
Saat Anda mengirimkan tugas Managed Service untuk Apache Spark, Managed Service untuk Apache Spark akan otomatis mengumpulkan output tugas dan membuatnya dapat diakses. Artinya, Anda dapat meninjau output tugas dengan cepat tanpa harus mempertahankan koneksi ke cluster saat tugas Anda berjalan atau menelusuri file log yang rumit.
Log Spark
Ada dua jenis log Spark: log driver Spark dan log eksekutor Spark.
Log driver Spark berisi output dari tugas, sedangkan log eksekutor Spark berisi output dari proses eksekusi atau peluncuran tugas, seperti pesan "Submitted application ... " spark-submit. Log ini sangat berguna untuk melakukan proses debug pada kegagalan tugas.
Driver tugas Managed Service untuk Apache Spark, yang berbeda dari driver Spark, adalah peluncur untuk berbagai jenis tugas. Saat meluncurkan tugas Spark, Dataproc bekerja sebagai wrapper pada file spark-submit yang dapat dieksekusi, yang kemudian meluncurkan driver Spark. Driver Spark menjalankan tugas di cluster Managed Service untuk Apache Spark dalam mode Spark
client atau cluster mode:
Mode
client: driver Spark menjalankan tugas dalam prosesspark-submit, dan log Spark dikirim ke driver tugas Managed Service untuk Apache Spark.Mode
cluster: driver Spark menjalankan tugas dalam container YARN. Log driver Spark tidak tersedia untuk driver tugas Managed Service untuk Apache Spark.
Ringkasan properti tugas Managed Service untuk Apache Spark dan Spark
| Properti | Nilai | Default | Deskripsi |
|---|---|---|---|
dataproc:dataproc.logging.stackdriver.job.driver.enable |
true atau false | false | Harus ditetapkan pada saat pembuatan cluster. Jika true,
output driver tugas akan ada di Logging,
terhubung dengan resource tugas; Jika false, output driver
tugas tidak akan ada di Logging.Catatan: Setelan properti cluster berikut juga diperlukan untuk mengaktifkan log driver tugas di Logging, dan ditetapkan secara default saat cluster dibuat: dataproc:dataproc.logging.stackdriver.enable=true
dan dataproc:jobs.file-backed-output.enable=true
|
dataproc:dataproc.logging.stackdriver.job.yarn.container.enable |
true atau false | false | Harus ditetapkan pada saat pembuatan cluster.
Jika true, log container YARN tugas akan dikaitkan
dengan resource tugas; jika false, log container YARN tugas
akan dikaitkan dengan resource cluster. |
spark:spark.submit.deployMode |
client atau cluster | client | Mengontrol mode Spark client atau cluster. |
Tugas Spark yang dikirimkan menggunakan Managed Service untuk Apache Spark jobs API
Tabel di bagian ini mencantumkan pengaruh berbagai setelan properti pada
tujuan output driver tugas Managed Service untuk Apache Spark saat tugas dikirimkan
melalui Managed Service untuk Apache Spark jobs API, yang mencakup pengiriman tugas melalui
Google Cloud konsol, gcloud CLI, dan Library Klien Cloud.
Properti Managed Service untuk Apache Spark dan Spark
yang tercantum dapat ditetapkan dengan flag --properties saat cluster dibuat, dan akan berlaku
untuk semua tugas Spark yang dijalankan di cluster. Properti Spark juga dapat ditetapkan dengan flag
--properties (tanpa awalan "spark:") saat tugas
dikirimkan ke Managed Service untuk Apache Spark jobs API, dan hanya akan berlaku untuk tugas tersebut.
Output driver tugas Managed Service untuk Apache Spark
Tabel berikut mencantumkan pengaruh berbagai setelan properti pada tujuan output driver tugas Managed Service untuk Apache Spark.
dataproc: |
Output |
|---|---|
| false (default) |
|
| true |
|
Log driver Spark
Tabel berikut mencantumkan pengaruh berbagai setelan properti pada tujuan log driver Spark.
spark: |
dataproc: |
dataproc: |
Output Driver |
|---|---|---|---|
| client | false (default) | true atau false |
|
| client | true | true atau false |
|
| cluster | false (default) | false |
|
| cluster | true | true |
|
Log eksekutor Spark
Tabel berikut mencantumkan pengaruh berbagai setelan properti pada tujuan log eksekutor Spark.
dataproc: |
Log eksekutor |
|---|---|
| false (default) | Di Logging: yarn-userlogs di bagian resource cluster |
| true | Di Logging dataproc.job.yarn.container di bagian resource tugas |
Tugas Spark yang dikirimkan tanpa menggunakan Managed Service untuk Apache Spark jobs API
Bagian ini mencantumkan pengaruh berbagai setelan properti pada tujuan log tugas Spark saat tugas dikirimkan tanpa menggunakan Managed Service untuk Apache Spark jobs API, misalnya saat mengirimkan tugas langsung di node cluster menggunakan spark-submit atau saat menggunakan notebook Jupyter atau Zeppelin. Tugas ini tidak memiliki ID tugas atau driver Managed Service untuk Apache Spark.
Log driver Spark
Tabel berikut mencantumkan pengaruh berbagai setelan properti pada tujuan log driver Spark untuk tugas yang tidak dikirimkan melalui Managed Service untuk Apache Spark jobs API.
spark: |
Output Driver |
|---|---|
| client |
|
| cluster |
|
Log eksekutor Spark
Jika tugas Spark tidak dikirimkan melalui Managed Service untuk Apache Spark jobs API, log eksekutor akan berada di Logging yarn-userlogs di bagian resource cluster.
Melihat output tugas
Anda dapat mengakses output tugas Managed Service untuk Apache Spark di Google Cloud konsol, gcloud CLI, Cloud Storage, atau Logging.
Konsol
Untuk melihat output tugas, buka bagian Jobs Managed Service untuk Apache Spark project Anda, lalu klik ID pekerjaan untuk melihat output tugas.
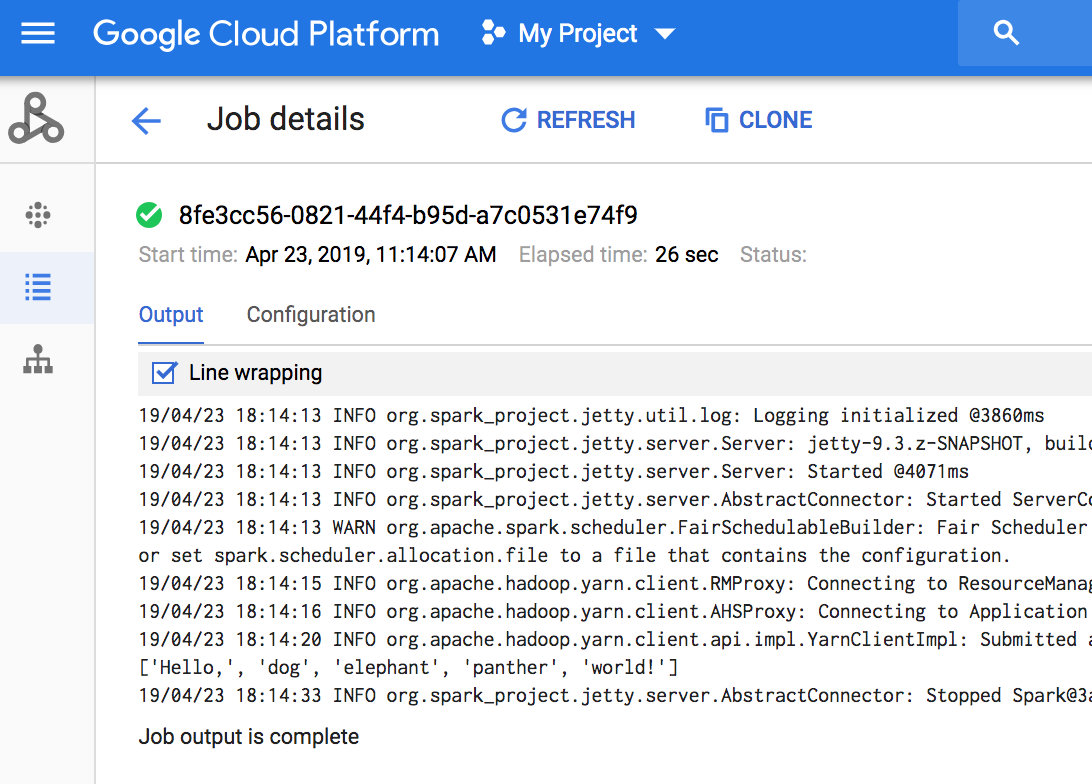
Jika tugas sedang berjalan, output tugas akan diperbarui secara berkala dengan konten baru.
perintah gcloud
Saat Anda mengirimkan tugas dengan perintah gcloud dataproc jobs submit, output tugas akan ditampilkan di konsol. Anda dapat "bergabung kembali"
dengan output tersebut di lain waktu, dari komputer yang berbeda, atau di
jendela baru dengan meneruskan ID tugas ke perintah
gcloud dataproc jobs wait. ID Tugas adalah GUID, seperti 5c1754a5-34f7-4553-b667-8a1199cb9cab. Berikut contohnya.
gcloud dataproc jobs wait 5c1754a5-34f7-4553-b667-8a1199cb9cab \ --project my-project-id --region my-cluster-region
Waiting for job output... ... INFO gcs.GoogleHadoopFileSystemBase: GHFS version: 1.4.2-hadoop2 ... 16:47:45 INFO client.RMProxy: Connecting to ResourceManager at my-test-cluster-m/ ...
Cloud Storage
Output tugas disimpan di Cloud Storage di bucket staging atau bucket yang Anda tentukan saat membuat cluster. Link ke output tugas di Cloud Storage tersedia di kolom Job.driverOutputResourceUri yang ditampilkan oleh:
- permintaan API jobs.get.
- perintah gcloud dataproc jobs describe
job-id.
$ gcloud dataproc jobs describe spark-pi ... driverOutputResourceUri: gs://dataproc-nnn/jobs/spark-pi/driveroutput ...