
Spark 및 Lakehouse 런타임 카탈로그로 레이크하우스 만들기
레이크하우스 아키텍처는 데이터 레이크의 유연성과 데이터 웨어하우스의 데이터 관리 기능을 결합합니다. 이 문서에서는 Google Cloud에서 레이크하우스를 설정하는 방법을 설명합니다. Apache Iceberg를 테이블 형식으로, Managed Service for Apache Spark를 처리용으로, Lakehouse 런타임 카탈로그 Iceberg REST 카탈로그를 통합 메타데이터 관리용으로 사용합니다.
이 아키텍처는 Iceberg와 같은 개방형 테이블 형식을 사용하여 Cloud Storage의 데이터에 트랜잭션 및 스키마 변경과 같은 데이터 웨어하우징 기능을 추가합니다. 이 접근 방식을 사용하면 다양한 엔진에서 액세스할 수 있는 데이터의 단일 정보 소스가 생성됩니다.
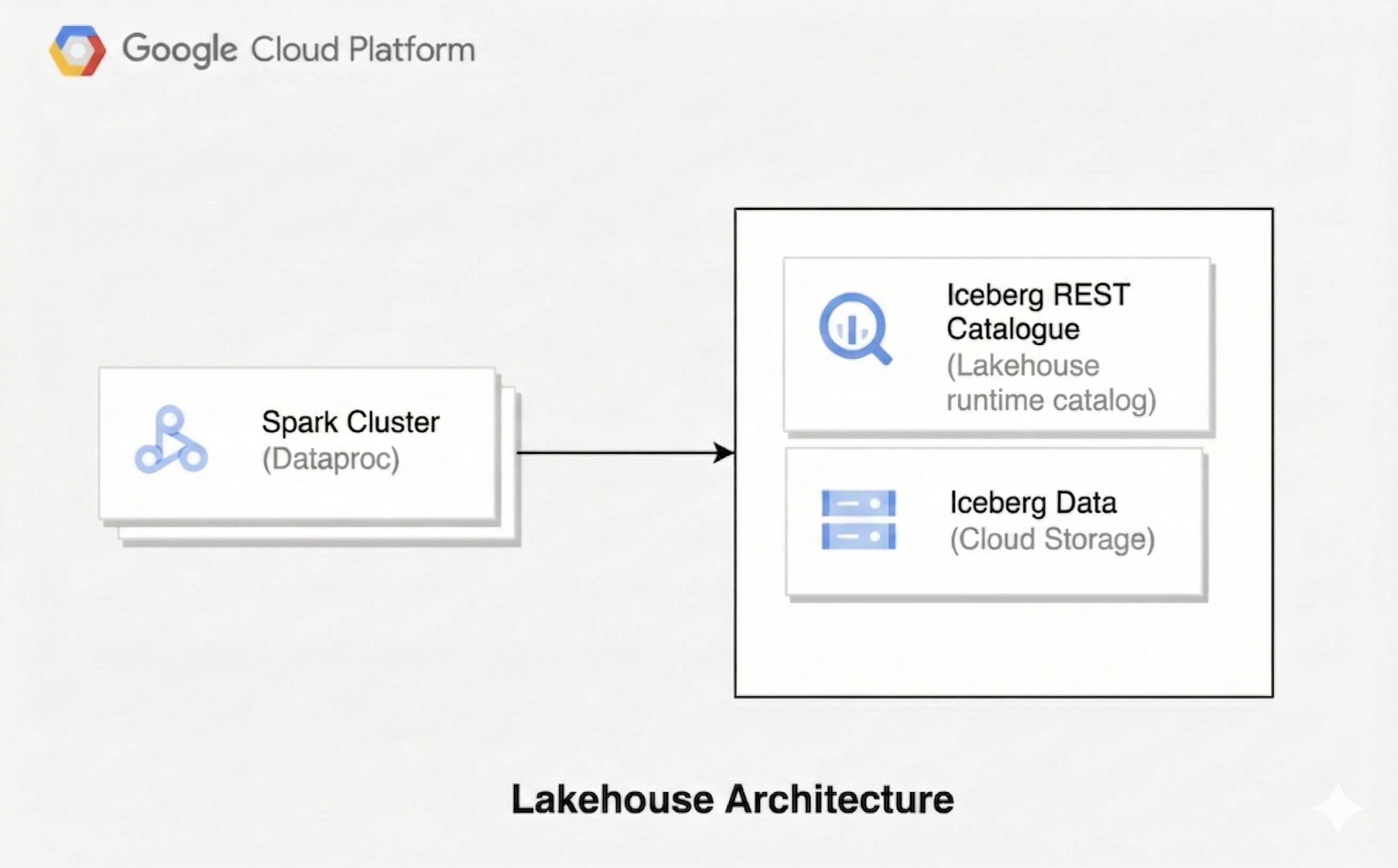
시작하기 전에
- Google Cloud 계정에 로그인합니다. Google Cloud를 처음 사용하는 경우 계정을 만들고 Google 제품의 실제 성능을 평가해 보세요. 신규 고객에게는 워크로드를 실행, 테스트, 배포하는 데 사용할 수 있는 $300의 무료 크레딧이 제공됩니다.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that you have the permissions required to complete this guide.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that you have the permissions required to complete this guide.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.- Iceberg 데이터를 저장할 Cloud Storage 버킷을 만듭니다.
필요한 역할
이 페이지의 예시를 실행하려면 특정 Identity and Access Management (IAM) 역할이 필요합니다. 조직 정책에 따라 이러한 역할이 이미 부여되었을 수 있습니다. 역할 부여를 확인하려면 역할을 부여해야 하나요?를 참고하세요.
역할 부여에 대한 자세한 내용은 프로젝트, 폴더, 조직에 대한 액세스 관리를 참고하세요.
사용자 역할
Managed Service for Apache Spark 클러스터를 만드는 데 필요한 권한을 얻으려면 관리자에게 다음 IAM 역할을 부여해 달라고 요청하세요.
- 프로젝트에 대한 Dataproc 편집자 (
roles/dataproc.editor) - Compute Engine 기본 서비스 계정의 서비스 계정 사용자 (
roles/iam.serviceAccountUser)
서비스 계정 역할
Compute Engine 기본 서비스 계정에 Apache Spark용 관리 서비스를 만드는 데 필요한 권한이 있는지 확인하려면 관리자에게 프로젝트에 대한 Dataproc 작업자 (roles/dataproc.worker) IAM 역할을 Compute Engine 기본 서비스 계정에 부여해 달라고 요청하세요.
Managed Service for Apache Spark 클러스터 만들기
Iceberg 및 Jupyter 선택적 구성요소가 포함된 Managed Service for Apache Spark 클러스터를 만듭니다.
클러스터를 만들려면 다음
gcloud명령어를 실행합니다.gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT_ID \ --region=REGION \ --image-version=2.3-debian12 \ --optional-components=ICEBERG,JUPYTER \ --enable-component-gateway \ --properties 'dataproc:dataproc.lineage.enabled=true'다음을 바꿉니다.
CLUSTER_NAME: 클러스터 이름입니다.PROJECT_ID: Google Cloud 프로젝트 ID입니다.REGION: 클러스터의 Google Cloud 리전(예:us-central1)
dataproc:dataproc.lineage.enabled=true설정은 Lakehouse 런타임 카탈로그 Iceberg REST 카탈로그가 올바르게 작동하는 데 필요하지 않습니다. 아래의 데이터 계보 예시에서 계보 추적을 위해 추가되었습니다.Jupyter 노트북을 사용하여 클러스터에 연결합니다. Vertex AI Workbench 노트북을 사용하거나 클러스터에서 직접 노트북을 실행할 수 있습니다.
Spark 세션 구성
Jupyter Notebook에서 Lakehouse 런타임 카탈로그 Iceberg REST 카탈로그를 사용하도록 구성된 Spark 세션을 만듭니다.
import pyspark
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
catalog_name = "CATALOG_NAME"
spark = SparkSession.builder.appName("APP_NAME") \
.config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') \
.config(f'spark.sql.catalog.{catalog_name}.type', 'rest') \
.config(f'spark.sql.catalog.{catalog_name}.uri', 'https://biglake.googleapis.com/iceberg/v1beta/restcatalog') \
.config(f'spark.sql.catalog.{catalog_name}.warehouse', 'gs://GCS_BUCKET') \
.config(f'spark.sql.catalog.{catalog_name}.header.x-goog-user-project', 'PROJECT_ID') \
.config(f'spark.sql.catalog.{catalog_name}.rest.auth.type', 'org.apache.iceberg.gcp.auth.GoogleAuthManager') \
.config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.gcp.gcs.GCSFileIO') \
.config(f'spark.sql.catalog.{catalog_name}.rest-metrics-reporting-enabled', 'false') \
.config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') \
.config('spark.sql.defaultCatalog', catalog_name) \
.getOrCreate()
다음을 바꿉니다.
CATALOG_NAME: Iceberg 카탈로그의 이름(예:iceberg_catalog)APP_NAME: Spark 애플리케이션의 이름입니다.GCS_BUCKET: Iceberg 테이블 데이터를 저장할 Cloud Storage 버킷입니다.PROJECT_ID: Google Cloud 프로젝트 ID입니다.
Spark SQL로 데이터 관리
Spark 세션을 구성한 후 Spark SQL을 사용하여 데이터 관리 작업을 실행합니다.
네임스페이스를 만듭니다. Lakehouse 런타임 카탈로그 Iceberg REST 카탈로그에서 네임스페이스는 BigQuery 데이터 세트에 해당합니다.
spark.sql("CREATE NAMESPACE IF NOT EXISTS NAMESPACE_NAME") spark.sql("USE NAMESPACE_NAME")NAMESPACE_NAME을 네임스페이스 이름(예:spark_lakehouse)으로 바꿉니다.Iceberg 형식으로 기본 테이블을 만들고 데이터를 삽입합니다.
spark.sql("DROP TABLE IF EXISTS base_table PURGE") spark.sql("CREATE TABLE base_table (id LONG) USING iceberg") spark.sql("INSERT INTO base_table VALUES 0, 1, 2, 3, 4") spark.sql("SELECT * FROM base_table").show()출력은 다음과 비슷합니다.
+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| +---+새 데이터용 두 번째 테이블을 만듭니다.
spark.sql("DROP TABLE IF EXISTS newdata PURGE") spark.sql("CREATE TABLE newdata(id LONG) USING iceberg") spark.sql("INSERT INTO newdata VALUES 3, 4, 5, 6") spark.sql("SELECT * FROM newdata").show()출력은 다음과 비슷합니다.
+---+ | id| +---+ | 3| | 4| | 5| | 6| +---+새 데이터를 기본 테이블에 병합합니다.
spark.sql("""MERGE INTO base_table USING newdata ON base_table.id = newdata.id WHEN MATCHED THEN UPDATE SET base_table.id = newdata.id WHEN NOT MATCHED THEN INSERT * """) spark.sql("SELECT * FROM base_table").show()출력은 다음과 비슷합니다.
+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| | 5| | 6| +---+기본 테이블의 레코드를 업데이트합니다.
spark.sql( "UPDATE base_table SET id = (id + 100) WHERE (id % 2 == 0)" ) spark.sql("SELECT * FROM base_table").show()출력은 다음과 비슷합니다.
+---+ | id| +---+ | 3| |104| | 5| |106| |100| |102| | 1| +---+기본 테이블에서 레코드를 삭제합니다.
spark.sql("DELETE FROM base_table WHERE (id % 2 == 0)") spark.sql("SELECT * FROM base_table").show()출력은 다음과 비슷합니다.
+---+ | id| +---+ | 3| | 5| | 1| +---+
이전 스냅샷 쿼리
특정 스냅샷 ID를 쿼리하여 테이블의 이전 버전을 가져옵니다. 이 작업을 타임 트래블이라고도 합니다.
MERGE,UPDATE,DELETE작업 전 테이블 버전의 스냅샷 ID를 가져옵니다.snapshot_ids = spark.sql( "SELECT snapshot_id FROM `NAMESPACE_NAME`.`base_table`.snapshots" ).collect() oldest_snapshot_id = snapshot_ids[1]["snapshot_id"]NAMESPACE_NAME를 생성한 네임스페이스로 바꿉니다.검색된 스냅샷 ID를 사용하여 테이블을 쿼리합니다.
df = ( spark.read.format("iceberg") .option("versionAsOf", oldest_snapshot_id) .load("base_table") ) df.show()출력에는
MERGE작업 후이지만UPDATE또는DELETE작업 전의 테이블 상태가 표시됩니다.+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| | 5| | 6| +---+
데이터 계보 확인
Managed Service for Apache Spark 2.2 이상 이미지 버전에서 사용할 수 있는 데이터 계보를 사용하여 Lakehouse 런타임 카탈로그 Iceberg REST 카탈로그 테이블 간의 데이터 이동을 추적할 수 있습니다.
데이터 계보 예
소스 및 타겟 Iceberg 테이블을 만든 다음 데이터를 복사합니다.
spark.sql("DROP TABLE IF EXISTS source_table PURGE") spark.sql("DROP TABLE IF EXISTS target_table PURGE") spark.sql("CREATE TABLE source_table (id LONG) USING iceberg") spark.sql("""CREATE TABLE target_table USING ICEBERG AS SELECT max(id) as top_id FROM source_table """)Google Cloud 콘솔에서 Knowledge Catalog 검색 페이지로 이동합니다.
테이블 중 하나를 검색한 다음
Lineage탭을 클릭합니다.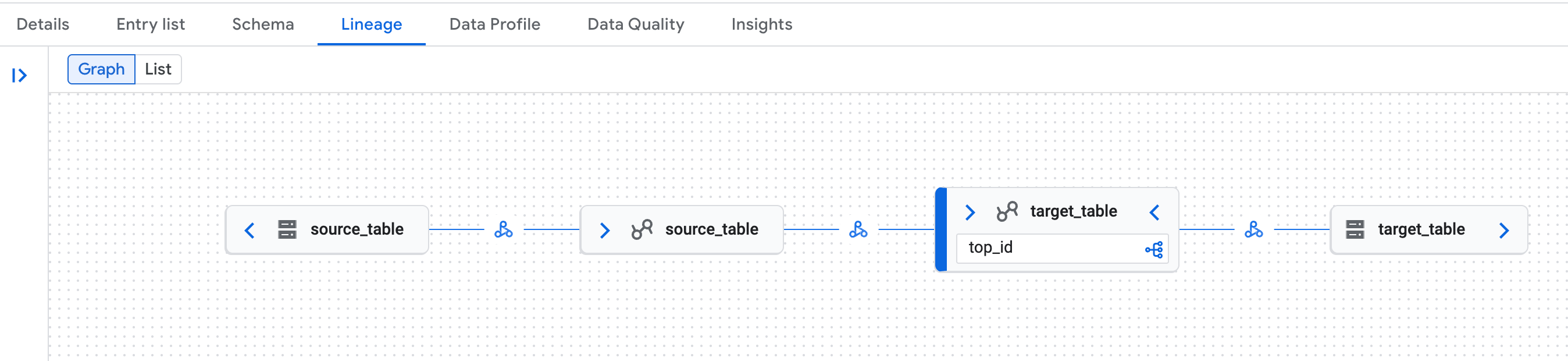
Google Cloud 콘솔의 Knowledge Catalog 페이지에 있는 데이터 계보 그래프의 예시 데이터 계보는 Lakehouse 런타임 카탈로그 Iceberg REST 카탈로그 테이블의 논리적 (Lakehouse 런타임 카탈로그 테이블) 표현과 물리적 (Cloud Storage) 표현을 모두 인식합니다.
데이터 계보 관련 알려진 문제
일부 Managed Service for Apache Spark 클러스터에서는 OpenLineage 라이브러리 문제로 인해 전체 데이터 계보가 생성되지 않을 수 있습니다.
해결 방법: Spark 세션 구성에서 spark.sql.catalog.{catalog_name}.uri 속성을 https://biglake.googleapis.com/iceberg/v1beta/restcatalog로 설정합니다.
다음 단계
- Lakehouse 런타임 카탈로그 Iceberg REST 카탈로그에 대해 자세히 알아보세요.
- Apache Iceberg의 기능을 살펴봅니다.
- Lakehouse 런타임 카탈로그에서 Iceberg 데이터를 쿼리하는 방법을 알아보세요.
- 데이터 계보 및 Managed Service for Apache Spark에 대해 자세히 알아보세요.