
En este tutorial se explica cómo puedes reducir costes desplegando un escalador automático programado en Google Kubernetes Engine (GKE). Este tipo de escalador automático aumenta o reduce el tamaño de los clústeres según una programación basada en la hora del día o el día de la semana. Un escalador automático programado es útil si tu tráfico tiene un flujo y reflujo predecibles. Por ejemplo, si eres un comercio regional o si tu software está dirigido a empleados cuyo horario de trabajo se limita a una parte específica del día.
Este tutorial está dirigido a desarrolladores y operadores que quieran aumentar la capacidad de los clústeres de forma fiable antes de que se produzcan picos y reducirla de nuevo para ahorrar dinero por la noche, los fines de semana o en cualquier otro momento en el que haya menos usuarios online. En este artículo se da por hecho que conoces Docker, Kubernetes, CronJobs de Kubernetes, GKE y Linux.
Introducción
Muchas aplicaciones experimentan patrones de tráfico irregulares. Por ejemplo, los trabajadores de una organización solo pueden interactuar con una aplicación durante el día. Por lo tanto, los servidores del centro de datos de esa aplicación están inactivos por la noche.
Además de otras ventajas, Google Cloud puede ayudarte a ahorrar dinero asignando infraestructura de forma dinámica en función de la carga de tráfico. En algunos casos, una configuración de escalado automático sencilla puede gestionar el problema de asignación que supone el tráfico desigual. Si es tu caso, sigue así. Sin embargo, en otros casos, los cambios bruscos en los patrones de tráfico requieren configuraciones de autoescalado más precisas para evitar la inestabilidad del sistema durante los aumentos de escala y para evitar el aprovisionamiento excesivo del clúster.
Este tutorial se centra en situaciones en las que se conocen bien los cambios bruscos en los patrones de tráfico y quieres dar pistas al escalador automático de que tu infraestructura va a experimentar picos. En este documento se muestra cómo aumentar la escala de los clústeres de GKE por la mañana y reducirla por la noche, pero puedes usar un enfoque similar para aumentar y reducir la capacidad en cualquier evento conocido, como eventos de escalado máximo, campañas publicitarias o tráfico de fin de semana.
Reducir la escala de un clúster si tienes descuentos por uso confirmado
En este tutorial se explica cómo reducir los costes minimizando tus clústeres de GKE durante las horas de menor actividad. Sin embargo, si has comprado un descuento por uso comprometido, es importante que sepas cómo funcionan estos descuentos junto con el ajuste automático de escala.
Los contratos por uso confirmado te ofrecen precios con grandes descuentos cuando te comprometes a pagar por una cantidad determinada de recursos (vCPUs, memoria y otros). Sin embargo, para determinar la cantidad de recursos que se van a asignar, debes saber de antemano cuántos recursos utilizan tus cargas de trabajo a lo largo del tiempo. Para ayudarte a reducir los costes, el siguiente diagrama muestra qué recursos debes incluir en tu planificación y cuáles no.

Como se muestra en el diagrama, la asignación de recursos en un contrato de uso comprometido es constante. Los recursos cubiertos por el contrato deben usarse la mayor parte del tiempo para que merezca la pena el compromiso que has adquirido. Por lo tanto, no debes incluir recursos que se utilicen durante los picos al calcular tus recursos comprometidos. En el caso de los recursos con picos, te recomendamos que uses las opciones de escalado automático de GKE. Entre estas opciones se incluye el escalador automático programado que se describe en este artículo u otras opciones gestionadas que se explican en Prácticas recomendadas para ejecutar aplicaciones de Kubernetes de coste optimizado en GKE.
Si ya tienes un contrato de uso comprometido por una cantidad determinada de recursos, no reducirás los costes si reduces el tamaño de tu clúster por debajo de ese mínimo. En estos casos, le recomendamos que intente programar algunas tareas para cubrir los huecos durante los periodos de baja demanda de computación.
Arquitectura
En el siguiente diagrama se muestra la arquitectura de la infraestructura y del escalador automático programado que implementará en este tutorial. El autoescalador programado consta de un conjunto de componentes que trabajan conjuntamente para gestionar el escalado según una programación.

En esta arquitectura, un conjunto de CronJobs de Kubernetes exporta información conocida sobre los patrones de tráfico a una métrica personalizada de Cloud Monitoring. Un autoescalador de pods horizontal (HPA) de Kubernetes lee estos datos como entrada para determinar cuándo debe escalar la carga de trabajo. Junto con otras métricas de carga, como el uso de CPU objetivo, el HPA decide cómo escalar las réplicas de un despliegue determinado.
Prepara tu entorno
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
En Cloud Shell, configura el ID de tu proyecto, tu dirección de correo electrónico y tu zona y región de computación: Google Cloud
PROJECT_ID=YOUR_PROJECT_ID ALERT_EMAIL=YOUR_EMAIL_ADDRESS gcloud config set project $PROJECT_ID gcloud config set compute/region us-central1 gcloud config set compute/zone us-central1-fHaz los cambios siguientes:
YOUR_PROJECT_ID: el nombre del proyecto Google Cloud del proyecto que estás usando.YOUR_EMAIL_ADDRESS: una dirección de correo electrónico para recibir notificaciones cuando el escalador automático programado no funcione correctamente.
Si quieres, puedes elegir otra región y zona para este tutorial.
Clona el repositorio de GitHub
kubernetes-engine-samples:git clone https://github.com/GoogleCloudPlatform/kubernetes-engine-samples/ cd kubernetes-engine-samples/cost-optimization/gke-scheduled-autoscalerEl código de este ejemplo se estructura en las siguientes carpetas:
- Raíz: contiene el código que usan los CronJobs para exportar métricas personalizadas a Cloud Monitoring.
k8s/: contiene un ejemplo de implementación que tiene un HPA de Kubernetes.k8s/scheduled-autoscaler/: contiene los CronJobs que exportan una métrica personalizada y una versión actualizada del HPA para leer una métrica personalizada.k8s/load-generator/: contiene un despliegue de Kubernetes que tiene una aplicación para simular el uso por horas. Un Deployment es un objeto de la API de Kubernetes que te permite ejecutar varias réplicas de pods distribuidas entre los nodos de un clúster.monitoring/: contiene los componentes de Cloud Monitoring que configurarás en este tutorial.
En Cloud Shell, crea un clúster de GKE para ejecutar el escalador automático programado:
gcloud container clusters create scheduled-autoscaler \ --enable-ip-alias \ --release-channel=stable \ --machine-type=e2-standard-2 \ --enable-autoscaling --min-nodes=1 --max-nodes=10 \ --num-nodes=1 \ --autoscaling-profile=optimize-utilizationEl resultado debería ser similar al siguiente:
NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS scheduled-autoscaler us-central1-f 1.22.15-gke.100 34.69.187.253 e2-standard-2 1.22.15-gke.100 1 RUNNINGNo es una configuración de producción, pero es adecuada para este tutorial. En esta configuración, se define el autoescalador de clústeres con un mínimo de 1 nodo y un máximo de 10 nodos. También puedes habilitar el perfil
optimize-utilizationpara acelerar el proceso de reducción.Despliega la aplicación de ejemplo sin el escalador automático programado:
kubectl apply -f ./k8sAbre el archivo
k8s/hpa-example.yaml.En la siguiente lista se muestra el contenido del archivo.
Ten en cuenta que el número mínimo de réplicas (
minReplicas) es 10. Esta configuración también define que el clúster se escale en función del uso de la CPU (los ajustesname: cpuytype: Utilization).Espera a que la aplicación esté disponible:
kubectl wait --for=condition=available --timeout=600s deployment/php-apache EXTERNAL_IP='' while [ -z $EXTERNAL_IP ] do EXTERNAL_IP=$(kubectl get svc php-apache -o jsonpath={.status.loadBalancer.ingress[0].ip}) [ -z $EXTERNAL_IP ] && sleep 10 done curl -w '\n' http://$EXTERNAL_IPCuando la aplicación está disponible, el resultado es el siguiente:
OK!Verifica los ajustes:
kubectl get hpa php-apacheEl resultado debería ser similar al siguiente:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE php-apache Deployment/php-apache 9%/60% 10 20 10 6d19hEn la columna
REPLICASse muestra10, que coincide con el valor del campominReplicasdel archivohpa-example.yaml.Comprueba si el número de nodos ha aumentado a 4:
kubectl get nodesEl resultado debería ser similar al siguiente:
NAME STATUS ROLES AGE VERSION gke-scheduled-autoscaler-default-pool-64c02c0b-9kbt Ready <none> 21S v1.17.9-gke.1504 gke-scheduled-autoscaler-default-pool-64c02c0b-ghfr Ready <none> 21s v1.17.9-gke.1504 gke-scheduled-autoscaler-default-pool-64c02c0b-gvl9 Ready <none> 21s v1.17.9-gke.1504 gke-scheduled-autoscaler-default-pool-64c02c0b-t9sr Ready <none> 21s v1.17.9-gke.1504Cuando creaste el clúster, definiste una configuración mínima con la marca
min-nodes=1. Sin embargo, la aplicación que has implementado al principio de este procedimiento solicita más infraestructura porqueminReplicasen el archivohpa-example.yamlse ha definido en 10.Asignar a
minReplicasun valor como 10 es una estrategia habitual que utilizan empresas como los comercios, que esperan un aumento repentino del tráfico en las primeras horas del día hábil. Sin embargo, si asigna valores altos aminReplicasde HPA, puede que sus costes aumenten, ya que el clúster no se puede reducir, ni siquiera por la noche, cuando el tráfico de la aplicación es bajo.En Cloud Shell, instala el adaptador de métricas personalizadas de Cloud Monitoring en tu clúster de GKE:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yaml kubectl wait --for=condition=available --timeout=600s deployment/custom-metrics-stackdriver-adapter -n custom-metricsEste adaptador permite el autoescalado de pods basado en métricas personalizadas de Cloud Monitoring.
Crea un repositorio en Artifact Registry y asigna permisos de lectura:
gcloud artifacts repositories create gke-scheduled-autoscaler \ --repository-format=docker --location=us-central1 gcloud auth configure-docker us-central1-docker.pkg.dev gcloud artifacts repositories add-iam-policy-binding gke-scheduled-autoscaler \ --location=us-central1 --member=allUsers --role=roles/artifactregistry.readerCompila e inserta el código del exportador de métricas personalizadas:
docker build -t us-central1-docker.pkg.dev/$PROJECT_ID/gke-scheduled-autoscaler/custom-metric-exporter . docker push us-central1-docker.pkg.dev/$PROJECT_ID/gke-scheduled-autoscaler/custom-metric-exporterDespliega los CronJobs que exportan métricas personalizadas y la versión actualizada del HPA que lee estas métricas personalizadas:
sed -i.bak s/PROJECT_ID/$PROJECT_ID/g ./k8s/scheduled-autoscaler/scheduled-autoscale-example.yaml kubectl apply -f ./k8s/scheduled-autoscalerAbre y examina el archivo
k8s/scheduled-autoscaler/scheduled-autoscale-example.yaml.En la siguiente lista se muestra el contenido del archivo.
Esta configuración especifica que los CronJobs deben exportar el número de réplicas de Pod sugerido a una métrica personalizada llamada
custom.googleapis.com/scheduled_autoscaler_exampleen función de la hora del día. Para facilitar la sección de monitorización de este tutorial, la configuración del campo schedule define aumentos y reducciones de escala por horas. En el entorno de producción, puedes personalizar esta programación para que se ajuste a las necesidades de tu empresa.Abre y examina el archivo
k8s/scheduled-autoscaler/hpa-example.yaml.En la siguiente lista se muestra el contenido del archivo.
Esta configuración especifica que el objeto HPA debe sustituir al HPA que se implementó anteriormente. Ten en cuenta que la configuración reduce el valor de
minReplicasa 1. Esto significa que la carga de trabajo se puede reducir a su mínimo. La configuración también añade una métrica externa (type: External). Esto significa que el autoescalado ahora se activa por dos factores.En este caso, el HPA calcula un número de réplicas propuesto para cada métrica y, a continuación, elige la métrica que devuelve el valor más alto. Es importante que lo tengas en cuenta: el escalador automático programado puede proponer que, en un momento dado, el número de pods sea 1. Sin embargo, si la utilización real de la CPU es superior a la esperada en un pod, el HPA crea más réplicas.
Vuelve a comprobar el número de nodos y réplicas de HPA ejecutando de nuevo cada uno de estos comandos:
kubectl get nodes kubectl get hpa php-apacheEl resultado que ve depende de lo que haya hecho el escalador automático programado recientemente. En concreto, los valores de
minReplicasynodesserán diferentes en distintos puntos del ciclo de escalado.Por ejemplo, aproximadamente entre los minutos 51 y 60 de cada hora (que representa un periodo de tráfico máximo), el valor de HPA de
minReplicasserá 10 y el valor denodesserá 4.Por el contrario, de los minutos 1 al 50 (que representa un periodo de menor tráfico), el valor de
minReplicasdel HPA será 1 y el valor denodesserá 1 o 2, en función de cuántos pods se hayan asignado y eliminado. En el caso de los valores más bajos (del minuto 1 al 50), el clúster puede tardar hasta 10 minutos en reducirse.En Cloud Shell, crea un canal de notificaciones:
gcloud beta monitoring channels create \ --display-name="Scheduled Autoscaler team (Primary)" \ --description="Primary contact method for the Scheduled Autoscaler team lead" \ --type=email \ --channel-labels=email_address=${ALERT_EMAIL}El resultado debería ser similar al siguiente:
Created notification channel NOTIFICATION_CHANNEL_ID.Este comando crea un canal de notificaciones de tipo
emailpara simplificar los pasos del tutorial. En entornos de producción, te recomendamos que uses una estrategia menos asíncrona configurando el canal de notificaciones comosmsopagerduty.Define una variable que tenga el valor que se ha mostrado en el marcador de posición
NOTIFICATION_CHANNEL_ID:NOTIFICATION_CHANNEL_ID=NOTIFICATION_CHANNEL_IDImplementa la política de alertas:
gcloud alpha monitoring policies create \ --policy-from-file=./monitoring/alert-policy.yaml \ --notification-channels=$NOTIFICATION_CHANNEL_IDEl archivo
alert-policy.yamlcontiene la especificación para enviar una alerta si la métrica no está presente después de cinco minutos.Ve a la página Alertas de Cloud Monitoring para ver la política de alertas.
Haz clic en Política de escalado automático programada y verifica los detalles de la política de alertas.
En Cloud Shell, implementa el generador de carga:
kubectl apply -f ./k8s/load-generatorEn la siguiente lista se muestra la secuencia de comandos
load-generator:command: ["/bin/sh", "-c"] args: - while true; do RESP=$(wget -q -O- http://php-apache.default.svc.cluster.local); echo "$(date +%H)=$RESP"; sleep $(date +%H | awk '{ print "s("$0"/3*a(1))*0.5+0.5" }' | bc -l); done;Este script se ejecuta en tu clúster hasta que eliminas la
load-generatorimplementación. Envía solicitudes a tu serviciophp-apachecada pocos milisegundos. El comandosleepsimula los cambios en la distribución de la carga durante el día. Si usas una secuencia de comandos que genere tráfico de esta forma, podrás saber qué ocurre cuando combinas la utilización de la CPU y las métricas personalizadas en tu configuración de HPA.En Cloud Shell, crea un panel de control:
gcloud monitoring dashboards create \ --config-from-file=./monitoring/dashboard.yamlVe a la página Paneles de Cloud Monitoring:
Haz clic en Panel de control de escalador automático programado.
El panel de control muestra tres gráficos. Debes esperar al menos 2 horas (lo ideal es 24 horas o más) para ver la dinámica de los aumentos y las reducciones de escala, así como para ver cómo afecta al escalado automático la distribución de la carga a lo largo del día.
Para que te hagas una idea de lo que muestran los gráficos, puedes consultar los siguientes, que presentan una vista de todo el día:
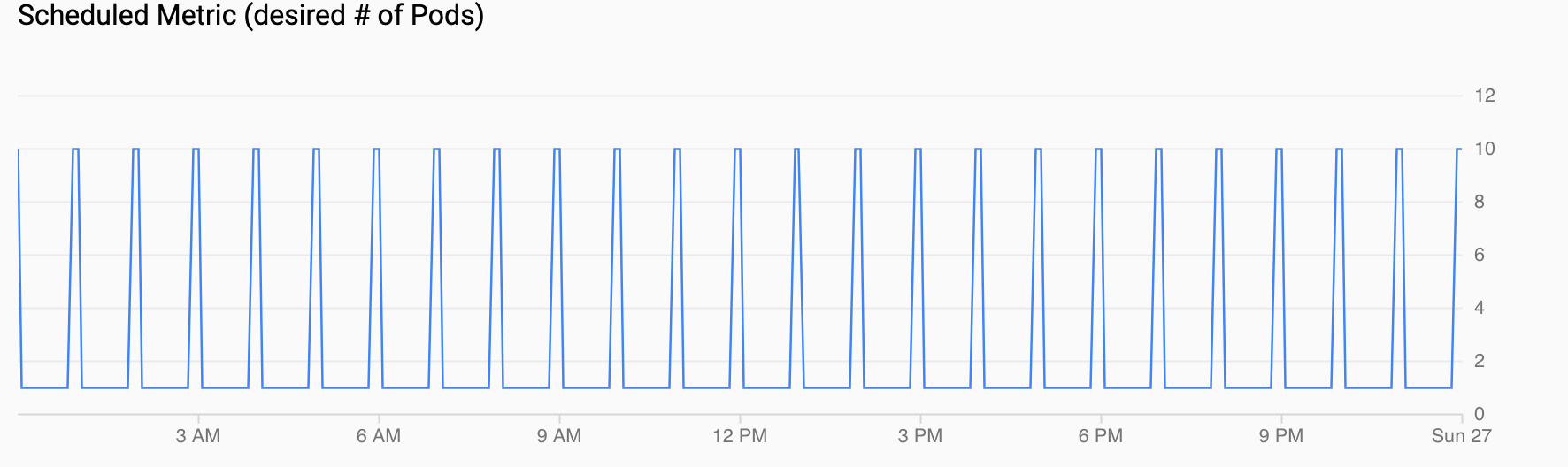
Métrica programada (número de pods deseado): muestra una serie temporal de la métrica personalizada que se exporta a Cloud Monitoring a través de los CronJobs que has configurado en Configurar un escalador automático programado.
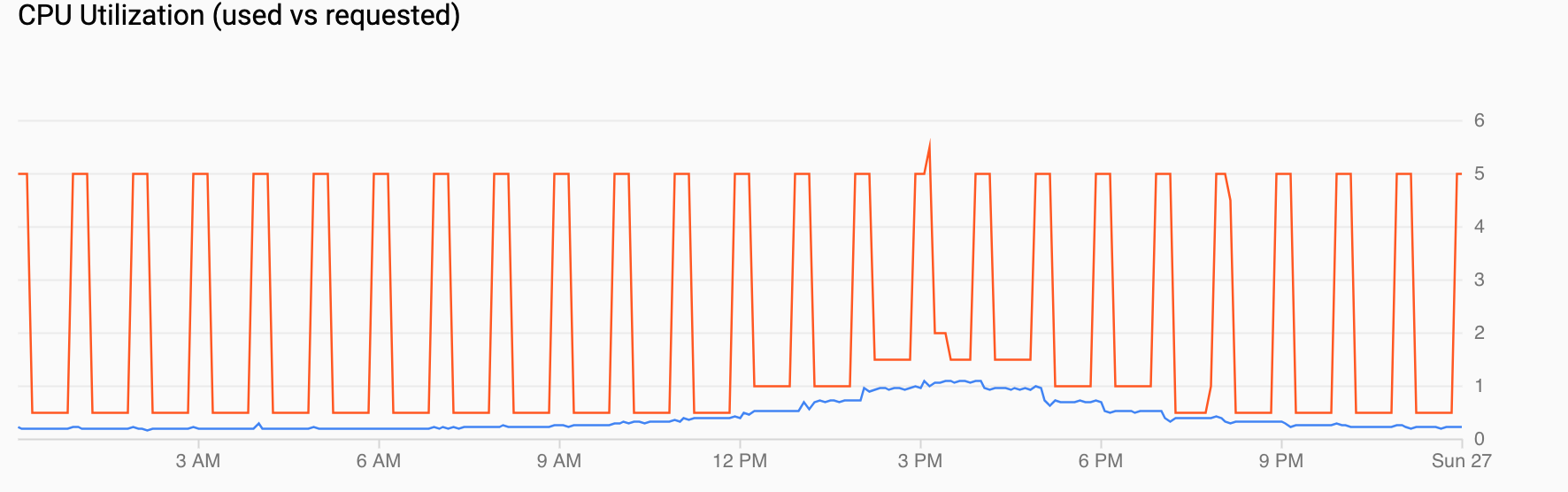
Uso de CPU (solicitada frente a usada) muestra una serie temporal de la CPU solicitada (rojo) y el uso real de la CPU (azul). Cuando la carga es baja, el HPA respeta la decisión de utilización de la herramienta de escalado automático programada. Sin embargo, cuando aumenta el tráfico, el HPA incrementa el número de pods según sea necesario, como se puede ver en los puntos de datos entre las 12:00 y las 18:00.
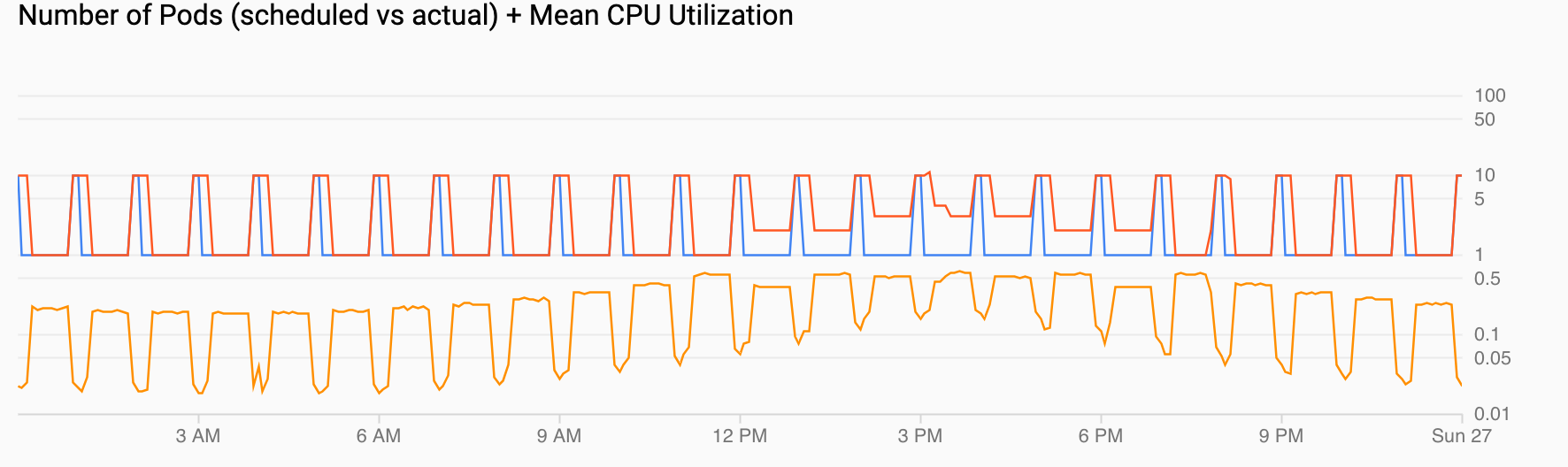
Número de pods (programados frente a reales) + Uso medio de CPU muestra una vista similar a las anteriores. El recuento de pods (rojo) aumenta a 10 cada hora según lo programado (azul). El número de pods aumenta y disminuye de forma natural con el tiempo en respuesta a la carga (12:00 y 18:00). La utilización media de la CPU (naranja) se mantiene por debajo del objetivo que has definido (60%).
Crea el clúster de GKE.
Desplegar la aplicación de ejemplo
Configurar una herramienta de ajuste automático programada
Configurar alertas para cuando el escalador automático programado no funcione correctamente
En un entorno de producción, normalmente querrá saber cuándo los CronJobs no rellenan la métrica personalizada. Para ello, puedes crear una alerta que se active cuando falte cualquier flujo custom.googleapis.com/scheduled_autoscaler_example durante un periodo de cinco minutos.
Generar carga en la aplicación de ejemplo
Visualizar el escalado en respuesta al tráfico o a las métricas programadas
En esta sección, se revisan las visualizaciones que muestran los efectos de aumentar y reducir la escala.