
בדף הזה מוסבר איך להעביר מסד נתונים של PostgreSQL בקוד פתוח ל-Spanner.
ההעברה כוללת את המשימות הבאות:
- מיפוי סכימת PostgreSQL לסכימת Spanner.
- יצירת מכונה, מסד נתונים וסכימה ב-Spanner.
- שינוי מבנה האפליקציה כדי שתפעל עם מסד הנתונים של Spanner.
- העברת הנתונים.
- אימות המערכת החדשה והעברתה לסטטוס של סביבת ייצור.
במאמר הזה יש גם כמה דוגמאות לסכימות שמשתמשות בטבלאות ממסד הנתונים של MusicBrainz ב-PostgreSQL.
מיפוי של סכימת PostgreSQL ל-Spanner
השלב הראשון בהעברת מסד נתונים מ-PostgreSQL ל-Spanner הוא לקבוע אילו שינויים בסכימה צריך לבצע. משתמשים ב-pg_dump כדי ליצור הצהרות של שפת הגדרת נתונים (DDL) שמגדירות את האובייקטים במסד הנתונים של PostgreSQL, ואז משנים את ההצהרות כמו שמתואר בקטעים הבאים. אחרי שמעדכנים את הצהרות ה-DDL, משתמשים בהן כדי ליצור את מסד הנתונים במופע Spanner.
סוגי הנתונים
בטבלה הבאה מתואר המיפוי של סוגי נתונים ב-PostgreSQL לסוגי נתונים ב-Spanner. מעדכנים את סוגי הנתונים בהצהרות DDL מסוגי נתונים של PostgreSQL לסוגי נתונים של Spanner.
| PostgreSQL | Spanner |
|---|---|
Bigint
|
INT64 |
Bigserial
|
INT64 |
bit [ (n) ] |
ARRAY<BOOL> |
bit varying [ (n) ]
|
ARRAY<BOOL> |
Boolean
|
BOOL |
box |
ARRAY<FLOAT64> |
bytea |
BYTES |
character [ (n) ]
|
STRING |
character varying [ (n) ]
|
STRING |
cidr |
STRING, באמצעות סימון CIDR רגיל. |
circle |
ARRAY<FLOAT64> |
date |
DATE |
double precision
|
FLOAT64 |
inet |
STRING |
Integer
|
INT64 |
interval[ fields ] [ (p) ] |
INT64 אם הערך מאוחסן באלפיות שנייה, או STRING אם הערך מאוחסן בפורמט של מרווח זמן שמוגדר על ידי האפליקציה. |
json |
STRING |
jsonb |
JSON |
line |
ARRAY<FLOAT64> |
lseg |
ARRAY<FLOAT64> |
macaddr |
STRING, באמצעות סימון כתובת MAC סטנדרטי. |
money |
INT64 או STRING למספרים עם דיוק שרירותי. |
numeric [ (p, s) ]
|
ב-PostgreSQL, סוגי הנתונים NUMERIC ו-DECIMAL תומכים ב-217 ספרות של דיוק וב-214-1 של קנה מידה, כפי שמוגדר בהצהרת העמודה.סוג הנתונים NUMERIC ב-Spanner תומך ב-38 ספרות של דיוק ו-9 ספרות אחרי הנקודה העשרונית של קנה מידה.אם אתם צריכים דיוק גבוה יותר, כדאי לעיין במאמר אחסון נתונים מספריים עם דיוק שרירותי כדי לקבל מידע על מנגנונים חלופיים. |
path |
ARRAY<FLOAT64> |
pg_lsn |
סוג הנתונים הזה ספציפי ל-PostgreSQL, ולכן אין לו מקבילה ב-Spanner. |
point |
ARRAY<FLOAT64> |
polygon |
ARRAY<FLOAT64> |
Real
|
FLOAT64 |
Smallint
|
INT64 |
Smallserial
|
INT64 |
Serial
|
INT64 |
text |
STRING |
time [ (p) ] [ without time zone ] |
STRING, באמצעות סימון HH:MM:SS.sss. |
time [ (p) ] with time zone
|
STRING, באמצעות סימון HH:MM:SS.sss+ZZZZ. לחלופין, אפשר לפצל את זה לשתי עמודות, אחת מהסוג TIMESTAMP ועוד אחת שמכילה את אזור הזמן. |
timestamp [ (p) ] [ without time zone ] |
אין מקבילה. אתם יכולים לשמור את הקובץ כ-STRING או כ-TIMESTAMP לפי שיקול דעתכם. |
timestamp [ (p) ] with time zone
|
TIMESTAMP |
tsquery |
אין מקבילה. במקום זאת, צריך להגדיר מנגנון אחסון באפליקציה. |
tsvector |
אין מקבילה. במקום זאת, צריך להגדיר מנגנון אחסון באפליקציה. |
txid_snapshot |
אין מקבילה. במקום זאת, צריך להגדיר מנגנון אחסון באפליקציה. |
uuid |
STRING או BYTES |
xml |
STRING |
מקש במקלדת הראשית
בטבלאות במסד הנתונים של Spanner שמוסיפים להן נתונים לעיתים קרובות, מומלץ להימנע משימוש במפתחות ראשיים שעולים או יורדים באופן מונוטוני, כי הגישה הזו גורמת לנקודות חמות במהלך פעולות כתיבה. במקום זאת, צריך לשנות את ההצהרות של DDL CREATE TABLE כך שישתמשו בשיטות נתמכות של מפתחות ראשיים. אם אתם משתמשים בתכונה של PostgreSQL כמו UUID סוג נתונים או פונקציה, SERIAL סוגי נתונים, IDENTITY עמודה או רצף, אתם יכולים להשתמש באסטרטגיות להעברת מפתחות שנוצרו אוטומטית שאנחנו ממליצים עליהן.
חשוב לזכור: אחרי שמגדירים את המפתח הראשי, אי אפשר להוסיף או להסיר עמודה של מפתח ראשי, או לשנות ערך של מפתח ראשי, בלי למחוק את הטבלה וליצור אותה מחדש. מידע נוסף על הגדרת המפתח הראשי זמין במאמר סכימה ומודל נתונים – מפתחות ראשיים.
במהלך ההעברה, יכול להיות שתצטרכו לשמור על חלק ממפתחות המספרים השלמים הקיימים שגדלים באופן מונוטוני. אם אתם צריכים לשמור מפתחות כאלה בטבלה שמתעדכנת לעיתים קרובות עם הרבה פעולות על המפתחות האלה, אתם יכולים למנוע יצירת נקודות חמות על ידי הוספת מספר פסאודו-אקראי כמחרוזת לפני המפתח הקיים. הטכניקה הזו גורמת ל-Spanner להפיץ מחדש את השורות. מידע נוסף על השימוש בגישה הזו זמין במאמר What DBAs need to know about Spanner, part 1: Keys and indexes.
מפתחות זרים ושלמות רפרנציאלית
מידע נוסף על תמיכה במפתחות זרים ב-Spanner
מדדים
PostgreSQL
b-tree indexes
דומים לsecondary indexes ב-Spanner. במסד נתונים של Spanner, משתמשים באינדקסים משניים כדי ליצור אינדקס לעמודות שמתבצע בהן חיפוש לעיתים קרובות, וכדי להחליף אילוצים של UNIQUE שצוינו בטבלאות. לדוגמה, אם ב-PostgreSQL DDL
מופיעה ההצהרה הבאה:
CREATE TABLE customer (
id CHAR (5) PRIMARY KEY,
first_name VARCHAR (50),
last_name VARCHAR (50),
email VARCHAR (50) UNIQUE
);
ההצהרה הזו תשמש אתכם ב-Spanner DDL:
CREATE TABLE customer (
id STRING(5),
first_name STRING(50),
last_name STRING(50),
email STRING(50)
) PRIMARY KEY (id);
CREATE UNIQUE INDEX customer_emails ON customer(email);
כדי למצוא את האינדקסים של אחת מהטבלאות שלכם ב-PostgreSQL, מריצים את פקודת המטא \di ב-psql.
אחרי שמחליטים אילו אינדקסים צריך, מוסיפים משפטי CREATE INDEX כדי ליצור אותם. פועלים לפי ההנחיות שבקטע יצירת אינדקסים.
מערכת Spanner מטמיעה אינדקסים כטבלאות, ולכן יצירת אינדקס לעמודות עם ערכים שעולים באופן מונוטוני (כמו אלה שמכילות נתוני TIMESTAMP) עלולה לגרום לנקודה חמה.
מידע נוסף על שיטות למניעת נקודות חמות זמין במאמר What DBAs need to know about Spanner, part 1: Keys and indexes.
בדיקת המגבלות
מידע נוסף על תמיכה במגבלות של CHECK ב-Spanner
אובייקטים אחרים במסד הנתונים
עליך ליצור את הפונקציונליות של האובייקטים הבאים בלוגיקה של האפליקציה שלך:
- תצוגות
- טריגרים
- תהליכים מאוחסנים
- פונקציות בהגדרת המשתמש (UDF)
- עמודות שמשתמשות בסוגי הנתונים
serialכגנרטורים של רצפים
כשמעבירים את הפונקציונליות הזו ללוגיקה של האפליקציה, חשוב לזכור את הטיפים הבאים:
- צריך להעביר את כל הצהרות ה-SQL שבהן אתם משתמשים מניבוב ה-SQL של PostgreSQL לניבוב ה-SQL של Google.
- אם אתם משתמשים בסמני מיקום, אתם יכולים לשנות את השאילתה כך שתשתמש בהיסטים ובמגבלות.
יצירת מכונת Spanner
אחרי שמעדכנים את הצהרות ה-DDL כך שיתאימו לדרישות של סכימת Spanner, משתמשים בהן כדי ליצור את מסד הנתונים ב-Spanner.
יצירת מופע Spanner. כדי לקבוע את ההגדרה האזורית הנכונה ואת קיבולת החישוב שתתמוך ביעדי הביצועים שלכם, פועלים לפי ההנחיות שבמאמר Instances.
יוצרים את מסד הנתונים באמצעות המסוף Google Cloud או כלי שורת הפקודה
gcloud:
המסוף
- כניסה לדף Instances
- לוחצים על שם המופע שבו רוצים ליצור את מסד הנתונים לדוגמה כדי לפתוח את הדף פרטי המופע.
- לוחצים על יצירת מסד נתונים.
- מקלידים שם למסד הנתונים ולוחצים על המשך.
- בקטע Define your database schema (הגדרת סכימת מסד הנתונים), מעבירים את המתג של האפשרות Edit as text (עריכה כטקסט).
- מעתיקים את הצהרות ה-DDL ומדביקים אותן בשדה הצהרות DDL.
- לוחצים על יצירה.
gcloud
- מתקינים את ה-CLI של gcloud.
- משתמשים בפקודה
gcloud spanner databases createכדי ליצור את מסד הנתונים:gcloud spanner databases create DATABASE_NAME --instance=INSTANCE_NAME --ddl='DDL1' --ddl='DDL2'
- DATABASE_NAME הוא השם של מסד הנתונים.
- INSTANCE_NAME הוא מופע Spanner שיצרתם.
- DDLn הם הצהרות ה-DDL ששיניתם.
אחרי שיוצרים את מסד הנתונים, פועלים לפי ההוראות שבמאמר הקצאת תפקידים ב-IAM כדי ליצור חשבונות משתמשים ולהעניק הרשאות למופע ולמסד הנתונים של Spanner.
הגדרת רמת הבידוד של טרנזקציה ובקרת בו-זמניות
רמת הבידוד שמוגדרת כברירת מחדל בעסקאות ב-Spanner היא בידוד ניתן לסידור, שמבטיח עקביות חיצונית של הנתונים. Spanner מציע גם בידוד קריאה חוזרת. מומלץ להגדיר את רמת הבידוד ל-repeatable read ואת בקרת בו-זמניות ל-pessimistic concurrency כחלק מתהליך העברת האפליקציה, כדי שהסמנטיקה של העסקאות ב-Spanner תתאים באופן הדוק לסמנטיקה של עסקאות ברירת המחדל ב-PostgreSQL. הוראות להגדרת רמת הבידוד ובקרת הגישה בו-זמנית באפליקציה מופיעות במאמרים שימוש ברמת הבידוד 'קריאה חוזרת' והגדרת בקרת גישה בו-זמנית.
שינוי מבנה האפליקציות ושכבות הגישה לנתונים
בנוסף לקוד שנדרש כדי להחליף את אובייקטי מסד הנתונים הקודמים, צריך להוסיף לוגיקה של אפליקציה כדי לטפל בפונקציונליות הבאה:
- גיבוב של מפתחות ראשיים לפעולות כתיבה, לטבלאות עם שיעורי כתיבה גבוהים למפתחות רציפים.
- אימות נתונים שלא נכללים כבר במגבלות של
CHECK. - בדיקות של שלמות רפרנציאלית שלא מכוסות כבר על ידי מפתחות זרים, שילוב טבלאות או לוגיקה של אפליקציות, כולל פונקציונליות שמטופלת על ידי טריגרים בסכימה של PostgreSQL.
מומלץ להשתמש בתהליך הבא כשמבצעים רפקטורינג:
- מוצאים את כל קוד האפליקציה שיש לו גישה למסד הנתונים, ומבצעים לו רפקטורינג למודול או לספרייה יחידים. כך תוכלו לדעת בדיוק איזה קוד ניגש למסד הנתונים, ולכן בדיוק איזה קוד צריך לשנות.
- לכתוב קוד שמבצע פעולות קריאה וכתיבה במופע Spanner, ולספק פונקציונליות מקבילה לקוד המקורי שקורא וכותב ב-PostgreSQL. במהלך פעולות כתיבה, צריך לעדכן את כל השורה, ולא רק את העמודות שהשתנו, כדי לוודא שהנתונים ב-Spanner זהים לנתונים ב-PostgreSQL.
- לכתוב קוד שמחליף את הפונקציונליות של אובייקטים ופונקציות במסד הנתונים שלא זמינים ב-Spanner.
העברת נתונים
אחרי שיוצרים את מסד הנתונים ב-Spanner ומבצעים רפקטורינג של קוד האפליקציה, אפשר להעביר את הנתונים ל-Spanner.
- משתמשים בפקודה
COPYשל PostgreSQL כדי לייצא נתונים לקובצי .csv. מעלים את קובצי ה-CSV ל-Cloud Storage.
- יצירת קטגוריה של Cloud Storage
- במסוף Cloud Storage, לוחצים על שם הקטגוריה כדי לפתוח את דפדפן הקטגוריות.
- לוחצים על העלאת קבצים.
- עוברים אל הספרייה שמכילה את קובצי ה-CSV ובוחרים אותם.
- לוחצים על פתיחה.
יוצרים אפליקציה לייבוא נתונים ל-Spanner. האפליקציה הזו יכולה להשתמש ב-Dataflow או בספריות הלקוח ישירות. כדי להשיג את הביצועים הטובים ביותר, חשוב לפעול לפי ההנחיות שמפורטות במאמר בנושא שיטות מומלצות לטעינת נתונים בכמות גדולה.
בדיקות
בודקים את כל הפונקציות של האפליקציה מול מופע Spanner כדי לוודא שהן פועלות כמצופה. מריצים עומסי עבודה ברמת הייצור כדי לוודא שהביצועים עונים על הצרכים שלכם. מעדכנים את קיבולת המחשוב לפי הצורך כדי להשיג את יעדי הביצועים שהוצבו.
מעבר למערכת החדשה
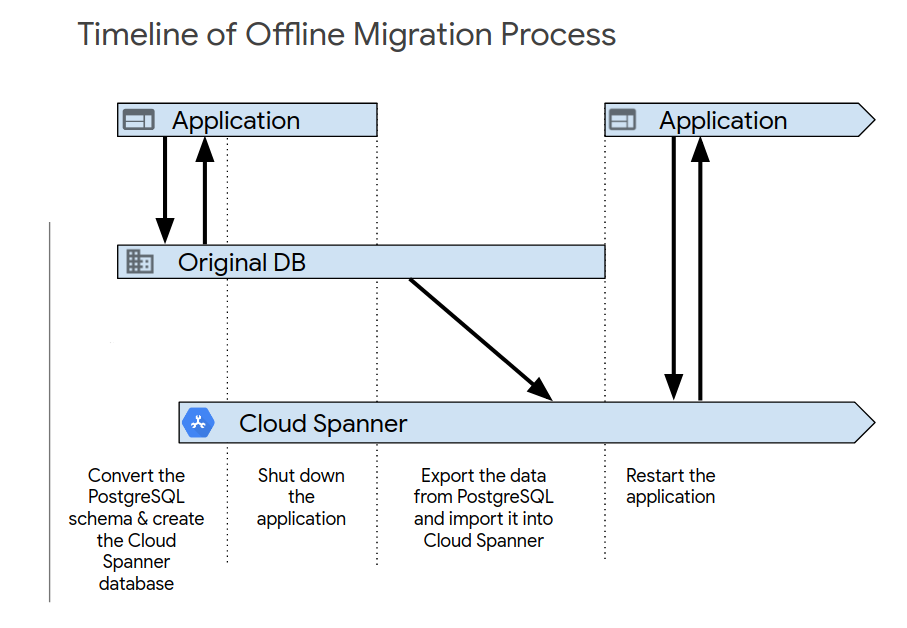
אחרי שתסיימו את הבדיקה הראשונית של האפליקציה, תפעילו את המערכת החדשה באמצעות אחד מהתהליכים הבאים. הדרך הפשוטה ביותר לבצע העברה היא העברה אופליין. עם זאת, הגישה הזו גורמת לכך שהאפליקציה לא תהיה זמינה למשך תקופה מסוימת, ולא מספקת אפשרות לחזור לגרסה קודמת אם מאוחר יותר תגלו בעיות בנתונים. כדי לבצע העברה אופליין:
- מחיקת כל הנתונים במסד הנתונים של Spanner.
- משביתים את האפליקציה שמכוונת למסד הנתונים של PostgreSQL.
- מייצאים את כל הנתונים ממסד הנתונים של PostgreSQL ומייבאים אותם למסד הנתונים של Spanner, כמו שמתואר בסקירה כללית על העברה.
מפעילים את האפליקציה שמכוונת למסד הנתונים של Spanner.
אפשר לבצע מיגרציה פעילה, אבל היא מצריכה שינויים משמעותיים באפליקציה כדי לתמוך במיגרציה.
דוגמאות להעברת סכימה
בדוגמאות האלה מוצגות הצהרות CREATE TABLE של כמה טבלאות בסכימה של מסד הנתונים MusicBrainz PostgreSQL.
כל דוגמה כוללת גם את סכימת PostgreSQL וגם את סכימת Spanner.
טבלת הקרדיטים של האומן
GoogleSQL
CREATE TABLE artist_credit (
hashed_id STRING(4),
id INT64,
name STRING(MAX) NOT NULL,
artist_count INT64 NOT NULL,
ref_count INT64,
created TIMESTAMP OPTIONS (
allow_commit_timestamp = true
),
) PRIMARY KEY(hashed_id, id);
PostgreSQL
CREATE TABLE artist_credit (
id SERIAL,
name VARCHAR NOT NULL,
artist_count SMALLINT NOT NULL,
ref_count INTEGER DEFAULT 0,
created TIMESTAMP WITH TIME ZONE DEFAULT NOW()
);
טבלת הקלטות
GoogleSQL
CREATE TABLE recording (
hashed_id STRING(36),
id INT64,
gid STRING(36) NOT NULL,
name STRING(MAX) NOT NULL,
artist_credit_hid STRING(36) NOT NULL,
artist_credit_id INT64 NOT NULL,
length INT64,
comment STRING(255) NOT NULL,
edits_pending INT64 NOT NULL,
last_updated TIMESTAMP OPTIONS (
allow_commit_timestamp = true
),
video BOOL NOT NULL,
) PRIMARY KEY(hashed_id, id);
PostgreSQL
CREATE TABLE recording (
id SERIAL,
gid UUID NOT NULL,
name VARCHAR NOT NULL,
artist_credit INTEGER NOT NULL, -- references artist_credit.id
length INTEGER CHECK (length IS NULL OR length > 0),
comment VARCHAR(255) NOT NULL DEFAULT '',
edits_pending INTEGER NOT NULL DEFAULT 0 CHECK (edits_pending >= 0),
last_updated TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
video BOOLEAN NOT NULL DEFAULT FALSE
);
טבלת כתובות אימייל חלופיות להקלטה
GoogleSQL
CREATE TABLE recording_alias (
hashed_id STRING(36) NOT NULL,
id INT64 NOT NULL,
alias_id INT64,
name STRING(MAX) NOT NULL,
locale STRING(MAX),
edits_pending INT64 NOT NULL,
last_updated TIMESTAMP NOT NULL OPTIONS (
allow_commit_timestamp = true
),
type INT64,
sort_name STRING(MAX) NOT NULL,
begin_date_year INT64,
begin_date_month INT64,
begin_date_day INT64,
end_date_year INT64,
end_date_month INT64,
end_date_day INT64,
primary_for_locale BOOL NOT NULL,
ended BOOL NOT NULL,
) PRIMARY KEY(hashed_id, id, alias_id),
INTERLEAVE IN PARENT recording ON DELETE NO ACTION;
PostgreSQL
CREATE TABLE recording_alias (
id SERIAL, --PK
recording INTEGER NOT NULL, -- references recording.id
name VARCHAR NOT NULL,
locale TEXT,
edits_pending INTEGER NOT NULL DEFAULT 0 CHECK (edits_pending >=0),
last_updated TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
type INTEGER, -- references recording_alias_type.id
sort_name VARCHAR NOT NULL,
begin_date_year SMALLINT,
begin_date_month SMALLINT,
begin_date_day SMALLINT,
end_date_year SMALLINT,
end_date_month SMALLINT,
end_date_day SMALLINT,
primary_for_locale BOOLEAN NOT NULL DEFAULT false,
ended BOOLEAN NOT NULL DEFAULT FALSE
-- CHECK constraint skipped for brevity
);