
Obiettivi
Questo tutorial mostra come installare il componente Jupyter di Managed Service for Apache Spark su un nuovo cluster e poi connetterti all'interfaccia utente del notebook Jupyter in esecuzione sul cluster dal browser locale utilizzando il gateway dei componenti di Managed Service for Apache Spark.
Google CloudCosti
In questo documento vengono utilizzati i seguenti componenti fatturabili di Google Cloud:
Per generare una stima dei costi in base all'utilizzo previsto,
utilizza il calcolatore prezzi.
Prima di iniziare
Se non l'hai ancora fatto, crea un Google Cloud progetto e un bucket Cloud Storage .
Configurazione del progetto
- Accedi al tuo Google Cloud account. Se non hai mai utilizzato Google Cloud, crea un account per valutare le prestazioni dei nostri prodotti in scenari reali. I nuovi clienti ricevono anche 300 $di crediti senza costi per l'esecuzione, il test e il deployment dei carichi di lavoro.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.-
Installa Google Cloud CLI.
-
Se utilizzi un provider di identità (IdP) esterno, devi prima accedere a gcloud CLI con la tua identità federata.
-
Per inizializzare gcloud CLI, esegui questo comando:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.-
Installa Google Cloud CLI.
-
Se utilizzi un provider di identità (IdP) esterno, devi prima accedere a gcloud CLI con la tua identità federata.
-
Per inizializzare gcloud CLI, esegui questo comando:
gcloud init
Crea un bucket Cloud Storage nel tuo progetto per archiviare i notebook che crei in questo tutorial.
- Nella Google Cloud console, vai alla pagina Bucket in Cloud Storage.
- Fai clic su Crea.
- Nella pagina Crea un bucket, inserisci le informazioni del bucket. Per passare al passaggio successivo, fai clic su Continua.
-
Nella sezione Inizia, procedi nel seguente modo:
- Inserisci un nome globalmente univoco che soddisfi i requisiti di denominazione dei bucket.
- Per aggiungere un'
etichetta del bucket,
espandi la sezione Etichette (),
fai clic su add_box
Aggiungi etichetta e specifica una
keye unvalueper l'etichetta.
-
Nella sezione Scegli dove archiviare i tuoi dati, procedi nel seguente modo:
- Seleziona un tipo di località.
- Scegli una località in cui i dati del bucket vengono archiviati in modo permanente dal menu a discesa Tipo di località.
- Se selezioni il tipo di località a doppia regione, puoi anche scegliere di abilitare la replica turbo utilizzando la casella di controllo pertinente.
- Per configurare la replica tra bucket, seleziona
Aggiungi una replica tra bucket mediante Storage Transfer Service e
segui questi passaggi:
Configura la replica tra bucket
- Nel menu Bucket, seleziona un bucket.
Nella sezione Impostazioni di replica , fai clic su Configura per configurare le impostazioni del job di replica.
Viene visualizzato il riquadro Configura replica tra bucket.
- Per filtrare gli oggetti da replicare in base al prefisso del nome dell'oggetto, inserisci un prefisso da includere o escludere gli oggetti, quindi fai clic su Aggiungi un prefisso.
- Per impostare una classe di archiviazione per gli oggetti replicati, seleziona una classe di archiviazione dal menu Classe di archiviazione. Se salti questo passaggio, gli oggetti replicati utilizzeranno per impostazione predefinita la classe di archiviazione del bucket di destinazione.
- Fai clic su Fine.
-
Nella sezione Scegli come archiviare i tuoi dati, procedi nel seguente modo:
- Seleziona una classe di archiviazione predefinita per il bucket o Autoclass per la gestione automatica della classe di archiviazione dei dati del bucket.
- Per abilitare lo spazio dei nomi gerarchico, nella sezione Ottimizza l'archiviazione per i carichi di lavoro con uso intensivo dei dati, seleziona Abilita uno spazio dei nomi gerarchico in questo bucket.
- Nella sezione Scegli come controllare l'accesso agli oggetti, seleziona se il bucket applica o meno la prevenzione dell'accesso pubblico, e seleziona un metodo di controllo dell'accesso per gli oggetti del bucket.
-
Nella sezione Scegli come proteggere i dati degli oggetti, procedi nel seguente modo:
- Seleziona una delle opzioni in Protezione dei dati che vuoi impostare per il bucket.
- Per abilitare l'eliminazione temporanea, fai clic sulla casella di controllo Policy di eliminazione temporanea (per il recupero dei dati) e specifica il numero di giorni per cui vuoi conservare gli oggetti dopo l'eliminazione.
- Per impostare il controllo delle versioni degli oggetti, fai clic sulla casella di controllo Controllo delle versioni degli oggetti (per il controllo delle versioni) e specifica il numero massimo di versioni per oggetto e il numero di giorni dopo i quali le versioni non correnti scadono.
- Per abilitare la policy di conservazione su oggetti e bucket, fai clic sulla casella di controllo Conservazione (per la conformità) e poi procedi nel seguente modo:
- Per abilitare il blocco della conservazione degli oggetti, fai clic sulla casella di controllo Abilita conservazione degli oggetti.
- Per abilitare il blocco dei bucket, fai clic sulla casella di controllo Imposta policy di conservazione dei bucket e scegli un'unità di tempo e una durata per il periodo di conservazione.
- Per scegliere come criptare i dati degli oggetti, espandi la la sezione Criptaggio dei dati () e seleziona un metodo di criptaggio dei dati.
- Seleziona una delle opzioni in Protezione dei dati che vuoi impostare per il bucket.
-
Nella sezione Inizia, procedi nel seguente modo:
- Fai clic su Crea. I notebook verranno archiviati in Cloud Storage in
gs://bucket-name/notebooks/jupyter.
Crea un cluster e installa il componente Jupyter
Crea un cluster con il componente Jupyter installato.
Apri le interfacce utente di Jupyter e JupyterLab
Fai clic sui link del gateway dei componenti della Google Cloud console nella Google Cloud console per aprire le interfacce utente del notebook Jupyter o di JupyterLab in esecuzione sul cluster.
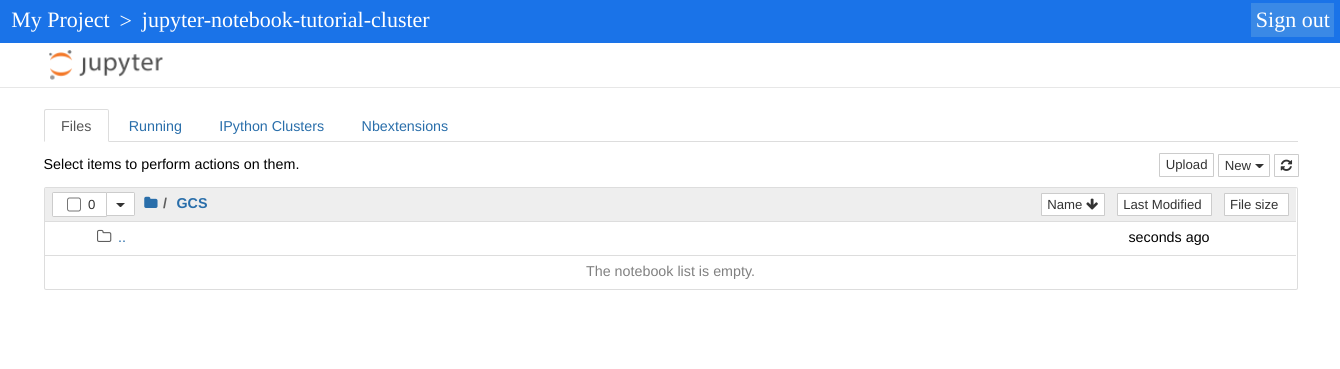
La directory di primo livello visualizzata dall'istanza Jupyter è una directory virtuale che ti consente di visualizzare i contenuti del bucket Cloud Storage o del file system locale. Puoi scegliere una delle due località facendo clic sul link GCS per Cloud Storage o Disco locale per il file system locale del nodo master nel cluster.
- Fai clic sul link GCS. L'interfaccia utente web del notebook Jupyter mostra
i notebook archiviati nel bucket Cloud Storage, inclusi eventuali
notebook che crei in questa esercitazione.
Esegui la pulizia
Al termine del tutorial, puoi eliminare le risorse che hai creato in modo che non utilizzino più la quota generando addebiti. Le seguenti sezioni descrivono come eliminare o disattivare queste risorse.
Elimina il progetto
Il modo più semplice per eliminare la fatturazione è eliminare il progetto creato per il tutorial.
Per eliminare il progetto:
- Nella Google Cloud console, vai alla pagina Gestisci risorse.
- Nell'elenco dei progetti, seleziona il progetto che vuoi eliminare, quindi fai clic su Elimina.
- Nella finestra di dialogo, digita l'ID progetto, quindi fai clic su Chiudi per eliminare il progetto.
Elimina il cluster
- Per eliminare il cluster:
gcloud dataproc clusters delete cluster-name \ --region=${REGION}
Elimina il bucket
- Per eliminare il bucket Cloud Storage che hai creato nel
passaggio 2 della sezione Prima di iniziare, inclusi i notebook
archiviati nel bucket:
gcloud storage rm gs://${BUCKET_NAME} --recursive
Passaggi successivi
- Gestisci il ciclo di vita del carico di lavoro dei dati in VS Code utilizzando Google Cloud Data Agent Kit
- Crea pipeline di dati con Data Agent Kit
- Consulta la guida rapida per notebook Jupyter/IPython