
בעיות באיזון העומסים ב-Google Kubernetes Engine (GKE) עלולות לגרום לשיבושים בשירות, כמו שגיאות HTTP 502, או למנוע גישה לאפליקציות.
במאמר הזה מוסבר איך לפתור שגיאות 502 מ-Ingress חיצוני, ואיך להשתמש ביומנים של איזון עומסים ובכלי אבחון, כמו check-gke-ingress, כדי לזהות בעיות.
המידע הזה חשוב לאדמינים ולמפעילים של פלטפורמות ולמפתחי אפליקציות שמגדירים ותחזקים שירותים עם איזון עומסים ב-GKE. מידע נוסף על התפקידים הנפוצים ועל דוגמאות למשימות שאנחנו מתייחסים אליהן בתוכן של Google Cloud זמין במאמר תפקידי משתמשים נפוצים ומשימות ב-GKE.
לא נמצא BackendConfig
השגיאה הזו מתרחשת כשמציינים BackendConfig ליציאת שירות בהערת השירות, אבל לא ניתן למצוא את משאב ה-BackendConfig בפועל.
כדי להעריך אירוע ב-Kubernetes, מריצים את הפקודה הבאה:
kubectl get event
הפלט הבא לדוגמה מציין שלא נמצא BackendConfig:
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: error getting BackendConfig for port 80 on service "default/my-service":
no BackendConfig for service port exists
כדי לפתור את הבעיה, צריך לוודא שלא יצרתם את משאב BackendConfig במרחב השמות הלא נכון, או שכתבתם את ההפניה שלו בצורה שגויה בהערת השירות.
לא נמצאה מדיניות אבטחה של Ingress
אחרי שיוצרים את אובייקט ה-Ingress, אם מדיניות האבטחה לא משויכת כמו שצריך לשירות LoadBalancer, צריך להעריך את אירוע Kubernetes כדי לראות אם יש טעות בהגדרה. אם ב-BackendConfig מוגדרת מדיניות אבטחה שלא קיימת, אירוע אזהרה מופק מעת לעת.
כדי להעריך אירוע ב-Kubernetes, מריצים את הפקודה הבאה:
kubectl get event
הפלט הבא לדוגמה מציין שמדיניות האבטחה לא נמצאה:
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: The given security policy "my-policy" does not exist.
כדי לפתור את הבעיה, צריך לציין את השם הנכון של מדיניות האבטחה ב-BackendConfig.
פתרון שגיאות מסדרה 500 באמצעות NEGs במהלך שינוי קנה מידה של עומסי עבודה ב-GKE
תסמין:
כשמשתמשים ב-NEGs שמוקצים על ידי GKE לצורך איזון עומסים, יכול להיות שיופיעו שגיאות 502 או 503 בשירותים במהלך הקטנת עומס העבודה. 502 שגיאות מתרחשות כאשר תרמילים מסתיימים לפני שחיבורים קיימים נסגרים, בעוד שגיאות 503 מתרחשות כאשר התנועה מופנית לתרמילים שנמחקו.
הבעיה הזו יכולה להשפיע על אשכולות אם אתם משתמשים במוצרים של GKE לניהול איזון עומסים שמשתמשים ב-NEGs, כולל Gateway, Ingress ו-NEGs עצמאיים. אם אתם משנים את גודל עומסי העבודה לעיתים קרובות, הסיכון שהאשכול יושפע גבוה יותר.
אבחון:
הסרה של Pod ב-Kubernetes בלי לנקז את נקודת הקצה שלו ולהסיר אותו קודם מ-NEG מובילה לשגיאות מסדרה 500. כדי להימנע מבעיות במהלך סיום הפעולה של ה-Pod, צריך לשים לב לסדר הפעולות. בתמונות הבאות מוצגים תרחישים שבהם BackendService Drain Timeout לא מוגדר ו-BackendService Drain Timeout מוגדר עם BackendConfig.
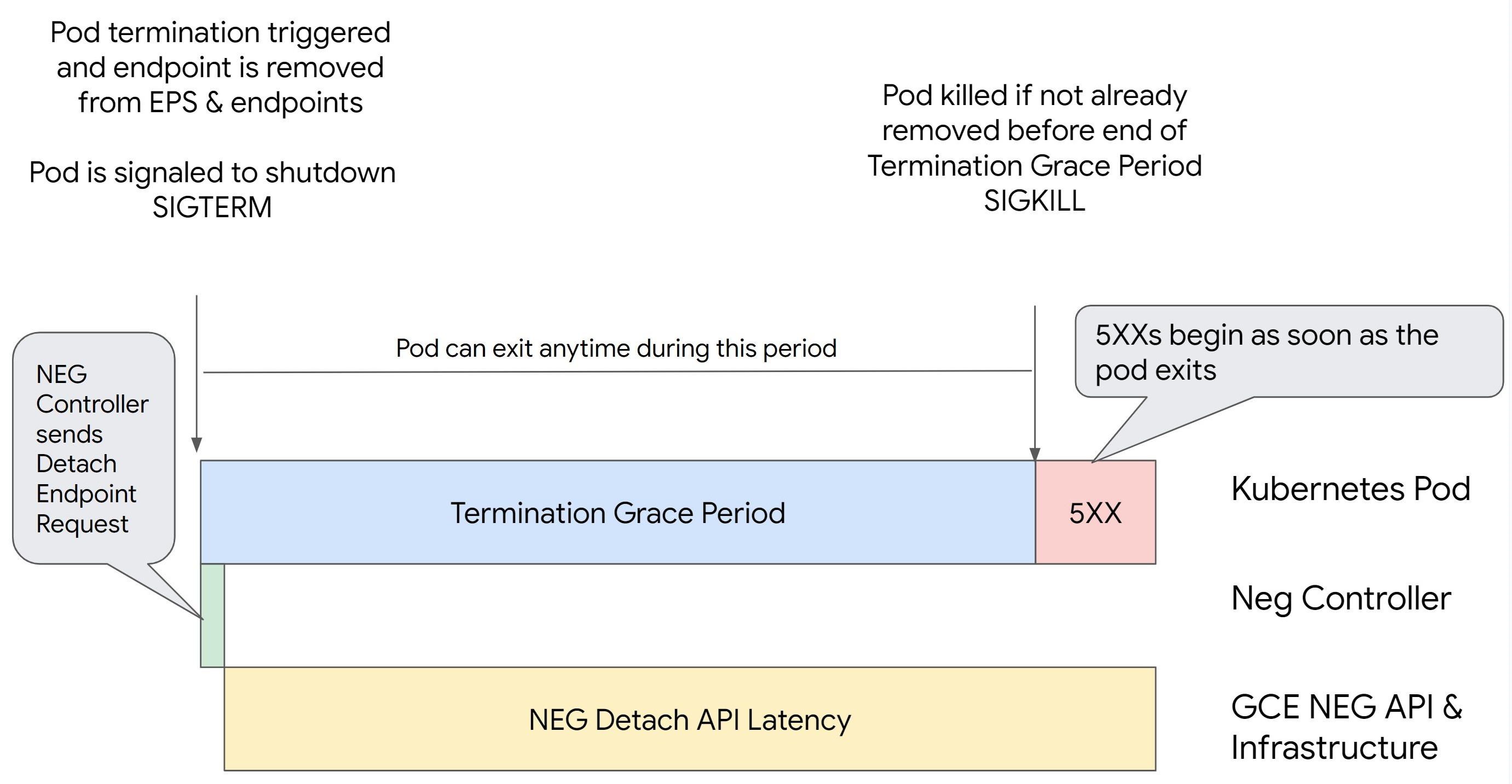
תרחיש 1: הערך של BackendService Drain Timeout לא מוגדר.
בתמונה הבאה מוצג תרחיש שבו הערך של BackendService Drain Timeout לא מוגדר.
תרחיש 2: הערך BackendService Drain Timeout מוגדר.
בתמונה הבאה מוצג תרחיש שבו הערך BackendService Drain Timeout מוגדר.
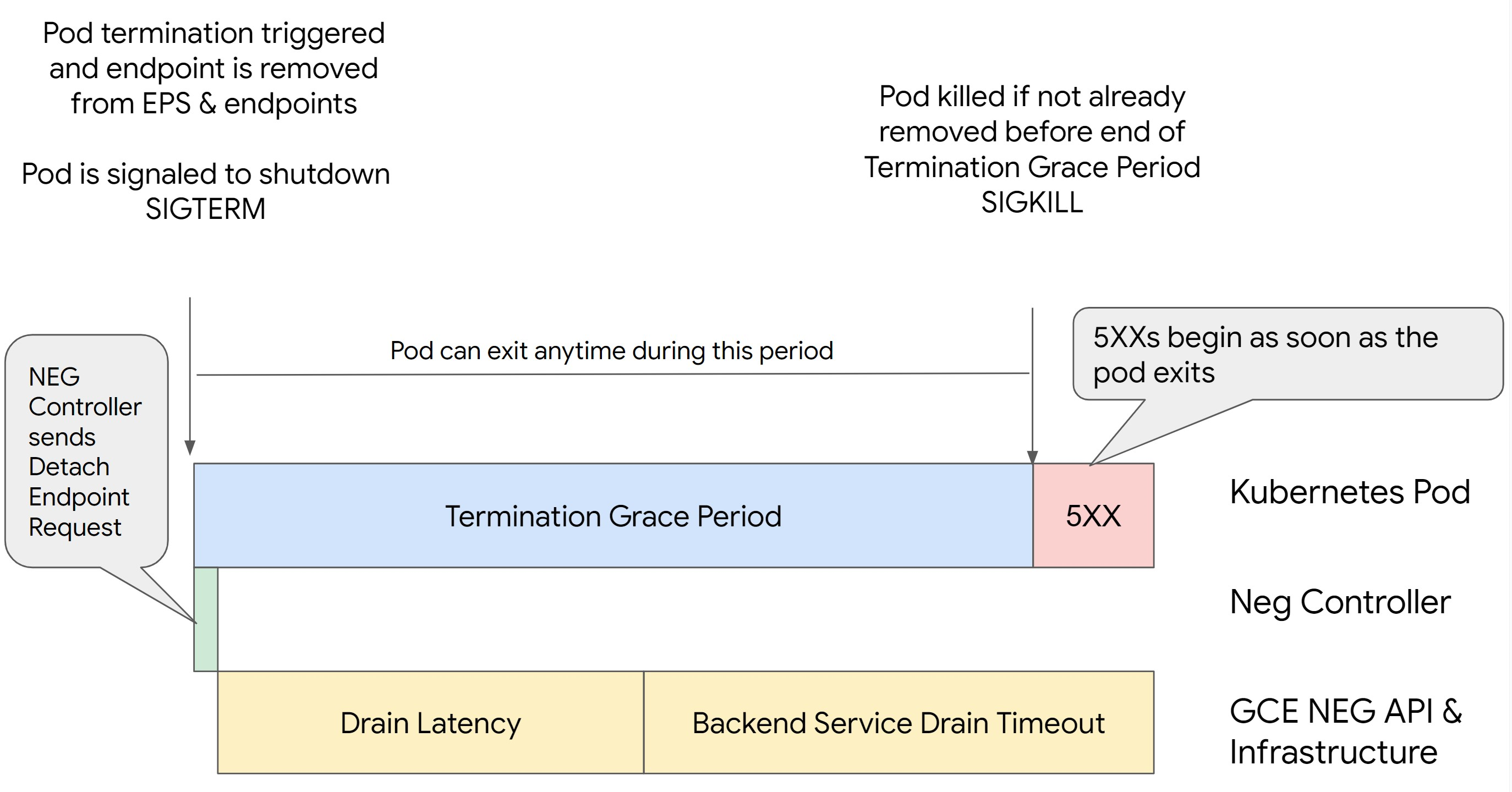
הזמן המדויק שבו מתרחשות השגיאות מסדרה 500 תלוי בגורמים הבאים:
השהיית הניתוק של NEG API: ההשהיה של הניתוק של NEG API מייצגת את הזמן הנוכחי שנדרש לסיום פעולת הניתוק ב- Google Cloud. ההחלטה הזו מושפעת ממגוון גורמים מחוץ ל-Kubernetes, כולל סוג מאזן העומסים והאזור הספציפי.
חביון של ניתוב תעבורה: חביון של ניתוב תעבורה הוא הזמן שנדרש למאזן העומסים כדי להתחיל להפנות את התעבורה מחלק מסוים במערכת. אחרי שמפעילים את הניקוז, מאזן העומסים מפסיק לשלוח בקשות חדשות לנקודת הקצה, אבל עדיין יש השהיה בהפעלת הניקוז (השהיית הניקוז) שיכולה לגרום לשגיאות זמניות מסוג 503 אם ה-Pod כבר לא קיים.
הגדרת בדיקת התקינות: ספי בדיקת תקינות רגישים יותר מקצרים את משך השגיאות מסוג 503, כי הם יכולים לאותת למאזן העומסים להפסיק לשלוח בקשות לנקודות קצה גם אם פעולת הניתוק לא הסתיימה.
תקופת חסד לסיום: תקופת החסד לסיום קובעת את משך הזמן המקסימלי שמוקצה ל-Pod כדי לצאת. עם זאת, אפשר לצאת מ-Pod לפני שתקופת החסד לסיום המינוי מסתיימת. אם הפוד פועל יותר מהזמן הזה, הוא נאלץ לצאת בסוף התקופה. זו הגדרה ב-Pod שצריך להגדיר בהגדרת עומס העבודה.
פתרון אפשרי:
כדי למנוע את שגיאות 5XX, צריך להחיל את ההגדרות הבאות. ערכי הזמן הקצוב לתפוגה הם בגדר הצעה, ויכול להיות שתצטרכו להתאים אותם לאפליקציה הספציפית שלכם. בקטע הבא מפורט תהליך ההתאמה האישית.
בתמונה הבאה אפשר לראות איך משאירים את ה-Pod פעיל באמצעות hook של preStop:
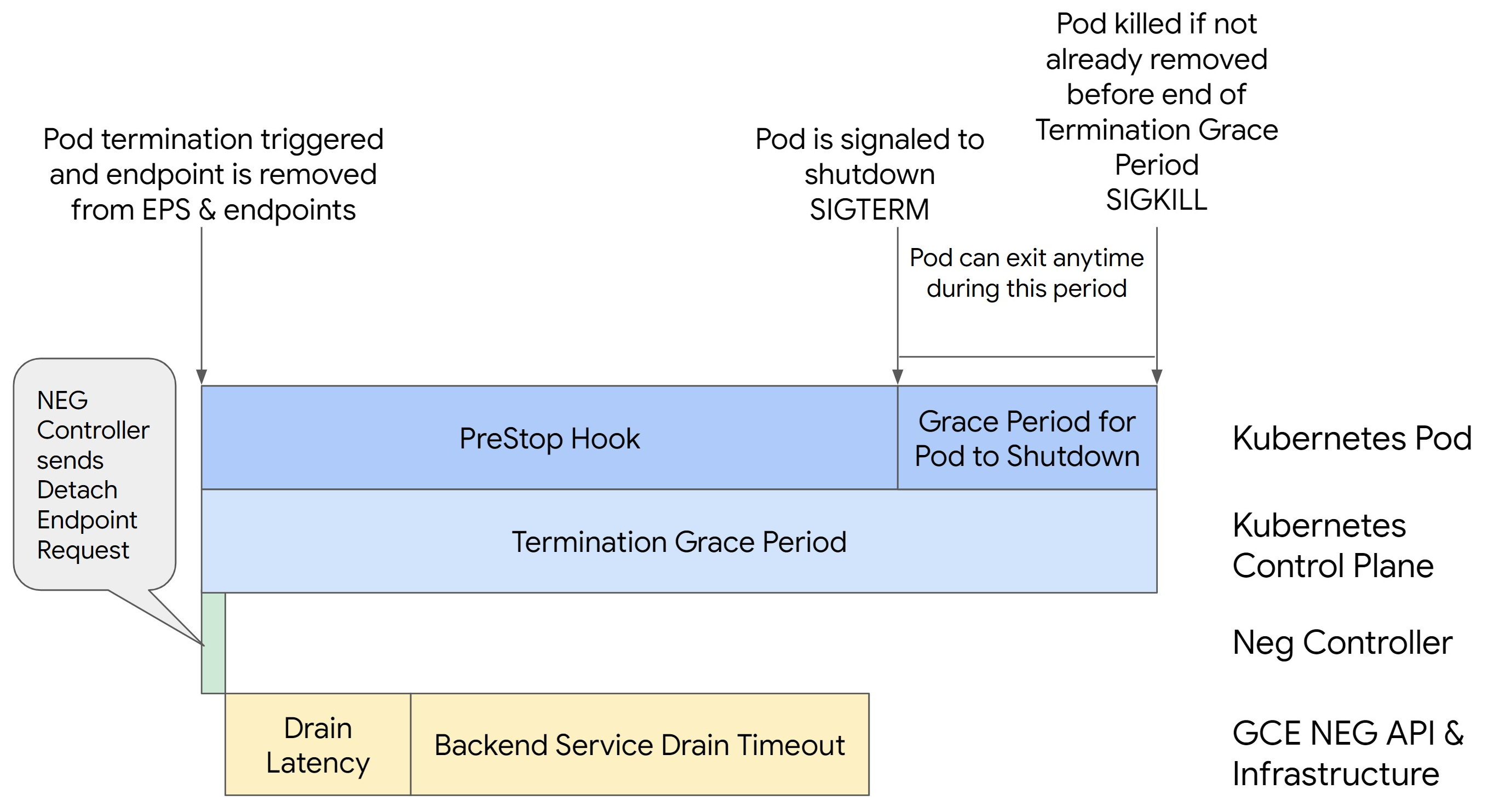
כדי להימנע משגיאות מסדרה 500, מבצעים את השלבים הבאים:
מגדירים את
BackendService Drain Timeoutשל השירות לדקה אחת.משתמשי Ingress יכולים לעיין במאמר הגדרת פסק זמן ב-BackendConfig.
משתמשי Gateway יכולים לקרוא על הגדרת פסק הזמן ב-GCPBackendPolicy.
אם אתם מנהלים את BackendServices ישירות כשאתם משתמשים ב-Standalone NEGs, תוכלו לעיין במאמר בנושא הגדרת זמן קצוב לתפוגה ישירות ב-Backend Service.
מאריכים את
terminationGracePeriodב-Pod.מגדירים את
terminationGracePeriodSecondsב-Pod ל-3.5 דקות. בשילוב עם ההגדרות המומלצות, ההגדרה הזו מאפשרת ל-Pods חלון של 30 עד 45 שניות לכיבוי מסודר אחרי שנקודת הקצה של ה-Pod הוסרה מ-NEG. אם אתם צריכים יותר זמן לסגירה מסודרת, אתם יכולים להאריך את תקופת החסד או לפעול לפי ההוראות שמפורטות בקטע התאמה אישית של פסק זמן.במניפסט של ה-Pod הבא מוגדר זמן קצוב לתפוגה של 210 שניות (3.5 דקות) לריקון החיבורים:
spec: terminationGracePeriodSeconds: 210 containers: - name: my-app ... ...החלת וו (hook) של
preStopעל כל מאגרי התגים.החלת וו
preStopשיבטיח שה-Pod יפעל למשך 120 שניות נוספות בזמן שנקודת הקצה של ה-Pod מתרוקנת במאזן העומסים ונקודת הקצה מוסרת מ-NEG.spec: containers: - name: my-app ... lifecycle: preStop: exec: command: ["/bin/sh", "-c", "sleep 120s"] ...
התאמה אישית של פסק זמן
כדי להבטיח את המשכיות של ה-Pod ולמנוע שגיאות מסדרה 500, ה-Pod צריך להיות פעיל עד להסרת נקודת הקצה מה-NEG. כדי למנוע שגיאות 502 ו-503, מומלץ להטמיע שילוב של פסק זמן ו-preStop hook.
כדי להאריך את משך הפעולה של ה-Pod במהלך תהליך ההשבתה, מוסיפים ל-Pod preStop hook. ה-hook preStop מופעל לפני שמתקבל אות ליציאה מ-Pod, כך שאפשר להשתמש ב-hook preStop כדי לשמור על פעילות ה-Pod עד שהנקודה המתאימה שלו מוסרת מ-NEG.
כדי להאריך את משך הזמן שבו ה-Pod נשאר פעיל במהלך תהליך ההשבתה, מוסיפים וו (hook) של preStop להגדרת ה-Pod באופן הבא:
spec:
containers:
- name: my-app
...
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep <latency time>"]
אתם יכולים להגדיר פסק זמן והגדרות קשורות כדי לנהל את ההשבתה המבוקרת של יחידות Pod במהלך צמצום של עומסי עבודה. אפשר לשנות את הגדרות הזמן הקצוב לתפוגה בהתאם לתרחישי שימוש ספציפיים. מומלץ להתחיל עם פסק זמן ארוך יותר ולקצר את משך הזמן לפי הצורך. אפשר להתאים אישית את פסק הזמן על ידי הגדרת פרמטרים שקשורים לפסק הזמן וה-hook preStop באחת מהדרכים הבאות:
זמן קצוב לתפוגה של ניקוז שירות לקצה העורפי
הפרמטר Backend Service Drain Timeout לא מוגדר כברירת מחדל ואין לו השפעה. אם מגדירים את הפרמטר Backend Service Drain Timeout ומפעילים אותו, מאזן העומסים מפסיק להפנות בקשות חדשות לנקודת הקצה וממתין עד שתוקף הזמן הקצוב לתפוגה יפוג לפני שהוא מסיים את החיבורים הקיימים.
אפשר להגדיר את הפרמטר Backend Service Drain Timeout באמצעות BackendConfig עם Ingress, GCPBackendPolicy עם Gateway או באופן ידני ב-BackendService עם NEGs עצמאיים. הזמן הקצוב לתפוגה צריך להיות ארוך פי 1.5 עד 2 מהזמן שנדרש לעיבוד הבקשה. כך אפשר לוודא שאם תתקבל בקשה רגע לפני הפעלת הניקוי, היא תושלם לפני שתגיע לסיום הזמן הקצוב לתפוגה. הגדרת הפרמטר Backend Service Drain Timeout לערך שגדול מ-0 עוזרת לצמצם את מספר השגיאות 503, כי לא נשלחות בקשות חדשות לנקודות קצה שמתוכננות להסרה. כדי שההגדרה הזו של הזמן הקצוב לתפוגה תהיה יעילה, צריך להשתמש בה עם ה-hook preStop כדי לוודא שה-Pod יישאר פעיל בזמן הניקוז. בלי השילוב הזה, בקשות קיימות שלא הושלמו יקבלו שגיאת 502.
preStop זמן הצפייה ברגע המושך
ה-hook preStop צריך לעכב את השבתת ה-Pod מספיק זמן כדי לאפשר את השלמת זמן האחזור של הניקוז ואת פסק הזמן של ניקוז שירות ה-Backend, וכך לוודא שמתבצע ניקוז תקין של החיבורים והסרת נקודת הקצה מה-NEG לפני השבתת ה-Pod.
כדי לקבל תוצאות אופטימליות, צריך לוודא שpreStop זמן ההפעלה של ה-hook גדול או שווה לסכום של Backend Service Drain Timeout ושל זמן האחזור של הניקוז.
כדי לחשב את זמן ההפעלה האידיאלי של ה-hook, משתמשים בנוסחה הבאה:preStop
preStop hook execution time >= BACKEND_SERVICE_DRAIN_TIMEOUT + DRAIN_LATENCY
מחליפים את מה שכתוב בשדות הבאים:
-
BACKEND_SERVICE_DRAIN_TIMEOUT: השעה שהגדרתם לBackend Service Drain Timeout. -
DRAIN_LATENCY: זמן משוער של השהיית הניקוז. מומלץ להשתמש בדקה אחת כאומדן.
אם שגיאות 500 נמשכות, צריך להעריך את משך ההתרחשות הכולל ולהוסיף את הזמן הזה כפול 2 לזמן האחזור המשוער של הניקוז. כך מוודאים שיש ל-Pod מספיק זמן להתרוקן בצורה מסודרת לפני שהוא מוסר מהשירות. אתם יכולים לשנות את הערך הזה אם הוא ארוך מדי לתרחיש השימוש הספציפי שלכם.
לחלופין, אפשר להעריך את התזמון על ידי בדיקת חותמת הזמן של המחיקה מה-Pod וחותמת הזמן שבה נקודת הקצה הוסרה מה-NEG ביומני הביקורת של Cloud.
פרמטר של תקופת חסד לסיום
צריך להגדיר את הפרמטר terminationGracePeriod כך שיהיה מספיק זמן לסיום של ה-hook preStop ולסיום תקין של ה-Pod.
כברירת מחדל, אם לא מגדירים את הערך במפורש, הערך של terminationGracePeriod הוא 30 שניות.
אפשר לחשב את הערך האופטימלי של terminationGracePeriod באמצעות הנוסחה:
terminationGracePeriod >= preStop hook time + Pod shutdown time
כדי להגדיר את terminationGracePeriod בתצורת ה-Pod באופן הבא:
spec:
terminationGracePeriodSeconds: <terminationGracePeriod>
containers:
- name: my-app
...
...
לא נמצא NEG כשיוצרים משאב Internal Ingress
יכול להיות שתקבלו את השגיאה הבאה כשאתם יוצרים Ingress פנימי ב-GKE:
Error syncing: error running backend syncing routine: googleapi: Error 404: The resource 'projects/PROJECT_ID/zones/ZONE/networkEndpointGroups/NEG' was not found, notFound
השגיאה הזו מתרחשת כי Ingress עבור מאזני עומסים פנימיים של אפליקציות דורש קבוצות של נקודות קצה ברשת (NEGs) כבק-אנד.
בסביבות של VPC משותף או באשכולות שמופעלת בהם מדיניות רשת, מוסיפים את ההערה cloud.google.com/neg: '{"ingress": true}' למניפסט של השירות.
504 Gateway Timeout: upstream request timeout
יכול להיות שתקבלו את השגיאה הבאה כשאתם ניגשים לשירות מ-Ingress פנימי ב-GKE:
HTTP/1.1 504 Gateway Timeout
content-length: 24
content-type: text/plain
upstream request timeout
השגיאה הזו מתרחשת כי תנועה שנשלחת אל מאזני עומסים פנימיים של אפליקציות מועברת דרך שרתי proxy של Envoy בטווח של רשת משנה רק ל-proxy.
כדי לאפשר תעבורה מטווח תת-הרשת של שרת proxy בלבד, יוצרים כלל חומת אש ב-targetPort של השירות.
שגיאה 400: ערך לא תקין בשדה 'resource.target'
יכול להיות שתקבלו את השגיאה הבאה כשאתם ניגשים לשירות מ-Ingress פנימי ב-GKE:
Error syncing:LB_NAME does not exist: googleapi: Error 400: Invalid value for field 'resource.target': 'https://www.googleapis.com/compute/v1/projects/PROJECT_NAME/regions/REGION_NAME/targetHttpProxies/LB_NAME. A reserved and active subnetwork is required in the same region and VPC as the forwarding rule.
כדי לפתור את הבעיה, צריך ליצור רשת משנה לשרת proxy בלבד.
שגיאה במהלך הסנכרון: שגיאה בהפעלת שגרת הסנכרון של מאזן העומסים: מאזן העומסים לא קיים
יכול להיות שתקבלו אחת מהשגיאות הבאות כשמישור הבקרה של GKE משודרג או כשמשנים אובייקט Ingress:
"Error during sync: error running load balancer syncing routine: loadbalancer
INGRESS_NAME does not exist: invalid ingress frontend configuration, please
check your usage of the 'kubernetes.io/ingress.allow-http' annotation."
או:
Error during sync: error running load balancer syncing routine: loadbalancer LOAD_BALANCER_NAME does not exist:
googleapi: Error 400: Invalid value for field 'resource.IPAddress':'INGRESS_VIP'. Specified IP address is in-use and would result in a conflict., invalid
כדי לפתור את הבעיות האלה, אפשר לנסות את השלבים הבאים:
- מוסיפים את השדה
hostsבקטעtlsשל מניפסט ה-Ingress, ואז מוחקים את ה-Ingress. ממתינים חמש דקות עד ש-GKE ימחק את משאבי ה-Ingress שלא נעשה בהם שימוש. לאחר מכן, יוצרים מחדש את ה-Ingress. מידע נוסף זמין במאמר השדה hosts של אובייקט Ingress. - מבטלים את השינויים שביצעתם ב-Ingress. לאחר מכן, מוסיפים אישור באמצעות הערה או סוד של Kubernetes.
תעבורת נתונים נכנסת (ingress) חיצונית יוצרת שגיאות HTTP 502
ההנחיות הבאות יעזרו לכם לפתור שגיאות HTTP 502 במשאבי Ingress חיצוניים:
- מפעילים יומנים לכל שירות לקצה העורפי שמשויך לכל שירות GKE שאליו יש הפניה ב-Ingress.
- כדי לזהות את הסיבות לתגובות HTTP 502, אפשר להשתמש בפרטי הסטטוס. פרטי הסטטוס שמציינים שתגובת HTTP 502 הגיעה מהקצה העורפי מחייבים פתרון בעיות ב-Pods של השרת, ולא במאזן העומסים.
קבוצות של מופעים לא מנוהלים
יכול להיות שתיתקלו בשגיאות HTTP 502 במשאבי Ingress חיצוניים אם משאבי Ingress החיצוניים משתמשים בבקאנד של קבוצת מופעים לא מנוהלת. הבעיה הזו מתרחשת אם כל התנאים הבאים מתקיימים:
- במאגר יש מספר גדול של צמתים בכל מאגרי הצמתים.
- ה-Pods של ההצגה של שירות אחד או יותר שמפנים אליהם ב-Ingress ממוקמים רק בכמה צמתים.
- השירותים שאליהם מתייחס ה-Ingress משתמשים ב-
externalTrafficPolicy: Local.
כדי לבדוק אם ה-Ingress החיצוני שלכם משתמש בשרתי קצה של קבוצת מופעים לא מנוהלת:
עוברים לדף Ingress במסוף Google Cloud .
לוחצים על השם של ה-Ingress החיצוני.
לוחצים על השם של מאזן העומסים. יוצג הדף Load balancing details.
כדי לדעת אם ה-Ingress החיצוני שלכם משתמש ב-NEGs או בקבוצות של מכונות וירטואליות, צריך לעיין בטבלה שבקטע Backend services.
כדי לפתור את הבעיה, אפשר לנסות אחד מהפתרונות הבאים:
- משתמשים באשכול שמותאם ל-VPC.
- משתמשים ב-
externalTrafficPolicy: Clusterלכל שירות שמפנים אליו ב-Ingress החיצוני. הפתרון הזה גורם לאיבוד כתובת ה-IP המקורית של הלקוח במקורות של החבילה. - משתמשים בהערה
node.kubernetes.io/exclude-from-external-load-balancers=true. מוסיפים את ההערה לצמתים או למאגרי הצמתים שלא מריצים אף Pod של שרת לאף שירות שמקושר ל-Ingress חיצוני או ל-LoadBalancerService באשכול.
הגדרת רישום ביומן של מאזן עומסים בשכבה 4
בקטע הזה מופיע מידע לפתרון בעיות אם הפעלתם רישום ביומן למאזן עומסי רשת חיצוני להעברת סיגנל ללא שינוי או למאזן עומסי רשת פנימי להעברת סיגנל ללא שינוי.
מעקב אחרי הסטטוס של הגדרת הרישום ביומן
בקר GKE L4LB מספק משוב על סטטוס ההתאמה של הרישום ביומן באמצעות הסוג status.conditions של השירות. כדי לבדוק את הסטטוס הזה, מריצים את הפקודה הבאה:
kubectl get svc SERVICE_NAME -o yaml
מחליפים את מה שכתוב בשדות הבאים:
-
SERVICE_NAME: שם האשכול.
בפלט, מחפשים את LoggingConfigManaged סוג התנאי. הטבלה הבאה מתארת את הסיבות האפשריות לתנאי:
| סטטוס התנאי | סיבה | תיאור |
|---|---|---|
| נכון | לאחר התאמות | הבקרה אוכפת באופן פעיל את הגדרות הרישום ביומן שמוגדרות ב-CRD של L4LBConfig. |
| לא נכון | לא מנוהל | הקטע logging חסר ב-CRD של L4LBConfig, או שההערה הוסרה. הבקר הפסיק את הניהול ועזב את שירות הקצה העורפי במצב האחרון הידוע שלו. |
| לא נכון | חסר | לא ניתן למצוא את המשאב L4LBConfig שאליו מתבצעת הפניה בהערת השירות. |
| לא נכון | לא חוקי | המשאב L4LBConfig נכשל באימות הצולב של הפרמטר optionalFields. |
| לא נכון | שגיאה | אירעה שגיאה במהלך ההתאמה של שירות הקצה העורפי. |
הסבר על התנהגות השיוט
אם ההערה networking.gke.io/l4lb-config מוסרת ממניפסט השירות, או אם משאב L4LBConfig שאליו מתבצעת הפניה נמחק, ההגדרה עוברת למצב Coast.
במצב הזה, בקר GKE מפסיק לנהל את הגדרות הרישום ביומן, אבל לא מאפס את שירות ה-Backend של Google Cloud להגדרות ברירת המחדל שלו. במקום זאת, שירות לקצה העורפי נשאר במצב האחרון שהיה תקין. בדרך כלל, אירוע אזהרה מונפק כדי להודיע לכם ש-Kubernetes כבר לא שולט בתצורה.
שימוש ביומנים של מאזן העומסים לפתרון בעיות
אתם יכולים להשתמש ביומני מאזן עומסי רשת פנימי להעברת סיגנל ללא שינוי וביומני מאזן עומסי רשת חיצוני להעברת סיגנל ללא שינוי כדי לפתור בעיות במאזני עומסים ולבצע קורלציה בין התנועה ממאזני העומסים לבין משאבי GKE.
היומנים מצטברים לפי חיבור ומיוצאים כמעט בזמן אמת. יומנים נוצרים לכל צומת GKE שמעורב בנתיב הנתונים של שירות LoadBalancer, גם לתעבורת נתונים נכנסת וגם לתעבורת נתונים יוצאת. הרשומות ביומן כוללות שדות נוספים למשאבי GKE, כמו:
- שם האשכול
- מיקום האשכול
- שם השירות
- מרחב השמות של השירות
- שם ה-Pod
- מרחב השמות של ה-Pod
תמחור
אין חיובים נוספים על שימוש ביומנים. התמחור הסטנדרטי של Cloud Logging, BigQuery או Pub/Sub חל בהתאם לאופן ההטמעה של היומנים. הפעלת היומנים לא משפיעה על הביצועים של מאזן העומסים.
שימוש בכלי אבחון לפתרון בעיות
כלי האבחון check-gke-ingress בודק משאבי Ingress כדי לזהות טעויות נפוצות בהגדרות. אפשר להשתמש בכלי check-gke-ingress בדרכים הבאות:
- מריצים את כלי שורת הפקודה
gcpdiagבאשכול. תוצאות ה-Ingress מופיעות בקטעgke/ERR/2023_004check rule. - אפשר להשתמש בכלי
check-gke-ingressלבד או כפלאגין של kubectl. כדי לעשות זאת, פועלים לפי ההוראות במאמר check-gke-ingress.
המאמרים הבאים
אם לא מצאתם פתרון לבעיה שלכם במסמכים, תוכלו לקבל עזרה נוספת במאמר בנושא קבלת תמיכה, כולל עצות בנושאים הבאים:
- פתיחת בקשת תמיכה באמצעות פנייה אל Cloud Customer Care.
- קבלת תמיכה מהקהילה על ידי פרסום שאלות ב-StackOverflow ושימוש בתג
google-kubernetes-engineכדי לחפש בעיות דומות. אפשר גם להצטרף לערוץ Slack#kubernetes-engineכדי לקבל תמיכה נוספת מהקהילה. - פתיחת דיווחים על בעיות או בקשות להוספת תכונות באמצעות הכלי הציבורי למעקב אחר בעיות.