
系統會將每部正面電影評分 (評分 >= 4) 視為產品頁面瀏覽事件。我們將訓練「你可能也會喜歡」類型的推薦模型,根據資料集中的任何使用者或種子電影推薦電影。
預計所需時間:
- 開始訓練模型的初始步驟:約 1.5 小時。
- 等待模型訓練:約 2 天。
- 評估模型預測結果及清除所用資源:約 30 分鐘。
目標
- 瞭解如何將 BigQuery 中的產品和使用者事件資料匯入 AI Commerce Search。
- 訓練及評估推薦模型。
費用
本教學課程使用 Google Cloud的計費元件,包括:- Cloud Storage
- BigQuery
- AI Commerce Search
如要進一步瞭解 Cloud Storage 費用,請參閱 Cloud Storage 定價頁面。
如要進一步瞭解 BigQuery 費用,請參閱 BigQuery 定價頁面。
如要進一步瞭解 AI 商業搜尋費用,請參閱 AI 商業搜尋定價頁面。
事前準備
- 登入 Google Cloud 帳戶。如果您是 Google Cloud新手,歡迎 建立帳戶,親自評估產品在實際工作環境中的成效。新客戶還能獲得價值 $300 美元的免費抵免額,可用於執行、測試及部署工作負載。
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
準備資料集
開啟 Google Cloud 控制台,然後選取 Google Cloud 專案。記下資訊主頁「專案資訊」資訊卡中的專案 ID。後續步驟會用到專案 ID。接著,按一下控制台頂端的「啟用 Cloud Shell」按鈕。

系統會在主控台底部的新頁框中開啟 Cloud Shell 工作階段,並顯示指令列提示。 Google Cloud
匯入資料集
使用 Cloud Shell 下載並解壓縮來源資料集:
wget https://files.grouplens.org/datasets/movielens/ml-latest.zip unzip ml-latest.zip建立 Cloud Storage bucket,並將資料上傳至該 bucket:
gcloud storage buckets create gs://PROJECT_ID-movielens-data gcloud storage cp ml-latest/movies.csv ml-latest/ratings.csv \ gs://PROJECT_ID-movielens-data建立 BigQuery 資料集
bq mk movielens將
movies.csv載入新的電影 BigQuery 資料表:bq load --skip_leading_rows=1 movielens.movies \ gs://PROJECT_ID-movielens-data/movies.csv \ movieId:integer,title,genres將
ratings.csv載入新的評分 BigQuery 資料表:bq load --skip_leading_rows=1 movielens.ratings \ gs://PROJECT_ID-movielens-data/ratings.csv \ userId:integer,movieId:integer,rating:float,time:timestamp
建立 BigQuery 檢視表
建立檢視表,將電影資料表轉換為零售產品目錄結構定義:
bq mk --project_id=PROJECT_ID \ --use_legacy_sql=false \ --view ' SELECT CAST(movieId AS string) AS id, SUBSTR(title, 0, 128) AS title, SPLIT(genres, "|") AS categories FROM `PROJECT_ID.movielens.movies`' \ movielens.products現在新的檢視畫面已採用 AI Commerce Search 預期的結構定義。接著,從左側邊欄選擇
BIG DATA -> BigQuery。接著,從左側的 Explorer 列展開專案名稱,然後選取movielens -> products開啟這個 view 的查詢頁面。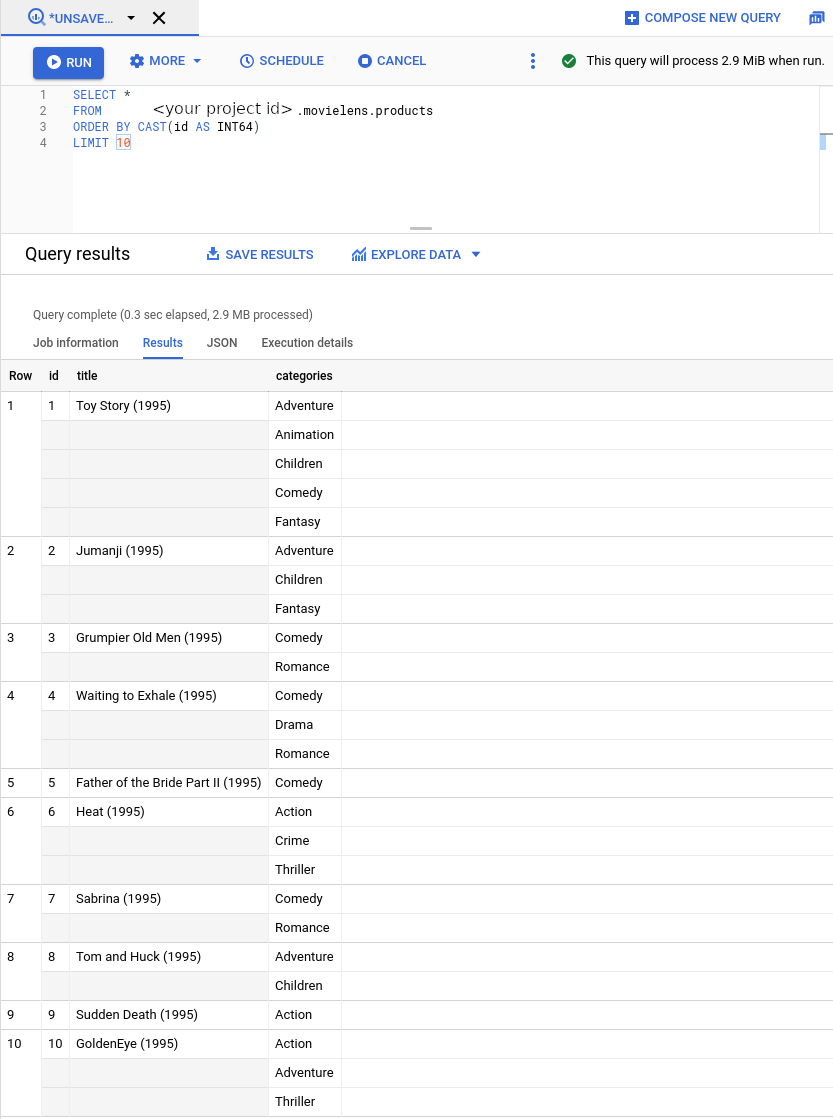
現在請將電影評分轉換為使用者事件。我們會:
- 忽略負面電影評分 (低於 4 分)
- 將每個正面評價視為產品頁面瀏覽事件
(
detail-page-view) - 將 Movielens 時間軸重新縮放為過去 90 天。我們這麼做有兩個原因:
- AI Commerce Search 規定使用者事件不得早於 2015 年。Movielens 評分資料可追溯至 1995 年。
- AI Commerce Search 在為使用者提供預測要求時,會使用過去 90 天的使用者事件。日後為任何使用者進行預測時,每位使用者都會顯示近期事件。
建立 BigQuery 檢視表。下列指令會使用符合先前列出轉換需求的 SQL 查詢。
bq mk --project_id=PROJECT_ID \ --use_legacy_sql=false \ --view ' WITH t AS ( SELECT MIN(UNIX_SECONDS(time)) AS old_start, MAX(UNIX_SECONDS(time)) AS old_end, UNIX_SECONDS(TIMESTAMP_SUB( CURRENT_TIMESTAMP(), INTERVAL 90 DAY)) AS new_start, UNIX_SECONDS(CURRENT_TIMESTAMP()) AS new_end FROM `PROJECT_ID.movielens.ratings`) SELECT CAST(userId AS STRING) AS visitorId, "detail-page-view" AS eventType, FORMAT_TIMESTAMP( "%Y-%m-%dT%X%Ez", TIMESTAMP_SECONDS(CAST( (t.new_start + (UNIX_SECONDS(time) - t.old_start) * (t.new_end - t.new_start) / (t.old_end - t.old_start)) AS int64))) AS eventTime, [STRUCT(STRUCT(movieId AS id) AS product)] AS productDetails, FROM `PROJECT_ID.movielens.ratings`, t WHERE rating >= 4' \ movielens.user_events
匯入產品目錄和使用者事件
現在可以將產品目錄和使用者事件資料匯入 AI Commerce Search。
為 Google Cloud 專案啟用 AI Commerce Search API。
按一下「開始使用」。
前往 Gemini Enterprise for Customer Experience 控制台的 AI Commerce Search「資料」頁面。
前往「資料」頁面按一下「匯入」。
匯入產品目錄
填寫表單,從先前建立的 BigQuery 檢視區塊匯入產品:
- 選取匯入類型:產品目錄。
- 選取預設分支版本名稱。
- 選取資料來源:BigQuery。
- 選取資料架構:零售產品架構。
輸入先前建立的產品 BigQuery 檢視區塊名稱 (
PROJECT_ID.movielens.products)。
按一下「匯入」。
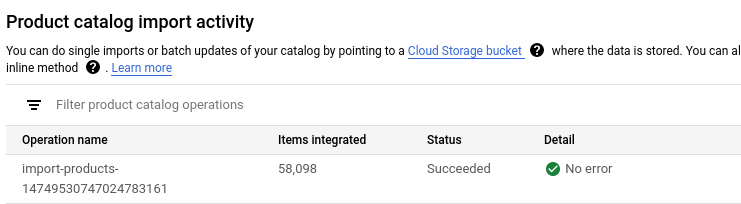
等待所有產品匯入完成,大約需要 5 到 10 分鐘。
您可以透過「匯入活動」查看匯入作業狀態。匯入完成後,匯入作業狀態會變更為「Succeeded」(已成功)。
匯入使用者事件
匯入 user_events BigQuery 檢視畫面:
- 選取匯入類型:使用者事件。
- 選取資料來源:BigQuery。
- 選取資料結構定義:零售使用者事件結構定義。
- 輸入您先前建立的
user_eventsBigQuery 檢視表名稱。
按一下「匯入」。
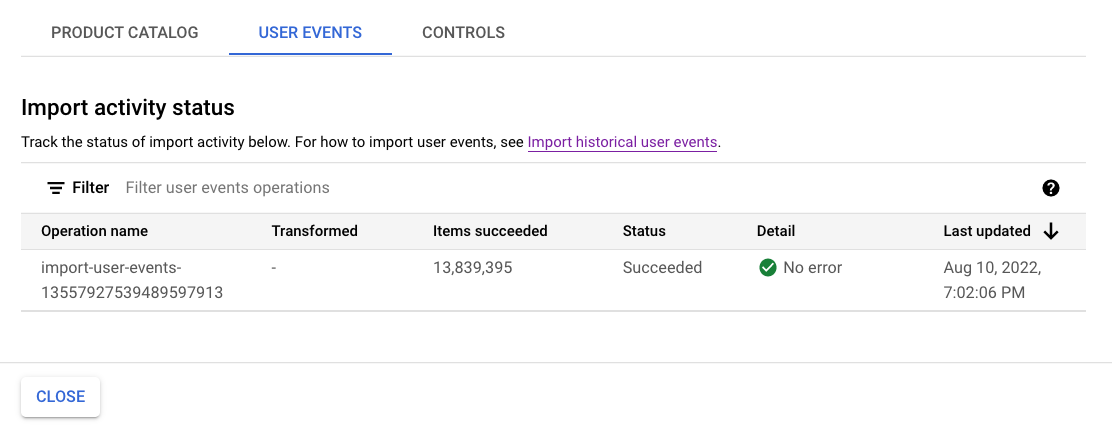
請等到至少匯入一百萬個事件後再繼續下一個步驟,以便符合訓練新模型的資料要求。
您可以查看匯入活動,瞭解作業狀態。這項程序大約需要一小時才能完成。
訓練及評估推薦模型
請按照這些說明訓練及評估推薦模型。
建立推薦模型
前往 Gemini Enterprise for Customer Experience 控制台的 AI Commerce Search「模型」頁面。
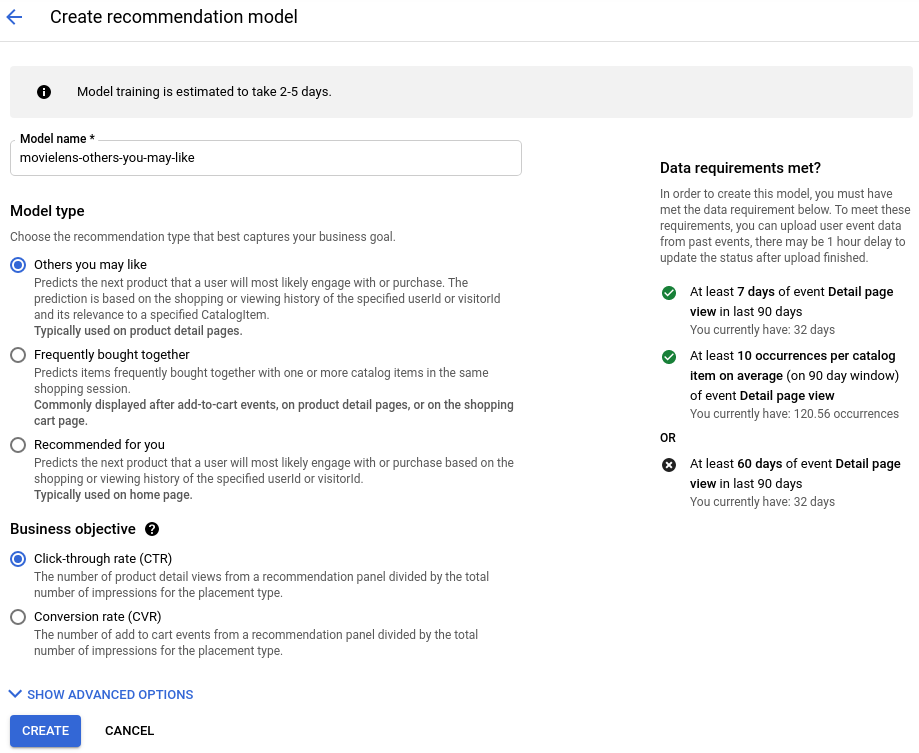
前往「模型」頁面按一下「建立模型」:
- 為模型命名。
- 選取「Others you may like」(您可能會喜歡的其他項目) 做為模型類型。
- 選擇「點閱率 (CTR)」做為業務目標。
點選「建立」。
新模型開始訓練。
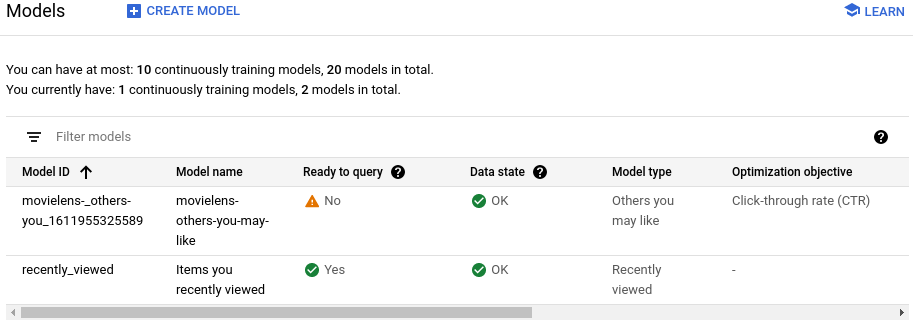
建立供應設定
前往 Gemini Enterprise for Customer Experience 控制台的 AI Commerce Search「Serving Configs」頁面。
前往「Serving configs」(放送設定) 頁面按一下「建立供應設定」:
- 選取「建議」。
- 為供應設定命名。
- 選取您建立的模式。
點選「建立」。
等待模型「準備好查詢」
模型約需兩天才能完成訓練並準備好接受查詢。
如要查看狀態,請在「供應設定」頁面中,按一下已建立的供應設定。
程序完成時,「Model ready to query」(模型可接受查詢) 欄位會顯示「Yes」(是)。
預覽建議內容
模型準備好查詢後,請執行以下操作:
-
前往 Gemini Enterprise for Customer Experience 控制台的 AI Commerce Search「Serving Configs」頁面。
前往「Serving configs」(放送設定) 頁面 - 按一下供應設定名稱,前往詳細資料頁面。
- 按一下「Evaluate」(評估) 分頁標籤。
輸入種子電影 ID,例如
4993可以代表「魔戒首部曲:魔戒現身 (2001)」。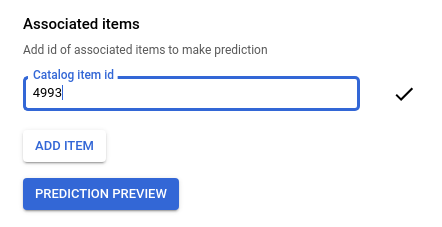
按一下「預測預覽」,即可在頁面右側查看建議項目清單。
清除所用資源
為避免因為本教學課程所用資源,導致系統向 Google Cloud 收取費用,請刪除含有相關資源的專案,或者保留專案但刪除個別資源。
刪除專案
- 前往 Google Cloud 控制台的「Manage resources」(管理資源) 頁面。
- 在專案清單中選取要刪除的專案,然後點選「Delete」(刪除)。
- 在對話方塊中輸入專案 ID,然後按一下 [Shut down] (關閉) 以刪除專案。
刪除個別資源
前往「供應設定」頁面,然後刪除您建立的供應設定。
前往「Models」(模型) 頁面,然後刪除模型。
在 Cloud Shell 中刪除 BigQuery 資料集:
bq rm --recursive --dataset movielens刪除 Cloud Storage bucket 和當中內容:
gcloud storage rm gs://PROJECT_ID-movielens-data --recursive