
Trino (לשעבר Presto) הוא מנוע מבוזר לשאילתות SQL שנועד להריץ שאילתות על מערכי נתונים גדולים שמפוזרים על פני מקורות נתונים הטרוגניים. Trino יכול לשלוח שאילתות ל-Hive, ל-MySQL, ל-Kafka ולמקורות נתונים אחרים באמצעות מחברים. המדריך הזה מסביר איך:
- התקנה של שירות Trino באשכול Managed Service for Apache Spark
- שאילתת נתונים ציבוריים מלקוח Trino שמותקן במחשב המקומי ומתקשר עם שירות Trino באשכול
- הפעלת שאילתות מאפליקציית Java שמתקשרת עם שירות Trino באשכול באמצעות מנהל ההתקן Trino Java JDBC.
מטרות
- שליפת הנתונים מ-BigQuery
- טוענים את הנתונים ל-Cloud Storage כקובצי CSV
- שינוי נתונים:
- חשיפת הנתונים כטבלה חיצונית של Hive כדי לאפשר ל-Trino לבצע שאילתות על הנתונים
- המרת הנתונים מפורמט CSV לפורמט Parquet כדי להאיץ את השאילתות
עלויות
במסמך הזה משתמשים ברכיבים הבאים של Google Cloud, והשימוש בהם כרוך בתשלום:
כדי להעריך את ההוצאות בהתאם לתחזית השימוש שלכם, אתם יכולים להיעזר במחשבון העלויות.
לפני שמתחילים
אם עדיין לא עשיתם את זה, צרו Google Cloud פרויקט וקטגוריה ב-Cloud Storage כדי לאחסן את הנתונים שמשמשים במדריך הזה. 1. הגדרת הפרויקט- נכנסים לחשבון Google Cloud . אם אתם משתמשים חדשים ב- Google Cloud, צרו חשבון כדי שתוכלו להעריך את הביצועים של המוצרים שלנו בתרחישים מהעולם האמיתי. לקוחות חדשים מקבלים בחינם גם קרדיט בשווי 300$ להרצה, לבדיקה ולפריסה של עומסי העבודה.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, Cloud Storage, and BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
התקינו את ה-CLI של Google Cloud.
-
אם אתם משתמשים בספק זהויות חיצוני (IdP), קודם אתם צריכים להיכנס ל-CLI של gcloud באמצעות המאגר המאוחד לניהול זהויות.
-
כדי לאתחל את ה-CLI של gcloud, הריצו את הפקודה הבאה:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, Cloud Storage, and BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
התקינו את ה-CLI של Google Cloud.
-
אם אתם משתמשים בספק זהויות חיצוני (IdP), קודם אתם צריכים להיכנס ל-CLI של gcloud באמצעות המאגר המאוחד לניהול זהויות.
-
כדי לאתחל את ה-CLI של gcloud, הריצו את הפקודה הבאה:
gcloud init
- במסוף Google Cloud , נכנסים לדף Buckets של Cloud Storage.
- לוחצים על יצירה.
- ממלאים את פרטי הקטגוריה בדף Create a bucket. כדי לעבור לשלב הבא לוחצים על Continue.
-
בקטע Get started (תחילת העבודה), מבצעים את הפעולות הבאות:
- מזינים שם ייחודי בהיקף גלובלי שעומד בקריטריונים לשמות של קטגוריות.
- כדי להוסיף תווית לדלי, מרחיבים את הקטע Labels (תוויות) (), לוחצים על add_box
Add label (הוספת תווית) ומציינים
keyו-valueבשביל התווית.
-
בקטע Choose where to store your data, מבצעים את הפעולות הבאות:
- בוחרים סוג מיקום.
- בתפריט הנפתח Location type, בוחרים מיקום שבו יישמרו נתוני הקטגוריה באופן קבוע.
- אם בוחרים את סוג המיקום בשני אזורים, אפשר גם להפעיל רפליקציה בקצב טורבו באמצעות תיבת הסימון הרלוונטית.
- כדי להגדיר שכפול בין מאגרי מידע, בוחרים באפשרות הוספת שכפול בין מאגרי מידע באמצעות Storage Transfer Service ופועלים לפי השלבים הבאים:
הגדרה של רפליקציה בין מאגרי מידע
- בתפריט Bucket, בוחרים באפשרות הרצויה.
בקטע הגדרות השכפול, לוחצים על הגדרה כדי להגדיר את ההגדרות של משימת השכפול.
מופיעה החלונית Configure cross-bucket replication.
- כדי לסנן אובייקטים לשכפול לפי קידומת של שם האובייקט, מזינים קידומת שרוצים לכלול או להחריג אובייקטים ממנה, ואז לוחצים על הוספת קידומת.
- כדי להגדיר סוג אחסון לאובייקטים המשוכפלים, בוחרים סוג אחסון בתפריט סוג אחסון. אם מדלגים על השלב הזה, האובייקטים המשוכפלים ישתמשו בסוג האחסון של קטגוריית היעד כברירת מחדל.
- לוחצים על סיום.
-
בקטע Choose how to store your data, מבצעים את הפעולות הבאות:
- בוחרים default storage class לקטגוריה או Autoclass לניהול אוטומטי של סוג האחסון (storage class) של נתוני הקטגוריה.
- כדי להפעיל מרחב שמות היררכי, בקטע Optimize storage for data-intensive workloads, בוחרים באפשרות Enable hierarchical namespace on this bucket.
- בקטע Choose how to control access to objects, בוחרים אם הקטגוריה אוכפת public access prevention או לא, ואז בוחרים שיטת בקרת גישה לאובייקטים של הקטגוריה.
-
בקטע Choose how to protect object data, מבצעים את הפעולות הבאות:
- בוחרים באחת מהאפשרויות בקטע הגנה על נתונים שרוצים להגדיר לקטגוריה.
- כדי להפעיל מחיקה עם יכולת שחזור, מסמנים את התיבה מדיניות מחיקה עם יכולת שחזור (לשחזור נתונים) ומציינים את מספר הימים שבהם רוצים לשמור אובייקטים אחרי המחיקה.
- כדי להגדיר ניהול גרסאות של אובייקטים, מסמנים את התיבה ניהול גרסאות של אובייקטים (לשליטה בגרסאות) ומציינים את מספר הגרסאות המקסימלי לכל אובייקט ואת מספר הימים שאחריהם הגרסאות הלא עדכניות יפוגו.
- כדי להפעיל את מדיניות שמירת הנתונים על אובייקטים וקטגוריות, לוחצים על תיבת הסימון שמירת נתונים (לצורך תאימות), ואז מבצעים את הפעולות הבאות:
- כדי להפעיל את הנעילה של שמירת אובייקטים, מסמנים את התיבה הפעלת שמירת אובייקטים.
- כדי להפעיל את נעילת הקטגוריה, מסמנים את תיבת הסימון הגדרת מדיניות שמירת נתונים בקטגוריה ובוחרים יחידת זמן ואת משך הזמן של תקופת השמירה.
- כדי לבחור איך להצפין את נתוני האובייקט, מרחיבים את הקטע Data encryption () ובוחרים Data encryption method.
- בוחרים באחת מהאפשרויות בקטע הגנה על נתונים שרוצים להגדיר לקטגוריה.
-
בקטע Get started (תחילת העבודה), מבצעים את הפעולות הבאות:
- לוחצים על יצירה.
יצירת אשכול Managed Service for Apache Spark
יוצרים אשכול של שירות מנוהל ל-Apache Spark באמצעות הדגל optional-components (זמין בגרסה 2.1 ואילך של התמונה) כדי להתקין את רכיב Trino האופציונלי באשכול, והדגל enable-component-gateway כדי להפעיל את Component Gateway ולאפשר גישה לממשק המשתמש האינטרנטי של Trino ממסוף Google Cloud .
- הגדרה של משתני סביבה:
- PROJECT: מזהה הפרויקט
- BUCKET_NAME: השם של קטגוריית Cloud Storage שיצרתם בקטע לפני שמתחילים
- REGION: region האזור שבו ייווצר האשכול שמשמש במדריך הזה, לדוגמה, us-west1
- עובדים: מומלץ להשתמש ב-3 עד 5 עובדים במדריך הזה
export PROJECT=project-id export WORKERS=number export REGION=region export BUCKET_NAME=bucket-name
- מריצים את Google Cloud CLI במחשב המקומי כדי ליצור את האשכול.
gcloud beta dataproc clusters create trino-cluster \ --project=${PROJECT} \ --region=${REGION} \ --num-workers=${WORKERS} \ --scopes=cloud-platform \ --optional-components=TRINO \ --image-version=2.1 \ --enable-component-gateway
הכנת הנתונים
מייצאים את מערך הנתונים bigquery-public-data chicago_taxi_trips ל-Cloud Storage כקובצי CSV, ואז יוצרים טבלה חיצונית של Hive כדי להפנות לנתונים.
- במחשב המקומי, מריצים את הפקודה הבאה כדי לייבא את נתוני המוניות מ-BigQuery כקובצי CSV ללא כותרות לקטגוריית Cloud Storage שיצרתם בשלב לפני שמתחילים.
bq --location=us extract --destination_format=CSV \ --field_delimiter=',' --print_header=false \ "bigquery-public-data:chicago_taxi_trips.taxi_trips" \ gs://${BUCKET_NAME}/chicago_taxi_trips/csv/shard-*.csv - יוצרים טבלאות חיצוניות של Hive שמגובות על ידי קובצי ה-CSV ו-Parquet בקטגוריה של Cloud Storage.
- יוצרים את הטבלה החיצונית של Hive
chicago_taxi_trips_csv.gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_csv( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE location 'gs://${BUCKET_NAME}/chicago_taxi_trips/csv/';" - בודקים את יצירת הטבלה החיצונית של Hive.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_csv;" - יוצרים עוד טבלה חיצונית של Hive
chicago_taxi_trips_parquetעם אותן עמודות, אבל עם נתונים שמאוחסנים בפורמט Parquet כדי לשפר את הביצועים של השאילתות.gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_parquet( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) STORED AS PARQUET location 'gs://${BUCKET_NAME}/chicago_taxi_trips/parquet/';" - טוענים את הנתונים מטבלת ה-CSV של Hive לטבלת ה-Parquet של Hive.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " INSERT OVERWRITE TABLE chicago_taxi_trips_parquet SELECT * FROM chicago_taxi_trips_csv;" - מוודאים שהנתונים נטענו בצורה תקינה.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_parquet;"
- יוצרים את הטבלה החיצונית של Hive
הרצת שאילתות
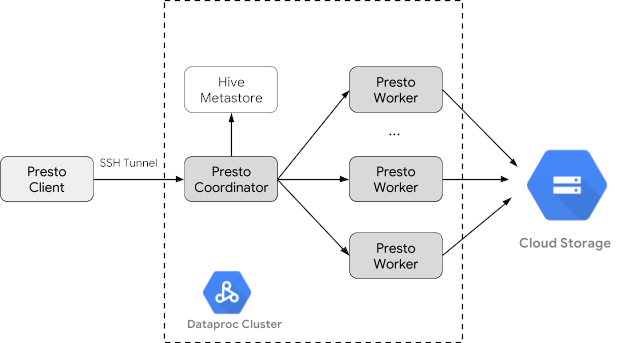
אפשר להריץ שאילתות באופן מקומי מ-Trino CLI או מאפליקציה.
שאילתות ב-Trino CLI
בקטע הזה נדגים איך לשלוח שאילתות למערך הנתונים של מוניות בפורמט Hive Parquet באמצעות Trino CLI.
- מריצים את הפקודה הבאה במחשב המקומי כדי להתחבר ל-SSH לצומת הראשי של האשכול:
הטרמינל המקומי יפסיק להגיב במהלך הביצוע של הפקודה.
gcloud compute ssh trino-cluster-m
- בחלון הטרמינל של SSH בצומת הראשי של האשכול, מריצים את Trino CLI, שמתחבר לשרת Trino שפועל בצומת הראשי.
trino --catalog hive --schema default
- בהנחיה
trino:default, מוודאים ש-Trino יכול למצוא את טבלאות Hive.show tables;
Table ‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐ chicago_taxi_trips_csv chicago_taxi_trips_parquet (2 rows)
- מריצים שאילתות מההנחיה
trino:defaultומשווים בין הביצועים של שאילתות על נתוני Parquet לעומת נתוני CSV.- שאילתת נתונים בפורמט Parquet
select count(*) from chicago_taxi_trips_parquet where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171735_00006_2sz8c, FINISHED, 3 nodes Splits: 308 total, 308 done (100.00%) 0:16 [113M rows, 297MB] [6.91M rows/s, 18.2MB/s] - שאילתת נתונים של קובץ CSV
select count(*) from chicago_taxi_trips_csv where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171936_00009_2sz8c, FINISHED, 3 nodes Splits: 881 total, 881 done (100.00%) 0:47 [113M rows, 41.5GB] [2.42M rows/s, 911MB/s]
- שאילתת נתונים בפורמט Parquet
שאילתות של אפליקציות Java
כדי להריץ שאילתות מאפליקציית Java באמצעות מנהל ההתקנים של Trino Java JDBC:
1. מורידים את מנהל ההתקן Trino Java JDBC.
1. מוסיפים תלות ב-trino-jdbc ב-Maven pom.xml.
<dependency> <groupId>io.trino</groupId> <artifactId>trino-jdbc</artifactId> <version>376</version> </dependency>
package dataproc.codelab.trino;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
public class TrinoQuery {
private static final String URL = "jdbc:trino://trino-cluster-m:8080/hive/default";
private static final String SOCKS_PROXY = "localhost:1080";
private static final String USER = "user";
private static final String QUERY =
"select count(*) as count from chicago_taxi_trips_parquet where trip_miles > 50";
public static void main(String[] args) {
try {
Properties properties = new Properties();
properties.setProperty("user", USER);
properties.setProperty("socksProxy", SOCKS_PROXY);
Connection connection = DriverManager.getConnection(URL, properties);
try (Statement stmt = connection.createStatement()) {
ResultSet rs = stmt.executeQuery(QUERY);
while (rs.next()) {
int count = rs.getInt("count");
System.out.println("The number of long trips: " + count);
}
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}רישום ביומן ומעקב
רישום ביומן
היומנים של Trino נמצאים בנתיב /var/log/trino/ בצמתי ה-master וה-worker של האשכול.
ממשק משתמש באינטרנט
כדי לפתוח את ממשק המשתמש באינטרנט של Trino שפועל בצומת הראשי של האשכול בדפדפן המקומי, אפשר לעיין במאמר בנושא הצגה וגישה לכתובות URL של שער רכיבים.
מעקב
Trino חושף מידע על זמן הריצה של האשכול באמצעות טבלאות זמן ריצה.
בסשן Trino (מההנחיה trino:default), מריצים את השאילתה הבאה כדי לראות את נתוני הטבלה בזמן הריצה:
select * FROM system.runtime.nodes;
הסרת המשאבים
אחרי שמסיימים את המדריך, אפשר למחוק את המשאבים שנוצרו, כדי שהם יפסיקו להשתמש במכסה ולצבור חיובים. בסעיפים הבאים מוסבר איך למחוק או להשבית את המשאבים האלו.
מחיקת הפרויקט
הדרך הקלה ביותר לבטל את החיוב היא למחוק את הפרויקט שיצרתם בשביל המדריך הזה.
כדי למחוק את הפרויקט:
- במסוף Google Cloud , נכנסים לדף Manage resources.
- ברשימת הפרויקטים, בוחרים את הפרויקט שרוצים למחוק ולוחצים על Delete.
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.
מחיקת האשכול
- כדי למחוק את האשכול:
gcloud dataproc clusters delete --project=${PROJECT} trino-cluster \ --region=${REGION}
מחיקת הקטגוריה
- כדי למחוק את קטגוריה של Cloud Storage שיצרתם בקטע לפני שמתחילים, כולל קובצי הנתונים שמאוחסנים בקטגוריה:
gcloud storage rm gs://${BUCKET_NAME} --recursive