
Questo documento fornisce le best practice per l'esecuzione di carichi di lavoro di inferenza batch su Google Kubernetes Engine (GKE). L'inferenza batch è il processo di utilizzo di un modello di machine learning per generare previsioni su grandi set di dati, dando la priorità a un throughput elevato e all'efficienza dei costi rispetto a risposte immediate a bassa latenza.
Questa guida distingue l'inferenza batch dal batching delle richieste (o batching dinamico), una tecnica lato server in motori come vLLM o SGLang che raggruppa le richieste simultanee in tempo reale per ottimizzare l'efficienza dell'acceleratore. Puoi applicare il batching delle richieste ai carichi di lavoro di inferenza batch.
Le best practice descritte in questa guida riguardano due tipi comuni di pattern di inferenza batch:
- Inferenza asincrona: elabora i dati in blocchi poco dopo la generazione. Con una latenza tipica di secondi o minuti, questo approccio bilancia la necessità di dati aggiornati con l'efficienza dell'elaborazione simultanea di più elementi. L'inferenza asincrona è talvolta definita inferenza quasi in tempo reale.
- Inferenza batch: elabora grandi volumi di dati accumulati a intervalli pianificati (ad esempio, ogni notte o ogni settimana). La latenza in genere varia da ore a giorni, poiché questi job vengono spesso pianificati durante i periodi di non punta per massimizzare la disponibilità delle risorse.
Questi consigli sono un livello specializzato di ottimizzazione basato sulle fondamenta descritte nella panoramica delle best practice di inferenza su GKE. Prima di eseguire l'ottimizzazione per i workload batch, assicurati di aver seguito le best practice di base per la selezione del modello, la quantizzazione e la scelta dell'acceleratore.
Scegli un pattern architetturale per l'elaborazione dell'inferenza batch
La selezione del pattern architetturale corretto è la decisione più critica per il deployment dei carichi di lavoro di inferenza batch, perché influisce sui compromessi tra latenza, velocità effettiva e costi. Per mantenere l'efficienza, assicurati che il throughput di inferenza superi la velocità delle query in entrata durante le ore non di punta per evitare che le code crescano all'infinito.
Utilizza l'inferenza asincrona per il lavoro a raffica
L'inferenza asincrona è adatta ai casi d'uso che richiedono aggiornamenti incrementali frequenti, ad esempio:
- Aggiornamento dei profili di raccomandazione degli utenti ogni pochi minuti in base alle interazioni recenti.
- Elaborazione delle menzioni sui social media a intervalli di un minuto per il monitoraggio in tempo reale.
- Rilevamento di segnali che influenzano il mercato da flussi di dati finanziari ad alta frequenza.
- Eseguire l'analisi del sentiment sul feedback dei clienti in arrivo o sui feed di notizie.
Scegli questo pattern se il tuo workload può tollerare una latenza che va da diversi secondi a pochi minuti.
Quando implementi l'inferenza asincrona, considera le seguenti caratteristiche:
- Latenza: puoi aspettarti un tempo di attesa per il primo token che va da decine di secondi a minuti.
- Origini dati: in genere elabori set di dati che vanno da megabyte a gigabyte, ad esempio messaggi da Pub/Sub o file da Cloud Storage accumulati in un breve periodo di tempo.
- Pattern di calcolo: la tua infrastruttura deve supportare un servizio continuo che gestisca frequenti picchi di lavoro.
- Ottimizzazione dei costi: questo pattern offre un equilibrio tra inferenza in tempo reale a bassa latenza ed elaborazione batch a throughput elevato.
Utilizzare l'inferenza batch per set di dati di grandi dimensioni
L'inferenza batch è ideale per job episodici su larga scala che possono tollerare ritardi di ore o giorni, ad esempio:
- Generazione di report di valutazione del rischio notturni in base alle transazioni finanziarie del giorno precedente.
- Creazione di incorporamenti di prodotti per un intero catalogo per potenziare i sistemi di ricerca e suggerimenti downstream.
- Etichettatura di grandi set di dati di immagini per l'addestramento del modello o la categorizzazione dell'archiviazione.
Scegli questo pattern se elabori grandi volumi di dati e puoi tollerare latenze che vanno da ore a diversi giorni.
Quando implementi l'inferenza batch, considera le seguenti caratteristiche:
- Latenza: la latenza di avvio del workload varia in genere da minuti a giorni perché i job vengono spesso pianificati durante gli orari non di punta.
- Origini dati: elabori set di dati di grandi dimensioni, da gigabyte a petabyte, in genere archiviati in Cloud Storage o nelle tabelle BigQuery.
- Pattern di calcolo: utilizzi job episodici e burst che inizializzano, elaborano i dati e poi terminano.
- Ottimizzazione dei costi: questo pattern è altamente ottimizzabile con un modello pay-per-use. Poiché i job batch hanno finestre di completamento flessibili, ti consigliamo di utilizzare le VM spot per ridurre i costi.
Ottimizza per velocità effettiva ed efficienza in termini di costi
I carichi di lavoro di inferenza batch sono particolarmente adatti per un'infrastruttura a basso costo che potrebbe comportare interruzioni.
Utilizzare le VM spot per ridurre i costi di calcolo
Utilizza gli sconti delle VM spot per i job batch. Poiché i carichi di lavoro di inferenza batch sono in genere tolleranti alla latenza e alle interruzioni, sono buoni candidati per i prezzi ridotti della capacità spot.
Assicurati che il codice di inferenza batch implementi il checkpointing per gestire potenziali eventi di preemption. Se una VM spot viene interrotta, puoi creare un nuovo nodo e riprendere il workload dall'ultimo batch elaborato anziché riavviarlo da zero.
Ottimizza le dimensioni del batch del carico di lavoro e della richiesta
Per evitare la contesa delle risorse e i timeout dei job, assicurati che il numero di elementi inviati al motore (batch di workload) sia almeno pari alle richieste simultanee che il server può elaborare (batch di richieste) per evitare di utilizzare in modo insufficiente gli acceleratori.
Ottimizzare le dimensioni del batch del carico di lavoro
La dimensione del batch del carico di lavoro è il numero totale di elementi inviati al motore di inferenza in una singola unità di lavoro. Puoi configurare questa impostazione nella logica di invio del client o nella configurazione del job Kubernetes suddividendo i dati o raggruppando più elementi in un'unica richiesta.
Per determinare le dimensioni ottimali del batch di lavoro, utilizza i seguenti limiti:
- Calcola la dimensione minima del batch: assicurati che la dimensione del batch del carico di lavoro sia almeno pari alla dimensione del batch della richiesta. Ad esempio, l'invio di un elemento a un server in grado di elaborare 256 elementi contemporaneamente comporta un sottoutilizzo significativo. Per trovare la dimensione minima, controlla la configurazione del server di inferenza, ad esempio l'argomento
max_num_seqsin vLLM. Puoi configurare la logica del client per raggruppare più elementi in una singola richiesta oppure puoi partizionare i dati in modo che ogni job riceva una quantità minima di dati che soddisfi o superi le dimensioni del batch di richieste. - Calcola le dimensioni massime del batch: assicurati che le dimensioni del batch del workload consentano al pod di terminare prima di raggiungere il timeout
activeDeadlineSecondsdefinito nel job Kubernetes. Stima il tempo necessario per elaborare un batch di richieste e imposta le dimensioni del workload in modo che il pod venga completato entro la scadenza. Ad esempio, se il tuoactiveDeadlineSecondsè di 3600 secondi e l'overhead di avvio è di 600 secondi, assicurati che il tempo di esecuzione massimo consenta al pod di terminare in meno di 3000 secondi.
Se la dimensione del batch del workload è troppo piccola, il job sprecherà tempo per l'overhead di avvio del pod (download dei pesi, provisioning, inizializzazione dell'acceleratore); se è troppo grande, rischi che il job venga terminato da GKE a causa del timeout activeDeadlineSeconds, causando l'esito negativo del job e la perdita dei progressi.
Ottimizzare le dimensioni del batch di richieste
La dimensione del batch di richieste è il numero di richieste simultanee che il server di inferenza
elabora contemporaneamente sull'acceleratore. Ottimizza questo parametro
ottimizzando i flag specifici del server nella configurazione del server di inferenza (ad esempio il flag --max-num-seqs per vLLM).
Il tuo obiettivo è massimizzare l'utilizzo della GPU senza attivare errori di memoria insufficiente (OOM). Se la dimensione del batch di richieste non è calibrata, il sistema sottoutilizzerà l'acceleratore o arresterà il server del modello. Per vLLM, puoi utilizzare
strumenti come lo script
auto_tune di vLLM per
trovare i valori migliori per le impostazioni max_num_seqs e max_num_batched_tokens per il tuo
hardware specifico. Per saperne di più, consulta
Ottimizzare la configurazione del server di inferenza
nella guida Panoramica delle best practice per l'inferenza su GKE.
Implementa componenti asincroni per l'inferenza asincrona
Per l'inferenza asincrona, ti consigliamo di utilizzare buffer di messaggistica per separare il livello di importazione dal livello di inferenza.
Il seguente diagramma dell'architettura illustra un esempio di piattaforma di inferenza asincrona. Questa architettura protegge i server di inferenza dai picchi di traffico, gestisce i backlog di lavoro e garantisce un elevato utilizzo degli acceleratori.
Il diagramma mostra il flusso da Pub/Sub agli abbonati, un gateway di inferenza e un server di inferenza, con i risultati salvati in AlloyDB e i messaggi non riusciti inviati a un argomento di coda dei messaggi non recapitabili.
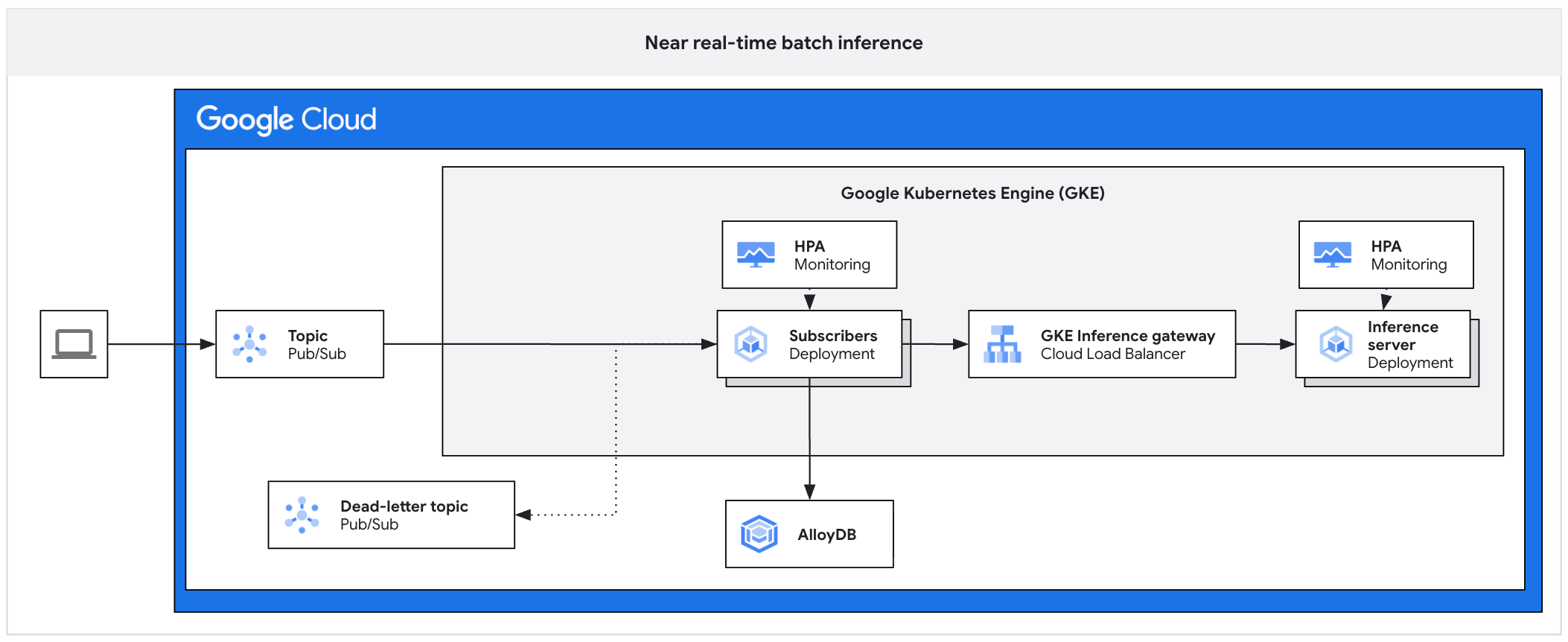
L'architettura è costituita dai seguenti componenti:
- Argomento Pub/Sub:funge da buffer persistente per i messaggi client in entrata, con un periodo di conservazione da 7 a 31 giorni.
- Sottoscrittore:un componente che legge i batch di messaggi, invia richieste al server di inferenza e conferma l'elaborazione.
- HPA per gli abbonati:scala il deployment degli abbonati in base alla metrica
num_undelivered_messages(il numero di messaggi non confermati). - Archiviazione:conserva i risultati dell'inferenza utilizzando un database (ad esempio AlloyDB) o l'archiviazione degli oggetti (ad esempio Cloud Storage) .
- Inference Gateway:espone i workload di inferenza all'abbonato.
- Server di inferenza:elabora le richieste di inferenza batch (ad esempio, vLLM).
- HPA del server:scala il motore di inferenza in base a metriche specifiche del motore
come
vllm:num_requests_waiting. - Argomento messaggi non recapitabili:acquisisce i messaggi la cui elaborazione non è riuscita dopo un numero stabilito di tentativi di backoff esponenziale.
Per maggiori informazioni, consulta l'implementazione di riferimento su GitHub.
Richieste di buffer e aggregate
Per gestire il flusso delle richieste:
- Utilizza Pub/Sub come buffer durevole:implementa Pub/Sub per archiviare le richieste di inferenza in modo durevole. Questa configurazione funge da buffer FIFO che contiene le richieste finché un consumer non ha la capacità di elaborarle, impedendo il sovraccarico del server durante il traffico burst.
- Utilizza le sottoscrizioni pull con il controllo del flusso lato client:configura un modello di sottoscrizione pull. In questo modo, l'applicazione abbonata può richiedere esplicitamente i messaggi solo quando ha la capacità di elaborarli, il che ti consente di controllare completamente la velocità di consumo.
- Aggrega i messaggi per riempire le dimensioni del batch del server:evita di inviare un messaggio Pub/Sub come una richiesta di inferenza. Al contrario, il sottoscrittore deve raggruppare più messaggi in una singola richiesta batch in linea con le dimensioni del batch ottimali del server di inferenza (ad esempio, corrispondenti alle impostazioni
max_num_seqsin vLLM). Questo approccio contribuisce a garantire che gli acceleratori siano completamente saturi e massimizza il throughput. In particolare, configura l'impostazione di pullmax_messagesdel sottoscrittore su un multiplo dimax_num_seqsper garantire che ogni progresso in avanti del modello sia completamente saturo.
Scalabilità automatica di abbonati e server
L'inferenza batch efficace richiede il ridimensionamento dei subscriber (vincolati alla CPU) in modo diverso dai server di inferenza (vincolati alla GPU o alla TPU).
Scalare i sottoscrittori in base al backlog di lavoro:configura HorizontalPodAutoscaler (HPA) per il deployment dei sottoscrittori in base alla metrica
num_undelivered_messagesdi Pub/Sub. Per saperne di più, consulta Ottimizza la scalabilità automatica dei pod in base alle metriche. Calcola le repliche che vuoi utilizzare utilizzando la seguente equazione:\[ desiredReplicas = \frac{num\_undelivered\_messages}{target\_latency\_seconds \times throughput\_per\_replica} \]
Rispetta le quote dell'infrastruttura:limita esplicitamente il numero massimo di repliche dei tuoi abbonati configurando l'impostazione
maxReplicasin HPA. Non scalare gli abbonati oltre quanto la quota di GPU o TPU dei server di inferenza può supportare. Il provisioning eccessivo degli abbonati sposterà il collo di bottiglia sul server di inferenza, aumentando la contesa delle risorse senza aumentare la velocità effettiva.Scala i server di inferenza in base alle metriche del motore:scala il deployment dei server di inferenza in base alle metriche esportate direttamente dal motore di inferenza (non solo tramite CPU/memoria). Ad esempio, utilizza l'impostazione
vllm:num_requests_waitingper vLLM, che misura direttamente il backlog di elaborazione a livello di server del modello. Per saperne di più, consulta Scalare automaticamente i pod.
Gestire errori e timeout
Per gestire errori e timeout:
- Estendi in modo proattivo le scadenze di riconoscimento:configura il sottoscrittore per estendere in modo proattivo la scadenza di riconoscimento (ack) di Pub/Sub per i messaggi in fase di elaborazione per evitare loop di riconsegna ed elaborazione duplicata. Questo approccio è necessario perché le attività di inferenza spesso richiedono più tempo rispetto alle finestre di timeout predefinite. Come regola generale, imposta il periodo di estensione in modo che sia più lungo del tempo di inferenza batch nel caso peggiore.
- Isola gli errori con un argomento messaggi non recapitabili:attiva un argomento messaggi non recapitabili per isolare automaticamente i messaggi non validi che non vengono recapitati ripetutamente. Questo approccio impedisce ai messaggi "poison pill" di bloccare la coda e interrompere l'intera pipeline.
- Implementa strategie di backoff:se il server di inferenza restituisce errori
429(Troppe richieste) o503(Servizio non disponibile), l'abbonato deve rilevarli e implementare una strategia di backoff esponenziale, mettendo temporaneamente in pausa il consumo da Pub/Sub finché il server non viene ripristinato.
Orchestrare i job batch su larga scala
Segui queste best practice per massimizzare il throughput, garantire l'efficienza dei costi, implementare una tracciabilità completa per l'audit e applicare la gestione avanzata delle quote e la definizione delle priorità dei job durante l'elaborazione di set di dati di grandi dimensioni.
Utilizza JobSet per l'inferenza distribuita su più nodi
Ti consigliamo di utilizzare la risorsa Kubernetes JobSet per orchestrare i workload di inferenza distribuiti che richiedono la collaborazione di più nodi, ad esempio modelli di grandi dimensioni eseguiti su pod TPU o cluster GPU multinodo. I job Kubernetes standard non possono garantire l'avvio simultaneo di tutti i pod richiesti, il che può portare a deadlock nei carichi di lavoro distribuiti.
JobSet è un'API nativa di Kubernetes che gestisce gruppi di job come un'unica unità e offre i seguenti vantaggi per l'inferenza batch:
- Pianificazione di gruppo:consente di garantire che tutte le risorse richieste, come le sezioni TPU o i nodi GPU, siano disponibili prima di avviare il workload per evitare deadlock.
- Posizionamento esclusivo:contribuisce a garantire che un singolo JobSet abbia accesso esclusivo alla topologia di rete (ad esempio, una slice TPU) per massimizzare le prestazioni dell'interconnessione.
- Recupero in caso di errore:consente di riavviare job replicati specifici o l'intero set se un worker non funziona, a seconda della configurazione.
Utilizzare i job indicizzati per lo sharding dei dati
Quando utilizzi JobSet, configura ReplicatedJob in modo che utilizzi l'impostazione completionMode:
Indexed. Questa impostazione inserisce automaticamente una variabile di ambiente JOB_COMPLETION_INDEX in ogni pod. Il codice di inferenza può utilizzare questo indice per
selezionare in modo deterministico una partizione univoca di dati da elaborare.
Ad esempio, se hai un bucket Cloud Storage con 100.000 immagini e deploy un JobSet con un parallelismo di 10, ciascuno dei 10 pod legge il proprio indice (0-9) all'avvio. Il pod 0 può quindi calcolare che deve elaborare le immagini da 0 a 9999, mentre il pod 1 elabora le immagini da 10.000 a 19.999. Questo approccio riduce la necessità di un servizio di coda di attività separato.
Utilizza il pattern sidecar per la saturazione del server
Per massimizzare l'utilizzo dell'acceleratore, configura i pod JobSet con due container utilizzando il pattern sidecar:
- Server di inferenza:un server ottimizzato (ad esempio vLLM) che si concentra interamente sul calcolo di GPU o TPU.
- Driver client:un contenitore logico che invia in modo asincrono un volume elevato di richieste al server su localhost.
Questo disaccoppiamento contribuisce a garantire che la GPU o la TPU rimanga occupata e non sia mai inattiva durante l'attesa di I/O di rete o pre-elaborazione dei dati. Senza questo approccio, i modelli che caricano i dati in sequenza possono causare l'attesa dell'acceleratore per il completamento delle operazioni di I/O, con conseguente sottoutilizzo. Ad esempio, anziché attendere l'elaborazione dei dati, il driver client può precaricare i dati e inviare continuamente richieste asincrone al server di inferenza, il che contribuisce a garantire che la coda di richieste dell'acceleratore rimanga satura.
Elenco di controllo di riepilogo
| Categoria | Best practice |
|---|---|
| Pattern architetturali |
|
| Costo e velocità effettiva |
|
| Messaggistica e scalabilità |
|
| Orchestrazione |
|