
本页面介绍了如何创建 Managed Service for Apache Spark 集群,以使用 Spark Spanner 连接器 通过 Apache Spark 从 Spanner 读取数据以及向其中写入数据。
Spanner 连接器与 Spark 搭配使用,以使用 Spanner Java 库从 Spanner 数据库读取数据 以及向其中写入数据。 Spanner 连接器支持将 Spanner 表和 图读入 Spark DataFrames 和 GraphFrames中,以及将 DataFrame 数据写入 Spanner 表。
费用
在本文档中,您将使用的以下收费组件: Google Cloud
- Managed Service for Apache Spark
- Spanner
- Cloud Storage
您可使用 价格计算器 根据您的预计使用情况来估算费用。
准备工作
- 登录您的 Google Cloud 账号。 如果您是新手,请创建一个账号来评估我们的产品在实际场景中的表现。 Google Cloud新客户还可获享 $300 赠金,用于 运行、测试和部署工作负载。
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Spanner, Managed Service for Apache Spark, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Spanner, Managed Service for Apache Spark, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.- 授予必需的角色。
- 设置 Managed Service for Apache Spark 集群。
- 设置包含 Singers 数据库表的 Spanner 实例。
授予必需的角色
如需运行本页中的示例,您需要拥有某些 IAM 角色。根据组织政策,这些角色可能已授予。如需检查角色授予情况,请参阅 是否需要授予角色?。
如需详细了解如何授予角色,请参阅 管理对项目、文件夹和组织的访问权限。
为确保 Compute Engine 默认服务帐号具有创建 Managed Service for Apache Spark 集群所需的 权限,请让您的管理员为 Compute Engine 默认服务帐号授予项目的以下 IAM 角色:
- Dataproc Worker (
roles/dataproc.worker) - Cloud Spanner Database User (
roles/spanner.databaseUser) - Cloud Spanner Database Reader with DataBoost (
roles/spanner.databaseReaderWithDataBoost)
设置 Managed Service for Apache Spark 集群
创建 Managed Service for Apache Spark 集群
或使用现有的 Managed Service for Apache Spark 集群(该集群是使用
2.1 或更高版本的 Managed Service for Apache Spark 映像创建的),或者,如果该
集群是使用 2.0 或更低版本的映像创建的,则必须使用设置为
cloud-platform 范围的
scope 属性创建。
设置包含 Singers 数据库表的 Spanner 实例
使用包含 Singers 表的数据库创建 Spanner 实例。记下 Spanner 实例 ID 和数据库 ID。
将 Spanner 连接器与 Spark 搭配使用
Spanner 连接器适用于 Spark 版本 3.1+。在向
Managed Service for Apache Spark 集群提交作业时,您可以在 Cloud Storage 连接器 JAR 文件规范中指定连接器版本。
示例: 使用 Spanner 连接器提交 gcloud CLI Spark 作业。
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar \ ... [other job submission flags]
替换以下内容:
CONNECTOR_VERSION:Spanner 连接器版本。从 GitHub
GoogleCloudDataproc/spark-spanner-connector 代码库中的版本列表中选择 Spanner 连接器版本。
读取 Spanner 表
您可以使用 Python 或 Scala 通过 Spark 数据源 API将 Spanner 表数据读入 Spark Dataframe 中。
PySpark
您可以通过以下方式在集群上运行本部分中的示例 PySpark 代码:将作业提交到 Managed Service for Apache Spark,或从集群主服务器上的 spark-submit REPL 运行作业。
Managed Service for Apache Spark 作业
- 使用本地文本编辑器或使用预安装的
vi、vim或nano文本编辑器在 Cloud Shell 中创建singers.py文件。 - 填充占位变量后,将以下代码
粘贴到
singers.py文件中。请注意,Spanner Data Boost 功能处于启用状态,对主 Spanner 实例的影响接近于零。#!/usr/bin/env python """Spanner PySpark read example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-spanner-demo') \ .getOrCreate() # Load data from Spanner. singers = spark.read.format('cloud-spanner') \ .option("projectId", "PROJECT_ID") \ .option("instanceId", "INSTANCE_ID") \ .option("databaseId", "DATABASE_ID") \ .option("table", "TABLE_NAME") \ .option("enableDataBoost", "true") \ .load() singers.createOrReplaceTempView('Singers') # Read from Singers result = spark.sql('SELECT * FROM Singers') result.show() result.printSchema()
替换以下内容:
- PROJECT_ID:您的 Google Cloud 项目 ID。 项目 ID 列在 Google Cloud 控制台信息中心的项目信息部分中。
- INSTANCE_ID、DATABASE_ID 和 TABLE_NAME:请参阅使用
Singers数据库表设置 Spanner 实例。
- 保存
singers.py文件。 - 使用
控制台、gcloud CLI 或 Google Cloud REST API 向 Managed Service for Apache Spark 提交作业。
示例: 使用 Spanner 连接器提交 gcloud CLI 作业。
gcloud dataproc jobs submit pyspark singers.py \ --cluster=CLUSTER_NAME \ --region=REGION \ --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar替换以下内容:
- CLUSTER_NAME:新集群的名称。
- REGION:用于运行工作负载的可用 Compute Engine 区域。
- CONNECTOR_VERSION:Spanner 连接器版本。从 GitHub
GoogleCloudDataproc/spark-spanner-connector代码库中的版本列表中选择 Spanner 连接器版本。
spark-submit 作业
- 使用 SSH 连接到 Managed Service for Apache Spark 集群主服务器节点。
- 在 控制台中前往 Managed Service for Apache Spark 集群 页面,然后点击集群的名称。 Google Cloud
- 在集群详情 页面上,选择“虚拟机实例”标签页。然后,点击集群主服务器节点名称右侧的
SSH。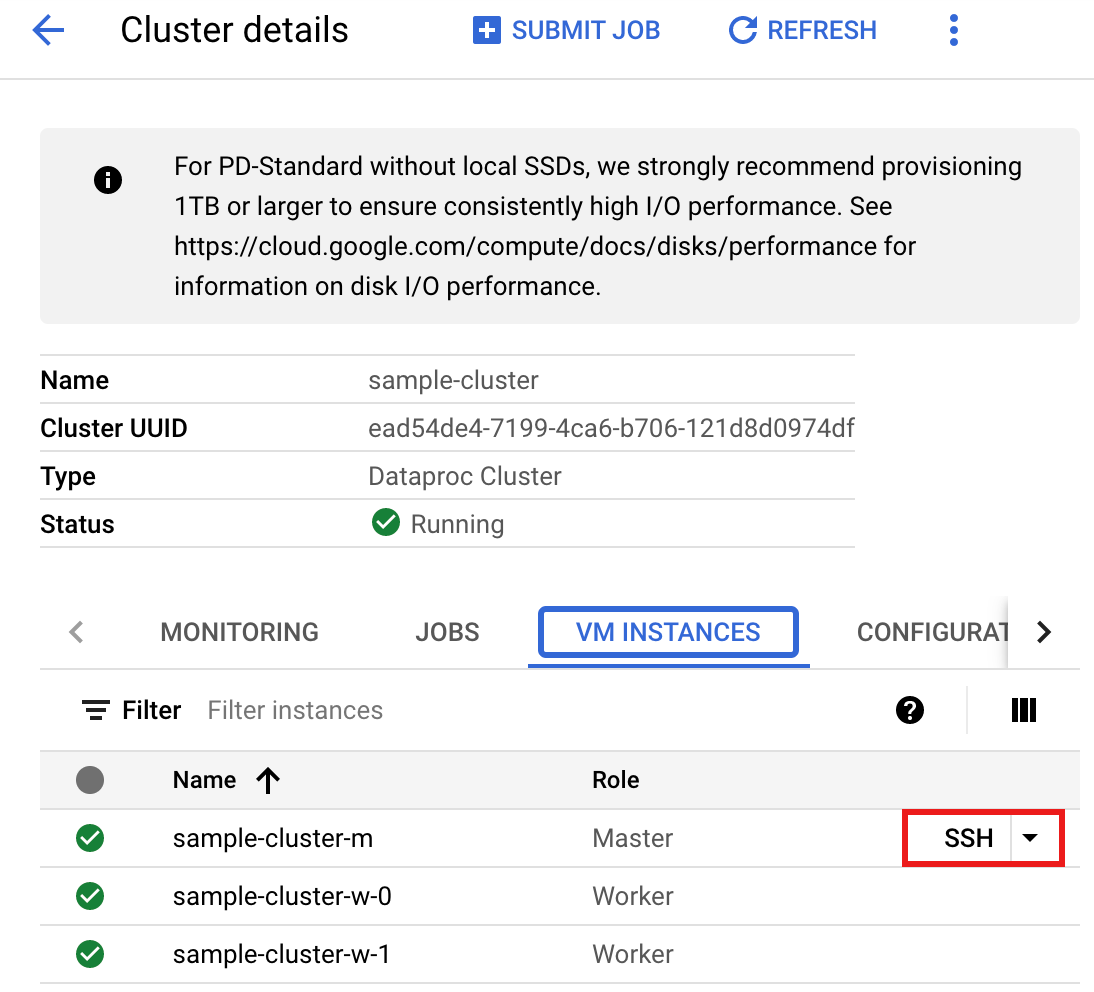
此时会打开一个浏览器窗口并显示主节点上的主目录。
Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- 使用预安装的
vi、vim或nano文本编辑器在主节点上创建singers.py文件。- 将占位变量填充到
singers.py文件后,将以下代码粘贴到singers.py文件中。请注意,Spanner Data Boost 功能处于启用状态,对主 Spanner 实例的影响接近于零。#!/usr/bin/env python """Spanner PySpark read example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-spanner-demo') \ .getOrCreate() # Load data from Spanner. singers = spark.read.format('cloud-spanner') \ .option("projectId", "PROJECT_ID") \ .option("instanceId", "INSTANCE_ID") \ .option("databaseId", "DATABASE_ID") \ .option("table", "TABLE_NAME") \ .option("enableDataBoost", "true") \ .load() singers.createOrReplaceTempView('Singers') # Read from Singers result = spark.sql('SELECT * FROM Singers') result.show() result.printSchema()
替换以下内容:
- PROJECT_ID:您的 Google Cloud 项目 ID。 项目 ID 列在 Google Cloud 控制台信息中心的项目信息部分中。
- INSTANCE_ID、DATABASE_ID 和 TABLE_NAME:请参阅使用
Singers数据库表设置 Spanner 实例。
- 保存
singers.py文件。
- 将占位变量填充到
- 使用
spark-submit运行singers.py以创建 SpannerSingers表。spark-submit --jars gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar singers.py
替换以下内容:
- CONNECTOR_VERSION:Spanner 连接器版本。从 GitHub
GoogleCloudDataproc/spark-spanner-connector代码库中的版本列表中选择 Spanner 连接器版本。
输出为:
... +--------+---------+--------+---------+-----------+ |SingerId|FirstName|LastName|BirthDate|LastUpdated| +--------+---------+--------+---------+-----------+ | 1| Marc|Richards| null| null| | 2| Catalina| Smith| null| null| | 3| Alice| Trentor| null| null| +--------+---------+--------+---------+-----------+ root |-- SingerId: long (nullable = false) |-- FirstName: string (nullable = true) |-- LastName: string (nullable = true) |-- BirthDate: date (nullable = true) |-- LastUpdated: timestamp (nullable = true) only showing top 20 rows
- CONNECTOR_VERSION:Spanner 连接器版本。从 GitHub
Scala
如需在集群上运行示例 Scala 代码,请完成以下步骤:
- 使用 SSH 连接到 Managed Service for Apache Spark 集群主服务器节点。
- 在 控制台中前往 Managed Service for Apache Spark 集群 页面,然后点击集群的名称。 Google Cloud
- 在集群详情 页面上,选择“虚拟机实例”标签页。然后,点击集群主节点名称右侧的
SSH。
此时会打开一个浏览器窗口并显示主节点上的主目录。
Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- 使用预安装的
vi、vim或nano文本编辑器在主节点上创建singers.scala文件。- 将以下代码粘贴到
singers.scala文件中。请注意,Spanner Data Boost 功能处于启用状态,对主 Spanner 实例的影响接近于零。object singers { def main(): Unit = { /* * Uncomment (use the following code) if you are not running in spark-shell. * import org.apache.spark.sql.SparkSession val spark = SparkSession.builder() .appName("spark-spanner-demo") .getOrCreate() */ // Load data in from Spanner. See // https://github.com/GoogleCloudDataproc/spark-spanner-connector/blob/main/README.md#properties // for option information. val singersDF = (spark.read.format("cloud-spanner") .option("projectId", "PROJECT_ID") .option("instanceId", "INSTANCE_ID") .option("databaseId", "DATABASE_ID") .option("table", "TABLE_NAME") .option("enableDataBoost", true) .load() .cache()) singersDF.createOrReplaceTempView("Singers") // Load the Singers table. val result = spark.sql("SELECT * FROM Singers") result.show() result.printSchema() } }
替换以下内容:
- PROJECT_ID:您的 Google Cloud 项目 ID。 项目 ID 列在 Google Cloud 控制台信息中心的项目信息部分中。
- INSTANCE_ID、DATABASE_ID 和 TABLE_NAME:请参阅使用
Singers数据库表设置 Spanner 实例。
- 保存
singers.scala文件。
- 将以下代码粘贴到
- 启动
spark-shellREPL。$ spark-shell --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar
替换以下内容:
CONNECTOR_VERSION:Spanner 连接器版本。从 GitHub
GoogleCloudDataproc/spark-spanner-connector代码库中的版本列表中选择 Spanner 连接器版本。 - 使用
:load singers.scala命令 运行singers.scala以创建 SpannerSingers表。输出列表会显示来自 Singers 输出的示例。> :load singers.scala Loading singers.scala... defined object singers > singers.main() ... +--------+---------+--------+---------+-----------+ |SingerId|FirstName|LastName|BirthDate|LastUpdated| +--------+---------+--------+---------+-----------+ | 1| Marc|Richards| null| null| | 2| Catalina| Smith| null| null| | 3| Alice| Trentor| null| null| +--------+---------+--------+---------+-----------+ root |-- SingerId: long (nullable = false) |-- FirstName: string (nullable = true) |-- LastName: string (nullable = true) |-- BirthDate: date (nullable = true) |-- LastUpdated: timestamp (nullable = true)
读取 Spanner 图
Spanner 连接器支持将该图导出到单独的
节点和边缘
DataFrames
,以及直接将其导出到
GraphFrames
。
以下示例将 Spanner 导出到 GraphFrame。该示例
使用 Python SpannerGraphConnector类来读取
Spanner 图,该类包含在
Spanner 连接器 jar 中。
from pyspark.sql import SparkSession connector_jar = "gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar" spark = (SparkSession.builder.appName("spanner-graphframe-graphx-example") .config("spark.jars.packages", "graphframes:graphframes:0.8.4-spark3.5-s_2.12") .config("spark.jars", connector_jar) .getOrCreate()) spark.sparkContext.addPyFile(connector_jar) from spannergraph import SpannerGraphConnector connector = (SpannerGraphConnector() .spark(spark) .project("PROJECT_ID") .instance("INSTANCE_ID") .database("DATABASE_ID") .graph("GRAPH_ID")) g = connector.load_graph() g.vertices.show() g.edges.show()
替换以下内容:
- CONNECTOR_VERSION:Spanner 连接器版本。
从 GitHub
GoogleCloudDataproc/spark-spanner-connector代码库中的版本列表中选择 Spanner 连接器版本。 - PROJECT_ID:您的 Google Cloud 项目 ID。 项目 ID 列在 Google Cloud 控制台信息中心的项目信息部分中。
- INSTANCE_ID、DATABASE_ID 和 TABLE_NAME:插入 实例、数据库和图表 ID。
如需导出节点和边缘 DataFrames (而不是 GraphFrame),请改用 load_dfs:
df_vertices, df_edges, df_id_map = connector.load_dfs()
写入 Spanner 表
Spanner 连接器支持使用 Spark 数据源 API将 Spark Dataframe 写入 Spanner 表。
将 DataFrame 写入 Spanner 表的示例
在保存和运行代码之前填充变量。
"""Spanner PySpark write example.""" from pyspark.sql import SparkSession spark = SparkSession.builder.appName('Spanner Write App').getOrCreate() columns = ['id', 'name', 'email'] data = [(1, 'John Doe', 'john.doe@example.com'), (2, 'Jane Doe', 'jane.doe@example.com')] df = spark.createDataFrame(data, columns) df.write.format('cloud-spanner') \ .option("projectId", "PROJECT_ID") .option("instanceId", "INSTANCE_ID") .option("databaseId", "DATABASE_ID") .option("table", "TABLE_NAME") .mode("append") \ .save()
替换以下内容。
- PROJECT_ID:项目 ID。 Google Cloud 项目 ID 列在 项目信息 部分中,位于 控制台 Google Cloud 信息中心。
- INSTANCE_ID、DATABASE_ID 和 TABLE_NAME:插入 实例、数据库和表 ID。
清理
为避免您的 Google Cloud 账号持续产生费用,您可以 停止或 删除您的 Managed Service for Apache Spark 集群,并 删除您的 Spanner 实例。
后续步骤
- 请参阅
pyspark.sql.DataFrame示例。 - 如需了解 Spark DataFrame 语言支持,请参阅以下内容:
- 请参阅 GitHub 上的 Spark Spanner 连接器代码库。
- 请参阅 Spark 作业调优提示。