlbumId, che è la condizione di join. In questo piano, la scansione
a sinistra della tabella Albums avanza ogni volta che i valori SingerId e AlbumId sono inferiori
ai valori SingerId_1 e AlbumId_1 della scansione a destra. Allo stesso modo, la scansione
a destra avanza ogni volta che i suoi valori sono inferiori a quelli della scansione a sinistra. Questa
unione avanzata continua a cercare equivalenze per restituire le righe corrispondenti.
Considera un altro esempio di merge join utilizzando la seguente query:
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=merge_join} songs AS s
ON a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Total Junk | The Second Time |
| Total Junk | Starting Again |
| Total Junk | Nothing Is The Same |
| Total Junk | Let's Get Back Together |
| Total Junk | I Knew You Were Magic |
| Total Junk | Blue |
| Total Junk | 42 |
| Total Junk | Not About The Guitar |
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Green | Not About The Guitar |
| Nothing To Do With Me | The Second Time |
| Nothing To Do With Me | Starting Again |
| Nothing To Do With Me | Nothing Is The Same |
| Nothing To Do With Me | Let's Get Back Together |
| Nothing To Do With Me | I Knew You Were Magic |
| Nothing To Do With Me | Blue |
| Nothing To Do With Me | 42 |
| Nothing To Do With Me | Not About The Guitar |
| Play | The Second Time |
| Play | Starting Again |
| Play | Nothing Is The Same |
| Play | Let's Get Back Together |
| Play | I Knew You Were Magic |
| Play | Blue |
| Play | 42 |
| Play | Not About The Guitar |
| Terrified | Fight Story |
+-----------------------+--------------------------*/
Il piano di esecuzione viene visualizzato nel seguente modo:
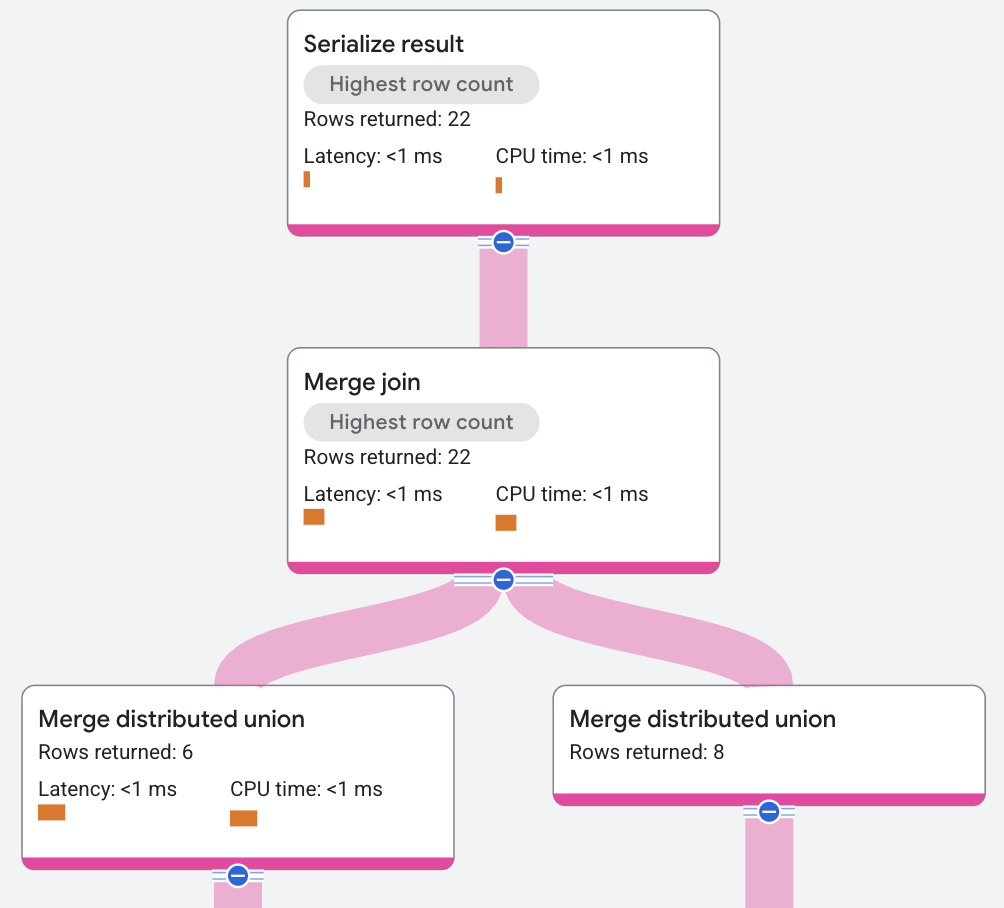
Nel piano di esecuzione precedente, l'ottimizzatore delle query ha introdotto operatori di ordinamento aggiuntivi per eseguire l'unione di tipo merge. La condizione JOIN in questa query di esempio
riguarda solo AlbumId, che non è il modo in cui vengono archiviati i dati, quindi è necessario
aggiungere un ordinamento. Il motore di query supporta un algoritmo di unione distribuita, che consente
l'ordinamento a livello locale anziché globale, distribuendo e parallelizzando il costo
della CPU.
Le corrispondenze risultanti potrebbero anche essere filtrate in base a una condizione residua. Ad esempio, le condizioni residue vengono visualizzate nei join di non uguaglianza. I piani di esecuzione di unione possono essere complessi a causa di ulteriori requisiti di ordinamento. L'algoritmo principale di unione gestisce le varianti di inner, semi, anti e outer join.
Proprietà e statistiche di esecuzione
Una proprietà di un operatore descrive una caratteristica utilizzata quando l'operatore viene eseguito. Una statistica di esecuzione è un valore raccolto durante l'esecuzione della query per aiutarti a valutare le prestazioni dell'operatore.
Proprietà
| Nome | Descrizione |
|---|---|
| Metodo di esecuzione | Nell'esecuzione per riga, l'operatore elabora una riga alla volta. Nell'esecuzione batch, l'operatore elabora un batch di righe contemporaneamente. |
Statistiche di esecuzione
| Nome | Descrizione |
|---|---|
| Latenza | Tempo trascorso di tutte le esecuzioni eseguite nell'operatore. |
| Latenza cumulativa | Il tempo totale dell'operatore corrente e dei relativi discendenti. |
| Tempo CPU | Somma del tempo di CPU dedicato all'esecuzione dell'operatore. |
| Tempo di CPU cumulativo | Il tempo di CPU totale dedicato all'esecuzione dell'operatore e dei relativi discendenti. |
| Tempo di esecuzione | Il tempo totale impiegato per eseguire la query ed elaborare i risultati. |
| Righe restituite | Il numero di righe generate da questo operatore |
| Numero di esecuzioni | Il numero di volte in cui l'operatore è stato eseguito. Alcune esecuzioni possono essere eseguite in parallelo. |
Unione ricorsiva
Un operatore recursive union esegue l'unione di due input, uno che rappresenta
un caso base e l'altro che rappresenta un caso recursive. Viene utilizzato nelle query grafiche con attraversamenti di percorsi quantificati. L'input di base viene elaborato per primo
e una sola volta. L'input ricorsivo viene elaborato fino al termine della ricorsione. La ricorsione termina quando viene raggiunto il limite superiore, se specificato, o quando non produce nuovi risultati. Nell'esempio
seguente, la tabella Collaborations viene aggiunta allo schema e viene creato un grafico delle proprietà
denominato MusicGraph.
CREATE TABLE Collaborations (
SingerId INT64 NOT NULL,
FeaturingSingerId INT64 NOT NULL,
AlbumTitle STRING(MAX) NOT NULL,
) PRIMARY KEY(SingerId, FeaturingSingerId, AlbumTitle);
CREATE OR REPLACE PROPERTY GRAPH MusicGraph
NODE TABLES(
Singers
KEY(SingerId)
LABEL Singers PROPERTIES(
BirthDate,
FirstName,
LastName,
SingerId,
SingerInfo)
)
EDGE TABLES(
Collaborations AS CollabWith
KEY(SingerId, FeaturingSingerId, AlbumTitle)
SOURCE KEY(SingerId) REFERENCES Singers(SingerId)
DESTINATION KEY(FeaturingSingerId) REFERENCES Singers(SingerId)
LABEL CollabWith PROPERTIES(
AlbumTitle,
FeaturingSingerId,
SingerId),
);
La seguente query del grafico trova i cantanti che hanno collaborato con un determinato cantante o con i suoi collaboratori.
GRAPH MusicGraph
MATCH (singer:Singers {singerId:42})-[c:CollabWith]->{1,2}(featured:Singers)
RETURN singer.SingerId AS singer, featured.SingerId AS featured
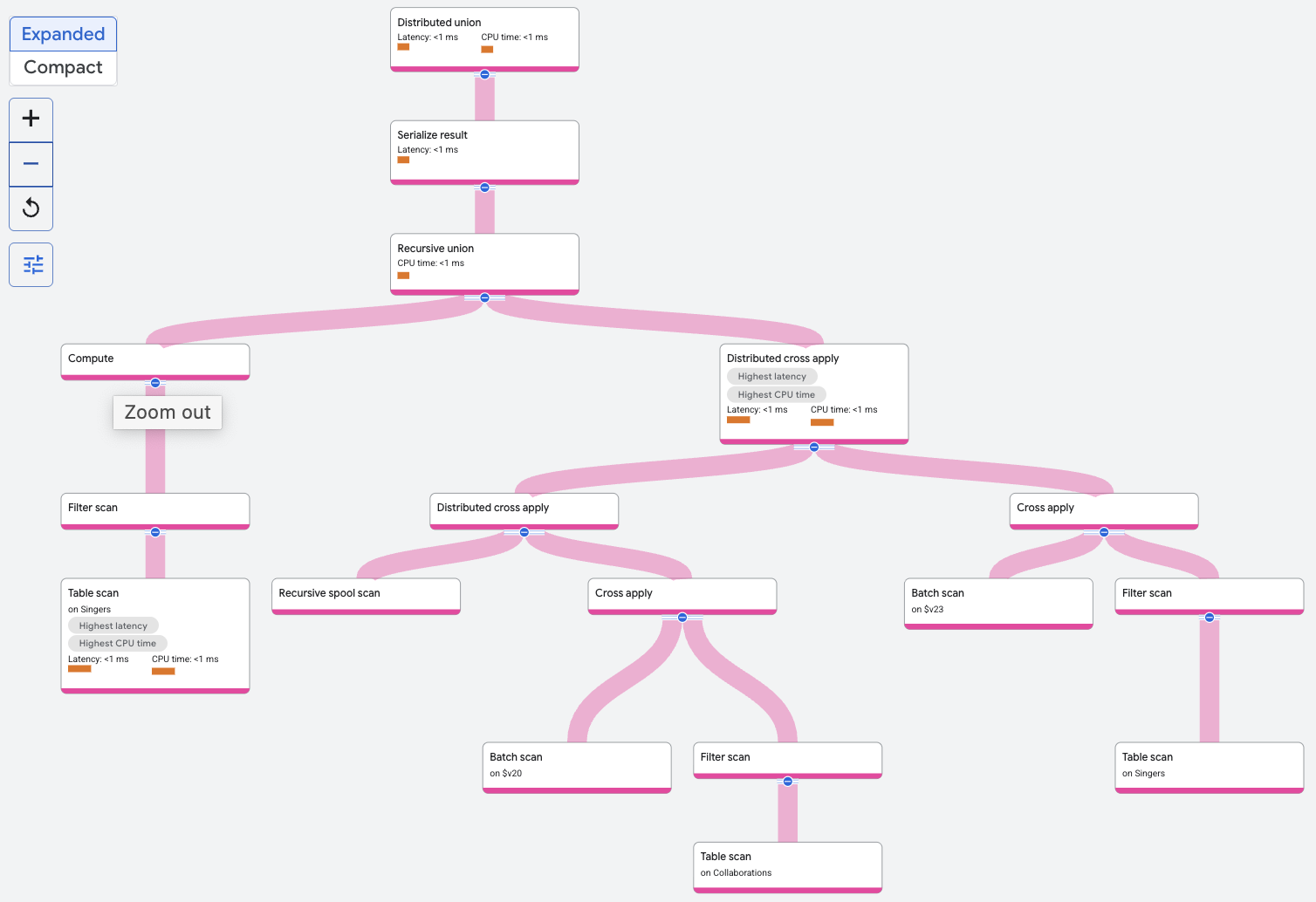
L'operatore di unione ricorsiva filtra la tabella Singers per trovare il cantante
con il SingerId specificato. Questo è l'input di base per l'unione ricorsiva. L'input ricorsivo per l'unione ricorsiva comprende un cross apply distribuito o un altro operatore di join per altre query che uniscono ripetutamente la tabella Collaborations con i risultati dell'iterazione precedente del join. Le righe del modulo di input di base costituiscono la prima iterazione.
A ogni iterazione, l'output viene archiviato dalla scansione
dello spool ricorsivo. Le righe della scansione spool ricorsiva vengono unite alla tabella Collaborations
in spoolscan.featuredSingerId = Collaborations.SingerId. La ricorsione
termina al completamento di due iterazioni, poiché questo è il limite superiore
specificato nella query.
Proprietà e statistiche di esecuzione
Una proprietà di un operatore descrive una caratteristica utilizzata quando l'operatore viene eseguito. Una statistica di esecuzione è un valore raccolto durante l'esecuzione della query per aiutarti a valutare le prestazioni dell'operatore.
Proprietà
| Nome | Descrizione |
|---|---|
| Metodo di esecuzione | Nell'esecuzione per riga, l'operatore elabora una riga alla volta. Nell'esecuzione batch, l'operatore elabora un batch di righe contemporaneamente. |
Statistiche di esecuzione
| Nome | Descrizione |
|---|---|
| Latenza | Tempo trascorso di tutte le esecuzioni eseguite nell'operatore. |
| Latenza cumulativa | Il tempo totale dell'operatore corrente e dei relativi discendenti. |
| Tempo CPU | Somma del tempo di CPU dedicato all'esecuzione dell'operatore. |
| Tempo di CPU cumulativo | Il tempo di CPU totale dedicato all'esecuzione dell'operatore e dei relativi discendenti. |
| Tempo di esecuzione | Il tempo totale impiegato per eseguire la query ed elaborare i risultati. |
| Righe restituite | Il numero di righe generate da questo operatore |
| Numero di esecuzioni | Il numero di volte in cui l'operatore è stato eseguito. Alcune esecuzioni possono essere eseguite in parallelo. |