
Il connettore Hive-BigQuery open source consente ai carichi di lavoro Apache Hive di leggere e scrivere dati da e in tabelle BigQuery e BigLake. Puoi archiviare i dati nello spazio di archiviazione BigQuery o in formati di dati open source su Cloud Storage.
Il connettore Hive-BigQuery implementa l' API Hive Storage Handler per consentire ai carichi di lavoro Hive di integrarsi con le tabelle BigQuery e BigLake. Il motore di esecuzione Hive gestisce le operazioni di calcolo, come aggregazioni e join, e il connettore gestisce le interazioni con i dati archiviati in BigQuery o nei bucket Cloud Storage connessi a BigLake.
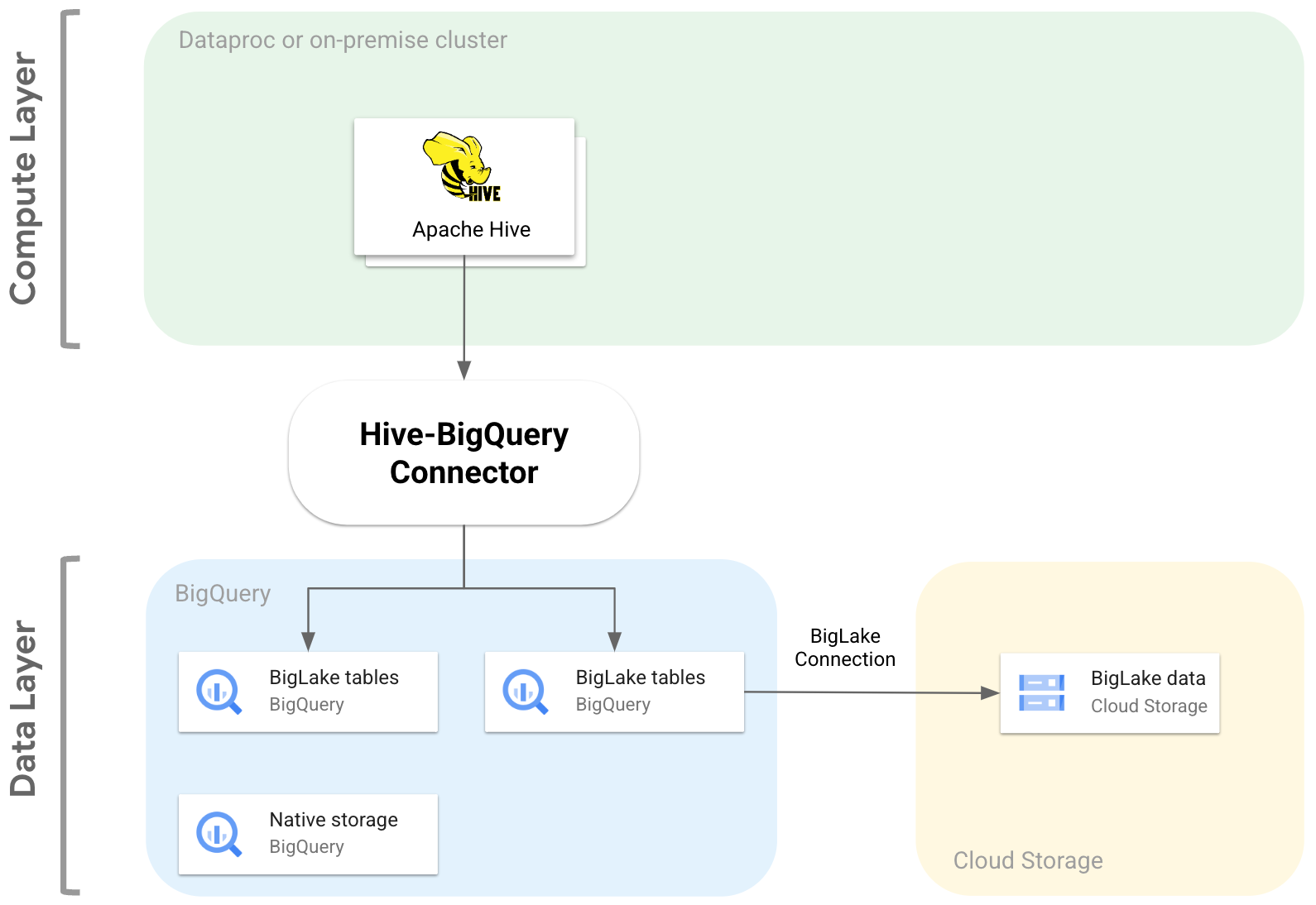
Il seguente diagramma illustra come il connettore Hive-BigQuery si inserisce tra i livelli di calcolo e dati.
Casi d'uso
Ecco alcuni modi in cui il connettore Hive-BigQuery può aiutarti in scenari comuni basati sui dati:
Migrazione dei dati. Prevedi di spostare il data warehouse Hive in BigQuery, quindi di tradurre gradualmente le query Hive nel dialetto SQL di BigQuery. Prevedi che la migrazione richieda una quantità di tempo significativa a causa delle dimensioni del data warehouse e del numero elevato di applicazioni connesse e devi garantire la continuità durante le operazioni di migrazione. Ecco il flusso di lavoro:
- Sposta i dati in BigQuery.
- Utilizzando il connettore, accedi ed esegui le query Hive originali mentre traduci gradualmente le query Hive nel dialetto SQL conforme ad ANSI di BigQuery.
- Al termine della migrazione e della traduzione, ritira Hive.
Workflow Hive e BigQuery. Prevedi di utilizzare Hive per alcune attività e BigQuery per i carichi di lavoro che usufruiscono delle sue funzionalità, come BigQuery BI Engine o BigQuery ML. Utilizza il connettore per unire le tabelle Hive alle tabelle BigQuery.
Affidamento su uno stack software open source (OSS). Per evitare il lock-in del fornitore, utilizza uno stack OSS completo per il data warehouse. Ecco il tuo piano dati:
Esegui la migrazione dei dati nel formato OSS originale, ad esempio Avro, Parquet o ORC, nei bucket Cloud Storage utilizzando una connessione BigLake.
Continua a utilizzare Hive per eseguire ed elaborare le query del dialetto SQL di Hive.
Utilizza il connettore, se necessario, per connetterti a BigQuery e usufruire delle seguenti funzionalità:
- Memorizzazione nella cache dei metadati per il rendimento delle query
- Prevenzione della perdita di dati
- Controllo dell'accesso a livello di colonna
- Mascheramento dinamico dei dati per la sicurezza e la governance su vasta scala.
Funzionalità
Puoi utilizzare il connettore Hive-BigQuery per lavorare con i dati BigQuery e svolgere le seguenti attività:
- Esegui query con i motori di esecuzione MapReduce e Tez.
- Crea ed elimina tabelle BigQuery da Hive.
- Unisci le tabelle BigQuery e BigLake con le tabelle Hive.
- Esegui letture rapide dalle tabelle BigQuery utilizzando i flussi dell'API Storage Read e il formato Apache Arrow.
- Scrivi dati in BigQuery utilizzando i seguenti metodi:
- Scritture dirette utilizzando l'API BigQuery Storage Write in modalità in attesa. Utilizza questo metodo per i carichi di lavoro che richiedono una bassa latenza di scrittura, ad esempio dashboard quasi in tempo reale con finestre di aggiornamento brevi.
- Scritture indirette mediante la gestione temporanea dei file Avro in Cloud Storage e quindi il caricamento dei file in una tabella di destinazione utilizzando l'API Load Job. Questo metodo è meno costoso del metodo diretto, poiché i job di caricamento di BigQuery non comportano addebiti. Poiché questo metodo è più lento, è più adatto ai carichi di lavoro che non sono sensibili al tempo.
Accedi alle tabelle di BigQuery con partizionamento temporale e clustering. L'esempio seguente definisce la relazione tra una tabella Hive e una tabella con partizionamento e clustering in BigQuery.
CREATE TABLE my_hive_table (int_val BIGINT, text STRING, ts TIMESTAMP) STORED BY 'com.google.cloud.hive.bigquery.connector.BigQueryStorageHandler' TBLPROPERTIES ( 'bq.table'='myproject.mydataset.mytable', 'bq.time.partition.field'='ts', 'bq.time.partition.type'='MONTH', 'bq.clustered.fields'='int_val,text' );
Elimina le colonne per evitare di recuperare colonne non necessarie dal livello dati.
Utilizza i pushdown dei predicati per prefiltrare le righe di dati nel livello di archiviazione di BigQuery. Questa tecnica può migliorare notevolmente il rendimento complessivo delle query riducendo la quantità di dati che attraversano la rete.
Converti automaticamente i tipi di dati Hive in tipi di dati BigQuery.
Leggi le viste e gli snapshot delle tabelle BigQuery.
Esegui l'integrazione con Spark SQL.
Esegui l'integrazione con Apache Pig e HCatalog.
Inizia
Consulta le istruzioni per installare e configurare il connettore Hive-BigQuery su un cluster Hive.