
בדף הזה מוסבר איך אפשר להשתמש ב-GKE Inference Quickstart (GIQ) כדי לפשט את הפריסה של עומסי עבודה של הסקת מסקנות מ-AI/ML ב-Google Kubernetes Engine (GKE). Inference Quickstart הוא כלי שמאפשר לציין את הדרישות העסקיות שלכם לגבי הסקת מסקנות ולקבל הגדרות אופטימליות של Kubernetes על סמך שיטות מומלצות ומדדי הביצועים של Google לגבי מודלים, שרתי מודלים, מאיצים (GPU, TPU), שינוי גודל ואחסון. כך לא תצטרכו לבצע התאמות ולבדוק את ההגדרות באופן ידני, תהליך שלוקח הרבה זמן.
הדף הזה מיועד למהנדסי למידת מכונה (ML), לאדמינים ולמפעילים של פלטפורמות ולמומחים בתחום הנתונים וה-AI שרוצים להבין איך לנהל ולייעל ביעילות את GKE להסקת מסקנות ב-AI/ML. מידע נוסף על תפקידים נפוצים ועל משימות לדוגמה שאנחנו מתייחסים אליהן בתוכן של Google Cloud , זמין במאמר תפקידים נפוצים של משתמשים ומשימות ב-GKE.
מידע נוסף על מושגים ומינוחים שקשורים להפעלת מודלים, ועל האופן שבו היכולות של GKE Gen AI יכולות לשפר ולתמוך בביצועים של הפעלת המודלים, זמין במאמר מידע על הסקת מסקנות ממודלים ב-GKE.
לפני שקוראים את הדף הזה, חשוב לוודא שמכירים את Kubernetes, GKE והצגת מודלים.
שימוש במדריך למתחילים בנושא הסקת מסקנות
המדריך למתחילים בנושא הסקת מסקנות מאפשר לכם לנתח את הביצועים ואת היעילות של עלויות עומסי העבודה של הסקת המסקנות, ולקבל החלטות מבוססות-נתונים לגבי הקצאת משאבים ואסטרטגיות פריסת מודלים.
השלבים העיקריים לשימוש בתכונה 'התחלה מהירה של הסקת מסקנות' הם:
ניתוח הביצועים והעלות: אפשר לעיין בהגדרות הזמינות ולסנן אותן לפי דרישות הביצועים והעלות באמצעות הפקודה
gcloud container ai profiles list. כדי לראות את כל נתוני ההשוואה להגדרה מסוימת, משתמשים בפקודהgcloud container ai profiles benchmarks list. הפקודה הזו מאפשרת לכם לזהות את החומרה הכי חסכונית שמתאימה לדרישות הביצועים הספציפיות שלכם.בנוסף, אפשר לסנן את ההמלצות של התחלת העבודה המהירה בנושא הסקת מסקנות לפי מאפיינים של עומס העבודה, כמו תרחיש שימוש וגדלים של קלט/פלט, ולפי מחסנית ההגשה. חבילת טכנולוגיות להצגת מודעות היא קבוצה מלאה של טכנולוגיות שמשמשות לאירוח מודל, לטיפול בהסקת מסקנות ולהפניית בקשות משתמשים כדי לספק תחזיות. לדוגמה, מחסנית התכונות
llm-dמשתמשת ב-vLLM כשרת המודלים הבסיסי שלה, ומוסיפה שכבה של תזמור וניתוב מעל מנוע ההסקה המרכזי.פריסת מניפסטים: אחרי הניתוח, אפשר ליצור מניפסט Kubernetes שעבר אופטימיזציה ולפרוס אותו. אופציונלי: אתם יכולים להפעיל אופטימיזציות לאחסון ולשינוי גודל אוטומטי. אפשר לבצע פריסה ממסוף Google Cloud או באמצעות הפקודה
kubectl apply. לפני הפריסה, צריך לוודא שיש לכם מכסת מאיצים מספקת עבור יחידות ה-GPU או ה-TPU שנבחרו בפרויקט. Google Cloud(אופציונלי) הפעלת בדיקות השוואה משלכם: ההגדרות ונתוני הביצועים שמסופקים על ידי Inference Quickstart מבוססים על בדיקות השוואה שנוצרו על ידי הכלי
inference-perf. יכול להיות שהביצועים של עומס העבודה שלכם יהיו שונים מהביצועים של המודל הבסיסי הזה, ולכן מומלץ להשתמש בinference-perfכלי למדידת הביצועים של המודל עם מערך נתונים שמייצג בצורה הטובה ביותר את תרחיש השימוש שלכם.
יתרונות
המדריך להתחלת העבודה עם הסקת מסקנות עוזר לכם לחסוך זמן ומשאבים באמצעות הגדרות אופטימליות. האופטימיזציות האלה משפרות את הביצועים ומפחיתות את עלויות התשתית, בדרכים הבאות:
- מקבלים שיטות מומלצות מפורטות ומותאמות אישית להגדרת המאיץ (GPU ו-TPU), שרת המודל והגדרות ההתאמה של קנה המידה. GKE מעדכן באופן שוטף את המדריך לתחילת העבודה עם הסקת מסקנות, ומוסיף לו את התיקונים, התמונות ומדדי הביצועים העדכניים ביותר.
- אפשר לציין את דרישות ההשהיה והתפוקה של עומס העבודה באמצעות ממשק המשתמש של מסוףGoogle Cloud או ממשק שורת פקודה, ולקבל המלצות מפורטות ומותאמות אישית כמאניפסטים של פריסת Kubernetes.
איך זה עובד
המדריך להתחלה מהירה בנושא היקש מספק שיטות מומלצות מותאמות אישית על סמך מדדי הביצועים המקיפים של Google לגבי שילובים של טופולוגיות של מודלים, שרתי מודלים ומאיצים עם רפליקה אחת. נקודות ההשוואה האלה מציגות גרף של זמן האחזור לעומת קצב העברת הנתונים, כולל מדדים של גודל התור ומטמון KV, שממפים עקומות ביצועים לכל שילוב.
איך נוצרות שיטות מומלצות מותאמות אישית
אנחנו מודדים את זמן האחזור באמצעות זמן מנורמל לכל טוקן פלט (NTPOT) והזמן עד לטוקן הראשון (TTFT) באלפיות השנייה, ואת התפוקה באמצעות טוקנים של פלט לשנייה, על ידי רוויית המאיצים. מידע נוסף על מדדי הביצועים האלה זמין במאמר מידע על הסקת מסקנות של מודלים ב-GKE.
פרופיל ההשהיה הבא לדוגמה ממחיש את נקודת הפיתול שבה קצב העברת הנתונים מתייצב (ירוק), את הנקודה שאחרי הפיתול שבה ההשהיה מתארכת (אדום) ואת האזור האידיאלי (כחול) לקצב העברת נתונים אופטימלי בהשהיה שהוגדרה כיעד. במדריך למתחילים בנושא הסקת מסקנות מוסבר על נתוני הביצועים וההגדרות של האזור האידיאלי הזה.
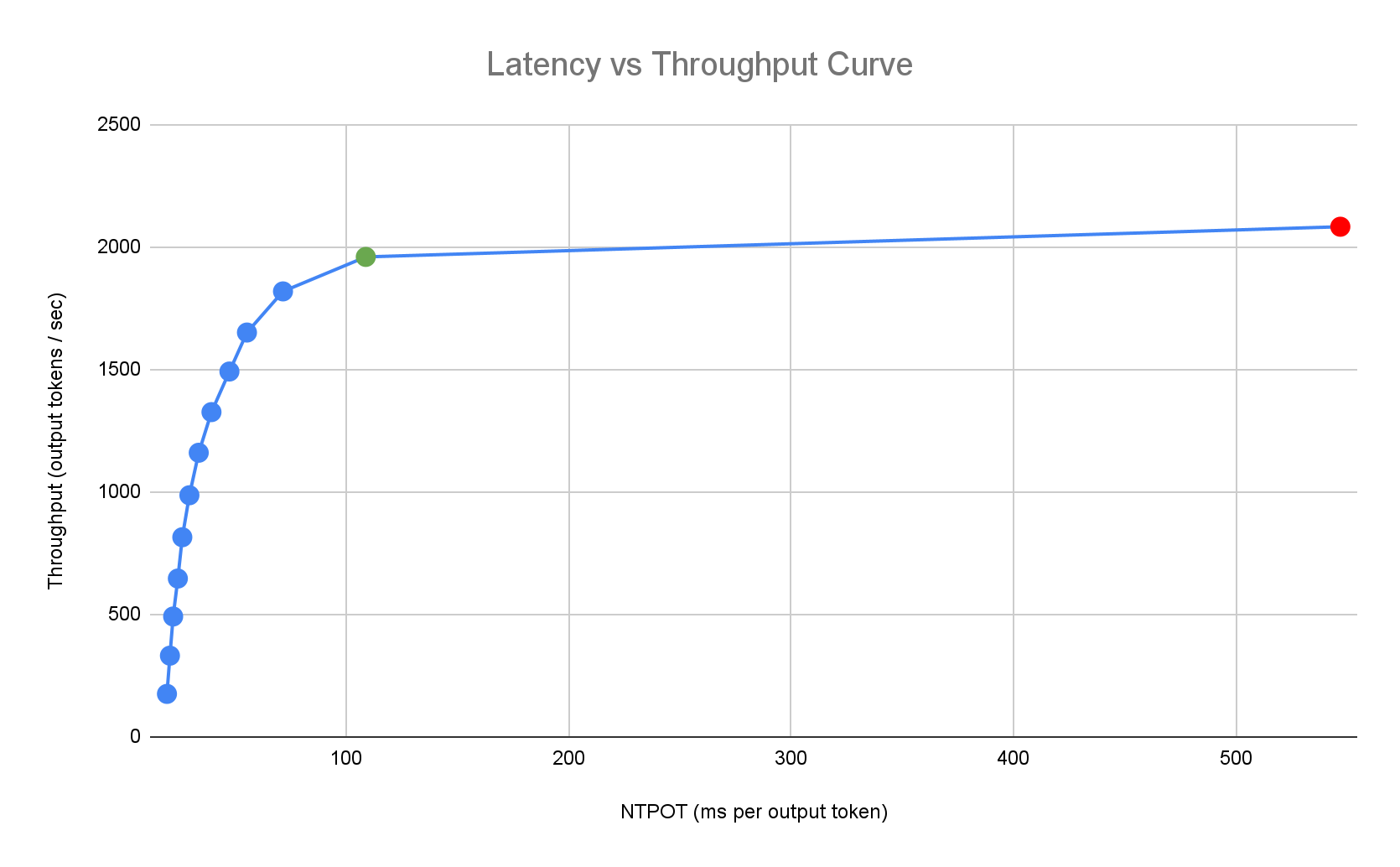
על סמך דרישות זמן האחזור של אפליקציית ההסקה, המדריך לתחילת העבודה עם הסקה מזהה שילובים מתאימים וקובע את נקודת ההפעלה האופטימלית בעקומת זמן האחזור והתפוקה. הנקודה הזו מגדירה את סף Horizontal Pod Autoscaler (HPA), עם מאגר לחישוב זמן האחזור של הגדלת הקיבולת. הסף הכולל משמש גם לקביעת מספר הרפליקות הראשוני שנדרש, אבל ה-HPA משנה את המספר הזה באופן דינמי בהתאם לעומס העבודה.
אומדן עלויות
כדי להעריך את העלויות לכל טוקן של מכונות וירטואליות עם האצת AI, במדריך לתחילת העבודה עם הסקת מסקנות נעשה שימוש ביחס עלות פלט לקלט שניתן להגדרה. לדוגמה, אם היחס הזה מוגדר כ-4, ההנחה היא שכל טוקן פלט עולה פי ארבעה יותר מטוקן קלט. המשוואות הבאות משמשות לחישוב מדדי העלות לכל טוקן:
\[ \$/\text{output token} = \frac{\text{GPU \$/s}}{(\frac{1}{\text{output-to-input-cost-ratio}} \cdot \text{input tokens/s} + \text{output tokens/s})} \]
איפה
\[ \$/\text{input token} = \frac{\text{\$/output token}}{\text{output-to-input-cost-ratio}} \]
השוואה לשוק
ההגדרות ונתוני הביצועים שסופקו מבוססים על נקודות השוואה שנוצרו על ידי הכלי inference-perf להפניית תנועה עם חלוקת הקלט והפלט הבאה.
| טוקנים של קלט | טוקנים של פלט | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| מינימום | חציון | ממוצע | P90 | P99 | מקסימום | מינימום | חציון | ממוצע | P90 | P99 | מקסימום |
| 4 | 108 | 226 | 635 | 887 | 1024 | 1 | 132 | 195 | 488 | 778 | 1024 |
לפני שמתחילים
לפני שמתחילים, חשוב לוודא שביצעתם את הפעולות הבאות:
- מפעילים את ממשק Google Kubernetes Engine API. הפעלת Google Kubernetes Engine API
- כדי להשתמש ב-CLI של Google Cloud למשימה הזו, צריך להתקין ואז להפעיל את gcloud CLI. אם התקנתם בעבר את ה-CLI של gcloud, מריצים את הפקודה
gcloud components updateכדי לקבל את הגרסה העדכנית. יכול להיות שגרסאות קודמות של ה-CLI של gcloud לא יתמכו בהרצת הפקודות שמופיעות במסמך הזה.
בדף לבחירת הפרויקט במסוף Google Cloud , בוחרים פרויקט ב- Google Cloud או יוצרים אותו.
מוודאים שיש מספיק קיבולת של מאיצים לפרויקט:
- אם אתם משתמשים ביחידות GPU: בדקו את דף המכסות.
- אם אתם משתמשים ב-TPU: כדאי לעיין במאמר איך מוודאים שיש מכסת TPU ומשאבים אחרים ב-GKE.
הכנה לשימוש בממשק המשתמש של GKE AI/ML
אם אתם משתמשים במסוף Google Cloud , אתם צריכים גם ליצור אשכול Autopilot, אם עדיין לא נוצר אשכול כזה בפרויקט שלכם. פועלים לפי ההוראות במאמר יצירת אשכול Autopilot.
הכנה לשימוש בממשק שורת הפקודה
אם משתמשים ב-CLI של gcloud כדי להריץ את המדריך למתחילים בנושא הסקת מסקנות, צריך להריץ גם את הפקודות הנוספות האלה:
מפעילים את ה-API של
gkerecommender.googleapis.com:gcloud services enable gkerecommender.googleapis.comמגדירים את פרויקט המכסה לחיוב שבו משתמשים לקריאות ל-API:
gcloud config set billing/quota_project PROJECT_IDבודקים שגרסת ה-CLI של gcloud היא לפחות 536.0.1. אם לא, מריצים את הפקודה הבאה:
gcloud components update
מגבלות
לפני שמתחילים להשתמש במדריך למתחילים בנושא הסקת מסקנות, חשוב להכיר את המגבלות הבאות:
- פריסת מודלים במסוףGoogle Cloud תומכת רק בפריסה לאשכולות של Autopilot.
- המדריך למתחילים בנושא הסקת מסקנות לא מספק פרופילים לכל המודלים שנתמכים על ידי שרת מודלים נתון.
- אם לא מגדירים את משתנה הסביבה
HF_HOMEכשמשתמשים במניפסט שנוצר עבור מודל גדול (90 GiB ומעלה) מ-Hugging Face, צריך להשתמש באשכול עם דיסקים לאתחול גדולים יותר מהברירת מחדל או לשנות את המניפסט כדי להגדיר אתHF_HOMEל-/dev/shm/hf_cache. הזיכרון הזה ישמש למטמון במקום דיסק האתחול של הצומת. מידע נוסף זמין בקטע פתרון בעיות. - טעינת מודלים מ-Cloud Storage מחייבת איחוד זהויות של עומסי עבודה ל-GKE. מנהל התקן ה-CSI של Cloud Storage FUSE נדרש גם לכל עומסי העבודה של TPU, ומשמש כגיבוי לגרסאות ספציפיות של שרת מודלים מגרסה
v0.11.1ומטה. במצב Autopilot, איחוד זהויות של עומסי עבודה ל-GKE ודרייבר ה-CSI של Cloud Storage FUSE מופעלים כברירת מחדל. פרטים נוספים זמינים במאמר בנושא הגדרת מנהל התקן ה-CSI של Cloud Storage FUSE ל-GKE.
ניתוח של הגדרות אופטימליות להסקת מסקנות ממודל וצפייה בהן
בקטע הזה מוסבר איך לבדוק ולנתח המלצות להגדרות באמצעות Google Cloud CLI.
משתמשים בפקודה gcloud container ai profiles כדי לבדוק ולנתח פרופילים שעברו אופטימיזציה (שילובים של מודל, שרת מודלים, גרסת שרת מודלים ומאיצים):
מודלים
כדי לעיין במודל ולבחור אותו, משתמשים באפשרות models.
gcloud container ai profiles models list
פרופילים
אפשר להשתמש בפקודה list כדי לעיין בפרופילים שנוצרו ולסנן אותם לפי דרישות הביצועים והעלות שלכם. לדוגמה:
gcloud container ai profiles list \
--model=openai/gpt-oss-20b \
--pricing-model=on-demand \
--target-ttft-milliseconds=300
בפלט מוצגים פרופילים נתמכים עם מדדי ביצועים כמו תפוקה, זמן אחזור ועלות למיליון טוקנים בנקודת הפיתול. הוא אמור להיראות כך:
Instance Type Accelerator Cost/M Input Tokens Cost/M Output Tokens Output Tokens/s NTPOT(ms) TTFT(ms) Model Server Model Server Version Model
a3-highgpu-1g nvidia-h100-80gb 0.009 0.035 13335 67 297 vllm gptoss openai/gpt-oss-20b
הערכים מייצגים את הביצועים שנצפו בנקודה שבה קצב העברת הנתונים מפסיק לעלות והחביון מתחיל לעלות באופן משמעותי (כלומר, נקודת הפיתול או נקודת הרוויה) עבור פרופיל נתון עם סוג המאיץ הזה. מידע נוסף על מדדי הביצועים האלה זמין במאמר מידע על הסקת מסקנות ממודלים ב-GKE.
רשימה מלאה של הדגלים שאפשר להגדיר מופיעה במאמרי העזרה של הפקודה list.
כל פרטי התמחור זמינים רק במטבע USD, והם מוגדרים כברירת מחדל לאזור us-east5, למעט הגדרות שמשתמשות במכונות A3, שמוגדרות כברירת מחדל לאזור us-central1.
נקודות השוואה
כדי לקבל את כל נתוני ההשוואה של פרופיל ספציפי, משתמשים בפקודה benchmarks list.
לדוגמה:
gcloud container ai profiles benchmarks list \
--model=deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \
--model-server=vllm
הפלט מכיל רשימה של מדדי ביצועים מנקודות השוואה שהופעלו בקצבי בקשות שונים.
הפלט של הפקודה מוצג בפורמט CSV. כדי לאחסן את הפלט כקובץ, משתמשים בהפניית פלט. לדוגמה:
gcloud container ai profiles benchmarks list > profiles.csv.
רשימה מלאה של הדגלים שאפשר להגדיר מופיעה במאמרי העזרה של הפקודה benchmarks list.
אחרי שבוחרים מודל, שרת מודלים, גרסת שרת מודלים ומאיץ, אפשר להמשיך ליצירת מניפסט פריסה.
הצגת המלצות לפי תרחיש לדוגמה
במדריך לתחילת העבודה עם הסקת מסקנות מפורטות המלצות לתרחישים שונים לדוגמה שמייצגים עומסי עבודה נפוצים של AI/ML. תרחישי השימוש האלה מאופיינים בטווח של אורכי טוקנים של קלט ופלט שמבוססים על עומסי עבודה של לקוחות בעולם האמיתי, שיכולים להשפיע על הביצועים של מחסנית ההסקה הבסיסית.
בטבלה הבאה מופיע סיכום של תרחישי השימוש הזמינים והמאפיינים שלהם:
| תרחיש שימוש | טוקנים של קלט | טוקנים של פלט | יחס | תיאור |
|---|---|---|---|---|
| תמיכת לקוחות מתקדמת | 8,192 | 256 | 32:1 | אתם יכולים לפתור בעיות מורכבות של לקוחות באמצעות תשובות מקיפות ומסוכמות, כדי להרחיב את פעולות התמיכה ולשפר את שביעות רצון המשתמשים. |
| השלמת קוד | 512 | 32 | 16:1 | האצת פיתוח התוכנה באמצעות הצעות והשלמות קוד אוטומטיות. |
| סיכום טקסט | 1,024 | 128 | 8:1 | לצמצם מסמכים ארוכים, מאמרים או שיחות לסיכומים תמציתיים. |
| צ'אט בוט (ShareGPT) | 128 | 128 | 1:1 | לספק עזרה מיידית בשיחה כדי לענות על שאלות, לבצע משימות או להציע הדרכה. |
| יצירת טקסט | 512 | 2,048 | 1:4 | אוטומציה של יצירת תוכן כתוב חדש, החל מטיוטות של אימיילים ודוחות ועד ליצירת סיפורים יצירתיים. |
| Deep Research | 256 | 4,096 | 1:16 | ניתוח וסינתוז של כמויות גדולות של נתונים כדי למצוא מידע ספציפי, לזהות דפוסים ולחשוף תובנות, וכך לאפשר חקירות ומחקרים מפורטים. |
כדי לראות את הרשימה המלאה של תרחישי השימוש שנתמכים על ידי התחלת העבודה המהירה עם הסקת מסקנות, משתמשים בפקודה gcloud container ai profiles use-cases list.
כדי לסנן את ההמלצות לפי תרחיש לדוגמה, משתמשים בדגל --use-case. כשיוצרים קובץ מניפסט, אם לא מציינים את הדגל הזה, ברירת המחדל היא Chatbot.
לדוגמה:
gcloud container ai profiles list \
--use-case="Text Summarization"
פריסת הגדרות מומלצות
בקטע הזה מוסבר איך ליצור ולפרוס המלצות להגדרות באמצעות מסוף Google Cloud או שורת הפקודה.
המסוף
- במסוף Google Cloud , עוברים לדף GKE AI/ML.
- לוחצים על Deploy Models (פריסת מודלים).
בוחרים את המודל שרוצים לפרוס. דגמים שנתמכים על ידי המדריך לתחילת העבודה עם הסקת מסקנות מוצגים עם התג Optimized (אופטימלי).
- אם בחרתם מודל בסיס, ייפתח דף המודל. לוחצים על פריסה. עדיין אפשר לשנות את ההגדרה לפני הפריסה בפועל.
- אם אין פרויקט כזה, תתבקשו ליצור אשכול Autopilot. פועלים לפי ההוראות במאמר יצירת אשכול Autopilot. אחרי שיוצרים את האשכול, חוזרים לדף GKE AI/ML במסוף Google Cloud כדי לבחור מודל.
- כדי לפרוס מודלים עם גישה מוגבלת כמו Gemma או Llama, קודם צריך ליצור טוקן של Hugging Face ולהוסיף אותו כסוד של Kubernetes. אם לא תעשו את זה, יכול להיות שתופיע שגיאה
"Does not have minimum availability"שתמנע את יצירת הפריסה. הוראות מפורטות מופיעות בכרטיסייה gcloud בדף התיעוד הזה.
בדף של פריסת המודל, המודל שבחרתם מאוכלס מראש, וגם שרת המודל והמאיץ המומלצים. אפשר גם להגדיר הגדרות כמו חביון מקסימלי ומקור המודל.
(אופציונלי) כדי לראות את קובץ המניפסט עם ההגדרה המומלצת, לוחצים על View YAML (הצגת YAML).
כדי לפרוס את קובץ המניפסט עם ההגדרה המומלצת, לוחצים על Deploy (פריסה). יכול להיות שיעברו כמה דקות עד שהפריסה תושלם.
כדי לראות את הפריסה, עוברים לדף Kubernetes Engine > Workloads.
gcloud
הכנה לטעינת מודלים ממאגר המודלים: המדריך למתחילים בנושא הסקת מסקנות תומך בטעינת מודלים מ-Hugging Face או מ-Cloud Storage.
Hugging Face
אם עדיין אין לכם, יוצרים טוקן גישה של Hugging Face וסוד Kubernetes תואם.
כדי ליצור סוד של Kubernetes שמכיל את האסימון של Hugging Face, מריצים את הפקודה הבאה:
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=HUGGING_FACE_TOKEN \ --namespace=NAMESPACEמחליפים את הערכים הבאים:
- HUGGING_FACE_TOKEN: האסימון של Hugging Face שיצרתם קודם.
- NAMESPACE: מרחב השמות של Kubernetes שבו רוצים לפרוס את שרת המודל.
יכול להיות שחלק מהמודלים ידרשו מכם גם לאשר ולחתום על הסכם רישיון להסכמה.
Cloud Storage
אתם יכולים לטעון מודלים נתמכים מ-Cloud Storage עם הגדרה מותאמת של Cloud Storage FUSE. כדי לעשות את זה, קודם צריך לטעון את המודל מ-Hugging Face לקטגוריה של Cloud Storage.
אפשר לפרוס את Kubernetes Job הזה כדי להעביר את המודל, ולשנות את
MODEL_IDלמודל שנתמך ב-Inference Quickstart.יצירת קובצי מניפסט: יש לכם את האפשרויות הבאות ליצירת קובצי מניפסט:
- הגדרת בסיס: יוצרת את המניפסטים הרגילים של Kubernetes Deployment, Service ו-PodMonitoring לפריסת שרת הסקה עם עותק יחיד.
- (אופציונלי) הגדרה לאופטימיזציה של אחסון: יוצרת מניפסט שעבר אופטימיזציה לטעינה ב-Cloud Storage. בהגדרה הזו יש עדיפות ל-Run:ai Model Streamer לשיפור הביצועים בגרסאות vLLM נתמכות, תוך שימוש בהגדרה מותאמת של Cloud Storage FUSE לגרסאות קודמות. כדי להפעיל את ההגדרה הזו, משתמשים בדגל
--model-bucket-uri. האופטימיזציות האלה יכולות לשפר את זמן ההפעלה של LLM Pod ביותר מפי 7. (אופציונלי) הגדרה אופטימלית להתאמה אוטומטית לעומס: יוצרת מניפסט עם Horizontal Pod Autoscaler (HPA) כדי להתאים באופן אוטומטי את מספר הרפליקות של שרת המודל על סמך התנועה. כדי להפעיל את ההגדרה הזו, צריך לציין יעד השהיה באמצעות פלאגים כמו
--target-ntpot-milliseconds.
הגדרת הבסיס
בטרמינל, משתמשים באפשרות
manifestsכדי ליצור מניפסטים של Deployment, Service ו-PodMonitoring:gcloud container ai profiles manifests createמשתמשים בפרמטרים הנדרשים
--model,--model-serverו---accelerator-typeכדי להתאים אישית את קובץ המניפסט.אפשר גם להגדיר את הפרמטרים האלה:
--target-ntpot-milliseconds: מגדירים את הפרמטר הזה כדי לציין את ערך הסף של ה-HPA. הפרמטר הזה מאפשר להגדיר סף של שינוי קנה מידה כדי לשמור על חביון P50 של זמן נורמלי ליצירת טוקן פלט (NTPOT), שנמדד באחוזון ה-50, מתחת לערך שצוין. בוחרים ערך שגבוה מהחביון המינימלי של המאיץ. ה-HPA מוגדר לתפוקה מקסימלית אם מציינים ערך NTPOT שגבוה מהחביון המקסימלי של המאיץ. לדוגמה:gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --model-server=vllm \ --model-server-version=v0.7.2 \ --accelerator-type=nvidia-l4 \ --target-ntpot-milliseconds=200
--target-ttft-milliseconds: זמן היעד עד לאסימון הראשון (TTFT) באלפיות השנייה. אם ההגדרה הזו מוגדרת, קובץ המניפסט כולל משאבי Horizontal Pod Autoscaler (HPA) כדי לשמור על ערך p50 של TTFT מתחת לסף שצוין.
--output-path: אם מציינים נתיב, הפלט נשמר בנתיב שצוין ולא מודפס במסוף, כדי שתוכלו לערוך את הפלט לפני הפריסה. לדוגמה, אפשר להשתמש באפשרות הזו עם האפשרות--output=manifestאם רוצים לשמור את המניפסט בקובץ YAML. לדוגמה:gcloud container ai profiles manifests create \ --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \ --model-server vllm \ --accelerator-type=nvidia-tesla-a100 \ --output=manifest \ --output-path /tmp/manifests.yaml-
--target-itl-milliseconds: זמן האחזור הממוצע בין אסימונים (ITL) באלפיות השנייה. אם המדיניות הזו מוגדרת, המניפסט כולל משאבי Horizontal Pod Autoscaler (HPA) כדי לשמור על ערך ה-ITL של p50 מתחת לסף שצוין. -
--use-case: המניפסט יעבור אופטימיזציה לתרחיש השימוש הזה. אם לא מציינים את הדגל הזה, ברירת המחדל היאChatbot. מידע נוסף מופיע במאמר צפייה בהמלצות לפי תרחיש שימוש.
-
רשימה מלאה של הדגלים שאפשר להגדיר מופיעה במאמרי העזרה של הפקודה
manifests create.מותאמת לאחסון (storage-optimized)
כדי לקצר את זמן ההפעלה של ה-Pod, אפשר לטעון מודלים מ-Cloud Storage. המדריך לתחילת העבודה עם הסקת מסקנות בוחר באופן אוטומטי את קצה העורף של האחסון עם הביצועים הכי טובים להגדרה שלכם:
- Run:ai Model Streamer: פתרון סטרימינג שמשמש באופן אוטומטי ל-vLLM מגרסה 0.11.1 ואילך ב-GPU ומגרסה 0.14.0 ואילך ב-TPU.
- מנהל התקן ה-CSI של Cloud Storage FUSE: האופטימיזציה הסטנדרטית של האחסון, שמשמשת לגרסאות vLLM מוקדמות יותר מ-0.11.1 ולשרתי מודלים אחרים.
טעינה מ-Cloud Storage מחייבת שימוש בגרסאות GKE 1.29.6-gke.1254000, 1.30.2-gke.1394000 או גרסאות מאוחרות יותר
לשם כך, בצע את הצעדים הבאים:
- טוענים את המודל ממאגר Hugging Face לקטגוריה שלכם ב-Cloud Storage.
מגדירים את הדגל
--model-bucket-uriכשיוצרים את קובץ המניפסט. ההגדרה הזו קובעת שהמודל ייטען מקטגוריה של Cloud Storage. המודל משתמש אוטומטית ב-Run:ai Model Streamer לביצועים גבוהים עבור גרסאות vLLM נתמכות, וחוזר למנהל התקן ה-CSI של Cloud Storage FUSE עבור גרסאות אחרות. ה-URI צריך להוביל לנתיב שמכיל את קובץconfig.jsonשל המודל ואת המשקלים שלו. אפשר לציין נתיב לספרייה בתוך הקטגוריה על ידי הוספתו ל-URI של הקטגוריה.לדוגמה:
gcloud container ai profiles manifests create \ --model=openai/gpt-oss-120b \ --model-server=vllm \ --model-server-version=v0.11.2 \ --accelerator-type=nvidia-h100-80gb \ --model-bucket-uri=gs://BUCKET_NAME \ --output-path=manifests.yamlמחליפים את
BUCKET_NAMEבשם של הקטגוריה שלכם ב-Cloud Storage.לפני שמחילים את קובץ המניפסט, צריך להריץ את הפקודה
gcloud storage buckets add-iam-policy-bindingשמופיעה בהערות של קובץ המניפסט. הפקודה הזו נדרשת כדי להעניק לחשבון השירות של GKE הרשאה לגשת לדלי ב-Cloud Storage באמצעות איחוד שירותי אימות הזהות של עומסי עבודה ב-GKE.אם אתם מתכוונים להרחיב את הפריסה ליותר עותק אחד ב-TPU, אתם צריכים לבחור באחת מהאפשרויות הבאות כדי למנוע שגיאות כתיבה בו-זמניות בנתיב של מטמון XLA (
VLLM_XLA_CACHE_PATH):- אפשרות 1 (מומלצת): קודם כל, משנים את קנה המידה של הפריסה ל-1 רפליקה. מחכים שה-Pod יהיה מוכן, כדי שיוכל לכתוב למטמון XLA. לאחר מכן, מגדילים את מספר הרפליקות הרצוי. העותקים הבאים יקראו מהמטמון המאוכלס ללא התנגשויות כתיבה.
- אפשרות 2: להסיר את משתנה הסביבה
VLLM_XLA_CACHE_PATHלחלוטין מהמניפסט. הגישה הזו פשוטה יותר, אבל היא משביתה את השמירה במטמון לכל העותקים.
בסוגי מאיצי TPU, נתיב המטמון הזה משמש לאחסון מטמון ההידור של XLA, שמאיץ את הכנת המודל לפריסות חוזרות.
טיפים נוספים לשיפור הביצועים מפורטים במאמר אופטימיזציה של מנהל התקן ה-CSI של Cloud Storage FUSE לביצועים ב-GKE.
אופטימיזציה להתאמה אוטומטית לעומס
אפשר להגדיר את Horizontal Pod Autoscaler (HPA) כך שישנה אוטומטית את מספר הרפליקות של שרת המודל על סמך העומס. כך שרתי המודלים יכולים לטפל ביעילות בעומסים משתנים על ידי הגדלה או הקטנה של הקיבולת לפי הצורך. ההגדרה של HPA מבוססת על השיטות המומלצות לשינוי גודל אוטומטי של מעבדי GPU וTPU.
כדי לכלול הגדרות של HPA כשיוצרים מניפסטים, משתמשים בדגל
--target-ntpot-millisecondsאו בדגל--target-ttft-milliseconds, או בשניהם. הפרמטרים האלה מגדירים סף שינוי גודל עבור HPA כדי לשמור על זמן האחזור של P50 עבור NTPOT או TTFT מתחת לערך שצוין. אם מגדירים רק אחד מהדגלים האלה, רק המדד הזה ייכלל בחישוב של שינוי קנה המידה.בוחרים ערך שגבוה מהחביון המינימלי של המאיץ. ה-HPA מוגדר לתפוקה מקסימלית אם מציינים ערך שגבוה מהחביון המקסימלי של המאיץ.
לדוגמה:
gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --accelerator-type=nvidia-l4 \ --target-ntpot-milliseconds=250יצירת אשכול: אפשר להפעיל את המודל באשכולות GKE Autopilot או Standard. כדי ליהנות מחוויית Kubernetes מנוהלת באופן מלא, מומלץ להשתמש באשכול Autopilot. כדי לבחור את מצב הפעולה של GKE שהכי מתאים לעומסי העבודה שלכם, אפשר לעיין במאמר בחירת מצב פעולה של GKE.
אם אין לכם אשכול קיים, אתם צריכים לפעול לפי השלבים הבאים:
טייס אוטומטי
פועלים לפי ההוראות האלה כדי ליצור אשכול Autopilot. GKE מטפל בהקצאת הצמתים עם קיבולת GPU או TPU על סמך מניפסטים של פריסה, אם יש לכם את המכסה הנדרשת בפרויקט.
רגילה
- יוצרים אשכול אזורי או אזורי.
יוצרים מאגר צמתים עם המאיצים המתאימים. פועלים לפי השלבים הבאים בהתאם לסוג המאיץ שבחרתם:
- GPU: קודם כל, בודקים את דף המכסות ב Google Cloud מסוף כדי לוודא שיש לכם מספיק קיבולת GPU. לאחר מכן, פועלים לפי ההוראות במאמר יצירת מאגר צמתים של GPU.
- TPU: קודם צריך לוודא שיש לכם מספיק מכסת TPU. לשם כך, פועלים לפי ההוראות במאמר איך מוודאים שיש מכסה ל-TPU ולמשאבי GKE אחרים. לאחר מכן, ממשיכים אל יצירת מאגר של צמתי TPU.
(אופציונלי, אבל מומלץ) הפעלת תכונות של יכולת צפייה: בקטע ההערות של המניפסט שנוצר, מופיעות פקודות נוספות להפעלת תכונות מוצעות של יכולת צפייה. הפעלת התכונות האלה מספקת תובנות נוספות שיעזרו לכם לעקוב אחרי הביצועים והסטטוס של עומסי העבודה והתשתית הבסיסית.
הדוגמה הבאה מראה איך להשתמש בפקודה כדי להפעיל את תכונות הניטור:
gcloud container clusters update $CLUSTER_NAME \ --project=$PROJECT_ID \ --location=$LOCATION \ --enable-managed-prometheus \ --logging=SYSTEM,WORKLOAD \ --monitoring=SYSTEM,DEPLOYMENT,HPA,POD,DCGM \ --auto-monitoring-scope=ALLמידע נוסף מופיע במאמר בנושא מעקב אחרי עומסי עבודה של הסקת מסקנות.
(HPA בלבד) פריסת מתאם מדדים: מתאם מדדים, כמו Custom Metrics Stackdriver Adapter, נדרש אם משאבי HPA נוצרו במניפסטים של הפריסה. מתאם המדדים מאפשר ל-HPA לגשת למדדים של שרת המודלים שמשתמשים ב-kube external metrics API. כדי לפרוס את המתאם, אפשר לעיין במסמכי התיעוד של המתאם ב-GitHub.
פורסים את המניפסטים: מריצים את הפקודה
kubectl applyומעבירים את קובץ ה-YAML של המניפסטים. לדוגמה:kubectl apply -f ./manifests.yaml
פריסת ההגדרות המומלצות למקבץ שרתים של llm-d
llm-d הוא מחסנית להסקת מסקנות מבוזרת שפועלת באופן מקורי ב-Kubernetes. היא מספקת נתיבים ברורים שנבדקו ועברו בחינות השוואתיות, כדי לעזור לכם להפעיל מודלים גדולים של AI גנרטיבי בקנה מידה גדול עם רמת ביצועים גבוהה. מידע נוסף זמין במאמרי העזרה בנושא llm-d.
כדי ליצור ולפרוס הגדרה מומלצת עבור מחסנית השרתים llm-d באמצעות ההפעלה המהירה של ההסקה, משתמשים בדגל --serving-stack עם הערך llm-d. לדוגמה:
gcloud container ai profiles manifests create \
--accelerator-type=nvidia-h100-80gb \
--model=openai/gpt-oss-120b \
--model-server=vllm \
--serving-stack=llm-d \
--use-case 'Multi Agent Large Document Summarization'
בודקים את הפלט של manifests create כדי לקבל הוראות נוספות ליצירת אשכול ולהתקנת תלות, כדי להגדיר את הסביבה בצורה נכונה עבור llm-d.
בדיקת נקודות הקצה של הפריסה
אחרי פריסת המניפסט, השירות נחשף בכתובת http://SERVICE_NAME:8000, כאשר SERVICE_NAME הוא שם הפריסה.
כדי לאשר את שם השירות, אפשר לרשום את השירותים במרחב השמות (לדוגמה, default):
kubectl get services --namespace NAMESPACE
כדי לבדוק את הפריסה, משתמשים בפקודה kubectl port-forward כדי להעביר יציאה מקומית ליציאת השירות. בטרמינל נפרד, מריצים את הפקודה הבאה:
kubectl port-forward service/SERVICE_NAME 8000:8000
לאחר מכן תוכלו לשלוח בקשות אל http://localhost:8000. דוגמאות לאופן שבו אפשר ליצור ולשלוח בקשות לנקודת הקצה מופיעות במסמכי התיעוד של vLLM.
ניהול גרסאות של מניפסט
במדריך לתחילת העבודה עם הסקת מסקנות מפורטים המניפסטים העדכניים שאומתו בגרסאות עדכניות של אשכול GKE. יכול להיות שהמניפסט שמוחזר לפרופיל ישתנה עם הזמן, כך שתקבלו הגדרה אופטימלית בזמן הפריסה. אם אתם צריכים קובץ מניפסט יציב, שמרו אותו בנפרד.
המניפסט כולל הערות ואת ההערה recommender.ai.gke.io/version בפורמט הבא:
# Generated on DATE using:
# GKE cluster CLUSTER_VERSION
# GPU_DRIVER_VERSION GPU driver for node version NODE_VERSION
# Model server MODEL_SERVER MODEL_SERVER_VERSION
הערכים של ההערה הקודמת:
- DATE: התאריך שבו נוצר המניפסט.
- CLUSTER_VERSION: גרסת אשכול GKE שמשמשת לאימות.
- NODE_VERSION: גרסת הצומת של GKE שמשמשת לאימות.
- GPU_DRIVER_VERSION: (GPU בלבד) גרסת מנהל ההתקן של ה-GPU ששימשה לאימות.
- MODEL_SERVER: שרת המודלים שמשמש במניפסט.
- MODEL_SERVER_VERSION: גרסת שרת המודל שמשמשת במניפסט.
מעקב אחרי עומסי עבודה של הסקת מסקנות
כדי לעקוב אחרי עומסי העבודה של ההסקות שהופעלו, עוברים אל Metrics Explorer במסוף Google Cloud .
הפעלת מעקב אוטומטי
GKE כולל תכונת מעקב אוטומטית שמהווה חלק מתכונות הנראות הרחבות יותר. התכונה הזו סורקת את האשכול כדי למצוא עומסי עבודה שפועלים בשרתי מודלים נתמכים, ומפריסה את משאבי PodMonitoring שמאפשרים לראות את מדדי עומסי העבודה האלה ב-Cloud Monitoring. מידע נוסף על הפעלה והגדרה של מעקב אוטומטי זמין במאמר הגדרת מעקב אוטומטי של אפליקציות לעומסי עבודה.
אחרי שמפעילים את התכונה, GKE מתקין לוחות בקרה מוכנים מראש למעקב אחרי אפליקציות עבור עומסי עבודה נתמכים.
אם אתם פורסים מהדף GKE AI/ML במסוף Google Cloud , המערכת יוצרת בשבילכם באופן אוטומטי את המשאבים PodMonitoring ו-HPA באמצעות ההגדרה targetNtpot.
פתרון בעיות
- אם תגדירו את זמן האחזור נמוך מדי, יכול להיות שהכלי Inference Quickstart לא ייצור המלצה. כדי לפתור את הבעיה הזו, בוחרים יעד זמן אחזור בין זמן האחזור המינימלי לזמן האחזור המקסימלי שנמדדו עבור המאיצים שנבחרו.
- המדריך לתחילת העבודה עם הסקת מסקנות לא תלוי ברכיבי GKE, ולכן גרסת האשכול לא רלוונטית ישירות לשימוש בשירות. עם זאת, מומלץ להשתמש באשכול חדש או באשכול מעודכן כדי למנוע אי-התאמות בביצועים.
- אם מקבלים שגיאת
PERMISSION_DENIEDבפקודותgkerecommender.googleapis.comשבה כתוב שחסר פרויקט מכסה, צריך להגדיר אותו באופן ידני. כדי לפתור את הבעיה, מריצים את הפקודהgcloud config set billing/quota_project PROJECT_ID.
ה-Pod הוצא בגלל נפח אחסון זמני נמוך
כשפורסים מודל גדול (90 GiB ומעלה) מ-Hugging Face, יכול להיות שה-Pod יסולק עם הודעת שגיאה שדומה לזו:
Fails because inference server consumes too much ephemeral storage, and gets evicted low resources: Warning Evicted 3m24s kubelet The node was low on resource: ephemeral-storage. Threshold quantity: 10120387530, available: 303108Ki. Container inference-server was using 92343412Ki, request is 0, has larger consumption of ephemeral-storage..,
השגיאה הזו מתרחשת כי המודל נשמר במטמון בדיסק האתחול של הצומת, שהוא סוג של אחסון זמני. דיסק האתחול משמש לאחסון זמני כשבקובץ המניפסט של הפריסה לא מוגדר משתנה הסביבה HF_HOME לספרייה בזיכרון ה-RAM של הצומת.
- כברירת מחדל, לצומתי GKE יש דיסק אתחול של 100GiB.
- ב-GKE, 10% מדיסק האתחול שמורים לתקורה של המערכת, כך שנותרים 90 GiB לעומסי העבודה.
- אם גודל המודל הוא 90 GiB או יותר, והוא מופעל בדיסק אתחול בגודל ברירת המחדל, kubelet מפנה את ה-Pod כדי לפנות אחסון זמני.
כדי לפתור את הבעיה, בוחרים אחת מהאפשרויות הבאות:
- שימוש ב-RAM לאחסון במטמון של המודל: בקובץ המניפסט של הפריסה, מגדירים את משתנה הסביבה
HF_HOMEלערך/dev/shm/hf_cache. המודל נשמר במטמון ב-RAM של הצומת במקום בדיסק האתחול. - הגדלת הגודל של דיסק האתחול:
- GKE Standard: מגדילים את הגודל של דיסק האתחול כשיוצרים אשכול, יוצרים מאגר צמתים או מעדכנים מאגר צמתים.
- Autopilot: כדי לבקש דיסק אתחול גדול יותר, יוצרים סוג מחשוב בהתאמה אישית ומגדירים את השדה
bootDiskSizeבכללmachineType.
ה-Pod נכנס ללולאת קריסה כשמטעינים מודלים מ-Cloud Storage
אחרי שפורסים מניפסט שנוצר באמצעות הדגל --model-bucket-uri, יכול להיות שהפריסה תיתקע וה-Pod יעבור למצב CrashLoopBackOff.
בדיקת היומנים של מאגר inference-server עשויה להציג שגיאה מטעה, כמו huggingface_hub.errors.HFValidationError. לדוגמה:
huggingface_hub.errors.HFValidationError: Repo id must use alphanumeric chars or '-', '_', '.', '--' and '..' are forbidden, '-' and '.' cannot start or end the name, max length is 96: '/data'.
השגיאה הזו מתרחשת בדרך כלל כשהנתיב של Cloud Storage שצוין בדגל --model-bucket-uri שגוי. שרת ההיסק, כמו vLLM,
לא יכול למצוא את קובצי המודל הנדרשים (כמו config.json) בנתיב המותקן.
אם השרת לא מצליח למצוא את הקבצים המקומיים, הוא מניח שהנתיב הוא מזהה מאגר ב-Hugging Face Hub. מכיוון שהנתיב אינו מזהה מאגר תקין, השרת נכשל עם שגיאת אימות ונכנס ללולאת קריסה.
כדי לפתור את הבעיה, צריך לוודא שהנתיב שציינתם לדגל --model-bucket-uri
מפנה לספרייה המדויקת בדליקת Cloud Storage שמכילה את קובץ config.json המודל ואת כל משקלי המודל המשויכים.
המאמרים הבאים
- בפורטל לתזמור של AI/ML ב-GKE אפשר לעיין במדריכים הרשמיים, בהדרכות ובתרחישים לדוגמה להרצת עומסי עבודה של AI/ML ב-GKE.
- מידע נוסף על אופטימיזציה של מודלים זמין במאמר שיטות מומלצות לאופטימיזציה של הסקת מסקנות של מודלים גדולים של שפה באמצעות מעבדי GPU. המדריך כולל שיטות מומלצות להפעלת מודלים גדולים של שפה (LLM) באמצעות מעבדי GPU ב-GKE, כמו קוונטיזציה, מקביליות טנסור וניהול זיכרון.
- מידע נוסף על שיטות מומלצות לשינוי אוטומטי של גודל ה-VM זמין במדריכים הבאים:
- מידע על שיטות מומלצות לאחסון זמין במאמר איך מייעלים את מנהל התקן ה-CSI של Cloud Storage FUSE לביצועים ב-GKE.
- ב-GKE AI Labs תוכלו לעיין בדוגמאות ניסיוניות לשימוש ב-GKE כדי לקדם את היוזמות שלכם בתחום ה-AI ולמידת המכונה.