
在使用可选组件功能创建 Managed Service for Apache Spark 集群时,您可以激活 Flink 等其他组件。本页面介绍如何创建激活了 Apache Flink 可选组件(即 Flink 集群)的 Managed Service for Apache Spark 集群,并在该集群上运行 Flink 作业。
您可以使用 Flink 集群执行以下操作:
通过 Google Cloud 控制台、Google Cloud CLI 或 Managed Service for Apache Spark API,使用 Managed Service for Apache Spark
Jobs资源运行 Flink 作业。
创建 Managed Service for Apache Spark Flink 集群
您可以使用 Google Cloud 控制台、Google Cloud CLI 或 Managed Service for Apache Spark API 创建一个 Managed Service for Apache Spark 集群,并在该集群上激活 Flink 组件。
建议:使用包含 Flink 组件的标准单主虚拟机集群。Managed Service for Apache Spark 高可用性模式集群(带有 3 个主控虚拟机)不支持 Flink 高可用性模式。
控制台
如需使用 Google Cloud 控制台创建 Managed Service for Apache Spark Flink 集群,请执行以下步骤:
打开 Managed Service for Apache Spark 在 Compute Engine 上创建 Managed Service for Apache Spark 集群页面。
- 设置集群面板已处于选中状态。
- 在版本控制部分,确认或更改映像类型和版本。集群映像版本决定了安装在集群上的 Flink 组件版本。
- 映像版本必须为 1.5 或更高版本,才能在集群上激活 Flink 组件(如需查看每个 Managed Service for Apache Spark 映像版本中包含的组件版本列表,请参阅支持的 Managed Service for Apache Spark 版本)。
- 如需通过 Managed Service for Apache Spark Jobs API 运行 Flink 作业,映像版本必须为 [TBD] 或更高版本(请参阅运行 Managed Service for Apache Spark Flink 作业)。
- 在组件部分中执行以下操作:
- 在组件网关下,选择启用组件网关。必须启用组件网关,才能激活组件网关与 Flink History Server 界面的链接。启用组件网关后,您还可以访问在 Flink 集群上运行的 Flink Job Manager 网页界面。
- 在可选组件部分,选择要在集群上激活的 Flink 和其他组件。
- 在版本控制部分,确认或更改映像类型和版本。集群映像版本决定了安装在集群上的 Flink 组件版本。
点击自定义集群(可选)面板。
在集群属性部分,为每个要添加到集群的可选集群属性点击添加属性。您可以添加以
flink为前缀的属性,以便在/etc/flink/conf/flink-conf.yaml中配置 Flink 属性,这些属性将作为您在集群中运行的 Flink 应用的默认值。示例:
- 设置
flink:historyserver.archive.fs.dir以指定用于写入 Flink 作业历史记录文件的 Cloud Storage 位置(此位置将由在 Flink 集群上运行的 Flink History Server 使用)。 - 使用
flink:taskmanager.numberOfTaskSlots=n设置 Flink 任务槽数。
- 设置
在自定义集群元数据部分,点击添加元数据以添加可选元数据。例如,添加
flink-start-yarn-sessiontrue以在集群主节点的后台运行 Flink YARN 守护程序 (/usr/bin/flink-yarn-daemon) 来启动 Flink YARN 会话(请参阅 Flink 会话模式)。
如果您使用的是 Managed Service for Apache Spark 映像版本 2.0 或更低版本,请点击管理安全性(可选)面板,然后在项目访问权限下选择
Enables the cloud-platform scope for this cluster。创建使用 Managed Service for Apache Spark 映像版本 2.1 或更高版本的集群时,cloud-platform范围默认处于启用状态。
- 设置集群面板已处于选中状态。
点击创建以创建集群。
gcloud
如需使用 gcloud CLI 创建 Managed Service for Apache Spark Flink 集群,请在本地终端窗口或 Cloud Shell 中运行以下 gcloud dataproc clusters create 命令:
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --image-version=DATAPROC_IMAGE_VERSION \ --optional-components=FLINK \ --enable-component-gateway \ --properties=PROPERTIES ... other flags
注意:
- CLUSTER_NAME:指定集群的名称。
- REGION:指定集群所在的 Compute Engine 区域。
DATAPROC_IMAGE_VERSION:酌情指定要在集群中使用的映像版本。集群映像版本决定了安装在集群上的 Flink 组件版本。
映像版本必须为 1.5 或更高版本,才能在集群上激活 Flink 组件(如需查看每个 Managed Service for Apache Spark 映像版本中包含的组件版本列表,请参阅支持的 Managed Service for Apache Spark 版本)。
如需通过 Dataproc Jobs API 运行 Flink 作业,映像版本必须为 [TBD] 或更高版本(请参阅运行 Managed Service for Apache Spark Flink 作业)。
--optional-components:必须指定FLINK组件,才能在集群上运行 Flink 作业和 Flink HistoryServer Web 服务。--enable-component-gateway:必须启用组件网关,才能激活组件网关与 Flink History Server 界面的链接。启用组件网关后,您还可以访问在 Flink 集群上运行的 Flink Job Manager 网页界面。PROPERTIES。(可选)指定一个或多个集群属性。
使用映像版本
2.0.67+ 和2.1.15+ 创建 Managed Service for Apache Spark 集群时,您可以使用--properties标志在/etc/flink/conf/flink-conf.yaml中配置 Flink 属性,这些属性将作为您在集群上运行的 Flink 应用的默认值。您可以设置
flink:historyserver.archive.fs.dir以指定用于写入 Flink 作业历史记录文件的 Cloud Storage 位置(此位置将由在 Flink 集群上运行的 Flink History Server 使用)。多属性示例:
--properties=flink:historyserver.archive.fs.dir=gs://my-bucket/my-flink-cluster/completed-jobs,flink:taskmanager.numberOfTaskSlots=2其他标志:
- 您可以添加可选的
--metadata flink-start-yarn-session=true标志,以便在集群主节点的后台运行 Flink YARN 守护程序 (/usr/bin/flink-yarn-daemon),以启动 Flink YARN 会话(请参阅 Flink 会话模式)。
- 您可以添加可选的
使用 2.0 或更低版本的映像时,您可以添加
--scopes=https://www.googleapis.com/auth/cloud-platform标志,以允许集群访问 Google Cloud API(请参阅范围最佳实践)。创建使用 Managed Service for Apache Spark 映像版本 2.1 或更高版本的集群时,cloud-platform范围默认处于启用状态。
API
如需使用 Managed Service for Apache Spark API 创建 Managed Service for Apache Spark Flink 集群,请提交 clusters.create 请求,如下所示:
注意:
将 SoftwareConfig.Component 设置为
FLINK。您可以酌情设置
SoftwareConfig.imageVersion以指定要在集群中使用的映像版本。集群映像版本决定了安装在集群上的 Flink 组件版本。映像版本必须为 1.5 或更高版本,才能在集群上激活 Flink 组件(如需查看每个 Managed Service for Apache Spark 映像版本中包含的组件版本列表,请参阅支持的 Managed Service for Apache Spark 版本)。
如需通过 Dataproc Jobs API 运行 Flink 作业,映像版本必须为 [TBD] 或更高版本(请参阅运行 Managed Service for Apache Spark Flink 作业)。
将 EndpointConfig.enableHttpPortAccess 设置为
true,以启用组件网关与 Flink History Server 界面的链接。启用组件网关后,您还可以访问在 Flink 集群上运行的 Flink Job Manager 网页界面。您可以选择设置
SoftwareConfig.properties,以指定一个或多个集群属性。- 您可以指定 Flink 属性,这些属性将作为您在集群上运行的 Flink 应用的默认值。例如,您可以设置
flink:historyserver.archive.fs.dir以指定用于写入 Flink 作业历史记录文件的 Cloud Storage 位置(此位置将由在 Flink 集群上运行的 Flink History Server 使用)。
- 您可以指定 Flink 属性,这些属性将作为您在集群上运行的 Flink 应用的默认值。例如,您可以设置
您可以酌情:
- 例如,设置
GceClusterConfig.metadata,以在集群主节点的后台运行 Flink YARN 守护程序 (/usr/bin/flink-yarn-daemon) 来启动 Flink YARN 会话,请指定flink-start-yarn-sessiontrue(请参阅 Flink 会话模式)。 - 在使用 2.0 或更低版本的 Dataproc 镜像时,将 GceClusterConfig.serviceAccountScopes 设置为
https://www.googleapis.com/auth/cloud-platform(即cloud-platform范围),以使您的集群能够访问 Google CloudAPI(请参阅范围最佳实践)。创建使用 Managed Service for Apache Spark 映像版本 2.1 或更高版本的集群时,cloud-platform范围默认处于启用状态。
- 例如,设置
创建 Flink 集群后
- 使用组件网关中的
Flink History Server链接查看在 Flink 集群上运行的 Flink History Server。 - 使用组件网关中的
YARN ResourceManager link查看在 Flink 集群上运行的 Flink Job Manager 网页界面。 - 创建 Managed Service for Apache Spark Persistent History Server,以查看由现有和已删除的 Flink 集群写入的 Flink 作业历史记录文件。
使用 Managed Service for Apache Spark Jobs 资源运行 Flink 作业
您可以使用 Managed Service for Apache Spark Jobs 资源,通过Google Cloud 控制台、Google Cloud CLI 或 Managed Service for Apache Spark API 运行 Flink 作业。
控制台
如需从控制台提交示例 Flink WordCount 作业,请执行以下操作:
在浏览器中通过Google Cloud 控制台打开 Managed Service for Apache Spark 提交作业页面。
填写提交作业页面上的字段:
- 从集群列表中选择集群名称。
- 将作业类型设置为
Flink。 - 将主类或 jar 设置为
org.apache.flink.examples.java.wordcount.WordCount。 - 将 jar 文件设置为
file:///usr/lib/flink/examples/batch/WordCount.jar。file:///表示位于集群中的文件。Managed Service for Apache Spark 在创建 Flink 集群时安装了WordCount.jar。- 此字段还接受 Cloud Storage 路径 (
gs://BUCKET/JARFILE) 或 Hadoop 分布式文件系统 (HDFS) 路径 (hdfs://PATH_TO_JAR)。
点击提交。
- 作业驱动程序输出显示在作业详情页面上。
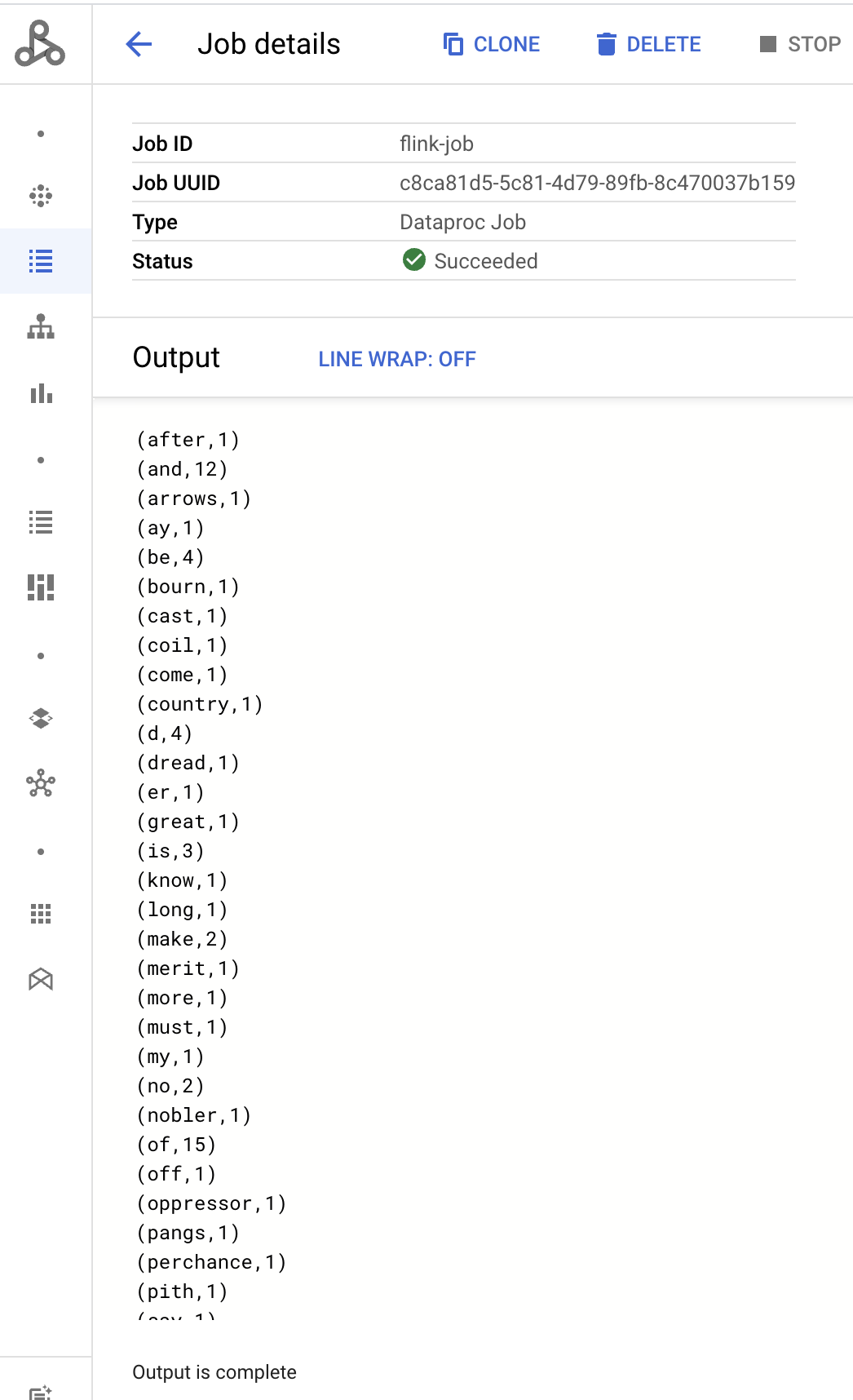
- Flink 作业列在 Google Cloud 控制台中的 Managed Service for Apache Spark 作业页面上。
- 在作业或作业详情页面中,点击停止或删除即可停止或删除作业。
gcloud
如需将 Flink 作业提交到 Managed Service for Apache Spark Flink 集群,请在本地终端窗口或 Cloud Shell 中运行 gcloud CLI gcloud dataproc jobs submit 命令。
gcloud dataproc jobs submit flink \ --cluster=CLUSTER_NAME \ --region=REGION \ --class=MAIN_CLASS \ --jar=JAR_FILE \ -- JOB_ARGS
注意:
- CLUSTER_NAME:指定要将作业提交到的 Managed Service for Apache Spark Flink 集群的名称。
- REGION:指定集群所在的 Compute Engine 区域。
- MAIN_CLASS:指定 Flink 应用的
main类,例如:org.apache.flink.examples.java.wordcount.WordCount
- JAR_FILE:指定 Flink 应用 jar 文件。您可以指定:
- 在集群上安装的 jar 文件,使用
file:///` 前缀:file:///usr/lib/flink/examples/streaming/TopSpeedWindowing.jarfile:///usr/lib/flink/examples/batch/WordCount.jar
- Cloud Storage 中的 jar 文件:
gs://BUCKET/JARFILE - HDFS 中的 jar 文件:
hdfs://PATH_TO_JAR
- 在集群上安装的 jar 文件,使用
JOB_ARGS:酌情在双短划线 (
--) 后添加作业参数。提交作业后,作业驱动程序输出会显示在本地或 Cloud Shell 终端中。
Program execution finished Job with JobID 829d48df4ebef2817f4000dfba126e0f has finished. Job Runtime: 13610 ms ... (after,1) (and,12) (arrows,1) (ay,1) (be,4) (bourn,1) (cast,1) (coil,1) (come,1)
REST
本部分介绍如何使用 Managed Service for Apache Spark jobs.submit API 将 Flink 作业提交到 Managed Service for Apache Spark Flink 集群。
在使用任何请求数据之前,请先进行以下替换:
- PROJECT_ID: Google Cloud 项目 ID
- REGION:集群地区
- CLUSTER_NAME:指定要将作业提交到的 Managed Service for Apache Spark Flink 集群的名称
HTTP 方法和网址:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/jobs:submit
请求 JSON 正文:
{
"job": {
"placement": {
"clusterName": "CLUSTER_NAME"
},
"flinkJob": {
"mainClass": "org.apache.flink.examples.java.wordcount.WordCount",
"jarFileUris": [
"file:///usr/lib/flink/examples/batch/WordCount.jar"
]
}
}
}
如需发送您的请求,请展开以下选项之一:
您应该收到类似以下内容的 JSON 响应:
{
"reference": {
"projectId": "PROJECT_ID",
"jobId": "JOB_ID"
},
"placement": {
"clusterName": "CLUSTER_NAME",
"clusterUuid": "CLUSTER_UUID"
},
"flinkJob": {
"mainClass": "org.apache.flink.examples.java.wordcount.WordCount",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/flink/examples/batch/WordCount.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "2020-10-07T20:16:21.759Z"
},
"jobUuid": "JOB_UUID"
}
- Flink 作业列在 Google Cloud 控制台中的 Managed Service for Apache Spark 作业页面上。
- 您可以在 Google Cloud 控制台的作业或作业详细信息页面中,点击停止或删除以停止或删除作业。
使用 flink CLI 运行 Flink 作业
您可以使用 flink CLI 在 Flink 集群的主节点上运行 Flink 作业,而不是使用 Managed Service for Apache Spark Jobs 资源运行 Flink 作业。
以下部分介绍了在 Managed Service for Apache Spark Flink 集群上运行 flink CLI 作业的不同方法。
通过 SSH 连接到主节点:使用 SSH 实用程序在集群主虚拟机上打开终端窗口。
设置类路径:从 Flink 集群主虚拟机的 SSH 终端窗口中初始化 Hadoop 类路径:
export HADOOP_CLASSPATH=$(hadoop classpath)运行 Flink 作业:您可以在 YARN 上以不同的部署模式运行 Flink 作业,包括应用模式、单作业模式和会话模式。
应用模式:Managed Service for Apache Spark 映像版本 2.0 及更高版本支持 Flink 应用模式。此模式将在 YARN 作业管理器上执行作业的
main()方法。集群在作业完成后关闭。作业提交示例:
flink run-application \ -t yarn-application \ -Djobmanager.memory.process.size=1024m \ -Dtaskmanager.memory.process.size=2048m \ -Djobmanager.heap.mb=820 \ -Dtaskmanager.heap.mb=1640 \ -Dtaskmanager.numberOfTaskSlots=2 \ -Dparallelism.default=4 \ /usr/lib/flink/examples/batch/WordCount.jar列出正在运行的作业:
./bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY取消正在运行的作业:
./bin/flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>单作业模式:此 Flink 模式会在客户端执行作业的
main()方法。作业提交示例:
flink run \ -m yarn-cluster \ -p 4 \ -ys 2 \ -yjm 1024m \ -ytm 2048m \ /usr/lib/flink/examples/batch/WordCount.jar会话模式:启动长时间运行的 Flink YARN 会话,然后向该会话提交一个或多个作业。
启动会话:您可以通过以下任一方式启动 Flink 会话:
创建 Flink 集群,并向
gcloud dataproc clusters create命令添加--metadata flink-start-yarn-session=true标志(请参阅创建 Dataproc Flink 集群)。启用此标志的情况下,在创建集群后,Managed Service for Apache Spark 会运行/usr/bin/flink-yarn-daemon以在集群上启动 Flink 会话。会话的 YARN 应用 ID 会保存在
/tmp/.yarn-properties-${USER}中。您可以使用yarn application -list命令列出该 ID。使用自定义设置运行预安装在集群主虚拟机上的 Flink
yarn-session.sh脚本:自定义设置示例:
/usr/lib/flink/bin/yarn-session.sh \ -s 1 \ -jm 1024m \ -tm 2048m \ -nm flink-dataproc \ --detached使用默认设置运行 Flink
/usr/bin/flink-yarn-daemon封装容器脚本:. /usr/bin/flink-yarn-daemon
将作业提交到会话:运行以下命令,将 Flink 作业提交到会话。
flink run -m <var>FLINK_MASTER_URL</var>/usr/lib/flink/examples/batch/WordCount.jar- FLINK_MASTER_URL:执行作业的 Flink 主虚拟机的网址(包括主机和名端口)。从网址中移除
http:// prefix。当您启动 Flink 会话时,此网址会列在命令输出中。您可以运行以下命令,在Tracking-URL字段中列出此网址:
yarn application -list -appId=<yarn-app-id> | sed 's#http://##' ```- FLINK_MASTER_URL:执行作业的 Flink 主虚拟机的网址(包括主机和名端口)。从网址中移除
列出会话中的作业:如需列出会话中的 Flink 作业,请执行以下任一操作:
不带参数运行
flink list。该命令会在/tmp/.yarn-properties-${USER}中查找会话的 YARN 应用 ID。从
/tmp/.yarn-properties-${USER}中或yarn application -list的输出中获取会话的 YARN 应用 ID,然后运行<code>flink list -yid YARN_APPLICATION_ID。运行
flink list -m FLINK_MASTER_URL。
停止会话:如需停止会话,请从
/tmp/.yarn-properties-${USER}中或yarn application -list的输出中获取会话的 YARN 应用 ID,然后运行以下任一命令:echo "stop" | /usr/lib/flink/bin/yarn-session.sh -id YARN_APPLICATION_IDyarn application -kill YARN_APPLICATION_ID
在 Flink 上运行 Apache Beam 作业
您可以使用 FlinkRunner 在 Managed Service for Apache Spark 上运行 Apache Beam 作业。
您可以通过以下方式在 Flink 上运行 Beam 作业:
- Java Beam 作业
- 可移植的 Beam 作业
Java Beam 作业
将 Beam 作业打包成一个 JAR 文件。为捆绑的 JAR 文件提供运行作业所需的依赖项。
以下示例从 Managed Service for Apache Spark 集群的主节点运行 Java Beam 作业。
创建启用了 Flink 组件的 Managed Service for Apache Spark 集群。
gcloud dataproc clusters create CLUSTER_NAME \ --optional-components=FLINK \ --image-version=DATAPROC_IMAGE_VERSION \ --region=REGION \ --enable-component-gateway \ --scopes=https://www.googleapis.com/auth/cloud-platform--optional-components:Flink。--image-version:集群的映像版本,用于确定集群上安装的 Flink 版本(例如,请参阅针对最近 4 个 2.0.x 映像发布版本列出的 Apache Flink 组件版本)。--region:受支持的 Managed Service for Apache Spark 区域。--enable-component-gateway:启用对 Flink Job Manager 界面的访问权限。--scopes:允许集群访问 Google Cloud API(请参阅范围最佳实践)。当您创建使用 Managed Service for Apache Spark 映像版本 2.1 或更高版本的集群时,cloud-platform范围是默认启用的(您无需添加此标志设置)。
使用 SSH 实用程序在 Flink 集群主节点上打开终端窗口。
在 Managed Service for Apache Spark 集群主服务器上启动 Flink YARN 会话。
. /usr/bin/flink-yarn-daemon记下 Managed Service for Apache Spark 集群上的 Flink 版本。
flink --version在本地机器上,使用 Java 生成规范的 Beam 字数统计示例。
选择与 Managed Service for Apache Spark 集群上的 Flink 版本兼容的 Beam 版本。请参阅 Flink 版本兼容性表,了解 Beam 与 Flink 版本之间的兼容性。
打开生成的 POM 文件。检查
<flink.artifact.name>标记指定的 Beam Flink 运行程序版本。如果 Flink 工件名称中的 Beam Flink 运行程序版本与您的集群上的 Flink 版本不匹配,请更新版本号以使其相匹配。mvn archetype:generate \ -DarchetypeGroupId=org.apache.beam \ -DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \ -DarchetypeVersion=BEAM_VERSION \ -DgroupId=org.example \ -DartifactId=word-count-beam \ -Dversion="0.1" \ -Dpackage=org.apache.beam.examples \ -DinteractiveMode=false打包字数统计示例。
mvn package -Pflink-runner将打包的超级 JAR 文件
word-count-beam-bundled-0.1.jar(约 135 MB)上传到您的 Managed Service for Apache Spark 集群的主节点。您可以使用gcloud storage cp加快从 Cloud Storage 向 Managed Service for Apache Spark 集群传输文件的速度。在本地终端上,创建一个 Cloud Storage 存储桶,然后上传超级 JAR。
gcloud storage buckets create BUCKET_NAMEgcloud storage cp target/word-count-beam-bundled-0.1.jar gs://BUCKET_NAME/在 Managed Service for Apache Spark 的主节点上,下载超级 JAR。
gcloud storage cp gs://BUCKET_NAME/word-count-beam-bundled-0.1.jar .
在 Managed Service for Apache Spark 集群的主节点上运行 Java Beam 作业。
flink run -c org.apache.beam.examples.WordCount word-count-beam-bundled-0.1.jar \ --runner=FlinkRunner \ --output=gs://BUCKET_NAME/java-wordcount-out检查结果是否已写入 Cloud Storage 存储桶。
gcloud storage cat gs://BUCKET_NAME/java-wordcount-out-SHARD_ID停止 Flink YARN 会话。
yarn application -listyarn application -kill YARN_APPLICATION_ID
可移植的 Beam 作业
如需运行以 Python、Go 及其他支持语言编写的 Beam 作业,您可以按照 Beam 的 Flink 运行程序页面中的说明使用 FlinkRunner 和 PortableRunner(另请参阅可移植性框架路线图)。
以下示例从 Managed Service for Apache Spark 集群的主节点运行以 Python 编写的可移植 Beam 作业。
创建同时启用了 Flink 和 Docker 组件的 Managed Service for Apache Spark 集群。
gcloud dataproc clusters create CLUSTER_NAME \ --optional-components=FLINK,DOCKER \ --image-version=DATAPROC_IMAGE_VERSION \ --region=REGION \ --enable-component-gateway \ --scopes=https://www.googleapis.com/auth/cloud-platform注意:
--optional-components:Flink 和 Docker。--image-version:集群的映像版本,用于确定集群上安装的 Flink 版本(例如,请参阅最近四个 2.0.x 映像发布版本中列出的 Apache Flink 组件版本)。--region:可用的 Managed Service for Apache Spark 区域。--enable-component-gateway:启用对 Flink Job Manager 界面的访问权限。--scopes:允许集群访问 Google Cloud API(请参阅范围最佳实践)。当您创建使用 Managed Service for Apache Spark 映像版本 2.1 或更高版本的集群时,cloud-platform范围是默认启用的(您无需添加此标志设置)。
在本地或 Cloud Shell 中使用 gcloud CLI 创建 Cloud Storage 存储桶。在运行示例 WordCount 程序时,您将指定 BUCKET_NAME。
gcloud storage buckets create BUCKET_NAME在集群虚拟机上的终端窗口中,启动 Flink YARN 会话。记下 Flink 主节点网址,即执行作业的 Flink 主节点的地址。在运行示例 WordCount 程序时,您将指定 FLINK_MASTER_URL。
. /usr/bin/flink-yarn-daemon显示并记下 Managed Service for Apache Spark 集群上运行的 Flink 版本。在运行示例 WordCount 程序时,您将指定 FLINK_VERSION。
flink --version在集群主节点上安装作业所需的 Python 库。
安装与集群上 Flink 版本兼容的 Beam 版本。
python -m pip install apache-beam[gcp]==BEAM_VERSION在集群主节点上运行 WordCount 示例。
python -m apache_beam.examples.wordcount \ --runner=FlinkRunner \ --flink_version=FLINK_VERSION \ --flink_master=FLINK_MASTER_URL --flink_submit_uber_jar \ --output=gs://BUCKET_NAME/python-wordcount-out注意:
--runner:FlinkRunner。--flink_version:FLINK_VERSION(前文已记录)。--flink_master:FLINK_MASTER_URL(前文已记录)。--flink_submit_uber_jar:使用 Uber JAR 来执行 Beam 作业。--output:BUCKET_NAME(之前创建)。
验证结果是否已写入您的存储桶。
gcloud storage cat gs://BUCKET_NAME/python-wordcount-out-SHARD_ID停止 Flink YARN 会话。
- 获取应用 ID。
yarn application -list1. Insert the <var>YARN_APPLICATION_ID</var>, then stop the session.yarn application -kill
在启用 Kerberos 认证的集群上运行 Flink
Managed Service for Apache Spark Flink 组件支持 Kerberos 化的集群。如需提交并保留 Flink 作业或启动 Flink 集群,需要有效的 Kerberos 票据。默认情况下,Kerberos 票据的有效期为 7 天。
访问 Flink Job Manager 界面
当 Flink 作业或 Flink 会话集群运行时,您可以使用 Flink Job Manager 网页界面。如需使用网页界面,请执行以下操作:
- 创建 Managed Service for Apache Spark Flink 集群。
- 创建集群后,在 Google Cloud 控制台的集群详细信息页面,点击“网页界面”标签页中的组件网关下的 YARN ResourceManager 链接。
- 在 YARN Resource Manager 界面中,识别 Flink 集群应用条目。根据作业的完成状态,系统将列出 ApplicationMaster 或历史记录链接。
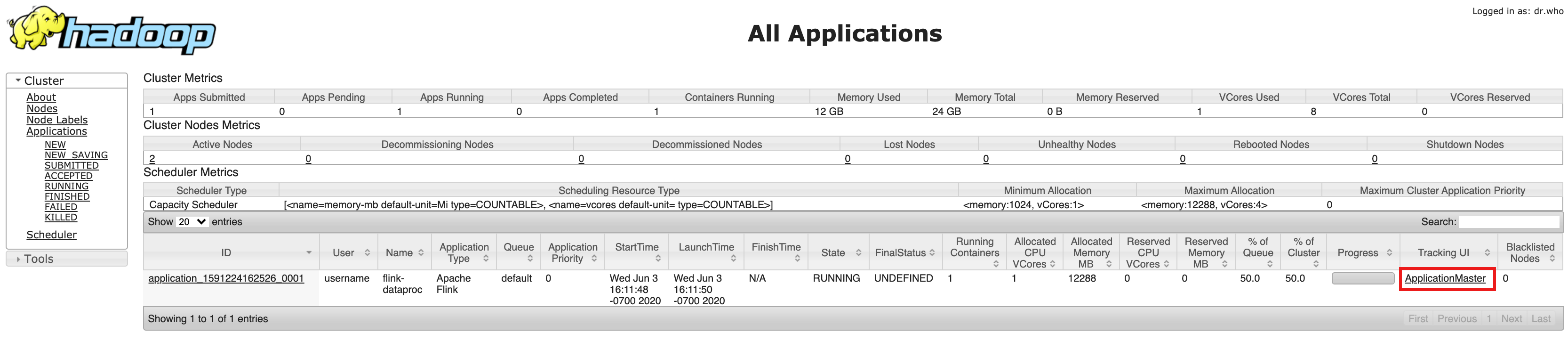
- 对于长时间运行的流式传输作业,请点击 ApplicationManager 链接以打开 Flink 信息中心;对于已完成的作业,请点击历史记录链接以查看作业详情。
