
提交 Managed Service for Apache Spark 作业后, Managed Service for Apache Spark 会自动收集 作业输出,并将其提供给您。这意味着,您可以快速查看作业输出,而无需在作业运行时保持与集群的连接,或查看复杂的日志文件。
Spark 日志
Spark 日志有两种类型:Spark 驱动程序日志和 Spark 执行器日志。
Spark 驱动程序日志包含作业输出;Spark
执行器日志包含作业可执行文件或启动器输出,例如 spark-submit“Submitted application ... ”消息,有助于调试作业失败问题。
Managed Service for Apache Spark 作业驱动程序(与 Spark 驱动程序不同)是许多作业类型的启动器。在启动
Spark 作业时,它会作为底层 spark-submit 可执行文件的封装容器运行,该可执行文件可启动 Spark 驱动程序。Spark 驱动程序在 Spark
client 或 cluster 模式下在 Managed Service for Apache Spark 集群上运行作业:
client模式:Spark 驱动程序在spark-submit进程中运行作业,Spark 日志会发送到 Managed Service for Apache Spark 作业驱动程序。cluster模式:Spark 驱动程序在 YARN 容器中运行作业。Managed Service for Apache Spark 作业驱动程序无法使用 Spark 驱动程序日志。
Managed Service for Apache Spark 和 Spark 作业属性概览
| 属性 | 值 | 默认值 | 说明 |
|---|---|---|---|
dataproc:dataproc.logging.stackdriver.job.driver.enable |
true 或 false | false | 必须在创建集群时设置。值为 true 时,作业驱动程序输出位于 Logging 中,与作业资源相关联;值为 false 时,作业驱动程序输出不在 Logging 中。注意:如需在 Logging 中启用作业驱动程序日志,还需要设置以下集群属性,这些属性会在创建集群时默认设置: dataproc:dataproc.logging.stackdriver.enable=true 和 dataproc:jobs.file-backed-output.enable=true
|
dataproc:dataproc.logging.stackdriver.job.yarn.container.enable |
true 或 false | false | 必须在创建集群时设置。
值为 true 时,作业 YARN 容器日志会与作业资源相关联;值为 false 时,作业 YARN 容器日志会与集群资源相关联。 |
spark:spark.submit.deployMode |
client 或 cluster | 客户端 | 控制 Spark client 或 cluster 模式。 |
使用 Managed Service for Apache Spark jobs API 提交的 Spark 作业
本部分中的表列出了在通过 Managed Service for Apache Spark jobs API 提交作业(包括通过
Google Cloud 控制台、gcloud CLI 和 Cloud 客户端库提交作业)时,不同的属性设置对
Managed Service for Apache Spark 作业驱动程序输出目标位置的影响。
创建集群时,可以使用 --properties 标志设置列出的 Managed Service for Apache Spark 和 Spark 属性
,这些属性会应用于在集群上运行的所有 Spark 作业;在作业提交到 Managed Service for Apache Spark jobs API 后,也可以使用
--properties 标志(不带“spark:”前缀)设置 Spark 属性,这些属性仅应用于该作业。
Managed Service for Apache Spark 作业驱动程序输出
下表列出了不同的属性设置对 Managed Service for Apache Spark 作业驱动程序输出目标位置的影响。
dataproc: |
输出 |
|---|---|
| false(默认) |
|
| true |
|
Spark 驱动程序日志
下表列出了不同的属性设置对 Spark 驱动程序日志目标位置的影响。
spark: |
dataproc: |
dataproc: |
驱动程序输出 |
|---|---|---|---|
| 客户端 | false(默认) | true 或 false |
|
| 客户端 | true | true 或 false |
|
| 集群 | false(默认) | false |
|
| 集群 | true | true |
|
Spark 执行器日志
下表列出了不同的属性设置对 Spark 执行器日志目标位置的影响。
dataproc: |
执行器日志 |
|---|---|
| false(默认) | 在 Logging yarn-userlogs 中的集群资源下 |
| true | 在 Logging 中的作业资源下:dataproc.job.yarn.container |
不使用 Managed Service for Apache Spark jobs API 提交的 Spark 作业
本部分列出了在不使用 Managed Service for Apache Spark jobs API 提交作业(例如,使用 spark-submit
直接在集群节点上提交作业,或者使用 Jupyter 或 Zeppelin 笔记本)时,不同的属性设置对 Spark
作业日志目标位置的影响。这些作业没有 Managed Service for Apache Spark 作业 ID 或驱动程序。
Spark 驱动程序日志
下表列出了不同的属性设置对不通过 Managed Service for Apache Spark jobs API 提交的作业的 Spark
驱动程序日志目标位置的影响。
spark: |
驱动程序输出 |
|---|---|
| 客户端 |
|
| 集群 |
|
Spark 执行器日志
如果 Spark 作业不通过 Managed Service for Apache Spark jobs API 提交,则执行器日志位于 Logging
中的集群资源下:yarn-userlogs。
查看作业输出
您可以在 Google Cloud 控制台、 gcloud CLI、Cloud Storage 或 Logging 中访问 Managed Service for Apache Spark 作业输出。
控制台
如需查看作业输出,请前往项目的 Managed Service for Apache Spark 作业 部分,然后点击 任务 ID 以查看作业输出。
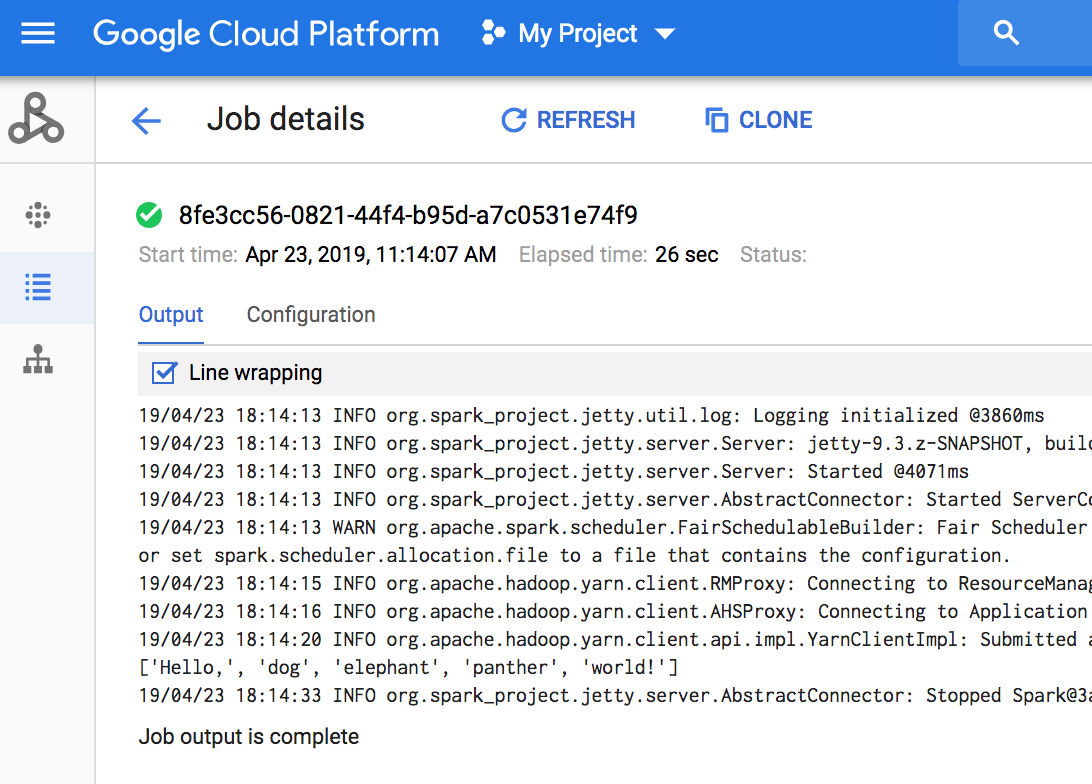
如果作业正在运行,则作业输出会定期刷新以显示 新内容。
gcloud 命令
当您使用 gcloud dataproc jobs submit 命令提交作业时,作业输出会显示在控制台上。通过将作业 ID 传递给 gcloud dataproc jobs wait 命令,您可以稍后在其他计算机上或在新窗口中“重新加入”输出。作业 ID 是 GUID,例如 5c1754a5-34f7-4553-b667-8a1199cb9cab。示例如下:
gcloud dataproc jobs wait 5c1754a5-34f7-4553-b667-8a1199cb9cab \ --project my-project-id --region my-cluster-region
Waiting for job output... ... INFO gcs.GoogleHadoopFileSystemBase: GHFS version: 1.4.2-hadoop2 ... 16:47:45 INFO client.RMProxy: Connecting to ResourceManager at my-test-cluster-m/ ...
Cloud Storage
作业输出存储在 Cloud Storage 中的暂存存储桶或创建集群时指定的存储桶中。以下项返回的 Job.driverOutputResourceUri 字段中提供了 Cloud Storage 中作业输出的链接:
- jobs.get API 请求。
- gcloud dataproc jobs describe job-id 命令。
$ gcloud dataproc jobs describe spark-pi ... driverOutputResourceUri: gs://dataproc-nnn/jobs/spark-pi/driveroutput ...