
סקירה כללית
במדריך הזה נסביר איך להכניס לשימוש בסביבת הייצור מודלי שפה גדולים (LLM) המתקדמים ביותר (SOTA) כמו DeepSeek-R1 671B או Llama 3.1 405B ב-Google Kubernetes Engine (GKE) באמצעות יחידות עיבוד גרפי (GPU) בכמה צמתים.
במדריך הזה נדגים איך להשתמש בטכנולוגיות ניידות בקוד פתוח – Kubernetes, vLLM ו-API LeaderWorkerSet (LWS) – כדי לפרוס ולהכניס לשימוש בסביבת הייצור עומסי עבודה של AI/ML ב-GKE, תוך ניצול היתרונות של GKE: שליטה מפורטת, מדרגיות, חוסן, ניידות וחסכוניות.
לפני שקוראים את הדף הזה, חשוב לוודא שמכירים את הנושאים הבאים:
רקע
בקטע הזה מתוארות הטכנולוגיות העיקריות שבהן נעשה שימוש במדריך הזה, כולל שני מודלים גדולים של שפה (LLM) שמשמשים כדוגמאות במדריך הזה – DeepSeek-R1 ו-Llama 3.1 405B.
DeepSeek-R1
DeepSeek-R1 הוא מודל שפה גדול עם 671 מיליארד פרמטרים של DeepSeek. הוא מיועד להסקת מסקנות לוגיות, לחשיבה מתמטית ולפתרון בעיות בזמן אמת במשימות שונות שמבוססות על טקסט. GKE מטפל בדרישות החישוב של DeepSeek-R1, ותומך ביכולות שלו באמצעות משאבים ניתנים להרחבה, מחשוב מבוזר ורשתות יעילות.
מידע נוסף זמין במאמרי העזרה של DeepSeek.
Llama 3.1 405B
Llama 3.1 405B הוא מודל שפה גדול (LLM) של מטא שנועד לביצוע מגוון רחב של משימות עיבוד שפה טבעית (NLP), כולל יצירת טקסט, תרגום ומענה לשאלות. GKE מציע את התשתית החזקה שנדרשת כדי לתמוך בצרכים של אימון מבוזר ושימוש במודלים בסדר גודל כזה.
מידע נוסף זמין במאמרי העזרה בנושא Llama.
שירות Kubernetes מנוהל של GKE
Google Cloud מציעה מגוון רחב של שירותים, כולל GKE, שמתאים מאוד לפריסה ולניהול של עומסי עבודה של AI/ML. GKE הוא שירות מנוהל של Kubernetes שמפשט את הפריסה, ההתאמה לעומס (scaling) והניהול של אפליקציות בקונטיינרים. GKE מספק את התשתית הנדרשת, כולל משאבים ניתנים להרחבה, מחשוב מבוזר ורשתות יעילות, כדי לעמוד בדרישות החישוב של מודלי LLM.
מידע נוסף על מושגי Kubernetes מרכזיים זמין במאמר תחילת הלימוד של Kubernetes. מידע נוסף על GKE ועל האופן שבו הוא עוזר לכם להתאים את המערכת לעומס, לבצע אוטומציה ולנהל את Kubernetes זמין במאמר סקירה כללית של GKE.
יחידות GPU
מעבדים גרפיים (GPU) מאפשרים להאיץ עומסי עבודה ספציפיים, כמו למידת מכונה ועיבוד נתונים. GKE מציע צמתים שמצוידים במעבדי ה-GPU העוצמתיים האלה, וכך מאפשר לכם להגדיר את האשכול כדי להשיג ביצועים אופטימליים במשימות של למידת מכונה ועיבוד נתונים. GKE מספק מגוון אפשרויות של סוגי מכונות להגדרת צמתים, כולל סוגי מכונות עם GPU מסוג NVIDIA H100, L4 ו-A100.
מידע נוסף זמין במאמר מידע על יחידות GPU ב-GKE.
LeaderWorkerSet (LWS)
LeaderWorkerSet (LWS) הוא Kubernetes deployment API שמטפל בדפוסי פריסה נפוצים של עומסי עבודה של מסקנות מ-AI/ML בכמה צמתים. הצגת מודלים בכמה צמתים מתבססת על כמה תרמילים (Pods), שכל אחד מהם יכול לפעול בצומת אחר, כדי לטפל בעומס העבודה של ההסקות המבוזרות. LWS מאפשרת להתייחס לכמה תרמילים כאל קבוצה, וכך מפשטת את הניהול של מודלים מבוזרים.
vLLM והצגה במספר מארחים
כשמציגים מודלים גדולים של שפה (LLM) שדורשים הרבה משאבי מחשוב, מומלץ להשתמש ב-vLLM ולהריץ את עומסי העבודה במעבדים גרפיים (GPU).
vLLM הוא פריימוורק קוד פתוח לאירוח מודלים גדולים של שפה (LLM) שעבר אופטימיזציה גבוהה, ויכול לשפר את קצב העברת הנתונים של אירוח מודלים ביחידות GPU. הוא כולל תכונות כמו:
- הטמעה אופטימלית של טרנספורמציה באמצעות PagedAttention
- הוספת תכונה של אצווה מתמשכת כדי לשפר את התפוקה הכוללת של הצגת המודעות
- הצגת מודלים מבוזרת בכמה מעבדי GPU
במקרים של מודלי שפה גדולים (LLM) שדורשים הרבה משאבי מחשוב ולא יכולים להיכנס לצומת GPU יחיד, אפשר להשתמש בכמה צמתי GPU כדי להפעיל את המודל. ב-vLLM יש שתי אסטרטגיות להפעלת עומסי עבודה במעבדי GPU:
מקביליות טנסור מפצלת את הכפל המטריציוני בשכבת הטרנספורמציה בין כמה מעבדי GPU. עם זאת, האסטרטגיה הזו דורשת רשת מהירה בגלל התקשורת שנדרשת בין ה-GPU, ולכן היא פחות מתאימה להרצת עומסי עבודה בצמתים.
Pipeline parallelism מפצל את המודל לפי שכבה, או אנכית. השיטה הזו לא דורשת תקשורת מתמדת בין מעבדי GPU, ולכן היא עדיפה כשמריצים מודלים על פני צמתים.
אפשר להשתמש בשתי האסטרטגיות בהצגה משרתים מרובים. לדוגמה, אם משתמשים בשני צמתים עם שמונה יחידות GPU מסוג H100 בכל אחד מהם, אפשר להשתמש בשתי השיטות:
- מקביליות דו-כיוונית של צינורות (pipeline) כדי לפצל את המודל בין שני הצמתים
- מקביליות טנסור שמונה-כיוונית כדי לפצל את המודל בין שמונה מעבדי ה-GPU בכל צומת
מידע נוסף זמין במסמכי התיעוד בנושא vLLM.
מטרות
- מכינים את הסביבה עם אשכול GKE במצב Autopilot או Standard.
- פורסים את vLLM בכמה צמתים באשכול.
- משתמשים ב-vLLM כדי להפעיל את המודל באמצעות
curl.
לפני שמתחילים
- נכנסים לחשבון Google Cloud . אם אתם משתמשים חדשים ב- Google Cloud, צרו חשבון כדי שתוכלו להעריך את הביצועים של המוצרים שלנו בתרחישים מהעולם האמיתי. לקוחות חדשים מקבלים בחינם גם קרדיט בשווי 300$ להרצה, לבדיקה ולפריסה של עומסי העבודה.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the required API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the required API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
צריך לוודא שיש לכם בפרויקט את התפקיד או התפקידים הבאים: roles/container.admin, roles/iam.serviceAccountAdmin, roles/iam.securityAdmin
בדיקת התפקידים
-
נכנסים לדף IAM במסוף Google Cloud .
כניסה לדף IAM - בוחרים את הפרויקט.
-
בעמודה Principal (חשבון המשתמש), מוצאים את כל השורות שבהן מופיע השם שלכם או של קבוצה שאתם נכללים בה. כדי לברר באילו קבוצות אתם נכללים, פנו לאדמין.
- בודקים את העמודה Role בכל השורות שבהן מצוין או מופיע השם שלכם, כדי לראות אם רשימת התפקידים כוללת את התפקידים הנדרשים.
מתן התפקידים
-
נכנסים לדף IAM במסוף Google Cloud .
כניסה לדף IAM - בוחרים את הפרויקט.
- לוחצים על Grant access.
-
בשדה New principals, מזינים את מזהה המשתמש. בדרך כלל מזהה המשתמש הוא כתובת האימייל של חשבון Google.
- לוחצים על Select a role ומחפשים את התפקיד.
- כדי לתת עוד תפקידים, לוחצים על Add another role ומוסיפים אותם.
- לוחצים על Save.
-
- אם עדיין אין לכם חשבון Hugging Face, אתם צריכים ליצור חשבון.
- כדאי לעיין בדגמי ה-GPU וסוגי המכונות הזמינים כדי להבין איזה סוג מכונה ואזור מתאימים לצרכים שלכם.
- בודקים שלפרויקט יש מכסה מספקת ל-
NVIDIA_H100_MEGA. במדריך הזה השתמשנו בסוג המכונהa3-highgpu-8g, שמצויד ב-8 ליבותNVIDIA H100 80GB GPUs. מידע נוסף על יחידות GPU ועל ניהול מכסות זמין במאמרים תכנון מכסת GPU ומכסת GPU.
גישה למודל
אפשר להשתמש במודלים Llama 3.1 405B או DeepSeek-R1.
DeepSeek-R1
יצירת אסימון גישה
אם עדיין אין לכם טוקן, יוצרים טוקן חדש של Hugging Face:
- לוחצים על הפרופיל שלך > הגדרות > טוקנים של גישה.
- בוחרים באפשרות New Token (טוקן חדש).
- מציינים שם לבחירתכם ותפקיד ברמה של
Readלפחות. - לוחצים על יצירת אסימון.
Llama 3.1 405B
יצירת אסימון גישה
אם עדיין אין לכם טוקן, יוצרים טוקן חדש של Hugging Face:
- לוחצים על הפרופיל שלך > הגדרות > טוקנים של גישה.
- בוחרים באפשרות New Token (טוקן חדש).
- מציינים שם לבחירתכם ותפקיד ברמה של
Readלפחות. - לוחצים על יצירת אסימון.
הכנת הסביבה
במדריך הזה משתמשים ב-Cloud Shell כדי לנהל משאבים שמתארחים ב-Google Cloud. ב-Cloud Shell מותקן מראש התוכנה שצריך למדריך הזה, כולל kubectl ו-
gcloud CLI.
כדי להגדיר את הסביבה באמצעות Cloud Shell:
ב Google Cloud מסוף, מפעילים סשן של Cloud Shell על ידי לחיצה על Activate Cloud Shell בGoogle Cloud מסוף.
 תופעל סשן בחלונית התחתונה של Google Cloud המסוף.
תופעל סשן בחלונית התחתונה של Google Cloud המסוף.מגדירים את משתני הסביבה שמוגדרים כברירת מחדל:
gcloud config set project PROJECT_ID gcloud config set billing/quota_project PROJECT_ID export PROJECT_ID=$(gcloud config get project) export CLUSTER_NAME=CLUSTER_NAME export REGION=REGION export ZONE=ZONE export HF_TOKEN=HUGGING_FACE_TOKEN export CLUSTER_VERSION=CLUSTER_VERSIONמחליפים את הערכים הבאים:
- PROJECT_ID: Google Cloud מזהה הפרויקט.
- CLUSTER_NAME: השם של אשכול GKE.
- CLUSTER_VERSION: גרסת GKE. כדי לקבל תמיכה ב-Autopilot, צריך להשתמש בגרסה 1.33 ואילך.
- REGION: האזור של אשכול GKE.
- ZONE: אזור שתומך במעבדי GPU מסוג NVIDIA H100 Tensor Core.
יצירת אשכול GKE
אתם יכולים להפעיל מודלים באמצעות vLLM בכמה צומתי GPU באשכול GKE Autopilot או Standard. מומלץ להשתמש באשכול Autopilot כדי ליהנות מחוויית Kubernetes מנוהלת באופן מלא. כדי לבחור את מצב הפעולה של GKE שהכי מתאים לעומסי העבודה שלכם, אפשר לעיין במאמר בחירת מצב פעולה של GKE.
טייס אוטומטי
ב-Cloud Shell, מריצים את הפקודה הבאה:
gcloud container clusters create-auto ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--location=${REGION} \
--cluster-version=${CLUSTER_VERSION}
רגילה
יוצרים אשכול GKE Standard עם שני צמתי CPU:
gcloud container clusters create CLUSTER_NAME \ --project=PROJECT_ID \ --num-nodes=2 \ --location=REGION \ --machine-type=e2-standard-16יצירת מאגר צמתים מסוג A3 עם שני צמתים, שכל אחד מהם כולל שמונה כרטיסי H100:
gcloud container node-pools create gpu-nodepool \ --node-locations=ZONE \ --num-nodes=2 \ --machine-type=a3-highgpu-8g \ --accelerator=type=nvidia-h100-80gb,count=8,gpu-driver-version=LATEST \ --placement-type=COMPACT \ --cluster=CLUSTER_NAME --location=${REGION}
הגדרה של kubectl לתקשורת עם האשכול
מגדירים את kubectl לתקשורת עם האשכול באמצעות הפקודה הבאה:
gcloud container clusters get-credentials CLUSTER_NAME --location=REGION
יצירת סוד של Kubernetes לפרטי הכניסה של Hugging Face
יוצרים סוד ב-Kubernetes שמכיל את הטוקן של Hugging Face באמצעות הפקודה הבאה:
kubectl create secret generic hf-secret \
--from-literal=hf_api_token=${HF_TOKEN} \
--dry-run=client -o yaml | kubectl apply -f -
התקנה של LeaderWorkerSet
כדי להתקין את LWS, מריצים את הפקודה הבאה:
kubectl apply --server-side -f https://github.com/kubernetes-sigs/lws/releases/latest/download/manifests.yaml
מריצים את הפקודה הבאה כדי לוודא שהבקר LeaderWorkerSet פועל במרחב השמות lws-system:
kubectl get pod -n lws-system
הפלט אמור להיראות כך:
NAME READY STATUS RESTARTS AGE
lws-controller-manager-546585777-crkpt 1/1 Running 0 4d21h
lws-controller-manager-546585777-zbt2l 1/1 Running 0 4d21h
פריסת שרת מודלים של vLLM
כדי לפרוס את שרת מודל vLLM, פועלים לפי השלבים הבאים:
מחילים את קובץ המניפסט, בהתאם למודל ה-LLM שרוצים לפרוס.
DeepSeek-R1
בודקים את קובץ המניפסט
vllm-deepseek-r1-A3.yaml.מריצים את הפקודה הבאה כדי להחיל את המניפסט:
kubectl apply -f vllm-deepseek-r1-A3.yaml
Llama 3.1 405B
בודקים את קובץ המניפסט
vllm-llama3-405b-A3.yaml.מריצים את הפקודה הבאה כדי להחיל את המניפסט:
kubectl apply -f vllm-llama3-405b-A3.yaml
ממתינים עד שהורדת נקודת הבדיקה של המודל מסתיימת. הפעולה הזו עשויה להימשך כמה דקות.
כדי להציג את היומנים משרת המודלים הפועל, מריצים את הפקודה הבאה:
kubectl logs vllm-0 -c vllm-leaderהפלט אמור להיראות כך:
INFO 08-09 21:01:34 api_server.py:297] Route: /detokenize, Methods: POST INFO 08-09 21:01:34 api_server.py:297] Route: /v1/models, Methods: GET INFO 08-09 21:01:34 api_server.py:297] Route: /version, Methods: GET INFO 08-09 21:01:34 api_server.py:297] Route: /v1/chat/completions, Methods: POST INFO 08-09 21:01:34 api_server.py:297] Route: /v1/completions, Methods: POST INFO 08-09 21:01:34 api_server.py:297] Route: /v1/embeddings, Methods: POST INFO: Started server process [7428] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
פרסום המודל
מגדירים העברה ליציאה אחרת למודל על ידי הרצת הפקודה הבאה:
kubectl port-forward svc/vllm-leader 8080:8080
אינטראקציה עם המודל באמצעות curl
כדי ליצור אינטראקציה עם המודל באמצעות curl, פועלים לפי ההוראות הבאות:
DeepSeek-R1
בטרמינל חדש, שולחים בקשה לשרת:
curl http://localhost:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-ai/DeepSeek-R1",
"prompt": "I have four boxes. I put the red box on the bottom and put the blue box on top. Then I put the yellow box on top the blue. Then I take the blue box out and put it on top. And finally I put the green box on the top. Give me the final order of the boxes from bottom to top. Show your reasoning but be brief",
"max_tokens": 1024,
"temperature": 0
}'
הפלט אמור להיראות כך:
{
"id": "cmpl-f2222b5589d947419f59f6e9fe24c5bd",
"object": "text_completion",
"created": 1738269669,
"model": "deepseek-ai/DeepSeek-R1",
"choices": [
{
"index": 0,
"text": ".\n\nOkay, let's see. The user has four boxes and is moving them around. Let me try to visualize each step. \n\nFirst, the red box is placed on the bottom. So the stack starts with red. Then the blue box is put on top of red. Now the order is red (bottom), blue. Next, the yellow box is added on top of blue. So now it's red, blue, yellow. \n\nThen the user takes the blue box out. Wait, blue is in the middle. If they remove blue, the stack would be red and yellow. But where do they put the blue box? The instruction says to put it on top. So after removing blue, the stack is red, yellow. Then blue is placed on top, making it red, yellow, blue. \n\nFinally, the green box is added on the top. So the final order should be red (bottom), yellow, blue, green. Let me double-check each step to make sure I didn't mix up any steps. Starting with red, then blue, then yellow. Remove blue from the middle, so yellow is now on top of red. Then place blue on top of that, so red, yellow, blue. Then green on top. Yes, that seems right. The key step is removing the blue box from the middle, which leaves yellow on red, then blue goes back on top, followed by green. So the final order from bottom to top is red, yellow, blue, green.\n\n**Final Answer**\nThe final order from bottom to top is \\boxed{red}, \\boxed{yellow}, \\boxed{blue}, \\boxed{green}.\n</think>\n\n1. Start with the red box at the bottom.\n2. Place the blue box on top of the red box. Order: red (bottom), blue.\n3. Place the yellow box on top of the blue box. Order: red, blue, yellow.\n4. Remove the blue box (from the middle) and place it on top. Order: red, yellow, blue.\n5. Place the green box on top. Final order: red, yellow, blue, green.\n\n\\boxed{red}, \\boxed{yellow}, \\boxed{blue}, \\boxed{green}",
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null,
"prompt_logprobs": null
}
],
"usage": {
"prompt_tokens": 76,
"total_tokens": 544,
"completion_tokens": 468,
"prompt_tokens_details": null
}
}
Llama 3.1 405B
בטרמינל חדש, שולחים בקשה לשרת:
curl http://localhost:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "meta-llama/Meta-Llama-3.1-405B-Instruct",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'
הפלט אמור להיראות כך:
{"id":"cmpl-0a2310f30ac3454aa7f2c5bb6a292e6c",
"object":"text_completion","created":1723238375,"model":"meta-llama/Llama-3.1-405B-Instruct","choices":[{"index":0,"text":" top destination for foodies, with","logprobs":null,"finish_reason":"length","stop_reason":null}],"usage":{"prompt_tokens":5,"total_tokens":12,"completion_tokens":7}}
הגדרת קנה מידה אוטומטי בהתאמה אישית
בקטע הזה מגדירים התאמה אופקית של קבוצות Pod לעומס לשימוש במדדים מותאמים אישית של Prometheus. אתם משתמשים במדדים של השירות המנוהל של Google Cloud ל-Prometheus משרת vLLM.
מידע נוסף זמין במאמר בנושא השירות המנוהל של Google Cloud ל-Prometheus. ההגדרה הזו אמורה להיות מופעלת כברירת מחדל באשכול GKE.
מגדירים את Custom Metrics Stackdriver Adapter באשכול:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yamlמוסיפים את התפקיד Monitoring Viewer לחשבון השירות שבו משתמש מתאם Stackdriver של מדדים מותאמים אישית:
gcloud projects add-iam-policy-binding projects/PROJECT_ID \ --role roles/monitoring.viewer \ --member=principal://iam.googleapis.com/projects/PROJECT_NUMBER/locations/global/workloadIdentityPools/PROJECT_ID.svc.id.goog/subject/ns/custom-metrics/sa/custom-metrics-stackdriver-adapterשומרים את קובץ המניפסט הבא בשם
vllm_pod_monitor.yaml:מחילים את המניפסט על האשכול:
kubectl apply -f vllm_pod_monitor.yaml
יצירת עומס בנקודת הקצה של vLLM
יוצרים עומס על שרת vLLM כדי לבדוק איך GKE מבצע התאמה אוטומטית לעומס (autoscaling) באמצעות מדד vLLM מותאם אישית.
מגדירים העברה ליציאה אחרת למודל:
kubectl port-forward svc/vllm-leader 8080:8080מריצים סקריפט bash (
load.sh) כדי לשלוחNמספר בקשות מקבילות לנקודת הקצה של vLLM:#!/bin/bash # Set the number of parallel processes to run. N=PARALLEL_PROCESSES # Get the external IP address of the vLLM load balancer service. export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}') # Loop from 1 to N to start the parallel processes. for i in $(seq 1 $N); do # Start an infinite loop to continuously send requests. while true; do # Use curl to send a completion request to the vLLM service. curl http://$vllm_service:8000/v1/completions -H "Content-Type: application/json" -d '{"model": "meta-llama/Llama-3.1-70B", "prompt": "Write a story about san francisco", "max_tokens": 100, "temperature": 0}' done & # Run in the background done # Keep the script running until it is manually stopped. waitמחליפים את PARALLEL_PROCESSES במספר התהליכים המקבילים שרוצים להריץ.
מריצים את סקריפט ה-Bash:
nohup ./load.sh &
אימות ההטמעה של המדדים בשירות המנוהל של Google Cloud ל-Prometheus
אחרי שהשירות המנוהל של Google Cloud ל-Prometheus סורק את המדדים ואתם מוסיפים עומס לנקודת הקצה של vLLM, תוכלו לראות את המדדים ב-Cloud Monitoring.
נכנסים לדף Metrics explorer במסוף Google Cloud .
לוחצים על < > PromQL.
מזינים את השאילתה הבאה כדי לראות את מדדי התנועה:
vllm:gpu_cache_usage_perc{cluster='CLUSTER_NAME'}
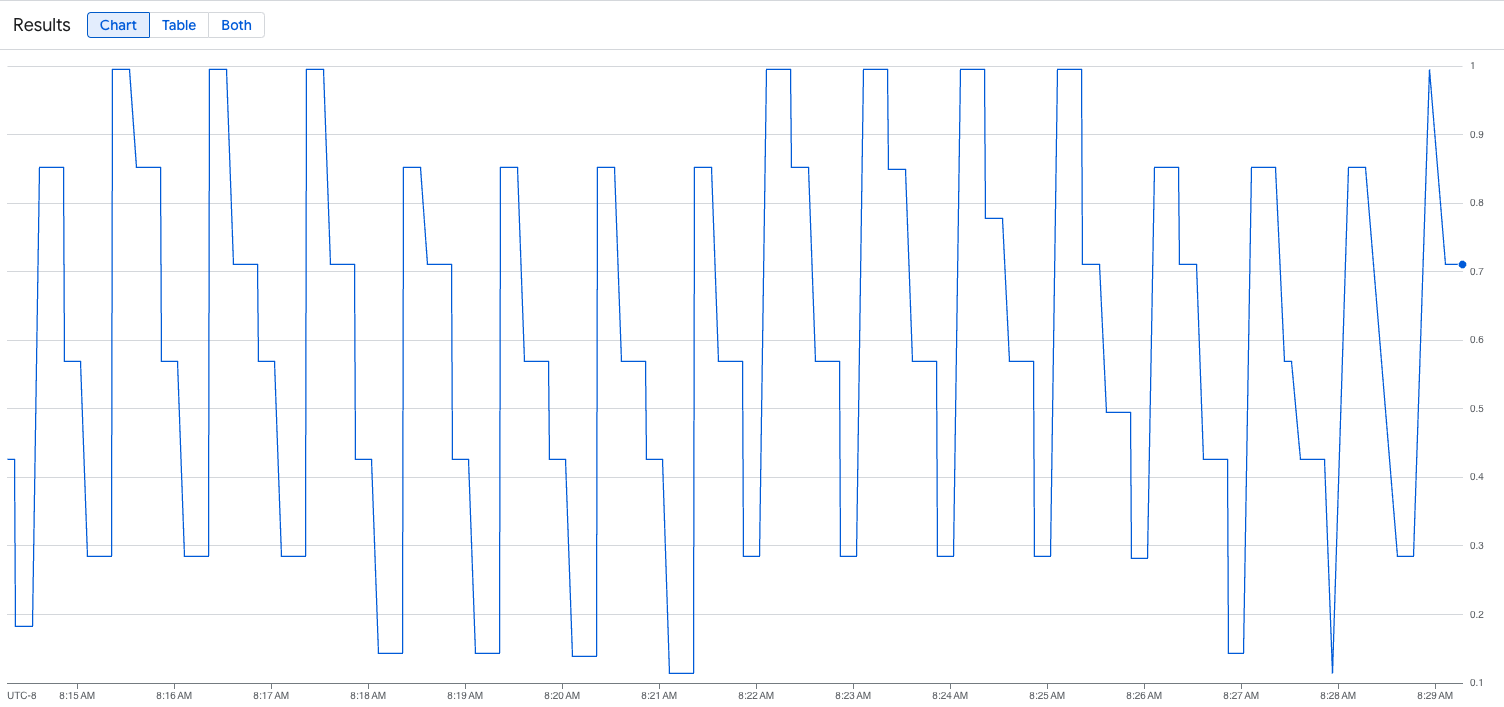
בתמונה הבאה אפשר לראות דוגמה לתרשים אחרי הפעלת סקריפט הטעינה. הגרף הזה מראה שהשירות המנוהל של Google Cloud ל-Prometheus קולט את מדדי התנועה בתגובה לעומס שנוסף לנקודת הקצה של vLLM:
פריסת ההגדרה של Horizontal Pod Autoscaler
כשמחליטים על איזה מדד להגדיר שינוי גודל אוטומטי, מומלץ להשתמש במדדים הבאים עבור vLLM:
num_requests_waiting: המדד הזה מתייחס למספר הבקשות שממתינות בתור של שרת המודל. המספר הזה מתחיל לגדול באופן משמעותי כשמטמון ה-KV מלא.
gpu_cache_usage_perc: המדד הזה קשור לניצול של מטמון KV, שקשור ישירות למספר הבקשות שעוברות עיבוד עבור מחזור הסקה נתון בשרת המודל.
מומלץ להשתמש ב-num_requests_waiting כשמבצעים אופטימיזציה של קצב העברת הנתונים והעלות, וכשיעדי ההשהיה ניתנים להשגה עם קצב העברת הנתונים המקסימלי של שרת המודל.
מומלץ להשתמש ב-gpu_cache_usage_perc כשעובדים עם עומסי עבודה שרגישים לזמן האחזור, ושינוי הגודל על בסיס תור לא מספיק מהיר כדי לעמוד בדרישות.
הסבר נוסף מופיע במאמר בנושא שיטות מומלצות להתאמה אוטומטית לעומס של עומסי עבודה של היקש של מודלים גדולים של שפה (LLM) באמצעות מעבדי GPU.
כשבוחרים averageValue יעד להגדרת HPA, צריך לקבוע על סמך איזה מדד תתבצע התאמה אוטומטית של קנה המידה בניסוי. רעיונות נוספים לאופטימיזציה של הניסויים זמינים בפוסט בבלוג חיסכון בעלויות של מעבדי GPU: התאמה אוטומטית חכמה יותר לעומסי העבודה של GKE inferencing. מחולל הפרופילים שבו נעשה שימוש בפוסט הזה בבלוג פועל גם עם vLLM.
כדי לפרוס את ההגדרה של Horizontal Pod Autoscaler באמצעות num_requests_waiting, פועלים לפי השלבים הבאים:
שומרים את קובץ המניפסט הבא בשם
vllm-hpa.yaml:המדדים של vLLM בשירות המנוהל של Google Cloud ל-Prometheus הם בפורמט
vllm:metric_name.שיטה מומלצת: משתמשים ב-
num_requests_waitingכדי לשנות את קצב העברת הנתונים. מומלץ להשתמש ב-gpu_cache_usage_percבתרחישי שימוש ב-GPU שרגישים לזמן הטעינה.פורסים את ההגדרה של Horizontal Pod Autoscaler:
kubectl apply -f vllm-hpa.yamlמערכת GKE מתזמנת פוד נוסף לפריסה, מה שגורם למנגנון לשינוי גודל מאגר הצמתים להוסיף צומת שני לפני פריסת הרפליקה השנייה של vLLM.
צופים בהתקדמות של התאמת קבוצות ה-Pod לעומס:
kubectl get hpa --watchהפלט אמור להיראות כך:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE lws-hpa LeaderWorkerSet/vllm 0/1 1 2 1 6d1h lws-hpa LeaderWorkerSet/vllm 1/1 1 2 1 6d1h lws-hpa LeaderWorkerSet/vllm 0/1 1 2 1 6d1h lws-hpa LeaderWorkerSet/vllm 4/1 1 2 1 6d1h lws-hpa LeaderWorkerSet/vllm 0/1 1 2 2 6d1h
קיצור זמני הטעינה של מודלים באמצעות Google Cloud Hyperdisk ML
בסוגים האלה של מודלים גדולים של שפה, יכול לעבור הרבה זמן עד שמורידים, טוענים ומפעילים את vLLM בכל רפליקה חדשה. לדוגמה, התהליך הזה יכול להימשך כ-90 דקות עם Llama 3.1 405B. אפשר לקצר את הזמן הזה (ל-20 דקות עם Llama 3.1 405B) על ידי הורדת המודל ישירות לנפח Hyperdisk ML והוספת הנפח לכל Pod. כדי להשלים את הפעולה הזו, במדריך הזה נעשה שימוש בנפח Hyperdisk ML וב-Kubernetes Job. ב-Kubernetes, בקר משימות יוצר פוד אחד או יותר ועוזר לוודא שהם מבצעים משימה ספציפית בהצלחה.
כדי לקצר את זמן הטעינה של המודל, מבצעים את השלבים הבאים:
שומרים את קובץ המניפסט לדוגמה הבא בשם
producer-pvc.yaml:kind: PersistentVolumeClaim apiVersion: v1 metadata: name: producer-pvc spec: # Specifies the StorageClass to use. Hyperdisk ML is optimized for ML workloads. storageClassName: hyperdisk-ml accessModes: - ReadWriteOnce resources: requests: storage: 800Giשומרים את קובץ המניפסט לדוגמה הבא בשם
producer-job.yaml:DeepSeek-R1
Llama 3.1 405B
פועלים לפי ההוראות במאמר האצת טעינת נתונים של AI/ML באמצעות Hyperdisk ML, ומשתמשים בשני הקבצים שיצרתם בשלבים הקודמים.
אחרי השלב הזה, נפח ה-Hyperdisk ML נוצר ואוכלס בנתוני המודל.
פורסים את הפריסה של שרת GPU מרובה צמתים vLLM, שתשתמש בנפח Hyperdisk ML שנוצר לאחרונה לנתוני המודל.
DeepSeek-R1
Llama 3.1 405B
הסרת המשאבים
כדי להימנע מחיובים בחשבון Google Cloud בגלל השימוש במשאבים שנעשה במסגרת המדריך הזה, אפשר למחוק את הפרויקט שמכיל את המשאבים, או להשאיר את הפרויקט ולמחוק את המשאבים בנפרד.
מחיקת המשאבים שנפרסו
כדי להימנע מחיובים בחשבון Google Cloud על המשאבים שיצרתם במדריך הזה, מריצים את הפקודה הבאה:
ps -ef | grep load.sh | awk '{print $2}' | xargs -n1 kill -9
gcloud container clusters delete CLUSTER_NAME \
--location=ZONE
המאמרים הבאים
- מידע נוסף על יחידות GPU ב-GKE
- אפשר לעיין במאגר GitHub ובמסמכי העזרה של vLLM.
- עיון במאגר GitHub של LWS