
לפני שמתחילים
אם עדיין לא עשיתם זאת, מגדירים Google Cloud פרויקט ושתי קטגוריות של Cloud Storage (2).
הגדרת הפרויקט
- נכנסים לחשבון Google Cloud . אם אתם משתמשים חדשים ב- Google Cloud, צרו חשבון כדי שתוכלו להעריך את הביצועים של המוצרים שלנו בתרחישים מהעולם האמיתי. לקוחות חדשים מקבלים בחינם גם קרדיט בשווי 300$ להרצה, לבדיקה ולפריסה של עומסי העבודה.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, Cloud Storage, and Cloud Run functions APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
התקינו את ה-CLI של Google Cloud.
-
אם אתם משתמשים בספק זהויות חיצוני (IdP), קודם אתם צריכים להיכנס ל-CLI של gcloud באמצעות המאגר המאוחד לניהול זהויות.
-
כדי לאתחל את ה-CLI של gcloud, הריצו את הפקודה הבאה:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, Cloud Storage, and Cloud Run functions APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
התקינו את ה-CLI של Google Cloud.
-
אם אתם משתמשים בספק זהויות חיצוני (IdP), קודם אתם צריכים להיכנס ל-CLI של gcloud באמצעות המאגר המאוחד לניהול זהויות.
-
כדי לאתחל את ה-CLI של gcloud, הריצו את הפקודה הבאה:
gcloud init
יצירה של שתי קטגוריות של Cloud Storage בפרויקט או שימוש בשתי קטגוריות קיימות
תצטרכו שתי קטגוריות של Cloud Storage בפרויקט: אחת לקובצי קלט ואחת לקובצי פלט.
- במסוף Google Cloud , נכנסים לדף Buckets של Cloud Storage.
- לוחצים על יצירה.
- ממלאים את פרטי הקטגוריה בדף Create a bucket. כדי לעבור לשלב הבא לוחצים על Continue.
-
בקטע Get started (תחילת העבודה), מבצעים את הפעולות הבאות:
- מזינים שם ייחודי בהיקף גלובלי שעומד בקריטריונים לשמות של קטגוריות.
- כדי להוסיף תווית לדלי, מרחיבים את הקטע Labels (תוויות) (), לוחצים על add_box
Add label (הוספת תווית) ומציינים
keyו-valueבשביל התווית.
-
בקטע Choose where to store your data, מבצעים את הפעולות הבאות:
- בוחרים סוג מיקום.
- בתפריט הנפתח Location type, בוחרים מיקום שבו יישמרו נתוני הקטגוריה באופן קבוע.
- אם בוחרים את סוג המיקום בשני אזורים, אפשר גם להפעיל רפליקציה בקצב טורבו באמצעות תיבת הסימון הרלוונטית.
- כדי להגדיר שכפול בין מאגרי מידע, בוחרים באפשרות הוספת שכפול בין מאגרי מידע באמצעות Storage Transfer Service ופועלים לפי השלבים הבאים:
הגדרה של רפליקציה בין דליים
- בתפריט Bucket, בוחרים באפשרות הרצויה.
בקטע הגדרות השכפול, לוחצים על הגדרה כדי להגדיר את ההגדרות של משימת השכפול.
מופיעה החלונית Configure cross-bucket replication.
- כדי לסנן אובייקטים לשכפול לפי קידומת של שם האובייקט, מזינים קידומת שרוצים לכלול או להחריג אובייקטים ממנה, ואז לוחצים על הוספת קידומת.
- כדי להגדיר סוג אחסון לאובייקטים המשוכפלים, בוחרים סוג אחסון בתפריט סוג אחסון. אם מדלגים על השלב הזה, האובייקטים המשוכפלים ישתמשו בסוג האחסון של קטגוריית היעד כברירת מחדל.
- לוחצים על סיום.
-
בקטע Choose how to store your data, מבצעים את הפעולות הבאות:
- בוחרים default storage class לקטגוריה או Autoclass לניהול אוטומטי של סוג האחסון (storage class) של נתוני הקטגוריה.
- כדי להפעיל מרחב שמות היררכי, בקטע Optimize storage for data-intensive workloads, בוחרים באפשרות Enable hierarchical namespace on this bucket.
- בקטע Choose how to control access to objects, בוחרים אם הקטגוריה אוכפת public access prevention או לא, ואז בוחרים שיטת בקרת גישה לאובייקטים של הקטגוריה.
-
בקטע Choose how to protect object data, מבצעים את הפעולות הבאות:
- בוחרים באחת מהאפשרויות בקטע הגנה על נתונים שרוצים להגדיר לקטגוריה.
- כדי להפעיל מחיקה עם אפשרות שחזור, מסמנים את התיבה Soft delete policy (For data recovery) ומציינים את מספר הימים שבהם רוצים לשמור אובייקטים אחרי המחיקה.
- כדי להגדיר ניהול גרסאות של אובייקטים, מסמנים את התיבה ניהול גרסאות של אובייקטים (לשליטה בגרסאות) ומציינים את מספר הגרסאות המקסימלי לכל אובייקט ואת מספר הימים שאחריהם הגרסאות הלא עדכניות יפוגו.
- כדי להפעיל את מדיניות שמירת הנתונים על אובייקטים וקטגוריות, לוחצים על תיבת הסימון שמירת נתונים (לצורך תאימות), ואז מבצעים את הפעולות הבאות:
- כדי להפעיל את הנעילה של שמירת אובייקטים, מסמנים את התיבה הפעלת שמירת אובייקטים.
- כדי להפעיל את נעילת הקטגוריה, מסמנים את תיבת הסימון הגדרת מדיניות שמירת נתונים בקטגוריה ובוחרים יחידת זמן ואת משך הזמן של תקופת השמירה.
- כדי לבחור איך להצפין את נתוני האובייקט, מרחיבים את הקטע Data encryption () ובוחרים Data encryption method.
- בוחרים באחת מהאפשרויות בקטע הגנה על נתונים שרוצים להגדיר לקטגוריה.
-
בקטע Get started (תחילת העבודה), מבצעים את הפעולות הבאות:
- לוחצים על יצירה.
יצירת תבנית של תהליך עבודה
כדי ליצור ולהגדיר תבנית של תהליך עבודה, מעתיקים ומריצים את הפקודות הבאות בחלון טרמינל מקומי או ב-Cloud Shell.
- יוצרים את תבנית תהליך העבודה.
gcloud dataproc workflow-templates create wordcount-template \ --region=us-central1
- מוסיפים את משימת ספירת המילים לתבנית של תהליך העבודה.
-
מציינים את output-bucket-name לפני שמריצים את הפקודה (הפונקציה תספק את דלי הקלט).
אחרי שמזינים את שם דלי הפלט, ארגומנט דלי הפלט צריך להיראות כך:
gs://your-output-bucket/wordcount-output". -
חובה לציין את מזהה השלב count, שמזהה את משימת ה-Hadoop שנוספה.
gcloud dataproc workflow-templates add-job hadoop \ --workflow-template=wordcount-template \ --step-id=count \ --jar=file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar \ --region=us-central1 \ -- wordcount gs://input-bucket gs://output-bucket-name/wordcount-output
-
מציינים את output-bucket-name לפני שמריצים את הפקודה (הפונקציה תספק את דלי הקלט).
אחרי שמזינים את שם דלי הפלט, ארגומנט דלי הפלט צריך להיראות כך:
- כדי להפעיל את תהליך העבודה, צריך להשתמש באשכול מנוהל עם צומת יחיד. Managed Service for Apache Spark ייצור את האשכול, יפעיל בו את תהליך העבודה ואז ימחק את האשכול כשתהליך העבודה יסתיים.
gcloud dataproc workflow-templates set-managed-cluster wordcount-template \ --cluster-name=wordcount \ --single-node \ --region=us-central1 - לוחצים על השם של
wordcount-templateבדף Workflows של Managed Service for Apache Spark במסוף Google Cloud כדי לפתוח את הדף Workflow template details. מאשרים את המאפיינים של wordcount-template.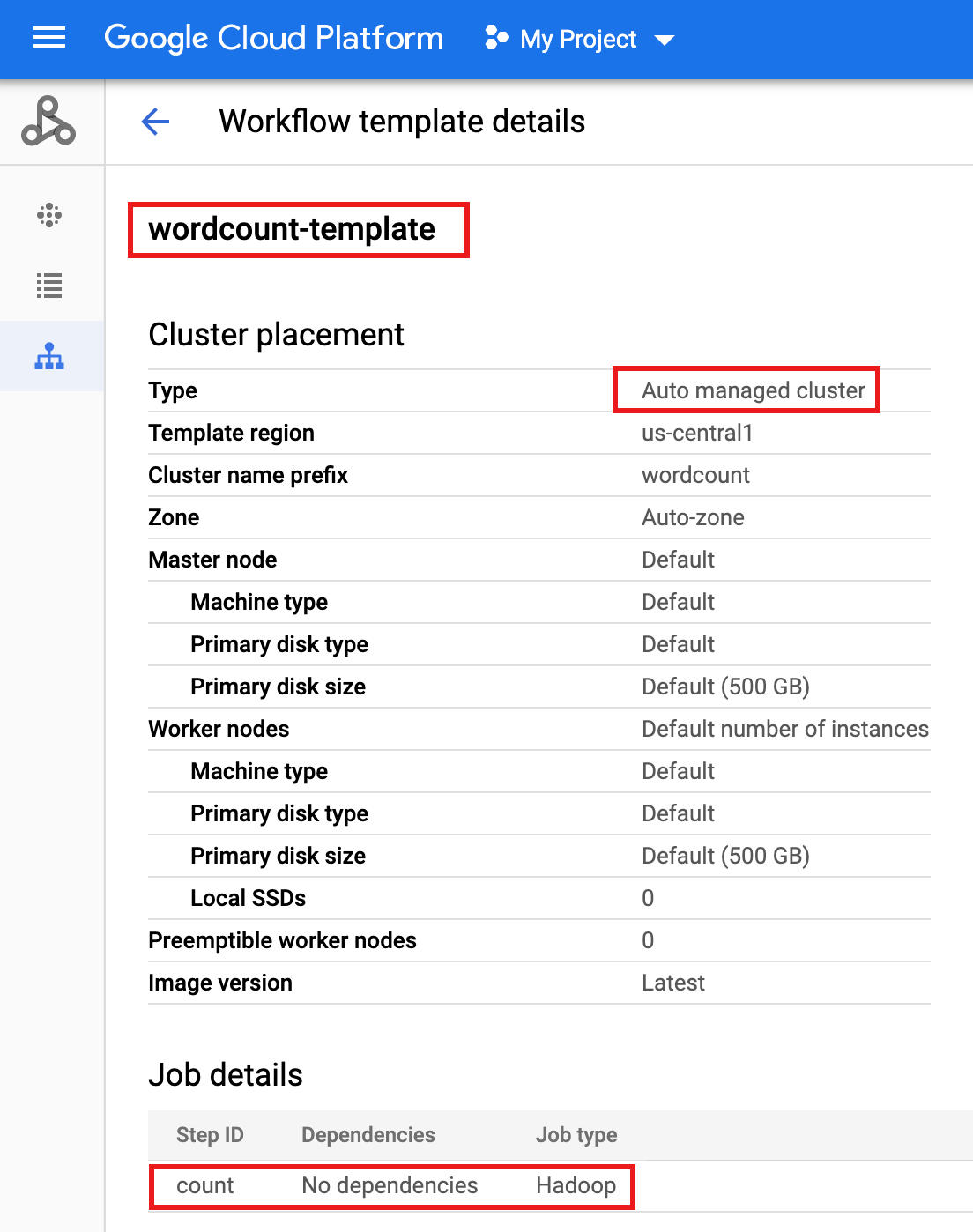
הגדרת פרמטרים בתבנית של תהליך העבודה
הגדרת פרמטרים למשתנה של דלי הקלט כדי להעביר אותו לתבנית של תהליך העבודה.
- מייצאים את תבנית זרימת העבודה לקובץ טקסט
wordcount.yamlכדי להגדיר פרמטרים.gcloud dataproc workflow-templates export wordcount-template \ --destination=wordcount.yaml \ --region=us-central1
- באמצעות עורך טקסט, פותחים את
wordcount.yaml, ואז מוסיפים בלוקparametersבסוף קובץ ה-YAML כדי שאפשר יהיה להעביר את Cloud Storage INPUT_BUCKET_URI בתורargs[1]לקובץ הבינארי wordcount כשמופעל תהליך העבודה.בהמשך מוצג קובץ YAML לדוגמה שיוצא. יש שתי דרכים לעדכן את התבנית:
- מעתיקים את כל הקובץ ומדביקים אותו כדי להחליף את קובץ
wordcount.yamlהמיוצא אחרי שמחליפים את your-output_bucket בשם של קטגוריית הפלט, או - מעתיקים רק את הקטע
parametersומדביקים אותו בסוף קובץwordcount.yamlשייצאתם.
jobs: - hadoopJob: args: - wordcount - gs://input-bucket - gs://your-output-bucket/wordcount-output mainJarFileUri: file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar stepId: count placement: managedCluster: clusterName: wordcount config: softwareConfig: properties: dataproc:dataproc.allow.zero.workers: 'true' parameters: - name: INPUT_BUCKET_URI description: wordcount input bucket URI fields: - jobs['count'].hadoopJob.args[1] - מעתיקים את כל הקובץ ומדביקים אותו כדי להחליף את קובץ
- מייבאים את קובץ הטקסט
wordcount.yamlעם הפרמטרים. מקלידים 'Y'es כשמוצגת בקשה להחלפת התבנית.gcloud dataproc workflow-templates import wordcount-template \ --source=wordcount.yaml \ --region=us-central1
יצירת פונקציה של Cloud Functions
פותחים את הדף Cloud Run functions במסוףGoogle Cloud ולוחצים על CREATE FUNCTION (יצירת פונקציה).
בדף Create function מזינים או בוחרים את הפרטים הבאים:
- שם: wordcount
- הזיכרון שהוקצה: משאירים את ברירת המחדל.
- טריגר:
- Cloud Storage
- סוג האירוע: סיום/יצירה
- קטגוריה: בוחרים את קטגוריית הקלט (ראו יצירת קטגוריה של Cloud Storage בפרויקט). כשמוסיפים קובץ לקטגוריה הזו, הפונקציה מפעילה את תהליך העבודה. תהליך העבודה יפעיל את אפליקציית ספירת המילים, שתעבד את כל קובצי הטקסט בדלי.
קוד מקור:
- עורך במקום
- זמן ריצה: Node.js 8
- בכרטיסייה
INDEX.JS: מחליפים את קטע הקוד שמוגדר כברירת מחדל בקוד הבא, ואז עורכים את השורהconst projectIdכדי לספק את -your-project-id- (בלי מקף '-' בתחילת או בסוף המחרוזת).
const dataproc = require('@google-cloud/dataproc').v1; exports.startWorkflow = (data) => { const projectId = '-your-project-id-' const region = 'us-central1' const workflowTemplate = 'wordcount-template' const client = new dataproc.WorkflowTemplateServiceClient({ apiEndpoint: `${region}-dataproc.googleapis.com`, }); const file = data; console.log("Event: ", file); const inputBucketUri = `gs://${file.bucket}/${file.name}`; const request = { name: client.projectRegionWorkflowTemplatePath(projectId, region, workflowTemplate), parameters: {"INPUT_BUCKET_URI": inputBucketUri} }; client.instantiateWorkflowTemplate(request) .then(responses => { console.log("Launched Dataproc Workflow:", responses[1]); }) .catch(err => { console.error(err); }); };- בכרטיסייה
PACKAGE.JSON: מחליפים את קטע הקוד שמוגדר כברירת מחדל בקוד הבא.
{ "name": "dataproc-workflow", "version": "1.0.0", "dependencies":{ "@google-cloud/dataproc": ">=1.0.0"} }- הפונקציה לביצוע: מזינים: startWorkflow.
לוחצים על 'יצירה'.
בדיקת הפונקציה
מעתיקים את הקובץ הציבורי
rose.txtלקטגוריה כדי להפעיל את הפונקציה. מזינים את your-input-bucket-name (הקטגוריה שמשמשת להפעלת הפונקציה) בפקודה.gcloud storage cp gs://pub/shakespeare/rose.txt gs://your-input-bucket-name
ממתינים 30 שניות, ואז מריצים את הפקודה הבאה כדי לוודא שהפונקציה הסתיימה בהצלחה.
gcloud functions logs read wordcount
... Function execution took 1348 ms, finished with status: 'ok'
כדי לצפות ביומני הפונקציה מהדף Functions ברשימה במסוף Google Cloud , לוחצים על שם הפונקציה
wordcountואז על VIEW LOGS בדף Function details.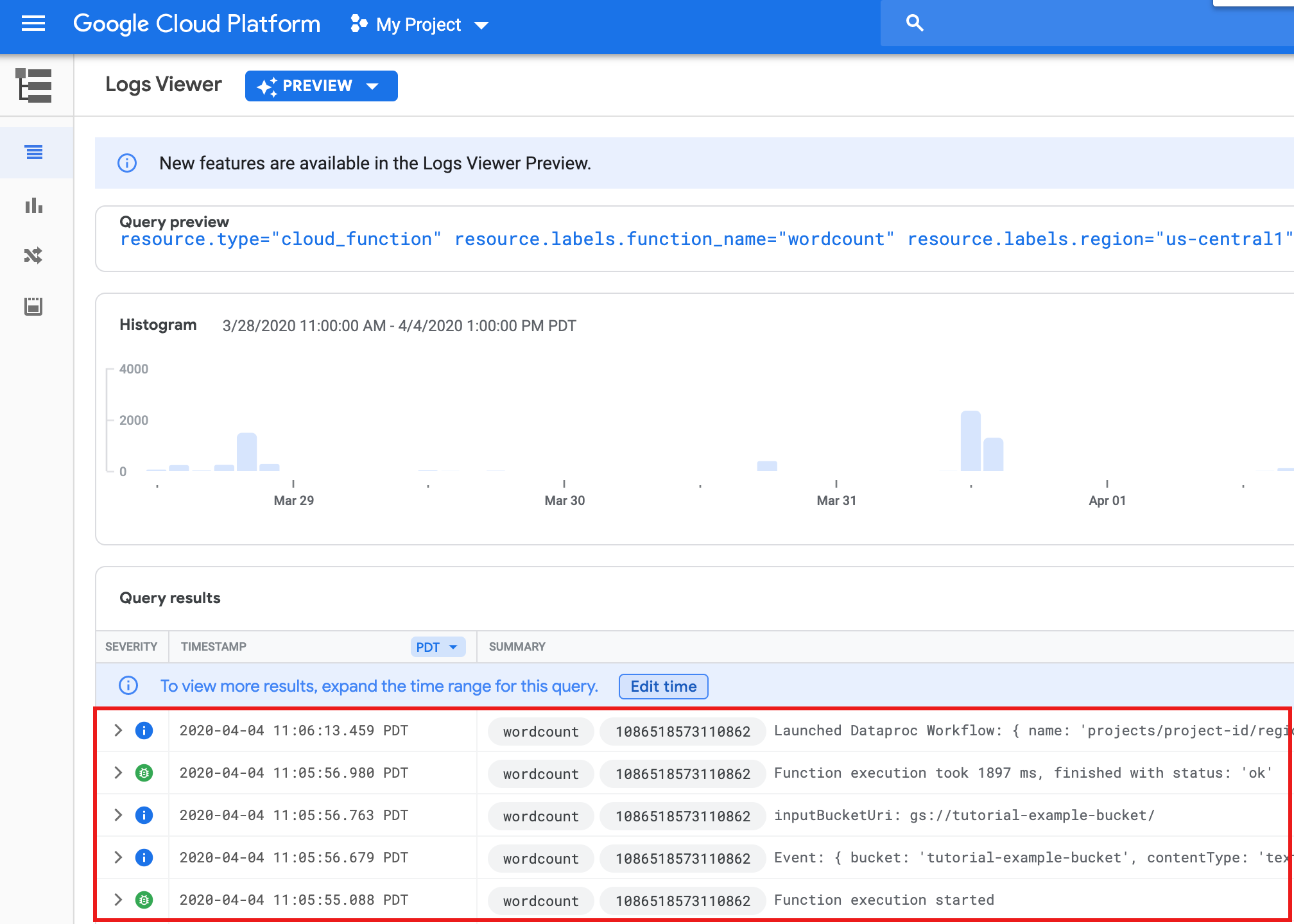
אפשר לראות את התיקייה
wordcount-outputבדלי הפלט בדף Storage browser במסוףGoogle Cloud .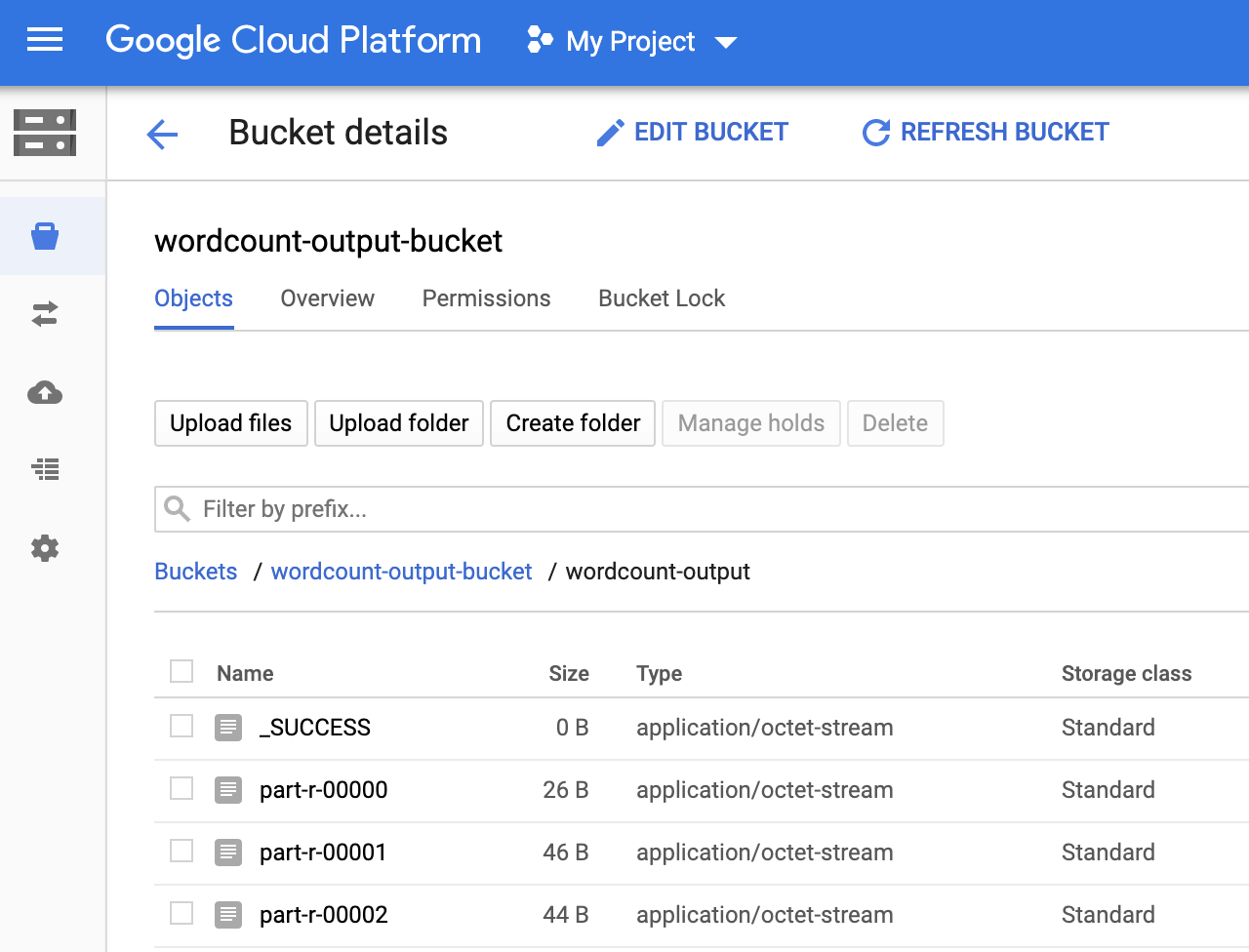
אחרי שהתהליך מסתיים, פרטי המשימה נשמרים בGoogle Cloud מסוף. לוחצים על המשימה
count...שמופיעה בדף משימות של Managed Service for Apache Spark כדי לראות את פרטי המשימה של תהליך העבודה.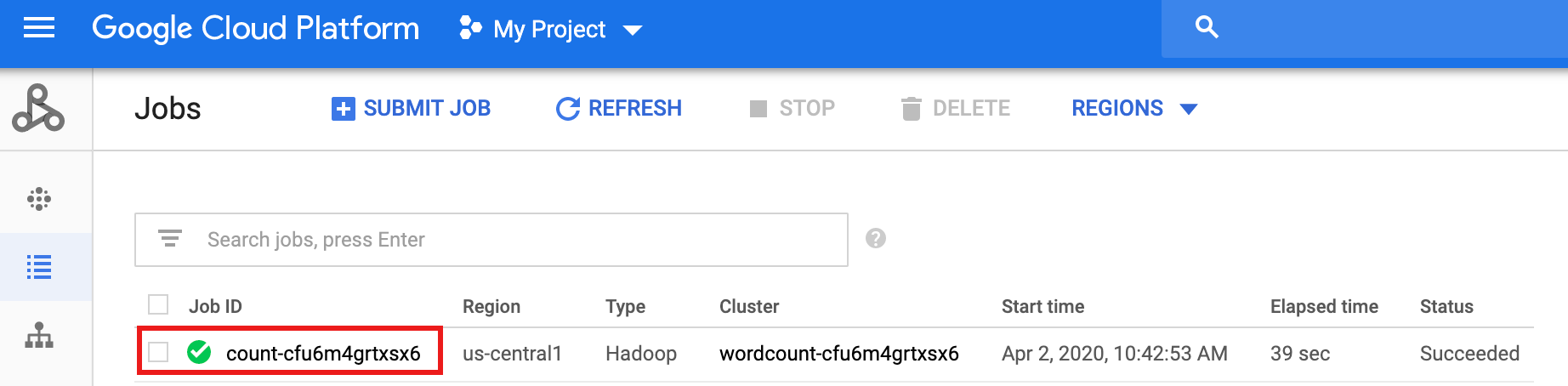
הסרת המשאבים
תהליך העבודה במדריך הזה מוחק את האשכול המנוהל שלו כשהוא מסתיים. כדי להימנע מעלויות חוזרות, אפשר למחוק משאבים אחרים שמשויכים למדריך הזה.
מחיקת פרויקטים
- במסוף Google Cloud , נכנסים לדף Manage resources.
- ברשימת הפרויקטים, בוחרים את הפרויקט שרוצים למחוק ולוחצים על Delete.
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.
מחיקת קטגוריות של Cloud Storage
- במסוף Google Cloud , נכנסים לדף Buckets של Cloud Storage.
- לוחצים על תיבת הסימון של הקטגוריה שרוצים למחוק.
- כדי למחוק את הקטגוריה, לוחצים על Delete ופועלים לפי ההוראות.
מחיקת תבנית של תהליך עבודה
gcloud dataproc workflow-templates delete wordcount-template \ --region=us-central1
מחיקת הפונקציה של Cloud Functions
פותחים את הדף Cloud Run functions במסוף Google Cloud , מסמנים את התיבה שמימין לפונקציה wordcount ולוחצים על Delete (מחיקה).