
自動スケーリングとは
ワークロードに対するクラスタ ワーカー(ノード)の「適正な」数を見積もることは容易ではありません。多くの場合、パイプライン全体で単一のクラスタサイズを使用することは理想的とは言えません。ユーザーがクラスタのスケーリングを開始することは、この課題の部分的な解決策となりますが、クラスタの使用状況のモニタリングと手動による操作が必要になります。
Managed Service for Apache Spark AutoscalingPolicies API は、クラスタ リソースの管理を自動化するメカニズムを提供し、クラスタ ワーカー VM の自動スケーリングを可能にします。Autoscaling Policy は、クラスタ ワーカーが自動スケーリング ポリシーを使用する方法を記述する再利用可能な構成です。スケーリングの境界や頻度、積極性を定義し、クラスタ存続期間中のクラスタ リソースをきめ細かく制御します。
自動スケーリングを使用する場合
次の場合に、自動スケーリングを使用します。
Cloud Storage や BigQuery などの外部サービスにデータを格納するクラスタ
多数のジョブを処理するクラスタ
単一ジョブをスケールアップするクラスタ
Spark バッチジョブに高度な柔軟性モードを使用している場合
以下の自動スケーリングは推奨されません。
HDFS: 自動スケーリングは、クラスタ内の HDFS のスケーリングを目的としたものではありません。その理由は以下のとおりです。
- HDFS の使用率は、自動スケーリングのシグナルではありません。
- HDFS データはプライマリ ワーカーでのみホストされます。プライマリ ワーカーの数は、すべての HDFS データをホストするのに十分な数にする必要があります。
- HDFS DataNode をデコミッションすると、ワーカーの削除が遅れる可能性があります。Datanodes は、ワーカーを削除する前に、HDFS ブロックを他の Datanode にコピーします。データサイズとレプリケーション係数によっては、このプロセスに数時間かかることがあります。
YARN ノードラベル: 自動スケーリングでは、YARN ノードラベルや、YARN-9088 のプロパティ
dataproc:am.primary_onlyはサポートされません。ノードラベルが使用された場合、YARN が誤ってクラスタ指標を報告します。Spark Structured Streaming: 自動スケーリングでは Spark Structured Streaming がサポートされません(自動スケーリングと Spark Structured Streaming をご覧ください)。
アイドル状態のクラスタ: クラスタがアイドル状態のときにクラスタを最小サイズまで縮小するための自動スケーリングはおすすめしません。新しいクラスタの作成にかかる時間はサイズを変更するのと同程度ですので、アイドル状態のクラスタを削除して再作成することを検討してください。この「エフェメラル」モデルをサポートするツールは次のとおりです。
Managed Service for Apache Spark Workflows を使用して、専用クラスタで一連のジョブをスケジュールし、ジョブが完了したらクラスタを削除します。高度なオーケストレーションを行うには、Apache Airflow に基づく Cloud Composer を使用します。
アドホック クエリまたは外部でスケジュールされたワークロードを処理するクラスタの場合、指定されたアイドル時間の後、または特定の時刻にクラスタを削除するには、クラスタのスケジュール設定された削除を使用します。
サイズが異なるワークロード: クラスタで小さなジョブと大規模なジョブが実行されている場合、正常なデコミッションでは、大規模なジョブが終了するまでスケールダウンが開始しません。その結果、長時間実行ジョブが完了するまで、クラスタで実行されている小規模なジョブのリソースの自動スケーリングが遅延します。この結果を回避するには、サイズの類似した小規模なジョブをクラスタにグループ化し、実行時間の長いジョブを個別のクラスタに分離します。
自動スケーリングを有効にする
クラスタで自動スケーリングを有効にするには、次の操作を行います。
次のいずれかを行います。
自動スケーリング ポリシーを作成する
gcloud CLI
自動スケーリング ポリシーを作成するには、gcloud dataproc autoscaling-policies import コマンドを使用します。このコマンドは、自動スケーリング ポリシーを定義するローカルの YAML ファイルを読み取ります。ファイルの形式と内容は、autoscalingPolicies REST API で定義された構成オブジェクトやフィールドと一致している必要があります。
次の YAML の例は、すべての必須フィールドを含む Managed Service for Apache Spark 標準クラスタのポリシーを定義しています。また、プライマリ ワーカーの minInstances 値と maxInstances 値、セカンダリ(プリエンプティブル)ワーカーの maxInstances 値を指定し、cooldownPeriod を 4 分に設定しています(デフォルトは 2 分)。workerConfig は、プライマリ ワーカーを構成します。この例では、プライマリ ワーカーのスケーリングを回避するため、minInstances と maxInstances に同じ値を設定しています。
workerConfig:
minInstances: 10
maxInstances: 10
secondaryWorkerConfig:
maxInstances: 50
basicAlgorithm:
cooldownPeriod: 4m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
gracefulDecommissionTimeout: 1h
次の YAML の例は、すべての必須フィールドと省略可能な自動スケーリング ポリシー フィールドを含む、Managed Service for Apache Spark 標準クラスタのポリシーを定義しています。
clusterType: STANDARD
workerConfig:
minInstances: 10
maxInstances: 10
weight: 1
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100
weight: 1
basicAlgorithm:
cooldownPeriod: 2m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
scaleUpMinWorkerFraction: 0.0
scaleDownMinWorkerFraction: 0.0
gracefulDecommissionTimeout: 1h
次の YAML の例は、ゼロスケール クラスタのポリシーを定義しています。
ゼロスケール クラスタの場合は、workerConfig を含めないでください。
clusterType: ZERO_SCALE
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100
weight: 1
basicAlgorithm:
cooldownPeriod: 2m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
scaleUpMinWorkerFraction: 0.0
scaleDownMinWorkerFraction: 0.0
gracefulDecommissionTimeout: 1h
ローカル ターミナルまたは Cloud Shell で次の gcloud コマンドを実行して、自動スケーリング ポリシーを作成します。ポリシーの名前を指定します。この名前はポリシー id となり、後の gcloud コマンドでポリシーを参照するために使用できます。--source フラグを使用して、インポートする自動スケーリング ポリシーの YAML ファイルのローカルパスとファイル名を指定します。
gcloud dataproc autoscaling-policies import policy-name \ --source=filepath/filename.yaml \ --region=region
REST API
autoscalingPolicies.create リクエストの一部として AutoscalingPolicy を定義し、自動スケーリング ポリシーを作成します。
コンソール
自動スケーリング ポリシーを作成するには、 Google Cloud コンソールを使用して、Managed Service for Apache Spark の [自動スケーリング ポリシー] ページで [ポリシーを作成] を選択します。[ポリシーの作成] ページで、ポリシーに関するパネルを選択して、特定のジョブタイプまたはスケーリング目標の自動スケーリング ポリシー フィールドに入力します。
自動スケーリング クラスタを作成する
自動スケーリング ポリシーを作成した後、自動スケーリング ポリシーを使用するクラスタを作成します。クラスタは、自動スケーリング ポリシーと同じリージョンに配置する必要があります。
gcloud CLI
ローカルのターミナルや Cloud Shell で、次の gcloud コマンドを実行し、自動スケーリング クラスタを作成します。クラスタ名を指定し、--autoscaling-policy フラグに policy ID(ポリシーを作成したときに指定したポリシー名)を指定するか、ポリシー resource URI (resource name) を指定します(AutoscalingPolicy の id と name フィールドをご覧ください)。
gcloud dataproc clusters create cluster-name \ --autoscaling-policy=policy id or resource URI \ --region=region
REST API
clusters.create リクエストに AutoscalingConfig を含めて、自動スケーリング クラスタを作成します。
コンソール
Google Cloud コンソールで、Managed Service for Apache Spark の [クラスタの作成] ページにある [クラスタの設定] パネルの [自動スケーリング ポリシー] セクションから、新しいクラスタに適用する既存の自動スケーリング ポリシーを選択します。
既存のクラスタで自動スケーリングを有効にする
自動スケーリング ポリシーを作成した後、同じリージョンの既存のクラスタで作成したポリシーを有効にします。
gcloud CLI
既存のクラスタで自動スケーリング ポリシーを有効にするには、ローカルのターミナルまたは Cloud Shell で、次の gcloud コマンドを実行します。クラスタ名を指定し、--autoscaling-policy フラグに policy ID(ポリシーを作成したときに指定したポリシー名)を指定するか、ポリシー resource URI (resource name) を指定します(AutoscalingPolicy の id と name フィールドをご覧ください)。
gcloud dataproc clusters update cluster-name \ --autoscaling-policy=policy id or resource URI \ --region=region
REST API
既存のクラスタで自動スケーリング ポリシーを有効にするには、clusters.patch リクエストの updateMask でポリシーの AutoscalingConfig.policyUri を設定します。
コンソール
Google Cloud コンソールでは、既存のクラスタで自動スケーリング ポリシーを有効にすることはできません。
マルチクラスタ ポリシーの使用
自動スケーリング ポリシーは、複数のクラスタに適用できるスケーリングの動作を定義します。自動スケーリング ポリシーは、類似したワークロードを共有したり、類似したリソース使用パターンでジョブを実行する場合に最適です。
複数のクラスタで使用されているポリシーを更新できます。この更新は、そのポリシーを使用するすべてのクラスタの自動スケーリングの動作にすぐに反映されます(autoscalingPolicies.update をご覧ください)。ポリシーを使用しているクラスタにポリシーの更新が適用されないようにするには、ポリシーを更新する前に、クラスタの自動スケーリングを無効にします。
gcloud CLI
クラスタで自動スケーリングを無効にするには、ローカルのターミナルまたは Cloud Shell で、次の gcloud コマンドを実行します。
gcloud dataproc clusters update cluster-name --disable-autoscaling \ --region=region
REST API
クラスタで自動スケーリングを無効にするには、AutoscalingConfig.policyUri に空の文字列を設定し、clusters.patch リクエストで update_mask=config.autoscaling_config.policy_uri を設定します。
コンソール
Google Cloud コンソールでは、クラスタでの自動スケーリングの無効化はサポートされていません。
- 1 つ以上のクラスタで使用されているポリシーは削除できません(autoscalingPolicies.delete をご覧ください)。
自動スケーリングの仕組み
自動スケーリングでは、クラスタをスケーリングするかどうかを決定するために、各クールダウン期間が経過するたびにクラスタの Hadoop YARN 指標をチェックし、スケーリングする場合は、更新の規模を決定します。
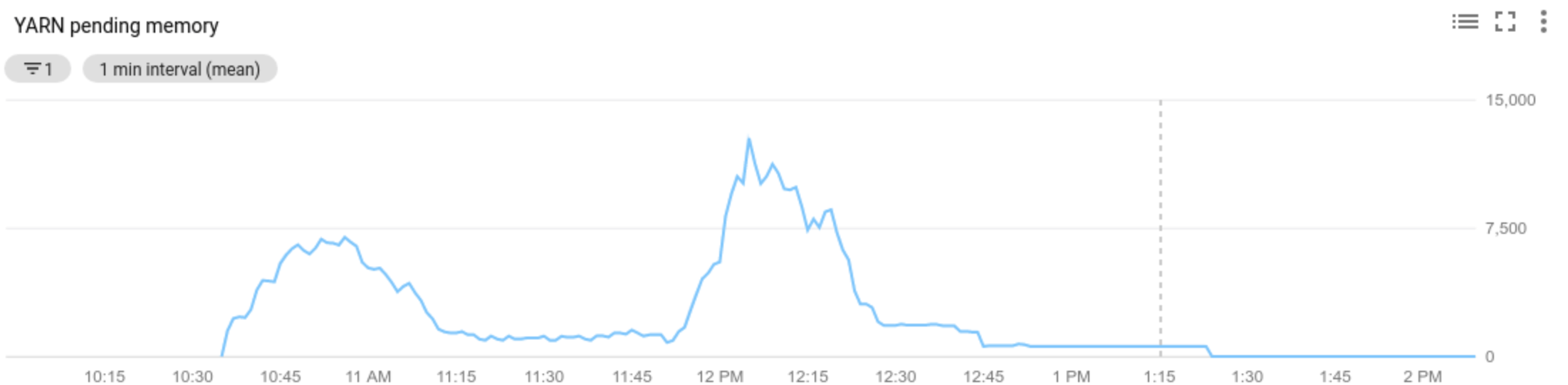
YARN 保留中リソース指標(保留中のメモリまたはコア)の値によって、スケールアップまたはスケールダウンするかどうかが決まります。値が
0より大きい場合は、YARN ジョブがリソースを待機しており、スケールアップが必要になる可能性があることを示します。0値は、YARN に十分なリソースがあるため、スケールダウンなどの変更が必要ない可能性があることを示します。保留中リソースが 0 より大きい場合:
$estimated\_worker\_count =$
\[ \Biggl \lceil AVERAGE\ during\ cooldown\ period\Big(\frac{Pending + Available + Allocated + Reserved}{Resource\ per\ worker}\Big)\Biggr \rceil \]
保留中リソースが 0 の場合:
$estimated\_worker\_count =$
\[ \Biggl \lceil AVERAGE\ during\ cooldown\ period\Big(\frac{Allocated + Reserved}{Resource\ per\ worker}\Big)\Biggr \rceil \]
Managed Service for Apache Spark イメージ 2.2 以降では、デフォルトでオートスケーラーが YARN メモリと YARN コアをモニタリングするため、
estimated_worker_countはメモリとコアについて別々に評価され、より多くのワーカー数が選択されます。以前のイメージ バージョンでは、コアベースの自動スケーリングを有効にしない限り、オートスケーラーは YARN メモリのみをモニタリングします。$estimated\_worker\_count =$
\[ max(estimated\_worker\_count\_by\_memory,\ estimated\_worker\_count\_by\_cores) \]
\[ estimated\ \Delta worker = estimated\_worker\_count - current\_worker\_count \]
ワーカー数に必要な変更が見積もられると、自動スケーリングは、
scaleUpFactorまたはscaleDownFactorを使用してワーカー数の実際の変更を計算します。if estimated Δworkers > 0: actual Δworkers = ROUND_UP(estimated Δworkers * scaleUpFactor) # examples: # ROUND_UP(estimated Δworkers=5 * scaleUpFactor=0.5) = 3 # ROUND_UP(estimated Δworkers=0.8 * scaleUpFactor=0.5) = 1 else: actual Δworkers = ROUND_DOWN(estimated Δworkers * scaleDownFactor) # examples: # ROUND_DOWN(estimated Δworkers=-5 * scaleDownFactor=0.5) = -2 # ROUND_DOWN(estimated Δworkers=-0.8 * scaleDownFactor=0.5) = 0 # ROUND_DOWN(estimated Δworkers=-1.5 * scaleDownFactor=0.5) = 0
scaleUpFactor や scaleDownFactor が 1.0 の場合、保留中または使用可能なリソースが 0(完全に使用されている)になるように自動スケーリングが行われます。
ワーカー数の変更が計算されると、
scaleUpMinWorkerFractionとscaleDownMinWorkerFractionのどちらかがしきい値として機能し、自動スケーリングによってクラスタがスケールされるかどうか判断されます。Δworkersが小さい場合でも、割合が小さければ自動スケーリングが必要であることを意味します。Δworkersが大きい場合は、割合が大きい場合のみ自動スケーリングが行われます。IF (Δworkers > scaleUpMinWorkerFraction * current_worker_count) then scale up
IF (abs(Δworkers) > scaleDownMinWorkerFraction * current_worker_count), THEN scale down.
スケールするワーカーの数がスケーリングのトリガーに十分な数の場合、自動スケーリングは、
workerConfig、secondaryWorkerConfig、weight(プライマリ ワーカーとセカンダリ ワーカーの比率)のminInstancesmaxInstancesの範囲を使用して、プライマリ ワーカー インスタンス グループとセカンダリ ワーカー インスタンス グループでワーカー数を分割する方法を決定します。こうした計算の結果は、スケーリング期間のクラスタに対する最終的な自動スケーリングの変更になります。次の条件を満たす場合、2.0.57 以降、2.1.5 以降のイメージ バージョンで作成されたクラスタで自動スケーリングのスケールダウン リクエストがキャンセルされます。
- ゼロ以外の正常なデコミッション タイムアウト値でスケールダウンが進行中である。
次の式に示すように、アクティブな YARN ワーカー(アクティブ ワーカー)の数に、オートスケーラーが推奨するワーカーの合計数(
Δworkers)の変更を加えると、DECOMMISSIONINGYARN ワーカー(デコミッション ワーカー)の数と等しいかそれ以上になる。IF (active workers + Δworkers ≥ active workers + decommissioning workers) THEN cancel the scaledown operation
スケールダウンのキャンセル例については、自動スケーリングによってスケールダウン オペレーションがキャンセルされるタイミングをご覧ください。
自動スケーリング構成の推奨事項
このセクションでは、自動スケーリングの構成に役立つ推奨事項について説明します。
プライマリ ワーカーのスケーリングを回避する
プライマリ ワーカーは HDFS データノードを実行しますが、セカンダリ ワーカーはコンピューティングのみを行います。セカンダリ ワーカーを使用すると、ストレージをプロビジョニングすることなくコンピューティング リソースを効率的にスケーリングできるため、スケーリング機能が向上します。HDFS Namenode に競合状態が複数あると、HDFS が破損し、デコミッションが恒久的に停止する可能性があります。この問題を防ぐには、プライマリ ワーカーのスケーリングを回避します。たとえば、次のようにします。
none
workerConfig:
minInstances: 10
maxInstances: 10
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100
クラスタの作成コマンドを次のように変更する必要があります。
- 自動スケーリング ポリシーのプライマリ ワーカー グループのサイズに合わせて
--num-workers=10を設定します。 - セカンダリ ワーカーを非プリエンプティブルになるように構成するには、
--secondary-worker-type=non-preemptibleを設定します。(プリエンプティブル VM が必要な場合を除く)。 - ハードウェア構成をプライマリ ワーカーからセカンダリ ワーカーにコピーします。たとえば、
--worker-boot-disk-size=1000GBと一致するように--secondary-worker-boot-disk-size=1000GBを設定します。
Spark バッチジョブでの高度な柔軟性モードの使用
自動スケーリングで高度な柔軟性モード(EFM)を使用すると、次のことが可能になります。
ジョブの実行中にクラスタのスケールダウンを高速化する
クラスタのスケールダウンによる実行中のジョブの停止を防ぐ
プリエンプティブル セカンダリ ワーカーのプリエンプションによる実行中のジョブの停止を最小限に抑える
EFM が有効な場合、自動スケーリング ポリシーの正常なデコミッションのタイムアウトを 0s に設定する必要があります。自動スケーリング ポリシーでは、セカンダリ ワーカーの自動スケーリングのみを行う必要があります。
正常なデコミッションのタイムアウトを選択する
自動スケーリングでは、クラスタからノードを削除するときに YARN の正常なデコミッションがサポートされます。正常なデコミッションにより、アプリケーションはジョブの進行を妨げないよう、ステージ間でデータのシャッフルを完了できます。自動スケーリング ポリシーで提供される正常なデコミッション タイムアウトは、YARN がノードを削除する前にアプリケーション(デコミッションの開始時に実行されていたアプリケーション)の実行を待機する時間の上限です。
指定された正常なデコミッション タイムアウト期間内にプロセスが完了しない場合、ワーカーノードは強制的にシャットダウンされ、データの損失やサービスの停止が発生する可能性があります。このような可能性を防ぐには、正常なデコミッションのタイムアウトをクラスタが処理する最長ジョブよりも長い値に設定します。たとえば、最長ジョブが 1 時間実行されると予想される場合は、タイムアウトを少なくとも 1 時間(1h)に設定します。
正常なデコミッションがブロックされないようにするため、処理時間が 1 時間を超えるジョブを独自のエフェメラル クラスタに移行することを検討してください。
scaleUpFactor の設定
scaleUpFactor は、オートスケーラーがクラスタをどのくらい積極的にスケールアップするかを制御します。0.0~1.0 の数値を指定して、ノードを追加する YARN の保留中リソースを小数値で設定します。
たとえば、100 MB の保留中コンテナがそれぞれ 512 MB をリクエストしている場合、保留中の YARN メモリは 50 GB になります。scaleUpFactor が 0.5 の場合、オートスケーラーは 25 GB の YARN メモリを追加するのに十分な数のノードを追加します。同様に、0.1 の場合、オートスケーラーは 5 GB のメモリの追加に十分なノードを追加します。これらの値は、VM 上で物理的に使用可能な合計メモリではなく、YARN メモリに対応しています。
まず、MapReduce ジョブと動的割り当てが有効になっている Spark ジョブに 0.05 を利用することをおすすめします。固定エグゼキュータ数と Tez ジョブを持つ Spark ジョブの場合は、1.0 を使用します。scaleUpFactor が 1.0 の場合、保留中または使用可能なリソースが 0(完全に使用されている)になるように自動スケーリングが行われます。
scaleDownFactor の設定
scaleDownFactor は、オートスケーラーがクラスタをどのくらい積極的にスケールダウンするかを制御します。0.0~1.0 の数値を指定して、ノードの削除の原因となる YARN リソースを小数値で設定します。
頻繁にスケールアップとスケールダウンが必要なほとんどのマルチジョブ クラスタでは、この値を 1.0 のままにします。正常なデコミッションの結果、スケールダウン オペレーションは、スケールアップ オペレーションよりも大幅に遅くなります。scaleDownFactor=1.0 を設定すると、積極的なスケールダウン率が設定されます。これにより、適切なクラスタサイズを達成するために必要なダウンスケーリング オペレーションの数を最小限に抑えることができます。
安定性を必要とするクラスタの場合は、スケールダウンのレートを遅くするために scaleDownFactor を低く設定します。
エフェメラル クラスタや単一ジョブクラスタを使用する場合などは、この値を 0.0 に設定して、クラスタのスケールダウンを回避します。
scaleUpMinWorkerFraction と scaleDownMinWorkerFraction の設定
scaleUpMinWorkerFraction と scaleDownMinWorkerFraction は scaleUpFactor または scaleDownFactor とともに使用されます。デフォルト値は 0.0 です。これらは、オートスケーラーがクラスタをスケールアップまたはスケールダウンするしきい値を表します。これは、スケールアップまたはスケールダウン リクエストを発行するために必要なクラスタサイズの最小の増減値です。
例: scaleUpMinWorkerFraction が 0.05(5%)以下でない限り、オートスケーラーは 100 ノードクラスタに 5 つのワーカーを追加するための更新リクエストを発行しません。0.1 に設定すると、オートスケーラーはクラスタのスケールアップ リクエストを発行しません。同様に、scaleDownMinWorkerFraction が 0.05 の場合、少なくとも 5 つのノードが削除されない限り、オートスケーラーはリクエストを発行しません。
デフォルト値の 0.0 は、しきい値がないことを示します。
小規模で不要なスケーリング オペレーションを回避するため、大規模なクラスタ(100 ノード以上)で scaleDownMinWorkerFractionthresholds を高く設定することを強くおすすめします。
クールダウン期間を選択する
cooldownPeriod は、オートスケーラーがクラスタサイズの変更リクエストを発行しない期間を設定します。これにより、クラスタサイズに対するオートスケーラーの変更頻度を制限できます。
cooldownPeriod の最小値は 2 分です(これがデフォルトです)。ポリシーにより短い cooldownPeriod を設定した場合、ワークロードの変化がクラスタのサイズにより早く影響を与えますが、クラスタが不必要にスケールアップやスケールダウンされる可能性があります。より短い cooldownPeriod を使う場合は、ポリシーの scaleUpMinWorkerFraction と scaleDownMinWorkerFraction をゼロ以外の値に設定することをおすすめします。この設定により、クラスタを更新する正当な理由に値するリソース使用量の変化がある場合に限り、クラスタがスケールアップまたはスケールダウンされます。
ワークロードがクラスタサイズの変更に影響を受けやすい場合は、クールダウン期間を長くすることができます。たとえば、バッチ処理ジョブを実行している場合は、クールダウン期間を 10 分以上に設定できます。さまざまなクールダウン期間を試して、ワークロードに最適な値を見つけてください。
ワーカー数とグループの重み
各ワーカー グループには minInstances と maxInstances があり、各グループのサイズにハードリミットを構成します。
各グループには、weight というパラメータもあり、2 つのグループの間の目標バランスを構成します。このパラメータはヒントにすぎません。グループが最小サイズまたは最大サイズに到達すると、ノードの追加と削除は他のグループからのみ行われます。したがって、weight はほとんどの場合、デフォルトの 1 のままにできます。
コアベースの自動スケーリングを使用する
CPU を多く使うアプリケーションの場合、リソース割り当てに Dominant Resource Calculator を使用することが推奨されます。Managed Service for Apache Spark のイメージ バージョン 2.2 以降では、デフォルトの YARN 構成がこの方式になっています。それより古いイメージを使っている場合は、Managed Service for Apache Spark はメモリ指標を基準に YARN のリソースを割り当てます。そのため、Dominant Resource Calculator を使いたい場合は、クラスタ作成時に以下のプロパティを設定する必要があります。
capacity-scheduler:yarn.scheduler.capacity.resource-calculator=org.apache.hadoop.yarn.util.resource.DominantResourceCalculator
自動スケーリング指標とログ
次のリソースとツールは、自動スケーリングの操作と、クラスタとそのジョブへの影響をモニタリングするのに役立ちます。
Cloud Monitoring
Cloud Monitoring を使用すると、次のことができます。
- 自動スケーリングで使用される指標を表示する
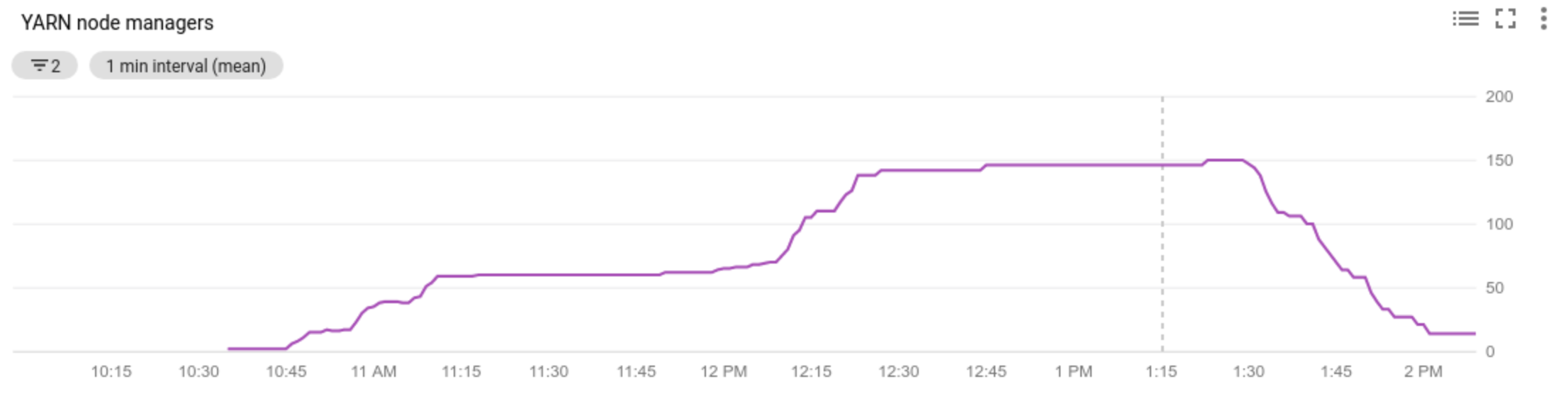
- クラスタ内のノード マネージャーの数を表示する
- 自動スケーリングでクラスタリングが行われた理由、または行われなかった理由を理解する
Cloud Logging
Cloud Logging を使用して、Managed Service for Apache Spark Autoscaler のログを表示します。
1)クラスタのログを検索します。
2)dataproc.googleapis.com/autoscaler を選択します。
3)ログ メッセージを開いて status フィールドを表示します。ログは、機械で読み取り可能な JSON 形式です。
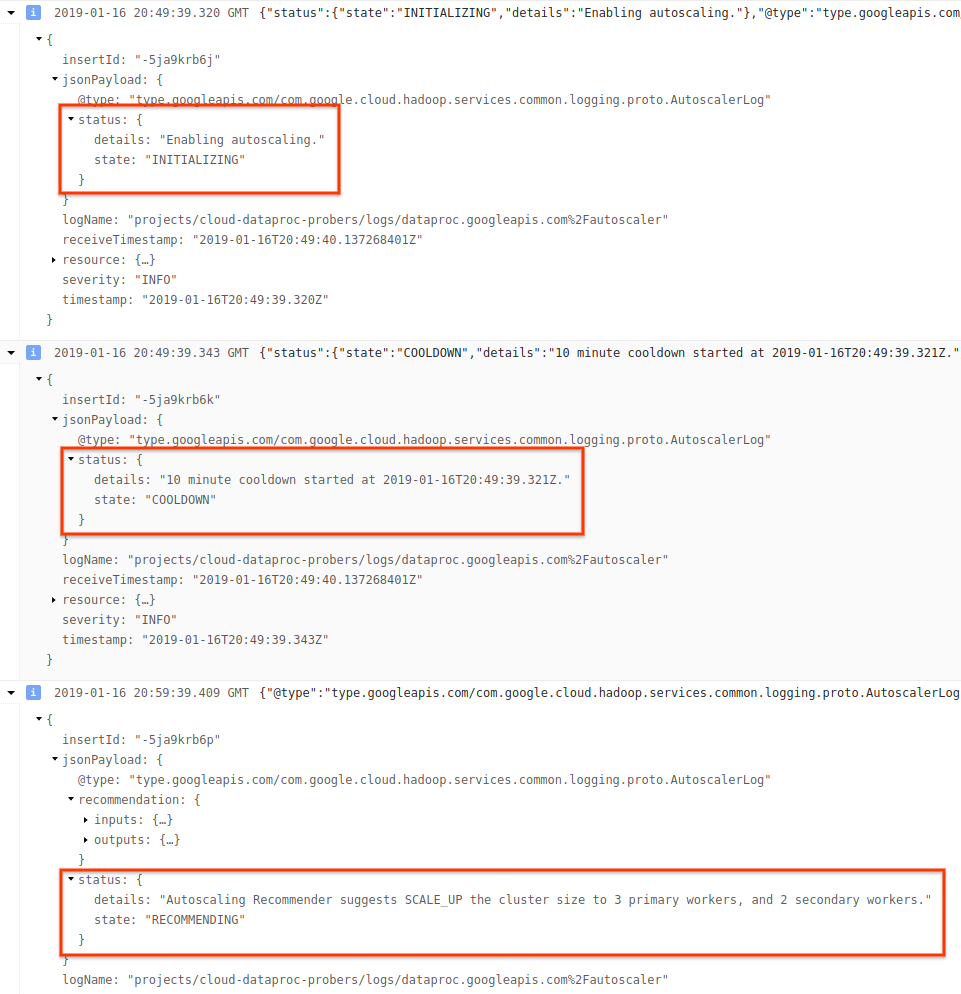
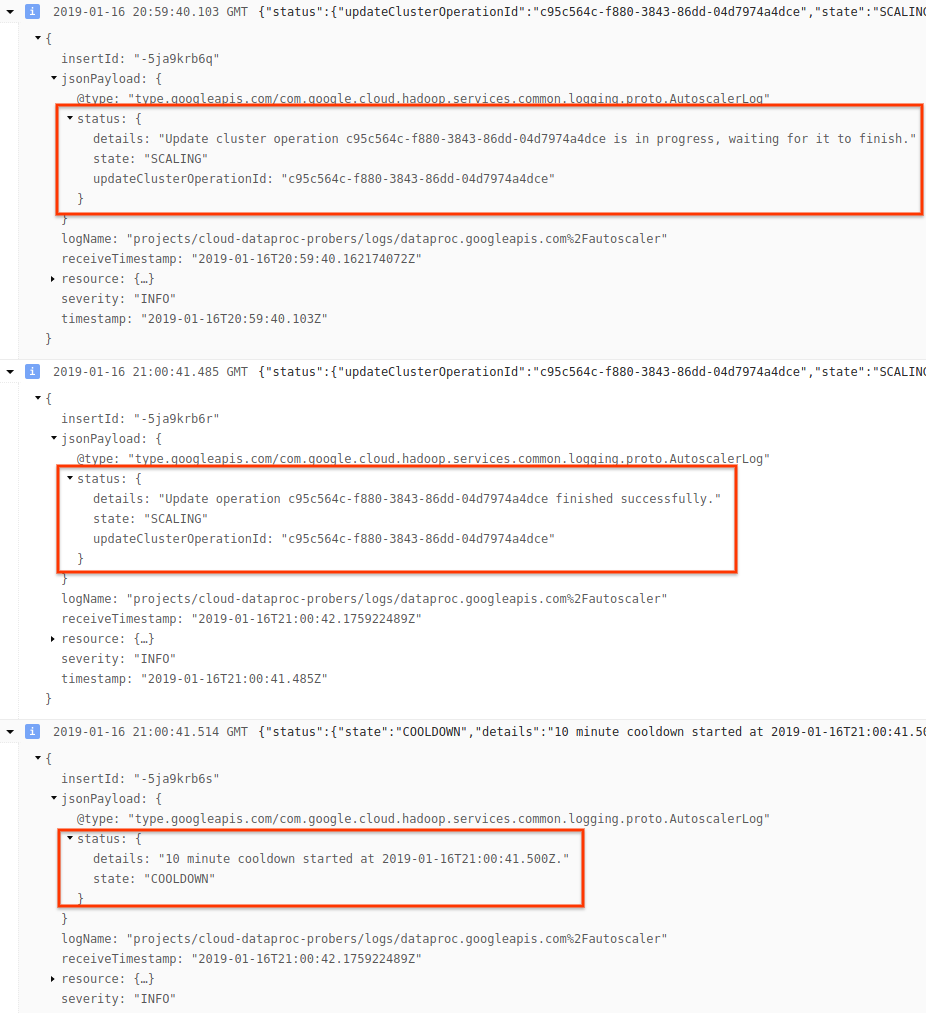
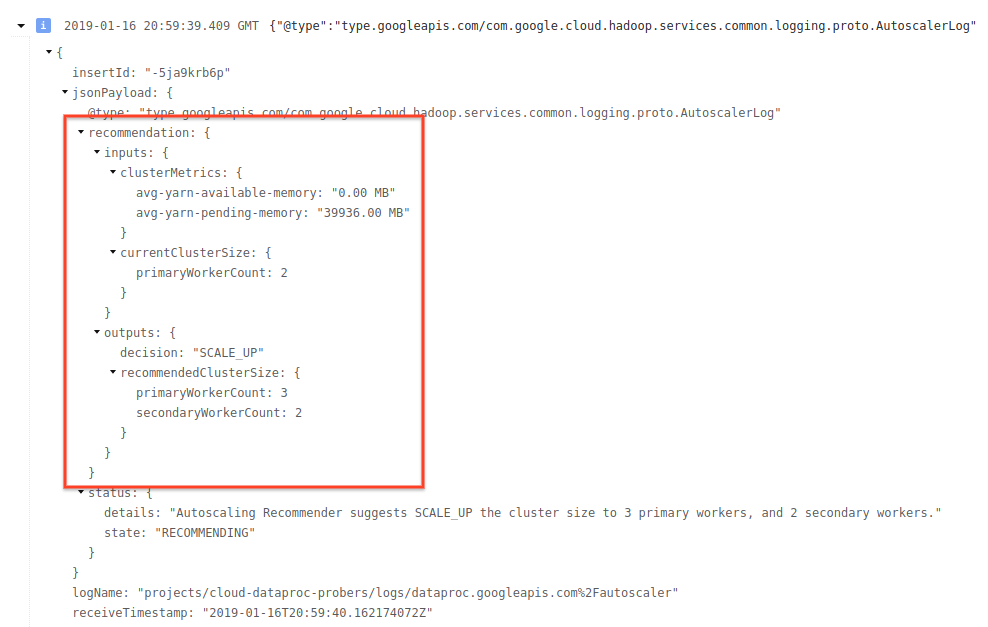
4)ログ メッセージを開いて、スケーリングの推奨値、スケーリングの決定に使用する指標、オリジナルのクラスタサイズ、新しいクラスタサイズを表示します。
背景: Apache Hadoop と Apache Spark による自動スケーリング
以下のセクションでは、自動スケーリングの Hadoop YARN、Hadoop Mapreduce、Apache Spark、Spark Streaming、Spark Structured Streaming との相互運用方法について説明します。
Hadoop YARN 指標
自動スケーリングは、次の Hadoop YARN 指標に基づいて実行されます。
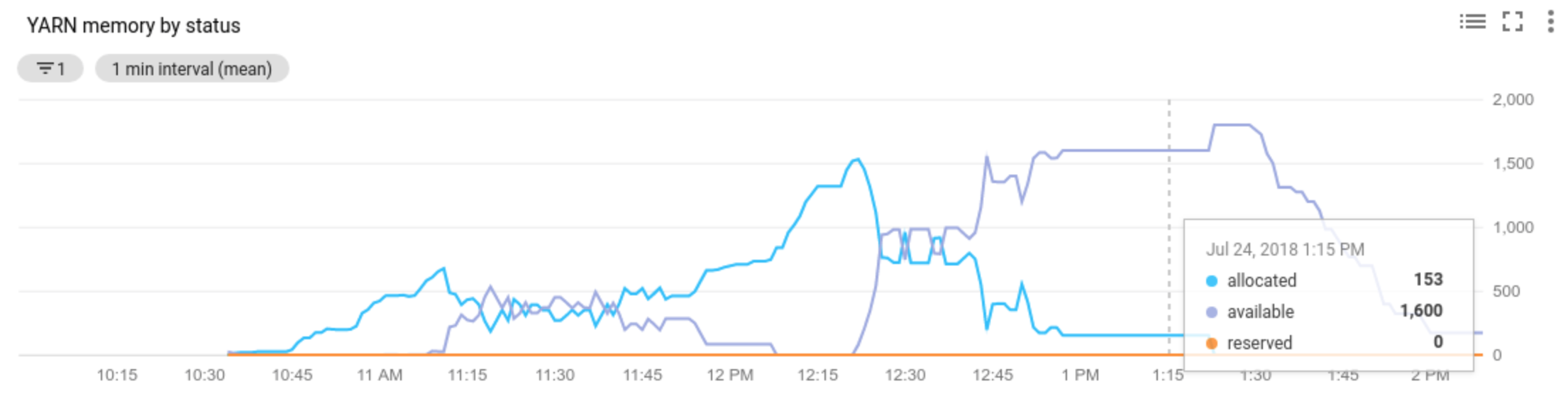
Allocated resourceは、コンテナを実行することによってクラスタ全体で使用される YARN リソースの合計を指します。6 つのコンテナが実行中で、それぞれ最大 1 つリソース谷を使用できる場合は、6 つのリソースが割り当てられます。Available resourceは、割り当てられたコンテナで使用されない、クラスタ内の YARN リソースです。すべてのノード マネージャーに 10 個のリソースがあり、そのうち 6 個が割り当てられている場合、利用可能なリソースは 4 個です。クラスタに利用可能な(使用されていない)リソースがある場合、自動スケーリングでクラスタからワーカーが削除されることがあります。Pending resourceは、保留中コンテナに対する YARN リソース リクエストの合計です。保留中コンテナは、YARN で実行するスペースを待機しています。利用可能なリソースが 0 か、少なすぎて次のコンテナに割り当てることができない場合にのみ、保留中リソースが 0 以外になります。保留中コンテナがある場合、自動スケーリングでクラスタにワーカーが追加されることがあります。
これらの指標は Cloud Monitoring で確認できます。デフォルトでは、クラスタ上の YARN メモリは「0.8 × 合計メモリ」となり、残りのメモリは他のデーモンや、ページ キャッシュなどオペレーティング システムでの使用に予約されます。このデフォルト値は、yarn.nodemanager.resource.memory-mb の YARN 構成設定でオーバーライドできます(Apache Hadoop YARN、HDFS、Spark、関連プロパティをご覧ください)。
自動スケーリングと Hadoop MapReduce
MapReduce は各マップを実行し、独立した YARN コンテナとしてタスクを削減します。ジョブが開始されると、MapReduce は各マップタスクに対するコンテナ リクエストを送信するため、保留中の YARN メモリが急増します。マップタスクが完了すると、保留中のメモリは減少します。
mapreduce.job.reduce.slowstart.completedmaps が完了すると(Managed Service for Apache Spark でのデフォルトは 95%)、MapReduce によりすべてのレデューサに対するコンテナ リクエストがキューに追加され、保留メモリがさらに急増します。
タスクのマッピングと縮小に数分以上かかる場合を除き、自動スケーリング scaleUpFactor に高い値を設定しないでください。クラスタにワーカーを追加するには少なくとも 1.5 分かかるので、新しいワーカーを利用するための十分な保留作業を行えるように数分間を確保してください。最初は scaleUpFactor を保留中のメモリの 0.05(5%)または 0.1(10%)に設定することをおすすめします。
自動スケーリングと Spark
Spark は、YARN の上にスケジューリングのためのレイヤを追加します。具体的には、Spark Core の動的割り当てにより、コンテナで Spark エグゼキューターを実行するように YARN にリクエストし、それらのエグゼキューターのスレッドで Spark タスクをスケジュールします。Managed Service for Apache Spark クラスタではデフォルトで動的割り当てが有効になっているため、エグゼキュータは必要に応じて追加されたり削除されたりします。
Spark は常に YARN にコンテナを要求しますが、動的割り当てが行われない場合は、ジョブの開始時にのみコンテナを要求します。動的割り当てが行われる場合、必要に応じてコンテナを削除したり、新しいコンテナをリクエストしたりします。
Spark は少数(自動スケーリング クラスタ上で 2 つ)のエグゼキュータから開始されます。未処理のタスクがある間は、エグゼキュータの数を倍増し続けます。これにより、保留中のメモリが少なくなります(保留中のメモリが急増することが少なくなります)。Spark ジョブの場合は、自動スケーリング scaleUpFactor に 1.0(100%)などの大きい数を設定することをおすすめします。
Spark の動的割り当てを無効にする
Spark の動的割り当ての恩恵を受けない個別の Spark ジョブを実行している場合は、spark.dynamicAllocation.enabled=false と spark.executor.instances を設定して Spark の動的割り当てを無効にできます。別の Spark ジョブの実行中でも、自動スケーリングを使用してクラスタをスケーリングできます。
キャッシュ データを使用した Spark ジョブ
データセットが不要になった場合は、spark.dynamicAllocation.cachedExecutorIdleTimeout を設定するか、データセットのキャッシュを解除します。デフォルトでは、Spark はキャッシュされたデータのあるエグゼキューターを削除せず、クラスタのスケールダウンを防止します。
自動スケーリングと Spark Streaming
Spark Streaming には、ストリーミング固有のシグナルを使用してエグゼキューターの追加や削除を行う独自の動的割り当てがあるため、
spark.streaming.dynamicAllocation.enabled=trueを設定して、Spark Core の動的割り当てを無効にするspark.dynamicAllocation.enabled=falseを設定します。Spark Streaming ジョブと一緒に正常なデコミッション(自動スケーリングの
gracefulDecommissionTimeout)を使用しないでください。代わりに、自動スケーリングでワーカーを安全に削除するには、フォールト トレランスのためのチェックポイントを構成します。
または、自動スケーリングなしで Spark Streaming を使用します。
- Spark Core の動的割り当て(
spark.dynamicAllocation.enabled=false)を無効にします。 - ジョブのエグゼキューターの数(
spark.executor.instances)を設定します。クラスタ プロパティをご覧ください。
自動スケーリングと Spark Structured Streaming
Spark Structured Streaming では動的割り当てがサポートされていないため、自動スケーリングには Spark Structured Streaming との互換性がありません(SPARK-24815: Structured Streaming should support dynamic allocation をご覧ください)。
パーティショニングと並列処理による自動スケーリングの制御
並列処理は通常、クラスタ リソースによって設定または決定されます(たとえば、複数のタスクで制御される HDFS ブロック数)。自動スケーリングではその逆が適用され、ジョブの並列性に従ってクラスタ リソース(ワーカー)が設定されます。ジョブの並列処理の設定に役立つガイドラインは次のとおりです。
- Managed Service for Apache Spark では、初期のクラスタサイズに基づいて MapReduce のデフォルトの削減タスク数が設定されますが、
mapreduce.job.reducesを設定して削減フェーズの並列処理を増やすことができます。 - Spark SQL と Dataframe の並列処理は
spark.sql.shuffle.partitionsによって決まります。デフォルトは 200 です。 - Spark の RDD 関数はデフォルトで
spark.default.parallelismに設定されます。これは、ジョブの開始時にワーカーノードのコア数に設定されます。ただし、シャッフルを作成する RDD 関数はすべて、spark.default.parallelismをオーバーライドするパーティション数のパラメータを使用します。
データが均等に分割されていることを確認する必要があります。重大なキースキューがある場合、1 つ以上のタスクが他のタスクよりも大幅に時間がかかり、結果として使用率が低くなる可能性があります。
自動スケーリングのデフォルトの Spark / Hadoop プロパティ設定
自動スケーリング クラスタには、プライマリ ワーカーが削除されたときやセカンダリ ワーカーがプリエンプトされたときのジョブの失敗を回避するために役立つデフォルトのクラスタ プロパティ値があります。これらのデフォルト値は、自動スケーリングを使用してクラスタを作成するときにオーバーライドできます(クラスタ プロパティ をご覧ください)。
以下は、タスク、アプリケーション マスター、ステージの最大再試行回数を増やすデフォルトの設定です。
yarn:yarn.resourcemanager.am.max-attempts=10 mapred:mapreduce.map.maxattempts=10 mapred:mapreduce.reduce.maxattempts=10 spark:spark.task.maxFailures=10 spark:spark.stage.maxConsecutiveAttempts=10
以下は再試行カウンタをリセットするデフォルトの設定です(長時間実行する Spark Streaming ジョブに役立ちます)。
spark:spark.yarn.am.attemptFailuresValidityInterval=1h spark:spark.yarn.executor.failuresValidityInterval=1h
以下は、Spark の小規模から開始する slow-start 動的割り当てメカニズムのデフォルトの設定です。
spark:spark.executor.instances=2
よくある質問(FAQ)
このセクションでは、自動スケーリングに関するよくある質問とその回答を紹介します。
高可用性クラスタと単一ノードクラスタで自動スケーリングを有効にすることはできますか?
高可用性クラスタでは自動スケーリングを有効にできますが、単一ノードクラスタでは有効にできません(単一ノードクラスタではサイズ変更がサポートされません)。
自動スケーリング クラスタのサイズを手動で変更できますか?
はい。自動スケーリング ポリシーを調整するときは、暫定措置として、クラスタのサイズを手動で変更できます。ただし、こうした変更には一時的な効果しかないため、自動スケーリングで最終的にクラスタが縮小されます。
自動スケーリング クラスタのサイズを手動で変更する代わりに、次のことを検討してください。
自動スケーリング ポリシーを更新する。自動スケーリング ポリシーに加えた変更は、現在そのポリシーを使用しているすべてのクラスタに影響します(マルチクラスタ ポリシーの使用を参照)。
ポリシーを解除し、クラスタを適切なサイズに手動でスケールする。
Managed Service for Apache Spark のサポートを受ける。
Managed Service for Apache Spark と Dataflow の自動スケーリングはどのように違いますか?
Dataflow の水平自動スケーリングと Dataflow Prime の垂直自動スケーリングをご覧ください。
Managed Service for Apache Spark の開発チームは、クラスタのステータスを ERROR から RUNNING にリセットできますか?
一般的に答えは「いいえ」です。手動でリセットするには、クラスタの状態をリセットするための作業が安全であることを手動で確認する必要があります。多くの場合、HDFS NameNode の再起動など、別の手動操作を行わないと、クラスタはリセットできません。
失敗したオペレーション後のクラスタのステータスを特定できない場合、Managed Service for Apache Spark はクラスタのステータスを ERROR に設定します。ERROR のクラスタは自動スケーリングされません。一般的には次のような原因が考えられます。
Compute Engine API から返されたエラー。多くの場合、Compute Engine のサービス停止中に起こります。
HDFS のデコミッションの不具合により、HDFS が破損した状態になっている。
Managed Service for Apache Spark Control API エラー(タスクのリース切れなど)。
ステータスが ERROR のクラスタを削除して再作成します。
自動スケーリングによってスケールダウン オペレーションがキャンセルされるタイミング
次の図は、自動スケーリングによってスケールダウン オペレーションがキャンセルされるタイミングを示しています(自動スケーリングの仕組みもご覧ください)。
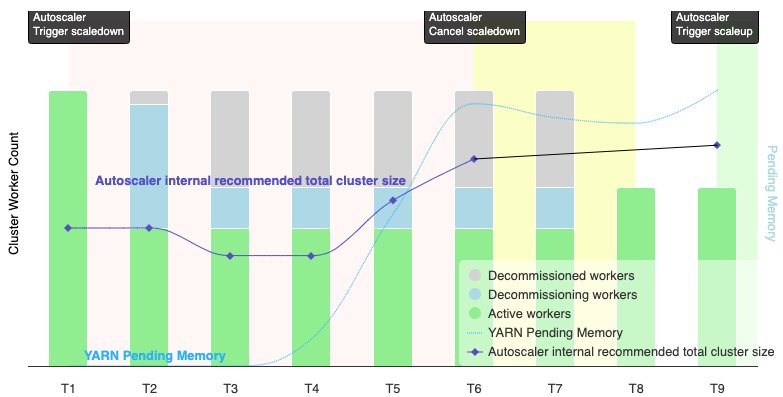
注:
- クラスタでは、YARN メモリ指標のみに基づいて自動スケーリングが有効になっています(デフォルト)。
- T1~T9 は、オートスケーラーがワーカー数を評価する際のクールダウン間隔を表します(イベントのタイミングは簡略化されています)。
- 積み上げ棒グラフは、アクティブなクラスタ YARN ワーカー、デコミッション中のクラスタ YARN ワーカー、デコミッションされたクラスタ YARN ワーカーの数を表します。
- オートスケーラーが推奨するワーカー数(黒い線)は、YARN メモリ指標、YARN アクティブ ワーカー数、自動スケーリング ポリシーの設定に基づいています(自動スケーリングの仕組みをご覧ください)。
- 背景が赤色の領域は、スケールダウン オペレーションが実行されている期間を示します。
- 背景が黄色の領域は、スケールダウン オペレーションがキャンセルされた期間を示します。
- 背景が緑色の領域は、スケールアップ オペレーションの期間を示します。
次の時点で、次の処理が発生します。
T1: オートスケーラーが、現在のクラスタ ワーカーの約半分をスケールダウンする正常なデコミッション スケールダウン オペレーションを開始します。
T2: オートスケーラーがクラスタ指標のモニタリングを継続します。スケールダウンの推奨事項は変更されず、スケールダウン オペレーションが続行されます。デコミッション済みのワーカーとデコミッション中のワーカーがあります(Managed Service for Apache Spark はデコミッション済みのワーカーを削除します)。
T3: オートスケーラーが、さらにスケールダウン可能なワーカー数を計算します。これは、追加の YARN メモリが使用可能になったことが原因である可能性があります。ただし、アクティブ ワーカー数に、推奨されるワーカー数の変更を加えると、アクティブ ワーカー数とデコミッション ワーカーの数の合計未満になるため、スケールダウンのキャンセル条件を満たさず、オートスケーラーはスケールダウン オペレーションをキャンセルしません。
T4: YARN が保留中のメモリの増加を報告します。ただし、オートスケーラーはワーカー数の推奨値を変更しません。T3 と同様に、スケールダウンのキャンセル条件を満たしていないため、オートスケーラーがスケールダウン オペレーションをキャンセルすることはありません。
T5: YARN の保留中のメモリが増加し、オートスケーラーによる推奨ワーカー数の変更が増えます。ただし、アクティブ ワーカー数に、推奨されるワーカー数の変更を加えると、アクティブ ワーカー数とデコミッション ワーカーの数の合計未満になり、キャンセル条件を満たしていないため、スケールダウン オペレーションがキャンセルされません。
T6: YARN の保留中のメモリがさらに増加します。アクティブなワーカー数に、オートスケーラーによって推奨されるワーカーの数の変更を加えると、アクティブなワーカー数とデコミッション ワーカーの合計より大きくなります。キャンセル条件を満たしているため、オートスケーラーによってスケールダウン オペレーションがキャンセルされます。
T7: オートスケーラーがスケールダウン オペレーションのキャンセルの完了を待機しています。オートスケーラーは、この期間中にワーカー数の変更の評価や推奨を行いません。
T8: スケールダウン オペレーションのキャンセルが完了します。デコミッション予定のワーカーがクラスタに追加され、アクティブになります。オートスケーラーはスケールダウン オペレーションのキャンセル完了を検出し、次の評価期間(T9)まで待機して、推奨されるワーカー数を計算します。
T9: T9 時点ではアクティブなオペレーションはありません。オートスケーラー ポリシーと YARN 指標に基づいて、オートスケーラーはスケールアップ オペレーションを推奨します。