
이 페이지에서는 Spark Spanner 커넥터를 사용하여 Apache Spark로 Spanner에서 데이터를 읽고 쓰는 Managed Service for Apache Spark 클러스터를 만드는 방법을 보여줍니다.
Spanner 커넥터는 Spark와 함께 Spanner Java 라이브러리를 사용하여 Spanner 데이터베이스에서 데이터를 읽고 씁니다. Spanner 커넥터는 Spanner 테이블 및 그래프를 Spark DataFrames 및 GraphFrames로 읽고 DataFrame 데이터를 Spanner 테이블에 쓸 수 있도록 지원합니다.
비용
이 문서에서는 비용이 청구될 수 있는 Google Cloud구성요소를 사용합니다.
- Managed Service for Apache Spark
- Spanner
- Cloud Storage
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용하세요.
시작하기 전에
- Google Cloud 계정에 로그인합니다. Google Cloud를 처음 사용하는 경우 계정을 만들고 Google 제품의 실제 성능을 평가해 보세요. 신규 고객에게는 워크로드를 실행, 테스트, 배포하는 데 사용할 수 있는 $300의 무료 크레딧이 제공됩니다.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Spanner, Managed Service for Apache Spark, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Spanner, Managed Service for Apache Spark, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.- 필수 역할 부여
- Managed Service for Apache Spark 클러스터를 설정합니다.
- Singers 데이터베이스 테이블이 있는 Spanner 인스턴스를 설정합니다.
필수 역할 부여
이 페이지의 예시를 실행하려면 특정 IAM 역할이 필요합니다. 조직 정책에 따라 이러한 역할이 이미 부여되었을 수 있습니다. 역할 부여를 확인하려면 역할을 부여해야 하나요?를 참고하세요.
역할 부여에 대한 상세 설명은 프로젝트, 폴더, 조직에 대한 액세스 관리를 참조하세요.
Compute Engine 기본 서비스 계정에 Apache Spark용 관리 서비스를 만드는 데 필요한 권한이 있는지 확인하려면 관리자에게 프로젝트의 Compute Engine 기본 서비스 계정에 다음 IAM 역할을 부여해 달라고 요청하세요.
- Dataproc 작업자 (
roles/dataproc.worker) - Cloud Spanner 데이터베이스 사용자 (
roles/spanner.databaseUser) - DataBoost가 포함된 Cloud Spanner 데이터베이스 리더 (
roles/spanner.databaseReaderWithDataBoost)
Managed Service for Apache Spark 클러스터 설정
Managed Service for Apache Spark 클러스터를 만들거나 2.1 이상 Managed Service for Apache Spark 이미지로 만든 기존 Managed Service for Apache Spark 클러스터를 사용합니다. 클러스터를 2.0 이하 이미지로 만든 경우 scope 속성이 cloud-platform 범위로 설정되어 있어야 합니다.
Singers 데이터베이스 테이블이 있는 Spanner 인스턴스 설정
Singers 테이블을 포함하는 데이터베이스가 있는 Spanner 인스턴스를 만듭니다. Spanner 인스턴스 ID와 데이터베이스 ID를 기록해 둡니다.
Spark에서 Spanner 커넥터 사용
Spanner 커넥터는 Spark 버전 3.1+에서 사용 가능합니다. Managed Service for Apache Spark 클러스터에 작업을 제출할 때 Cloud Storage 커넥터 JAR 파일 사양에 따라 커넥터 버전을 지정합니다.
예: Spanner 커넥터를 사용하는 gcloud CLI Spark 작업 제출
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar \ ... [other job submission flags]
다음을 바꿉니다.
CONNECTOR_VERSION: Spanner 커넥터 버전.
GitHub GoogleCloudDataproc/spark-spanner-connector 저장소의 버전 목록에서 Spanner 커넥터 버전을 선택합니다.
Spanner 테이블 읽기
Python 또는 Scala를 사용하여 Spark 데이터 소스 API를 통해 Spanner 테이블 데이터를 Spark Dataframe으로 읽어올 수 있습니다.
PySpark
Managed Service for Apache Spark에 작업을 제출하거나 클러스터 마스터 노드의 spark-submit REPL에서 작업을 실행하여 클러스터에서 이 섹션의 PySpark 코드 예시를 실행할 수 있습니다.
Managed Service for Apache Spark 작업
- 로컬 텍스트 편집기를 사용하거나 Cloud Shell에서 미리 설치된
vi,vim,nano텍스트 편집기를 사용하여singers.py파일을 만듭니다. - 자리표시자 변수를 채운 후 다음 코드를
singers.py파일에 붙여넣습니다. Spanner Data Boost 기능이 사용 설정되어 기본 Spanner 인스턴스에 거의 0에 가까운 영향을 줍니다.#!/usr/bin/env python """Spanner PySpark read example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-spanner-demo') \ .getOrCreate() # Load data from Spanner. singers = spark.read.format('cloud-spanner') \ .option("projectId", "PROJECT_ID") \ .option("instanceId", "INSTANCE_ID") \ .option("databaseId", "DATABASE_ID") \ .option("table", "TABLE_NAME") \ .option("enableDataBoost", "true") \ .load() singers.createOrReplaceTempView('Singers') # Read from Singers result = spark.sql('SELECT * FROM Singers') result.show() result.printSchema()
다음을 바꿉니다.
- PROJECT_ID: Google Cloud 프로젝트 ID입니다. 프로젝트 ID는 Google Cloud 콘솔 대시보드의 프로젝트 정보 섹션에 나열됩니다.
- INSTANCE_ID, DATABASE_ID, TABLE_NAME:
Singers데이터베이스 테이블이 있는 Spanner 인스턴스 설정을 참조하세요.
singers.py파일을 저장합니다.- Google Cloud 콘솔, gcloud CLI, REST API를 사용하여 Managed Service for Apache Spark에 작업을 제출합니다.
예시: Spanner 커넥터를 사용하는 gcloud CLI 작업 제출
gcloud dataproc jobs submit pyspark singers.py \ --cluster=CLUSTER_NAME \ --region=REGION \ --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar다음을 바꿉니다.
- CLUSTER_NAME: 새 클러스터의 이름입니다.
- REGION: 워크로드를 실행하는 데 사용할 수 있는 Compute Engine 리전입니다.
- CONNECTOR_VERSION: Spanner 커넥터 버전.
GitHub
GoogleCloudDataproc/spark-spanner-connector저장소의 버전 목록에서 Spanner 커넥터 버전을 선택합니다.
spark-submit 작업
- SSH를 사용하여 Managed Service for Apache Spark 클러스터 마스터 노드에 연결합니다.
- Google Cloud 콘솔에서 Managed Service for Apache Spark 클러스터 페이지로 이동한 다음 클러스터 이름을 클릭합니다.
- 클러스터 세부정보 페이지에서 VM 인스턴스 탭을 선택합니다. 그런 후 클러스터 마스터 노드 이름 오른쪽에 있는
SSH를 클릭합니다.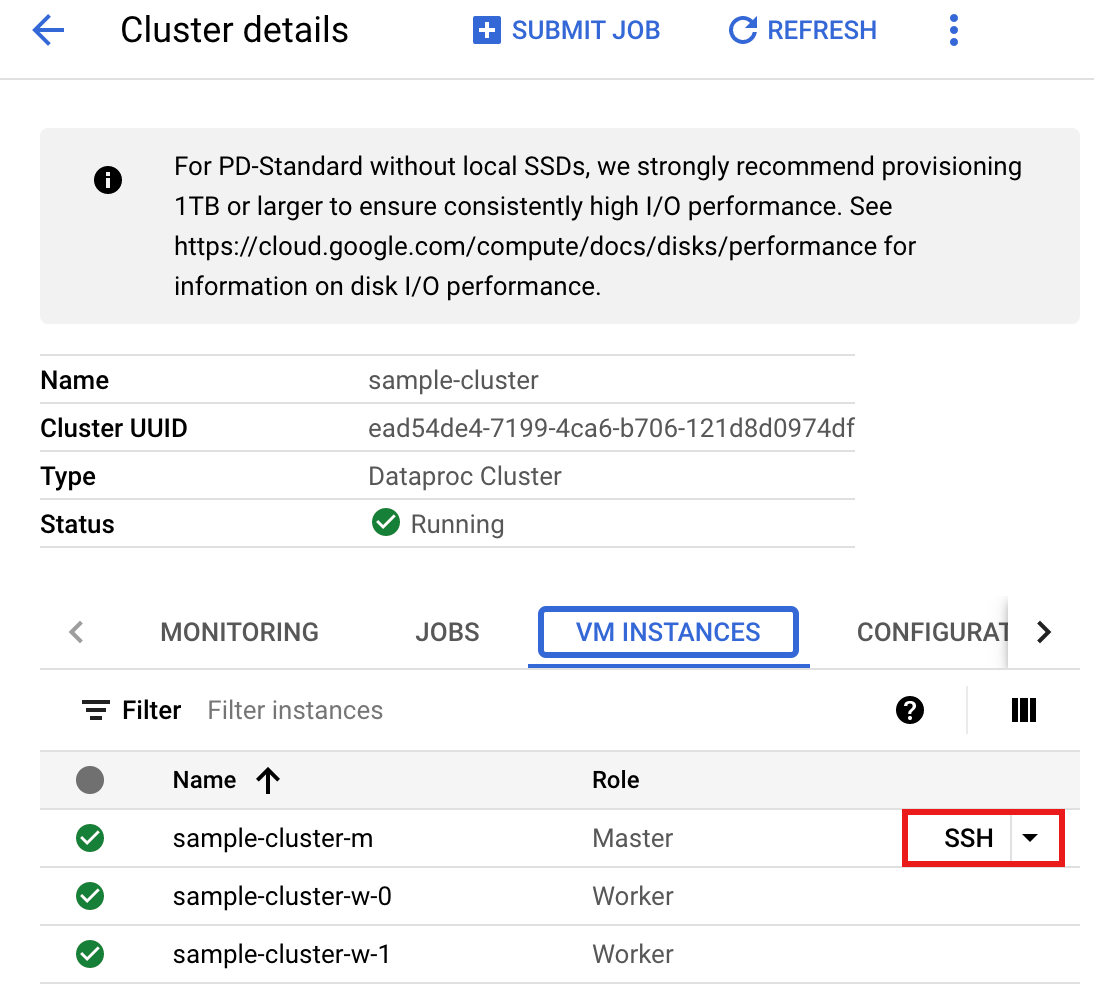
마스터 노드의 홈 디렉터리에 브라우저 창이 열립니다.
Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- 사전 설치된
vi,vim,nano텍스트 편집기를 사용하여 마스터 노드에서singers.py파일을 만듭니다.- 자리표시자 변수를
singers.py파일에 채운 후 다음 코드를singers.py파일에 붙여넣습니다. Spanner Data Boost 기능이 사용 설정되어 기본 Spanner 인스턴스에 거의 0에 가까운 영향을 줍니다.#!/usr/bin/env python """Spanner PySpark read example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-spanner-demo') \ .getOrCreate() # Load data from Spanner. singers = spark.read.format('cloud-spanner') \ .option("projectId", "PROJECT_ID") \ .option("instanceId", "INSTANCE_ID") \ .option("databaseId", "DATABASE_ID") \ .option("table", "TABLE_NAME") \ .option("enableDataBoost", "true") \ .load() singers.createOrReplaceTempView('Singers') # Read from Singers result = spark.sql('SELECT * FROM Singers') result.show() result.printSchema()
다음을 바꿉니다.
- PROJECT_ID: Google Cloud 프로젝트 ID입니다. 프로젝트 ID는 Google Cloud 콘솔 대시보드의 프로젝트 정보 섹션에 나열됩니다.
- INSTANCE_ID, DATABASE_ID, TABLE_NAME:
Singers데이터베이스 테이블이 있는 Spanner 인스턴스 설정을 참조하세요.
singers.py파일을 저장합니다.
- 자리표시자 변수를
spark-submit을 사용해서singers.py를 실행하여 SpannerSingers테이블을 만듭니다.spark-submit --jars gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar singers.py
다음을 바꿉니다.
- CONNECTOR_VERSION: Spanner 커넥터 버전.
GitHub
GoogleCloudDataproc/spark-spanner-connector저장소의 버전 목록에서 Spanner 커넥터 버전을 선택합니다.
출력은 다음과 같습니다.
... +--------+---------+--------+---------+-----------+ |SingerId|FirstName|LastName|BirthDate|LastUpdated| +--------+---------+--------+---------+-----------+ | 1| Marc|Richards| null| null| | 2| Catalina| Smith| null| null| | 3| Alice| Trentor| null| null| +--------+---------+--------+---------+-----------+ root |-- SingerId: long (nullable = false) |-- FirstName: string (nullable = true) |-- LastName: string (nullable = true) |-- BirthDate: date (nullable = true) |-- LastUpdated: timestamp (nullable = true) only showing top 20 rows
- CONNECTOR_VERSION: Spanner 커넥터 버전.
GitHub
Scala
클러스터에서 Scala 코드 예시를 실행하려면 다음 단계를 수행합니다.
- SSH를 사용하여 Managed Service for Apache Spark 클러스터 마스터 노드에 연결합니다.
- Google Cloud 콘솔에서 Managed Service for Apache Spark 클러스터 페이지로 이동한 다음 클러스터 이름을 클릭합니다.
- 클러스터 세부정보 페이지에서 VM 인스턴스 탭을 선택합니다. 그런 후 클러스터 마스터 노드 이름 오른쪽에 있는
SSH를 클릭합니다.
마스터 노드의 홈 디렉터리에 브라우저 창이 열립니다.
Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- 사전 설치된
vi,vim,nano텍스트 편집기를 사용하여 마스터 노드에서singers.scala파일을 만듭니다.- 다음 코드를
singers.scala파일에 붙여넣습니다. Spanner Data Boost 기능이 사용 설정되어 기본 Spanner 인스턴스에 거의 0에 가까운 영향을 줍니다.object singers { def main(): Unit = { /* * Uncomment (use the following code) if you are not running in spark-shell. * import org.apache.spark.sql.SparkSession val spark = SparkSession.builder() .appName("spark-spanner-demo") .getOrCreate() */ // Load data in from Spanner. See // https://github.com/GoogleCloudDataproc/spark-spanner-connector/blob/main/README.md#properties // for option information. val singersDF = (spark.read.format("cloud-spanner") .option("projectId", "PROJECT_ID") .option("instanceId", "INSTANCE_ID") .option("databaseId", "DATABASE_ID") .option("table", "TABLE_NAME") .option("enableDataBoost", true) .load() .cache()) singersDF.createOrReplaceTempView("Singers") // Load the Singers table. val result = spark.sql("SELECT * FROM Singers") result.show() result.printSchema() } }
다음을 바꿉니다.
- PROJECT_ID: Google Cloud 프로젝트 ID입니다. 프로젝트 ID는 Google Cloud 콘솔 대시보드의 프로젝트 정보 섹션에 나열됩니다.
- INSTANCE_ID, DATABASE_ID, TABLE_NAME:
Singers데이터베이스 테이블이 있는 Spanner 인스턴스 설정을 참조하세요.
singers.scala파일을 저장합니다.
- 다음 코드를
spark-shellREPL을 실행합니다.$ spark-shell --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar
다음을 바꿉니다.
CONNECTOR_VERSION: Spanner 커넥터 버전. GitHub
GoogleCloudDataproc/spark-spanner-connector저장소의 버전 목록에서 Spanner 커넥터 버전을 선택합니다.:load singers.scala명령어로singers.scala를 실행하여 SpannerSingers테이블을 만듭니다. 출력 목록에는 Singers 출력의 예시가 표시됩니다.> :load singers.scala Loading singers.scala... defined object singers > singers.main() ... +--------+---------+--------+---------+-----------+ |SingerId|FirstName|LastName|BirthDate|LastUpdated| +--------+---------+--------+---------+-----------+ | 1| Marc|Richards| null| null| | 2| Catalina| Smith| null| null| | 3| Alice| Trentor| null| null| +--------+---------+--------+---------+-----------+ root |-- SingerId: long (nullable = false) |-- FirstName: string (nullable = true) |-- LastName: string (nullable = true) |-- BirthDate: date (nullable = true) |-- LastUpdated: timestamp (nullable = true)
Spanner 그래프 읽기
Spanner 커넥터에서는 GraphFrames로 직접 내보내기는 물론 개별 노드 및 에지 DataFrames로 그래프 내보내기가 지원됩니다.
다음 예시에서는 Spanner를 GraphFrame으로 내보냅니다. 여기에서는 Spanner 커넥터 jar에 포함된 Python SpannerGraphConnector 클래스를 사용하여 Spanner Graph를 읽습니다.
from pyspark.sql import SparkSession connector_jar = "gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar" spark = (SparkSession.builder.appName("spanner-graphframe-graphx-example") .config("spark.jars.packages", "graphframes:graphframes:0.8.4-spark3.5-s_2.12") .config("spark.jars", connector_jar) .getOrCreate()) spark.sparkContext.addPyFile(connector_jar) from spannergraph import SpannerGraphConnector connector = (SpannerGraphConnector() .spark(spark) .project("PROJECT_ID") .instance("INSTANCE_ID") .database("DATABASE_ID") .graph("GRAPH_ID")) g = connector.load_graph() g.vertices.show() g.edges.show()
다음을 바꿉니다.
- CONNECTOR_VERSION: Spanner 커넥터 버전.
GitHub
GoogleCloudDataproc/spark-spanner-connector저장소의 버전 목록에서 Spanner 커넥터 버전을 선택합니다. - PROJECT_ID: Google Cloud 프로젝트 ID입니다. 프로젝트 ID는 Google Cloud 콘솔 대시보드의 프로젝트 정보 섹션에 나열됩니다.
- INSTANCE_ID, DATABASE_ID, TABLE_NAME: 인스턴스, 데이터베이스, 그래프 ID를 삽입합니다.
GraphFrames 대신 노드 및 에지 DataFrames를 내보내려면 load_dfs를 사용하세요.
df_vertices, df_edges, df_id_map = connector.load_dfs()
Spanner 테이블 쓰기
Spanner 커넥터는 Spark 데이터 소스 API를 사용하여 Spark Dataframe을 Spanner 테이블에 쓸 수 있도록 지원합니다.
DataFrame을 Spanner 테이블에 쓰는 예
코드를 저장하고 실행하기 전에 변수를 채웁니다.
"""Spanner PySpark write example.""" from pyspark.sql import SparkSession spark = SparkSession.builder.appName('Spanner Write App').getOrCreate() columns = ['id', 'name', 'email'] data = [(1, 'John Doe', 'john.doe@example.com'), (2, 'Jane Doe', 'jane.doe@example.com')] df = spark.createDataFrame(data, columns) df.write.format('cloud-spanner') \ .option("projectId", "PROJECT_ID") .option("instanceId", "INSTANCE_ID") .option("databaseId", "DATABASE_ID") .option("table", "TABLE_NAME") .mode("append") \ .save()
다음을 바꿉니다.
- PROJECT_ID: Google Cloud 프로젝트 ID입니다. 프로젝트 ID는 Google Cloud 콘솔 대시보드의 프로젝트 정보 섹션에 나열됩니다.
- INSTANCE_ID, DATABASE_ID, TABLE_NAME: 인스턴스, 데이터베이스, 테이블 ID를 삽입합니다.
삭제
Google Cloud 계정에 비용이 계속 청구되지 않도록 하려면 Managed Service for Apache Spark 클러스터를 중지하거나 삭제하고 Spanner 인스턴스를 삭제하면 됩니다.
다음 단계
pyspark.sql.DataFrame예시 참조하기- Spark DataFrame 언어 지원은 다음을 참조하세요.
- GitHub의 Spark Spanner Connector 저장소 참조하기
- Spark 작업 조정 팁 참조하기