
Este documento apresenta as práticas recomendadas para executar cargas de trabalho de inferência em lote no Google Kubernetes Engine (GKE). A inferência em lote é o processo de usar um modelo de machine learning para gerar previsões em grandes conjuntos de dados, priorizando a alta capacidade de processamento e a economia em relação a respostas imediatas de baixa latência.
Este guia distingue a inferência em lote do agrupamento de solicitações (ou agrupamento dinâmico), uma técnica do lado do servidor em mecanismos como vLLM ou SGLang que agrupa solicitações simultâneas em tempo real para otimizar a eficiência do acelerador. É possível aplicar o agrupamento de solicitações a cargas de trabalho de inferência em lote.
As práticas recomendadas neste guia abrangem dois tipos comuns de padrões de inferência em lote:
- Inferência assíncrona: processa dados em blocos logo após a geração. Com uma latência típica de segundos a minutos, essa abordagem equilibra a necessidade de dados atualizados com a eficiência do processamento simultâneo de vários itens. A inferência assíncrona às vezes é chamada de inferência quase em tempo real.
- Inferência em lote: processa grandes volumes de dados acumulados em intervalos programados (por exemplo, noturnos ou semanais). A latência normalmente varia de horas a dias, já que esses jobs costumam ser programados durante horários de pico para maximizar a disponibilidade de recursos.
Essas recomendações são uma camada especializada de otimização criada com base nos fundamentos descritos na Visão geral das práticas recomendadas de inferência no GKE. Antes de otimizar para cargas de trabalho em lote, siga as práticas recomendadas principais para seleção de modelos, quantização e escolha de aceleradores.
Escolher um padrão arquitetônico para o processamento de inferência em lote
Selecionar o padrão arquitetônico correto é a decisão mais importante para implantar cargas de trabalho de inferência em lote, porque afeta as compensações entre latência, capacidade de processamento e custo. Para manter a eficiência, verifique se a capacidade de processamento de inferência excede a taxa de consultas recebidas durante os horários de pico para evitar que as filas cresçam indefinidamente.
Usar inferência assíncrona para trabalhos em lote
A inferência assíncrona funciona bem para casos de uso que exigem atualizações frequentes e incrementais, como:
- Atualizar perfis de recomendação do usuário a cada poucos minutos com base em interações recentes.
- Processar menções de rede social em intervalos de um minuto para monitoramento em tempo real.
- Detectar sinais de movimentação de mercado em fluxos de dados financeiros de alta frequência.
- Realizar análises de sentimento no feedback do cliente ou em feeds de notícias.
Escolha esse padrão se a carga de trabalho puder tolerar latência que varia de vários segundos a alguns minutos.
Ao implementar a inferência assíncrona, considere as seguintes características:
- Latência: você pode esperar um tempo até o primeiro token que varia de dezenas de segundos a minutos.
- Fontes de dados: normalmente, você processa conjuntos de dados que variam de megabytes a gigabytes, como mensagens do Pub/Sub ou arquivos do Cloud Storage acumulados em uma pequena janela de tempo.
- Padrão de computação: sua infraestrutura precisa oferecer suporte a um serviço contínuo que processa picos frequentes de trabalho.
- Otimização de custos: esse padrão oferece um equilíbrio entre inferência em tempo real de baixa latência e processamento em lote de alta capacidade.
Usar inferência em lote para conjuntos de dados enormes
A inferência em lote é ideal para jobs episódicos em grande escala que podem tolerar atrasos de horas ou dias, como:
- Gerar relatórios de avaliação de risco noturnos com base nas transações financeiras do dia anterior.
- Criar embeddings de produtos para um catálogo inteiro para ativar sistemas de pesquisa e recomendação downstream.
- Rotular grandes conjuntos de dados de imagens para treinamento de modelo ou categorização de arquivos.
Escolha esse padrão se você estiver processando grandes volumes de dados e puder tolerar latências que variam de horas a vários dias.
Ao implementar a inferência em lote, considere as seguintes características:
- Latência: a latência de início da carga de trabalho normalmente varia de minutos a dias porque os jobs costumam ser programados durante horários de pico.
- Fontes de dados: você processa grandes conjuntos de dados de gigabytes a petabytes, normalmente armazenados em tabelas do Cloud Storage ou do BigQuery.
- Padrão de computação: você usa jobs episódicos e em lote que inicializam, processam os dados e encerram.
- Otimização de custos: esse padrão é altamente otimizável com um modelo de pagamento por uso. Como os jobs em lote têm janelas de conclusão flexíveis, recomendamos o uso de VMs spot para reduzir custos.
Otimizar a capacidade de processamento e a economia
As cargas de trabalho de inferência em lote são adequadas para infraestruturas econômicas que podem envolver interrupções.
Usar VMs spot para reduzir os custos de computação
Use os descontos das VMs spot para jobs em lote. Como as cargas de trabalho de inferência em lote normalmente são tolerantes à latência e às interrupções, elas são boas candidatas para o preço reduzido da capacidade spot.
Verifique se o código de inferência em lote implementa checkpointing para processar possíveis eventos de preempção. Se uma VM spot for interrompida, você poderá criar um novo nó e retomar a carga de trabalho do último lote processado em vez de reiniciar do zero.
Ajustar o tamanho do lote de carga de trabalho e o tamanho do lote de solicitações
Para evitar a contenção de recursos e os tempos limite de jobs, verifique se o número de itens enviados ao mecanismo (lote de carga de trabalho) é pelo menos tão grande quanto as solicitações simultâneas que o servidor pode processar (lote de solicitações) para evitar a subutilização de aceleradores.
Ajustar o tamanho do lote de carga de trabalho
O tamanho do lote de carga de trabalho é o número total de itens enviados ao mecanismo de inferência em uma única unidade de trabalho. Você configura isso na lógica de envio do cliente ou na configuração do job do Kubernetes, fragmentando os dados ou agrupando vários itens em uma única solicitação.
Para determinar o tamanho ideal do lote de carga de trabalho, use os seguintes limites:
- Calcular o tamanho mínimo do lote: verifique se o tamanho do lote de carga de trabalho é pelo menos tão grande quanto o tamanho do lote de solicitações. Por exemplo, enviar um item para um servidor que pode processar 256 itens simultaneamente resulta em subutilização significativa. Para encontrar o tamanho mínimo, verifique a configuração do servidor de inferência, como o argumento
max_num_seqsno vLLM. É possível configurar a lógica do cliente para agrupar vários itens em uma única solicitação ou fragmentar os dados para que cada job receba uma quantidade mínima de dados que atenda ou exceda o tamanho do lote de solicitações. - Calcular o tamanho máximo do lote: verifique se o tamanho do lote de carga de trabalho permite que o pod termine antes de atingir o
activeDeadlineSecondstempo limite definido no job do Kubernetes. Estime o tempo necessário para processar um lote de solicitações e defina o tamanho da carga de trabalho para que o pod seja concluído dentro do prazo. Por exemplo, se oactiveDeadlineSecondsfor de 3.600 segundos e a sobrecarga de inicialização for de 600 segundos, verifique se o tempo máximo de execução permite que o pod termine em menos de 3.000 segundos.
Se o tamanho do lote de carga de trabalho for muito pequeno, o job vai perder tempo com a sobrecarga de inicialização do pod (download de pesos, provisionamento, inicialização do acelerador);
se for muito grande, você corre o risco de o job ser encerrado pelo
GKE devido ao
activeDeadlineSeconds
tempo limite, fazendo com que o job falhe e perca o progresso.
Ajustar o tamanho do lote de solicitações
O tamanho do lote de solicitações é o número de solicitações simultâneas que o servidor de inferência processa simultaneamente no acelerador. Você otimiza esse parâmetro ajustando sinalizações específicas do servidor na configuração do servidor de inferência (por exemplo, a sinalização --max-num-seqs para vLLM).
Seu objetivo é maximizar a utilização da GPU sem acionar erros de falta de memória (OOM, na sigla em inglês). Se o tamanho do lote de solicitações não for calibrado, o sistema vai subutilizar o acelerador ou falhar no servidor de modelo. Para o vLLM, é possível usar
ferramentas como o script
auto_tune do vLLM para
encontrar os melhores valores para as configurações max_num_seqs e max_num_batched_tokens para seu
hardware específico. Para mais informações, consulte
Otimizar a configuração do servidor de inferência
no guia Visão geral das práticas recomendadas de inferência no GKE.
Implementar componentes assíncronos para inferência assíncrona
Para inferência assíncrona, recomendamos o uso de buffers de mensagens para desacoplar a camada de ingestão da camada de inferência.
O diagrama de arquitetura a seguir ilustra um exemplo de plataforma de inferência assíncrona. Essa arquitetura protege os servidores de inferência contra picos de tráfego, gerencia backlogs de trabalho e garante alta utilização do acelerador.
O diagrama mostra o fluxo do Pub/Sub para assinantes, um gateway de inferência e um servidor de inferência, com resultados mantidos no AlloyDB e mensagens com falha enviadas para um tópico de mensagens inativas.
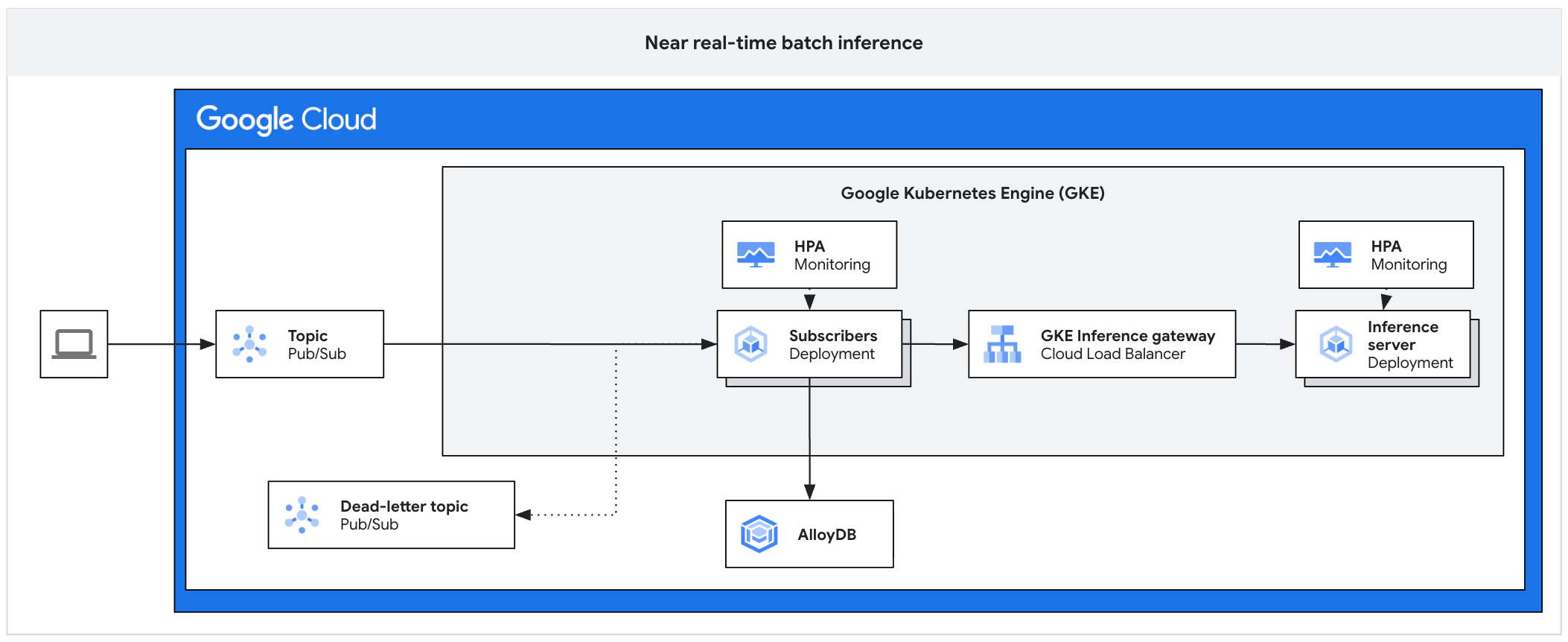
A arquitetura consiste nos seguintes componentes:
- Tópico do Pub/Sub:atua como um buffer persistente para mensagens de clientes recebidas, com um período de armazenamento de 7 a 31 dias.
- Assinante:um componente que lê lotes de mensagens, envia solicitações ao servidor de inferência e confirma o processamento.
- HPA do assinante:escalona a implantação do assinante com base na métrica
num_undelivered_messages(o número de mensagens não reconhecidas). - Armazenamento:mantém os resultados de inferência usando um banco de dados (como o AlloyDB) ou armazenamento de objetos (como o Cloud Storage) .
- Gateway de inferência:expõe as cargas de trabalho de inferência ao assinante.
- Servidor de inferência:processa as solicitações de inferência em lote (por exemplo, vLLM).
- HPA do servidor:escalona o mecanismo de inferência com base em métricas específicas do mecanismo, como
vllm:num_requests_waiting. - Tópico de mensagens inativas:captura mensagens que falham no processamento após um número definido de novas tentativas de espera exponencial.
Para mais informações, consulte a implementação de referência no GitHub.
Buffer e agregar solicitações
Para gerenciar o fluxo de solicitações, faça o seguinte:
- Usar o Pub/Sub como um buffer durável:implemente o Pub/Sub para armazenar solicitações de inferência de maneira durável. Essa configuração atua como um buffer FIFO que mantém as solicitações até que um consumidor tenha capacidade para processá-las, evitando a sobrecarga do servidor durante o tráfego em lote.
- Usar assinaturas de extração com controle de fluxo do lado do cliente: configure um modelo de assinatura de extração. Isso permite que o aplicativo assinante solicite mensagens explicitamente apenas quando tiver capacidade para processá-las, concedendo controle total sobre a taxa de consumo.
- Agregar mensagens para preencher o tamanho do lote do servidor:evite enviar uma mensagem do Pub/Sub como uma solicitação de inferência. Em vez disso, o assinante precisa agrupar várias mensagens em uma única solicitação em lote que esteja alinhada ao tamanho do lote ideal do servidor de inferência (por exemplo, correspondendo às configurações
max_num_seqsno vLLM). Essa abordagem ajuda a garantir que os aceleradores estejam totalmente saturados e maximiza a capacidade de processamento. Especificamente, configure a configuração de extraçãomax_messagesdo assinante como um múltiplo demax_num_seqspara garantir que cada passagem direta do modelo esteja totalmente saturada.
Escalonar automaticamente assinantes e servidores
A inferência em lote eficaz exige o escalonamento dos assinantes (vinculados à CPU) de maneira diferente dos servidores de inferência (vinculados à GPU ou TPU).
Escalonar assinantes com base no backlog de trabalho:configure o HorizontalPodAutoscaler (HPA) para a implantação do assinante com base na métrica
num_undelivered_messagesdo Pub/Sub. Para mais informações, consulte Otimizar o escalonamento automático de pods com base em métricas. Calcule as réplicas que você quer usar usando a seguinte equação:\[ desiredReplicas = \frac{num\_undelivered\_messages}{target\_latency\_seconds \times throughput\_per\_replica} \]
Respeitar as cotas de infraestrutura:limite explicitamente o número máximo de réplicas dos assinantes configurando a configuração
maxReplicasno HPA. Não escale os assinantes além do que a cota de GPU ou TPU dos servidores de inferência pode oferecer suporte. O provisionamento excessivo de assinantes vai mudar o gargalo para o servidor de inferência, aumentando a contenção de recursos sem aumentar a capacidade de processamento.Escalonar servidores de inferência com base em métricas do mecanismo:escale a implantação do servidor de inferência com base em métricas exportadas diretamente pelo mecanismo de inferência (não apenas pela CPU/memória). Por exemplo, use a configuração
vllm:num_requests_waitingpara vLLM, que mede diretamente o backlog de processamento no nível do servidor de modelo. Para mais informações, consulte Escalonar automaticamente seus pods.
Tratar erros e tempos limite
Para tratar erros e tempos limite, faça o seguinte:
- Estender proativamente os prazos de confirmação:configure o assinante para estender proativamente o prazo de confirmação (ack) do Pub/Sub para mensagens que estão sendo processadas para evitar loops de reentrega e processamento duplicado. Essa abordagem é necessária porque as tarefas de inferência costumam levar mais tempo do que as janelas de tempo limite padrão. Como regra geral, defina o período de extensão para ser maior do que o tempo de inferência em lote no pior caso.
- Isolar falhas com um tópico de mensagens inativas:ative um tópico de mensagens inativas para isolar automaticamente mensagens malformadas que falham na entrega repetidamente. Essa abordagem impede que mensagens de "pílula de veneno" bloqueiem a fila e interrompam todo o pipeline.
- Implementar estratégias de espera:se o servidor de inferência retornar erros
429(muitas solicitações) ou503(serviço indisponível), o assinante precisará detectar esses erros e implementar uma estratégia de espera exponencial, pausando temporariamente o consumo do Pub/Sub até que o servidor seja recuperado.
Orquestrar jobs em lote em escala
Siga estas práticas recomendadas para maximizar a capacidade de processamento, garantir a economia, implementar a rastreabilidade abrangente para auditoria e aplicar o gerenciamento avançado de cotas e a priorização de jobs ao processar conjuntos de dados enormes.
Usar o JobSet para inferência distribuída de vários nós
Recomendamos o uso do recurso JobSet do Kubernetes para orquestrar cargas de trabalho de inferência distribuídas que exigem a cooperação de vários nós, como modelos grandes executados em pods de TPU ou clusters de GPU de vários nós. Os jobs padrão do Kubernetes não podem garantir que todos os pods necessários sejam iniciados simultaneamente, o que pode levar a impasses em cargas de trabalho distribuídas.
O JobSet é uma API nativa do Kubernetes que gerencia grupos de jobs como uma unidade e oferece os seguintes benefícios para inferência em lote:
- Programação de gangues:ajuda a garantir que todos os recursos necessários, como frações de TPU ou nós de GPU, estejam disponíveis antes de iniciar a carga de trabalho para evitar impasses.
- Posicionamento exclusivo:ajuda a garantir que um único JobSet tenha acesso exclusivo à topologia de rede (por exemplo, uma fração de TPU) para maximizar a performance da interconexão.
- Recuperação de falhas:permite reiniciar jobs replicados específicos ou todo o conjunto se um worker falhar, dependendo da configuração.
Usar jobs indexados para fragmentação de dados
Ao usar o JobSet, configure o ReplicatedJob para usar a configuração completionMode:
Indexed. Essa configuração injeta automaticamente uma variável de ambiente JOB_COMPLETION_INDEX em cada pod. O código de inferência pode usar esse índice para selecionar deterministicamente um fragmento exclusivo de dados a ser processado.
Por exemplo, se você tiver um bucket do Cloud Storage com 100.000 imagens e implantar um JobSet com um paralelismo de 10, cada um dos 10 pods vai ler o índice (0 a 9) na inicialização. O pod 0 pode calcular que ele precisa processar imagens de 0 a 9.999, enquanto o pod 1 processa de 10.000 a 19.999. Essa abordagem reduz a necessidade de um serviço de fila de tarefas separado.
Usar o padrão de sidecar para saturação do servidor
Para maximizar a utilização do acelerador, configure os pods do JobSet com dois contêineres usando o padrão de sidecar:
- Servidor de inferência:um servidor otimizado (como o vLLM) que se concentra inteiramente na computação de GPU ou TPU.
- Driver do cliente:um contêiner lógico que envia de forma assíncrona um grande volume de solicitações ao servidor no localhost.
Esse desacoplamento ajuda a garantir que a GPU ou TPU permaneça ocupada e nunca fique inativa enquanto aguarda a E/S de rede ou o pré-processamento de dados. Sem essa abordagem, os modelos que carregam dados sequencialmente podem fazer com que o acelerador aguarde a conclusão das operações de E/S, levando à subutilização. Por exemplo, em vez de esperar que os dados sejam processados, o driver do cliente pode pré-buscar dados e enviar continuamente solicitações assíncronas ao servidor de inferência, o que ajuda a garantir que a fila de solicitações do acelerador permaneça saturada.
Lista de verificação resumida
| Categoria | Prática recomendada |
|---|---|
| Padrões arquitetônicos |
|
| Custo e capacidade de processamento |
|
| Mensagens e escalonamento |
|
| Orquestração |
|