
データ探索を有効にするには、Looker(Google Cloud コア)をデータベースに接続する必要があります。BigQuery クイックスタート接続を使用して、BigQuery 標準 SQL データベースへのデフォルト接続を作成できます。
始める前に
BigQuery クイックスタートの接続を構成するには、次の権限が必要です。
Looker の権限
次のいずれかの Looker 権限が付与されている場合、Looker(Google Cloud コア)インスタンスの [ホーム] ページで [BigQuery クイック スタートの接続] ページを表示および編集できます。
IAM の権限
Looker(Google Cloud コア)インスタンスでは、BigQuery への接続を設定するときに、アプリケーションのデフォルト認証情報(ADC)を使用して認証できます。ADC を使用すると、接続は Looker(Google Cloud コア)サービス アカウントの認証情報を使用してデータベースに対して認証を行います。サービス アカウントには、BigQuery データセットにアクセスするための次の IAM 権限が必要です。
BigQuery データセットを含むプロジェクトの場合、Looker サービス アカウントには次の IAM ロールが必要です。
- Service Usage コンシューマー(
roles/serviceusage.serviceUsageConsumer) - BigQuery ジョブユーザー(
roles/bigquery.jobUser) BigQuery データ編集者(
roles/bigquery.dataEditor)、または次の IAM 権限:bigquery.config.getbigquery.datasets.createbigquery.datasets.getbigquery.tables.createbigquery.tables.get
- Service Usage コンシューマー(
請求プロジェクトの場合、Looker サービス アカウントには次の IAM ロールが必要です。
- Service Usage コンシューマー(
roles/serviceusage.serviceUsageConsumer) - BigQuery ジョブユーザー(
roles/bigquery.jobUser)
- Service Usage コンシューマー(
Looker(Google Cloud コア)サービス アカウントに必要な IAM ロールがまだ付与されていない場合は、そのプロジェクトでロールを付与するときにサービス アカウントのメールアドレスを使用します。サービス アカウントのメールアドレスを確認するには、 Google Cloud コンソールの [IAM] ページに移動し、[Google 提供のロール付与を含める] チェックボックスをオンにします。メールアドレスの形式は service-<project number>@gcp-sa-looker.iam.gserviceaccount.com です。このメールアドレスを使用して、サービス アカウントに適切なロールを付与します。
BigQuery クイック スタートの接続を構成する
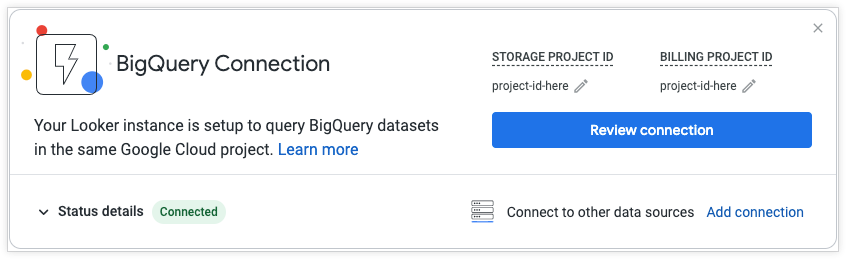
BigQuery クイックスタートの接続は、適切な権限を持つユーザーが、[ホーム] ページまたは [管理] パネルの [接続] ページで表示および編集できます。[接続] ページには、[デフォルトの BigQuery 接続] という名前で BigQuery クイックスタートの接続が表示されます。新しいインスタンスでは、[ストレージ プロジェクト ID] フィールドと [課金対象プロジェクト ID] フィールドのデフォルト値は [なし] になります。
[ホーム] ページで [接続を確認する] ボタンをクリックして接続を管理します。[ホーム] ページのタイルを閉じるには、[x] をクリックするか、[ディスカバリー] サイドバーで [BigQuery クイックスタート] オプションを切り替えます。
BigQuery クイックスタートの接続には、次のセクションがあります。
課金プロジェクト ID
プロジェクト ID は、 Google Cloud 課金プロジェクトの一意の識別子として機能します。課金プロジェクトは Google Cloud BigQuery の使用に対して課金されるプロジェクトですが、LookML デベロッパーが LookML のビュー、Explore、結合の sql_table_name パラメータに完全にスコープされたテーブル名を指定していれば、別の Google Cloud プロジェクトのデータセットをクエリできます。これは必須項目です。
OAuth を使用して BigQuery データベースに認証するには: BigQuery 接続の場合、Looker(Google Cloud コア)は、Looker(Google Cloud コア)管理者がインスタンスの作成時に使用した OAuth アプリケーション認証情報を自動的に使用できます。詳細については、Looker(Google Cloud コア)インスタンスの OAuth クライアントと認証情報を作成するをご覧ください。
[ステータスの詳細] セクションを開いて、接続の設定をテストします。
プライマリ データセット
[プライマリ データセット] ページには、次の設定があります。
ストレージ プロジェクト ID
[ストレージ プロジェクト ID] フィールドに、接続する BigQuery データセットを含むプロジェクトのプロジェクト ID を入力します。Looker(Google Cloud コア)インスタンスを含むプロジェクトと同じプロジェクトの場合でも、入力する必要があります。これは必須項目です。
プライマリ データセット
プライマリ データセットは、SQL クエリテキストでロケーションが指定されていない場合に、BigQuery がテーブルを検索するデータセットです。クエリで project_id.dataset_name.table_name 形式の完全にスコープされたテーブル名が使用されている限り、Looker(Google Cloud コア)クエリは任意のプロジェクトまたはデータセットのテーブルを参照できることに注意してください。Looker(Google Cloud コア)サービス アカウントには、その場所のテーブルにアクセスするための適切な IAM 権限も必要です。これは必須項目です。
データセットの詳細については、Looker を BigQuery に接続するドキュメント ページをご覧ください。
[ステータスの詳細] セクションを開いて、接続の設定をテストします。
BigQuery 接続のオプション設定を構成する
[オプションの設定] セクションには、次のオプションがあります。
ノードあたりの最大接続数: 一度に許可されるデータベースへの接続の最大数。注: この設定は、Looker(Google Cloud コア)デプロイのノードごとに行います。値は 5~100 の範囲で指定してください。最初はデフォルト値のままにしておきます。この設定の詳細については、Looker をデータベースに接続するドキュメント ページのノードあたりの最大接続数セクションをご覧ください。
接続プールのタイムアウト: 接続プールがいっぱいである場合にクエリがタイムアウトするまで待機する秒数。最初の設定ではデフォルト値のままで問題ありません。 この設定の詳細については、Looker をデータベースに接続するのドキュメント ページの接続プールのタイムアウトのセクションをご覧ください。
その他の JDBC パラメータ: BigQuery のラベルなど、その他の JDBC パラメータを追加します(詳細については、このページの BigQuery 接続のジョブラベルとコンテキスト コメントのセクションをご覧ください)。
メンテナンス スケジュール: データグループ トリガー チェックと PDT メンテナンスの最大頻度を示す cron 式。この設定の詳細については、メンテナンス スケジュールのドキュメントをご覧ください。
SSL: Looker(Google Cloud コア)とデータベースの間で渡されるデータを保護するために SSL 暗号化を使用するかどうかを選択します。SSL はデータの保護に使用できる唯一のオプションです。その他のセキュアなオプションについては、セキュアなデータベースアクセスを可能にするドキュメント ページをご覧ください。
SSL を確認: 接続で使用される SSL 証明書の確認を求めるかどうかを選択します。この設定の詳細については、Looker をデータベースに接続するドキュメント ページの SSL を確認セクションをご覧ください。
テーブルと列を事前にキャッシュに保存: SQL Runner では、ユーザーが接続とスキーマを選択するとすぐに、テーブル情報が事前に読み込まれます。これにより、SQL Runner ではテーブル名をクリックすると即座にテーブル列が表示されるようになります。ただし、多くのテーブルや大規模なテーブルが関係する接続とスキーマの場合は、SQL Runnerですべての情報を事前にロードしないようにすることをお勧めします。
スキーマを取得してキャッシュに保存する: 集計テーブルの自動認識などの一部の SQL 書き込み機能では、Looker(Google Cloud コア)はデータベースの情報スキーマを使用して SQL 書き込みを最適化します。この設定の詳細については、Looker をデータベースに接続するドキュメント ページの SQL 書き込み用に情報スキーマを取得するセクションをご覧ください。
PDT を有効にする: 永続的な派生テーブル(PDT)を有効にするには、[PDT を有効にする] 切り替えボタンをオンにします。PDT が有効になると、追加の PDT フィールドと [PDT オーバーライド] セクションが [オプション設定] ウィンドウに表示されます。
一時データベース: Looker(Google Cloud コア)が永続的な派生テーブルを作成する BigQuery のデータセットを入力します。このデータセットは、適切な書き込み権限を使用して事前に構成する必要があります。このフィールドは、PDT を使用するために必要です。
PDT ビルダーの最大接続数: [PDT ビルダーの最大接続数] 設定のデフォルトは 1 ですが、100 まで設定できます。ただし、この値を [ノードあたりの最大接続数] で設定された値より大きくすることはできません。この設定の詳細については、Looker をデータベースに接続ドキュメント ページの PDT ビルダーの最大接続数セクションをご覧ください。この値を設定するときには注意してください。 値が大きすぎると、データベースの負荷が高くなります。 値が小さいと、長期実行PDTまたは集計テーブルが原因で他の永続的なテーブルの作成が遅れるか、その接続の他のクエリが遅くなります。
失敗した PDT ビルドを再試行: [失敗した PDT ビルドを再試行] 切り替えボタンは、Looker(Google Cloud コア)リジェネレータが前のリジェネレータ サイクルで失敗したトリガー永続テーブルの再作成方法を構成します。この設定の詳細については、Looker をデータベースに接続ドキュメント ページの失敗した PDT ビルドを再試行するセクションをご覧ください。
PDT API コントロール: [PDT API コントロール] 切り替えボタンで、
start_pdt_build、check_pdt_build、stop_pdt_buildAPI 呼び出しをこの接続に使用できるかどうかを指定します。[PDT API コントロール] 切り替えボタンが無効になっている場合、この接続で PDT を参照していると、API 呼び出しは失敗します。PDT オーバーライド: データベースが永続的な派生テーブルをサポートしていて、接続設定の [PDT を有効にする] 切り替えボタンをオンにしている場合、Looker(Google Cloud コア)で [PDT オーバーライド] セクションが表示されます。[PDT オーバーライド] セクションには、PDT プロセスに固有の個々の JDBC パラメータ(ホスト、ポート、データベース、ユーザー名、パスワード、スキーマ、追加パラメータ、接続後のステートメント)を入力できます。この設定の詳細については、Looker をデータベースに接続するドキュメント ページの PDT のオーバーライドセクションをご覧ください。
データベースのタイムゾーン: 時間に基づく情報をデータベースで保管するときのタイムゾーン。Looker(Google Cloud コア)は、ユーザーのために時間の値を変換するため、この値が必要です。これにより、時間ベースのデータをユーザーが理解して使用しやすくなります。詳しくは、タイムゾーン設定の使用のドキュメント ページをご覧ください。
クエリのタイムゾーン: [クエリのタイムゾーン] オプションは、[ユーザー固有のタイムゾーン] を無効にしている場合にのみ表示されます。詳しくは、タイムゾーンの設定の使用ドキュメント ページをご覧ください。
[ステータスの詳細] セクションを開いて、接続の設定をテストします。
確認
[確認] セクションで、前のセクションで入力した接続の詳細を確認して変更します。
[ステータスの詳細] セクションを開いて、接続の設定をテストします。各セクションの横にある編集アイコンをクリックすると、そのセクションに戻って設定を変更できます。
接続を保存してテストする
BigQuery クイックスタートの接続に加えた変更を保存するには、[保存] をクリックします。
Looker(Google Cloud コア)UI のいくつかの場所から接続設定をテストできます。
- クイックスタートの接続ページの下部にある [ステータスの詳細] セクションを開き、[接続をテスト] をクリックします。
- [ホーム] ページで、クイックスタート接続タイルの下部にある [ステータスの詳細] セクションを開き、[接続をテスト] をクリックします。
- 接続ドキュメント ページの説明に従って、[接続] 管理ページで、接続リストの横にある [テスト] ボタンを選択します。
接続設定を入力したら、[テスト] をクリックして情報が正しいことと、データベースに接続できることを確認します。
接続が 1 つ以上のテストに合格しない場合は、以下の解決方法をお試しください。
- データベース接続のテストに関するドキュメント ページに記載されているトラブルシューティングの手順をお試しください。
- 詳細なエラー メッセージについては、Looker(Google Cloud コア)インスタンスのログをご覧ください。
- トラブルシューティングのサポートが必要な場合は、サポートにお問い合わせください。
次のステップ
- Looker(Google Cloud コア)内のユーザーを管理する
- Google Cloud コンソールから Looker(Google Cloud コア)インスタンスを管理する
- Looker(Google Cloud コア)管理設定
- Looker(Google Cloud コア)インスタンスで LookML プロジェクトのサンプルを使用する