
Questa pagina mostra come creare un cluster Managed Service for Apache Spark che utilizza il connettore Spark Spanner per leggere e scrivere dati da e in Spanner utilizzando Apache Spark.
Il connettore Spanner funziona con Spark per leggere e scrivere dati nel database Spanner utilizzando la libreria Java Spanner. Il connettore Spanner supporta la lettura di tabelle e grafici di Spanner in DataFrames e GraphFrames di Spark, nonché la scrittura di dati DataFrame nelle tabelle Spanner.
Costi
In questo documento vengono utilizzati i seguenti componenti fatturabili di Google Cloud:
- Managed Service for Apache Spark
- Spanner
- Cloud Storage
Per generare una stima dei costi in base all'utilizzo previsto,
utilizza il calcolatore prezzi.
Prima di iniziare
- Accedi al tuo account Google Cloud . Se non conosci Google Cloud, crea un account per valutare le prestazioni dei nostri prodotti in scenari reali. I nuovi clienti ricevono anche 300 $di crediti senza costi per l'esecuzione, il test e il deployment dei carichi di lavoro.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Spanner, Managed Service for Apache Spark, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Spanner, Managed Service for Apache Spark, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.- Concedi i ruoli richiesti.
- Configura un cluster Managed Service for Apache Spark.
- Configura un'istanza di Spanner con una tabella del database Singers.
Concedi i ruoli richiesti
Per eseguire gli esempi riportati in questa pagina sono necessari determinati ruoli IAM. A seconda delle norme dell'organizzazione, questi ruoli potrebbero essere già stati concessi. Per controllare le concessioni dei ruoli, consulta Devi concedere i ruoli?.
Per saperne di più sulla concessione dei ruoli, consulta Gestisci l'accesso a progetti, cartelle e organizzazioni.
Per assicurarti che il account di servizio predefinito di Compute Engine disponga delle autorizzazioni necessarie per creare un cluster Managed Service for Apache Spark, chiedi all'amministratore di concedere i seguenti ruoli IAM al account di servizio predefinito di Compute Engine sul progetto:
- Dataproc Worker (
roles/dataproc.worker) - Utente database Cloud Spanner (
roles/spanner.databaseUser) - Cloud Spanner Database Reader with DataBoost (
roles/spanner.databaseReaderWithDataBoost)
Configura un cluster Managed Service for Apache Spark
Crea un cluster Managed Service for Apache Spark
o utilizza un cluster Managed Service for Apache Spark esistente creato con l'immagine
2.1 o successiva di Managed Service for Apache Spark oppure, se il
cluster è stato creato con l'immagine 2.0 o precedente, deve essere stato creato con
la proprietà scope impostata sull'ambito cloud-platform.
Configura un'istanza Spanner con una tabella del database Singers
Crea un'istanza Spanner
con un database che contenga una tabella Singers. Prendi nota dell'ID istanza e dell'ID database Spanner.
Utilizzo del connettore Spanner con Spark
Il connettore Spanner è disponibile per le versioni di Spark 3.1+. Specifichi la versione del connettore come parte della specifica del file JAR del connettore Cloud Storage quando invii un job a un cluster Managed Service for Apache Spark.
Esempio: invio di job Spark con gcloud CLI con il connettore Spanner.
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar \ ... [other job submission flags]
Sostituisci quanto segue:
CONNECTOR_VERSION: versione del connettore Spanner.
Scegli la versione del connettore Spanner dall'elenco delle versioni nel repository GitHub
GoogleCloudDataproc/spark-spanner-connector.
Leggere le tabelle Spanner
Puoi utilizzare Python o Scala per leggere i dati delle tabelle Spanner in un DataFrame Spark utilizzando l'API Spark Data Source.
PySpark
Puoi eseguire il codice PySpark di esempio in questa sezione sul tuo cluster inviando il job a
Managed Service for Apache Spark o eseguendo il job dal REPL spark-submit
sul nodo master del cluster.
Job Managed Service for Apache Spark
- Crea un file
singers.pyutilizzando un editor di testo locale o in Cloud Shell utilizzando l'editor di testovi,vimonanopreinstallato. - Dopo aver compilato le variabili segnaposto, incolla il seguente codice
nel file
singers.py. Tieni presente che la funzionalità Spanner Data Boost è abilitata e ha un impatto quasi nullo sull'istanza Spanner principale.#!/usr/bin/env python """Spanner PySpark read example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-spanner-demo') \ .getOrCreate() # Load data from Spanner. singers = spark.read.format('cloud-spanner') \ .option("projectId", "PROJECT_ID") \ .option("instanceId", "INSTANCE_ID") \ .option("databaseId", "DATABASE_ID") \ .option("table", "TABLE_NAME") \ .option("enableDataBoost", "true") \ .load() singers.createOrReplaceTempView('Singers') # Read from Singers result = spark.sql('SELECT * FROM Singers') result.show() result.printSchema()
Sostituisci quanto segue:
- PROJECT_ID: l'ID progetto Google Cloud . Gli ID progetto sono elencati nella sezione Informazioni sul progetto della dashboard della console Google Cloud .
- INSTANCE_ID, DATABASE_ID e TABLE_NAME : consulta
Configurare un'istanza Spanner con la tabella del database
Singers.
- Salva il file
singers.py. - Invia il job
a Managed Service for Apache Spark utilizzando la console Google Cloud , gcloud CLI o
l'API REST.
Esempio:invio di job gcloud CLI con il connettore Spanner.
gcloud dataproc jobs submit pyspark singers.py \ --cluster=CLUSTER_NAME \ --region=REGION \ --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jarSostituisci quanto segue:
- CLUSTER_NAME: il nome del nuovo cluster.
- REGION: una regione di Compute Engine disponibile per eseguire il carico di lavoro.
- CONNECTOR_VERSION: versione del connettore Spanner.
Scegli la versione del connettore Spanner dall'elenco delle versioni nel repository GitHub
GoogleCloudDataproc/spark-spanner-connector.
Job spark-submit
- Connettiti al nodo master del cluster Managed Service for Apache Spark utilizzando SSH.
- Vai alla pagina Cluster di Managed Service for Apache Spark nella console Google Cloud , quindi fai clic sul nome del cluster.
- Nella pagina Dettagli cluster, seleziona la scheda Istanze VM. Quindi, fai clic su
SSHa destra del nome del nodo master del cluster.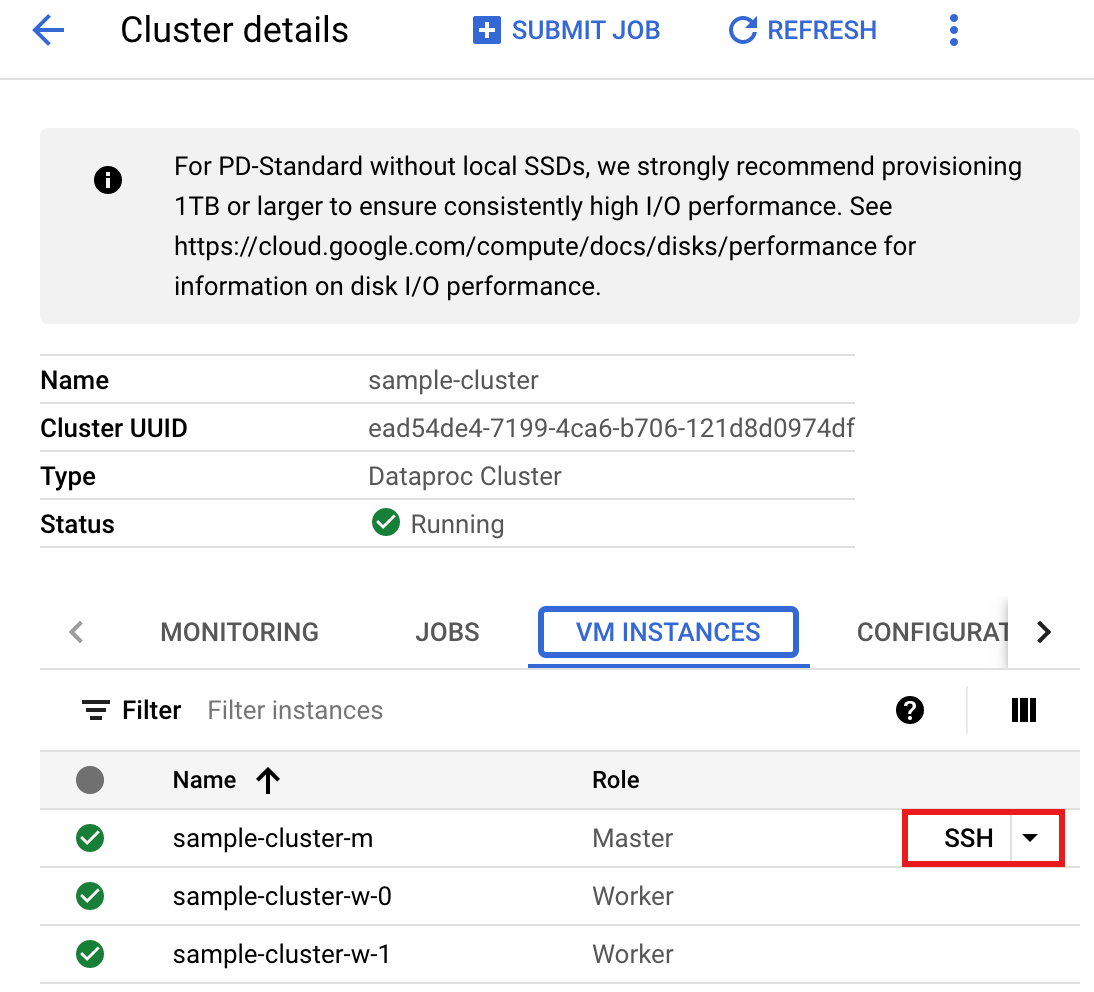
Si apre una finestra del browser nella directory home del nodo master.
Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Crea un file
singers.pysul nodo master utilizzando l'editor di testovi,vimonanopreinstallato.- Incolla il seguente codice nel file
singers.pydopo aver compilato le variabili segnaposto nel filesingers.py. Tieni presente che la funzionalità Spanner Data Boost è abilitata e ha un impatto quasi nullo sull'istanza Spanner principale.#!/usr/bin/env python """Spanner PySpark read example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-spanner-demo') \ .getOrCreate() # Load data from Spanner. singers = spark.read.format('cloud-spanner') \ .option("projectId", "PROJECT_ID") \ .option("instanceId", "INSTANCE_ID") \ .option("databaseId", "DATABASE_ID") \ .option("table", "TABLE_NAME") \ .option("enableDataBoost", "true") \ .load() singers.createOrReplaceTempView('Singers') # Read from Singers result = spark.sql('SELECT * FROM Singers') result.show() result.printSchema()
Sostituisci quanto segue:
- PROJECT_ID: l'ID progetto Google Cloud . Gli ID progetto sono elencati nella sezione Informazioni sul progetto della dashboard della console Google Cloud .
- INSTANCE_ID, DATABASE_ID e TABLE_NAME : consulta
Configurare un'istanza Spanner con la tabella del database
Singers.
- Salva il file
singers.py.
- Incolla il seguente codice nel file
- Esegui
singers.pyconspark-submitper creare la tabella SpannerSingers.spark-submit --jars gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar singers.py
Sostituisci quanto segue:
- CONNECTOR_VERSION: versione del connettore Spanner.
Scegli la versione del connettore Spanner dall'elenco delle versioni nel repository GitHub
GoogleCloudDataproc/spark-spanner-connector.
L'output è:
... +--------+---------+--------+---------+-----------+ |SingerId|FirstName|LastName|BirthDate|LastUpdated| +--------+---------+--------+---------+-----------+ | 1| Marc|Richards| null| null| | 2| Catalina| Smith| null| null| | 3| Alice| Trentor| null| null| +--------+---------+--------+---------+-----------+ root |-- SingerId: long (nullable = false) |-- FirstName: string (nullable = true) |-- LastName: string (nullable = true) |-- BirthDate: date (nullable = true) |-- LastUpdated: timestamp (nullable = true) only showing top 20 rows
- CONNECTOR_VERSION: versione del connettore Spanner.
Scegli la versione del connettore Spanner dall'elenco delle versioni nel repository GitHub
Scala
Per eseguire il codice Scala di esempio sul cluster, completa i seguenti passaggi:
- Connettiti al nodo master del cluster Managed Service for Apache Spark utilizzando SSH.
- Vai alla pagina Cluster di Managed Service for Apache Spark nella console Google Cloud , quindi fai clic sul nome del cluster.
- Nella pagina Dettagli cluster, seleziona la scheda Istanze VM. Quindi, fai clic su
SSHa destra del nome del nodo master del cluster.
Si apre una finestra del browser nella directory home del nodo master.
Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Crea un file
singers.scalasul nodo master utilizzando l'editor di testovi,vimonanopreinstallato.- Incolla il seguente codice nel file
singers.scala. Tieni presente che la funzionalità Spanner Data Boost è abilitata e ha un impatto quasi nullo sull'istanza Spanner principale.object singers { def main(): Unit = { /* * Uncomment (use the following code) if you are not running in spark-shell. * import org.apache.spark.sql.SparkSession val spark = SparkSession.builder() .appName("spark-spanner-demo") .getOrCreate() */ // Load data in from Spanner. See // https://github.com/GoogleCloudDataproc/spark-spanner-connector/blob/main/README.md#properties // for option information. val singersDF = (spark.read.format("cloud-spanner") .option("projectId", "PROJECT_ID") .option("instanceId", "INSTANCE_ID") .option("databaseId", "DATABASE_ID") .option("table", "TABLE_NAME") .option("enableDataBoost", true) .load() .cache()) singersDF.createOrReplaceTempView("Singers") // Load the Singers table. val result = spark.sql("SELECT * FROM Singers") result.show() result.printSchema() } }
Sostituisci quanto segue:
- PROJECT_ID: l'ID progetto Google Cloud . Gli ID progetto sono elencati nella sezione Informazioni sul progetto della dashboard della console Google Cloud .
- INSTANCE_ID, DATABASE_ID e TABLE_NAME : consulta
Configurare un'istanza Spanner con la tabella del database
Singers.
- Salva il file
singers.scala.
- Incolla il seguente codice nel file
- Avvia il REPL
spark-shell.$ spark-shell --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar
Sostituisci quanto segue:
CONNECTOR_VERSION: versione del connettore Spanner. Scegli la versione del connettore Spanner dall'elenco delle versioni nel repository GitHub
GoogleCloudDataproc/spark-spanner-connector. - Esegui
singers.scalacon il comando:load singers.scalaper creare la tabella SpannerSingers. L'elenco dell'output mostra esempi dell'output di Singers.> :load singers.scala Loading singers.scala... defined object singers > singers.main() ... +--------+---------+--------+---------+-----------+ |SingerId|FirstName|LastName|BirthDate|LastUpdated| +--------+---------+--------+---------+-----------+ | 1| Marc|Richards| null| null| | 2| Catalina| Smith| null| null| | 3| Alice| Trentor| null| null| +--------+---------+--------+---------+-----------+ root |-- SingerId: long (nullable = false) |-- FirstName: string (nullable = true) |-- LastName: string (nullable = true) |-- BirthDate: date (nullable = true) |-- LastUpdated: timestamp (nullable = true)
Leggi i grafici Spanner
Il connettore Spanner supporta l'esportazione del grafico in DataFrames separati per nodi e archi, nonché l'esportazione direttamente in GraphFrames.
L'esempio seguente esporta un database Spanner in un file GraphFrame. Utilizza
la classe Python SpannerGraphConnector, inclusa nel
file JAR del connettore Spanner, per leggere
Spanner Graph.
from pyspark.sql import SparkSession connector_jar = "gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar" spark = (SparkSession.builder.appName("spanner-graphframe-graphx-example") .config("spark.jars.packages", "graphframes:graphframes:0.8.4-spark3.5-s_2.12") .config("spark.jars", connector_jar) .getOrCreate()) spark.sparkContext.addPyFile(connector_jar) from spannergraph import SpannerGraphConnector connector = (SpannerGraphConnector() .spark(spark) .project("PROJECT_ID") .instance("INSTANCE_ID") .database("DATABASE_ID") .graph("GRAPH_ID")) g = connector.load_graph() g.vertices.show() g.edges.show()
Sostituisci quanto segue:
- CONNECTOR_VERSION: versione del connettore Spanner.
Scegli la versione del connettore Spanner dall'elenco delle versioni nel repository GitHub
GoogleCloudDataproc/spark-spanner-connector. - PROJECT_ID: l'ID progetto Google Cloud . Gli ID progetto sono elencati nella sezione Informazioni sul progetto della dashboard della console Google Cloud .
- INSTANCE_ID, DATABASE_ID e TABLE_NAME Inserisci gli ID istanza, database e grafico.
Per esportare nodi e archi DataFrames anziché GraphFrames, utilizza load_dfs:
df_vertices, df_edges, df_id_map = connector.load_dfs()
Scrivere tabelle Spanner
Il connettore Spanner supporta la scrittura di un DataFrame Spark in una tabella Spanner utilizzando l'API di origine dati Spark.
Esempio di scrittura di DataFrame nella tabella Spanner
Compila le variabili prima di salvare ed eseguire il codice.
"""Spanner PySpark write example.""" from pyspark.sql import SparkSession spark = SparkSession.builder.appName('Spanner Write App').getOrCreate() columns = ['id', 'name', 'email'] data = [(1, 'John Doe', 'john.doe@example.com'), (2, 'Jane Doe', 'jane.doe@example.com')] df = spark.createDataFrame(data, columns) df.write.format('cloud-spanner') \ .option("projectId", "PROJECT_ID") .option("instanceId", "INSTANCE_ID") .option("databaseId", "DATABASE_ID") .option("table", "TABLE_NAME") .mode("append") \ .save()
Sostituisci quanto segue.
- PROJECT_ID: l' Google Cloud ID progetto. Gli ID progetto sono elencati nella sezione Informazioni sul progetto della dashboard della console Google Cloud .
- INSTANCE_ID, DATABASE_ID e TABLE_NAME Inserisci gli ID di istanza, database e tabella.
Esegui la pulizia
Per evitare di incorrere in addebiti continui sul tuo account Google Cloud , puoi interrompere o eliminare il tuo cluster Managed Service for Apache Spark ed eliminare l'istanza Spanner.
Passaggi successivi
- Fai riferimento agli
esempi di
pyspark.sql.DataFrame. - Per il supporto delle lingue per Spark DataFrame, consulta quanto segue:
- Consulta il repository Spark Spanner Connector su GitHub.
- Consulta i suggerimenti per l'ottimizzazione del job Spark.