
使用選用元件功能建立 Managed Service for Apache Spark 叢集時,可以啟用 Flink 等其他元件。本頁說明如何建立 Managed Service for Apache Spark 叢集,並啟用 Apache Flink 選用元件 (Flink 叢集),然後在叢集上執行 Flink 工作。
Flink 叢集可用於:
使用 Managed Service for Apache Spark
Jobs資源執行 Flink 工作:透過 Google Cloud 控制台、Google Cloud CLI 或 Managed Service for Apache Spark API 執行。
建立 Managed Service for Apache Spark Flink 叢集
您可以使用 Google Cloud 控制台、Google Cloud CLI 或 Managed Service for Apache Spark API,建立已在叢集上啟用 Flink 元件的 Managed Service for Apache Spark 叢集。
建議:使用標準的 1 個主要 VM 叢集,並搭配 Flink 元件。 Managed Service for Apache Spark 高可用性模式叢集 (含 3 個主要 VM) 不支援 Flink 高可用性模式。
控制台
如要使用 Google Cloud 控制台建立 Managed Service for Apache Spark Flink 叢集,請執行下列步驟:
開啟 Managed Service for Apache Spark 的「Create a Managed Service for Apache Spark cluster on Compute Engine」(在 Compute Engine 上建立 Managed Service for Apache Spark 叢集) 頁面。
- 系統會選取「設定叢集」面板。
- 在「Versioning」(版本管理)部分中,確認或變更「映像檔類型和版本」。叢集映像檔版本決定叢集上安裝的 Flink 元件版本。
- 映像檔版本必須為 1.5 以上,才能在叢集上啟用 Flink 元件 (請參閱「支援的 Managed Service for Apache Spark 版本」,查看每個 Managed Service for Apache Spark 映像檔版本中包含的元件版本清單)。
- 如要透過 Managed Service for Apache Spark Jobs API 執行 Flink 工作,映像檔版本必須為 [TBD] 以上 (請參閱「執行 Managed Service for Apache Spark Flink 工作」)。
- 在「元件」部分:
- 在「元件閘道」下方,選取「啟用元件閘道」。您必須啟用元件閘道,才能啟動 Flink 記錄伺服器 UI 的元件閘道連結。啟用元件閘道後,您也可以存取在 Flink 叢集上執行的 Flink Job Manager 網頁介面。
- 在「選用元件」下方,選取要在叢集上啟用的「Flink」和其他選用元件。
- 在「Versioning」(版本管理)部分中,確認或變更「映像檔類型和版本」。叢集映像檔版本決定叢集上安裝的 Flink 元件版本。
按一下「Customize cluster (optional)」(自訂叢集 (選用)) 面板。
在「叢集屬性」部分中,按一下每個要新增至叢集的選用叢集屬性的「新增屬性」。您可以新增
flink前置字元的屬性,在/etc/flink/conf/flink-conf.yaml中設定 Flink 屬性,做為您在叢集上執行的 Flink 應用程式預設值。範例:
- 設定
flink:historyserver.archive.fs.dir,指定要寫入 Flink 工作記錄檔案的 Cloud Storage 位置 (Flink 叢集上執行的 Flink 記錄伺服器會使用這個位置)。 - 使用
flink:taskmanager.numberOfTaskSlots=n設定 Flink 工作插槽。
- 設定
在「Custom cluster metadata」(自訂叢集中繼資料) 專區中,按一下「Add Metadata」(新增中繼資料),即可新增選用中繼資料。舉例來說,新增
flink-start-yarn-sessiontrue可在叢集主節點的背景中執行 Flink YARN Daemon (/usr/bin/flink-yarn-daemon),以啟動 Flink YARN 工作階段 (請參閱「Flink 工作階段模式」)。
如果您使用 Managed Service for Apache Spark 映像檔 2.0 版或更早版本,請按一下「管理安全性 (選用)」面板,然後在「專案存取權」下方選取
Enables the cloud-platform scope for this cluster。建立使用 Managed Service for Apache Spark 映像檔 2.1 以上版本的叢集時,系統預設會啟用cloud-platform範圍。
- 系統會選取「設定叢集」面板。
點選「建立」來建立叢集。
gcloud
如要使用 gcloud CLI 建立 Managed Service for Apache Spark Flink 叢集,請在本機的終端機視窗或 Cloud Shell 中執行下列 gcloud dataproc clusters create 指令:
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --image-version=DATAPROC_IMAGE_VERSION \ --optional-components=FLINK \ --enable-component-gateway \ --properties=PROPERTIES ... other flags
注意:
- CLUSTER_NAME:指定叢集名稱。
- REGION:指定叢集所在的 Compute Engine 區域。
DATAPROC_IMAGE_VERSION:視需要指定要在叢集上使用的映像檔版本。叢集映像檔版本決定了叢集上安裝的 Flink 元件版本。
映像檔版本必須為 1.5 以上,才能在叢集上啟用 Flink 元件 (請參閱「支援的 Managed Service for Apache Spark 版本」,查看每個 Managed Service for Apache Spark 映像檔版本中包含的元件版本清單)。
如要透過 Dataproc Jobs API 執行 Flink 工作,映像檔版本必須為 [TBD] 以上 (請參閱「執行 Managed Service for Apache Spark Flink 工作」)。
--optional-components:您必須指定FLINK元件,才能在叢集上執行 Flink 工作和 Flink HistoryServer Web Service。--enable-component-gateway:您必須啟用元件閘道,才能啟動 Flink 歷記錄伺服器 UI 的元件閘道連結。啟用元件閘道後,您也可以存取在 Flink 叢集上執行的 Flink Job Manager 網頁介面。PROPERTIES。視需要指定一或多個叢集屬性。
使用映像檔版本
2.0.67+ 和2.1.15+ 建立 Managed Service for Apache Spark 叢集時,您可以使用--properties標記,在/etc/flink/conf/flink-conf.yaml中設定 Flink 屬性,做為叢集上執行的 Flink 應用程式預設值。您可以設定
flink:historyserver.archive.fs.dir,指定要將 Flink 工作記錄檔寫入哪個 Cloud Storage 位置 (Flink 叢集上執行的 Flink 記錄伺服器會使用這個位置)。多個屬性的範例:
--properties=flink:historyserver.archive.fs.dir=gs://my-bucket/my-flink-cluster/completed-jobs,flink:taskmanager.numberOfTaskSlots=2其他旗標:
- 您可以新增選用的
--metadata flink-start-yarn-session=true旗標,在叢集主節點的背景中執行 Flink YARN Daemon (/usr/bin/flink-yarn-daemon),啟動 Flink YARN 工作階段 (請參閱「Flink 工作階段模式」)。
- 您可以新增選用的
使用 2.0 以下的映像檔版本時,您可以新增
--scopes=https://www.googleapis.com/auth/cloud-platform旗標,啟用叢集對 Google Cloud API 的存取權 (請參閱範圍最佳做法)。建立使用 Managed Service for Apache Spark 映像檔 2.1 以上版本的叢集時,系統預設會啟用cloud-platform範圍。
API
如要使用 Managed Service for Apache Spark API 建立 Managed Service for Apache Spark Flink 叢集,請提交 clusters.create 要求,如下所示:
注意:
將 SoftwareConfig.Component 設為
FLINK。您可以視需要設定
SoftwareConfig.imageVersion,指定要在叢集上使用的映像檔版本。叢集映像檔版本決定了叢集上安裝的 Flink 元件版本。映像檔版本必須為 1.5 以上,才能在叢集上啟用 Flink 元件 (請參閱「支援的 Managed Service for Apache Spark 版本」,查看每個 Managed Service for Apache Spark 映像檔版本中包含的元件版本清單)。
如要透過 Dataproc Jobs API 執行 Flink 工作,映像檔版本必須為 [TBD] 以上 (請參閱「執行 Managed Service for Apache Spark Flink 工作」)。
將 EndpointConfig.enableHttpPortAccess 設為
true,啟用元件閘道連結至 Flink 記錄伺服器 UI。啟用元件閘道後,您也可以存取在 Flink 叢集上執行的 Flink Job Manager 網頁介面。您可以選擇設定
SoftwareConfig.properties,指定一或多個叢集屬性。- 您可以指定 Flink 屬性,做為在叢集上執行的 Flink 應用程式預設值。舉例來說,您可以設定
flink:historyserver.archive.fs.dir,指定要寫入 Flink 工作記錄檔案的 Cloud Storage 位置 (Flink 叢集上執行的 Flink 記錄伺服器會使用這個位置)。
- 您可以指定 Flink 屬性,做為在叢集上執行的 Flink 應用程式預設值。舉例來說,您可以設定
您可以選擇設定下列項目:
GceClusterConfig.metadata。舉例來說,如要指定flink-start-yarn-sessiontrue在叢集主節點的背景執行 Flink YARN Daemon (/usr/bin/flink-yarn-daemon),以啟動 Flink YARN 工作階段 (請參閱「Flink 工作階段模式」)。- 使用 2.0 以下的映像檔版本時,請將 GceClusterConfig.serviceAccountScopes 設為
https://www.googleapis.com/auth/cloud-platform(cloud-platform範圍),讓叢集能夠存取 Google CloudAPI (請參閱範圍最佳做法)。建立使用 Managed Service for Apache Spark 映像檔 2.1 以上版本的叢集時,系統預設會啟用cloud-platform範圍。
建立 Flink 叢集後
- 使用「Component Gateway」(元件閘道) 中的
Flink History Server連結,查看在 Flink 叢集上執行的 Flink 記錄伺服器。 - 使用元件閘道中的
YARN ResourceManager link,查看在 Flink 叢集上執行的 Flink Job Manager 網頁介面。 - 建立 Managed Service for Apache Spark 永久記錄伺服器,即可查看現有和已刪除 Flink 叢集寫入的 Flink 工作記錄檔。
使用 Managed Service for Apache Spark Jobs 資源執行 Flink 工作
您可以使用 Managed Service for Apache Spark Jobs 資源,透過Google Cloud 控制台、Google Cloud CLI 或 Managed Service for Apache Spark API 執行 Flink 工作。
控制台
如要從主控台提交範例 Flink 字數統計工作,請按照下列步驟操作:
在瀏覽器中開啟Google Cloud 控制台,然後前往 Managed Service for Apache Spark「Submit a job」(提交工作) 頁面。
填寫「Submit a job」(提交工作) 頁面中的欄位:
- 從叢集清單選取您的「Cluster」(叢集) 名稱。
- 將「Job type」(工作類型) 設為
Flink。 - 將「Main class or jar」(主要類別或 jar) 設為
org.apache.flink.examples.java.wordcount.WordCount。 - 將「Jar files」(Jar 檔案) 設為
file:///usr/lib/flink/examples/batch/WordCount.jar。file:///表示位於叢集中的檔案。Managed Service for Apache Spark 在建立 Flink 叢集時,已安裝WordCount.jar。- 這個欄位也接受 Cloud Storage 路徑 (
gs://BUCKET/JARFILE) 或 Hadoop 分散式檔案系統 (HDFS) 路徑 (hdfs://PATH_TO_JAR)。
按一下「提交」。
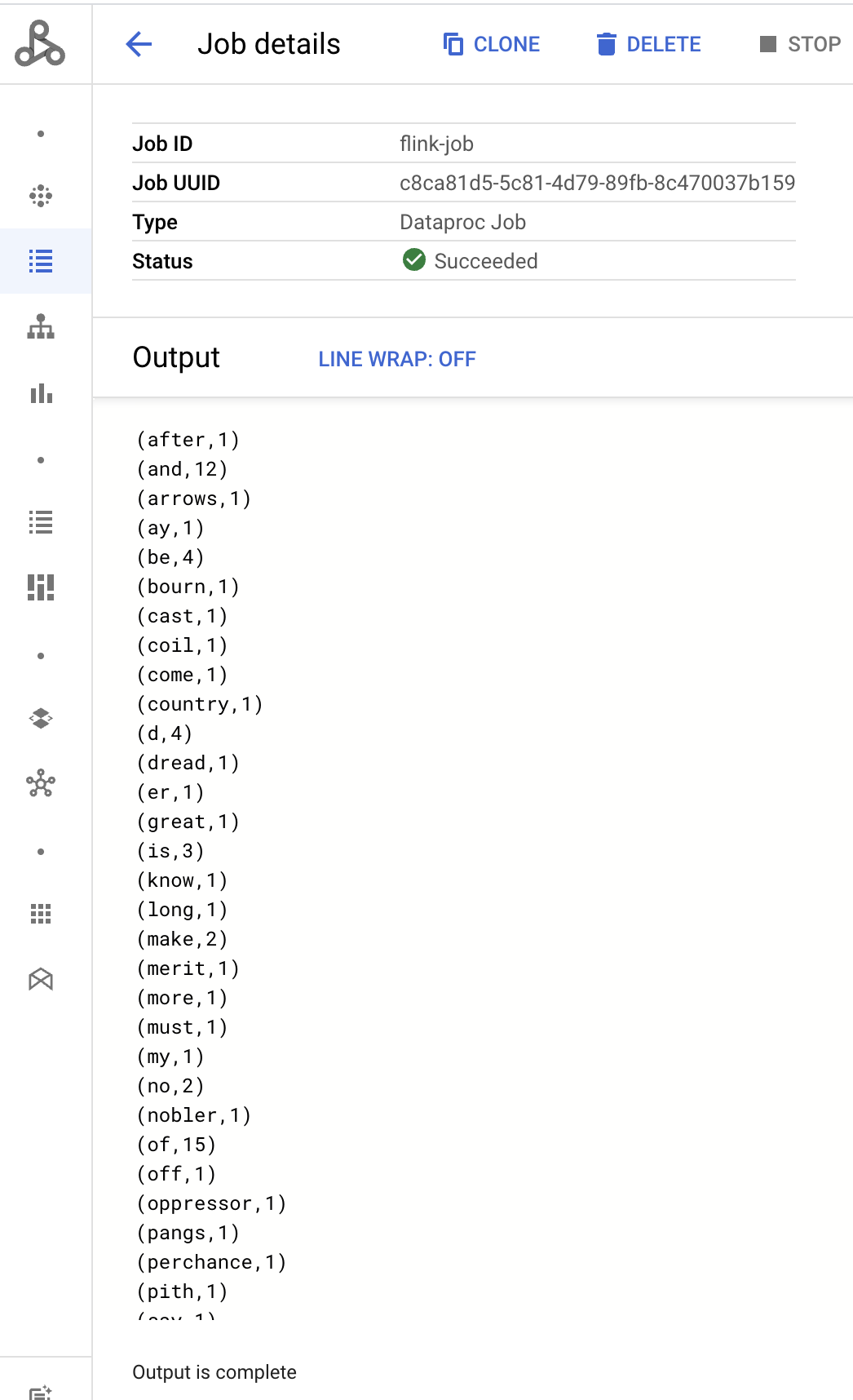
- 「Job details」(工作詳細資料) 頁面會顯示工作驅動程式輸出內容。
gcloud
如要將 Flink 工作提交至 Managed Service for Apache Spark Flink 叢集,請在本機的終端機視窗或 Cloud Shell 中執行 gcloud CLI gcloud dataproc jobs submit 指令。
gcloud dataproc jobs submit flink \ --cluster=CLUSTER_NAME \ --region=REGION \ --class=MAIN_CLASS \ --jar=JAR_FILE \ -- JOB_ARGS
注意:
- CLUSTER_NAME:指定要將工作提交至的 Managed Service for Apache Spark Flink 叢集名稱。
- REGION:指定叢集所在的 Compute Engine 區域。
- MAIN_CLASS:指定 Flink 應用程式的
main類別,例如:org.apache.flink.examples.java.wordcount.WordCount
- JAR_FILE:指定 Flink 應用程式 JAR 檔案。您可以指定:
- 安裝在叢集上的 jar 檔案,使用
file:///` prefix:file:///usr/lib/flink/examples/streaming/TopSpeedWindowing.jarfile:///usr/lib/flink/examples/batch/WordCount.jar
- Cloud Storage 中的 JAR 檔案:
gs://BUCKET/JARFILE - HDFS 中的 jar 檔案:
hdfs://PATH_TO_JAR
- 安裝在叢集上的 jar 檔案,使用
JOB_ARGS:(選用) 在雙連字號 (
--) 後方新增工作引數。提交工作後,工作驅動程式輸出會顯示在本機或 Cloud Shell 終端機中。
Program execution finished Job with JobID 829d48df4ebef2817f4000dfba126e0f has finished. Job Runtime: 13610 ms ... (after,1) (and,12) (arrows,1) (ay,1) (be,4) (bourn,1) (cast,1) (coil,1) (come,1)
REST
本節說明如何使用 Managed Service for Apache Spark jobs.submit API,將 Flink 工作提交至 Managed Service for Apache Spark Flink 叢集。
使用任何要求資料之前,請先修改下列項目的值:
- PROJECT_ID: Google Cloud 專案 ID
- REGION:叢集區域
- CLUSTER_NAME:指定要將工作提交至的 Managed Service for Apache Spark Flink 叢集名稱
HTTP 方法和網址:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/jobs:submit
JSON 要求主體:
{
"job": {
"placement": {
"clusterName": "CLUSTER_NAME"
},
"flinkJob": {
"mainClass": "org.apache.flink.examples.java.wordcount.WordCount",
"jarFileUris": [
"file:///usr/lib/flink/examples/batch/WordCount.jar"
]
}
}
}
請展開以下其中一個選項,以傳送要求:
您應該會收到如下的 JSON 回覆:
{
"reference": {
"projectId": "PROJECT_ID",
"jobId": "JOB_ID"
},
"placement": {
"clusterName": "CLUSTER_NAME",
"clusterUuid": "CLUSTER_UUID"
},
"flinkJob": {
"mainClass": "org.apache.flink.examples.java.wordcount.WordCount",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/flink/examples/batch/WordCount.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "2020-10-07T20:16:21.759Z"
},
"jobUuid": "JOB_UUID"
}
使用 flink CLI 執行 Flink 工作
您可以使用 flink CLI,在 Flink 叢集的主節點上執行 Flink 工作,而不必使用 Managed Service for Apache Spark Jobs 資源執行 Flink 工作。
以下各節說明在 Managed Service for Apache Spark Flink 叢集上執行 flink CLI 工作的方式。
透過 SSH 連線至主節點:使用 SSH 公用程式,在叢集主 VM 上開啟終端機視窗。
設定類別路徑:從 Flink 叢集主 VM 的 SSH 終端機視窗初始化 Hadoop 類別路徑:
export HADOOP_CLASSPATH=$(hadoop classpath)執行 Flink 工作:您可以在 YARN 上以不同的部署模式執行 Flink 工作,包括應用程式、每個工作和工作階段模式。
應用程式模式:Managed Service for Apache Spark 映像檔 2.0 以上版本支援 Flink 應用程式模式。 這個模式會在 YARN Job Manager 上執行作業的
main()方法。工作完成後,叢集就會關機。工作提交範例:
flink run-application \ -t yarn-application \ -Djobmanager.memory.process.size=1024m \ -Dtaskmanager.memory.process.size=2048m \ -Djobmanager.heap.mb=820 \ -Dtaskmanager.heap.mb=1640 \ -Dtaskmanager.numberOfTaskSlots=2 \ -Dparallelism.default=4 \ /usr/lib/flink/examples/batch/WordCount.jar列出執行中的工作:
./bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY取消正在執行的工作:
./bin/flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>依工作模式:這個 Flink 模式會在用戶端執行工作的
main()方法。工作提交範例:
flink run \ -m yarn-cluster \ -p 4 \ -ys 2 \ -yjm 1024m \ -ytm 2048m \ /usr/lib/flink/examples/batch/WordCount.jar工作階段模式:啟動長時間執行的 Flink YARN 工作階段,然後將一或多項工作提交至該工作階段。
啟動工作階段:您可以透過下列任一方式啟動 Flink 工作階段:
建立 Flink 叢集,並將
--metadata flink-start-yarn-session=true標記新增至gcloud dataproc clusters create指令 (請參閱「建立 Dataproc Flink 叢集」)。啟用這個標記後,Managed Service for Apache Spark 會在叢集建立完成後執行/usr/bin/flink-yarn-daemon,在叢集上啟動 Flink 工作階段。工作階段的 YARN 應用程式 ID 會儲存在
/tmp/.yarn-properties-${USER}中。 您可以使用yarn application -list指令列出 ID。使用自訂設定執行 Flink
yarn-session.sh指令碼 (預先安裝在叢集主 VM 上):使用自訂設定的範例:
/usr/lib/flink/bin/yarn-session.sh \ -s 1 \ -jm 1024m \ -tm 2048m \ -nm flink-dataproc \ --detached使用預設設定執行 Flink
/usr/bin/flink-yarn-daemon包裝函式指令碼:. /usr/bin/flink-yarn-daemon
將作業提交至工作階段:執行下列指令,將 Flink 作業提交至工作階段。
flink run -m <var>FLINK_MASTER_URL</var>/usr/lib/flink/examples/batch/WordCount.jar- FLINK_MASTER_URL:Flink 主機 VM 的網址,包括主機和通訊埠,用於執行作業。從網址中移除
http:// prefix。 啟動 Flink 工作階段時,指令輸出會列出這個網址。您可以執行下列指令,在Tracking-URL欄位中列出這個網址:
yarn application -list -appId=<yarn-app-id> | sed 's#http://##' ```- FLINK_MASTER_URL:Flink 主機 VM 的網址,包括主機和通訊埠,用於執行作業。從網址中移除
列出工作階段中的工作:如要列出工作階段中的 Flink 工作,請執行下列其中一項操作:
執行不含引數的
flink list。這項指令會在/tmp/.yarn-properties-${USER}中尋找工作階段的 YARN 應用程式 ID。從
/tmp/.yarn-properties-${USER}或yarn application -list的輸出內容取得工作階段的 YARN 應用程式 ID,然後執行<code>flink list -yid YARN_APPLICATION_ID。執行
flink list -m FLINK_MASTER_URL。
停止工作階段:如要停止工作階段,請從
/tmp/.yarn-properties-${USER}或yarn application -list的輸出內容取得工作階段的 YARN 應用程式 ID,然後執行下列任一指令:echo "stop" | /usr/lib/flink/bin/yarn-session.sh -id YARN_APPLICATION_IDyarn application -kill YARN_APPLICATION_ID
在 Flink 上執行 Apache Beam 工作
您可以使用 FlinkRunner 在 Managed Service for Apache Spark 上執行 Apache Beam 工作。
您可以使用下列方式在 Flink 上執行 Beam 工作:
- Java Beam 工作
- 可攜式 Beam 工作
Java Beam 工作
將 Beam 工作封裝至 JAR 檔案。提供已組合的 JAR 檔案,其中包含執行工作所需的依附元件。
以下範例會從 Managed Service for Apache Spark 叢集的主要節點執行 Java Beam 工作。
建立已啟用 Flink 元件的 Managed Service for Apache Spark 叢集。
gcloud dataproc clusters create CLUSTER_NAME \ --optional-components=FLINK \ --image-version=DATAPROC_IMAGE_VERSION \ --region=REGION \ --enable-component-gateway \ --scopes=https://www.googleapis.com/auth/cloud-platform--optional-components:Flink。--image-version:叢集的映像檔版本,決定叢集上安裝的 Flink 版本 (例如,請參閱最新和前四個 2.0.x 映像檔發布版本列出的 Apache Flink 元件版本)。--region:支援的 Managed Service for Apache Spark 區域。--enable-component-gateway:啟用 Flink Job Manager UI 的存取權。--scopes:啟用叢集對 API 的存取權 (請參閱 Google Cloud 範圍最佳做法)。建立使用 Managed Service for Apache Spark 映像檔 2.1 以上版本的叢集時,系統預設會啟用cloud-platform範圍 (您不需要加入這個標記設定)。
使用 SSH 公用程式,在 Flink 叢集主節點上開啟終端機視窗。
在 Managed Service for Apache Spark 叢集主節點上啟動 Flink YARN 工作階段。
. /usr/bin/flink-yarn-daemon記下 Managed Service for Apache Spark 叢集上的 Flink 版本。
flink --version在本機電腦上以 Java 產生標準 Beam 字數統計範例。
選擇與 Managed Service for Apache Spark 叢集上 Flink 版本相容的 Beam 版本。請參閱「Flink 版本相容性 」 表格,瞭解 Beam-Flink 版本相容性。
開啟產生的 POM 檔案。檢查標記
<flink.artifact.name>指定的 Beam Flink 執行器版本。如果 Flink 構件名稱中的 Beam Flink 執行器版本與叢集上的 Flink 版本不符,請更新版本號碼以符合。mvn archetype:generate \ -DarchetypeGroupId=org.apache.beam \ -DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \ -DarchetypeVersion=BEAM_VERSION \ -DgroupId=org.example \ -DartifactId=word-count-beam \ -Dversion="0.1" \ -Dpackage=org.apache.beam.examples \ -DinteractiveMode=false封裝字數範例。
mvn package -Pflink-runner將封裝的 uber JAR 檔案
word-count-beam-bundled-0.1.jar(~135 MB) 上傳至 Managed Service for Apache Spark 叢集的主節點。您可以使用gcloud storage cp,將檔案從 Cloud Storage 更快速地傳輸到 Managed Service for Apache Spark 叢集。在本機終端機中建立 Cloud Storage bucket,並上傳 uber JAR。
gcloud storage buckets create BUCKET_NAMEgcloud storage cp target/word-count-beam-bundled-0.1.jar gs://BUCKET_NAME/在 Managed Service for Apache Spark 的主要節點上,下載 uber JAR。
gcloud storage cp gs://BUCKET_NAME/word-count-beam-bundled-0.1.jar .
在 Managed Service for Apache Spark 叢集的主要節點上執行 Java Beam 工作。
flink run -c org.apache.beam.examples.WordCount word-count-beam-bundled-0.1.jar \ --runner=FlinkRunner \ --output=gs://BUCKET_NAME/java-wordcount-out確認結果已寫入 Cloud Storage bucket。
gcloud storage cat gs://BUCKET_NAME/java-wordcount-out-SHARD_ID停止 Flink YARN 工作階段。
yarn application -listyarn application -kill YARN_APPLICATION_ID
可攜式 Beam 工作
如要執行以 Python、Go 和其他支援語言編寫的 Beam 工作,可以使用 FlinkRunner 和 PortableRunner,詳情請參閱 Beam 的 Flink Runner 頁面 (另請參閱 Portability Framework Roadmap)。
以下範例會從 Managed Service for Apache Spark 叢集的主要節點,以 Python 執行可攜式 Beam 工作。
建立 Managed Service for Apache Spark 叢集,並啟用 Flink 和 Docker 元件。
gcloud dataproc clusters create CLUSTER_NAME \ --optional-components=FLINK,DOCKER \ --image-version=DATAPROC_IMAGE_VERSION \ --region=REGION \ --enable-component-gateway \ --scopes=https://www.googleapis.com/auth/cloud-platform注意:
--optional-components:Flink 和 Docker。--image-version:叢集的映像檔版本,決定叢集上安裝的 Flink 版本 (例如,請參閱最新和前四個 2.0.x 映像檔發布版本列出的 Apache Flink 元件版本)。--region:可用的 Managed Service for Apache Spark 區域。--enable-component-gateway:啟用 Flink Job Manager UI 的存取權。--scopes:啟用叢集對 API 的存取權 (請參閱 Google Cloud 範圍最佳做法)。建立使用 Managed Service for Apache Spark 映像檔 2.1 以上版本的叢集時,系統預設會啟用cloud-platform範圍 (您不需要加入這個標記設定)。
在本機或 Cloud Shell 中使用 gcloud CLI 建立 Cloud Storage bucket。執行範例字數統計程式時,您會指定 BUCKET_NAME。
gcloud storage buckets create BUCKET_NAME在叢集 VM 的終端機視窗中,啟動 Flink YARN 工作階段。 請記下 Flink 主機網址,這是執行工作的 Flink 主機位址。執行範例字數統計程式時,您會指定 FLINK_MASTER_URL。
. /usr/bin/flink-yarn-daemon顯示並記下執行 Managed Service for Apache Spark 叢集的 Flink 版本。執行範例字數統計程式時,您會指定 FLINK_VERSION。
flink --version在叢集主節點上安裝作業所需的 Python 程式庫。
安裝與叢集上 Flink 版本相容的 Beam 版本。
python -m pip install apache-beam[gcp]==BEAM_VERSION在叢集主節點上執行字數範例。
python -m apache_beam.examples.wordcount \ --runner=FlinkRunner \ --flink_version=FLINK_VERSION \ --flink_master=FLINK_MASTER_URL --flink_submit_uber_jar \ --output=gs://BUCKET_NAME/python-wordcount-out注意:
--runner:FlinkRunner.--flink_version:FLINK_VERSION,如先前所述。--flink_master:FLINK_MASTER_URL,如先前所述。--flink_submit_uber_jar:使用 uber JAR 執行 Beam 工作。--output:先前建立的 BUCKET_NAME。
確認結果是否已寫入值區。
gcloud storage cat gs://BUCKET_NAME/python-wordcount-out-SHARD_ID停止 Flink YARN 工作階段。
- 取得應用程式 ID。
yarn application -list1. Insert the <var>YARN_APPLICATION_ID</var>, then stop the session.yarn application -kill
在 Kerberized 叢集上執行 Flink
Managed Service for Apache Spark Flink 元件支援 Kerberos 叢集。如要提交及保存 Flink 工作,或啟動 Flink 叢集,必須使用有效的 Kerberos 票證。根據預設,Kerberos 票證的有效期限為七天。
存取 Flink Job Manager 使用者介面
Flink 工作或 Flink 工作階段叢集執行時,Flink Job Manager 網頁介面會處於可用狀態。如要使用網頁介面,請按照下列步驟操作:
- 建立 Managed Service for Apache Spark Flink 叢集。
- 建立叢集後,請在 Google Cloud 主控台的「叢集詳細資料」頁面中,按一下「網頁介面」分頁標籤上的「Component Gateway」(元件閘道) YARN ResourceManager 連結。
- 在 YARN Resource Manager UI 中,找出 Flink 叢集應用程式項目。系統會根據工作完成狀態列出 ApplicationMaster 或 History 連結。
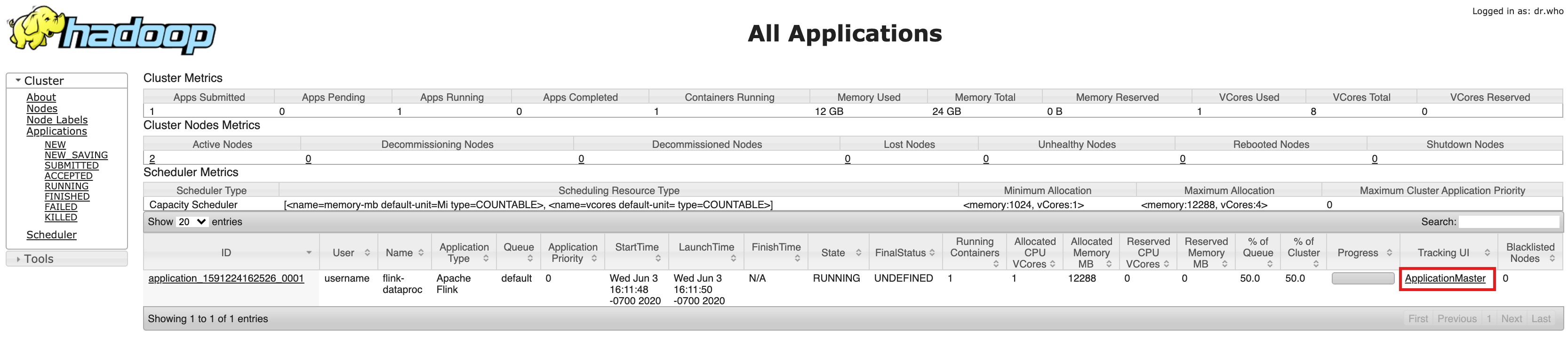
- 如果是長時間執行的串流工作,請按一下「ApplicationManager」連結開啟 Flink 資訊主頁;如果是已完成的工作,請按一下「History」連結查看工作詳細資料。
