
Les opérateurs distribués s'exécutent sur plusieurs serveurs, contrairement aux opérateurs feuille, unaire, binaire ou n-aire.
Les opérateurs suivants sont des opérateurs distribués :
Schéma de base de données
Les requêtes et les plans d'exécution de cette page sont basés sur le schéma de base de données suivant :
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
Vous pouvez utiliser les instructions LMD (langage de manipulation de données) suivantes pour ajouter des données à ces tables :
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
L'opérateur distributed union est l'opérateur primitif d'où proviennent l'application croisée distribuée et l'application externe distribuée.
Les opérateurs distribués apparaissent dans les plans d'exécution avec une variante d'union distribuée en plus d'une ou plusieurs variantes d'union distribuée locale. Une variante d'union distribuée effectue la distribution à distance des sous-plans.
Une variante d'union distribuée locale se trouve au-dessus de chacune des analyses effectuées pour la requête. Les variantes d'union distribuée locale garantissent une exécution stable des requêtes lors de redémarrages visant à modifier de façon dynamique les limites de partition. Bien que cet opérateur soit masqué dans le plan visuel, il est toujours présent.
Chaque fois que cela est possible, une variante d'union distribuée utilise un prédicat de partition pour l'élimination de la partition. L'élimination des partitions signifie que les serveurs distants n'exécutent des sous-plans que sur les partitions correspondant au prédicat, ce qui améliore la latence et les performances des requêtes.
Distributed union
L'opérateur distributed union divise de manière conceptuelle une ou plusieurs tables en différentes partitions, évalue à distance et de manière indépendante une sous-requête sur chaque partition, puis réunit tous les résultats.
La requête suivante illustre cet opérateur :
SELECT s.songname,
s.songgenre
FROM songs AS s
WHERE s.singerid = 2
AND s.songgenre = 'ROCK';
/*-----------------+-----------+
| SongName | SongGenre |
+-----------------+-----------+
| Starting Again | ROCK |
| The Second Time | ROCK |
| Fight Story | ROCK |
+-----------------+-----------*/
Le plan d'exécution se présente comme suit :
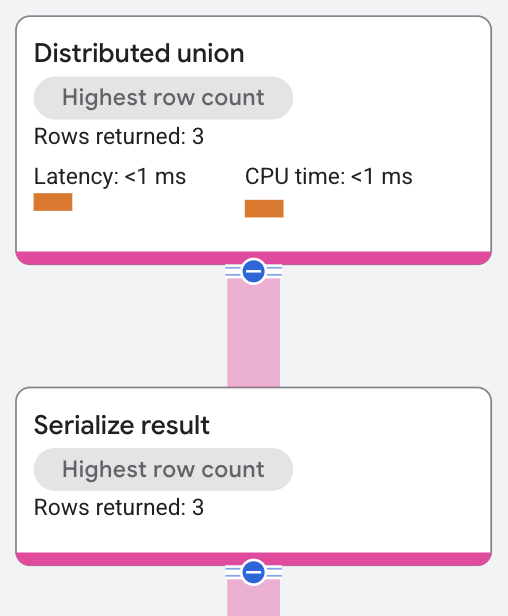
L'opérateur distributed union envoie des sous-plans aux serveurs distants, qui effectuent une analyse de table sur des partitions concordant avec le prédicat WHERE s.SingerId = 2 AND s.SongGenre = 'ROCK' de la requête.
Un opérateur serialize result calcule les valeurs SongName et SongGenre à partir des lignes renvoyées par les analyses de table. L'opérateur distributed union renvoie ensuite les résultats combinés des serveurs distants en tant que résultats de la requête SQL.
Propriétés et statistiques d'exécution
Une propriété d'un opérateur décrit un trait utilisé lors de l'exécution de l'opérateur. Une statistique d'exécution est une valeur collectée lors de l'exécution d'une requête pour vous aider à évaluer les performances de l'opérateur.
L'opérateur Distributed union comporte des statistiques d'exécution distinctes supplémentaires.Propriétés
| Nom | Description |
|---|---|
| Méthode d'exécution | Dans l'exécution de ligne, l'opérateur traite une ligne à la fois. Dans l'exécution par lot, l'opérateur traite un lot de lignes à la fois. |
Statistiques d'exécution
| Nom | Description |
|---|---|
| Exécutions parallèles locales | Nombre de sous-requêtes exécutées en parallèle. |
| Appels distants | Nombre de sous-requêtes distantes exécutées. |
| Latence | Temps écoulé pour toutes les exécutions effectuées dans l'opérateur. |
| Latence cumulée | Temps total de l'opérateur actuel et de ses descendants. |
| Temps CPU | Somme du temps CPU consacré à l'exécution de l'opérateur. |
| Temps CPU cumulé | Temps CPU total utilisé pour exécuter l'opérateur et ses descendants. |
| Durée d'exécution | Temps total nécessaire pour exécuter la requête et traiter les résultats. |
| Lignes renvoyées | Nombre de lignes générées par cet opérateur |
| Nombre d'exécutions | Nombre de fois où l'opérateur a été exécuté. Certaines exécutions peuvent s'effectuer en parallèle. |
En général, les exécutions sont parallèles, contrairement aux exécutions d'application croisée. Pour cette raison, les chiffres de latence des opérateurs distribués sont cumulatifs, contrairement à la plupart des opérateurs, qui indiquent la latence ajoutée par l'opérateur. Le nombre d'exécutions sous une union distribuée est basé sur les limites de fractionnement de la table, qui dépendent à leur tour de la taille et de la charge des données, et peuvent inclure l'indication d'instruction use_additional_parallelism. Cette approche des statistiques s'applique à tous les opérateurs distribués.
Distributed apply
L'opérateur distributed apply (DA) étend l'opérateur apply join en s'exécutant sur plusieurs serveurs. Le côté entrée regroupe les lignes en lots (contrairement à un opérateur cross apply classique, qui agit sur une seule ligne d'entrée à la fois). Le côté carte de l'application distribuée est un ensemble d'opérateurs de jointure apply simple qui s'exécutent sur des serveurs distants. Une jointure distributed apply est compatible avec les mêmes méthodes apply que apply join.
Propriétés et statistiques d'exécution
Une propriété d'un opérateur décrit un trait utilisé lors de l'exécution de l'opérateur. Une statistique d'exécution est une valeur collectée lors de l'exécution d'une requête pour vous aider à évaluer les performances de l'opérateur.
L'opérateur Distributed apply dispose de statistiques d'exécution distinctes supplémentaires.Propriétés
| Nom | Description |
|---|---|
| Méthode d'exécution | Dans l'exécution de ligne, l'opérateur traite une ligne à la fois. Dans l'exécution par lot, l'opérateur traite un lot de lignes à la fois. |
Statistiques d'exécution
| Nom | Description |
|---|---|
| Exécutions parallèles locales | Nombre de sous-requêtes exécutées en parallèle. |
| Appels distants | Nombre de sous-requêtes distantes exécutées. |
| Nombre de lots | Un lot est une collection dynamique de lignes traitées en même temps. Indique le nombre de lots qu'une application croisée distribuée a envoyés de l'entrée au côté Map. |
| Latence | Temps écoulé pour toutes les exécutions effectuées dans l'opérateur. |
| Latence cumulée | Temps total de l'opérateur actuel et de ses descendants. |
| Temps CPU | Somme du temps CPU consacré à l'exécution de l'opérateur. |
| Temps CPU cumulé | Temps CPU total utilisé pour exécuter l'opérateur et ses descendants. |
| Durée d'exécution | Temps total nécessaire pour exécuter la requête et traiter les résultats. |
| Lignes renvoyées | Nombre de lignes générées par cet opérateur |
| Nombre d'exécutions | Nombre de fois où l'opérateur a été exécuté. Certaines exécutions peuvent s'effectuer en parallèle. |
Distributed cross apply
La requête suivante illustre cet opérateur :
SELECT albumtitle
FROM songs
JOIN albums
ON albums.albumid = songs.albumid;
/*-----------------------+
| AlbumTitle |
+-----------------------+
| Green |
| Nothing To Do With Me |
| Play |
| Total Junk |
| Green |
+-----------------------*/
Le plan d'exécution se présente comme suit :
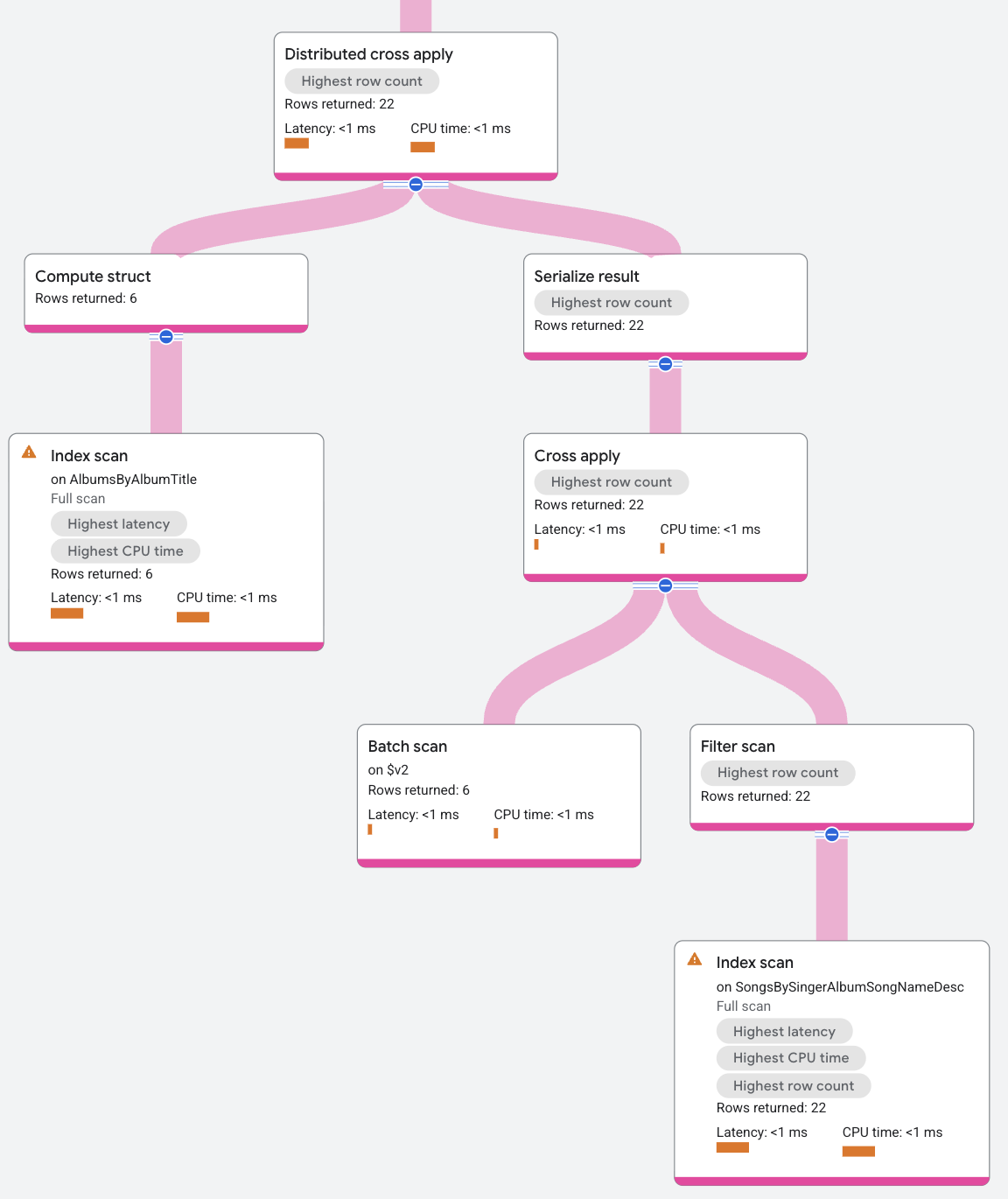
L'entrée de l'application croisée contient une analyse d'index sur SongsBySingerAlbumSongNameDesc qui regroupe les lignes de AlbumId. Le côté carte de l'application croisée distribuée est une application croisée standard, où l'entrée est un lot de lignes et le côté carte est une analyse d'index sur l'index AlbumsByAlbumTitle, à condition que le prédicat de AlbumId dans la ligne d'entrée corresponde à la clé AlbumId dans l'index AlbumsByAlbumTitle. Le mappage renvoie la valeur SongName pour les valeurs SingerId dans les lignes d'entrée regroupées.
Récapitulons le processus d'application croisée distribuée utilisé dans cet exemple. L'entrée de l'application croisée distribuée correspond aux lignes regroupées de la table Albums. La sortie de l'application croisée distribuée correspond quant à elle à l'application de ces lignes à la carte de l'analyse d'index.
Distributed outer apply
Un distributed outer apply est un DA avec une sémantique de jointure externe gauche. Pour en savoir plus sur la sémantique, consultez outer apply.
La requête suivante illustre cet opérateur :
SELECT lastname,
concertdate
FROM singers LEFT OUTER join@{JOIN_TYPE=APPLY_JOIN} concerts
ON singers.singerid=concerts.singerid;
/*----------+-------------+
| LastName | ConcertDate |
+----------+-------------+
| Trentor | 2014-02-18 |
| Smith | 2011-09-03 |
| Smith | 2010-06-06 |
| Lomond | 2005-04-30 |
| Martin | 2015-11-04 |
| Richards | |
+----------+-------------*/
Le plan d'exécution se présente comme suit :
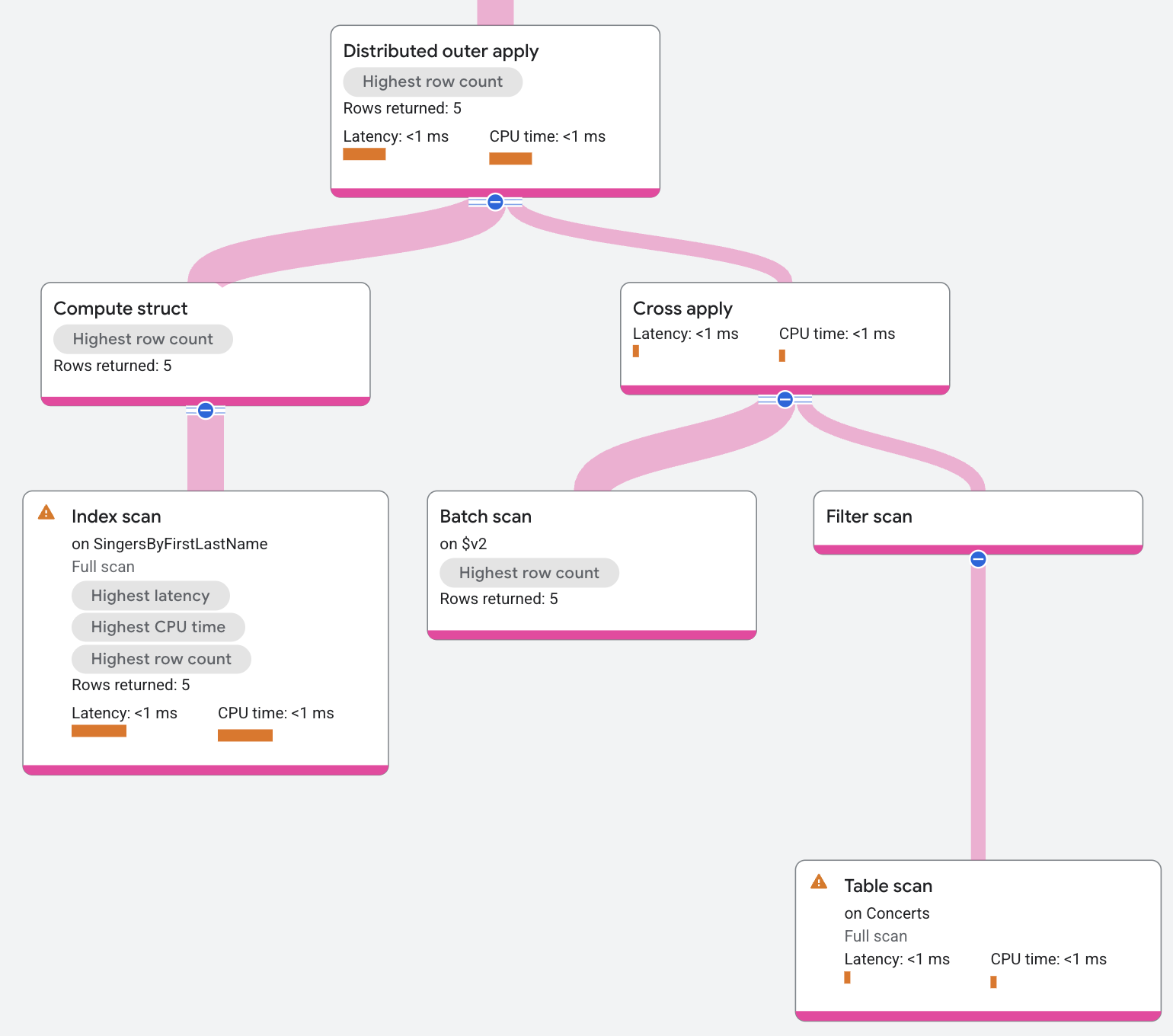
Distributed semi apply
Un distributed semi apply est un DA avec une sémantique de semi-jointure. Pour en savoir plus sur la sémantique, consultez semi apply.
Distributed anti-semi apply
Un distributed anti-semi apply est un DA avec une sémantique d'anti-semi-jointure. Pour en savoir plus sur la sémantique, consultez anti-semi apply.
Distributed merge union
L'opérateur distributed merge union distribue une requête sur plusieurs serveurs distants. Il combine ensuite les résultats de la requête pour produire un résultat trié, appelé tri fusion distribué.
Une union de fusion distribuée exécute les étapes suivantes :
Le serveur racine envoie une sous-requête à chaque serveur distant qui héberge une partition des données interrogées. La sous-requête inclut des instructions pour trier les résultats dans un ordre spécifique.
Chaque serveur distant exécute la sous-requête sur sa division, puis renvoie les résultats dans l'ordre demandé.
Le serveur racine fusionne la sous-requête triée pour produire un résultat entièrement trié.
L'union de fusion distribuée est activée par défaut pour Spanner version 3 et ultérieures.
Propriétés et statistiques d'exécution
Une propriété d'un opérateur décrit un trait utilisé lors de l'exécution de l'opérateur. Une statistique d'exécution est une valeur collectée lors de l'exécution d'une requête pour vous aider à évaluer les performances de l'opérateur.
L'opérateur Distributed apply dispose de statistiques d'exécution distinctes supplémentaires.Propriétés
| Nom | Description |
|---|---|
| Méthode d'exécution | Dans l'exécution de ligne, l'opérateur traite une ligne à la fois. Dans l'exécution par lot, l'opérateur traite un lot de lignes à la fois. |
Statistiques d'exécution
| Nom | Description |
|---|---|
| Exécutions parallèles locales | Nombre de sous-requêtes exécutées en parallèle. |
| Appels distants | Nombre de sous-requêtes distantes exécutées. |
| Nombre de lots | Un lot est une collection dynamique de lignes traitées en même temps. Indique le nombre de lots qu'une application croisée distribuée a envoyés de l'entrée au côté Map. |
| Latence | Temps écoulé pour toutes les exécutions effectuées dans l'opérateur. |
| Latence cumulée | Temps total de l'opérateur actuel et de ses descendants. |
| Temps CPU | Somme du temps CPU consacré à l'exécution de l'opérateur. |
| Temps CPU cumulé | Temps CPU total utilisé pour exécuter l'opérateur et ses descendants. |
| Durée d'exécution | Temps total nécessaire pour exécuter la requête et traiter les résultats. |
| Lignes renvoyées | Nombre de lignes générées par cet opérateur |
| Nombre d'exécutions | Nombre de fois où l'opérateur a été exécuté. Certaines exécutions peuvent s'effectuer en parallèle. |
Push broadcast hash join
L'opérateur push broadcast hash join est une mise en œuvre des jointures SQL basée sur la jointure de hachage. L'opérateur de jointure par hachage de diffusion push lit les lignes du côté entrée afin de construire un lot de données. L'opérateur diffuse ce lot à tous les serveurs contenant des données côté carte. Sur les serveurs de destination où le lot de données est reçu, l'opérateur crée une jointure par hachage en utilisant le lot comme données de côté compilation et analyse les données locales en tant que côté vérification de la jointure par hachage.
Push broadcast hash join présente les avantages suivants :
- Si la table de compilation est petite, elle peut être envoyée à toutes les divisions côté mappeur.
- Le tableau latéral de la carte peut être analysé, avec ou sans filtres résiduels. Cela se produit lorsque les clés de jointure ne sont pas identiques aux clés primaires de la table de mappage.
L'optimiseur ne sélectionne pas automatiquement l'opérateur push broadcast hash join. Pour utiliser cet opérateur, définissez la méthode de jointure sur PUSH_BROADCAST_HASH_JOIN dans l'optimisation de requête, comme indiqué dans l'exemple suivant :
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=push_broadcast_hash_join} songs AS s
ON a.singerid = s.singerid
AND a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
| Nothing To Do With Me | Not About The Guitar |
+-----------------------+--------------------------*/
Le plan d'exécution se présente comme suit :
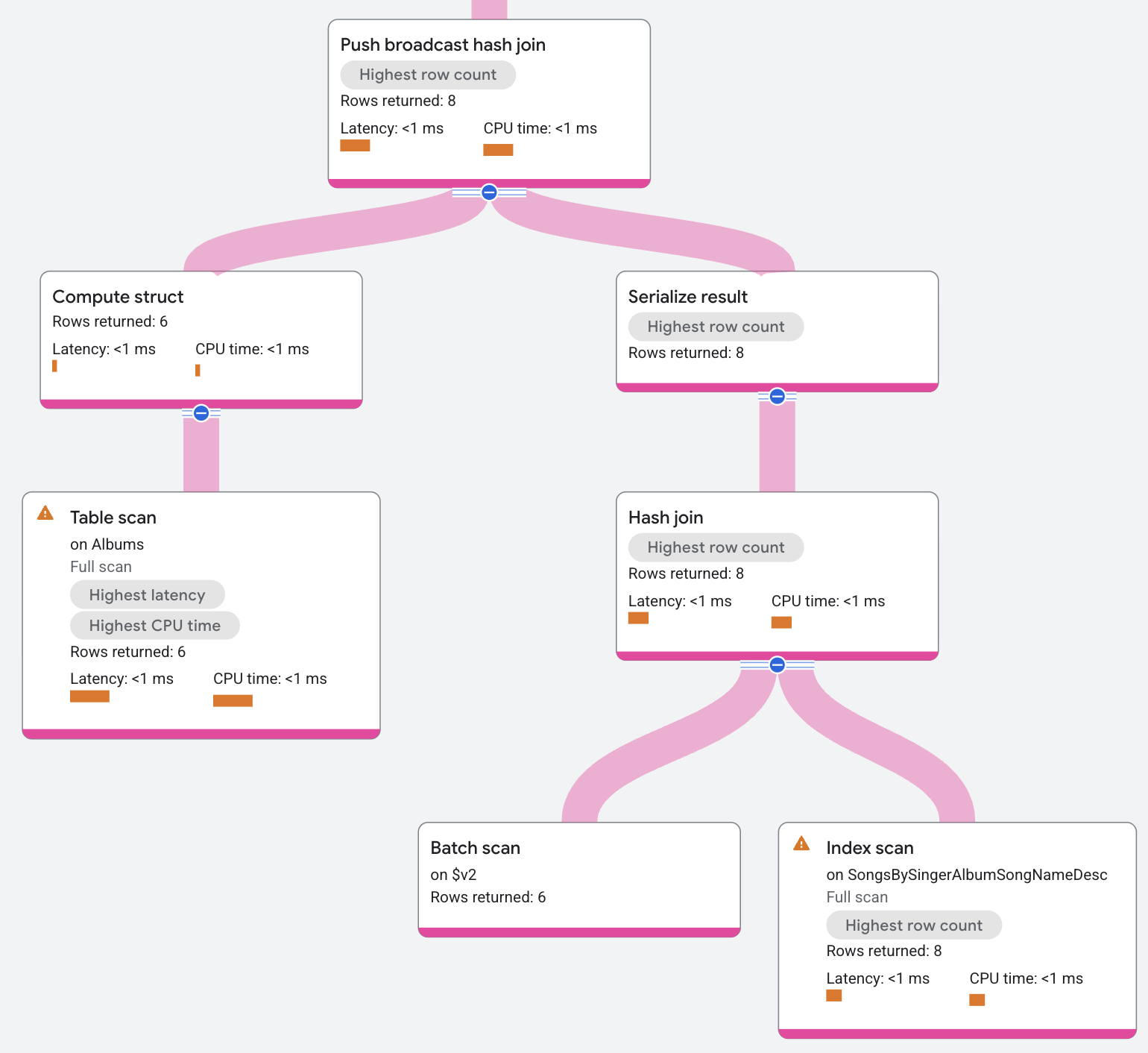
L'entrée de la jointure de hachage de diffusion push est l'index AlbumsByAlbumTitle.
L'opérateur sérialise cette entrée en un lot de données. L'opérateur envoie ce lot à toutes les divisions locales de l'index SongsBySingerAlbumSongNameDesc, où il le désérialise et l'intègre à une table de hachage. La table de hachage utilise ensuite les données d'index local en tant que vérification renvoyant les correspondances obtenues.
Les correspondances de résultats peuvent également être filtrées sur la base d'une condition résiduelle avant d'être renvoyées. (Les conditions résiduelles apparaissent par exemple dans les jointures sans égalité)
Propriétés et statistiques d'exécution
Une propriété d'un opérateur décrit un trait utilisé lors de l'exécution de l'opérateur. Une statistique d'exécution est une valeur collectée lors de l'exécution d'une requête pour vous aider à évaluer les performances de l'opérateur.
L'opérateur Distributed apply dispose de statistiques d'exécution distinctes supplémentaires.Propriétés
| Nom | Description |
|---|---|
| Méthode d'exécution | Dans l'exécution de ligne, l'opérateur traite une ligne à la fois. Dans l'exécution par lot, l'opérateur traite un lot de lignes à la fois. |
Statistiques d'exécution
| Nom | Description |
|---|---|
| Exécutions parallèles locales | Nombre de sous-requêtes exécutées en parallèle. |
| Appels distants | Nombre de sous-requêtes distantes exécutées. |
| Nombre de lots | Un lot est une collection dynamique de lignes traitées en même temps. Indique le nombre de lots qu'une application croisée distribuée a envoyés de l'entrée au côté Map. |
| Latence | Temps écoulé pour toutes les exécutions effectuées dans l'opérateur. |
| Latence cumulée | Temps total de l'opérateur actuel et de ses descendants. |
| Temps CPU | Somme du temps CPU consacré à l'exécution de l'opérateur. |
| Temps CPU cumulé | Temps CPU total utilisé pour exécuter l'opérateur et ses descendants. |
| Durée d'exécution | Temps total nécessaire pour exécuter la requête et traiter les résultats. |
| Lignes renvoyées | Nombre de lignes générées par cet opérateur |
| Nombre d'exécutions | Nombre de fois où l'opérateur a été exécuté. Certaines exécutions peuvent s'effectuer en parallèle. |