
Ce document présente les bonnes pratiques pour exécuter des charges de travail d'inférence par lot sur Google Kubernetes Engine (GKE). L' inférence par lot consiste à utiliser un modèle de machine learning pour générer des prédictions sur de grands ensembles de données, en privilégiant un débit élevé et une rentabilité plutôt que des réponses immédiates à faible latence.
Ce guide distingue l'inférence par lot du traitement par lot des requêtes (ou traitement par lot dynamique), une technique côté serveur dans des moteurs tels que vLLM ou SGLang qui regroupe les requêtes simultanées en temps réel pour optimiser l'efficacité de l'accélérateur. Vous pouvez appliquer le traitement par lot des requêtes aux charges de travail d'inférence par lot.
Les bonnes pratiques de ce guide couvrent deux types courants de schémas d'inférence par lot :
- Inférence asynchrone : traite les données par blocs peu de temps après leur génération. Avec une latence typique de quelques secondes à quelques minutes, cette approche équilibre le besoin de données récentes et l'efficacité du traitement simultané de plusieurs éléments. L'inférence asynchrone est parfois appelée inférence en temps quasi réel.
- Inférence par lot : traite de grands volumes de données accumulées à des intervalles planifiés (par exemple, toutes les nuits ou toutes les semaines). La latence varie généralement de quelques heures à quelques jours, car ces tâches sont souvent planifiées en dehors des heures de pointe pour maximiser la disponibilité des ressources.
Ces recommandations constituent une couche d'optimisation spécialisée basée sur les principes décrits dans la présentation des bonnes pratiques d'inférence sur GKE. Avant d'optimiser les charges de travail par lot, assurez-vous d'avoir suivi les bonnes pratiques de base pour la sélection de modèles, la quantification et le choix d'accélérateurs.
Choisir un schéma architectural pour le traitement de l'inférence par lot
La sélection du schéma architectural approprié est la décision la plus importante à prendre pour déployer vos charges de travail d'inférence par lot, car elle affecte les compromis entre la latence, le débit et le coût. Pour maintenir l'efficacité, assurez-vous que votre débit d'inférence dépasse le taux de requêtes entrantes en dehors des heures de pointe afin d'éviter que les files d'attente ne s'allongent indéfiniment.
Utiliser l'inférence asynchrone pour les pics de travail
L'inférence asynchrone est adaptée aux cas d'utilisation qui nécessitent des mises à jour incrémentales fréquentes, tels que les suivants :
- Mise à jour des profils de recommandation des utilisateurs toutes les quelques minutes en fonction des interactions récentes.
- Traitement des mentions sur les réseaux sociaux à intervalles d'une minute pour la surveillance en temps réel.
- Détection des signaux de marché à partir de flux de données financières à haute fréquence.
- Analyse des sentiments sur les commentaires des clients ou les flux d'actualités entrants.
Choisissez ce schéma si votre charge de travail peut tolérer une latence allant de plusieurs secondes à quelques minutes.
Lorsque vous implémentez l'inférence asynchrone, tenez compte des caractéristiques suivantes :
- Latence : vous pouvez vous attendre à un délai avant le premier jeton allant de quelques dizaines de secondes à quelques minutes.
- Sources de données : vous traitez généralement des ensembles de données allant de quelques mégaoctets à quelques gigaoctets, tels que des messages provenant de Pub/Sub ou des fichiers provenant de Cloud Storage accumulés sur une courte période.
- Schéma de calcul : votre infrastructure doit être compatible avec un service continu qui gère les pics de travail fréquents.
- Optimisation des coûts : ce schéma offre un équilibre entre l'inférence en temps réel à faible latence et le traitement par lot à haut débit.
Utiliser l'inférence par lot pour les ensembles de données volumineux
L'inférence par lot est idéale pour les tâches à grande échelle et épisodiques qui peuvent tolérer des délais de quelques heures ou quelques jours, telles que les suivantes :
- Génération de rapports d'évaluation des risques quotidiens basés sur les transactions financières de la veille.
- Création d'embeddings de produits pour l'ensemble d'un catalogue afin d'alimenter les systèmes de recherche et de recommandation en aval.
- Ajout d'étiquettes à de grands ensembles de données d'images pour l'entraînement de modèles ou la catégorisation d'archives.
Choisissez ce schéma si vous traitez de grands volumes de données et que vous pouvez tolérer des latences allant de quelques heures à plusieurs jours.
Lorsque vous implémentez l'inférence par lot, tenez compte des caractéristiques suivantes :
- Latence : la latence de démarrage de la charge de travail varie généralement de quelques minutes à quelques jours car les tâches sont souvent planifiées en dehors des heures de pointe.
- Sources de données : vous traitez de grands ensembles de données allant de quelques gigaoctets à quelques pétaoctets, généralement stockés dans Cloud Storage ou des tables BigQuery.
- Schéma de calcul : vous utilisez des tâches épisodiques et par rafales qui s'initialisent, traitent les données, puis se terminent.
- Optimisation des coûts : ce schéma est hautement optimisable avec un modèle de paiement à l'utilisation. Étant donné que les tâches par lot disposent de fenêtres d'exécution flexibles, nous vous recommandons d'utiliser des VM Spot pour réduire les coûts.
Optimiser le débit et la rentabilité
Les charges de travail d'inférence par lot sont particulièrement adaptées à une infrastructure économique qui peut impliquer des interruptions.
Utiliser des VM Spot pour réduire les coûts de calcul
Utilisez les remises des VM Spot pour les tâches par lot. Étant donné que les charges de travail d'inférence par lot tolèrent généralement la latence et les interruptions, elles sont de bons candidats pour la tarification réduite de la capacité Spot.
Assurez-vous que votre code d'inférence par lot implémente la création de points de contrôle pour gérer les événements de préemption potentiels. Si une VM Spot est préemptée, vous pouvez créer un nœud et reprendre votre charge de travail à partir du dernier lot traité au lieu de redémarrer à zéro.
Ajuster la taille du lot de charge de travail et la taille du lot de requêtes
Pour éviter la contention des ressources et les délais avant expiration des tâches, assurez-vous que le nombre d'éléments envoyés à votre moteur (lot de charge de travail) est au moins aussi important que les requêtes simultanées que le serveur peut traiter (lot de requêtes) afin d'éviter la sous-utilisation des accélérateurs.
Ajuster la taille de lot de votre charge de travail
La taille du lot de charge de travail correspond au nombre total d'éléments envoyés à votre moteur d'inférence dans une seule unité de travail. Vous configurez cela dans la logique d'envoi de votre client ou dans la configuration de la tâche Kubernetes en segmentant vos données ou en regroupant plusieurs éléments dans une seule requête.
Pour déterminer la taille optimale du lot de charge de travail, utilisez les limites suivantes :
- Calculer la taille de lot minimale : assurez-vous que la taille de lot de votre charge de travail est au
moins aussi importante que la taille de lot de votre requête. Par exemple, l'envoi d'un seul élément à un serveur pouvant traiter 256 éléments simultanément entraîne une sous-utilisation importante. Pour trouver votre taille minimale, vérifiez la configuration de votre serveur d'inférence, par exemple l'argument
max_num_seqsdans vLLM. Vous pouvez configurer la logique de votre client pour regrouper plusieurs éléments dans une seule requête, ou vous pouvez segmenter vos données afin que chaque tâche reçoive une quantité minimale de données qui correspond ou dépasse la taille du lot de requêtes. - Calculer la taille maximale du lot : assurez-vous que la taille du lot de charge de travail permet au pod de se terminer avant d'atteindre le délai avant expiration
activeDeadlineSecondsdéfini dans votre tâche Kubernetes. Estimez le temps nécessaire au traitement d'un lot de requêtes et définissez la taille de la charge de travail de sorte que le pod se termine bien avant la date limite. Par exemple, si votreactiveDeadlineSecondsest de 3 600 secondes et que votre surcharge de démarrage est de 600 secondes, assurez-vous que la durée d'exécution maximale permet au pod de se terminer en moins de 3 000 secondes.
Si la taille du lot de charge de travail est trop petite, votre tâche perdra du temps sur la surcharge de démarrage du pod (téléchargement des pondérations, provisionnement, initialisation de l'accélérateur).
Si elle est trop grande, vous risquez que la tâche soit arrêtée par
GKE en raison du
activeDeadlineSeconds
délai avant expiration, ce qui entraînera l'échec de la tâche et la perte de sa progression.
Ajuster la taille du lot de requêtes
La taille du lot de requêtes correspond au nombre de requêtes simultanées que le serveur d'inférence traite simultanément sur l'accélérateur. Vous optimisez ce paramètre en ajustant les options spécifiques au serveur dans la configuration de votre serveur d'inférence (par exemple, l'option --max-num-seqs pour vLLM).
Votre objectif est de maximiser l'utilisation du GPU sans déclencher d'erreurs de mémoire insuffisante (OOM). Si la taille du lot de requêtes n'est pas calibrée, votre système sous-utilisera l'accélérateur ou plantera le serveur de modèles. Pour vLLM, vous pouvez utiliser
des outils tels que le script
vLLM auto_tune pour
trouver les meilleures valeurs pour les paramètres max_num_seqs et max_num_batched_tokens pour votre
matériel spécifique. Pour en savoir plus, consultez la section
Optimiser la configuration de votre serveur d'inférence
dans le guide Présentation des bonnes pratiques d'inférence sur GKE.
Implémenter des composants asynchrones pour l'inférence asynchrone
Pour l'inférence asynchrone, nous vous recommandons d'utiliser des tampons de messagerie pour dissocier votre couche d'ingestion de votre couche d'inférence.
Le schéma d'architecture suivant illustre un exemple de plate-forme d'inférence asynchrone. Cette architecture protège les serveurs d'inférence des pics de trafic, gère les arriérés de travail et garantit une utilisation élevée des accélérateurs.
Le schéma montre le flux de Pub/Sub vers les abonnés, une passerelle d'inférence et un serveur d'inférence, avec des résultats persistants dans AlloyDB et des messages ayant échoué envoyés à un sujet de lettres mortes.
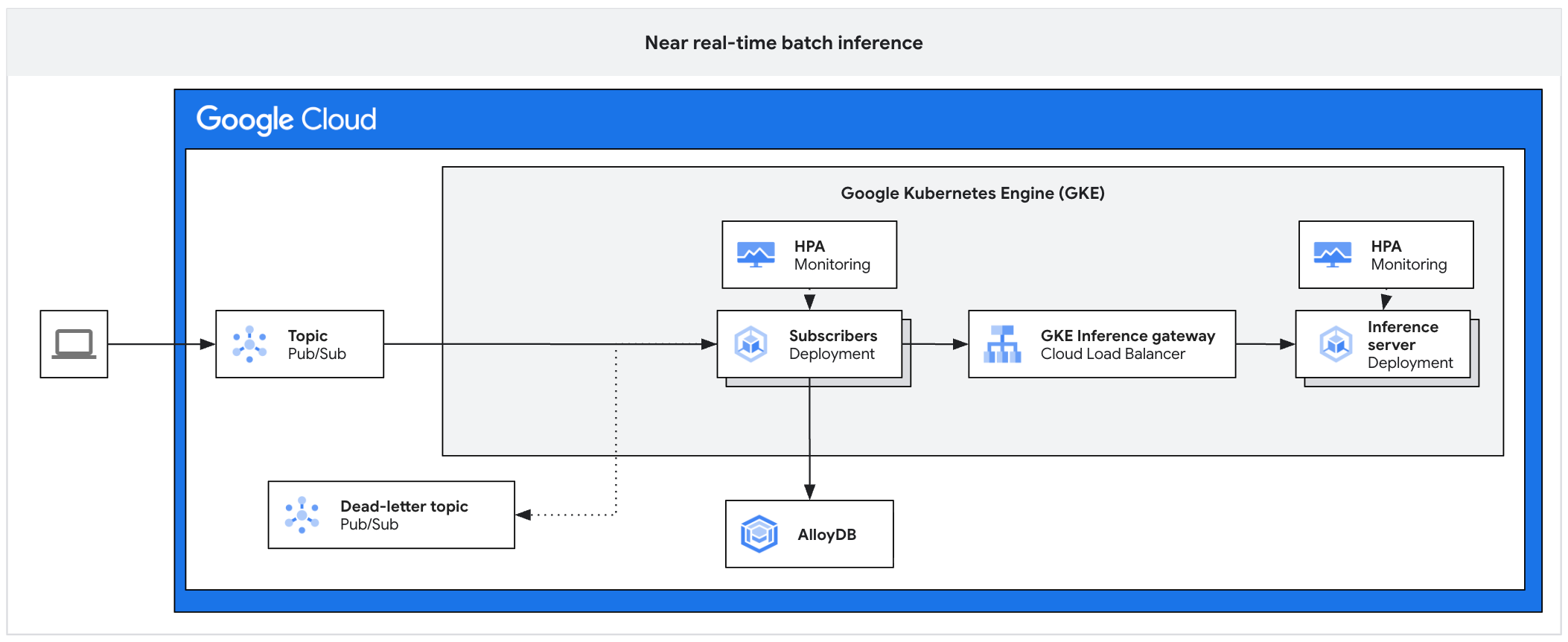
L'architecture se compose des composants suivants :
- Sujet Pub/Sub : sert de tampon persistant pour les messages clients entrants, avec une période de conservation de 7 à 31 jours.
- Abonné : composant qui lit les lots de messages, envoie des requêtes au serveur d'inférence et confirme le traitement.
- HPA de l'abonné : adapte le déploiement de l'abonné en fonction de la métrique
num_undelivered_messages(nombre de messages non confirmés). - Stockage : conserve les résultats d'inférence à l'aide d'une base de données (telle qu'AlloyDB) ou d'un stockage d'objets (tel que Cloud Storage) .
- Passerelle d'inférence : expose les charges de travail d'inférence à l'abonné.
- Serveur d'inférence : traite les requêtes d'inférence par lot (par exemple, vLLM).
- HPA du serveur : adapte le moteur d'inférence en fonction de métriques spécifiques au moteur, telles que
vllm:num_requests_waiting. - Sujet de file d'attente de lettres mortes : capture les messages dont le traitement échoue après un certain nombre de tentatives avec intervalle exponentiel entre les tentatives.
Pour en savoir plus, consultez l'implémentation de référence sur GitHub.
Mettre en mémoire tampon et agréger les requêtes
Pour gérer le flux de requêtes, procédez comme suit :
- Utiliser Pub/Sub comme tampon durable : implémentez Pub/Sub pour stocker les requêtes d'inférence de manière durable. Cette configuration sert de tampon FIFO qui conserve les requêtes jusqu'à ce qu'un consommateur ait la capacité de les traiter, ce qui empêche la surcharge du serveur en cas de pic de trafic.
- Utiliser des abonnements pull avec contrôle de flux côté client : configurez un modèle d'abonnement pull. Cela permet à votre application d'abonné de demander explicitement des messages uniquement lorsqu'elle a la capacité de les traiter, ce qui vous donne un contrôle total sur le taux de consommation.
- Agréger les messages pour remplir la taille du lot de serveurs : évitez d'envoyer un message Pub/Sub en tant que requête d'inférence. Au lieu de cela, l'abonné doit regrouper plusieurs messages dans une seule requête par lot qui correspond à la taille de lot optimale de votre serveur d'inférence (par exemple, en faisant correspondre les paramètres
max_num_seqsdans vLLM). Cette approche permet de s'assurer que les accélérateurs sont entièrement saturés et de maximiser le débit. Plus précisément, configurez le paramètre pullmax_messagesde votre abonné sur un multiple demax_num_seqspour vous assurer que chaque transmission du modèle est entièrement saturée.
Effectuer un autoscaling sur les abonnés et les serveurs
Une inférence par lot efficace nécessite d'adapter les abonnés (liés au processeur) différemment des serveurs d'inférence (liés au GPU ou au TPU).
Adapter les abonnés en fonction de l'arriéré de travail : configurez HorizontalPodAutoscaler (AHP) pour le déploiement de votre abonné en fonction de la métrique
num_undelivered_messagesde Pub/Sub. Pour en savoir plus, consultez la section Optimiser l'autoscaling des pods en fonction des métriques. Calculez les instances répliquées que vous souhaitez utiliser à l'aide de l'équation suivante :\[ desiredReplicas = \frac{num\_undelivered\_messages}{target\_latency\_seconds \times throughput\_per\_replica} \]
Respecter les quotas d'infrastructure : limitez explicitement le nombre maximal d'instances répliquées de vos abonnés en configurant le paramètre
maxReplicasdans votre AHP. N'adaptez pas les abonnés au-delà de ce que le quota de GPU ou de TPU de vos serveurs d'inférence peut prendre en charge. Le surprovisionnement des abonnés déplacera le goulot d'étranglement vers le serveur d'inférence, ce qui augmentera la contention des ressources sans augmenter le débit.Adapter les serveurs d'inférence en fonction des métriques du moteur : adaptez le déploiement de votre serveur d'inférence en fonction des métriques exportées directement par le moteur d'inférence (et pas seulement via le processeur/la mémoire). Par exemple, utilisez le paramètre
vllm:num_requests_waitingpour vLLM, qui mesure directement l'arriéré de traitement au niveau du serveur de modèles. Pour en savoir plus, consultez la section Adapter automatiquement vos pods.
Gérer les erreurs et les délais avant expiration
Pour gérer les erreurs et les délais avant expiration, procédez comme suit :
- Étendre de manière proactive les délais de confirmation : configurez votre abonné pour qu'il étende de manière proactive le délai de confirmation Pub/Sub pour les messages en cours de traitement afin d'éviter les boucles de rediffusion et le traitement en double. Cette approche est nécessaire, car les tâches d'inférence prennent souvent plus de temps que les fenêtres de délai avant expiration par défaut. En règle générale, définissez la période d'extension sur une durée supérieure à votre temps d'inférence par lot dans le pire des cas.
- Isoler les échecs avec une file d'attente de lettres mortes : activez une file d'attente de lettres mortes pour isoler automatiquement les messages mal formés qui échouent à plusieurs reprises. Cette approche empêche les messages "poison pill" de bloquer la file d'attente et d'arrêter l'ensemble de votre pipeline.
- Implémenter des stratégies d'intervalle exponentiel entre les tentatives : si le serveur d'inférence renvoie des erreurs
429(Trop de requêtes) ou503(Service indisponible), l'abonné doit les intercepter et implémenter une stratégie d'intervalle exponentiel entre les tentatives, en mettant temporairement en pause la consommation de Pub/Sub jusqu'à ce que le serveur récupère.
Orchestrer des tâches par lot à grande échelle
Suivez ces bonnes pratiques pour maximiser le débit, garantir la rentabilité, implémenter une traçabilité complète pour l'audit, et appliquer une gestion avancée des quotas et une priorisation des tâches lors du traitement d'ensembles de données volumineux.
Utiliser JobSet pour l'inférence distribuée multinœuds
Nous vous recommandons d'utiliser la ressource Kubernetes JobSet pour orchestrer les charges de travail d'inférence distribuées qui nécessitent la coopération de plusieurs nœuds, tels que les grands modèles exécutés sur des pods TPU ou des clusters GPU multinœuds. Les tâches Kubernetes standards ne peuvent pas garantir que tous les pods requis démarrent simultanément, ce qui peut entraîner des interblocages dans les charges de travail distribuées.
JobSet est une API native de Kubernetes qui gère les groupes de tâches en tant qu'unité et offre les avantages suivants pour l'inférence par lot :
- Planification de groupe : permet de s'assurer que toutes les ressources requises, telles que les tranches de TPU ou les nœuds GPU, sont disponibles avant de démarrer la charge de travail pour éviter les interblocages.
- Placement exclusif : permet de s'assurer qu'un seul JobSet dispose d'un accès exclusif à la topologie du réseau (par exemple, une tranche de TPU) afin de maximiser les performances d'interconnexion.
- Récupération en cas d'échec : vous permet de redémarrer des tâches répliquées spécifiques ou l'ensemble si un nœud de calcul échoue, en fonction de votre configuration.
Utiliser des tâches indexées pour le segmentation des données
Lorsque vous utilisez JobSet, configurez le ReplicatedJob pour qu'il utilise le paramètre completionMode:
Indexed. Ce paramètre injecte automatiquement une variable d'environnement JOB_COMPLETION_INDEX dans chaque pod. Votre code d'inférence peut utiliser cet index pour sélectionner de manière déterministe un segment de données unique à traiter.
Par exemple, si vous disposez d'un bucket Cloud Storage contenant 100 000 images et que vous déployez un JobSet avec un parallélisme de 10, chacun des 10 pods lit son index (0-9) au démarrage. Le pod 0 peut ensuite calculer qu'il doit traiter les images 0 à 9 999, tandis que le pod 1 traite les images 10 000 à 19 999. Cette approche réduit le besoin d'un service de file d'attente de tâches distinct.
Utiliser le schéma side-car pour la saturation du serveur
Pour maximiser l'utilisation de l'accélérateur, configurez vos pods JobSet avec deux conteneurs à l'aide du schéma side-car :
- Serveur d'inférence : serveur optimisé (tel que vLLM) qui se concentre entièrement sur le calcul GPU ou TPU.
- Pilote client : conteneur logique qui envoie de manière asynchrone un volume élevé de requêtes au serveur sur l'hôte local.
Cette dissociation permet de s'assurer que le GPU ou le TPU reste occupé et n'est jamais inactif en attendant les E/S réseau ou le prétraitement des données. Sans cette approche, les modèles qui chargent les données de manière séquentielle peuvent entraîner l'attente de l'accélérateur pour que les opérations d'E/S se terminent, ce qui entraîne une sous-utilisation. Par exemple, au lieu d'attendre le traitement des données, le pilote client peut préextraire les données et envoyer en continu des requêtes asynchrones au serveur d'inférence, ce qui permet de s'assurer que la file d'attente des requêtes de l'accélérateur reste saturée.
Checklist
| Catégorie | Bonne pratique |
|---|---|
| Schémas architecturaux |
|
| Coût et débit |
|
| Messagerie et scaling |
|
| Orchestration |
|