
Un opérateur binaire a deux enfants relationnels. Les opérateurs suivants sont des opérateurs binaires :
Schéma de base de données
Les requêtes et les plans d'exécution de cette page sont basés sur le schéma de base de données suivant :
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
Vous pouvez utiliser les instructions LMD (langage de manipulation de données) suivantes pour ajouter des données à ces tables :
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
Appliquer une jointure
Une jointure par application est le principal opérateur de jointure utilisé par Spanner. Les opérateurs apply join exécutent un traitement basé sur les lignes, contrairement aux opérateurs exécutant un traitement basé sur des ensembles, tel que hash join. L'opérateur apply possède deux entrées : input (enfant de gauche) et map (enfant de droite). L'opérateur apply applique chaque ligne du côté entrée au côté carte à l'aide d'une méthode apply : cross, outer, semi ou anti-semi. De plus, une variante d'une jointure "apply" apparaît également du côté carte d'une jointure "apply" distribuée.
L'opérateur de jointure "Appliquer" est plus efficace lorsque :
- La cardinalité de l'entrée est faible.
- La clé de jointure est un préfixe de la clé primaire côté mappage.
- La requête joint deux tables entrelacées.
Propriétés et statistiques d'exécution
Une propriété d'un opérateur décrit un trait utilisé lors de l'exécution de l'opérateur. Une statistique d'exécution est une valeur collectée lors de l'exécution d'une requête pour vous aider à évaluer les performances de l'opérateur.
Propriétés
| Nom | Description |
|---|---|
| Méthode d'exécution | Dans l'exécution de ligne, l'opérateur traite une ligne à la fois. Dans l'exécution par lot, l'opérateur traite un lot de lignes à la fois. |
Statistiques d'exécution
| Nom | Description |
|---|---|
| Latence | Temps écoulé pour toutes les exécutions effectuées dans l'opérateur. |
| Latence cumulée | Temps total de l'opérateur actuel et de ses descendants. |
| Temps CPU | Somme du temps CPU consacré à l'exécution de l'opérateur. |
| Temps CPU cumulé | Temps CPU total utilisé pour exécuter l'opérateur et ses descendants. |
| Durée d'exécution | Temps total nécessaire pour exécuter la requête et traiter les résultats. |
| Lignes renvoyées | Nombre de lignes générées par cet opérateur |
| Nombre d'exécutions | Nombre de fois où l'opérateur a été exécuté. Certaines exécutions peuvent s'effectuer en parallèle. |
Cross apply
Une application croisée effectue une jointure interne où seules les lignes correspondantes sont renvoyées.
La requête suivante illustre cet opérateur :
La requête demande le prénom de chaque chanteur, ainsi que le titre d'un seul de leurs titres.
SELECT si.firstname,
(SELECT so.songname
FROM songs AS so
WHERE so.singerid = si.singerid
LIMIT 1)
FROM singers AS si;
/*-----------+--------------------------+
| FirstName | Unspecified |
+-----------+--------------------------+
| Alice | Not About The Guitar |
| Catalina | Let's Get Back Together |
| David | NULL |
| Lea | NULL |
| Marc | NULL |
+-----------+--------------------------*/
La requête remplit la première colonne à partir de la table Singers et la deuxième colonne à partir de la table Songs. Si un ID de chanteur (SingerId) existe dans la table Singers, mais qu'il n'y a pas de SingerId correspondant dans la table Songs, la deuxième colonne contient la valeur NULL.
Le plan d'exécution commence comme suit :
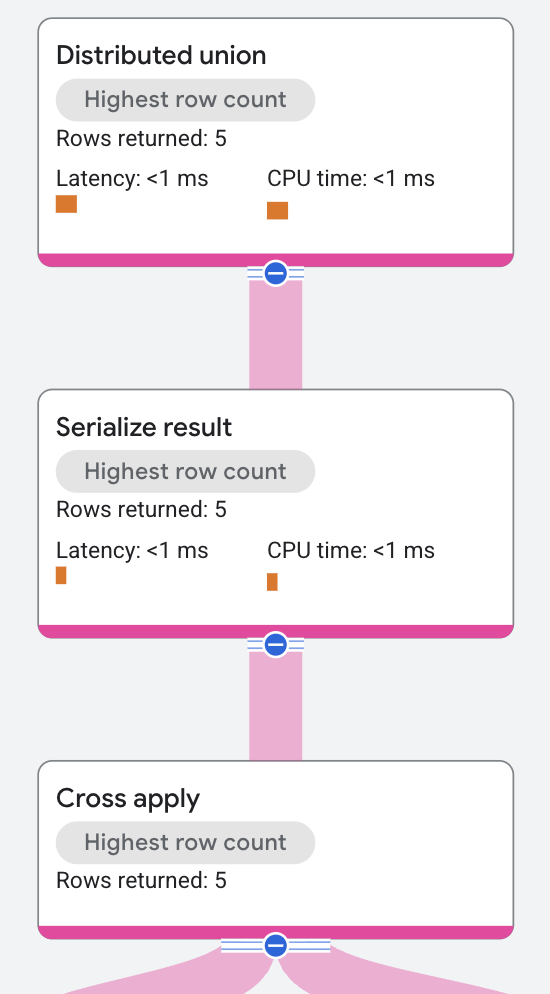
Le nœud de premier niveau est un opérateur distributed union. L'opérateur distributed union distribue des sous-plans aux serveurs distants. Le sous-plan contient un opérateur serialize result qui calcule le prénom du chanteur et l'un de ses titres, puis sérialise chaque ligne du résultat.
L'opérateur serialize result reçoit ses entrées d'un opérateur cross apply.
Le côté entrée de l'opérateur cross apply est une analyse de table sur la table Singers.
Le plan d'exécution se poursuit comme suit :
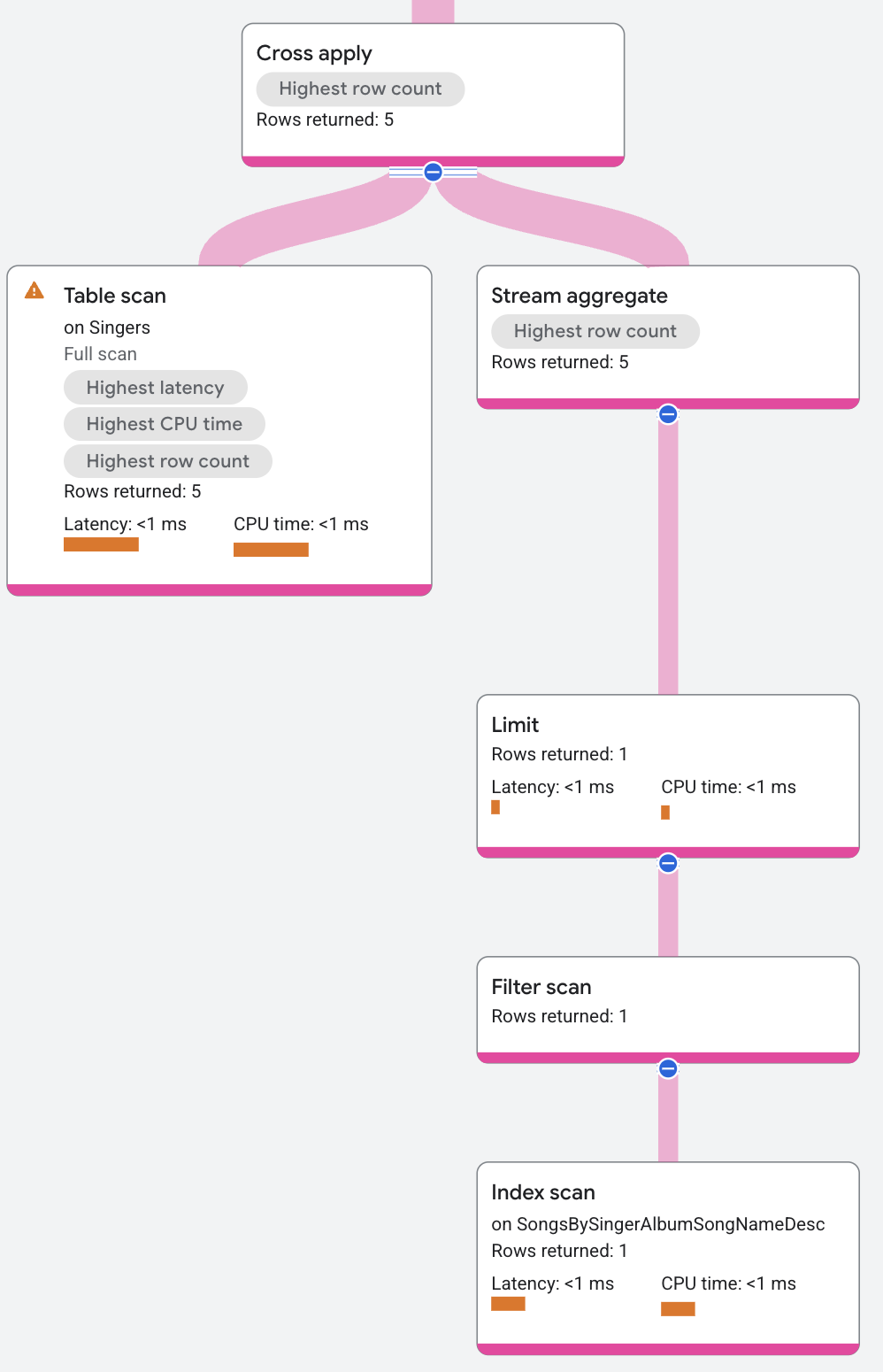
Le côté carte de l'opération d'application croisée contient les éléments suivants (de haut en bas) :
- Un opérateur aggregate qui renvoie
Songs.SongName. - Un opérateur limit qui limite le nombre de titres renvoyés à un par artiste.
- Une analyse d'index sur l'index
SongsBySingerAlbumSongNameDesc.
L'opérateur cross apply mappe chaque ligne du côté entrée à une ligne du côté carte ayant le même ID de chanteur (SingerId). La sortie de l'opérateur cross apply correspond à la valeur FirstName de la ligne d'entrée et à la valeur SongName de la ligne de carte.
(La valeur SongName est NULL si aucune ligne de mappage ne correspond à SingerId.) L'opérateur distributed union en haut du plan d'exécution combine ensuite toutes les lignes de sortie des serveurs distants et les renvoie en tant que résultats de la requête.
Outer apply
Un outer apply fournit une sémantique de jointure externe gauche. Il vérifie que chaque exécution côté mappage renvoie au moins une ligne en ajoutant un remplissage NULL si nécessaire.
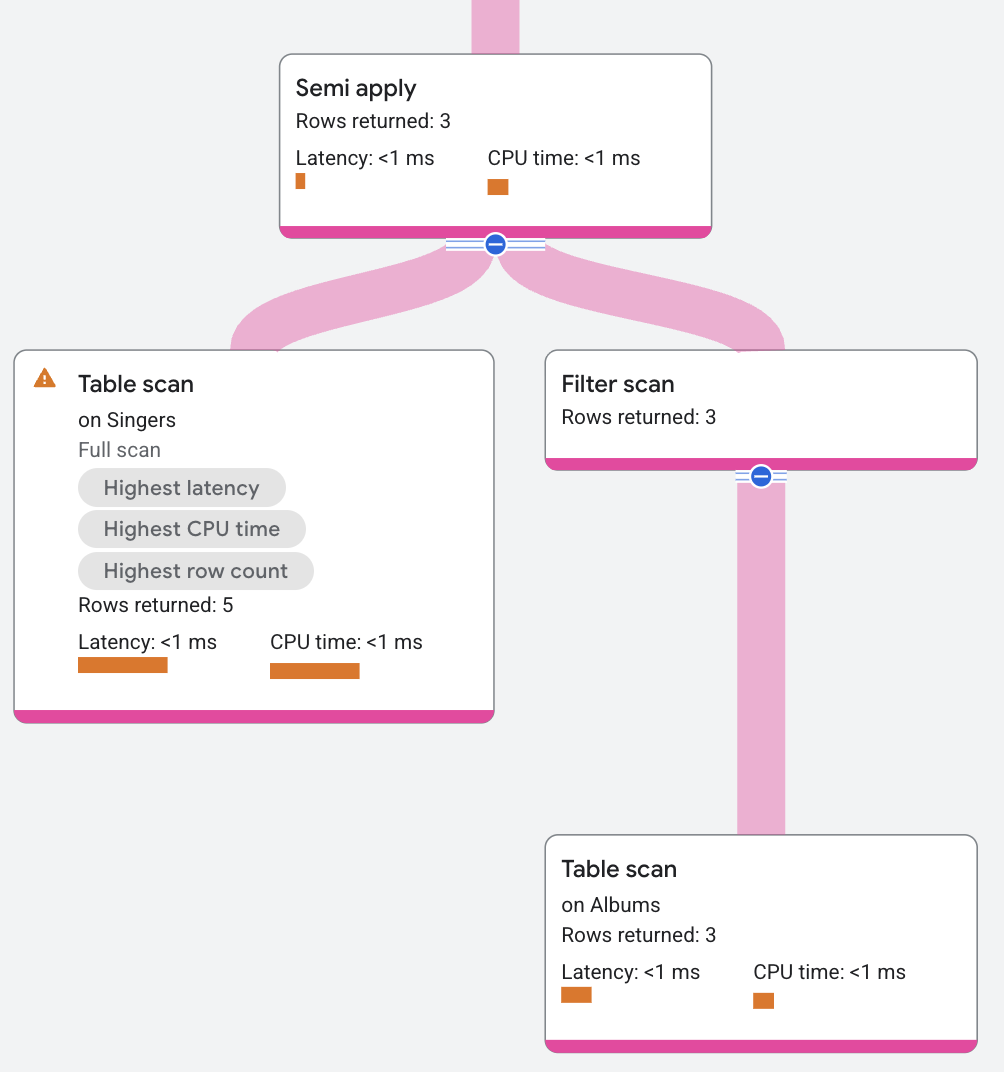
Semi-appliquer
L'opérateur semi-apply renvoie les colonnes d'entrée uniquement lorsqu'une correspondance est trouvée du côté de la carte.
La requête suivante utilise une semi-jointure pour identifier les chanteurs qui ont un album :
SELECT
FirstName,
LastName
FROM
Singers
WHERE
SingerId IN (
SELECT
SingerId
FROM
Albums);
/*-----------+----------+
| FirstName | LastName |
+-----------+----------+
| Marc | Richards |
| Catalina | Smith |
| Alice | Trentor |
| Lea | Martin |
+-----------+----------*/
Le segment de forfait se présente comme suit :
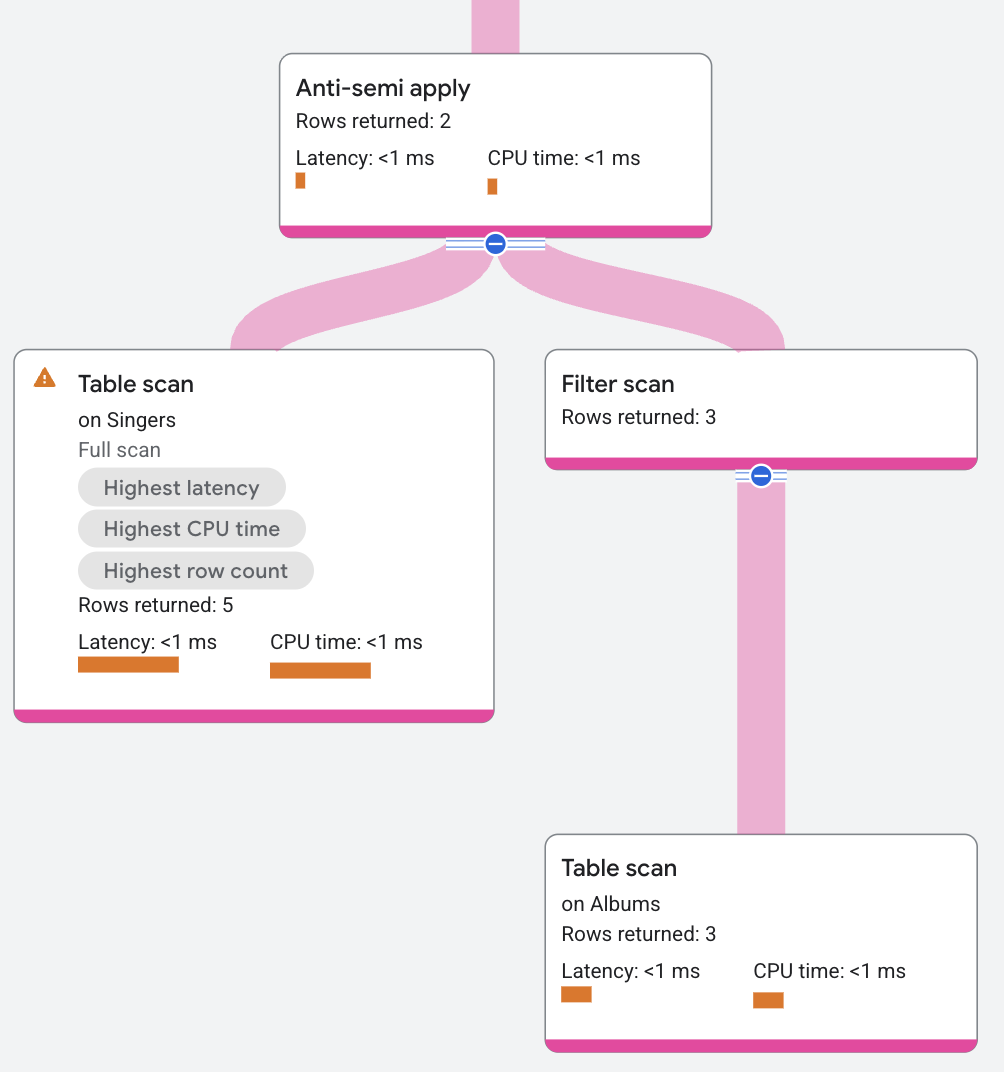
Anti-semi-apply
Un opérateur anti-semi apply est semblable à un opérateur semi apply, à la différence qu'il ne renvoie les colonnes de la table d'entrée que lorsqu'aucune correspondance n'est trouvée du côté carte.
La requête suivante utilise une semi-jointure négative pour identifier les chanteurs qui n'ont pas d'album :
SELECT
FirstName,
LastName
FROM
Singers
WHERE
SingerId NOT IN (
SELECT
SingerId
FROM
Albums);
/*-----------+----------+
| FirstName | LastName |
+-----------+----------+
| David | Lomond |
+-----------+----------*/
Le segment de forfait se présente comme suit :
Hash join
L'opérateur hash join est une implémentation de jointures SQL basée sur le hachage. Les jointures de hachage exécutent un traitement basé sur des ensembles. L'opérateur hash join lit les lignes de l'entrée signalée comme build (enfant de gauche) et les insère dans une table de hachage en fonction d'une condition de jointure. Il lit ensuite les lignes de l'entrée signalée comme probe (enfant de droite). Pour chaque ligne lue à partir de l'entrée de vérification (probe), l'opérateur hash join recherche les lignes correspondantes dans la table de hachage. L'opérateur hash join renvoie les lignes correspondantes en tant que résultat.
L'opération de jointure par hachage présente les avantages suivants :
- Il n'est pas nécessaire de trier les entrées.
- Il calcule un filtre Bloom lors de la création de la table de hachage. L'opérateur utilise le filtre pour exclure les lignes du côté de la requête qui ne correspondent à aucune ligne. Notez qu'il s'agit d'un filtre résiduel, et non d'un filtre de recherche.
La requête suivante illustre cet opérateur :
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=hash_join} songs AS s
ON a.singerid = s.singerid
AND a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Nothing To Do With Me | Not About The Guitar |
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
+-----------------------+--------------------------*/
Le segment du plan d'exécution se présente comme suit :
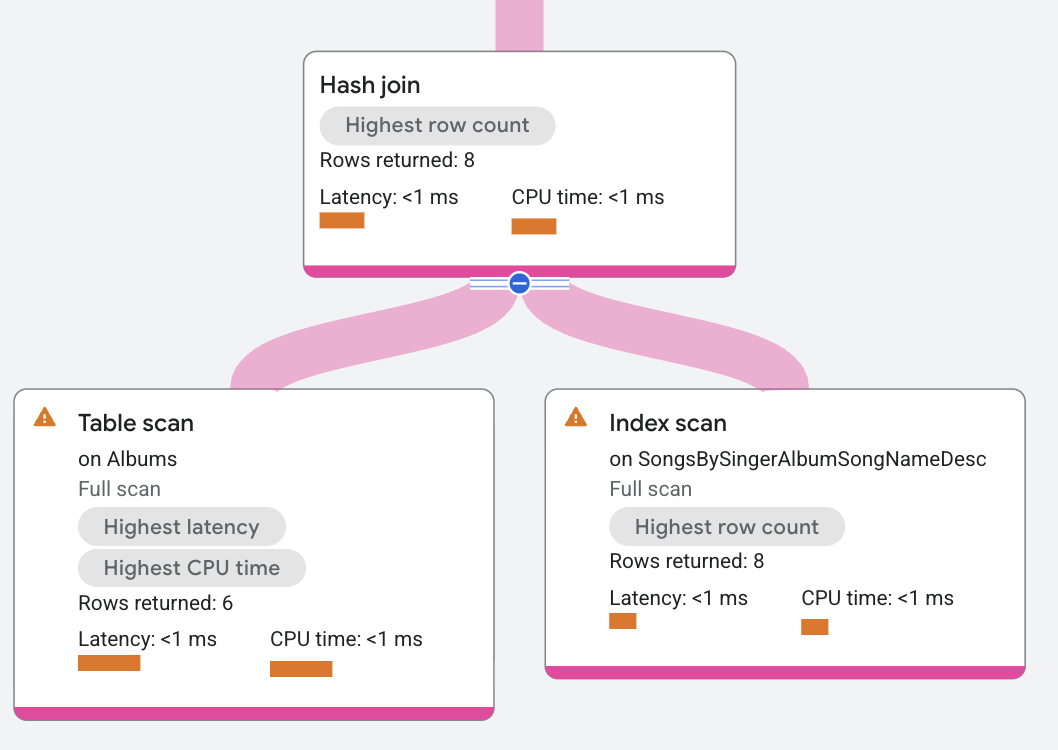
Dans le plan d'exécution, build est une union distribuée qui envoie des analyses sur la table Albums. Probe est un opérateur distributed union qui envoie des analyses sur l'index SongsBySingerAlbumSongNameDesc.
L'opérateur hash join lit toutes les lignes du côté build. Chaque ligne de build est placée dans une table de hachage en fonction des colonnes de la condition a.SingerId =
s.SingerId AND a.AlbumId = s.AlbumId. L'opérateur hash join lit ensuite toutes les lignes du côté vérification. Pour chaque ligne de vérification, l'opérateur hash join recherche des correspondances dans la table de hachage. Les correspondances en résultant sont renvoyées par l'opérateur hash join.
Les correspondances de la table de hachage peuvent également être filtrées par une condition résiduelle avant d'être renvoyées. (Les conditions résiduelles apparaissent par exemple dans les jointures sans égalité.) Les plans d'exécution de jointure de hachage peuvent s'avérer complexes de par la gestion de la mémoire et les variantes de jointure. L'algorithme principal de jointure de hachage est adapté à la gestion des variantes de jointure, à savoir inner, semi, anti et outer.
Propriétés et statistiques d'exécution
Une propriété d'un opérateur décrit un trait utilisé lors de l'exécution de l'opérateur. Une statistique d'exécution est une valeur collectée lors de l'exécution d'une requête pour vous aider à évaluer les performances de l'opérateur.
Propriétés
| Nom | Description |
|---|---|
| Méthode d'exécution | Dans l'exécution de ligne, l'opérateur traite une ligne à la fois. Dans l'exécution par lot, l'opérateur traite un lot de lignes à la fois. |
Statistiques d'exécution
| Nom | Description |
|---|---|
| Latence | Temps écoulé pour toutes les exécutions effectuées dans l'opérateur. |
| Latence cumulée | Temps total de l'opérateur actuel et de ses descendants. |
| Temps CPU | Somme du temps CPU consacré à l'exécution de l'opérateur. |
| Temps CPU cumulé | Temps CPU total utilisé pour exécuter l'opérateur et ses descendants. |
| Durée d'exécution | Temps total nécessaire pour exécuter la requête et traiter les résultats. |
| Lignes renvoyées | Nombre de lignes générées par cet opérateur |
| Nombre d'exécutions | Nombre de fois où l'opérateur a été exécuté. Certaines exécutions peuvent s'effectuer en parallèle. |
Merge join
L'opérateur merge join (jointure par fusion) est une implémentation de jointure SQL basée sur la fusion. Les deux côtés de la jointure produisent des lignes triées en fonction des colonnes utilisées dans la condition de jointure. La jointure par fusion consomme simultanément les flux d'entrée et génère des lignes lorsque la condition de jointure est remplie. Si les entrées ne sont pas triées, l'optimiseur ajoute des opérateurs Sort explicites au plan.
L'opération de jointure par fusion présente les avantages suivants :
- Si les données sont déjà triées, aucune mémoire n'est nécessaire.
- Même si les données ne sont pas triées, pour une jointure distribuée, le tri peut être effectué sur chaque fraction individuelle, plutôt que de créer une grande table de hachage sur la racine.
L'optimiseur ne sélectionne pas automatiquement l'opérateur Merge join. Pour utiliser cet opérateur, définissez la méthode de jointure sur MERGE_JOIN dans l'optimisation de requête, comme indiqué dans l'exemple suivant :
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=merge_join} songs AS s
ON a.singerid = s.singerid
AND a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
| Nothing To Do With Me | Not About The Guitar |
+-----------------------+--------------------------*/
Le plan d'exécution se présente comme suit :
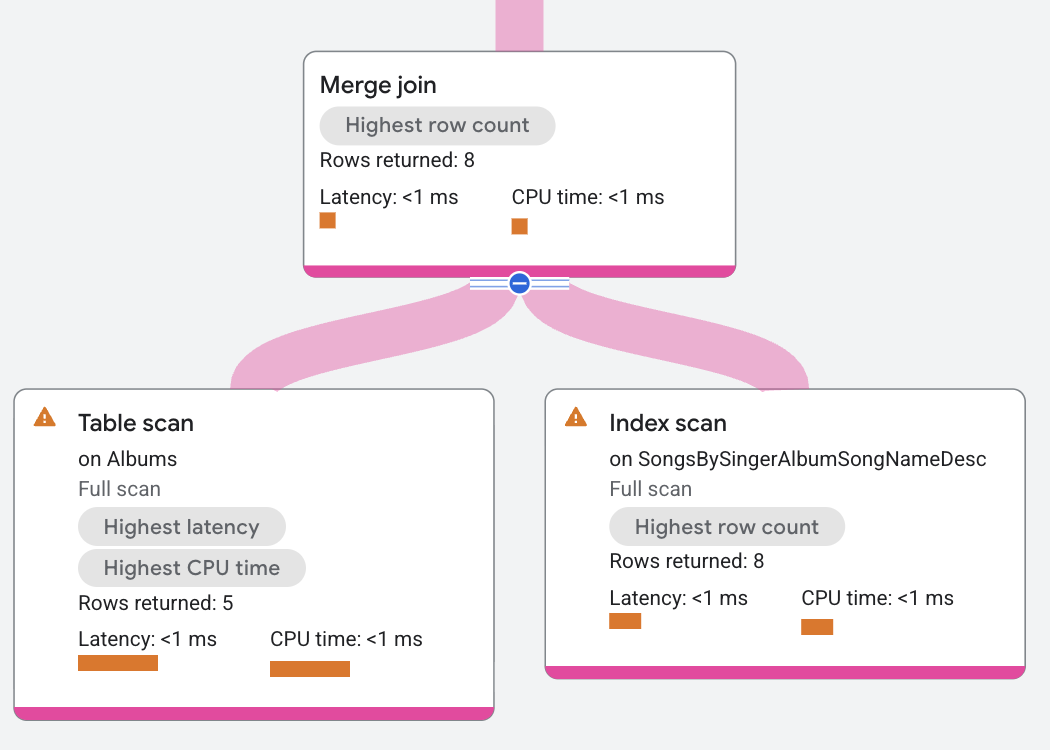
Dans ce plan d'exécution, la jointure par fusion est distribuée afin de s'exécuter à l'emplacement des données. Cela permet également de procéder à la jointure par fusion sans ajouter d'opérateurs de tri supplémentaires, car les deux analyses de table sont déjà triées par SingerId et AlbumId, ce qui correspond à la condition de jointure. Dans ce plan, l'analyse de gauche de la table Albums avance lorsque son SingerId, AlbumId est inférieur aux valeurs SingerId_1, AlbumId_1 de l'analyse de droite. De même, le scan de droite avance chaque fois que ses valeurs sont inférieures à celles du scan de gauche. Cette avancée par fusion continue de rechercher des équivalences pour renvoyer les lignes correspondantes.
Prenons un autre exemple de merge join à l'aide de la requête suivante :
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=merge_join} songs AS s
ON a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Total Junk | The Second Time |
| Total Junk | Starting Again |
| Total Junk | Nothing Is The Same |
| Total Junk | Let's Get Back Together |
| Total Junk | I Knew You Were Magic |
| Total Junk | Blue |
| Total Junk | 42 |
| Total Junk | Not About The Guitar |
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Green | Not About The Guitar |
| Nothing To Do With Me | The Second Time |
| Nothing To Do With Me | Starting Again |
| Nothing To Do With Me | Nothing Is The Same |
| Nothing To Do With Me | Let's Get Back Together |
| Nothing To Do With Me | I Knew You Were Magic |
| Nothing To Do With Me | Blue |
| Nothing To Do With Me | 42 |
| Nothing To Do With Me | Not About The Guitar |
| Play | The Second Time |
| Play | Starting Again |
| Play | Nothing Is The Same |
| Play | Let's Get Back Together |
| Play | I Knew You Were Magic |
| Play | Blue |
| Play | 42 |
| Play | Not About The Guitar |
| Terrified | Fight Story |
+-----------------------+--------------------------*/
Le plan d'exécution se présente comme suit :
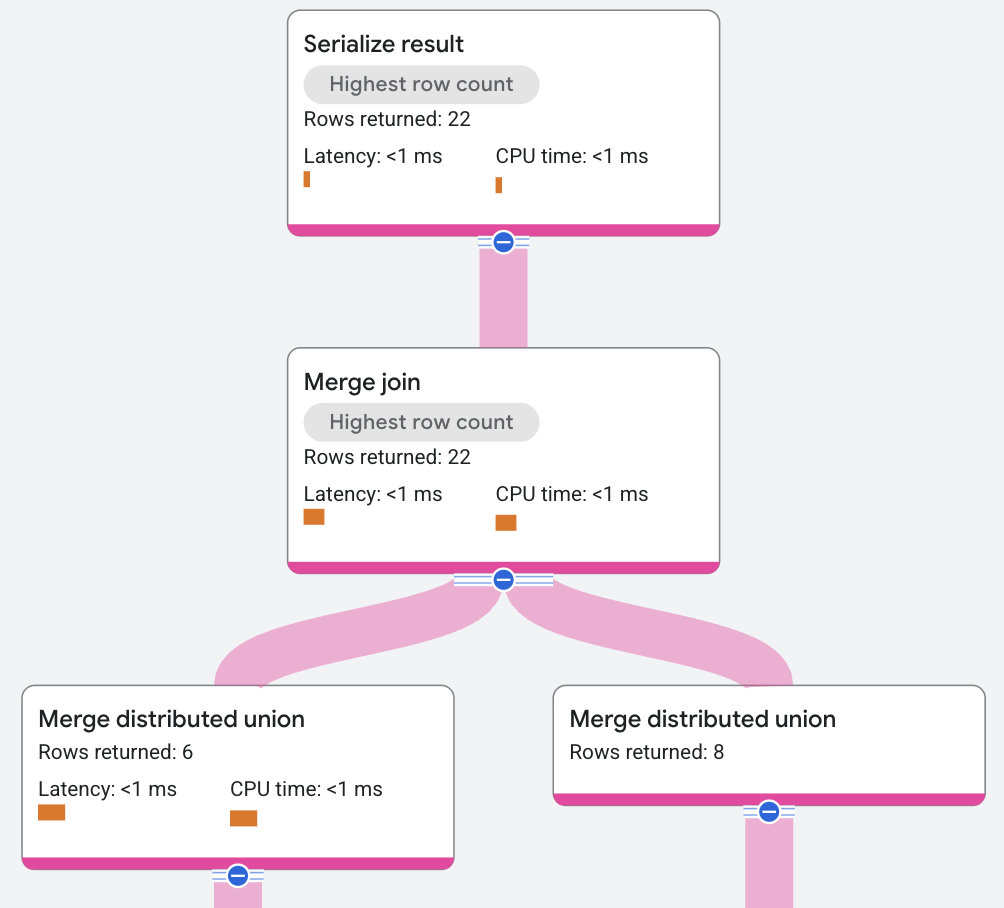
Dans le plan d'exécution précédent, l'optimiseur de requêtes a introduit d'autres opérateurs de tri pour exécuter la jointure par fusion. La condition JOIN dans cet exemple de requête n'est appliquée qu'à AlbumId, qui n'est pas le mode de stockage des données. Par conséquent, un tri doit être ajouté. Le moteur de requête est compatible avec un algorithme de fusion distribuée, ce qui permet d'effectuer un tri local plutôt que global afin de distribuer et paralléliser les coûts de processeur.
Les correspondances obtenues peuvent également être filtrées sur la base d'une condition résiduelle. Par exemple, les conditions résiduelles apparaissent dans les jointures sans égalité. Les plans d'exécution de jointure par fusion peuvent être complexes en raison d'exigences de tri supplémentaires. L'algorithme principal de jointure par fusion gère les variantes de jointure, à savoir inner, semi, anti et outer.
Propriétés et statistiques d'exécution
Une propriété d'un opérateur décrit un trait utilisé lors de l'exécution de l'opérateur. Une statistique d'exécution est une valeur collectée lors de l'exécution d'une requête pour vous aider à évaluer les performances de l'opérateur.
Propriétés
| Nom | Description |
|---|---|
| Méthode d'exécution | Dans l'exécution de ligne, l'opérateur traite une ligne à la fois. Dans l'exécution par lot, l'opérateur traite un lot de lignes à la fois. |
Statistiques d'exécution
| Nom | Description |
|---|---|
| Latence | Temps écoulé pour toutes les exécutions effectuées dans l'opérateur. |
| Latence cumulée | Temps total de l'opérateur actuel et de ses descendants. |
| Temps CPU | Somme du temps CPU consacré à l'exécution de l'opérateur. |
| Temps CPU cumulé | Temps CPU total utilisé pour exécuter l'opérateur et ses descendants. |
| Durée d'exécution | Temps total nécessaire pour exécuter la requête et traiter les résultats. |
| Lignes renvoyées | Nombre de lignes générées par cet opérateur |
| Nombre d'exécutions | Nombre de fois où l'opérateur a été exécuté. Certaines exécutions peuvent s'effectuer en parallèle. |
Union récursive
Un opérateur recursive union effectue une union de deux entrées, l'une représentant un cas base et l'autre un cas recursive. Il est utilisé dans les requêtes graphiques avec des traversées de chemin quantifiées. L'entrée de base est traitée en premier et une seule fois. L'entrée récursive est traitée jusqu'à ce que la récursivité se termine. La récursivité se termine lorsque la limite supérieure, si elle est spécifiée, est atteinte ou lorsque la récursivité ne produit aucun nouveau résultat. Dans l'exemple suivant, la table Collaborations est ajoutée au schéma et un graphique de propriétés appelé MusicGraph est créé.
CREATE TABLE Collaborations (
SingerId INT64 NOT NULL,
FeaturingSingerId INT64 NOT NULL,
AlbumTitle STRING(MAX) NOT NULL,
) PRIMARY KEY(SingerId, FeaturingSingerId, AlbumTitle);
CREATE OR REPLACE PROPERTY GRAPH MusicGraph
NODE TABLES(
Singers
KEY(SingerId)
LABEL Singers PROPERTIES(
BirthDate,
FirstName,
LastName,
SingerId,
SingerInfo)
)
EDGE TABLES(
Collaborations AS CollabWith
KEY(SingerId, FeaturingSingerId, AlbumTitle)
SOURCE KEY(SingerId) REFERENCES Singers(SingerId)
DESTINATION KEY(FeaturingSingerId) REFERENCES Singers(SingerId)
LABEL CollabWith PROPERTIES(
AlbumTitle,
FeaturingSingerId,
SingerId),
);
La requête de graphique suivante permet de trouver les chanteurs qui ont collaboré avec un chanteur donné ou avec ses collaborateurs.
GRAPH MusicGraph
MATCH (singer:Singers {singerId:42})-[c:CollabWith]->{1,2}(featured:Singers)
RETURN singer.SingerId AS singer, featured.SingerId AS featured
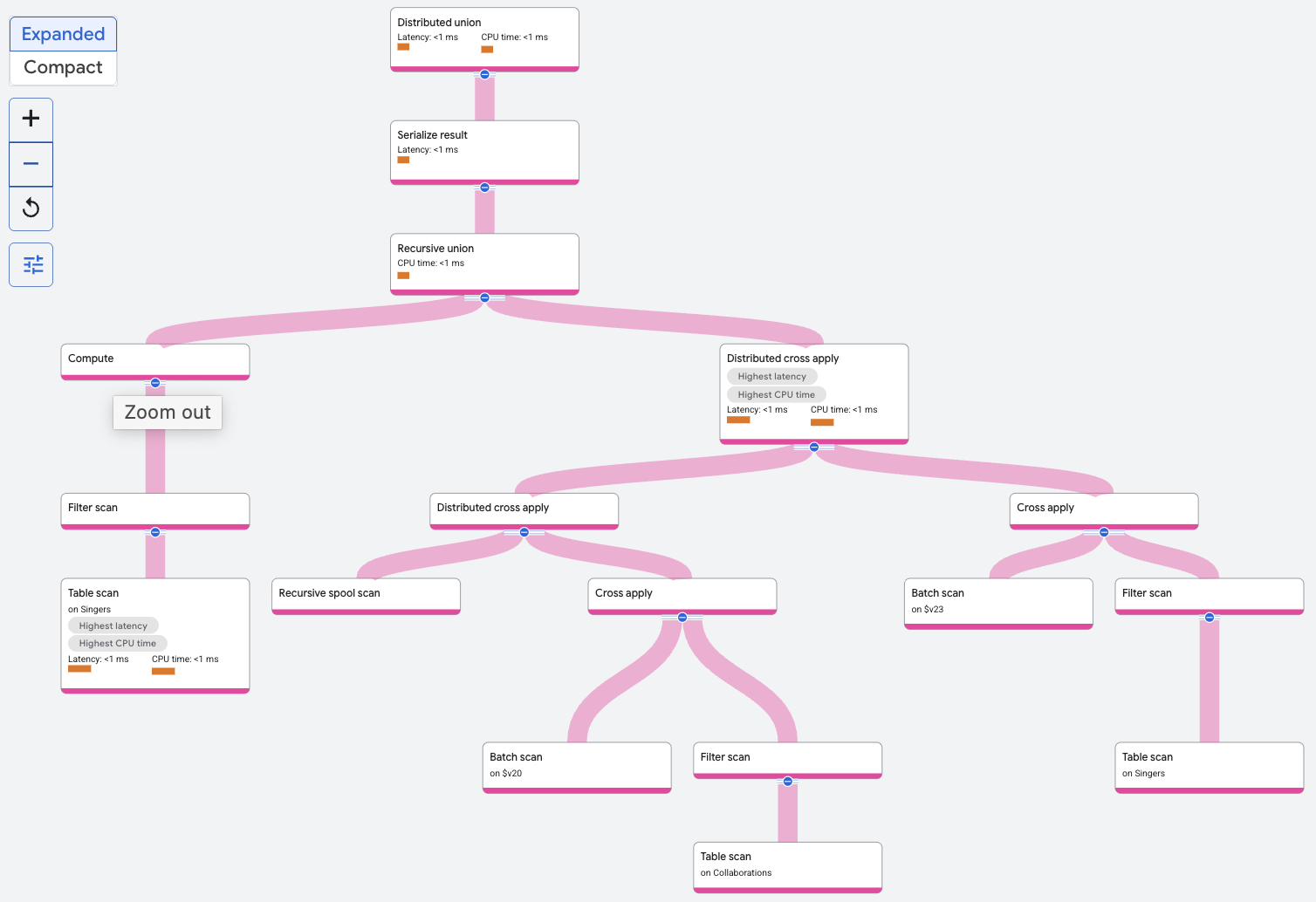
L'opérateur recursive union filtre la table Singers pour trouver le chanteur avec le SingerId donné. Il s'agit de l'entrée de base de l'union récursive. L'entrée récursive de l'union récursive comprend un distributed cross apply ou un autre opérateur de jointure pour les autres requêtes qui joint la table Collaborations de manière répétée aux résultats de l'itération précédente de la jointure. Les lignes de l'entrée de base constituent la première itération.
À chaque itération, le résultat est stocké par l'analyse récursive du spouleur. Les lignes de l'analyse de spool récursive sont jointes à la table Collaborations sur spoolscan.featuredSingerId = Collaborations.SingerId. La récursivité se termine lorsque deux itérations sont terminées, car il s'agit de la limite supérieure spécifiée dans la requête.
Propriétés et statistiques d'exécution
Une propriété d'un opérateur décrit un trait utilisé lors de l'exécution de l'opérateur. Une statistique d'exécution est une valeur collectée lors de l'exécution d'une requête pour vous aider à évaluer les performances de l'opérateur.
Propriétés
| Nom | Description |
|---|---|
| Méthode d'exécution | Dans l'exécution de ligne, l'opérateur traite une ligne à la fois. Dans l'exécution par lot, l'opérateur traite un lot de lignes à la fois. |
Statistiques d'exécution
| Nom | Description |
|---|---|
| Latence | Temps écoulé pour toutes les exécutions effectuées dans l'opérateur. |
| Latence cumulée | Temps total de l'opérateur actuel et de ses descendants. |
| Temps CPU | Somme du temps CPU consacré à l'exécution de l'opérateur. |
| Temps CPU cumulé | Temps CPU total utilisé pour exécuter l'opérateur et ses descendants. |
| Durée d'exécution | Temps total nécessaire pour exécuter la requête et traiter les résultats. |
| Lignes renvoyées | Nombre de lignes générées par cet opérateur |
| Nombre d'exécutions | Nombre de fois où l'opérateur a été exécuté. Certaines exécutions peuvent s'effectuer en parallèle. |