
Nesta página, descrevemos como importar as informações do seu catálogo e mantê-las atualizadas.
Os procedimentos de importação nesta página se aplicam às recomendações e à pesquisa. Depois que você importar dados, ambos os serviços poderão usar esses dados. Portanto, não é necessário importar os mesmos dados duas vezes se você usar os dois serviços.
É possível importar os dados de produtos do BigQuery ou especificar os dados in-line na solicitação. Cada um desses procedimentos são importações únicas, com exceção da vinculação do Merchant Center. Programe importações de catálogo regulares (de preferência, diariamente) para verificar se ele está atualizado.
Consulte Mantenha seu catálogo atualizado.
Também é possível importar itens de produtos individuais. Para mais informações, consulte Fazer upload de um produto.
Antes de começar
Antes de começar a importar seu catálogo, faça o seguinte:
- Criar um projeto;
- Crie uma conta de serviço.
- Adicione a conta de serviço ao ambiente local.
Consulte Pré-requisitos de configuração para mais informações.
Considerações sobre importação de catálogo
Nesta seção, descrevemos os métodos que podem ser usados para importação em lote dos dados de catálogo, quando você usa cada método e algumas das limitações deles.
| BigQuery | Descrição | Importe dados de uma tabela do BigQuery carregada anteriormente que use o esquema do AI Commerce Search. Pode ser realizado usando o console do Google Cloud ou o curl. |
|---|---|---|
| Quando usar |
Se você tiver catálogos de produtos com muitos atributos. A importação
do BigQuery usa o esquema do AI Commerce Search, que tem mais atributos
de produto do que outras opções de importação, incluindo atributos personalizados
de chave-valor.
Se você tiver grandes volumes de dados. A importação do BigQuery não tem um limite de dados. Se você já usa o BigQuery. |
|
| Limitações | Exige a etapa extra de criação de uma tabela do BigQuery que é mapeada para o esquema da Pesquisa de comércio com IA. | |
| Cloud Storage | Descrição |
Importe dados em um formato JSON de arquivos carregados em um bucket do
Cloud Storage. Cada arquivo precisa ter 2 GB ou menos e até 100 arquivos por vez são importados. A importação pode ser feita usando o console Google Cloud
ou o curl. Usa o formato de dados JSON Product, que permite atributos personalizados.
|
| Quando usar | Se você precisa carregar uma grande quantidade de dados em uma única etapa | |
| Limitações | Não é ideal para catálogos com atualizações frequentes de inventário e preços, já que as alterações não são refletidas imediatamente. | |
| Importação in-line | Descrição |
Importação usando uma chamada para o método Product.import. Usa
o objeto ProductInlineSource, que tem menos atributos de catálogo
de produtos do que o esquema da AI Commerce Search, mas é compatível com atributos
personalizados.
|
| Quando usar | Se você tem dados de catálogo planos e não relacionais ou uma alta frequência de atualizações de quantidade ou preço. | |
| Limitações | Apenas 100 itens do catálogo podem ser importados por vez. No entanto, muitas etapas de carregamento podem ser executadas: não há limite de itens. |
Tutoriais
Nesta seção, você vai conhecer diferentes métodos de importação de catálogo com um vídeo e tutoriais em shell.
Tutorial em vídeo
Assista a este vídeo para saber como importar um catálogo usando a API AI Commerce Search.
Tutorial de importação de catálogo do BigQuery
Neste tutorial, você vai aprender a usar uma tabela do BigQuery para importar grandes quantidades de dados de catálogo sem limites.
Para seguir as instruções da tarefa diretamente no editor do Cloud Shell, clique em Orientação:
Tutorial para importar catálogo do Cloud Storage
Neste tutorial, mostramos como importar um grande número de itens para um catálogo.
Para seguir as instruções da tarefa diretamente no editor do Cloud Shell, clique em Orientação:
Tutorial in-line de importação de dados do catálogo
Neste tutorial, você vai aprender a importar produtos para um catálogo in-line.
Para seguir as instruções da tarefa diretamente no editor do Cloud Shell, clique em Orientação:
Práticas recomendadas de importação de catálogo
Dados de alta qualidade são necessários para gerar resultados de alta qualidade. Se os dados não tiverem campos ou tiverem valores de marcador em vez de valores reais, a qualidade das previsões e dos resultados da pesquisa será prejudicada.
Ao importar dados do catálogo, implemente as seguintes práticas recomendadas:
Distinga com cuidado os produtos principais e as variantes de produto. Antes de fazer upload de dados, consulte Níveis de produto.
Mudar a configuração no nível do produto depois de fazer um esforço significativo para importar dados. Os itens principais, não as variantes, são retornados como resultados da pesquisa ou recomendações.
Exemplo: se o grupo de SKUs principal for Camisa com gola em V,o modelo de recomendação vai retornar uma camisa com gola em V e, talvez, camisas com gola redonda e em U. No entanto, se as variantes não forem usadas e cada SKU for um item principal, todas as combinações de cores ou tamanhos de camisetas com gola em V serão retornadas como um item distinto no painel de recomendações: Camiseta marrom com gola em V, tamanho GG, camiseta marrom com gola em V, tamanho G até Camiseta branca com gola em V, tamanho M, camiseta branca com gola em V, tamanho P.
As coleções podem ser reconhecidas juntas desde que os IDs de variantes sejam incluídos com os IDs de produtos principais em
collectionMemberIds[]. Isso faz com que uma coleção de produtos, em que um usuário pode ter comprado um ou mais itens do conjunto, seja capturada no evento do usuário, creditando todo o conjunto à compra. Isso facilita a veiculação de outros produtos da mesma coleção para o mesmo usuário em uma consulta relacionada futura.Exemplo: um usuário comprou uma capa de edredom. Por isso, produtos correspondentes em uma coleção de lençóis, como fronhas, são retornados.
Observe os limites de importação de itens do produto.
Para a importação em massa do Cloud Storage, o tamanho de cada arquivo precisa ser 2 GB ou menor. É possível incluir até 100 arquivos por vez em uma única solicitação de importação em massa.
Para realizar a importação in-line, importe no máximo 5 mil itens de cada vez.
Verifique se todas as informações de catálogo necessárias estão incluídas e corretas. Não use valores de marcador de posição.
Inclua o máximo possível de informações opcionais do catálogo.
Certifique-se de que todos os seus eventos usem uma única moeda, principalmente se você pretende usar o console doGoogle Cloud para ver métricas de receita. A API AI Commerce Search não é compatível com o uso de várias moedas por catálogo.
Mantenha seu catálogo atualizado, de preferência todos os dias. A programação de importações periódicas de catálogo evita que a qualidade do modelo diminua com o tempo. É possível programar importações automáticas e recorrentes ao importar o catálogo usando o console da AI Commerce Search no Gemini Enterprise for Customer Experience. Se preferir, use o Google Cloud Scheduler para automatizar importações.
Não registre eventos de usuário de itens de produtos que ainda não foram importados.
Depois de importar as informações do catálogo, revise os relatórios de erros e as informações de geração de registros do seu projeto. Se você encontrar mais do que alguns erros, revise-os e corrija os problemas de processo que os causaram.
O pipeline de ingestão de dados da AI Commerce Search abrange dados de catálogo de produtos e dados de eventos do usuário. Esse fluxo de dados fornece a base para um treinamento de modelo robusto e uma avaliação contínua por mecanismos de feedback. A ingestão de dados precisa e completa não é apenas um pré-requisito, mas um processo contínuo essencial para manter a adaptabilidade dos modelos subjacentes. Isso, por sua vez, influencia diretamente a qualidade e a relevância dos resultados da pesquisa, oferecendo um retorno significativo sobre o investimento.
Considere estas práticas recomendadas de ingestão de dados ao arquitetar sua solução de pesquisa de comércio.
Importação em massa, streaming em tempo real ou ambos?
AI Commerce Search oferece dois métodos principais para ingestão de catálogo:
Importação em massa
Streaming em tempo real
Essa abordagem dupla atende às diversas necessidades arquitetônicas de vários back-ends de clientes. Não é necessário escolher exclusivamente um método. É possível usar um modo de ingestão híbrido, com importação em massa e atualizações de streaming com base em requisitos específicos.
As importações em massa são ideais para adições, exclusões ou atualizações em grande escala de milhares de produtos de uma só vez. Por outro lado, o streaming em tempo real é excelente quando são necessárias atualizações contínuas para um volume relativamente menor de produtos. A escolha entre esses métodos depende da natureza do catálogo de produtos, da frequência de atualizações e da arquitetura geral dos sistemas de back-end.
A funcionalidade de importação em massa oferece suporte a três fontes de dados distintas:
- BigQuery: facilita a modificação rápida dos dados do catálogo, permite a especificação de datas de partição durante a importação e possibilita a transformação eficiente de dados com consultas SQL.
- Google Cloud Storage: o Cloud Storage exige a adesão a formatos específicos, como JSON, e restrições de arquivos. Os usuários são responsáveis por gerenciar estruturas de bucket, divisão de arquivos em partes e outros aspectos do processo de importação. Além disso, editar diretamente o catálogo no Cloud Storage pode ser complicado e, embora seja potencialmente econômico, não tem a flexibilidade de outros métodos.
- Dados inline: para catálogos extensos, as importações inline podem não ser a opção mais escalonável devido a limitações de tamanho. Reserve o uso para pequenas atualizações ou testes experimentais.
Para cenários que envolvem um grande volume de atualizações do catálogo de produtos (milhares de mudanças, adições ou exclusões de produtos) em um curto período e em intervalos regulares, uma abordagem combinada de importações em massa e streaming em tempo real pode ser muito eficaz. Faça o staging das atualizações no BigQuery ou no Cloud Storage e realize importações incrementais em massa em intervalos regulares, como a cada uma ou duas horas. Esse método gerencia atualizações em grande escala de maneira eficiente, minimizando as interrupções.
Para atualizações menores, menos frequentes ou que precisam ser refletidas imediatamente no catálogo, use a API de streaming em tempo real. Na abordagem híbrida, o streaming em tempo real pode preencher as lacunas entre as importações em massa, garantindo que seu catálogo permaneça atualizado. Essa estratégia equilibra a realização de chamadas individuais da API REST (para correção de produtos) e a execução de mudanças em massa, otimizando a eficiência e a capacidade de resposta no gerenciamento do catálogo do AI Commerce Search.
Estratégias de ramificação para gerenciamento de catálogo
Mantenha um catálogo unificado em uma única ramificação, em vez de ter catálogos diferentes em várias ramificações. Essa prática simplifica as atualizações do catálogo e reduz o risco de inconsistências durante a troca de ramificações.
As seguintes estratégias de ramificação comuns são eficazes para o gerenciamento de catálogos.
Atualizações de uma única ramificação
Designar uma ramificação ativa como padrão e atualizá-la continuamente conforme as mudanças no catálogo. Para atualizações em massa, use a funcionalidade de importação durante períodos de baixo tráfego para minimizar as interrupções. Use APIs de streaming para atualizações incrementais menores ou agrupe-as em partes maiores para importações regulares.
Comutação de ramificações
Há algumas opções para gerenciar diferentes ramificações:
Use ramificações para teste e verificação:
- Alguns engenheiros de sites de comércio eletrônico optam por uma abordagem de troca de ramificações, em que o catálogo é atualizado em uma ramificação não ativa e depois se torna a ramificação padrão (ativa) quando está pronto para produção. Isso permite preparar o catálogo do dia seguinte com antecedência. As atualizações podem ser feitas usando a importação em massa ou o streaming para a ramificação não ativa, garantindo uma transição tranquila durante os horários de baixo tráfego.
- A escolha entre essas estratégias depende dos seus requisitos específicos, da frequência de atualização e da configuração da infraestrutura. No entanto, independente da estratégia escolhida, manter um catálogo unificado em uma única ramificação é crucial para o desempenho ideal e resultados de pesquisa consistentes no AI Commerce Search.
Use ramificações para backups:
- Uma única ramificação ativa se concentra na ingestão e no processamento contínuos de atualizações de produtos para manter o índice do AI Commerce Search atualizado quase em tempo real.
- Outra ramificação se concentra na criação de um snapshot diário dos dados transformados no AI Commerce Search, atuando como um mecanismo de substituição robusto em caso de corrupção de dados ou problemas com a ramificação 0.
- Uma terceira ramificação se concentra na criação de um snapshot semanal da data transformada. Assim, o cliente pode ter um backup de um dia e um backup de uma semana em ramificações diferentes.
Limpar ramificações do catálogo
Se você estiver importando novos dados de catálogo para uma ramificação existente, é importante que ela esteja vazia para garantir a integridade dos dados importados para a ramificação. Quando a ramificação estiver vazia, você poderá importar novos dados de catálogo e vincular a ramificação a uma conta do comerciante.
Se você estiver veiculando previsões ou tráfego de pesquisa em tempo real e planejar limpar sua ramificação padrão, especifique outra ramificação como padrão antes de fazer isso. Como a ramificação padrão vai disponibilizar resultados vazios depois de ser excluída permanentemente, excluir permanentemente uma ramificação padrão ativa pode causar uma interrupção do serviço.
Para limpar dados de uma ramificação do catálogo, siga estas etapas:
Acesse a página Dados no console da Pesquisa de comércio com IA no Gemini Enterprise for Customer Experience.
Acessar a página "Dados"Selecione uma ramificação do catálogo no campo Nome da ramificação.
No menu de três pontos ao lado do campo Nome da ramificação, escolha Remover ramificação.
Uma mensagem vai aparecer avisando que você está prestes a excluir todos os dados na ramificação, bem como os atributos criados para ela.
Insira a ramificação e clique em Confirmar para limpar os dados do catálogo da ramificação.
Uma operação de longa duração é iniciada para limpar os dados da ramificação do catálogo. Quando a operação de limpeza for concluída, o status dela será exibido na lista Catálogo de produtos na janela Status da atividade.
Atualizações de inventário no AI Commerce Search
Esta seção descreve como otimizar a performance do AI Commerce Search fazendo atualizações regulares de inventário.
Streaming em tempo real
- Para dados dinâmicos, como informações de inventário (preço, disponibilidade) e detalhes no nível da loja, incluindo status de operação de fulfillment e preços específicos da loja, o streaming em tempo real é a única opção na AI Commerce Search.
- Essa distinção surge devido à natureza de alta frequência das flutuações de inventário em comparação com os dados relativamente estáticos do catálogo de produtos. A disponibilidade do produto pode mudar várias vezes por dia, enquanto as descrições ou os atributos permanecem relativamente constantes.
- A frequência das atualizações no nível da loja aumenta ainda mais com o número de locais de varejo.
Atualizações assíncronas
- Para acompanhar esse ritmo rápido de mudanças, a AI Commerce Search usa atualizações assíncronas de inventário com APIs que retornam um ID de tarefa.
- O processo de atualização não é considerado concluído até que o status do job seja pesquisado e confirmado, o que pode causar um pequeno atraso que varia de segundos a minutos.
Atualizações fora de ordem
- Um recurso importante desse sistema é a capacidade de atualizar as informações de inventário antes que o produto correspondente seja ingerido no catálogo. Isso resolve o cenário comum em que os pipelines de dados de inventário e produtos operam de forma independente nos varejistas, às vezes fazendo com que as informações de inventário fiquem disponíveis antes da atualização do catálogo de produtos. Ao atualizar o inventário, use a opção
allowMissingpara processar atualizações fora de ordem do inventário em relação ao produto. - Ao permitir que as atualizações de inventário precedam a ingestão do catálogo, a Pesquisa para Commerce com IA acomoda essas discrepâncias de pipeline, garantindo que dados de inventário precisos estejam disponíveis mesmo para produtos recém-lançados.
- No entanto, as informações de inventário de um produto são mantidas por 24 horas e serão excluídas se um produto correspondente não for ingerido nesse período. Esse mecanismo garante a consistência dos dados e evita que informações desatualizadas do inventário permaneçam no sistema.
Pré-verificações do catálogo de produtos para testes A/B robustos no AI Commerce Search
Esta seção aborda como executar pré-verificações nos dados do catálogo de produtos.
Garantir a paridade consistente das atualizações do catálogo
- Em preparação para um teste A/B na AI Commerce Search, é fundamental manter uma paridade estrita entre o catálogo legado (controle) e o catálogo da AI Commerce Search (teste). Qualquer desequilíbrio entre os dois pode afetar negativamente o teste A/B, levando a observações distorcidas e resultados potencialmente inválidos. Por exemplo, inconsistências na disponibilidade do produto, nos preços ou até mesmo pequenas discrepâncias de atributos podem introduzir vieses não intencionais nos dados de teste.
- Para reduzir esse risco, é fundamental projetar um processo de atualização paralela para os catálogos de controle e de teste, evitando atualizações sequenciais sempre que possível. O objetivo é maximizar o tempo em que os dois catálogos estão sincronizados. Já as atualizações em série podem causar atrasos em uma faixa ou outra. Esses atrasos podem resultar em incompatibilidades temporárias de catálogo, em que um produto pode estar em estoque em um catálogo, mas não em outro. Ou um produto recém-adicionado aparece em um catálogo antes do outro. Essas disparidades podem influenciar significativamente o comportamento, os cliques e as compras dos usuários, levando a uma comparação injusta e resultados imprecisos do teste A/B.
- Ao priorizar atualizações paralelas e buscar uma paridade consistente do catálogo, os varejistas podem garantir condições de concorrência justas para os testes A/B na AI Commerce Search. Essa abordagem permite uma análise imparcial e justa dos resultados do teste, gerando insights mais confiáveis e decisões mais fundamentadas.
Alcançar a paridade de dados do catálogo
- A profundidade e a acurácia da compreensão de produtos de um modelo de pesquisa de e-commerce dependem da riqueza e da qualidade das informações do catálogo de produtos subjacente. Quanto mais abrangentes forem os dados de produtos no catálogo, mais preparado o modelo estará para entender e classificar os itens de forma eficaz.
- Portanto, em preparação para o teste A/B, é fundamental garantir que os dados de produtos enviados para o catálogo legado (controle) e para o catálogo da AI Commerce Search (teste) sejam idênticos. Qualquer discrepância nas informações do produto entre esses dois ambientes pode influenciar significativamente os resultados do teste A/B.
- Por exemplo, se o mecanismo de pesquisa legado tiver um catálogo mais rico ou extenso do que a AI Commerce Search, isso vai criar uma vantagem injusta. A falta de informações no catálogo da AI Commerce Search pode ser prejudicial para a compreensão e classificação de produtos, o que pode levar a resultados de pesquisa imprecisos e comparações de desempenho enganosas. Detectar essas disparidades pode ser difícil com ferramentas externas e geralmente requer uma inspeção manual meticulosa dos dois catálogos.
- Ao garantir que ambos os catálogos contenham os mesmos dados de produtos com o mesmo nível de detalhes, os varejistas podem criar um campo de testes A/B justo na AI Commerce Search. Essa abordagem promove uma comparação justa e imparcial dos dois mecanismos de pesquisa, facilitando a avaliação precisa da performance e dos recursos de cada um.
Planejamento de recuperação de desastres
Um plano de recuperação de desastres bem preparado garante que seus recursos de pesquisa de comércio permaneçam operacionais e responsivos, minimizando o impacto na experiência do cliente e na geração de receita. Esse plano precisa permitir a restauração rápida do catálogo para resolver a possível falha dos fluxos de trabalho de ingestão de eventos do usuário e do catálogo, independente da causa.
Usar o BigQuery para o preparo de dados oferece uma vantagem distinta na recuperação de desastres. Se os dados atuais de catálogo ou dados de eventos do usuário na AI Commerce Search não forem muito diferentes do snapshot mais recente armazenado no BigQuery, chamar a API de importação poderá iniciar uma restauração rápida. Essa abordagem minimiza o tempo de inatividade e garante que a funcionalidade de pesquisa permaneça operacional.
Por outro lado, se o BigQuery não estiver integrado ao pipeline de dados, mecanismos alternativos precisarão estar em vigor para recarregar rapidamente o catálogo de um estado bom conhecido. Esses mecanismos podem envolver sistemas de backup, replicação de dados ou outras estratégias de failover.
Ao incorporar essas considerações de recuperação de desastres na arquitetura da AI Commerce Search, você pode aumentar a robustez do sistema e manter a continuidade dos negócios mesmo diante de interrupções inesperadas.
Planejar a alta disponibilidade
Ao fazer upload do catálogo de produtos para a AI Commerce Search, é importante considerar como diferentes Google Cloud serviços lidam com a regionalidade para projetar um pipeline de ingestão de dados resiliente.
Para criar um pipeline de ingestão com capacidade de recuperação de desastres usando o Dataflow, implante seus jobs em várias regiões usando um dos seguintes designs:
- Ativo/ativo:as instâncias do Dataflow em várias regiões processam dados simultaneamente.
- Ativa/passiva:uma instância do Dataflow em uma região fica ativa, enquanto as instâncias em outras regiões permanecem em espera.
Veja como implementar esses projetos com o Pub/Sub e o Dataflow:
- Serviços globais:alguns serviços, como o Pub/Sub, operam globalmente.O Google Cloud gerencia a disponibilidade deles de acordo com os Contratos de nível de serviço (SLAs) específicos.
- Serviços regionais:outros serviços, como o Dataflow, que você pode usar para transformar e ingerir dados na AI Commerce Search, são regionais. Você é responsável por configurar esses componentes para alta disponibilidade e recuperação de desastres.
Por exemplo, ao usar o BigQuery para persistir dados, ele pode ser configurado como multirregional para que a redundância e a disponibilidade de dados sejam processadas automaticamente pelo Google Cloud. Da mesma forma, ao usar o Cloud Storage, ele pode ser configurado como multirregional.
Design ativo/ativo
O design ativo/ativo usa atributos de mensagem e filtros de assinatura do Pub/Sub para garantir que cada mensagem seja processada exatamente uma vez por um job do Dataflow ativo em uma região específica.
Adicionar atributos de mensagem: ao publicar mensagens no tópico do Pub/Sub, como atualizações de produtos, inclua um atributo que indique a região de destino. Exemplo:
region:us-central1region:us-east1
Configurar filtros de assinatura: para cada pipeline regional do Dataflow, configure a assinatura do Pub/Sub para extrair apenas mensagens que correspondam à região usando filtros de mensagem. Por exemplo, a assinatura do job do Dataflow
us-central1teria um filtro comoattributes.region = "us-central1".Failover: se uma região ficar indisponível, atualize seu sistema de publicação upstream para marcar todas as novas mensagens com um atributo de uma região íntegra. Isso redireciona o processamento de mensagens para a instância do Dataflow na região de failover.
Vários componentes usados na arquitetura podem ser configurados como multirregionais por padrão. Por exemplo, ao usar o BigQuery para persistir dados, ele pode ser configurado como multirregional para que a redundância e a disponibilidade de dados sejam processadas automaticamente pelo Cloud Storage. Da mesma forma, ao usar o Cloud Storage, ele pode ser configurado como multirregional.
Design ativo/passivo
Esse design envolve ter apenas um pipeline regional do Dataflow buscando mensagens do Pub/Sub a qualquer momento.
Anexe uma assinatura: verifique se apenas a assinatura do Pub/Sub para o job do Dataflow da região ativa está anexada e extraindo mensagens. As assinaturas de jobs do Dataflow em regiões passivas precisam ser criadas, mas permanecer separadas.
Failover: se a região ativa apresentar uma falha, faça o seguinte de forma manual ou programática:
- Desvincule a assinatura do Pub/Sub associada ao job do Dataflow da região com falha.
- Anexe a assinatura do Pub/Sub associada a um job do Dataflow em uma das regiões passivas (em espera).
Isso transfere a carga de processamento de mensagens para a região recém-ativada.
Resiliência e análise forense
Usar o BigQuery no design da ingestão de dados pode resultar no tratamento da capacidade de recuperação e na criação de recursos para perícia e depuração. Os produtos e o inventário ingeridos diretamente com as APIs patch e addLocalInventory significam que, quando os dados são enviados para o AI Commerce Search, não há nenhum rastreamento da atualização de produtos e inventário. O usuário pode querer saber por que um produto não está aparecendo como esperado. Ter uma área de staging criada com o BigQuery e um histórico completo de dados facilita esse tipo de investigação e depuração.
Arquitetura de referência
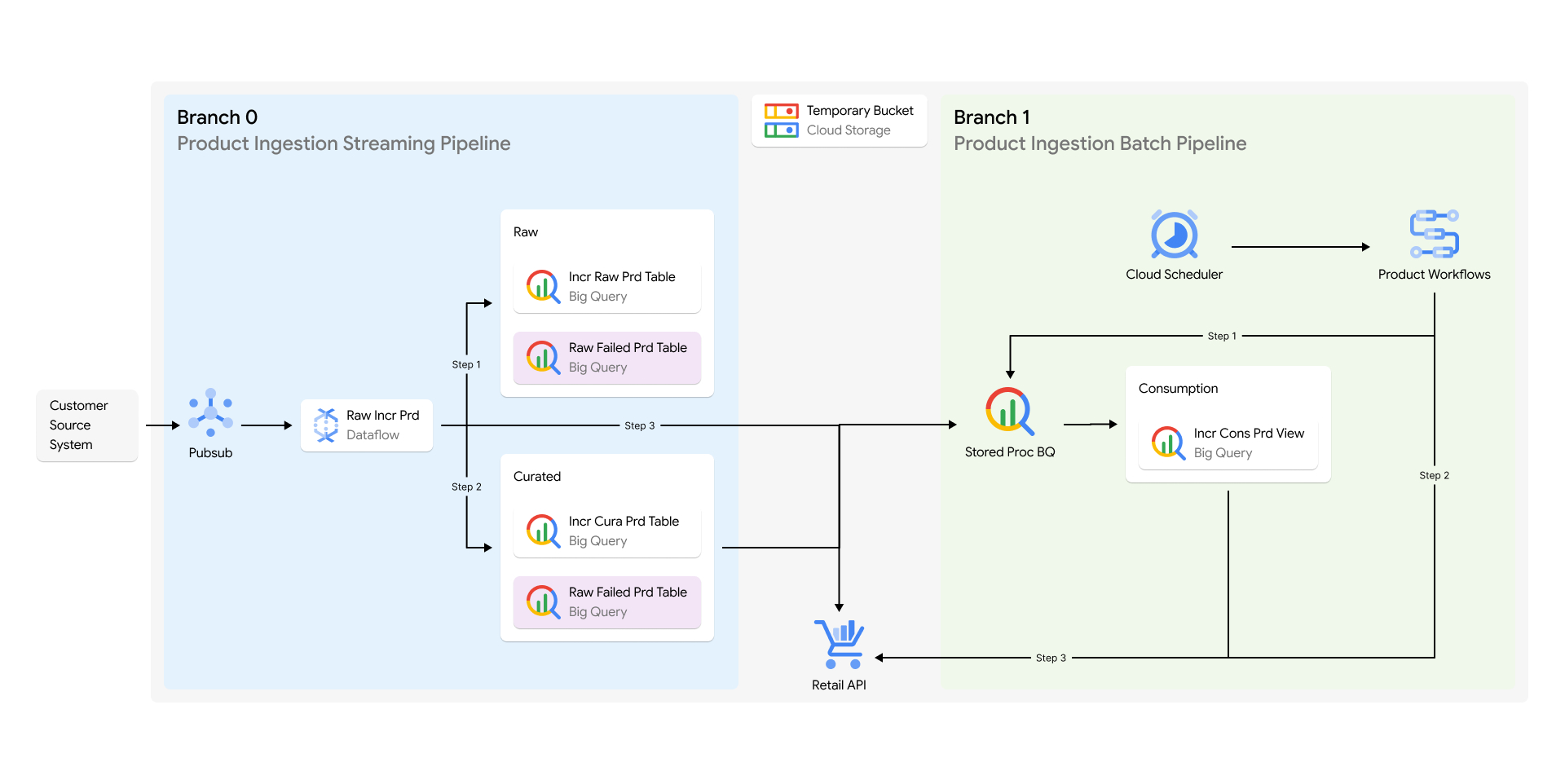
Nessa arquitetura, a ingestão de dados normalmente tem estágios brutos, selecionados e de consumo, todos criados no BigQuery. O sistema moveria os dados entre as etapas usando o Dataflow e orquestraria para automatizar tudo isso usando fluxos de trabalho na nuvem:
- O sistema usaria os dados brutos como eles são e os marcariam com carimbos de data/hora para manter o histórico. Esses dados não mudam, então os clientes os consideram uma fonte verdadeira.
- Em seguida, o sistema transformaria os dados em uma etapa selecionada e os marcariam novamente com um carimbo de data/hora. Assim, os clientes saberiam quando ele foi transformado e se algo falhou.
- Por fim, o sistema criaria visualizações na etapa de consumo dos dados selecionados usando o horário em que o sistema marcou os dados anteriormente. Assim, o cliente sabe exatamente quais dados transformados devem ser ingeridos no AI Commerce Search.
As ramificações 0, 1 e 2 servem como backup ativo e de um dia e ramificações de backup de uma semana. Os dados ingeridos diretamente na ramificação 0 são agregados e indexados na ramificação 1 diariamente e na ramificação 2 semanalmente. Assim, qualquer corrupção de dados pode ser revertida, aumentando a continuidade de negócios e a resiliência do sistema.
Além disso, é possível fazer análises e depurações, já que todo o histórico e a linhagem dos dados são mantidos em conjuntos de dados globais do BigQuery.
Planejar casos extremos com a ingestão de catálogos
Assim que os mecanismos principais para ingestão de catálogo na AI Commerce Search forem estabelecidos, uma abordagem proativa envolverá a avaliação da resiliência deles em relação a vários casos extremos. Embora alguns desses cenários possam não ser imediatamente relevantes para seus requisitos comerciais específicos, considerá-los no design de back-end pode oferecer uma proteção inestimável para o futuro.
Essa etapa preparatória envolve analisar a capacidade do pipeline de dados de lidar com cenários inesperados ou de casos extremos, garantindo a robustez e a adaptabilidade dele às demandas em constante mudança. Ao antecipar e resolver possíveis desafios de forma proativa, você pode reduzir interrupções futuras e manter o fluxo contínuo de dados de produtos no seu sistema de AI Commerce Search.
Para isso, a lógica do Dataflow precisa ser criada de forma que:
Valida cada item dos dados brutos para corresponder a um esquema adequado. O contrato dos dados brutos precisa ser determinado antecipadamente, e cada elemento de dados precisa ser sempre comparado com o contrato. Em caso de falha na validação, o elemento de dados brutos precisa ser marcado com carimbo de data/hora e mantido nas tabelas brutas com falha do BigQuery com erros reais destinados à análise forense.
Exemplos de falha:
- Um determinado atributo que não faz parte do contrato aparece de repente no elemento de dados brutos.
- Um determinado atributo obrigatório não está presente no elemento de dados brutos.
Valida cada item dos dados brutos para transformação no formato da Pesquisa de e-commerce com IA. Há alguns campos obrigatórios exigidos pela AI Commerce Search para a ingestão de produtos. Agora, todos os elementos dos dados brutos precisam ser verificados novamente para saber se podem ser transformados no formato de esquema da AI Commerce Search. Em caso de falha na transformação, o elemento de dados brutos precisa ser marcado com carimbo de data/hora e mantido nas tabelas selecionadas com falha do BigQuery com mensagens de erro reais que podem ajudar na análise forense.
Exemplos de falha:
- Um determinado atributo, como preço, não pode ser formatado como um número porque o elemento de dados brutos o tem como alfanumérico.
- O nome do produto está completamente ausente.
Este exemplo mostra um esquema de tabela do BigQuery para manter todas as falhas para depuração:
Ver um exemplo de esquema de tabela do BigQuery
[ { "mode": "REQUIRED", "name": "ingestedTimestamp", "type": "TIMESTAMP" }, { "mode": "REQUIRED", "name": "payloadString", "type": "STRING" }, { "mode": "REQUIRED", "name": "payloadBytes", "type": "BYTES" }, { "fields": [ { "mode": "NULLABLE", "name": "key", "type": "STRING" }, { "mode": "NULLABLE", "name": "value", "type": "STRING" } ], "mode": "REPEATED", "name": "attributes", "type": "RECORD" }, { "mode": "NULLABLE", "name": "errorMessage", "type": "STRING" }, { "mode": "NULLABLE", "name": "stacktrace", "type": "STRING" } ]
Teste de estresse e escalonabilidade
Prepare-se para eventos de alto volume e crescimento com testes de estresse e escalonabilidade.
Eventos com alto volume de tráfego
Eventos com alto tráfego, como feriados, representam um desafio significativo para os pipelines de ingestão de dados. O aumento nas atualizações de inventário, incluindo níveis de estoque e preços, e possíveis mudanças nos atributos do produto exigem uma infraestrutura robusta. É importante avaliar se o sistema de ingestão consegue lidar com esse aumento de carga. Os testes de carga simulada, que replicam padrões de tráfego de pico, identificam gargalos e garantem uma operação tranquila durante esses períodos críticos.
Ofertas relâmpago
As ofertas relâmpago apresentam um desafio único devido à curta duração e às rápidas variações de inventário. Garantir a sincronização do inventário em tempo real é fundamental para evitar discrepâncias entre os resultados da pesquisa e a disponibilidade real. Caso contrário, os clientes podem ter experiências negativas, como produtos populares aparecendo como disponíveis quando estão esgotados ou vice-versa. Além disso, as mudanças de preço durante as promoções relâmpago podem afetar significativamente a classificação do produto, destacando a necessidade de atualizações de preço precisas e oportunas no índice de pesquisa.
Expansão do catálogo
O crescimento dos negócios ou a expansão da linha de produtos podem resultar em um aumento drástico, como 5 ou 10 vezes, no número de produtos no catálogo. Sua arquitetura de ingestão precisa ser escalonável para acomodar esse crescimento sem problemas. Isso pode exigir uma revisão de todo o pipeline de ETL (extração, transformação e carregamento), principalmente se forem introduzidas novas fontes de dados ou formatos de informações do produto.
Ao abordar de forma proativa esses cenários possíveis, você garante que seu pipeline de ingestão do AI Commerce Search permaneça robusto, escalonável e responsivo, mesmo diante de picos repentinos de tráfego, promoções relâmpago ou crescimento significativo do catálogo. Essa abordagem proativa protege a acurácia e a confiabilidade dos resultados da pesquisa, contribuindo para uma experiência positiva do usuário e impulsionando o sucesso dos negócios.
A performance do pipeline de ingestão de dados precisa ser avaliada, e um valor de referência precisa ser formado para as seguintes métricas:
- Quanto tempo leva para publicar e ingerir todos os dados de catálogo e inventário? Isso pode ser necessário de maneira pontual durante a BFCM, quando os preços podem mudar significativamente para todo o catálogo.
- Quanto tempo leva para uma única atualização de produto ser refletida?
- Qual é a maior taxa de atualizações de produtos e inventário que o sistema pode gerar?
Gargalos
- Avalie e descubra se os pipelines podem escalonar verticalmente e horizontalmente corretamente.
- Determine se o teto máximo para o número de instâncias está muito alto ou muito baixo.
- Determine se o sistema está sendo limitado pela AI Commerce Search verificando o código HTTP 429.
- Confirme se é necessário aumentar determinadas cotas de API para reduzir os limites de taxa.
Estrutura de dados de produtos para ingestão de catálogo
Nesta seção, descrevemos como preparar os dados de produtos para a ingestão de catálogo.
Produtos principais
Os produtos principais servem como contêineres para agrupar variantes de produto e como entradas na grade de pesquisa. Ter apenas atributos comuns compartilhados entre as variantes especificadas para produtos principais. São eles:
- ID do produto principal
- ID do produto (igual ao ID do produto principal)
- Título
- Descrição
Consulte Sobre atributos de produto para mais informações.
Variantes de produto
As variantes de produto herdam atributos comuns do produto principal, mas também podem especificar valores exclusivos.
Os atributos obrigatórios incluem:
- Todos os atributos especificados para produtos principais (título, descrição). O preço, o título e a descrição podem ser diferentes do produto principal.
- Atributos específicos da variante (cor, tamanho e outras variações relevantes do produto).
Consulte Sobre atributos de produto para mais informações.
Recuperação de atributos
O processo de recuperação considera todos os atributos pesquisáveis para produtos principais e variantes de produto.
Pontuação de relevância
A pontuação de relevância é baseada apenas nos campos de título e descrição. Para garantir a diferenciação adequada, modifique um pouco os títulos das variantes em relação aos produtos principais (por exemplo, Nome do produto + Cor).
Correspondência de variantes nos resultados da pesquisa
A correspondência de variantes (por exemplo, vestido azul) filtra os resultados com base em atributos de variantes predefinidos, como cor e tamanho. Os resultados da pesquisa retornam até cinco variantes correspondentes para cada produto principal.
Sincronizar o Merchant Center com a AI Commerce Search
O Merchant Center é uma ferramenta que você pode usar para disponibilizar os dados da sua loja e os dados de produtos para anúncios do Shopping e outros serviços do Google.
Para a sincronização contínua entre o Merchant Center e a AI Commerce Search, vincule sua conta do Merchant Center à AI Commerce Search.
Ao configurar uma sincronização do Merchant Center para a AI Commerce Search, você precisa ter a função do IAM de administrador atribuída no Merchant Center. Embora uma função de acesso padrão permita ler os feeds do Merchant Center, ao tentar sincronizar o MC com a AI Commerce Search, você recebe uma mensagem de erro. Portanto, antes de sincronizar o Merchant Center com a AI Commerce Search, faça upgrade da sua função.
Vincular sua conta do Merchant Center
Enquanto a Pesquisa de comércio com IA estiver vinculada à conta do Merchant Center, as mudanças nos dados de produtos na conta do Merchant Center serão atualizadas automaticamente em minutos na Pesquisa de comércio com IA. Se você quiser impedir que as mudanças do Merchant Center sejam sincronizadas com o AI Commerce Search, desvincule sua conta do Merchant Center.
Desvincular sua conta do Merchant Center não exclui produtos no AI Commerce Search. Para excluir produtos importados, consulte Como excluir informações do produto.
Para sincronizar sua conta do Merchant Center, conclua as etapas a seguir.
Sincronizar sua conta do Merchant Center
Console do Cloud
-
Acesse a página Dados no console da Pesquisa de comércio com IA no Gemini Enterprise for Customer Experience.
Acessar a página "Dados" - Clique em Importar para abrir o painel Importar dados.
- Escolha Catálogo de produtos.
- Selecione Merchant Center Sync como sua fonte de dados.
- Selecione sua conta do Merchant Center. Verifique Acesso do usuário se você não encontrar sua conta.
- Opcional: selecione Filtro de feeds do Merchant Center para importar apenas ofertas de feeds selecionados.
Se não for especificado, as ofertas de todos os feeds serão importadas, incluindo os futuros. - Opcional: para importar apenas ofertas segmentadas para determinados países ou idiomas, expanda Mostrar opções avançadas e selecione os países de venda e idiomas do Merchant Center para filtrar.
- Selecione a ramificação para fazer o upload do catálogo.
- Clique em Importar.
curl
Verifique se a conta de serviço no seu ambiente local tem acesso à conta do Merchant Center e à Pesquisa de comércio com IA. Para verificar quais contas têm acesso à sua conta do Merchant Center, consulte Acesso do usuário para o Merchant Center.
Use o método
MerchantCenterAccountLink.createpara estabelecer a vinculação.curl -X POST \ -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ --data '{ "merchantCenterAccountId": MERCHANT_CENTER_ID, "branchId": "BRANCH_ID", "feedFilters": [ {"dataSourceId": DATA_SOURCE_ID_1} {"dataSourceId": DATA_SOURCE_ID_2} ], "languageCode": "LANGUAGE_CODE", "feedLabel": "FEED_LABEL", }' \ "https://retail.googleapis.com/v2alpha/projects/PROJECT_ID/locations/global/catalogs/default_catalog/merchantCenterAccountLinks"
- MERCHANT_CENTER_ID: o ID da conta do Merchant Center.
- BRANCH_ID: o ID da ramificação com que você quer estabelecer a vinculação. Aceita os valores "0", "1" ou "2".
- LANGUAGE_CODE: (OPCIONAL) o código de idioma de duas letras dos
produtos que você quer importar. Como visto no Merchant Center, na coluna
Languagedo produto. Se não for definido, todos os idiomas serão importados. - FEED_LABEL: (OPCIONAL) o rótulo do feed dos produtos que você quer importar. Você pode conferir o rótulo do feed no Merchant Center, na coluna Rótulo do feed do produto. Se não for definido, todos os rótulos do feed serão importados.
- FEED_FILTERS: (OPCIONAL) Lista de feeds principais de onde os produtos serão importados. Não selecionar feeds significa que todos os feeds da conta do Merchant Center serão compartilhados. Os IDs podem ser encontrados no recurso de datafeeds da API Content ou acessando o Merchant Center, selecionando um feed e recebendo o ID do feed do parâmetro afmDataSourceId no URL do site. Por exemplo,
mc/products/sources/detail?a=MERCHANT_CENTER_ID&afmDataSourceId=DATA_SOURCE_ID.
Para ver seu Merchant Center vinculado, acesse a página Dados do console da AI Commerce Search no Gemini Enterprise for Customer Experience e clique no botão Merchant Center no canto superior direito. Isso abre o painel Contas do Merchant Center vinculadas. Também é possível adicionar outras contas do Merchant Center nesse painel.
Consulte Como visualizar informações agregadas sobre seu catálogo para instruções sobre como visualizar os produtos que foram importados.
Listar os links da sua conta do Merchant Center
Console do Cloud
Acesse a página Dados no console da Pesquisa de comércio com IA no Gemini Enterprise for Customer Experience.
Acessar a página "Dados"Clique no botão Merchant Center no canto superior direito da página para abrir uma lista das suas contas vinculadas do Merchant Center.
curl
Use o método MerchantCenterAccountLink.list
para listar o recurso de links.
curl -X GET \ -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ "https://retail.googleapis.com/v2alpha/projects/PROJECT_NUMBER/locations/global/catalogs/default_catalog/merchantCenterAccountLinks"
Desvincular sua conta do Merchant Center
Desvincular sua conta do Merchant Center impede que ela sincronize os dados de catálogo com o AI Commerce Search. Esse procedimento não exclui nenhum produto na AI Commerce Search que já tenha sido enviado.
Console do Cloud
Acesse a página Dados no console da Pesquisa de comércio com IA no Gemini Enterprise for Customer Experience.
Acessar a página "Dados"Clique no botão Merchant Center no canto superior direito da página para abrir uma lista das suas contas vinculadas do Merchant Center.
Clique em Desvincular ao lado da conta do Merchant Center que você quer desvincular e confirme sua escolha na caixa de diálogo exibida.
curl
Use o método MerchantCenterAccountLink.delete
para remover o recurso MerchantCenterAccountLink.
curl -X DELETE \ -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ "https://retail.googleapis.com/v2alpha/projects/PROJECT_NUMBER/locations/global/catalogs/default_catalog/merchantCenterAccountLinks/BRANCH_ID_MERCHANT_CENTER_ID"
Limitações ao vincular ao Merchant Center
Uma conta do Merchant Center pode ser vinculada a qualquer número de ramificações de catálogo, mas uma única ramificação de catálogo só pode ser vinculada a uma conta do Merchant Center.
Uma conta do Merchant Center não pode ser uma conta de múltiplos clientes (MCA). No entanto, é possível vincular subcontas individuais.
A primeira importação depois de vincular sua conta do Merchant Center pode levar horas para ser concluída. O tempo depende do número de ofertas na conta do Merchant Center.
As modificações de produtos que usam os métodos da API são desativadas para ramificações vinculadas a uma conta do Merchant Center. Qualquer alteração nos dados do catálogo de produtos nessas ramificações precisa ser feita usando o Merchant Center. Essas mudanças são sincronizadas automaticamente com o AI Commerce Search.
O tipo de produto da coleção não é compatível com ramificações que usam o Merchant Center.
Sua conta do Merchant Center só pode ser vinculada a ramificações de catálogo vazias para garantir a precisão dos dados. Para excluir produtos de uma ramificação de catálogo, consulte Excluir informações do produto.
Importar dados do catálogo do BigQuery
Para importar dados do catálogo no formato correto do BigQuery, use o esquema da Pesquisa de e-commerce com IA para criar uma tabela do BigQuery com o formato correto e carregue a tabela vazia com os dados do catálogo. Em seguida, faça upload dos seus dados para a AI Commerce Search.
Para mais ajuda com as tabelas do BigQuery, consulte Introdução às tabelas. Para ajuda com as consultas do BigQuery, consulte Visão geral da consulta de dados do BigQuery.
Para seguir as instruções da tarefa diretamente no editor do Cloud Shell, clique em Orientação:
Para importar seu catálogo:
Se o conjunto de dados do BigQuery estiver em outro projeto, configure as permissões necessárias para que a AI Commerce Search possa acessar o conjunto de dados do BigQuery. Saiba mais.
Importe os dados do seu catálogo para a AI Commerce Search.
Console do Cloud
-
Acesse a página Dados no console da Pesquisa de comércio com IA no Gemini Enterprise for Customer Experience.
Acessar a página "Dados" - Clique em Importar para abrir o painel Importar dados.
- Escolha Catálogo de produtos.
- Selecione BigQuery como sua fonte de dados.
- Selecione a ramificação para fazer o upload do catálogo.
- Escolha Esquema de catálogos de produtos da Retail. Este é o esquema de produto para a AI Commerce Search.
- Insira a tabela do BigQuery em que seus dados estão localizados.
- Opcional: em Mostrar opções avançadas, insira o local de um bucket do Cloud Storage no projeto como um local temporário para seus dados.
Se não for especificado, um local padrão será usado. Caso seja especificado, os buckets do BigQuery e do Cloud Storage precisam estar na mesma região. - Se você não tiver a pesquisa ativada e estiver usando
o esquema do Merchant Center, selecione o nível do produto.
É necessário selecionar o nível do produto se esta for a primeira vez que você está importando o catálogo ou se estiver importando o catálogo novamente depois de limpá-lo. Saiba mais sobre os níveis de produto. Alterar os níveis de produto depois de importar todos os dados requer um esforço significativo.
Importante:não é possível ativar a pesquisa de projetos com um catálogo de produtos que foi ingerido como variantes. - Clique em Importar.
curl
Se esta for a primeira vez que você está carregando o catálogo ou se estiver importando o catálogo novamente após a limpeza, defina os níveis do produto usando o método
Catalog.patch. Essa operação requer o papel de Administrador de varejo.ingestionProductType: aceita os valoresprimary(padrão) evariant.merchantCenterProductIdField: tem suporte aos valoresofferIdeitemGroupId. Se você não usa o Merchant Center, não é necessário definir esse campo.
curl -X PATCH \ -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ --data '{ "productLevelConfig": { "ingestionProductType": "PRODUCT_TYPE", "merchantCenterProductIdField": "PRODUCT_ID_FIELD" } }' \ "https://retail.googleapis.com/v2/projects/PROJECT_ID/locations/global/catalogs/default_catalog"
Crie um arquivo de dados para os parâmetros de entrada para a importação.
Use o objeto BigQuerySource para apontar para o conjunto de dados do BigQuery.
- DATASET_ID: o ID do conjunto de dados do BigQuery.
- TABLE_ID: o ID da tabela do BigQuery que contém os dados.
- PROJECT_ID: o ID do projeto em que está a origem do BigQuery. Se não for especificado, o ID do projeto será herdado da solicitação principal.
- STAGING_DIRECTORY: opcional. Um diretório do Cloud Storage usado como um local temporário para seus dados antes de importá-los para o BigQuery. Deixe esse campo em branco para criar automaticamente um diretório temporário (recomendado).
- ERROR_DIRECTORY: opcional. Um diretório do Cloud Storage para informações de erros sobre a importação. Deixe esse campo em branco para criar automaticamente um diretório temporário (recomendado).
dataSchema: para a propriedadedataSchema, use o valorproduct(padrão). Você vai usar o esquema da AI Commerce Search.
Recomendamos que você não especifique diretórios de preparo ou erro para que um bucket do Cloud Storage com novos diretórios de preparo e erro seja criado automaticamente. Eles são criados na mesma região que o conjunto de dados do BigQuery e são exclusivos para cada importação, o que impede que vários jobs de importação organizem dados para o mesmo diretório e, possivelmente, reimportam os mesmos dados. de dados. Após três dias, o bucket e os diretórios são excluídos automaticamente para reduzir os custos de armazenamento.
Um nome de bucket criado automaticamente inclui o ID do projeto, a região do bucket e o nome do esquema de dados, separados por sublinhados (por exemplo,
4321_us_catalog_retail). Os diretórios criados automaticamente são chamados destagingouerrors, anexados por um número (por exemplo,staging2345ouerrors5678).Se você especificar diretórios, o bucket do Cloud Storage precisará estar na mesma região do conjunto de dados do BigQuery. Caso contrário, a importação falhará. Forneça os diretórios de preparo e erro no formato
gs://<bucket>/<folder>/. cada uma delas deve ser diferente.{ "inputConfig":{ "bigQuerySource": { "projectId":"PROJECT_ID", "datasetId":"DATASET_ID", "tableId":"TABLE_ID", "dataSchema":"product"} } }
Importe as informações do seu catálogo fazendo uma solicitação
POSTpara o método RESTProducts:import, fornecendo o nome do arquivo de dados (aqui, mostrado comoinput.json).curl -X POST \ -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" -d @./input.json \ "https://retail.googleapis.com/v2/projects/PROJECT_NUMBER/locations/global/catalogs/default_catalog/branches/0/products:import"
É possível verificar o status de maneira programática usando a API. Você receberá um objeto de resposta com esta aparência:
{ "name": "projects/PROJECT_ID/locations/global/catalogs/default_catalog/operations/import-products-123456", "done": false }
O campo de nome é o ID do objeto de operação. Para solicitar o status desse objeto, substitua o campo de nome pelo valor retornado pelo método
import, até o campodoneretornar comotrue:curl -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ "https://retail.googleapis.com/v2/projects/PROJECT_ID/locations/global/catalogs/default_catalog/operations/import-products-123456"
Quando a operação for concluída, o objeto retornado terá um valor
donedetruee incluirá um objeto Status semelhante ao exemplo a seguir:{ "name": "projects/PROJECT_ID/locations/global/catalogs/default_catalog/operations/import-products-123456", "metadata": { "@type": "type.googleapis.com/google.cloud.retail.v2.ImportMetadata", "createTime": "2020-01-01T03:33:33.000001Z", "updateTime": "2020-01-01T03:34:33.000001Z", "successCount": "2", "failureCount": "1" }, "done": true, "response": { "@type": "type.googleapis.com/google.cloud.retail.v2.ImportProductsResponse", }, "errorsConfig": { "gcsPrefix": "gs://error-bucket/error-directory" } }
Você pode inspecionar os arquivos no diretório de erros no Cloud Storage para ver se ocorreram erros durante a importação.
-
Acesse a página Dados no console da Pesquisa de comércio com IA no Gemini Enterprise for Customer Experience.
Configurar o acesso ao conjunto de dados do BigQuery
Para configurar o acesso quando o conjunto de dados do BigQuery estiver em um projeto diferente do serviço AI Commerce Search, conclua as etapas a seguir.
Abra a página do IAM no console Google Cloud .
Selecione seu projeto da AI Commerce Search.
Encontre a conta de serviço com o nome Agente de serviço de varejo.
Se você ainda não iniciou uma operação de importação, essa conta de serviço pode não estar listada. Se essa conta de serviço não aparecer, retorne à tarefa de importação e inicie a importação. Quando ela falhar devido a erros de permissão, volte aqui e conclua esta tarefa.
Copie o identificador da conta de serviço, que se parece com um endereço de e-mail (por exemplo,
service-525@gcp-sa-retail.iam.gserviceaccount.com).Alterne para seu projeto do BigQuery (na mesma página IAM e administrador) e clique em person_add Conceder acesso.
Em Novos principais, insira o identificador da conta de serviço do AI Commerce Search e selecione o papel BigQuery > Usuário do BigQuery.
Clique em Adicionar outro papel e selecione BigQuery > Editor de dados do BigQuery.
Se você não quiser fornecer o papel de editor de dados a todo o projeto, adicione esse papel diretamente ao conjunto de dados. Saiba mais.
Clique em Salvar.
Esquema de produto
Ao importar um catálogo do BigQuery, use o seguinte esquema de produto do AI Commerce Search para criar uma tabela do BigQuery com o formato correto e carregá-la com os dados do catálogo. Em seguida, importe o catálogo.
Importar dados de catálogo do Cloud Storage
Para importar dados do catálogo no formato JSON, crie um ou mais arquivos JSON que contenham os dados do catálogo que você quer importar e faça o upload deles para o Cloud Storage. A partir daí, você pode importar para o AI Commerce Search.
Para ver um exemplo do formato de item JSON do produto, consulte Formato de dados JSON do item do produto.
Para ajuda sobre o upload de arquivos para o Cloud Storage, consulte Fazer upload de objetos.
Verifique se a conta de serviço do AI Commerce Search tem permissão para ler e gravar no bucket.
A conta de serviço da Pesquisa de comércio com IA está listada na página do IAM no console do Google Cloud com o nome Agente de serviço de varejo. Use o identificador da conta de serviço, que se parece com um endereço de e-mail (por exemplo,
service-525@gcp-sa-retail.iam.gserviceaccount.com) ao adicionar a conta às permissões do bucket.Importe os dados do catálogo.
Console do Cloud
-
Acesse a página Dados no console da Pesquisa de comércio com IA no Gemini Enterprise for Customer Experience.
Acessar a página "Dados" - Clique em Importar para abrir o painel Importar dados.
- Escolha Catálogo de produtos como sua fonte de dados.
- Selecione a ramificação para fazer o upload do catálogo.
- Escolha Esquema de catálogos de produtos de varejo.
- Insira o local dos seus dados no Cloud Storage.
- Se você não tiver a pesquisa ativada, selecione os níveis de produto.
É necessário selecionar os níveis de produto se esta for a primeira vez que você está importando o catálogo ou se estiver importando o catálogo novamente depois de limpá-lo. Saiba mais sobre os níveis de produto. Alterar os níveis de produto depois de importar todos os dados requer um esforço significativo.
Importante:não é possível ativar a pesquisa de projetos com um catálogo de produtos que foi ingerido como variantes. - Clique em Importar.
curl
Se esta for a primeira vez que você está carregando o catálogo ou se estiver importando o catálogo novamente após a limpeza, defina os níveis do produto usando o método
Catalog.patch. Saiba mais sobre os níveis de produto.ingestionProductType: compatível com os valoresprimary(padrão) evariant.merchantCenterProductIdField: tem suporte aos valoresofferIdeitemGroupId. Se você não usa o Merchant Center, não é necessário definir esse campo.
curl -X PATCH \ -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ --data '{ "productLevelConfig": { "ingestionProductType": "PRODUCT_TYPE", "merchantCenterProductIdField": "PRODUCT_ID_FIELD" } }' \ "https://retail.googleapis.com/v2/projects/PROJECT_ID/locations/global/catalogs/default_catalog"
Crie um arquivo de dados para os parâmetros de entrada para a importação. Use o objeto
GcsSourcepara apontar para o bucket do Cloud Storage.É possível fornecer vários arquivos ou apenas um. este exemplo usa dois arquivos.
- INPUT_FILE: um ou mais arquivos no Cloud Storage que contêm os dados do catálogo.
- ERROR_DIRECTORY: um diretório do Cloud Storage para informações de erro sobre a importação.
Os campos do arquivo de entrada precisam estar no formato
gs://<bucket>/<path-to-file>/. O diretório de erro precisa estar no formatogs://<bucket>/<folder>/. Se o diretório de erros não existir, ele será criado. O bucket já precisa existir.{ "inputConfig":{ "gcsSource": { "inputUris": ["INPUT_FILE_1", "INPUT_FILE_2"] } }, "errorsConfig":{"gcsPrefix":"ERROR_DIRECTORY"} }
Importe as informações do seu catálogo fazendo uma solicitação
POSTpara o método RESTProducts:import, fornecendo o nome do arquivo de dados (aqui, mostrado comoinput.json).curl -X POST \ -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" -d @./input.json \ "https://retail.googleapis.com/v2/projects/PROJECT_NUMBER/locations/global/catalogs/default_catalog/branches/0/products:import"
A maneira mais fácil de verificar o status da operação de importação é usar o console Google Cloud . Para mais informações, consulte Como ver o status de uma operação de integração específica.
Também é possível verificar o status de maneira programática usando a API. Você receberá um objeto de resposta com esta aparência:
{ "name": "projects/PROJECT_ID/locations/global/catalogs/default_catalog/operations/import-products-123456", "done": false }
O campo de nome é o ID do objeto de operação. Solicite o status desse objeto e substitua o campo de nome pelo valor retornado pelo método de importação, até que o campo
doneretorne comotrue:curl -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ "https://retail.googleapis.com/v2/projects/PROJECT_ID/locations/global/catalogs/default_catalog/operations/[OPERATION_NAME]"
Quando a operação for concluída, o objeto retornado terá um valor
donedetruee incluirá um objeto Status semelhante ao seguinte exemplo:{ "name": "projects/PROJECT_ID/locations/global/catalogs/default_catalog/operations/import-products-123456", "metadata": { "@type": "type.googleapis.com/google.cloud.retail.v2.ImportMetadata", "createTime": "2020-01-01T03:33:33.000001Z", "updateTime": "2020-01-01T03:34:33.000001Z", "successCount": "2", "failureCount": "1" }, "done": true, "response": { "@type": "type.googleapis.com/google.cloud.retail.v2.ImportProductsResponse" }, "errorsConfig": { "gcsPrefix": "gs://error-bucket/error-directory" } }
É possível inspecionar os arquivos no diretório de erros no Cloud Storage para ver que tipo de erros ocorreu durante a importação.
-
Acesse a página Dados no console da Pesquisa de comércio com IA no Gemini Enterprise for Customer Experience.
Importar dados de catálogo in-line
curl
Importe as informações do seu catálogo inline. Para isso, faça uma solicitação POST ao método REST Products:import usando o objeto productInlineSource para especificar os dados do catálogo.
Forneça um produto inteiro em uma única linha. Cada produto precisa estar em uma linha.
Para ver um exemplo do formato de item JSON do produto, consulte Formato de dados JSON do item do produto.
Crie o arquivo JSON para seu produto e chame-o
./data.json:{ "inputConfig": { "productInlineSource": { "products": [ { PRODUCT_1 } { PRODUCT_2 } ] } } }Chame o método POST:
curl -X POST \ -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ --data @./data.json \ "https://retail.googleapis.com/v2/projects/PROJECT_NUMBER/locations/global/catalogs/default_catalog/branches/0/products:import"
Java
Formato de dados JSON do item do produto
As entradas Product no arquivo JSON devem ser semelhantes aos exemplos a seguir.
Forneça um produto inteiro em uma única linha. Cada produto precisa estar em uma linha.
Campos obrigatórios mínimos:
{
"id": "1234",
"categories": "Apparel & Accessories > Shoes",
"title": "ABC sneakers"
}
{
"id": "5839",
"categories": "casual attire > t-shirts",
"title": "Crew t-shirt"
}
Ver objeto completo
{ "name": "projects/PROJECT_NUMBER/locations/global/catalogs/default_catalog/branches/0/products/1234", "id": "1234", "categories": "Apparel & Accessories > Shoes", "title": "ABC sneakers", "description": "Sneakers for the rest of us", "attributes": { "vendor": {"text": ["vendor123", "vendor456"]} }, "language_code": "en", "tags": [ "black-friday" ], "priceInfo": { "currencyCode": "USD", "price":100, "originalPrice":200, "cost": 50 }, "availableTime": "2020-01-01T03:33:33.000001Z", "availableQuantity": "1", "uri":"http://example.com", "images": [ {"uri": "http://example.com/img1", "height": 320, "width": 320 } ] } { "name": "projects/PROJECT_NUMBER/locations/global/catalogs/default_catalog/branches/0/products/4567", "id": "4567", "categories": "casual attire > t-shirts", "title": "Crew t-shirt", "description": "A casual shirt for a casual day", "attributes": { "vendor": {"text": ["vendor789", "vendor321"]} }, "language_code": "en", "tags": [ "black-friday" ], "priceInfo": { "currencyCode": "USD", "price":50, "originalPrice":60, "cost": 40 }, "availableTime": "2020-02-01T04:44:44.000001Z", "availableQuantity": "2", "uri":"http://example.com", "images": [ {"uri": "http://example.com/img2", "height": 320, "width": 320 } ] }
Dados históricos do catálogo
AI Commerce Search oferece suporte para importação e gerenciamento de dados históricos de catálogo. Os dados históricos do catálogo podem ser úteis quando você usa eventos históricos do usuário para treinamento de modelo. Informações anteriores do produto podem ser usadas para enriquecer dados históricos de eventos do usuário e melhorar a precisão do modelo.
Os produtos históricos são armazenados como expirados. Elas não são retornadas em respostas de pesquisa, mas são visíveis para as chamadas de API Update, List e Delete.
Importar dados históricos de catálogo
Quando o campo expireTime de um produto é definido como um carimbo de data/hora no passado, esse produto é considerado como histórico. Defina a disponibilidade do produto como OUT_OF_STOCK para evitar que as recomendações sejam afetadas.
Recomendamos o uso dos seguintes métodos para importar dados históricos de catálogo:
- Chamando o método
Product.Create. - Importação inline de produtos expirados.
- Importação de produtos expirados do BigQuery.
Chame o método Product.Create
Use o método Product.Create para criar uma entrada Product
com o campo expireTime definido para um carimbo de data/hora no passado.
Produtos importados expirados
As etapas são idênticas às da importação in-line, exceto pelo fato de os produtos
precisarem ter os campos expireTime definidos como um carimbo de data/hora
passado.
Forneça um produto inteiro em uma única linha. Cada produto precisa estar em uma linha.
Um exemplo do ./data.json usado na solicitação de importação in-line:
Confira este exemplo usado na solicitação de importação inline
{
"inputConfig": {
"productInlineSource": {
"products": [
{
"id": "historical_product_001",
"categories": "Apparel & Accessories > Shoes",
"title": "ABC sneakers",
"expire_time": {
"second": "2021-10-02T15:01:23Z" // a past timestamp
}
},
{
"id": "historical product 002",
"categories": "casual attire > t-shirts",
"title": "Crew t-shirt",
"expire_time": {
"second": "2021-10-02T15:01:24Z" // a past timestamp
}
}
]
}
}
}
Importar produtos expirados do BigQuery ou do Cloud Storage
Use os mesmos procedimentos documentados para importar dados do catálogo do BigQuery ou importar dados do catálogo do Cloud Storage. No entanto, defina o campo expireTime como um carimbo de data/hora no passado.
Mantenha seu catálogo atualizado
Para melhores resultados, seu catálogo precisa ter informações atualizadas. Recomendamos importar o catálogo diariamente para garantir que ele esteja atualizado. Use o Google Cloud Scheduler para programar importações ou escolha uma opção de programação automática ao importar dados usando o consoleGoogle Cloud .
É possível atualizar apenas itens de produtos novos ou alterados ou importar todo o catálogo. Se você importar produtos que já estão no seu catálogo, eles não serão adicionados novamente. Todos os itens que foram alterados serão atualizados.
Para atualizar um único item, consulte Atualizar informações do produto.
Atualização em lote
Você pode usar o método de importação para atualizar seu catálogo em lote. Isso é feito da mesma maneira que a importação inicial; siga as etapas em Importar dados de catálogo.
Monitorar a integridade da importação
Para monitorar a ingestão e a integridade do catálogo:
Confira informações agregadas sobre seu catálogo e visualize os produtos enviados na guia Catálogo da página Dados do AI Commerce Search no Gemini Enterprise for Customer Experience.
Avalie se é necessário atualizar os dados do catálogo para melhorar a qualidade dos resultados da pesquisa e desbloquear os níveis de performance de pesquisa na página Qualidade de dados.
Para saber mais sobre como verificar a qualidade de dados de pesquisa e conferir os níveis de desempenho da pesquisa, consulte Desbloquear níveis de desempenho da pesquisa. Para um resumo das métricas de catálogo disponíveis nesta página, consulte Métricas de qualidade do catálogo.
Para criar alertas que informam se algo der errado com seus uploads de dados, siga os procedimentos em Configurar alertas do Cloud Monitoring.
É importante manter seu catálogo atualizado para conseguir resultados de alta qualidade. Use alertas para monitorar as taxas de erro de importação e tome as medidas necessárias.
A seguir
- Comece a gravar eventos de usuários.
- Veja informações agregadas sobre seu catálogo.
- Configure alertas de upload de dados.