
מטרות
המדריך הזה מסביר איך:
- יצירת אשכול Managed Service for Apache Spark, והתקנה של Apache HBase ו-Apache ZooKeeper באשכול
- יצירת טבלת HBase באמצעות מעטפת HBase שפועלת בצומת הראשי של אשכול Managed Service for Apache Spark
- שימוש ב-Cloud Shell כדי לשלוח משימת Spark ב-Java או ב-PySpark אל Managed Service for Apache Spark, שכותב נתונים לטבלת HBase ואז קורא נתונים ממנה
עלויות
במסמך הזה משתמשים ברכיבים הבאים של Google Cloud, והשימוש בהם כרוך בתשלום:
כדי להעריך את ההוצאות בהתאם לתחזית השימוש שלכם, אתם יכולים להיעזר במחשבון העלויות.
לפני שמתחילים
אם עדיין לא עשיתם זאת, צרו פרויקט ב-Google Cloud Platform.
- נכנסים לחשבון Google Cloud . אם אתם משתמשים חדשים ב- Google Cloud, צרו חשבון כדי שתוכלו להעריך את הביצועים של המוצרים שלנו בתרחישים מהעולם האמיתי. לקוחות חדשים מקבלים בחינם גם קרדיט בשווי 300$ להרצה, לבדיקה ולפריסה של עומסי העבודה.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc and Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc and Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
יצירת אשכול Managed Service for Apache Spark
מריצים את הפקודה הבאה במסוף של סשן Cloud Shell כדי:
- מתקינים את הרכיבים HBase ו-ZooKeeper
- הקצאת שלושה צמתי עובדים (מומלץ להקצות שלושה עד חמישה צמתי עובדים כדי להריץ את הקוד במדריך הזה)
- הפעלת שער הרכיבים
- שימוש בגרסת תמונה 2.0
- משתמשים בדגל
--propertiesכדי להוסיף את ההגדרה של HBase ואת הספרייה של HBase לנתיבי המחלקות של מנהל ההתקן והמבצע של Spark.
gcloud dataproc clusters create cluster-name \ --region=region \ --optional-components=HBASE,ZOOKEEPER \ --num-workers=3 \ --enable-component-gateway \ --image-version=2.0 \ --properties='spark:spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark:spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
אימות ההתקנה של המחבר
ממסוף Google Cloud או מטרמינל של סשן Cloud Shell, מתחברים באמצעות SSH לצומת הראשי של אשכול Managed Service for Apache Spark.
מאמתים את ההתקנה של מחבר Apache HBase Spark בצומת הראשי:
ls -l /usr/lib/spark/jars | grep hbase-spark
-rw-r--r-- 1 root root size date time hbase-spark-connector.version.jar
משאירים את חלון הטרמינל של סשן ה-SSH פתוח כדי:
- יצירת טבלת HBase
- (משתמשי Java): מריצים פקודות בצומת הראשי של האשכול כדי לקבוע את הגרסאות של הרכיבים שמותקנים באשכול
- סורקים את טבלת ה-Hbase אחרי הרצת הקוד
יצירת טבלת HBase
מריצים את הפקודות שמופיעות בקטע הזה בטרמינל של סשן ה-SSH של צומת הראשי שפתחתם בשלב הקודם.
פותחים את מעטפת HBase:
hbase shell
יוצרים את טבלת HBase my-table עם קבוצת העמודות cf:
create 'my_table','cf'
- כדי לוודא שהטבלה נוצרה, במסוף Google Cloud לוחצים על HBase בקישורים של רכיב שער המסוףGoogle Cloud כדי לפתוח את ממשק המשתמש של Apache HBase.
my-tableמופיע בקטע טבלאות בדף דף הבית.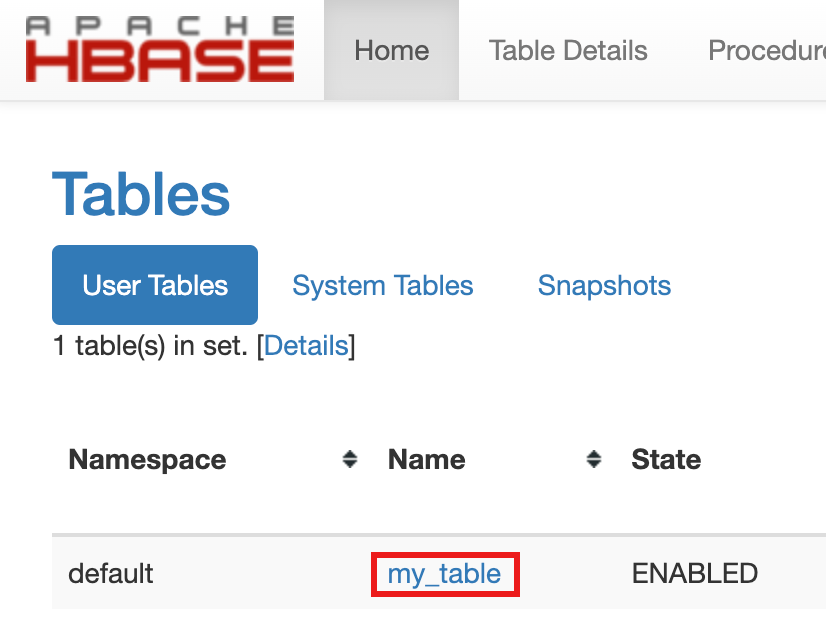
- כדי לוודא שהטבלה נוצרה, במסוף Google Cloud לוחצים על HBase בקישורים של רכיב שער המסוףGoogle Cloud כדי לפתוח את ממשק המשתמש של Apache HBase.
הצגת קוד Spark
Java
Python
הרצת הקוד
פותחים טרמינל של סשן Cloud Shell.
משכפלים את מאגר GitHub GoogleCloudDataproc/cloud-dataproc לטרמינל של סשן Cloud Shell:
git clone https://github.com/GoogleCloudDataproc/cloud-dataproc.git
עוברים לספרייה
cloud-managed-spark/spark-hbase:cd cloud-managed-spark/spark-hbase
user-name@cloudshell:~/cloud-managed-spark/spark-hbase (project-id)$
שולחים את המשימה של Managed Service for Apache Spark.
Java
- מגדירים את גרסאות הרכיבים בקובץ
pom.xml.- בדף גרסאות 2.0.x של Managed Service for Apache Spark מפורטות גרסאות הרכיבים Scala, Spark ו-HBase שמותקנות עם הגרסה המשנית האחרונה ועם ארבע הגרסאות המשניות האחרונות של אימג' 2.0.
- כדי למצוא את הגרסה המשנית של אשכול גרסת התמונה 2.0, לוחצים על שם האשכול בדף Clusters במסוףGoogle Cloud כדי לפתוח את הדף Cluster details, שבו מופיעה Image version של האשכול.
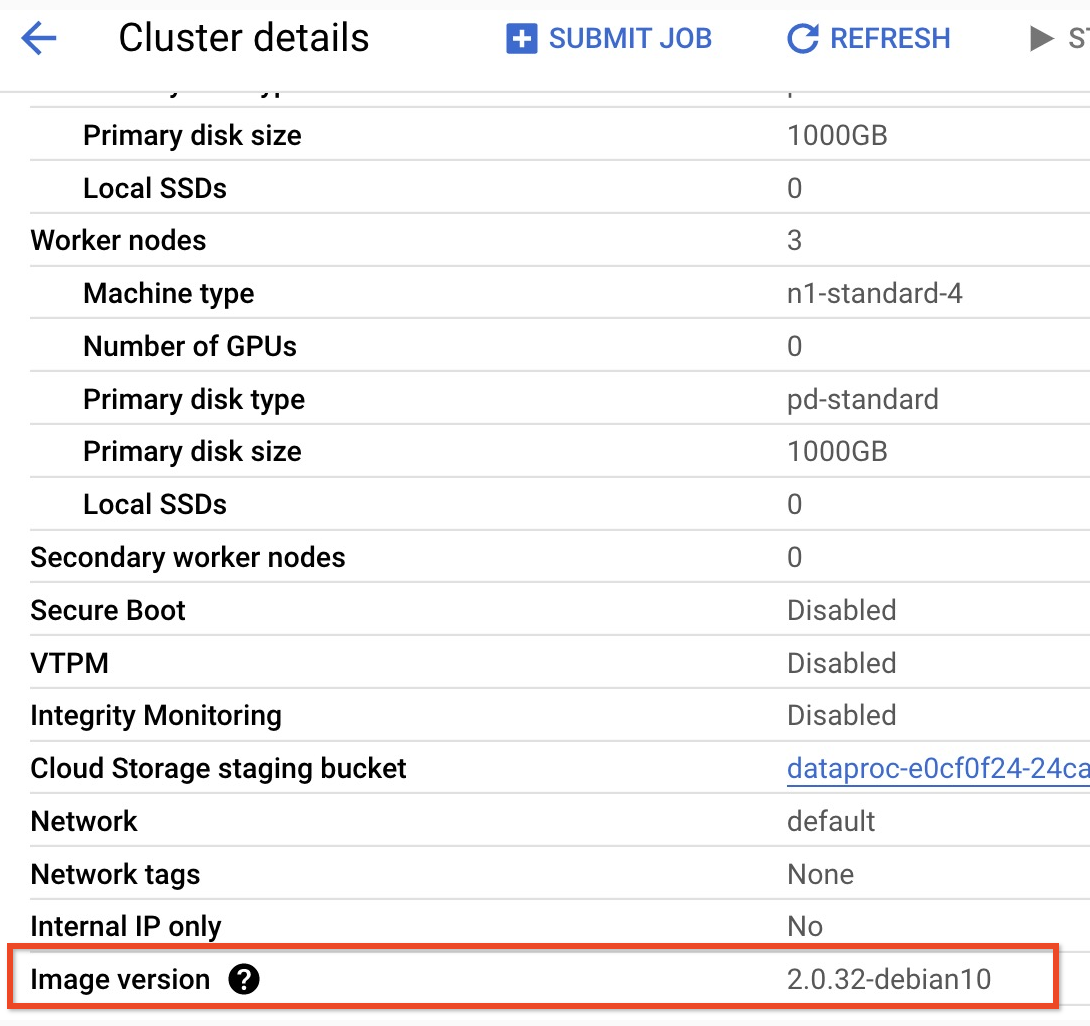
- כדי למצוא את הגרסה המשנית של אשכול גרסת התמונה 2.0, לוחצים על שם האשכול בדף Clusters במסוףGoogle Cloud כדי לפתוח את הדף Cluster details, שבו מופיעה Image version של האשכול.
- לחלופין, אפשר להריץ את הפקודות הבאות בטרמינל של סשן SSH מהצומת הראשי של האשכול כדי לקבוע את גרסאות הרכיבים:
- בודקים את גרסת Scala:
scala -version
- בודקים את גרסת Spark (לחיצה על Control-D כדי לצאת):
spark-shell
- בודקים את הגרסה של HBase:
hbase version
- מזהים את יחסי התלות בגרסאות של Spark, Scala ו-HBase ב-Maven
pom.xml: <properties> <scala.version>scala full version (for example, 2.12.14)</scala.version> <scala.main.version>scala main version (for example, 2.12)</scala.main.version> <spark.version>spark version (for example, 3.1.2)</spark.version> <hbase.client.version>hbase version (for example, 2.2.7)</hbase.client.version> <hbase-spark.version>1.0.0(the current Apache HBase Spark Connector version)> </properties>
hbase-spark.versionהיא הגרסה הנוכחית של מחבר Spark HBase. אין לשנות את מספר הגרסה הזה.
- בודקים את גרסת Scala:
- עורכים את הקובץ
pom.xmlב-Cloud Shell Editor כדי להוסיף את מספרי הגרסאות הנכונים של Scala, Spark ו-HBase. כשמסיימים לערוך, לוחצים על Open Terminal כדי לחזור לשורת הפקודה של הטרמינל ב-Cloud Shell.cloudshell edit .
- עוברים ל-Java 8 ב-Cloud Shell. נדרשת גרסת ה-JDK הזו כדי לבנות את הקוד (אפשר להתעלם מהודעות אזהרה לגבי תוספים):
sudo update-java-alternatives -s java-1.8.0-openjdk-amd64 && export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
- אימות ההתקנה של Java 8:
java -version
openjdk version "1.8..."
- בדף גרסאות 2.0.x של Managed Service for Apache Spark מפורטות גרסאות הרכיבים Scala, Spark ו-HBase שמותקנות עם הגרסה המשנית האחרונה ועם ארבע הגרסאות המשניות האחרונות של אימג' 2.0.
- יוצרים את הקובץ
jar: mvn clean package
.jarממוקם בספריית המשנה/target(לדוגמה,target/spark-hbase-1.0-SNAPSHOT.jar). שולחים את העבודה.
gcloud dataproc jobs submit spark \ --class=hbase.SparkHBaseMain \ --jars=target/filename.jar \ --region=cluster-region \ --cluster=cluster-name
-
--jars: צריך להוסיף את השם של קובץ.jarאחרי target/ ולפני .jar. - אם לא הגדרתם את נתיבי המחלקות של HBase למנהל ההתקנים ולרכיב ההרצה של Spark כשיצרתם את האשכול, אתם צריכים להגדיר אותם בכל שליחת משימה על ידי הוספת הדגל
‑‑propertiesהבא לפקודת שליחת המשימה:--properties='spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
-
צופים בפלט של טבלת HBase בפלט של הטרמינל בסשן של Cloud Shell:
Waiting for job output... ... +----+----+ | key|name| +----+----+ |key1| foo| |key2| bar| +----+----+
Python
שולחים את העבודה.
gcloud dataproc jobs submit pyspark scripts/pyspark-hbase.py \ --region=cluster-region \ --cluster=cluster-name
- אם לא הגדרתם את נתיבי המחלקות של HBase למנהל ההתקנים ולרכיב ההרצה של Spark כשיצרתם את האשכול, אתם צריכים להגדיר אותם בכל שליחת משימה על ידי הוספת הדגל
‑‑propertiesהבא לפקודת שליחת המשימה:--properties='spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
- אם לא הגדרתם את נתיבי המחלקות של HBase למנהל ההתקנים ולרכיב ההרצה של Spark כשיצרתם את האשכול, אתם צריכים להגדיר אותם בכל שליחת משימה על ידי הוספת הדגל
צופים בפלט של טבלת HBase בפלט של הטרמינל בסשן של Cloud Shell:
Waiting for job output... ... +----+----+ | key|name| +----+----+ |key1| foo| |key2| bar| +----+----+
סריקת טבלת HBase
כדי לסרוק את התוכן של טבלת HBase, מריצים את הפקודות הבאות בטרמינל של סשן ה-SSH של הצומת הראשי שפתחתם בקטע אימות ההתקנה של המחבר:
- פותחים את מעטפת HBase:
hbase shell
- סריקת הטבלה my-table:
scan 'my_table'
ROW COLUMN+CELL key1 column=cf:name, timestamp=1647364013561, value=foo key2 column=cf:name, timestamp=1647364012817, value=bar 2 row(s) Took 0.5009 seconds
הסרת המשאבים
אחרי שמסיימים את המדריך, אפשר למחוק את המשאבים שנוצרו, כדי שהם יפסיקו להשתמש במכסה ולצבור חיובים. בסעיפים הבאים מוסבר איך למחוק או להשבית את המשאבים האלו.
מחיקת הפרויקט
הדרך הקלה ביותר לבטל את החיוב היא למחוק את הפרויקט שיצרתם בשביל המדריך הזה.
כדי למחוק את הפרויקט:
- במסוף Google Cloud , נכנסים לדף Manage resources.
- ברשימת הפרויקטים, בוחרים את הפרויקט שרוצים למחוק ולוחצים על Delete.
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.
מחיקת האשכול
- כדי למחוק את האשכול:
gcloud dataproc clusters delete cluster-name \ --region=${REGION}