
התוסף Managed Service for Apache Spark Ranger Cloud Storage, שזמין בגרסאות התמונות 1.5 ו-2.0 של Managed Service for Apache Spark, מפעיל שירות הרשאות בכל מכונה וירטואלית של אשכול Managed Service for Apache Spark. שירות ההרשאות מעריך בקשות ממחבר Cloud Storage בהתאם למדיניות Ranger, ואם הבקשה מאושרת, הוא מחזיר אסימון גישה לחשבון השירות של המכונה הווירטואלית של האשכול.
התוסף Ranger Cloud Storage מסתמך על Kerberos לאימות, ופועל בשילוב עם תמיכה במחברי Cloud Storage לאסימוני העברה. אסימוני ההרשאה מאוחסנים במסד נתונים מסוג MySQL בצומת הראשי של האשכול. סיסמת הבסיס למסד הנתונים מוגדרת דרך מאפייני האשכול כשיוצרים את אשכול Managed Service for Apache Spark.
לפני שמתחילים
מקצים את התפקיד יצירת אסימונים בחשבון שירות ואת התפקיד אדמין של תפקיד ב-IAM בחשבון השירות של מכונת ה-VM של Managed Service for Apache Spark בפרויקט.
התקנת הפלאגין Ranger Cloud Storage
מריצים את הפקודות הבאות בחלון מסוף מקומי או ב-Cloud Shell כדי להתקין את הפלאגין Ranger Cloud Storage כשיוצרים אשכול Managed Service for Apache Spark.
הגדרה של משתני סביבה
export CLUSTER_NAME=new-cluster-name \ export REGION=region \ export KERBEROS_KMS_KEY_URI=Kerberos-KMS-key-URI \ export KERBEROS_PASSWORD_URI=Kerberos-password-URI \ export RANGER_ADMIN_PASSWORD_KMS_KEY_URI=Ranger-admin-password-KMS-key-URI \ export RANGER_ADMIN_PASSWORD_GCS_URI=Ranger-admin-password-GCS-URI \ export RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI=MySQL-root-password-KMS-key-URI \ export RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI=MySQL-root-password-GCS-URI
הערות:
- CLUSTER_NAME: השם של האשכול החדש.
- REGION: האזור שבו ייווצר האשכול, לדוגמה,
us-west1. - KERBEROS_KMS_KEY_URI ו-KERBEROS_PASSWORD_URI: אפשר לעיין במאמר בנושא הגדרה של סיסמת המשתמש הראשי של Kerberos.
- RANGER_ADMIN_PASSWORD_KMS_KEY_URI ו-RANGER_ADMIN_PASSWORD_GCS_URI: אפשר לעיין במאמר בנושא הגדרת סיסמת האדמין של Ranger.
- RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI ו-RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI: מגדירים סיסמת MySQL באותו אופן שבו הגדרתם סיסמת אדמין ב-Ranger.
יצירת אשכול Managed Service for Apache Spark
מריצים את הפקודה הבאה כדי ליצור אשכול Managed Service for Apache Spark ולהתקין את הפלאגין Ranger Cloud Storage באשכול.
gcloud dataproc clusters create ${CLUSTER_NAME} \
--region=${REGION} \
--scopes cloud-platform \
--enable-component-gateway \
--optional-components=SOLR,RANGER \
--kerberos-kms-key=${KERBEROS_KMS_KEY_URI} \
--kerberos-root-principal-password-uri=${KERBEROS_PASSWORD_URI} \
--properties="dataproc:ranger.gcs.plugin.enable=true, \
dataproc:ranger.kms.key.uri=${RANGER_ADMIN_PASSWORD_KMS_KEY_URI}, \
dataproc:ranger.admin.password.uri=${RANGER_ADMIN_PASSWORD_GCS_URI}, \
dataproc:ranger.gcs.plugin.mysql.kms.key.uri=${RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI}, \
dataproc:ranger.gcs.plugin.mysql.password.uri=${RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI}"
הערות:
- גרסה 1.5 של תמונה: אם יוצרים אשכול של גרסה 1.5 של תמונה (ראו בחירת גרסאות), מוסיפים את הדגל
--metadata=GCS_CONNECTOR_VERSION="2.2.6" or higherכדי להתקין את גרסת המחבר הנדרשת.
אימות ההתקנה של הפלאגין Ranger Cloud Storage
אחרי שהיצירה של האשכול מסתיימת, מופיע GCS סוג שירות בשםgcs-dataproc בממשק האינטרנט של Ranger admin.
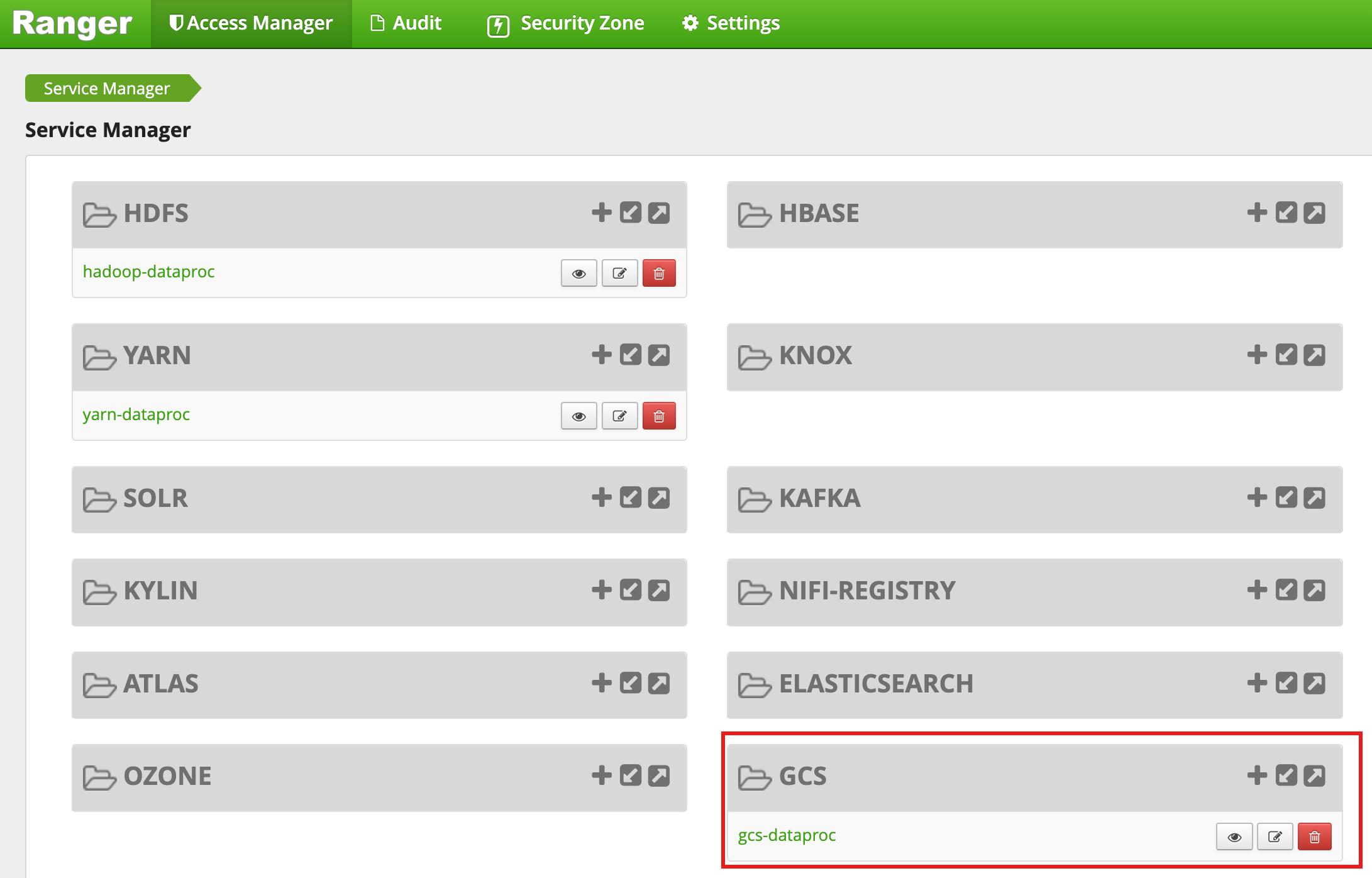
מדיניות ברירת המחדל של התוסף Ranger Cloud Storage
לשירות gcs-dataproc שמוגדר כברירת מחדל יש את כללי המדיניות הבאים:
מדיניות לקריאה וכתיבה באשכול staging and temp buckets של Managed Service for Apache Spark
מדיניות
all - bucket, object-path, שמאפשרת לכל המשתמשים לגשת למטא-נתונים של כל האובייקטים. הגישה הזו נדרשת כדי לאפשר למחבר Cloud Storage לבצע פעולות HCFS (Hadoop Compatible Filesystem).
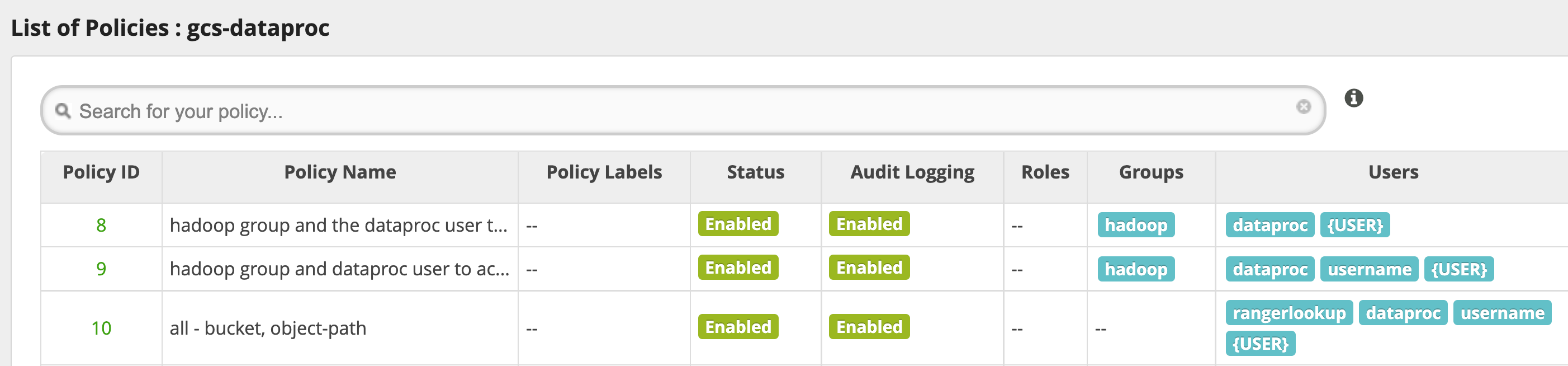
טיפים לשימוש
גישה של אפליקציות לתיקיות של מאגרי מידע
כדי להתאים לאפליקציות שיוצרות קבצים זמניים בקטגוריה של Cloud Storage, אפשר להעניק הרשאות Modify Objects, List Objects ו-Delete Objects בנתיב של הקטגוריה של Cloud Storage, ואז לבחור במצב recursive כדי להרחיב את ההרשאות לנתיבי משנה בנתיב שצוין.
אמצעי הגנה
כדי למנוע עקיפה של התוסף:
צריך לתת לחשבון השירות של מכונת ה-VM גישה למשאבים בקטגוריות של Cloud Storage כדי לאפשר לו לתת גישה למשאבים האלה באמצעות אסימוני גישה עם היקף מצומצם (ראו הרשאות IAM ל-Cloud Storage). בנוסף, כדי למנוע גישה ישירה של משתמשים לקטגוריות, צריך להסיר את הגישה של המשתמשים למשאבים בקטגוריה.
כדי למנוע התחזות או שינויים בהגדרות האימות וההרשאה, צריך להשבית את
sudoואמצעים אחרים לגישת שורש במכונות וירטואליות של אשכולות, כולל עדכון הקובץsudoer. מידע נוסף זמין בהוראות ל-Linux בנושא הוספה או הסרה שלsudoהרשאות משתמש.משתמשים ב-
iptableכדי לחסום בקשות לגישה ישירה ל-Cloud Storage ממכונות וירטואליות באשכול. לדוגמה, אתם יכולים לחסום את הגישה לשרת המטא-נתונים של המכונה הווירטואלית כדי למנוע גישה לפרטי הכניסה של חשבון השירות של המכונה הווירטואלית או לאסימון הגישה שמשמש לאימות ולאישור גישה ל-Cloud Storage (ראוblock_vm_metadata_server.sh, סקריפט אתחול שמשתמש בכלליiptableכדי לחסום את הגישה לשרת המטא-נתונים של המכונה הווירטואלית).
משימות Spark, Hive-on-MapReduce ו-Hive-on-Tez
כדי להגן על פרטי אימות רגישים של משתמשים וכדי להפחית את העומס על מרכז הפצת המפתחות (KDC), מנהל ההתקן של Spark לא מפיץ אישורי Kerberos למנהלי ההפעלה. במקום זאת, מנהל ההתקן של Spark מקבל אסימון הרשאה מהתוסף Ranger Cloud Storage, ואז מפיץ את אסימון ההרשאה למנהלי הביצוע. ה-Executors משתמשים באסימון ההרשאה כדי לבצע אימות לתוסף Ranger Cloud Storage, ומחליפים אותו באסימון גישה ל-Google שמאפשר גישה ל-Cloud Storage.
משימות Hive-on-MapReduce ו-Hive-on-Tez משתמשות גם הן בטוקנים כדי לגשת ל-Cloud Storage. אתם יכולים להשתמש במאפיינים הבאים כדי לקבל אסימונים לגישה לקטגוריות ספציפיות ב-Cloud Storage כשאתם שולחים את סוגי העבודות הבאים:
משימות Spark:
--conf spark.yarn.access.hadoopFileSystems=gs://bucket-name,gs://bucket-name,...
משימות Hive-on-MapReduce:
--hiveconf "mapreduce.job.hdfs-servers=gs://bucket-name,gs://bucket-name,..."
משימות Hive-on-Tez:
--hiveconf "tez.job.fs-servers=gs://bucket-name,gs://bucket-name,..."
תרחיש לדוגמה לשימוש ב-Spark
משימה של ספירת מילים ב-Spark נכשלת כשמריצים אותה מחלון טרמינל במכונת VM של אשכול Managed Service for Apache Spark שמותקן בה התוסף Ranger Cloud Storage.
spark-submit \
--conf spark.yarn.access.hadoopFileSystems=gs://${FILE_BUCKET} \
--class org.apache.spark.examples.JavaWordCount \
/usr/lib/spark/examples/jars/spark-examples.jar \
gs://bucket-name/wordcount.txt
הערות:
- FILE_BUCKET: קטגוריה של Cloud Storage לגישת Spark.
פלט השגיאה:
Caused by: com.google.gcs.ranger.client.shaded.io.grpc.StatusRuntimeException: PERMISSION_DENIED: Access denied by Ranger policy: User: '<USER>', Bucket: '<dataproc_temp_bucket>', Object Path: 'a97127cf-f543-40c3-9851-32f172acc53b/spark-job-history/', Action: 'LIST_OBJECTS'
הערות:
- הפרמטר
spark.yarn.access.hadoopFileSystems=gs://${FILE_BUCKET}נדרש בסביבה שמופעל בה Kerberos.
פלט השגיאה:
Caused by: java.lang.RuntimeException: Failed creating a SPNEGO token. Make sure that you have run `kinit` and that your Kerberos configuration is correct. See the full Kerberos error message: No valid credentials provided (Mechanism level: No valid credentials provided)
עורכים מדיניות באמצעות Access Manager בממשק האינטרנט של אדמין Ranger
כדי להוסיף את username לרשימת המשתמשים שיש להם List Objects והרשאות אחרות של temp bucket.
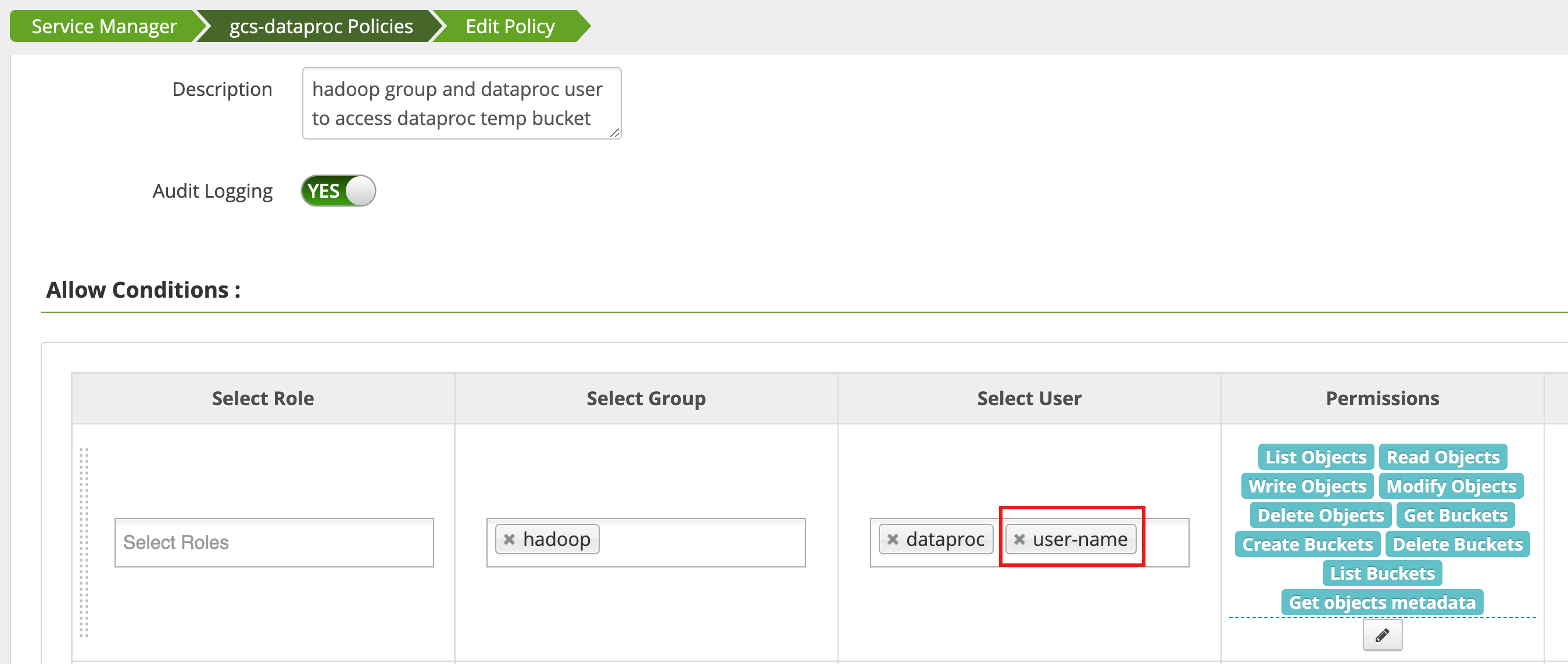
הפעלת העבודה יוצרת שגיאה חדשה.
פלט השגיאה:
com.google.gcs.ranger.client.shaded.io.grpc.StatusRuntimeException: PERMISSION_DENIED: Access denied by Ranger policy: User: <USER>, Bucket: '<file-bucket>', Object Path: 'wordcount.txt', Action: 'READ_OBJECTS'
נוסף כלל מדיניות כדי להעניק למשתמש הרשאת קריאה לנתיב wordcount.textCloud Storage.
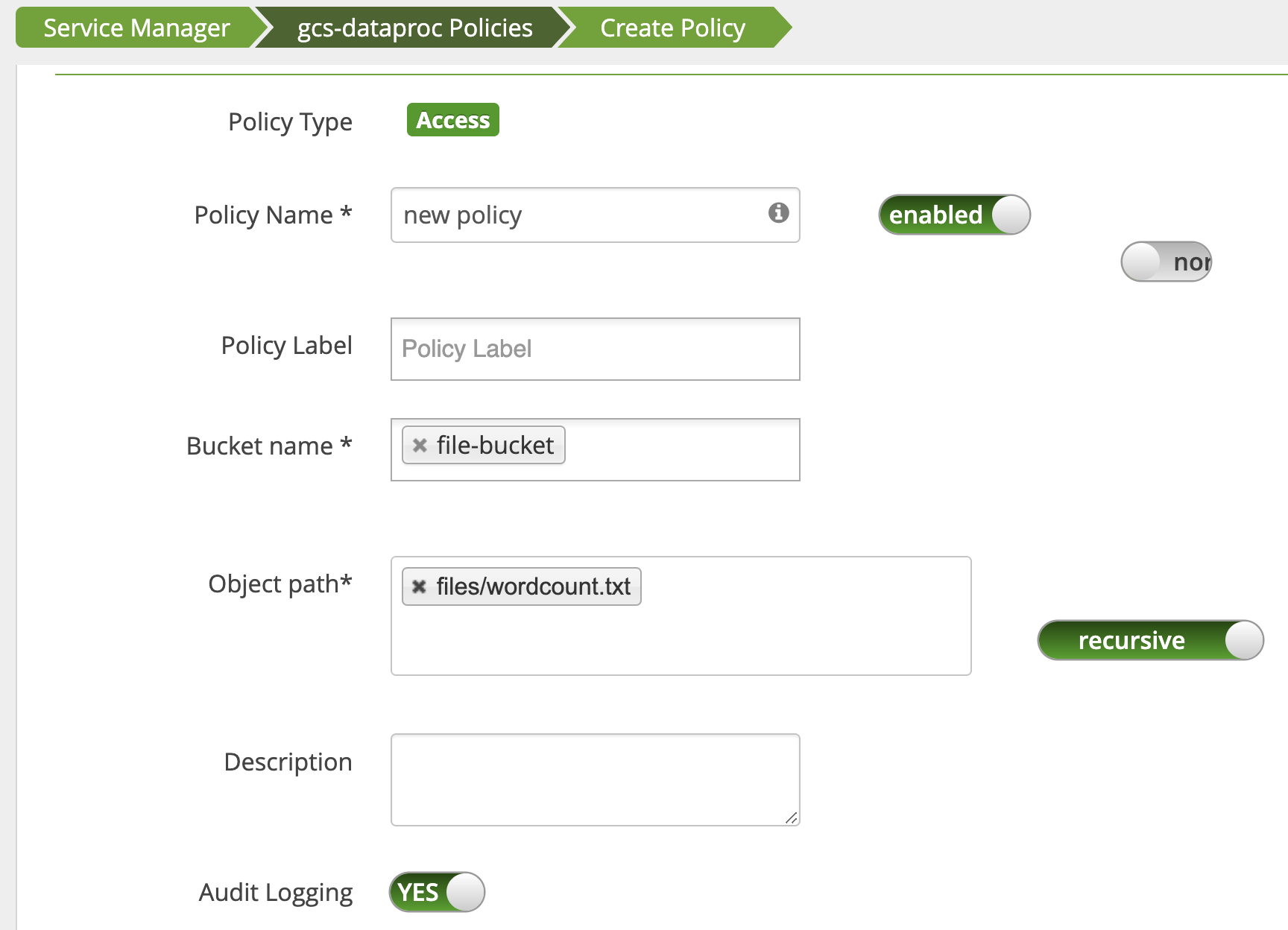
העבודה מופעלת ומושלמת בהצלחה.
INFO com.google.cloud.hadoop.fs.gcs.auth.GcsDelegationTokens: Using delegation token RangerGCSAuthorizationServerSessionToken owner=<USER>, renewer=yarn, realUser=, issueDate=1654116824281, maxDate=0, sequenceNumber=0, masterKeyId=0 this: 1 is: 1 a: 1 text: 1 file: 1 22/06/01 20:54:13 INFO org.sparkproject.jetty.server.AbstractConnector: Stopped