
IAM granulare di Managed Service for Apache Spark è una funzionalità che ti consente di concedere autorizzazioni a livello di cluster, job, operazioni, modello di workflow o policy di scalabilità automatica.
Esempio: puoi concedere a un utente il ruolo Visualizzatore cluster, che gli consente di visualizzare un cluster all'interno di un progetto, e a un altro utente il ruolo Editor job, che gli consente di aggiornare, annullare e visualizzare il job. Per comprendere i comandi Google Cloud CLI specifici abilitati da ogni ruolo IAM granulare di Managed Service for Apache Spark, consulta Comandi SDK abilitati da IAM granulare.
Ruoli e autorizzazioni IAM granulari di Managed Service for Apache Spark
IAM granulare di Managed Service for Apache Spark può impostare i seguenti ruoli con le seguenti autorizzazioni per le risorse Managed Service for Apache Spark.
Ruoli cluster
| Ruolo | Autorizzazioni |
|---|---|
| Visualizzatore | dataproc.clusters.get |
| Editor | dataproc.clusters.get dataproc.clusters.list dataproc.clusters.delete dataproc.clusters.update dataproc.clusters.use dataproc.clusters.start dataproc.clusters.stop |
| Proprietario | dataproc.clusters.get dataproc.clusters.list dataproc.clusters.delete dataproc.clusters.update dataproc.clusters.use dataproc.clusters.start dataproc.clusters.stop dataproc.clusters.setIamPolicy dataproc.clusters.getIamPolicy |
Ruoli professionali
| Ruolo | Autorizzazioni |
|---|---|
| Visualizzatore | dataproc.jobs.get |
| Editor | dataproc.jobs.get dataproc.jobs.cancel dataproc.jobs.delete dataproc.jobs.update |
| Proprietario | dataproc.jobs.get dataproc.jobs.cancel dataproc.jobs.delete dataproc.jobs.update dataproc.jobs.setIamPolicy dataproc.jobs.getIamPolicy |
Ruoli operativi
| Ruolo | Autorizzazioni |
|---|---|
| Visualizzatore | dataproc.operations.get |
| Editor | dataproc.jobs.get dataproc.operations.cancel dataproc.operations.delete |
| Proprietario | dataproc.jobs.get dataproc.operations.cancel dataproc.operations.delete dataproc.operations.setIamPolicy dataproc.operations.getIamPolicy |
Ruoli del modello di workflow
| Ruolo | Autorizzazioni |
|---|---|
| Visualizzatore | dataproc.workflowTemplates.get |
| Editor | dataproc.workflowTemplates.get dataproc.workflowTemplates.delete dataproc.workflowTemplates.update |
| Proprietario | dataproc.workflowTemplates.get dataproc.workflowTemplates.delete dataproc.workflowTemplates.update dataproc.workflowTemplates.setIamPolicy dataproc.workflowTemplates.getIamPolicy |
Ruoli delle policy di scalabilità automatica
| Ruolo | Autorizzazioni |
|---|---|
| Visualizzatore | dataproc.autoscalingPolicies.get |
| Editor | dataproc.autoscalingPolicies.get dataproc.autoscalingPolicies.use dataproc.autoscalingPolicies.delete dataproc.autoscalingPolicies.update |
| Proprietario | dataproc.autoscalingPolicies.get dataproc.autoscalingPolicies.use dataproc.autoscalingPolicies.delete dataproc.autoscalingPolicies.update dataproc.autoscalingPolicies.setIamPolicy dataproc.autoscalingPolicies.getIamPolicy |
Utilizzare IAM granulare di Managed Service for Apache Spark
Questa sezione spiega come utilizzare IAM granulare di Managed Service for Apache Spark per assegnare ruoli agli utenti su una risorsa Managed Service for Apache Spark esistente. Per saperne di più sull'aggiornamento e sulla rimozione dei ruoli Identity and Access Management (IAM), consulta Gestire l'accesso a progetti, cartelle e organizzazioni.
Comando gcloud
- Recupera il criterio IAM della risorsa e scrivilo in un file JSON (resource-type può essere "clusters", "jobs", "operations", "workflow-templates" o "autoscaling-policies"):
gcloud dataproc resource-type get-iam-policy resource-id \ --region=region \ --format=json > iam.json
- I contenuti del file JSON saranno simili ai seguenti:
{ "bindings": [ { "role": "roles/editor", "members": [ "user:mike@example.com", "group:admins@example.com", "domain:google.com", "serviceAccount:my-other-app@appspot.gserviceaccount.com" ] } ], "etag": "string" } - Utilizzando un editor di testo, aggiungi un nuovo
oggetto binding
all'array di binding che definisce gli utenti e il ruolo di accesso alle risorse
per questi utenti. Ad esempio, per concedere
il ruolo Visualizzatore (
roles/viewer) all'utentesean@example.com, devi modificare l'esempio precedente per aggiungere un nuovo oggetto di associazione (mostrato in grassetto nell'esempio seguente). Nota: assicurati di restituire il valoreetagricevuto dagcloud dataproc resource-type get-iam-policy. Consulta la documentazione sugli ETag.{ "bindings": [ { "role": "roles/editor", "members": [ "user:mike@example.com", "group:admins@example.com", "domain:google.com", "serviceAccount:my-other-app@appspot.gserviceaccount.com" ] }, { "role": "roles/viewer", "members": [ "user:sean@example.com" ] } ], "etag": "value-from-get-iam-policy" } - Aggiorna la policy del cluster con il nuovo array di binding eseguendo il seguente comando (resource-type può essere "clusters", "jobs", "operations", "workflow-templates" o "autoscaling-policies"):
gcloud dataproc resource-type set-iam-policy resource-name \ --region=region \ --format=json iam.json
- Il comando restituisce la policy aggiornata:
{ "bindings": [ { "role": "roles/editor", "members": [ "user:mike@example.com", "group:admins@example.com", "domain:google.com", "serviceAccount:my-other-app@appspot.gserviceaccount.com" ] }, { "role": "roles/viewer", "members": [ "user:sean@example.com" ] } ], "etag": "string" }
API REST
- Esegui una richiesta resource-type ("clusters" or "jobs" or "operations" or "workflowTemplates" or "autoscalingPolicies") getIamPolicy per ottenere il criterio IAM per la risorsa.
Esempio di getIamPolicy del cluster:
GET https://dataproc.googleapis.com/v1/projects/projectName/regions/region/clusters/clusterName:getIamPolicy
- I contenuti del file JSON saranno simili ai seguenti:
{ "bindings": [ { "role": "roles/editor", "members": [ "user:mike@example.com", "group:admins@example.com", "domain:google.com", "serviceAccount:my-other-app@appspot.gserviceaccount.com" ] } ], "etag": "string" } - Utilizzando un editor di testo, crea il seguente oggetto policy JSON per racchiudere l'array di binding che hai appena ricevuto dal servizio Managed Service for Apache Spark. Assicurati di restituire il valore "etag" ricevuto nella risposta getIamPolicy (consulta la
documentazione etag).
Ora aggiungi un nuovo
oggetto binding
all'array di binding che definisce gli utenti e il ruolo di accesso al cluster per questi utenti. Ad esempio, per concedere
il ruolo Visualizzatore (
roles/viewer) all'utentesean@example.com, devi modificare l'esempio precedente per aggiungere un nuovo oggetto di associazione (mostrato in grassetto di seguito).{ "policy": { "version": "", "bindings": [ { "role": "roles/editor", "members": [ "user:mike@example.com", "group:admins@example.com", "domain:google.com", "serviceAccount:my-other-app@appspot.gserviceaccount.com" ] }, { "role": "roles/viewer", "members": [ "user:sean@example.com" ] } ], "etag": "value-from-getIamPolicy" } } - Imposta la policy aggiornata sulla risorsa inviando una richiesta
setIamPolicy.Cluster setIamPolicy Esempio:
POST https://dataproc.googleapis.com/v1/projects/projectName/regions/region/clusters/clusterName:setIamPolicy Request body
{ "policy": { "version": "", "bindings": [ { "role": "roles/editor", "members": [ "user:mike@example.com", "group:admins@example.com", "domain:google.com", "serviceAccount:my-other-app@appspot.gserviceaccount.com" ] }, { "role": "roles/viewer", "members": [ "user:sean@example.com" ] } ], "etag": "value-from-getIamPolicy" } } - I contenuti della risposta JSON saranno simili ai seguenti:
Risposta
{ "bindings": [ { "role": "roles/editor", "members": [ "user:mike@example.com", "group:admins@example.com", "domain:google.com", "serviceAccount:my-other-app@appspot.gserviceaccount.com" ] }, { "role": "roles/viewer", "members": [ "user:sean@example.com" ] } ], "etag": "string" }
Console
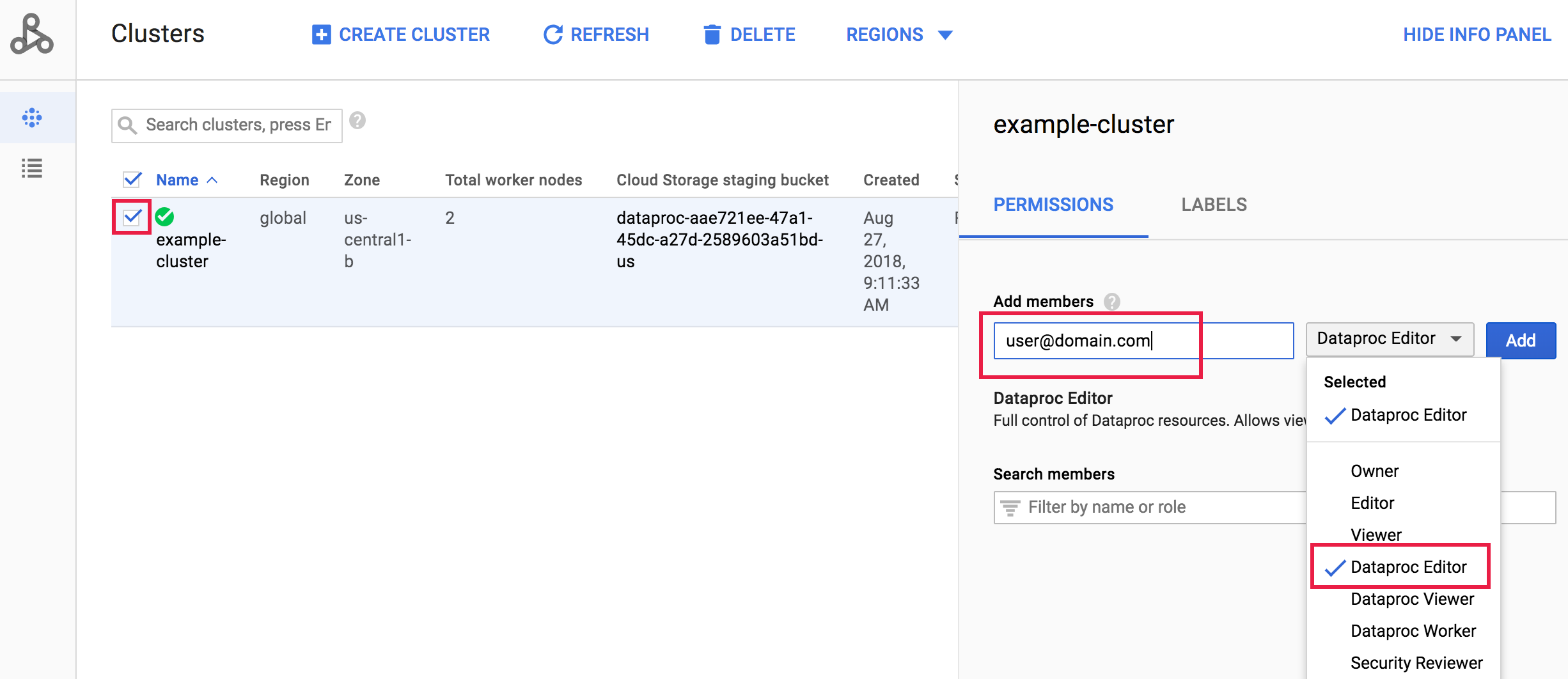
Vai alla pagina Cluster Managed Service for Apache Spark nella console Google Cloud , quindi fai clic sulla casella a sinistra del nome del cluster per aprire il riquadro Autorizzazioni/Etichette (se il riquadro non è visualizzato, fai clic su MOSTRA RIQUADRO INFORMAZIONI in alto a destra della pagina). Nella scheda Autorizzazioni, seleziona il ruolo Managed Service for Apache Spark, aggiungi uno o più indirizzi account nella casella Aggiungi entità, quindi fai clic su Aggiungi.
Comandi SDK abilitati da IAM granulare
Questa sezione descrive i comandi gcloud dataproc abilitati per le risorse Managed Service for Apache Spark da ogni ruolo IAM granulare.
Cluster
| Ruolo IAM | Comando |
|---|---|
| Visualizzatore | gcloud dataproc clusters describe cluster-name |
| Editor | gcloud dataproc clusters describe cluster-namegcloud dataproc clusters listgcloud dataproc clusters delete cluster-namegcloud dataproc clusters diagnose cluster-namegcloud dataproc clusters update cluster-namegcloud beta dataproc clusters start cluster-namegcloud beta dataproc clusters stop cluster-name |
| Proprietario | gcloud dataproc clusters describe cluster-namegcloud dataproc clusters listgcloud dataproc clusters delete cluster-namegcloud dataproc clusters diagnose cluster-namegcloud dataproc clusters update cluster-namegcloud beta dataproc clusters start cluster-namegcloud beta dataproc clusters stop cluster-namegcloud dataproc clusters get-iam-policy cluster-namegcloud dataproc clusters set-iam-policy cluster-name |
Job
| Ruolo IAM | Comando |
|---|---|
| Visualizzatore | gcloud dataproc jobs describe job-id |
| Editor | gcloud dataproc jobs delete job-idgcloud dataproc jobs describe job-idgcloud dataproc jobs kill job-idgcloud dataproc jobs update job-idgcloud dataproc jobs wait job-id |
| Proprietario | gcloud dataproc jobs delete job-idgcloud dataproc jobs describe job-idgcloud dataproc jobs kill job-idgcloud dataproc jobs update job-idgcloud dataproc jobs wait job-idgcloud dataproc jobs get-iam-policy job-idgcloud dataproc jobs set-iam-policy job-id |
Operazioni
| Ruolo IAM | Comando |
|---|---|
| Visualizzatore | gcloud dataproc operations describe operation-id |
| Editor | gcloud dataproc operations delete operation-idgcloud dataproc operations describe operation-idgcloud dataproc operations cancel operation-id |
| Proprietario | gcloud dataproc operations delete operation-idgcloud dataproc operations describe operation-idgcloud dataproc operations cancel operation-idgcloud dataproc operations get-iam-policy operation-idgcloud dataproc operations set-iam-policy operation-id |
Modelli di workflow
| Ruolo IAM | Comando |
|---|---|
| Visualizzatore | gcloud dataproc workflow-templates describe template-id |
| Editor | gcloud dataproc workflow-templates delete template-idgcloud dataproc workflow-templates describe template-idgcloud dataproc workflow-templates remove-job template-idgcloud dataproc workflow-templates run template-id |
| Proprietario | gcloud dataproc workflow-templates delete template-idgcloud dataproc workflow-templates describe template-idgcloud dataproc workflow-templates remove-job template-idgcloud dataproc workflow-templates run template-idgcloud dataproc workflow-templates get-iam-policy template-idgcloud dataproc workflow-templates set-iam-policy template-id |
Policy di scalabilità automatica
| Ruolo IAM | Comando |
|---|---|
| Visualizzatore | gcloud dataproc autoscaling-policies describe policy-id |
| Editor | gcloud dataproc autoscaling-policies delete policy-idgcloud dataproc autoscaling-policies describe policy-idgcloud dataproc autoscaling-policies update policy-idgcloud dataproc clusters create cluster-name --autoscaling-policy policy-id |
| Proprietario | gcloud dataproc autoscaling-policies delete policy-idgcloud dataproc autoscaling-policies describe policy-idgcloud dataproc autoscaling-policies update policy-idgcloud dataproc clusters create cluster-name --autoscaling-policy policy-idgcloud dataproc autoscaling-policies get-iam-policy policy-idgcloud dataproc autoscaling-policies set-iam-policy policy-id |
Invio di job con IAM granulare
Per consentire a un'entità (utente, gruppo o account di servizio) di inviare job a un cluster specificato utilizzando IAM granulare di Managed Service for Apache Spark, oltre a concedere a un utente un ruolo Editor su un cluster, è necessario impostare autorizzazioni aggiuntive a livello di progetto. Di seguito sono riportati i passaggi da seguire per consentire a un principal di inviare job su un cluster Managed Service for Apache Spark specificato:
- Crea un bucket Cloud Storage che il cluster può utilizzare per connettersi a Cloud Storage.
- Aggiungi l'entità alla policy a livello di bucket,
selezionando il ruolo Visualizzatore oggetti Storage per l'entità
(vedi
roles/storage.objectViewer), che include le seguenti autorizzazioni:storage.objects.getstorage.objects.list
- Quando crei il cluster, passa il nome del bucket appena creato
al cluster utilizzando il parametro
--bucket(vedigcloud dataproc clusters create --bucket). - Dopo aver creato il cluster, imposta una policy che assegni al principal un ruolo Editor o Proprietario (vedi Utilizzare IAM granulare di Managed Service for Apache Spark).
- Crea un ruolo personalizzato IAM
con le seguenti autorizzazioni:
dataproc.jobs.createdataproc.jobs.get
- Seleziona o aggiungi l'entità nella pagina IAM della console Google Cloud , quindi seleziona il ruolo personalizzato da applicare all'entità.